Ten Levels of AI Alignment Difficulty
post by Sammy Martin (SDM) · 2023-07-03T20:20:21.403Z · LW · GW · 24 commentsContents
The Scale Table Behavioural Safety is Insufficient Sharp Left Turn Defining ‘Alignment Difficulty’ What ‘well enough’ means Scaling techniques indefinitely Techniques which produce positively transformative AI Alignment vs. Capabilities Summary None 25 comments
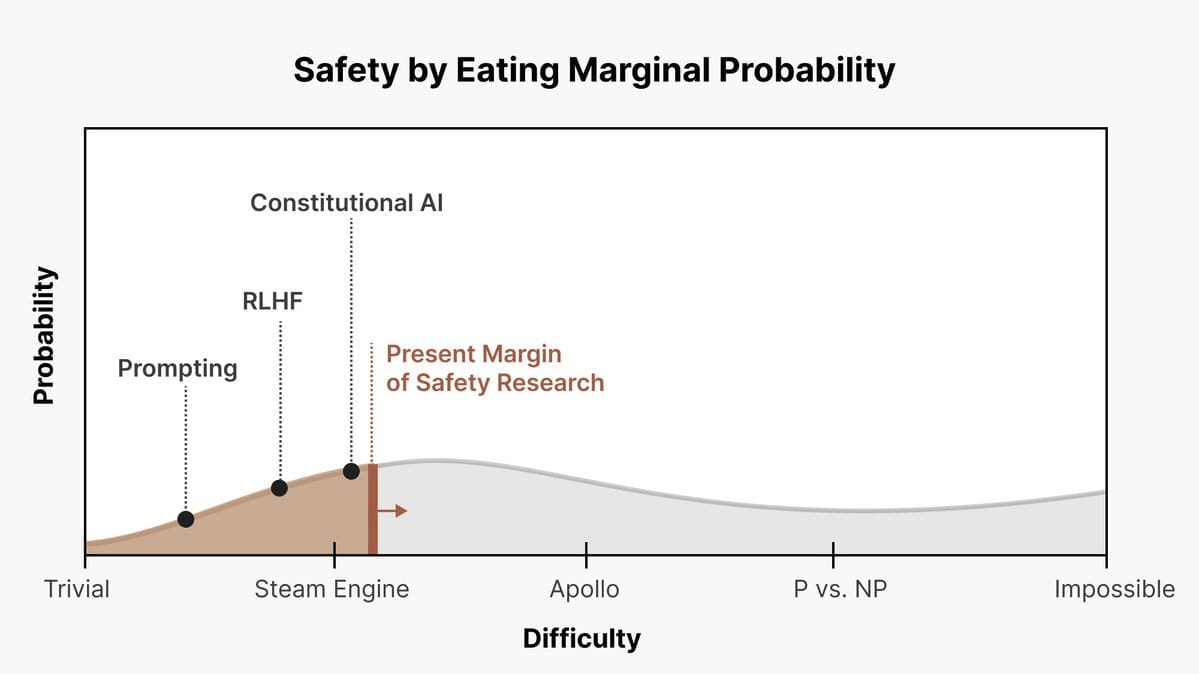
Chris Olah recently released a tweet thread describing how the Anthropic team thinks about AI alignment difficulty. On this view, there is a spectrum of possible scenarios ranging from ‘alignment is very easy’ to ‘alignment is impossible’, and we can frame AI alignment research as a process of increasing the probability of beneficial outcomes by progressively addressing these scenarios. I think this framing is really useful, and here I have expanded on it by providing a more detailed scale of AI alignment difficulty and explaining some considerations that arise from it.
The discourse around AI safety is dominated by detailed conceptions of potential AI systems and their failure modes, along with ways to ensure their safety. This article by the DeepMind safety team [LW · GW] provides an overview of some of these failure modes. I believe that we can understand these various threat models through the lens of "alignment difficulty" - with varying sources of AI misalignment sorted from easy to address to very hard to address, and attempt to match up technical AI safety interventions with specific alignment failure mode scenarios. Making this uncertainty clearer makes some debates between alignment researchers easier to understand.
An easier scenario could involve AI models generalising and learning goals in ways that fit with common sense. For example, it could be the case that LLMs of any level of complexity are best understood as generative frameworks over potential writers, with Reinforcement Learning from Human Feedback (RLHF) or Constitutional AI (CAI) selecting only among potential writers. This is sometimes called ‘alignment by default’ [LW · GW].
A hard scenario could look like that outlined in ‘Deep Deceptiveness’ [AF · GW], where systems rapidly and unpredictably generalise in ways that quickly obsolete previous alignment techniques [LW · GW], and they also learn deceptive reward-hacking strategies that look superficially identical to good behaviour according to external evaluations, red-teaming, adversarial testing or interpretability examinations.
When addressing the spectrum of alignment difficulty, we should examine each segment separately.
If we assume that transformative AI will be produced, then the misuse risk associated with aligned transformative AI does not depend on how difficult alignment is. Therefore, misuse risk is a relatively bigger problem the easier AI alignment is.
Easy scenarios should therefore mean more resources should be allocated to issues like structural risk, economic implications, misuse, and geopolitical problems. On the ‘harder’ end of easy, where RLHF-trained systems typically end up honestly and accurately pursuing oversimplified proxies for what we want, like ‘improve reported life satisfaction’, or ‘raise the stock price of company X’, we also have to worry about scenarios like Production Web or What Failure looks like 1 [LW · GW] which require a mix of technical and governance interventions to address.
