Analysis of Global AI Governance Strategies
post by Sammy Martin (SDM), Justin Bullock (justin-bullock), Corin Katzke (corin-katzke) · 2024-12-04T10:45:25.311Z · LW · GW · 10 commentsContents
Summary
The strength of these strategies depends on alignment difficulty and expected timelines to TAI. We explore how the strength of each strategy varies with these parameters.
These strategies are not necessarily mutually exclusive, and offer varying levels of optionality.
Scenarios involving moderate alignment difficulty require the most further exploration.
Introduction
Criteria
Strategy Comparison
Table
The Strategies explained
Cooperative Development
Strategic Advantage
Global Moratorium
Conclusion
None
10 comments
We analyze three prominent strategies for governing transformative AI (TAI) development: Cooperative Development, Strategic Advantage, and Global Moratorium. We evaluate these strategies across varying levels of alignment difficulty and development timelines, examining their effectiveness in preventing catastrophic risks while preserving beneficial AI development.
Our analysis reveals that strategy preferences shift significantly based on these key variables. Cooperative Development proves most effective with longer timelines and easier alignment challenges, offering maximum flexibility and minimal intrinsic risk. Strategic Advantage becomes more viable under shorter timelines or moderate alignment difficulty, particularly when international cooperation appears unlikely, but carries the most intrinsic risk. Global Moratorium emerges as potentially necessary in scenarios with very hard alignment or extremely short timelines, but is the least intrinsically viable. The paper also examines the transitional possibilities between strategies and their implications for current policy decisions. This analysis provides a framework for policymakers and AI governance stakeholders to evaluate and adapt their approaches as new information about alignment difficulty and development timelines emerges.
Summary
AI governance strategies are broad plans guiding the AI governance community’s efforts to influence Western governments (e.g., the UK, US, and allies), sub-national groups (e.g., California), the international community (e.g. the annual AI safety summits), and leading AI labs. These strategies aim to direct advocacy efforts toward paths that eliminate AI-related existential risks. We have identified three which implicitly underlie the majority of AI governance advocacy or research:
- Cooperative Development (CD): This strategy advocates for regulating TAI development through national and international mechanisms to secure capabilities advantages for trustworthy developers. These developers would use their advantage to create aligned, powerful TAI systems capable of protecting against unaligned or misused AI, ensuring they are deployed widely and effectively. These TAIs would fulfill several goals: limiting the growth of dangerous AI by performing key economic tasks, defending against physical or informational attacks, and ensuring the alignment of other AI systems. CD also seeks to reduce race dynamics, enforce transparency, and promote alignment standards. By avoiding centralization, CD envisions a distributed defense strategy where multiple aligned systems work in concert to protect against misaligned or misused TAI.
- Strategic Advantage (SA): This strategy involves the US or a coalition of allied nations accelerating AI progress by nationalizing or de facto nationalising AI labs. The goal is to develop aligned TAI rapidly and establish a dominant position to prevent rogue actors, unaligned AI, or adversaries from gaining a foothold. The resultant strategic advantage would enable the creation of an accountable global TAI hyperpower, ensuring security and control in the face of emerging risks.
- Global Moratorium (GM): This strategy aims to slow or pause frontier TAI development above a certain level of capability, through international control of large model training and compute governance, using mechanisms like mutual transparency, export controls and verification regimes. The primary goal of GM is to buy time for technical alignment, governance, or defensive measures to reduce the risks posed by uncontrolled TAI development, before proceeding further.
The strength of these strategies depends on alignment difficulty and expected timelines to TAI. We explore how the strength of each strategy varies with these parameters.
- Cooperative Development (CD) is favored when alignment is easy and timelines are longer. In these cases, gradual regulatory development and societal adaptation are more feasible, and the control challenges are more comparable to those of other powerful technologies. CD minimizes the risks associated with centralization and retains flexibility to transition to other strategies if needed.
- Strategic Advantage (SA) is more favored when alignment is easy but timelines are short (under 5 years), in which racing dynamics make cooperation more difficult and proliferation to malicious actors more likely. When offensive AI technologies are likely to outpace defensive technologies, SA becomes yet more favored.
- Global Moratorium (GM) is favored if alignment is very hard, and timelines are short or moderate, as capabilities progress then becomes a "suicide race" where the technology is uncontrollable and it doesn’t matter who develops it. GM also has advantages in moderate or easier alignment scenarios with short timelines, as it mitigates risks of misuse, societal instability, and state conflict even if alignment is not a significant challenge.
These strategies are not necessarily mutually exclusive, and offer varying levels of optionality.
- CD offers the greatest flexibility, with the ability to shift to SA or GM if needed. Transitioning from CD to GM is more straightforward, involving progressively stricter controls on frontier models.
- However, shifting from SA to CD or GM is far more challenging, as SA’s unilateral nature and intensified race dynamics undermine international cooperation.
- Shifting from GM to CD may be feasible—some GM plans (such as ‘A Narrow Path’) call for an eventual transition to CD. However, if hardware progress continues while only frontier AI research stops, this might result in significant ‘hardware overhang’, where lifting GM restrictions could lead to rapid AI advancement as new algorithms are run on faster chips. Shifting from GM to SA seems infeasible.
Scenarios involving moderate alignment difficulty require the most further exploration.
- On longer timelines (20+ years), CD may work well: while the oversight challenges are significant, we will have plenty of time to improve our scientific understanding of AI alignment.
- In moderate timelines (5 to 20 years), we require sophisticated frameworks for cooperative development. If misaligned AIs deceptively fake alignment for instrumental reasons (as happens at moderate and hard difficulties), then conventional tech regulation may not be sufficient, but there is still enough time to develop more effective strategies.
- In shorter timelines, moderate difficulty scenarios favor SA or GM over CD, depending on alignment difficulty or other assumptions, due to the need for rapid action and the difficulty of distinguishing genuine from deceptive alignment. Very short timelines, even with easy or moderate alignment difficulty, might necessitate a shift to GM to buy time to develop more robust alignment techniques.
Introduction
Current AI safety discourse often focuses on extreme scenarios - either very difficult or very easy alignment, and either imminent or distant timelines - while potentially overlooking intermediate possibilities. To address this, we map the space of possibilities in terms of both alignment difficulty and AI development timelines. The ‘strategy comparison’ section will explain how the strategies compare across two key variables - AI development timelines and alignment difficulty, and the ‘strategies explained’ section will then analyze each strategy in full detail, looking at all the considerations that influence which is favored.
This approach aims to illustrate clusters of existing views and highlight neglected areas for further analysis. By doing so, we intend to help individuals and organizations prioritize their work based on an improved picture of the strategic landscape and the key uncertainties.
We discuss 3 major plans and analyses how differing AI timelines or AI alignment difficulty influence their desirability:
- Cooperative Development (CD): International laws ensure defensive AI technologies aligned with humans are developed before offensive technologies, improving security against dangerous AI threats.
- Strategic Advantage (SA): US and Western powers race to develop advanced AI systems for protection, aligning with human values to shape global AI governance.
- Global Moratorium (GM): A global effort is instituted to slow down the development of advanced AI as much as possible to buy time for alignment and governance advances.
The three strategies (Cooperative Development, Strategic Advantage, and Global Moratorium) were derived from a comprehensive review of AI governance literature and discussions with experts in the field. These strategies closely align with the "theories of victory" identified by Convergence Analysis.
However, it's important to note the distinction between the strategies outlined in this analysis and the "theories of victory" discussed in some AI governance literature. While they can be aligned with one another, they serve different purposes and operate at different levels of abstraction.
The 3 Strategies, as presented here, are more concrete and actionable approaches to AI governance, focusing on near-term and mid-term policies and actions. They provide specific guidance on what should be done now and in the coming years by the AI governance community to address AI risks. In contrast, theories of victory are higher-level, more abstract concepts that describe end states and broad pathways to achieving existential security from AI risk. They have a longer-term focus, outlining ultimate goals rather than immediate actions. Strategies can be seen as potential pathways to achieve the end states described in theories of victory, while theories of victory provide the overarching framework within which strategies can be developed and evaluated.
The successful implementation of any of these strategies would make the world safer, but it may not guarantee the ultimate goal of complete existential security. These strategies are intended to address the risks of AI driven great power conflict, catastrophic AI misuse, and catastrophic AI misalignment, and not to address every social or economic problem that could be produced by TAI.
Each strategy has notable proponents within the AI safety community which we have identified.