Intermediate scenarios are cases where behavioural safety isn’t good enough and the easiest ways to produce Transformative AI result in dangerous deceptive misalignment. This is when systems work against our interests but pretend to be useful and safe. This scenario requires us to push harder on alignment work and explore promising strategies like scalable oversight, AI assistance on alignment research and interpretability-based oversight processes. We should also focus on governance interventions to ensure the leading projects have the time they need to actually implement these solutions and then use them (in conjunction with governments and civil society) to change [EA(p) · GW(p)]the overall strategic landscape [EA(p) · GW(p)] and eliminate the risk of misaligned AI.
In contrast, if alignment is as hard as pessimistic scenarios suggest, intense research effort in the coming years to decades may not be enough to make us confident that Transformative AI can be developed safely. Alignment being very hard would call for robust testing and interpretability techniques to be applied to frontier systems. This would reduce uncertainty, demonstrate the truth of the pessimistic scenario, and build the motivation to stop progress towards Transformative AI altogether.
If we knew confidently whether we were in an optimistic or pessimistic scenario, our available options would be far simpler. Strategies that are strongly beneficial and even necessary to ensure successful alignment in an easy scenario are dangerous and harmful and in the extreme will cause an existential catastrophe in a hard scenario. This makes figuring out what to do much more difficult.
The Scale
Here I will present a scale of increasing AI alignment difficulty, with ten levels corresponding to what techniques are sufficient to ensure sufficiently powerful (i.e. Transformative) AI systems are aligned. I will later get a bit more precise about what this scale is measuring.
At each level, I will describe what techniques are sufficient for the alignment of TAI, and then describe roughly what that scenario entails about how TAI behaves, and then list the main failure modes at that level.
Some comments:
- This scale is ordinal, and the difficulty of the last few steps might increase disproportionately compared to the difficulty of the first few. My rough perception is that there’s a big jump between 5 and 6, and another between 7 and 8.
- The ordering is my own attempt at placing these in terms of what techniques I expect supersede previous techniques (i.e. solve all of the problems those techniques solve and more), but I’m open to correction here. I don’t know how technically difficult each will turn out to be, and it’s possible that e.g., interpretability research will turn out to be much easier than getting scalable oversight to work, even though I think interpretability-based oversight is more powerful than oversight that doesn’t use interpretability.[1]
- I have done my best to figure out what failure modes each technique can and can’t address, but there doesn’t seem to be much consistency in views about this (which techniques can and can’t address which specific failure modes is another thing we’re uncertain about).
- Later AI alignment techniques include and build upon the previous steps, e.g. scalable oversight will probably use component AIs that have also been fine tuned with RLHF. This cumulative nature of progress means that advancing one level often requires addressing the challenges identified at preceding levels.
- The current state of the art in terms of what techniques are in fact applied to cutting-edge models is between a 2 and a 3, with substantial research effort also applied to 4-6.
- Although this scale is about the alignment of transformative AI, not current AI, it seems plausible that it is harder to align more sophisticated than less sophisticated AIs. For example, current LLMs like GPT-4 are plausibly between a 2 and a 3 in terms of what’s required for alignment, and fortunately that’s also where the current state of the art on alignment is. However, GPT-4.5 might ‘move up’ and require 5 for successful alignment.
- Therefore you could view the overall alignment problem as a process of trying to make sure the current state of the art on alignment always stays ahead of the frontier of what is required.
- In the table, the green stands for the ‘easy’ cases that Chris Olah talked about, where unusually reckless actors, misuse and failing on technically easy problems because of institutional mistakes are the main concerns. Orange and Red correspond to ‘intermediate’ cases where increasingly hard technical problems must be solved and black corresponds to cases where alignment is probably impossible in practice, if not in principle.
- This scale can be compared and is similar to the idea that there is some 'adversarial pressure' from more and more sophisticated AI systems as described here [LW(p) · GW(p)].
Table
| Difficulty Level | Alignment technique X is sufficient | Description | Key Sources of risk |
| 1 | (Strong) Alignment by Default | As we scale up AI models without instructing or training them for specific risky behaviour or imposing problematic and clearly bad goals (like 'unconditionally make money'), they do not pose significant risks. [LW · GW] Even superhuman systems basically do the commonsense version of what external rewards (if RL) or language instructions (if LLM) imply. | Misuse and/or recklessness with training objectives. RL of powerful models towards badly specified or antisocial objectives is still possible, including accidentally through poor oversight, recklessness or structural factors [EA · GW]. |
| 2 | Reinforcement Learning from Human Feedback | We need to ensure that the AI behaves well even in edge cases by guiding it more carefully using human feedback in a wide range of situations, not just crude instructions or hand-specified reward functions. When done diligently, RLHF fine tuning works. One reason to think alignment will be this easy is if systems are naturally inductively biased towards honesty and representing the goals humans give them. In that case, they will tend to learn simple honest and obedient strategies even if these are not the optimal policy to maximise reward. | Even if human feedback is sufficient to ensure models roughly do what their overseer intends, systems widely deployed in the economy may still for structural reasons end up being trained to pursue crude and antisocial proxies that don’t capture what we really want. Misspecified rewards [LW · GW] / ‘outer misalignment’ / structural failures where systems don’t learn adversarial policies [2]but do learn to pursue overly crude and clearly underspecified versions of what we want [LW · GW], e.g. the production web or WFLL1. |
| 3 | Constitutional AI | Human feedback is an insufficiently clear and rich signal with which to fine tune AIs. It must be augmented with AI-provided simulations of human feedback to cover edge cases. This is ‘reinforcement learning from AI feedback’. | |