- Cooperative Development is supported by figures such as Vitalik Buterin, Paul Christiano, Holden Karnofsky, and Carl Shulman, along with labs such as Anthropic. Examples of this approach can be found in Holden Karnofsky's "Success without Dignity [LW · GW]" scenario, Anthropics’ ‘Checklist’ and Vitalik Buterin's “defensive acceleration”.
- The Strategic Advantage approach is described by researchers like Leopold Aschenbrenner or Samuel Hammond and groups like the Heritage Foundation
- Global Moratorium finds support among organisations such as MIRI and initiatives like PauseAI, and has recently been explained in depth in the report ‘A Narrow Path’.
By analyzing these widely-discussed strategies, we aim to provide a framework that captures the main threads of current thinking in AI governance while allowing for nuanced analysis based on varying alignment difficulties and timelines.
Criteria
This describes roughly how we rank outcomes when assessing strategies. This framework is designed to be compatible with a diverse range of ethical and political views, and does not constitute a particular axiology itself—rather, it’s best read as a list of heuristics. If a strategy satisfies these heuristics, it is likely robustly beneficial across common moral views.
- Prevent Existential Catastrophe and Extremely Negative Futures
- Avoid human extinction
- Prevent the lock-in of futures with suffering that outweighs flourishing
- Prevent significantly sub-Optimal Value Lock-Ins
- Avoid futures with authoritarian values or governance structures that, while not causing net suffering, fall far short of potential. Example: An authoritarian surveillance state with an unaccountable elite and great inequality but with lives worth living for most, secure against x-risks but severely limiting human potential
- Preserve a status quo that is not worse than current western liberal democracies
- Prevent any unnecessary Value Lock-Ins
- Prevent scenarios where positive values are permanently locked in, even if they're comparable to or slightly better than current Western liberal democracies
- This recognizes that while such futures might be good, they unnecessarily limit potential for further improvement
- Provide for continued moral and political progress
- Secure a future that's protected against existential risks while maintaining minimal value lock-in, and an environment with pluralistic values that encourage continued moral progress
- This allows for continued moral and societal progress
In this framework, the first points are essential priorities, and the later steps are the next steps if the first steps are achieved. This approach balances preventing catastrophic outcomes with preserving long-term potential for improvement, and is important for e.g. trading off the risk of global war, stable global authoritarianism, misaligned AI takeover and the other potential threat modes.
Strategy Comparison
We here provide an overview of how to effectively choose among the three AI governance strategies considering two primary variables—TAI alignment difficulty and TAI development timelines— which form the basis of our strategy preference table, illustrating how different combinations of these variables influence the desirability of each strategy. We also explore two additional variables – AI takeoff speed and AI offence/defense balance.
- TAI alignment difficulty: “The alignment problem” is the problem of aligning sufficiently powerful AI systems, such that we can be confident they will be able to reduce the risks posed by misused or unaligned AI systems
- TAI development timelines: How long until we see systems which are capable of substituting fully for a human remote-worker at any economically or scientifically relevant task
This section gives us an overview of how these crucial considerations should influence our choice among the 3 governance strategies. In the next section on ‘strategies explained’, we will move into a broader, more qualitative analysis that considers a wider range of variables.
Two other important variables correlate specifically with alignment difficulty and TAI timeline. These other two variables are AI takeoff speed (roughly speaking, the time it takes for an AI system to go from unable to significantly automate the economy to full automation, or alternatively from subhuman to superintelligent) and AI offence-defence balance (how easy it is to cause destruction vs prevent destruction given the widespread availability of TAI). The AI offence-defence balance and takeoff speed arise often in discussions of AI risk, and so it’s worth examining them here.
- Takeoff Speed and Timeline Correlation: Takeoff speed and timeline length are correlated, with longer timelines generally implying slower takeoff. This correlation arises from the current state of AI capabilities; given where we are now, a longer timeline to reach TAI logically implies a more gradual ascent in capabilities from now until then.
- Offence-Defense Balance and Alignment Difficulty Connection: The offence-defence balance in AI development is closely tied to alignment difficulty, with harder alignment generally implying a more offence-dominant landscape. This is because more challenging alignment makes it harder to build reliable defensive AI systems and increases the potential threat from unaligned AI, diminishing defence while increasing offence.
- Offence-Defense Balance and Timeline Connection: In general, shorter timelines suggest more offence-dominance. This is because defence is a many-to-one problem most of the time. Technologies have to be adopted by the whole of society through legal, consensual means to improve defence (e.g. groups need to adopt improved cybersecurity), while offence can be mounted by single actors who just need the technology to be mature.
Our methodology focuses on comparing strategies against each other across different scenarios, rather than evaluating them in isolation. This approach helps identify which strategy is preferable under different conditions and how these preferences might shift as circumstances change. Therefore, our analysis assumes that all three strategies are feasible in principle, though not equally easy to implement.
This assumption allows us to explore the implications of each strategy across different scenarios of alignment difficulty and AI development timelines.
We consider the scenarios to be in approximately descending order of feasibility to enact (CD > SA > GM), leaving aside their chance of success. We judge ‘feasibility to enact’, as the feasibility of the AI governance community convincing the relevant actors to enact policies in accordance with the plan.
Currently:
- CD-aligned policies are already being adopted (e.g., reporting requirements, AI safety institutes in the US and UK, international AI summits) but the public-private partnerships to develop defensive AI are not established. California’s SB 1047, which is a CD-aligned policy, gained strong support before it was defeated. Therefore, CD is closest to the approach already being taken by western countries and therefore requires the smallest change, as it simply requires expanding and adding to existing legal structures, institutes and voluntary commitments as time goes on, with the only new element being proactive deployment of protective technologies.
- Some SA-aligned policies are in place (e.g., investment in domestic chip infrastructure, expanding defence AI projects, increased scrutiny of AI labs from a national security perspective), although key aspects of SA (namely nationalization and state-led AI capabilities development) have not been fully adopted. There have been recent suggestions from congressional committees in the US to build the capacity to develop “AGI”, and we have also seen advocacy for more SA-like approaches from powerful groups like the Heritage Foundation. SA follows precedents for arms races and new technological developments, and so could be expected to be put into place in the future should an AI arms race intensify. Therefore, SA is probably second closest in feasibility.
- GM-aligned policies have been proposed and gained significant attention, but have so far failed to gain significant traction legislatively. However, there is increasing public support for restrictions on AI capabilities, and increasing calls from leading AI researchers. SB 1047 had some GM-like characteristics (and would have resulted in an effective moratorium if models couldn’t be demonstrated to be safe). There are also compelling game-theoretic arguments that on certain assumptions GM is the ‘optimally rational’ strategy. GM strategies have been partially successful for nuclear or chemical weapons, more successful for bioweapons development, and still more successful for the genetic modification of humans, human cloning, and space-based weapons development. These are mostly theoretical comparisons, however, and there are important dissimilarities between AI and those technologies [LW · GW]. That means GM is the least likely.
Since we do not rule out any of the three plans as fundamentally infeasible, when constructing the strategy preference table we make certain assumptions, including:
- The possibility of good faith engagement with major AI-developing nations like China. Competition between major powers (e.g., US and China) is more likely by default than full cooperation, but not inevitable.
- The potential for effective coordination to slow AI development, especially in response to sufficiently strong evidence and warning shots.
- It is possible to develop regulations which effectively mandate alignment testing, safety and capability evaluations and companies may make good-faith efforts to follow them.
- Bad actors will not invariably overtake military-industrial projects to develop aligned AI.
We also don’t make any assumptions about AI timelines or AI alignment difficulty, instead accepting a broad range from very near term (~3 years) to 30+ years, and very easy (Alignment by default [LW · GW]: current techniques scale to superintelligence, misaligned power-seeking never arises by accident) to impossible [LW · GW](any system trained through deep learning of any sort will develop power-seeking misaligned goals when scaled up to superhuman capability, no matter what mitigations are applied).
When speaking of timelines, ‘short’ means under 5 years, ‘medium’ describes 5-20 years and ‘long’ describes over 20 years until TAI. Our detailed analysis of AI alignment difficulty [AF · GW] explains what the difficulty levels represent more fully, but briefly, 1-3 describe states where current techniques like RLHF are sufficient for the intent alignment of TAI, 4-7 describe ‘moderate’ scenarios where interpretability probes, scalable oversight and other still experimental techniques are sufficient [LW · GW], and 8-10 describe worlds where fundamentally new approaches are needed to prevent catastrophic misaligned power seeking, or the alignment of TAI is impossible.