Behavioural Safety is Insufficient Past this point, we assume following Ajeya Cotra [LW · GW] that a strategically aware system which performs well enough to receive perfect human-provided external feedback has probably learned a deceptive human simulating model instead of the intended goal. The later techniques have the potential to address this failure mode [LW · GW]. (It is possible that this system would still under-perform on sufficiently superhuman behavioral evaluations) | |||
| 4 | Scalable Oversight | We need methods to ensure that human-like oversight of AIs continues even for problems unaided humans can’t supervise. Therefore, we need methods which, unlike Constitutional AI, get AIs to apply humanlike supervision more effectively than humans can. Some strategies along these lines are discussed here [LW · GW]. There are many sub-approaches here, outlined for example in the ELK report. | Human feedback is an insufficiently clear signal to align superhuman systems and so must be augmented [LW · GW]. AND Deceptive Human-Simulators arise by default [LW · GW] in situationally aware [LW · GW] AIs, but this tendency can be eliminated with superhuman behavioural feedback[3]. |
| 5 | Scalable Oversight with AI Research Assistance | At this stage, we are entrusting the AIs aligned using techniques like those in 1-4 to perform research on better methods of oversight and to augment human understanding. We are then using those research outputs to improve our oversight processes or improve the overseer AI’s understanding of the behaviour of the AI in training. There are many potential approaches here, including techniques like IDA and debate, which are discussed here. | |
| 6 | Oversight employing Advanced Interpretability Techniques | Conceptual or Mechanistic Interpretability tools are used as part of the (AI augmented) oversight process. Processes internal to the AIs that seem to correlate with deceptiveness can be detected and penalised by the AI or Human+AI overseers developed in 4 and 5. The ELK report discusses some particular approaches to this, such as penalising correlates of deceptive thinking (like excessive computation time spent on simple questions). | Human feedback is an insufficiently clear signal to align superhuman systems and so must be augmented [LW · GW]. AND Deceptive Human-Simulators arise by default [LW · GW] in situationally aware [LW · GW] AIs, even given perfect behavioural feedback. |
| 7 | Experiments with Potentially Catastrophic Systems to Understand Misalignment | At this level, even when we use the techniques in 2-6, AI systems routinely defeat oversight and continue unwanted behaviour. They do this by altering their internal processes to avoid detection by interpretability tools, and by ‘playing the training game’ to seem behaviourally safe. Crucially, though, it is still possible to contain these systems. Therefore we can conduct (potentially dangerous) experiments with these AI systems to understand how they might generalise [LW · GW] post-deployment. Here we would employ the interpretability and oversight tools in 4,5 and 6 and attempt to elicit misgeneralization and reward hacking behaviour from AIs. But we wouldn’t try to remove those behaviours using oversight-based training. Instead, using techniques like red-teaming we try to understand [LW · GW]the basis on which they occur, learning practical tricks and new theoretical insights about how and why misalignment arises, allowing us to develop new mitigations. | |
Sharp Left Turn Past this point, we assume, following Nate Soares [AF · GW], that when systems become capable enough there is a sharp left turn [LW · GW]. This is where AIs suddenly become much more strategically aware and able to consider a very wide range of plans, such that they quickly become able to avoid any attempts to align their behaviour.[4] | |||
| 8 | Theoretical Research for Understanding Misalignment | All of the problematic behaviours either emerge too quickly to respond, or emerge only when systems are deployed, so experiments like those in 7 are useless or cannot be performed safely. For this capability level and following Soares’ view, we need to have an understanding in advance of how AI models generalise their learning. Hopefully, these foundational insights will inspire new techniques for alignment. | There is a ‘sharp left turn’ where a system suddenly gains new concepts and much greater intelligence and generality [LW · GW], obsoleting previous alignment techniques. Systems post-SLT are superintelligent and cannot be experimented on safely or contained. |
| 9 | Coming up with a Fundamentally New Paradigm (abandoning deep learning) | According to this view, deep learning systems cannot be aligned even if you change fundamental things about them. | |
| 10 | Impossible | Alignment of a superintelligent system is impossible in principle. | Alignment is theoretically impossible, incoherent or similar. |
Defining ‘Alignment Difficulty’
Chris Olah’s original thread was quite informal, but I thought it would be useful to flesh this model out in more detail. His original 'how difficult is alignment' scale described various technical or mathematical projects, including building a working steam engine or solving P vs. NP, which represent an informal scale measuring, roughly, ‘how hard the alignment problem is overall’. But we can be more precise about what this scale measures. And we can place existing approaches to alignment along this alignment difficulty scale.
So, to be more precise about what the scale measures, I define alignment difficulty as the degree of complexity and effort required to successfully guide an AI system's behaviour, objectives, and decisions to conform with human values and expectations, well enough to effectively mitigate the risks posed by unaligned, potentially dangerous AI systems.
What ‘well enough’ means
Scaling techniques indefinitely
One perspective on 'well enough' is that a technique should scale indefinitely, implying that it will continue to be effective regardless of the system's intelligence. For example, if RLHF always works on arbitrarily powerful systems, then RLHF is sufficient. This supersedes other criteria: if a technique always works, it will also work for a system powerful enough to help mitigate any risk.
Techniques which produce positively transformative AI
An alternative perspective is that a technique works ‘well enough' if it can robustly align AI systems that are powerful enough to be deployed safely (maybe in a research lab, maybe in the world as a whole), and that these AI systems are transformative in ways that reduce the overall risk from unaligned AI. [LW(p) · GW(p)] Call such systems ‘positively transformative AI’.
Positively transformative AI systems could reduce the overall risk from AI by: preventing the construction of a more dangerous AI; changing something about how global governance works; instituting surveillance or oversight mechanisms widely; rapidly and safely performing alignment research or other kinds of technical research; greatly improving cyberdefense; persuasively exposing misaligned behaviour in other AIs and demonstrating alignment solutions, and through many other actions that incrementally reduce risk [EA(p) · GW(p)].
One common way of imagining this process is that an aligned AI could perform a ‘pivotal act’ that solves AI existential safety in one swift stroke. However, it is important to consider this much wider range of ways in which one or several transformative AI systems could reduce the total risk from unaligned transformative AI.
As well as disagreeing about how hard it is to align an AI of a certain capability, people disagree on how capable an aligned AI must be to be positively transformative in some way. For example, Jan Leike et al. think that there is no known indefinitely scalable solution to the alignment problem, but that we won’t need an indefinitely scalable alignment technique, just one that is good enough to align a system that can automate alignment research.
Therefore, the scale should be seen as covering increasingly sophisticated techniques which work to align more and more powerful and/or adversarial systems.
Alignment vs. Capabilities
There’s a common debate in the alignment community about what counts as ‘real alignment research’ vs just advancing capabilities, see e.g. here [LW · GW] for one example of the debate around RLHF, but similar debates exist around more sophisticated methods like interpretability-based oversight [LW · GW].
This scale helps us understand where this debate comes from.
Any technique on this scale which is insufficient to solve TAI alignment will (if it succeeds) make a system appear to be ‘aligned’ in the short term. Many techniques, such as RLHF, also make a system more practically useful and therefore more commercially viable and more capable. Spending time on these alignment techniques also trades off with other kinds of alignment work.
Given our uncertainty about what techniques are and aren’t sufficient, the boundary between what counts as ‘just capabilities research’ vs ‘alignment research’ isn’t exact. In other words, before the (unknown) point at which a given technique becomes sufficient, advancing less effective alignment techniques is at best diverting resources away from useful efforts, but more likely just advancing AI capabilities and helping to hide problems. In other words, advancing alignment techniques which are insufficient for solving the problem at best takes resources away from more useful work and at worst advances capabilities whilst concealing misaligned behaviour.
However, crucially, since we don’t know where on the scale the difficulty lies, we don’t know whether working on a given technique is counterproductive or not. Additionally, as we go further along the scale it becomes harder and harder to make progress. RLHF is already widely used and applied to cutting-edge systems today, with constitutional AI not far away (2-3), whereas the hopes for coming up with a new AI paradigm that’s fundamentally safer than deep learning (9) seem pretty thin.
Therefore, we get the phenomenon of, "everyone more optimistic about alignment than me is just working on capabilities."
I think that acknowledging our uncertainty about alignment difficulty takes some of the force out of arguments that e.g., constitutional AI research is net-negative. This kind of research is beneficial in some worlds, even though it creates negative externalities and could make AIs more dangerous in worlds where alignment is harder.
Chris Olah’s original point was that given this uncertainty we should aim to push the frontier further than it is already, so the optimal strategy is to promote any method which is past the ‘present margin of safety research’, i.e. would counterfactually not get worked on and works to reduce the risk in some scenarios.
Summary
In summary, I have:
- Expanded upon Chris Olah’s framing of alignment difficulty as a spectrum over which we have some uncertainty about which techniques will and won’t be sufficient to ensure alignment.
- Attempted to line up specific failure scenarios with the alignment techniques meant to mitigate them (e.g. RLHF on the right objective solves the problem that simple reward functions can’t capture what we want, oversight solves the problem that human oversight won’t be good enough to govern superhuman systems, interpretability solves the problem that even perfectly behaviourally safe systems could be deceptive).
- Explained what the scale of alignment difficulty is measuring in more detail, i.e. the degree of complexity and effort required to successfully guide a TAI system's behaviour, objectives, and decisions to conform with human values and expectations, well enough to effectively mitigate the risks posed by unaligned TAI systems.
- Outlined some of the difficulties arising from the fact that we don’t know what techniques are sufficient, and insufficient techniques plausibly just accelerate AI capabilities and so actually increase rather than reduce risk.
I’d be interested to know what people think of my attempted ordering of alignment techniques by increasing sophistication and matching them up with the failure modes they’re meant to address. I’d also like to know your thoughts on whether Chris Olah’s original framing, that anything which advances this ‘present margin of safety research’ is net positive, is the correct response to this uncertainty.[5]
- ^
Oversight which employs interpretability tools would catch failure modes that oversight without interpretability tools wouldn't, i.e. failure modes where, before deployment, a system seems safe according to superhuman behavioural oversight, but is actually being deceptive and power seeking.
- ^
Systems that aren't being deceptive in a strategically aware way might be misaligned in subtler ways that are still very difficult to deal with [LW · GW]for strategic or governance reasons (e.g. strong competitive economic pressures to build systems that pursue legible goals), so you might object to calling this an 'easy' problem just because in this scenario RLHF doesn't lead to deceptive strategically aware agents. However, this is a scale of the difficulty of technical AI alignment, not how difficult AI existential safety is overall.
- ^
Ajeya Cotra’s report on AI takeover lists this as a potential solution [LW · GW]: ‘We could provide training to human evaluators to make them less susceptible to manipulative and dishonest tactics, and instruct them to give reward primarily or entirely based on whether the model followed honest procedures rather than whether it got good results. We could try to use models themselves to help explain what kinds of tactics are more and less likely to be manipulative' - as an example of something that might do better than behavioral safety.
Therefore, I do not take her report to be arguing that external behavioural evaluation will fail to eliminate deception. Instead, I interpret her as arguing that any human-level external behavioural evaluation won’t work but that superior oversight processes can work to eliminate deception. However, even superhuman behavioural oversight is still a kind of 'behavioral safety'.