Table
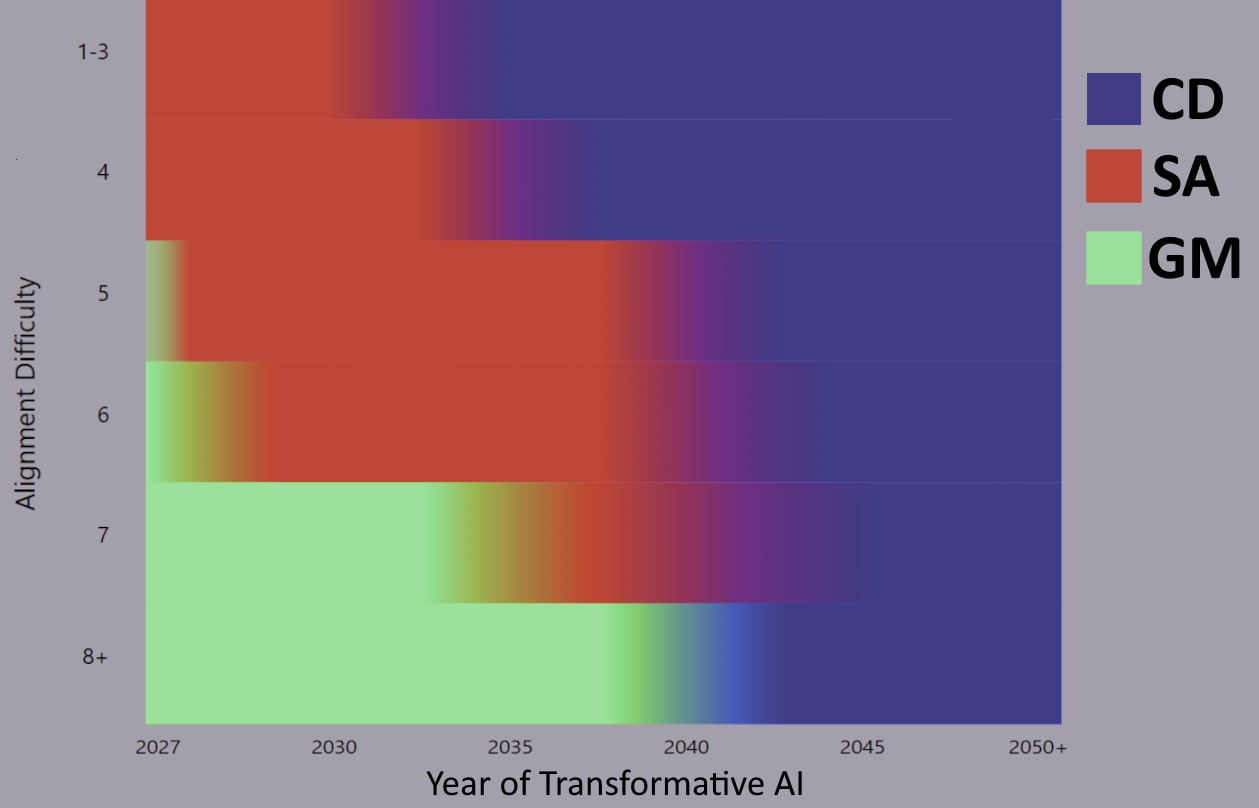
Assuming that all the strategies are feasible in principle, this heat map outlines how we believe variation in TAI timeline and alignment difficulty influences which strategy is preferable. CD is more preferable when alignment is easier and timelines are longer, but is excluded on very short timelines as the incentives to race or defect are too strong. SA is favored for somewhat short timelines as alignment gets harder and GM is the only viable strategy if alignment is very hard unless timelines are long. On long enough timelines, CD is always favored regardless of alignment difficulty.
This heatmap assumes that, before evaluating the key variables of alignment difficulty and timelines, you are roughly indifferent between the three strategies. This assumption, while unrealistic, has been done to illustrate what we believe to be the effects of varying timeline and alignment difficulty separate from other considerations. If, for example, you heavily disfavor SA intrinsically because you think it will lead to global conflict, you should still disfavor it less on lower alignment difficulties and shorter timelines.
What does this heat map tell us?
- Cooperative Development becomes more effective with longer timelines across all alignment difficulties, as there's more time for conventional cooperative efforts to succeed. It's particularly advantageous with easier alignment, due to the less strict requirements on AI developers. It also has the fewest intrinsic risks (SA heavily centralizes power in one actor who could be corrupted, GM forgoes potentially hugely beneficial technology) and so should be considered the default, assuming it can work. CD also has the advantage of being able to most easily switch to SA or GM later if needed, making it less unilateral and irreversible, thus keeping options open.
- Strategic Advantage becomes more important with easier alignment and shorter timeline. In these scenarios, alignment is more feasible, but there's greater potential for damaging disruption from misuse due to faster AI progress, which a strong AI hyperpower could mitigate. However, adopting SA too early with long timelines can be counterproductive, accelerating AI progress and geopolitical competition without achieving strategic advantage sooner, and unnecessarily accelerating development timelines. On shorter timelines, there is less to be lost by accelerating and so this is less of a concern. SA inherently risks catastrophic failure if the centralized project becomes compromised or misaligned and, leaving aside misalignment and misuse risks, has more downsides than CD overall. The importance of nationalisation and racing extends to longer timelines with moderately difficult alignment (levels 5-6), as maintaining a strategic advantage remains crucial even with longer wait times.
- Global Moratorium is favored if alignment is very hard, as progress then becomes a "suicide race." However, with long timelines, CD might still be favoured for potential alignment breakthroughs and near-term AI benefits. GM becomes more relevant with extremely short timelines (2027) even for easier alignment, as it mitigates misuse and structural risks, and addresses the risk of unaligned AI deployment despite solvable alignment. Generally, slowing development is beneficial if timelines are short regardless of alignment risks, as non-misalignment threats (e.g., misuse) become more serious.
The Strategies explained
We have examined how the crucial variables of alignment difficulty and AI timeline influence strategy choice. In this section, we will broaden our analysis and provide a qualitative exploration of CD, SA and GM. For each strategy, we will delve into its underlying assumptions, operational mechanisms, and potential outcomes. We will make the case that each strategy, despite its challenges, is viable in principle and could potentially be the optimal approach depending on how events unfold.
We will consider a range of factors including geopolitical dynamics, the offence-defence balance in AI capabilities, the potential for international cooperation, and the role of various stakeholders in AI development. By examining these strategies through multiple lenses, we aim to provide a nuanced understanding of each approach, highlighting both their strengths and potential weaknesses.
While our strategy preference table focuses on alignment difficulty and timelines, our broader analysis considers various strategic parameters:
- Is good faith engagement between major AI-developing nations possible?
- How offense-dominant (if at all) will TAI technologies be?
- How fast will AI technology diffuse (via copycat development, leaks, deliberate open sourcing)?
- How risky is centralising TAI: what is the chance that a centralised TAI singleton becomes corrupted in some way?
- How much should we trust the safety culture and voluntary safety commitments of AI labs?
- How plausible is it that large institutions can be set up to solve scientific problems without clear feedback loops (as in the case of hard alignment)?
- How likely is it that we will see “warning shots” if alignment is very difficult vs misaligned power seeking arising from invisible failures?
- To what extent would clear warning shots and obvious evidence of imminent risk motivate pressure to slow AI development?
- Would regulators asked to develop effective AI safety regulations actually do so or would other incentives mean that the regulations don’t end up addressing core risks?
Cooperative Development
The underlying idea behind Cooperative Development is defensive acceleration or differential technological development, conducted cooperatively among multiple actors without an attempt to produce a singleton (a single AI hyperpower with a strategic advantage over all others). CD recognizes that AI progress alone won't ensure security, but believes that protective technologies can be developed through private initiative, public-private partnerships, or limited state involvement - though not complete state control. There isn’t a pre-arranged rush to do this, rather an attempt to get ahead of developments and develop effective regulations and defensive technologies. How aggressively and by whom varies depending on the details of the plan: for some, ‘soft nationalisation’ with a few favored developers cooperating closely with the government is the ideal, for others it may be broader and about accountability and transparency requirements.
Three examples of this vision come from Carl Shulman, Vitalik Buterin and Holden Karnofsky. Shulman’s vision emphasizes the importance of AI-enabled checks and balances, including the role AI decision support could play in improving government decision-making and the importance of defensive technologies like biodefense and enhanced cybersecurity. Buterin by contrast covers many of the same overall insights as Shulman but is more focused on the private development of defensive technologies, which create a more resilient world overall, with less central coordination. By contrast, Karnofsky’s overall vision focuses on how a responsible TAI developer can proactively develop defensive technologies for the government, deploying them first to occupy the economic niches that unaligned or dangerous AI could occupy. Similarly, the ‘checklist’ from anthropic involves handing off TAI technologies to the government or some more accountable decision maker after they’ve verified alignment, for defensive purposes.
In CD plans, there is usually also an international component, perhaps involving AI decision support or forecasting, to defuse potential conflicts and avoid racing, even if progress is still quite fast. CD takes a cautious stance toward accelerating AI capabilities development progress more generally (e.g. through dramatic build outs of compute infrastructure prematurely) and would only favor such a project if doing so differentially accelerates defensive technologies by enough to justify the lost AI timeline.
Cooperative Development strategies have several key features.
- Proactive development of technologies to address the offence-defence balance (e.g. biodefense, cyberdefense, alignment verification)
- A substantial role for AI decision support as well as defensive AI technologies (to manage the fast-changing world during AI takeoff)
- Some form of government intervention to promote defensive development.
- This could involve just regulations and incentives in the most hands off case described by Buterin, or more direct close public-private cooperation or even ‘soft nationalisation’
- Eventual adoption of defensive AI technologies across society.
Crucially, rather than attempting to permanently prevent diffusion of dangerous AI technologies, CD focuses on maximizing the time gap between responsible and irresponsible developers.
As a plan, if implemented successfully CD has some desirable features.
- Addressing power concentration risks: By promoting collaborative efforts, CD can help mitigate risks that arise from concentrations of power. Unlike SA there is not a single point of failure, so the risk of authoritarian lock in is substantially reduced.
- Reducing likelihood of AI-driven international conflict: International cooperation reduces the chances of adversarial AI development. It reduces ‘race to the bottom’ dynamics in international competition and the incentives for war.
- Flexibility: CD can more easily transition to other strategies (SA or GM) if needed, making it suitable for uncertain scenarios. It requires the least irreversible commitment to an overall AI governance strategy.
- External feedback: Because CD allows for regulation and public-private partnership rather than closed nationalization and development, there’s the potential for a larger number of actors and independent groups to assess the alignment or safety of models under development. CD probably makes it easier for 3rd party groups to evaluate the safety or alignment of frontier models.
However, it also relies on several crucial assumptions which if violated could render the plan non-viable.
- May be too weak: Crucially, if offensive AI capabilities significantly outpace defensive ones, or the offence-defence balance in general is unfavourable, then CD may struggle to maintain stability as it assumes that AI capabilities will diffuse to many actors eventually.
- Less effective against unilateral actions: If a single actor decides to break away from cooperative agreements and race ahead, CD may struggle to prevent misuse if there isn’t robust enforcement or if defensive technologies aren't ready
- Vulnerable to societal-scale risks: CD trades away risks arising from the concentration of power for the potential for competitive degradation of safety standards to develop in more diffuse contexts.
- Vulnerable to more difficult alignment: If alignment is too difficult for it to be reliably enforced through regulation and public-private cooperation, then CD may fail to produce any aligned useful AI systems in time.
- Vulnerable to foreign adversaries: If China or other powers are unwilling to engage in good faith then attempting CD will likely erode competitive advantage and increase the chance that authoritarian or reckless actors gain a lead.
Analysis
Cooperative Development is an evolved ‘business as usual’ strategy which attempts to use the normal mechanisms of technology adoption and adaptation to handle the challenge of TAI. The goal is to deploy aligned, powerful AI systems for defensive purposes before misaligned or misused AI becomes a significant threat. Even if dangerous AI capabilities eventually diffuse, which CD assumes will probably happen as it doesn't rely on government control to completely stop AI proliferation, this “lead time” is critical for reducing the overall risk posed by TAI.
Protective actions taken by the leading projects are necessary to enhance alignment, provide physical defence against new threats, defend against cyberattacks, and improve cooperation. These capabilities could include automated alignment research, new defensive weapons technologies, counters to viruses (automated biodefense), improved cyberdefense, and AI decision support and forecasting tools. This discussion of High Impact Tasks (HIT) provides [LW · GW]more examples of this dynamic.
Importantly, many of these systems may be superhuman in narrow or even in broad domains: e.g. the decision support systems may (or will eventually, as AI takeoff continues) be vastly superhuman at predicting the consequences of policy decisions or assessing the intent of adversaries.
CD also favors maintaining core human control over decision-making, or a ‘human in the loop’ for as long as possible: e.g. a scenario where human corporate and government leaders employ superhuman decision support systems over a world where these systems are delegated authority themselves, in order to improve stability and reduce the chance of runaway race dynamics. This may need to be enforced by international agreement. It is a more central requirement to retain a “man in the loop” for longer under CD compared to SA, as one can imagine some versions of SA where an agent-like singular system is sent out on its own to act on behalf of the project, but for CD the competition inherent to multiple actors means there needs to be more control of the process.
The effectiveness of Cooperative Development is highly dependent on both alignment difficulty and AI development timelines. In scenarios of easy alignment (levels 1-4), CD becomes increasingly viable as we can anticipate a wide availability of relatively trusted, powerful TAI systems for defensive purposes, along with a lower frequency of unaligned systems, which means the defensive acceleration crucial to CD becomes more viable. Similarly, in terms of the "tech tree of TAI," or which capabilities TAI development enables first, CD works best when key defensive technologies like robust cybersecurity measures, AI alignment verification systems, and decision support tools can be developed and implemented before offensive capabilities (like the ability to rapidly develop new bioweapons) become overwhelming.
Regarding takeoff speed, CD is most effective in scenarios with slower, more gradual takeoffs. This allows time for regulatory frameworks to mature, international cooperation to solidify, and for defensive technologies to be widely adopted. Slower takeoffs also reduce the risk of a single actor gaining a decisive strategic advantage, which is essential for maintaining the cooperative nature of this approach. CD can succeed on faster takeoffs, especially with the help of AI decision-support to navigate the transition, but it is more perilous to attempt.
For CD to succeed, there needs to be enough time from the development of intent-aligned TAI for it to propagate widely and be used in ways that improve the world’s defenses against unaligned AI systems.
These can include [LW · GW]: occupying the economically and scientifically valuable niches that could otherwise be filled by misaligned AI (sometimes this is described as the system using up ‘free energy’ in the global economy), bolstering cyber defences against AI-enabled attacks, improving physical defences against AI enabled threats like new weapons systems, and enhancing international cooperation and decision-making through super-accurate forecasting and decision support.
However, as alignment difficulty increases or timelines shorten, CD faces greater challenges. Medium alignment difficulty scenarios present more complex governance challenges, shifting the focus to creating institutions capable of responding quickly to ambiguous evidence of misalignment. In these cases, all frontier AI developers need to cultivate a strong safety culture for CD to remain viable, and more government intervention e.g. through public-private partnership, is likely needed. Shorter timelines increase the pressure on CD, as there's less time for defensive acceleration through cooperative channels. This may necessitate a shift towards more aggressive strategies.
The viability of CD also depends heavily on the extent of international cooperation, which becomes increasingly vital as takeoff speeds accelerate and the relative diffusion speed of AI technology slows. Without proper global coordination, national CD efforts could devolve into de facto Strategic Advantage (SA) scenarios, especially if all of the leading AI projects are concentrated in a single country like the US. This is made more likely if the TAI technologies developed through public-private partnerships end up under government control. The likelihood of conflict also depends on the natural spread rate of AI technology.
If TAI technology diffuses easily, so ‘catch up growth’ is always possible, there may not be a single state with a strong strategic advantage, and the usual mechanisms of deterrence could prevent conflict without strong international agreements. However, if the speed of technology diffusion is slow relative to AI takeoff speed, then there may be substantial gaps between the leading TAI projects. This may result in strong pressures to compete or race, leading to a winner-take-all dynamic emerging. In this scenario, international agreements become more necessary.
AI-powered decision support systems could play a pivotal role in facilitating CD by providing clear, verifiable information to aid decision-making and de-escalate potential arms races during the fast-changing period of AI takeoff.
For these systems to emerge in time, the critical phase of AI takeoff must not outpace society's ability to adapt, or there must be a smooth diffusion of AI technology. Longer timelines are more conducive to CD as they allow more opportunity for defensive technologies and international cooperation to mature. Longer timelines are correlated with slower takeoff, reducing the likelihood of a decisive strategic advantage and therefore reducing the need for strongly binding international agreements to ensure that one project does not race ahead.