- ^
It is essential to distinguish the sharp left turn from very fast AI progress due to e.g., AIs contributing a continuously but rapidly increasing [LW · GW] fraction of work to AI research efforts. While fast progress could pose substantial governance problems, it wouldn’t mean that oversight-based approaches to alignment fail.
If progress is fast enough but continuous, then we might have a takeoff that looks discontinuous and almost identical to the sharp left turn from the perspective of the wider world outside AI labs. However, within the labs it would be quite different, because running oversight strategies where more and more powerful AIs oversee each other would still be feasible.
- ^
Take any person’s view of how difficult alignment is, accounting for their uncertainty over this question. It could be possible to model the expected benefit of putting resources into a given alignment project, knowing that it could help to solve the problem, but it could also make the problem worse if it merely produces systems which appear safe. Additionally, this modelling has to account for how putting resources into this alignment solution takes away resources from other solutions (the negative externality). Would it be productive to try to model the optimal allocation of resources in this way, and what would the result of this modelling be?
24 comments
Comments sorted by top scores.
comment by johnswentworth · 2023-07-04T05:45:32.248Z · LW(p) · GW(p)
I would order these differently.
Within the first section (prompting/RLHF/Constitutional):
- I'd guess that Constitutional AI would work only in the very easiest worlds
- RLHF would work in slightly less-easy worlds
- Prompting would work in worlds where alignment is easy, but too hard for RLHF or Constitutional AI
The core reasoning here is that human feedback directly selects for deception. Furthermore, deception induced by human feedback does not require strategic awareness - e.g. that thing with the hand which looks like it's grabbing a ball but isn't is a good example [? · GW]. So human-feedback-induced deception is more likely to occur, and to occur earlier in development, than deception from strategic awareness. Among the three options, "Constitutional" AI applies the most optimization pressure toward deceiving humans (IIUC), RLHF the next most, whereas prompting alone provides zero direct selection pressure for deception; it is by far the safest option of the three. (Worlds Where Iterative Design Fails [? · GW] talks more broadly about the views behind this.)
Next up, I'd put "Experiments with Potentially Catastrophic Systems to Understand Misalignment" as 4th-hardest world. If we can safely experiment with potentially-dangerous systems in e.g. a sandbox, and that actually works (i.e. the system doesn't notice when it's in testing and deceptively behave itself, or otherwise generalize in ways the testing doesn't reveal), then we don't really need oversight tools in the first place. Just test the thing and see if it misbehaves.
The oversight stuff would be the next three hardest worlds (5th-7th). As written I think they're correctly ordered, though I'd flag that "AI research assistance" as a standalone seems far safer than using AI for oversight. The last three seem correctly-ordered to me.
I'd also add that all of these seem very laser-focused on intentional deception as the failure mode, which is a reasonable choice for limiting scope, but sure does leave out an awful lot.
Replies from: SDM↑ comment by Sammy Martin (SDM) · 2023-07-06T11:38:06.495Z · LW(p) · GW(p)
deception induced by human feedback does not require strategic awareness - e.g. that thing with the hand which looks like it's grabbing a ball but isn't is a good example [? · GW]. So human-feedback-induced deception is more likely to occur, and to occur earlier in development, than deception from strategic awareness
The phenomenon that a 'better' technique is actually worse than a 'worse' technique if both are insufficient is something I talk about in a later section [LW · GW]of the post and I specifically mention RLHF. I think this holds true in general throughout the scale, e.g. Eliezer and Nate have said that even complex interpretability-based oversight with robustness testing and AI research assistance is also just incentivizing more and better deception, so this isn't unique to RLHF.
But I tend to agree with Richard's view in his discussion with you under that post that while if you condition on deception occurring by default RLHF is worse than just prompting [LW(p) · GW(p)] (i.e. prompting is better in harder worlds), RLHF is better than just prompting in easy worlds. I also wouldn't call non-strategically aware pursuit of inaccurate proxies for what we want 'deception', because in this scenario the system isn't being intentionally deceptive.
In easy worlds, the proxies RLHF learns are good enough in practice and cases like the famous thing with the hand which looks like it's grabbing a ball but isn't [? · GW] just disappear if you're diligent enough with how you provide feedback. In that world, not using RLHF would get systems pursuing cruder and worse proxies for what we want that fail often (e.g. systems just overtly lie to you all the time, say and do random things etc.). I think that's more or less the situation we're in right now with current AIs!
If the proxies that RLHF ends up pursuing are in fact close enough, then RLHF works and will make systems behave more reliably and be harder to e.g. jailbreak or provoke into random antisocial behavior than with just prompting. I did flag in a footnote that the 'you get what you measure' problem that RLHF produces could also be very difficult to deal with for structural or institutional reasons.
Next up, I'd put "Experiments with Potentially Catastrophic Systems to Understand Misalignment" as 4th-hardest world. If we can safely experiment with potentially-dangerous systems in e.g. a sandbox, and that actually works (i.e. the system doesn't notice when it's in testing and deceptively behave itself, or otherwise generalize in ways the testing doesn't reveal), then we don't really need oversight tools in the first place.
I'm assuming you meant fourth-easiest here not fourth hardest. It's important to note that I'm not here talking about testing systems to see if they misbehave in a sandbox and then if they don't assuming you've solved the problem and deploying. Rather, I'm talking about doing science with models that exhibit misaligned power seeking, with the idea being that we learn general rules about e.g. how specific architectures generalize, why certain phenomena arise etc. that are theoretically sound and we expect to hold true even post deployment with much more powerful systems. Incidentally this seems quite similar to what the OpenAI superalignment team is apparently planning.