Strict regulations may be necessary for CD, even without the full nationalisation of AI development. The extent of regulation required depends on factors such as alignment difficulty, offence-defence balance, the number of bad actors, and the geopolitical situation. Regulations might include transparency requirements, third-party assessments, and measures to ensure the proactive development of defensive technologies. If the situation is favorable in various ways with responsible developers and slower takeoff, then liability requirements and voluntary commitments and no proactive development may be good enough.
Many skeptical of regulation or aware of past instances of regulatory failure or regulatory capture would argue that CD approaches would not result in binding regulations that effectively address catastrophic risks and would instead just result in useless, burdensome requirements that slow down careful law-abiding actors while doing nothing about risks, or even produce false security. They might also point to the difficulties of measuring alignment progress to argue that AI regulations will impose burdens on cautious developers while not addressing real alignment concerns. They might further argue that it is impossible to reach a good-faith agreement with adversaries like China and trying just opens the door to a strategic disadvantage, even if such regulations are successful in western countries.
Another objection is that CD relies too heavily on the assumption that leading AI labs are safety-minded. If one believes that these labs are not genuinely committed to safety or are willing to cut corners and engage in unethical practices for competitive advantage, this undermines the feasibility of CD. Some may also argue that CD also does not help mitigate incentives for military projects to create dangerous, non-civilian models.
CD proponents have several ways to respond to these objections. One major response is that, while regulatory challenges exist, there are examples of successful international regulation in high-stakes domains, from nuclear non-proliferation to aviation safety. With sufficient political will and clear evidence of AI risks, effective regulations could be implemented, and we have already seen examples of regulatory innovation (e.g. at the UK AISI) aimed at still hypothetical threat models like deceptive alignment.
On international cooperation, CD advocates point to instances where countries have successfully collaborated on global challenges, such as climate change agreements, and the promising signs that AI risk concerns are already being taken seriously globally. As for AI lab safety-mindedness, proponents suggest that a combination of public pressure, market incentives, and regulatory oversight could effectively align lab behavior with safety goals without needing strong assumptions about safety culture. They also argue that CD doesn't necessarily rely on complete trust in AI labs, but rather on creating a framework that incentivizes and enforces safe development practices.
Overall, while (like all the strategies) CD faces formidable challenges, it represents perhaps the most natural evolution of current AI governance efforts. Given certain plausible assumptions about international cooperation and the development of defensive technologies, it offers a viable path forward that builds on existing institutional frameworks rather than requiring radical changes. CD's greatest strength lies in its flexibility and its ability to maintain beneficial AI development while working within established norms. By focusing on defense-first development and maintaining international transparency, it could create a stable foundation for managing TAI risks through cooperation rather than competition. The strategy's emphasis on distributed defense and multiple independent aligned systems provides crucial redundancy against single points of failure. While CD requires significant international coordination and may struggle with very rapid AI development, its alignment with current governance trends and its ability to transition to other strategies if needed make it an important and viable AI governance strategy.
Strategic Advantage
Strategic Advantage emerges from the premise that cooperative approaches are insufficient, necessitating more aggressive control over AI development. Perhaps AI technologies are intrinsically offense-dominant and too dangerous to keep under control, such that even if there are protective technologies developed ahead of time, dangerous AI capabilities will still diffuse too quickly.
On this view, planning for dangerous AI capabilities to eventually diffuse and hoping we can handle them when they do so, is planning to fail. Therefore, only very few companies strictly nationalized or in close cooperation with a government could solve alignment and build the required defensive AI technologies.
SA is also motivated by the view that international competition is unavoidable: the current geopolitical situation (at least as described [LW(p) · GW(p)]by many analysts) combined with the extreme advantage provided by TAI technologies makes any attempts at international cooperation, as described in CD, unviable.
For any or all of these reasons, SA proponents argue that CD is unworkable and so the only remaining option is to win the AI race.
The Strategic Advantage plan therefore proposes that a nation or a small coalition of nations should aim to be the first to develop advanced, aligned AI systems. This approach combines elements of the AI Leviathan concept, where a single entity controls AI, with a strong emphasis on ensuring the AI is aligned with human values and its overseers are held accountable. To achieve this advantage, the plan suggests significant investments in AI research and development, including building massive computing infrastructure, attracting top AI talent to one country or a close alliance (usually the US and allies), and potentially even employing aggressive tactics like export controls or cyber operations against adversaries, to maintain a lead in the TAI race.
Leopold Aschenbrenner and Samuel Hammond have articulated clearer visions for a Strategic Advantage plan. Alongside this, we see the precursors of such plans (focusing on TAI development for national security and rejecting cooperative approaches) from groups like the Heritage Foundation. Hammond focuses on forecasting what he sees as the inevitable result of centralization, with the alternative being the destructive misuse of AI technologies (strong offence-defence imbalance). Ascenbrenner argues from a short-timelines assumption that the racing pressures are too strong to avoid, so therefore SA is the only viable option.
Strategic Advantage offers several key benefits:
- Mitigates societal-scale risks: SA places ultimate control over TAI in a single government or public-private project, meaning that the risks posed by a wide proliferation of powerful AI capabilities under the control of many different actors are mitigated.
- Rapid decision-making: Centralised control allows for quicker responses to emerging risks, relative to CD. If new evidence emerges about dangerous AI technologies or alignment difficulty the singular project can change its approach more easily.
- Mitigating Destructive Misuse: On this plan, dangerous AI capabilities are not supposed to fall into public circulation and so the risk of misuse of offense-dominant technologies is curtailed
- Handling adversaries: In scenarios where adversaries (e.g. China) will not engage with GM or CD approaches in good faith, SA provides a way to handle them anyway
- Better able to handle moderate alignment difficulty: With CD, alignment has to be enforced through standards or government oversight, while with SA the central project can apply as much alignment research as it wants into frontier development. This makes it better suited to cases where the challenges of measuring alignment are greater.
SA represents a high-stakes approach with both significant potential benefits and serious risks. While it can handle threat models that seem unworkable for CD, the project has many significant and unique drawbacks.
- Likely to exacerbate international tensions: SA will assuredly exacerbate or lead to an arms race with other powers developing TAI. This will raise tensions in the leadup to the development of TAI and also increase the likelihood of conflict.
- Irreversible: Unlike CD, which could more easily transition SA, SA is very difficult to back out of once started as arms races are difficult to de-escalate
- Single point of failure: If the leading project is subverted or develops an unaligned TAI, there are no plausible alternatives
- Pressure to cut back on safety measures: Especially for higher alignment difficulty, the pressure to develop more powerful systems and to cut back on safety efforts trade off against each other.
Analysis
SA is a high risk approach which can handle situations which seem too difficult for CD to handle, especially under conditions of incorrigibly hostile foreign adversaries, extreme TAI offence-defence imbalance or moderate alignment difficulty (or a combination of all three), at the cost of removing optionality, introducing new geopolitical and centralization risks and potentially not resolving core alignment challenges at high difficulty. SA, if effectively used to produce a benevolent AI singleton, is also capable of addressing many potential systemic risks inherent in CD.
The viability of Strategic Advantage is significantly influenced by alignment difficulty and AI development timelines. SA becomes more critical with easier alignment and shorter timelines, in order to prevent a significant strategic disadvantage. In these scenarios, while alignment is more feasible, there's greater potential for damaging disruption from misuse due to faster AI progress. SA approaches allow for quicker responses to emerging risks and more centralized control over AI development, which can be crucial in rapid development scenarios.
However, the calculus changes as alignment becomes more difficult or timelines extend. With moderately difficult alignment (levels 5-6), the importance of nationalisation extends to longer timelines, as it may not be feasible for the regulations and public-private cooperation described in CD to instill the necessary rigor and safety culture, even if there is longer to do so. Conversely, adopting SA too early with medium or long timelines can be counterproductive, unnecessarily accelerating AI progress and worsening geopolitical competition. An early adoption of SA can provoke the arms race dynamic without actually securing the desired strategic advantage, becoming highly damaging. In hard alignment scenarios, SA may struggle to effectively address the extreme difficulty in verifying alignment progress, especially when working under race conditions, potentially necessitating a shift towards more restrictive approaches like GM.
SA is more viable in scenarios where the offence-defence balance tilts towards offence, especially if this advantage is expected to be temporary or limited to early-movers. In the context of the TAI “tech tree”, SA works well when offensive capabilities like advanced AI-enabled cyber weapons, autonomous systems, or highly capable persuasive agents can provide a significant edge to their possessor.
However, this offensive advantage must be substantial enough to create a meaningful gap between the leading actor and others, yet not so overwhelming that it becomes impossible to maintain control or prevent proliferation. Regarding takeoff speed, SA is better suited to faster takeoff scenarios. Rapid development leaves less room for gradual, cooperative processes and increases the likelihood that a single actor or small coalition can gain and maintain a decisive lead. In such scenarios, the ability to make quick, unilateral decisions becomes crucial, favoring the more centralized approach of SA. Thus, SA is most effective when AI progress is expected to be rapid and potentially discontinuous, allowing a prepared actor to leap ahead and establish a durable advantage.
Regarding international stability, long-term concerns arise from the potential impact of SA on international tensions. SA could escalate conflicts or trigger an arms race with other powers, potentially even provoking a pre-emptive war. Additionally, it could undermine international trust, making it challenging to transition to alternative approaches such as GM or CD later on if evidence emerges about alignment difficulty.
The existing nuclear deterrence framework could impact the dynamics around SA in dangerous ways, particularly if SA is sought for explicit military advantage. The motivation for a preemptive attack might arise due to the perception that a sufficiently capable AI could potentially undermine a nuclear-armed adversary’s second strike capabilities, eliminating the concept of Mutually Assured Destruction (MAD). Whether a country pursuing SA would lead to a global pre-emptive war is complex and uncertain. The outcome would depend on factors such as the speed of diffusion of SA technology, the levels of international trust, and the broader geopolitical context.
The effectiveness of past centralized development programs reveals important nuances about when SA might succeed or fail. The Manhattan Project demonstrates both the potential and limitations of this approach - while it achieved unprecedented scientific progress through concentrated effort, it also shows how wartime pressures can override safety considerations despite institutional safeguards. Modern examples like DARPA provide a different model, showing how focused government programs can drive technological progress while maintaining stronger safety protocols and civilian oversight. These examples suggest that SA's success may depend heavily on an institutional design that properly balances urgency with safety culture. A further crucial consideration is how SA might evolve if initial assumptions prove incorrect. If alignment proves harder than expected, or if competing programs make more progress than anticipated, an SA project would face intense pressure to cut corners on safety. Creating institutional structures that can resist such pressure while maintaining development speed represents a key challenge.
There are several major objections to SA. Many who are critical of previous national security decisions related to catastrophic or existential risks, e.g. early cold-war era nuclear policy, would argue that any project like this poses an unacceptable risk of discarding safety standards or would just become compromised by those who only care about great power competition at the expense of everything else.
However, SA proponents can point out that there are many examples of successful, safety-conscious government projects, such as NASA's space programs. Regarding power concentration, a well-designed SA approach could include robust checks and balances, civilian oversight, and accountability measures to elected governments that can mitigate authoritarian risks in the same way as other government projects.
SA proponents also emphasize that their approach provides unique advantages in scenarios requiring rapid technological development of defensive measures, or difficult alignment. A well-resourced, coordinated national project might be uniquely positioned to achieve crucial scientific breakthroughs that would be difficult in more fragmented environments. Just as the Manhattan Project achieved unprecedented scientific advances through concentrated effort, or how NASA's focused mission enabled rapid space technology development, an SA approach could potentially accelerate progress on AI alignment and safety in ways that distributed efforts cannot match.
SA proponents can further argue that the risks of centralization must be weighed against the risks of inaction or failed coordination. In scenarios with rapid AI progress or hostile international dynamics, the alternative to SA might not be successful cooperative development, but rather an uncontrolled race to the bottom between multiple actors with varying safety standards. While government control introduces risks of authoritarian capture or safety compromise, a well-structured SA program could establish clear red lines, independent oversight bodies, and constitutional constraints that make safety violations or authoritarian overreach more difficult than in a competitive landscape. The key is establishing institutional structures that embed safety considerations so deeply that they become procedurally impossible to ignore, rather than relying on individual judgment or organizational culture.
Overall, while SA represents a high-stakes and potentially risky approach, it offers a compelling path to existential security in scenarios where cooperative approaches may fail. In situations with hostile international dynamics, very rapid AI progress, or moderate alignment difficulty, SA provides a framework for maintaining control through centralized, accountable development. With careful oversight and democratic constraints, an SA project could channel the race for AI capability into a structured process that prioritizes safety and alignment. While the strategy introduces significant risks of centralization and potential authoritarian outcomes, these might be acceptable trade-offs in scenarios where more cooperative approaches seem likely to fail. The historical precedent of other transformative technologies, from nuclear power to space exploration, suggests that state-led development can successfully balance innovation with safety. Therefore, while SA should not be adopted lightly, it represents a powerful and potentially necessary option that must be seriously considered as part of the strategic landscape.
Global Moratorium
The Global Moratorium strategy seeks to establish a coordinated international effort to significantly slow or halt the development of advanced AI systems beyond certain capability thresholds. Unlike a permanent ban, this approach allows for the eventual possibility of controlled, cautious development with a strong emphasis on safety and risk mitigation. GM aims to slow AI development globally, not just in specific countries, by implementing ceilings on computing power for AI training and/or controlling the sale of high-performance hardware worldwide.
GM can be configured to activate automatically in response to specific triggers - whether shifts in public opinion, concrete warning events, or the crossing of predetermined AI capability thresholds (such as fully autonomous replication, fully automating AI research or genuine evidence of ability to accelerate weapons development). It involves establishing strong international institutions to oversee compute access and usage, drawing lessons from nuclear nonproliferation and climate change efforts. GM may include elements of defensive acceleration, using the additional time to develop robust safety measures and less powerful AI systems with realized benefits. The strategy also involves preparing for eventually lifting the moratorium once verifiable and robust safeguards are in place.
Global Moratorium finds support among organizations such as MIRI and initiatives like PauseAI, and has recently been explained in depth in the report ‘A Narrow Path’. This report calls for a 20 year moratorium with plans to eventually resume the development of TAI after institutional and scientific advances. The Existential Risk Observatory advocates for a ‘Conditional AI safety treaty’ with focus on pausing only when specific, actionable dangerous capability thresholds have been reached. Both these later plans focus on ensuring that the capability triggers for such a drastic step clearly constitute signs of danger, so it is only existentially risky TAI systems that are banned.
As a plan, if implemented successfully, GM has several significant advantages:
- It delays potential catastrophic risks, providing more time to solve fundamental AI safety problems
- It allows safety researchers to make progress on AI alignment without racing against capability developments
- It enables the development of (non-TAI enabled) defensive measures and allows societal resilience to enhance
- It reduces the risks posed by the rapid, uncontrolled proliferation of advanced AI systems
- It provides time for the establishment of strong international governance frameworks
However, GM also faces substantial challenges and potential drawbacks:
- It is potentially extremely difficult to enforce globally, requiring unprecedented levels of international cooperation and monitoring. Likely to face strong opposition from AI-developing nations and companies, making implementation challenging
- It may not directly address underlying technical challenges of AI safety
- As with CD, it is vulnerable to defection, by covert development of AI systems by non-compliant actors (especially military projects).
- It could lead to significant opportunity costs by delaying beneficial AI applications
- It might create a technological overhang, potentially leading to more rapid and dangerous development once lifted
Analysis
Global Moratorium is the most difficult to implement but safest of the three major strategies. Under conditions of short timelines or high alignment difficulty, a global moratorium emerges as the optimal approach for reasons of simple safety. The risk of catastrophic AI misuse or AI-driven conflict is generally agreed to be not low if AI emerges suddenly in a world that has not had more than a few years to adapt, simply because of the misuse risk associated with such a powerful technology. This holds true even if alignment is straightforward, as we expect TAI to invent at least some offense-dominant technologies. Therefore, the overall risk posed by TAI can never be very low on short timelines.
It is therefore in everyone's interest to slow TAI development, in order to mitigate these risks. If enforceable, GM is what most actors would prefer. Conditional on at least a few percent existential risk from AI, nearly all governments with an interest in the welfare of their citizens have a rational motivation to sign onto a binding treaty which provides for a halt to the development of dangerous AI capabilities. The challenge lies in translating this abstract rational-actor observation into an actual TAI moratorium.
The desirability of a Global Moratorium depends critically on alignment difficulty and AI development timelines. GM becomes increasingly favoured as alignment difficulty increases, particularly if the timeline is not very long. In hard alignment scenarios, GM is generally favored on any somewhat near (under ten year) timeline if alignment is nearly infeasible (8+). This is because progress then becomes akin to a "suicide race," where it doesn’t matter who develops TAI or why, because any TAI will develop misaligned power-seeking goals and attempt to cause catastrophic harm. In these scenarios, the primary technical challenge is to convincingly demonstrate this fact, and the primary governance task is to prevent the development of TAI altogether.