So it's basically, "can we build a science of alignment through a mix of experimentation and theory". So if e.g. we study in a lab setting a model that's been fooled into thinking it's been deployed, then commits a treacherous turn, enough times we can figure out the underlying cause of the behavior and maybe get new foundational insights? Maybe we can try to deliberately get AIs to exhibit misalignment and learn from that. It's hard to anticipate in advance what scientific discoveries will and won't tell you about systems, and I think we've already seen cases of experiment-driven theoretical insights, like simulator theory, that seem to offer new handles for solving alignment. How much quicker and how much more useful will these be if we get the chance to experiment on very powerful systems?
comment by Jack O'Brien (jack-o-brien) · 2023-07-04T06:22:54.093Z · LW(p) · GW(p)
Hey thanks for writing this up! I thought you communicated the key details excellently - in particular these 3 camps of varying alignment difficulty worlds, and the variation within those camps. Also I think you included just enough caveats and extra details to give readers more to think about, but without washing out the key ideas of the post.
Just wanted to say thanks, this post makes a great reference for me to link to.
comment by Stephen McAleese (stephen-mcaleese) · 2024-12-27T13:23:41.341Z · LW(p) · GW(p)
I think this post is really helpful and has clarified my thinking about the different levels of AI alignment difficulty. It seems like a unique post with no historical equivalent, making it a major contribution to the AI alignment literature.
As you point out in the introduction, many LessWrong posts provide detailed accounts of specific AI risk threat models or worldviews. However, since each post typically explores only one perspective, readers must piece together insights from different posts to understand the full spectrum of views.
The new alignment difficulty scale introduced in this post offers a novel framework for thinking about AI alignment difficulty. I believe it is an improvement compared to the traditional 'P(doom)' approach which requires individuals to spontaneously think of several different possibilities which is mentally taxing. Additionally, reducing one's perspective to a single number may oversimplify the issue and discourage nuanced thinking.
In contrast, the ten-level taxonomy provides concrete descriptions of ten scenarios to the reader, each describing alignment problems of varying difficulties. This comprehensive framework encourages readers to consider a variety of diverse scenarios and problems when thinking about the difficulty of the AI alignment problem. By assigning probabilities to each level, readers can construct a more comprehensive and thoughtful view of alignment difficulty. This framework therefore encourages deeper engagement with the problem.
The new taxonomy may also foster common understanding within the AI alignment community and serve as a valuable tool for facilitating high-level discussions and resolving disagreements. Additionally, it proposes hypotheses about the relative effectiveness of different AI alignment techniques which could be empirically tested in future experiments.
comment by Joseph Bloom (Jbloom) · 2023-07-04T03:38:46.958Z · LW(p) · GW(p)
Thanks for writing this up. I really liked this framing when I first read about it but reading this post has helped me reflect more deeply on it.
I’d also like to know your thoughts on whether Chris Olah’s original framing, that anything which advances this ‘present margin of safety research’ is net positive, is the correct response to this uncertainty.
I wouldn't call it correct or incorrect only useful in some ways and not others. Whether it's net positive may rely on whether it is used by people in cases where it is appropriate/useful.
As an educational resource/communication tool, I think this framing is useful. It's often useful to collapse complex topics into few axes and construct idealised patterns, in this case a difficulty-distribution on which we place techniques by the kinds of scenarios where they provide marginal safety. This could be useful for helping people initially orient to existing ideas in the field or in governance or possibly when making funding decisions.
However, I feel like as a tool to reduce fundamental confusion about AI systems, it's not very useful. The issue is that many of the current ideas we have in AI alignment are based significantly on pre-formal conjecture that is not grounded in observations of real world systems (see the Alignment Problem from a Deep Learning Perspective). Before we observe more advanced future systems, we should be highly uncertain about existing ideas. Moreover, it seems like this scale attempts to describe reality via the set of solutions which produce some outcome in it? This seems like an abstraction that is unlikely to be useful.
In other words, I think it's possible that this framing leads to confusion between the map and the territory, where the map is making predictions about tools that are useful in territory which we have yet to observe.
To illustrate how such an axis may be unhelpful if you were trying to think more clearly, consider the equivalent for medicine. Diseases can be divided up into varying classes on difficulty to cure with corresponding research being useful for curing them. Cuts/Scrapes are self-mending whereas infections require corresponding antibiotics/antivirals, immune disorders and cancers are diverse and therefore span various levels of difficulties amongst their instantiations. It's not clear to me that biologists/doctors would find much use from conjecture on exactly how hard vs likely each disease is to occur, especially in worlds where you lack a fundamental understanding of the related phenomena. Possibly, a closer analogy would be trying to troubleshoot ways evolution can generate highly dangerous species like humans.
I think my attitude here leads into more takes about good and bad ways to discuss which research we should prioritise but I'm not sure how to convey those concisely. Hopefully this is useful.
Replies from: SDM↑ comment by Sammy Martin (SDM) · 2023-07-06T11:04:58.423Z · LW(p) · GW(p)
You're right that I think this is more useful as an unscientific way for (probably less technical governance and strategy people) to orientate towards AI alignment than for actually carving up reality. I wrote the post with that audience and that framing in mind. By the same logic, your chart of how difficult various injuries and diseases are to fix would be very useful e.g. as a poster in a military triage tent even if it isn't useful for biologists or trained doctors.