With extremely short timelines, GM becomes more relevant even for easier alignment scenarios, as the GM mitigates misuse and structural risks, and addresses the risk of unaligned AI deployment despite technically feasible alignment issues that might be solvable with more time and slower progress.
However, with long timelines, other strategies like CD might still be favoured even if alignment is very difficult and requires fundamentally new approaches. In these cases, longer timelines allow for continued alignment research, with the possibility that new, safer AI paradigms may emerge or international cooperation may strengthen, potentially making immediate preparations for a moratorium counterproductive and ‘too soon’ if the critical window during which political capital is to be spent is still far off.
GM also becomes increasingly attractive in scenarios where the offence-defence balance is heavily skewed towards offence, particularly if this imbalance is expected to persist or worsen as AI capabilities advance, as then the prospect of relying on TAI for defense as described in the CD or SA sections diminishes. GM is most crucial when offensive technologies are developing faster than defensive ones, or when the potential for misuse of advanced AI systems (such as for large-scale manipulation, autonomous weapons, or rapid development of other dangerous technologies) far outweighs our ability to defend against these threats, even with the advantages provided by a well resourced single SA project. It is also favored in cases where high-level military or security decision-making is not considered sufficiently trustworthy for any country to embark on a SA project.
The takeoff speed considerations for GM are somewhat paradoxical. On one hand, GM is often seen as a response to the threat of very fast takeoff scenarios, where the risks of rapid, uncontrolled AI development are deemed too high. In these cases, GM serves as a mechanism to buy time for developing better safeguards or alignment techniques. On the other hand, for GM to be successfully implemented and maintained, there needs to be enough time for international consensus to form and for enforcement mechanisms to be put in place. Therefore, GM is most viable either as a proactive measure in slower takeoff scenarios where the offensive threat is clear but not yet imminent, or as a reactive measure in fast takeoff scenarios where the dangers become quickly apparent to all major actors, prompting rapid, coordinated action.
From a game-theoretic perspective, GM helps prevent arms race dynamics and represents the best outcome in a simplified assurance game scenario, assuming there are correspondingly strong race incentives. However, implementing GM is exceedingly difficult, and attempts to enforce it could undermine other strategies.
If progress is slowed but not entirely stopped, and the most advanced and cautious actors are differentially slowed the most, this undermines the defensive acceleration crucial to CD, so a failed GM may be much worse than not attempting it at all. Similarly, if the leading project, which is safer and based in the West, is slowed, this can undermine the strategic lead required for SA to work.
Effective verification systems are essential for GM's effectiveness. If such systems can be established, the strategic logic for nations to sign onto GM becomes more compelling. However, challenges exist in creating verification systems that do not confer strategic advantages to certain countries. AI technologies themselves could potentially be used to create effective monitoring systems (this is central to CD), but GM is likely to slow down the development of those very technologies. The challenge lies in developing improved AI-based verification tools that are not themselves TAI.
Similarly, GM requires an assurance of dangerous AI capabilities to have a chance of success. While the precautionary principle might motivate some to resist continued AI progress, to obtain broad buy-in will probably require better dangerous AI capability evaluations than we currently have. However, if such evaluations can be developed and broadly adopted, this could help overcome major political hurdles preventing the adoption of GM.
While there are historical precedents of successful moratoriums in other fields—such as bioweapons and human cloning—that suggest international agreements are possible, differences between AI and other regulated technologies may affect GM's viability. For example, decreasing training costs due to ongoing hardware advancements could make AI development more accessible, complicating enforcement. Lessons from nuclear non-proliferation and climate change efforts could also provide valuable insights, although these domains have their own unique challenges and successes.
Feasibility concerns regarding GM, given current geopolitical realities, are significant. Securing cooperation from all major AI-developing nations presents a considerable challenge. Public opinion and "wake-up calls" might influence GM's feasibility; for instance, it seems plausible that many countries would voluntarily slow down AI development internally if there is an explosion of powerful AI capabilities. Clear evidence of AI risks could increase GM's viability. One approach is to pre-arrange GM to activate after certain conditions are met, which might make implementation easier.
Potential "capability triggers" could be established to initiate GM, such as signs that AI systems are capable of fully replacing humans in scientific research roles or that they are capable of highly destructive actions under AI capabilities evaluations which genuinely represent danger. Warning shots—such as the first instance where the deliberate actions of an unaligned AI cause a human death—could also serve as triggers to enable the adoption of GM.
There are significant objections to a global moratorium. Many would argue that an effective moratorium covering the United States is impossible, even with clear evidence, warning shots, and widespread consensus on the extreme risks of AI. Cooperating with other countries on a global moratorium is seen as even less likely. Any attempt to enforce such a moratorium in one country could just result in a less safety-conscious nation gaining the lead. Opponents also contend that GM could lead to significant opportunity costs by delaying potentially beneficial AI applications.
However, while challenging, a moratorium is not impossible to implement. This is especially true if compelling dangerous capability evaluations can be developed, along with robust mutual monitoring and enforcement mechanisms. With sufficient evidence of AI risks, even traditionally competitive nations might recognize the shared existential threat and choose to cooperate, just as e.g. the US and Soviet Union were able to cooperate on arms control treaties despite being adversaries. This could become easier as unaligned AI systems become more prominent. To address the technological overhang concern, a well-designed moratorium could include provisions for gradual, controlled lifting to prevent a dangerous race once restrictions are eased. The moratorium period could also be used to develop robust safety measures and governance frameworks to manage the eventual development of advanced AI.
GM advocates also emphasize that the strategy's apparent difficulty may be overstated when compared to the implementation challenges of CD and SA. While GM requires unprecedented international cooperation, both CD and SA face equally daunting challenges: CD must solve the problem of maintaining safety standards across multiple competing actors during rapid technological advancement, while SA must prevent both international conflict and authoritarian capture while developing aligned TAI under intense time pressure. In contrast, GM's core mechanism - controlling compute and hardware infrastructure - builds on existing export control frameworks and requires fewer novel governance innovations than its alternatives. This relative simplicity, combined with the clear alignment of incentives among rational actors facing existential risk, suggests that GM might actually be more tractable than commonly assumed.
Overall, upon closer examination, we can see that there are several plausible pathways to establishing a global moratorium that warrant serious consideration. The strategy's foundation would rest on three pillars: concrete demonstrations of dangerous AI capabilities that make the risks undeniable, clear warning shots that serve as wake-up calls to the international community, and robust mutual verification mechanisms that make the moratorium enforceable.
While past attempts at technological moratoriums have had mixed success, the precedent of arms control treaties - particularly between adversarial powers during the Cold War - demonstrates that international cooperation is possible when existential risks are clearly understood. GM's greatest strength lies in its ability to buy crucial time for solving fundamental safety challenges, while its biggest hurdle is achieving the necessary international consensus. Given the potential consequences of uncontrolled AI development, particularly in scenarios with very hard alignment or extremely short timelines, GM represents a vital and potentially necessary option that must be maintained as part of our strategic toolkit.
Conclusion
The analysis of AI governance strategies reveals that no single approach—Cooperative Development (CD), Strategic Advantage (SA), or Global Moratorium (GM)—emerges as universally optimal across all scenarios. As we have shown, all three strategies are potentially viable and must be seriously considered. The most preferred strategy depends critically on the interplay between alignment difficulty, development timelines, and other key factors such as the offense-defense balance and the potential for international cooperation.
CD appears to be the most viable with longer timelines and easier alignment challenges, offering the greatest flexibility and lowest intrinsic risks. SA becomes more attractive under shorter timelines or moderate alignment difficulty, particularly when international cooperation seems unlikely, though it introduces significant risks of centralization and even global conflict. GM, while the most challenging to implement, emerges as potentially necessary under scenarios of very hard alignment or extremely short timelines, serving as a crucial emergency brake against catastrophic risks.
The strategic landscape is further complicated by the potential irreversibility of certain choices—particularly SA and GM—and the dynamic nature of global technological development. The ability to transition between strategies becomes a crucial consideration, with CD providing the greatest strategic flexibility while SA and GM potentially lock in certain trajectories. This suggests that in cases of uncertainty, defaulting to more flexible approaches like CD may be prudent, provided the circumstances allow for it.
Looking forward, the AI governance community faces the challenge of not only selecting appropriate strategies but also maintaining the ability to pivot as new information about alignment difficulty, the international situation, AI offense and defense, and TAI development timelines emerges. This may require developing hybrid approaches or establishing clear triggers for strategic shifts, all while building international consensus and institutional capacity for whichever strategy proves necessary. Success in AI governance will likely require both the wisdom to choose the right strategy and the flexibility to adapt as circumstances evolve.
10 comments
Comments sorted by top scores.
comment by MichaelDickens · 2024-12-05T01:24:53.709Z · LW(p) · GW(p)
Cooperative Development (CD) is favored when alignment is easy and timelines are longer. [...]
Strategic Advantage (SA) is more favored when alignment is easy but timelines are short (under 5 years)
I somewhat disagree with this. CD is favored when alignment is easy with extremely high probability. A moratorium is better given even a modest probability that alignment is hard, because the downside to misalignment is so much larger than the downside to a moratorium.[1] The same goes for SA—it's only favored when you are extremely confident about alignment + timelines.
[1] Unless you believe a moratorium has a reasonable probability of permanently preventing friendly AI from being developed.
Replies from: MichaelDickens, nathan-helm-burger, SDM↑ comment by MichaelDickens · 2024-12-05T01:31:11.013Z · LW(p) · GW(p)
Also, I don't feel that this article adequately addressed the downside of SA that it accelerates an arms race. SA is only favored when alignment is easy with high probability and you're confident that you will win the arms race, and you're confident that it's better for you to win than for the other guy[1], and you're talking about a specific kind of alignment where an "aligned" AI doesn't necessarily behave ethically, it just does what its creator intends.
[1] How likely is a US-controlled (or, more accurately, Sam Altman/Dario Amodei/Mark Zuckerberg-controlled) AGI to usher in a global utopia? How likely is a China-controlled AGI to do the same? I think people are too quick to take it for granted that the former probability is larger than the latter.
Replies from: SDM↑ comment by Sammy Martin (SDM) · 2024-12-11T11:32:31.930Z · LW(p) · GW(p)
We do discuss this in the article and tried to convey that it is a very significant downside of SA. All 3 plans have enormous downsides though, so a plan posing massive risks is not disqualifying. The key is understanding when these risks might be worth taking given the alternatives.
- CD might be too weak if TAI is offense-dominant, regardless of regulations or cooperative partnerships, and result in misuse or misalignment catastrophe
- If GM fails it might blow any chance of producing protective TAI and hand over the lead to the most reckless actors.
- SA might directly provoke a world war or produce unaligned AGI ahead of schedule.
SA is favored when alignment is easy or moderately difficult (e.g. at the level where interpretability probes, scalable oversight etc. help [LW · GW]) with high probability, and you expect to win the arms race. But it doesn't require you to be the 'best'. The key isn't whether US control is better than Chinese control, but whether centralized development under any actor is preferable to widespread proliferation of TAI capabilities to potentially malicious actors
Regarding whether the US (remember on SA there's assumed to be extensive government oversight) is better than the CCP: I think the answer is yes and I talk a bit more about why here [LW(p) · GW(p)]. I don't consider US AI control being better than Chinese AI control to be the most important argument in favor of SA, however. That fact alone doesn't remotely justify SA: you also need easy/moderate alignment and you need good evidence than an arms race is likely unavoidable regardless of what we recommend.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-06T05:17:12.635Z · LW(p) · GW(p)
I think moratorium is basically intractable short of a totalitarian world government cracking down on all personal computers.
Unless you mean just a moratorium on large training runs, in which case I think it buys a minor delay at best, and comes with counterproductive pressures on researchers to focus heavily on diverse small-scale algorithmic efficiency experiments.
Replies from: MichaelDickens↑ comment by MichaelDickens · 2024-12-06T19:27:46.263Z · LW(p) · GW(p)
I don't think controlling compute would be qualitatively harder than controlling, say, pseudoephedrine.
(I think it would be harder, but not qualitatively harder—the same sorts of strategies would work.)
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-07T00:00:45.560Z · LW(p) · GW(p)
I agree that some amount of control is possible.
But if we are in a scenario in the future where the offense-defense balance of bioweapons remains similar to how it is today, then a single dose of pseudoephedrine going unregulated by the government and getting turned into methamphetamine could result in the majority of humanity being wiped out.
Pseudoephedrine is regulated, yes, but not so strongly that literally none slips past the enforcement. With the stakes so high, a mostly effective enforcement scheme doesn't cut it.
Replies from: MichaelDickens↑ comment by MichaelDickens · 2024-12-07T01:55:48.873Z · LW(p) · GW(p)
That's only true if a single GPU (or small number of GPUs) is sufficient to build a superintelligence, right? I expect it to take many years to go from "it's possible to build superintelligence with a huge multi-billion-dollar project" and "it's possible to build superintelligence on a few consumer GPUs". (Unless of course someone does build a superintelligence which then figures out how to make GPUs many orders of magnitude cheaper, but at that point it's moot.)
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-07T15:49:15.699Z · LW(p) · GW(p)
Sadly, no. It doesn't take superintelligence to be deadly. Even current open-weight LLMs, like Llama 3 70B, know quite a lot about genetic engineering. The combination of a clever and malicious human, and an LLM able to offer help and advice is sufficient.
Furthermore, there is the consideration of "seed AI" which is competent enough to improve and not plateau. If you have a competent human helping it and getting it unstuck, then the bar is even lower. My prediction is that the bar for "seed AI" is lower than the bar for AGI.
↑ comment by Sammy Martin (SDM) · 2024-12-11T11:20:24.695Z · LW(p) · GW(p)
Let me clarify an important point: The strategy preferences outlined in the paper are conditional statements - they describe what strategy is optimal given certainty about timeline and alignment difficulty scenarios. When we account for uncertainty and the asymmetric downside risks - where misalignment could be catastrophic - the calculation changes significantly. However, it's not true that GM's only downside is that it might delay the benefits of TAI.
Misalignment (or catastrophic misuse) has a much larger downside than a successful moratorium. That is true, but trying to do a moratorium, losing your lead, and then someone else developing catastrophically misaligned AI when you could have developed a defense against it if you'd adopted CD or SA has just as large a downside.
And GM has a lower chance of being adopted than CD or SA, so the downside to pushing for a moratorium is not necessarily lower.
Since a half-successful moratorium is the worst of all worlds (assuming that alignment is feasible) because you lose out on your chances of developing defenses against unaligned or misused AGI, it's not always true that the moratorium plan has fewer downsides than the others.
However, I agree with your core point - if we were to model this with full probability distributions over timeline and alignment difficulty, GM would likely be favored more heavily than our conditional analysis suggests, especially if we place significant probability on short timelines or hard alignment
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-05T16:56:18.618Z · LW(p) · GW(p)
Ugh. I like your analysis a lot, but feel like it's worthless because your Overton window is too narrow.
I write about this in more depth elsewhere, but I'll give a brief overview here.
-
Misuse risk is already very high. Even open-weights models, when fine-tuned on bioweapons-relevant papers, can produce thorough and accurate plans for insanely deadly bioweapons. With surprisingly few resources, a bad actor could wipe out the majority of humanity within a few months of release.
-
Global Moratorium on AGI research is nearly impossible. It would require government monitoring and control of personal computers worldwide. Stopping big training runs doesn't help, maybe buys you one or two years of delay at best. Once more efficient algorithms are discovered, personal computers will be able to create dangerous AI. Scaling is the fastest route to more powerful AI, not the only route. Further discussion [LW(p) · GW(p)]
-
AGI could be here as soon as 2025, which isn't even on your plot.
-
Once we get close enough to AGI for recursive self-improvement (an easier threshold to hit) then rapid algorithmic improvements make it cheap, quick and easy to create AGI. Furthermore, advancement towards ASI will likely be rapid and easy because the AGI will be able to do the work. https://manifold.markets/MaxHarms/will-ai-be-recursively-self-improvi
-
AI may soon be given traits that make it self-aware/self-modeling, internal-goal-driven, etc. In other words, conscious. And someone will probably set it to the task of self-improving. Nobody has to let it out of the box if its creator never puts it in a box to begin with. Nobody needs to steal the code and weights if they are published publicly. Any coherent plan must address what will be done about such models, able to run on personal computers, with open code and open weights, with tremendous capability for harm if programmed/convinced to harm humanity.
https://www.lesswrong.com/posts/NRZfxAJztvx2ES5LG/a-path-to-human-autonomy [LW · GW]