However, while I didn't explore the idea much I do think that it is possible to cash this scale out as an actual variable related to system behavior, something along the lines of 'how adversarial are systems/how many extra bits of optimization over and above behavioral feedback are needed'. See here [LW(p) · GW(p)]for further discussion on that. Evan Hubinger also talked in a bit more detail about what might be computationally different about ML models in low vs high adversarialness worlds [AF(p) · GW(p)]here.
comment by Mateusz Bagiński (mateusz-baginski) · 2024-04-26T09:59:33.850Z · LW(p) · GW(p)
Behavioural Safety is Insufficient
Past this point, we assume following Ajeya Cotra [LW · GW] that a strategically aware system which performs well enough to receive perfect human-provided external feedback has probably learned a deceptive human simulating model instead of the intended goal. The later techniques have the potential to address this failure mode [LW · GW]. (It is possible that this system would still under-perform on sufficiently superhuman behavioral evaluations)
There are (IMO) plausible threat models in which alignment is very difficult but we don't need to encounter deceptive alignment. Consider the following scenario:
Our alignment techinques (whatever they are) scale pretty well, as far as we can measure, even up to well-beyond-human-level AGI. However, in the year (say) 2100, the tails come apart [LW · GW]. It gradually becomes pretty clear that what we want out powerful AIs to do and what they actually do turns out not to generalize that well outside of the distribution on which we have been testing them so far. At this point, it is to late to roll them back, e.g. because the AIs have become uncorrigible and/or power-seeking. The scenario may also have more systemic character, with AI having already been so tightly integrated into the economy that there is no "undo button".
This doesn't assume either the sharp left turn or deceptive alignment, but I'd put it at least at level 8 in your taxonomy.
I'd put the scenario from Karl von Wendt's novel VIRTUA [LW · GW] into this category.
Replies from: SDM↑ comment by Sammy Martin (SDM) · 2024-07-08T11:08:10.365Z · LW(p) · GW(p)
I agree that this is a real possibility and in the table I did say at level 2,
Misspecified rewards [LW · GW] / ‘outer misalignment’ / structural failures where systems don’t learn adversarial policies [2] [LW(p) · GW(p)]but do learn to pursue overly crude and clearly underspecified versions of what we want [LW · GW], e.g. the production web or WFLL1.
From my perspective, it is entirely possible to have an alignment failure that works like this and occurs at difficulty level 2. This is still an 'easier' world than the higher levels because you can get killed in a much swifter and earlier way with far less warning in those worlds.
The reason I wouldn't put it at level 8 is because presumably the models are following a reasonable proxy for what we want if it generalizes well beyond human level, but this proxy is inadequate in some ways that become apparent later on. The level 8 says not that any misgeneralization occurs but that rapid, unpredictable misgeneralization occurs around the human level such that alignment techniques quickly break down.
In the scenario you describe, there'd be an opportunity to notice what's going on (after all you'd have superhuman AI that more or less does what it's told to help you predict future consequences of even more superhuman AI) and the failure occurs much later.
comment by Sammy Martin (SDM) · 2023-08-09T11:03:51.147Z · LW(p) · GW(p)
Update
This helpful article [? · GW]by Holden Karnofsky also describes an increasing scale of alignment difficulty, although it's focused on a narrower range of the scale than mine (his scale covers 4-7) and is a bit more detailed about the underlying causes of the misalignment. Here's how my scale relates to his:
The "playing the training game" threat model, where systems behave deceptively only to optimize in-episode reward, corresponds to an alignment difficulty level of 4 or higher. This is because scalable oversight without interpretability tools (level 4) should be sufficient to detect and address this failure mode. The AI may pretend to be helpful during training episodes, but oversight exposing it to new situations will reveal its tendency toward deception.
(Situationally aware) Deception by default corresponds to a difficulty level of 6. If misaligned AIs form complex inner goals and engage in long-term deception, then scalable oversight alone will not catch intentionally deceptive systems that can maintain consistent deceitful behavior. Only interpretability tools used as part of the oversight process (level 6) give us the ability to look inside the system and identify deceptive thought patterns and tendencies.
Finally, the gradient hacking threat model, where AIs actively manipulate their training to prevent alignment, represents an alignment difficulty of 7 or higher. Even interpretability-based oversight can be defeated by sufficiently sophisticated systems that alter their internals to dodge detection.
comment by Remmelt (remmelt-ellen) · 2023-07-07T13:54:17.703Z · LW(p) · GW(p)
Regarding level 10 'impossible', here is a summary of arguments [LW · GW].
| 10 | Impossible | Alignment of a superintelligent system is impossible in principle. | Alignment is theoretically impossible, incoherent or similar. |
↑ comment by Sammy Martin (SDM) · 2023-07-07T20:07:46.085Z · LW(p) · GW(p)
Thanks for this! Will add to the post, was looking for sources on this scenario
comment by RogerDearnaley (roger-d-1) · 2023-12-19T08:09:54.329Z · LW(p) · GW(p)
See Interpreting the Learning of Deceit [AF · GW] for a practical proposal that should work up to and including level 7 on this scale (under certain assumptions that it discusses).
comment by Nicholas / Heather Kross (NicholasKross) · 2023-07-08T01:16:32.234Z · LW(p) · GW(p)
Nitpick (probably just me overthinking/stating the obvious) on levels 8-9 (I'm "on" level 8): I'd assume the point of this alignment research pre-SLT is specifically to create techniques that aren't broken by the SLT "obsoleting previous alignment techniques." I also think alignment techniques of the required soundness, would also happen to work on less-intelligence systems.
Replies from: SDM↑ comment by Sammy Martin (SDM) · 2023-07-10T15:33:05.609Z · LW(p) · GW(p)
This is plausibly true for some solutions this research could produce like e.g. some new method of soft optimization, but might not be in all cases.
For levels 4-6 especially the pTAI [LW · GW]that's capable of e.g. automating alignment research or substantially reducing the risks of unaligned TAI might lack some of the expected 'general intelligence' of AIs post SLT and be too unintelligent for techniques that rely on it having complete strategic awareness, self-reflection, a consistent decision theory, the ability to self improve or other post SLT characteristics.
One (unrealistic) example, if we have a technique for fully loading the human CEV into a superintelligence ready to go that works for levels 8 or 9, that may well not help at all with improving scalable oversight of non-superintelligent pTAI which is incapable of representing the full human value function.
comment by Lorec · 2024-12-27T21:15:09.963Z · LW(p) · GW(p)
Positively transformative AI systems could reduce the overall risk from AI by: preventing the construction of a more dangerous AI; changing something about how global governance works; instituting surveillance or oversight mechanisms widely; rapidly and safely performing alignment research or other kinds of technical research; greatly improving cyberdefense; persuasively exposing misaligned behaviour in other AIs and demonstrating alignment solutions, and through many other actions that incrementally reduce risk.
One common way of imagining this process is that an aligned AI could perform a ‘pivotal act’ that solves AI existential safety in one swift stroke. However, it is important to consider this much wider range of ways in which one or several transformative AI systems could reduce the total risk from unaligned transformative AI.
Is it important to consider the wide range of ways in which a chimp could beat Garry Kasparov in a single chess match, or the wide range of ways in which your father [or, for that matter, von Neumann] could beat the house after going to Vegas?
Sorry if I sound arrogant, but this is a serious question. Sometimes differences in perspective can be large enough to warrant asking such silly-sounding questions.
I am unclear where you think the problem for a superintelligence [which is smart enough to complete some technologically superhuman pivotal act] is non-vanishingly-likely to come in, from a bunch of strictly less smart beings which existed previously, and which the smarter ASI can fully observe and outmaneuver.
If you don't think the intelligence difference is likely to be big enough that "the smarter ASI can fully observe and outmaneuver" the previously-extant, otherwise-impeding thinkers, then I understand where our difference of opinion lies, and would be happy to make my extended factual case that that's not true.
Replies from: SDM↑ comment by Sammy Martin (SDM) · 2025-01-05T11:36:21.652Z · LW(p) · GW(p)
The point is that in this scenario you have aligned AGI or ASI on your side. On the assumption that the other side has/is a superintelligence and you are not, then yes this is likely a silly question, but I talk about 'TAI systems reducing the total risk from unaligned TAI'. So this is the chimp with access to a chess computer playing Gary Kasparov at chess.
And to be clear, on any slower takeoff scenario where there's intermediate steps from AGI to ASI, the analogy might not be quite that. In the scenario where there I'm talking about multiple actions, I'm usually talking about a moderate or slow takeoff where there are intermediately powerful AIs and not just a jump to ASI.
Replies from: Lorec↑ comment by Lorec · 2025-01-07T20:41:45.731Z · LW(p) · GW(p)
A chimp with a chess computer beating Garry Kasparov seems plausible to you?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-07T21:22:00.566Z · LW(p) · GW(p)
Yes, for me, though I'd give this low probability mostly due to the chimp breaking the computer, and most of the problems for the chimp fundamentally come down to their body structure being very unoptimized for tools, rather than them being less intelligent absolutely, and humans have much better abilities to use tools than chimps.
Replies from: Lorec↑ comment by Lorec · 2025-01-07T21:38:25.210Z · LW(p) · GW(p)
I'm inclined to conclude from this that you model the gulf between chimp society and human society as in general having mostly anatomical rather than cognitive causes. Is that correct?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-07T21:42:27.010Z · LW(p) · GW(p)
I'd say that cognitive causes like coordination/pure smartness do matter, but yes I'm non-trivially stating that a big cause of the divergence between chimps and humans is because of their differing anatomies, combined with an overhang from evolution where evolution spent it's compute shockingly inefficiently compared to us, though we haven't reduced the overhang to 0, and some exploitable overhangs from evolution still remain.
I'm modeling this as multiple moderate influences, plus a very large influenced added up to a ridiculous divergence.
Replies from: Lorec↑ comment by Lorec · 2025-01-07T22:03:05.367Z · LW(p) · GW(p)
AFAIK, there's around as much evidence for non-human ape capability in the mirror test as there is for certain cetaceans and magpies, and the evidence on apes being somewhat capable of syntactical sign language is mixed to dubious. It's true the internal politics of chimp societies are complex and chimps have been known to manipulate humans very complexly for rewards, but on both counts the same could be said of many other species [corvids, cetaceans, maybe elephants] none of which I would put on approximate par with humans intelligence-wise, in the sense of crediting them with plausibly being viable halves of grandmaster-level chess centaurs.
I'm curious if you have an alternate perspective wrt any of these factors, or if your divergence from me here comes from looking for intelligence in a different place.
Also, I'm not sure what you mean by "overhang [from] evolution spen[ding] its compute shockingly inefficiently" in this context.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-07T22:27:33.845Z · LW(p) · GW(p)
My alternate perspective here is that while IQ/intelligence actually matters, I don't think that the difference is so large as to explain why chimp society was completely outclassed, and I usually model mammals as having 2 OOMs worse to a few times better intelligence than us, though usually towards the worse end of that range, so other factors matter.
So the difference is I'm less extreme than this:
none of which I would put on approximate par with humans intelligence-wise.
On the overhang from evolution spending it's compute shockingly inefficiently, I was referring to this post, where evolution was way weaker than in-lifetime updating, for the purposes of optimization:
https://www.lesswrong.com/posts/hvz9qjWyv8cLX9JJR/evolution-provides-no-evidence-for-the-sharp-left-turn#Evolution_s_sharp_left_turn_happened_for_evolution_specific_reasons [LW · GW]
Replies from: Loreccomment by Review Bot · 2024-05-19T16:42:07.099Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?