Per protocol analysis as medical malpractice
post by braces · 2024-01-31T16:22:21.367Z · LW · GW · 8 commentsContents
8 comments
“Per protocol analysis” is when medical trial researchers drop people who didn’t follow the treatment protocol. It is outrageous and must be stopped.
For example: let’s say you want to know the impact of daily jogs on happiness. You randomly instruct 80 people to either jog daily or to simply continue their regular routine. As a per protocol analyst, you drop the many treated people who did not go jogging. You keep the whole control group because it wasn’t as hard for them to follow instructions.
At this point, your experiment is ruined. You ended up with lopsided groups: people able to jog and the unfiltered control group. It would not be surprising if the eager joggers had higher happiness. This is confounded: it could be due to preexisting factors that made them more able to jog in the first place, like being healthy. You’ve thrown away the random variation that makes experiments useful in the first place.
This sounds ridiculous enough that in many fields per protocol analysis has been abandoned. But…not all fields. Enter the Harvard hot yoga study, studying the effect of hot yoga on depression.
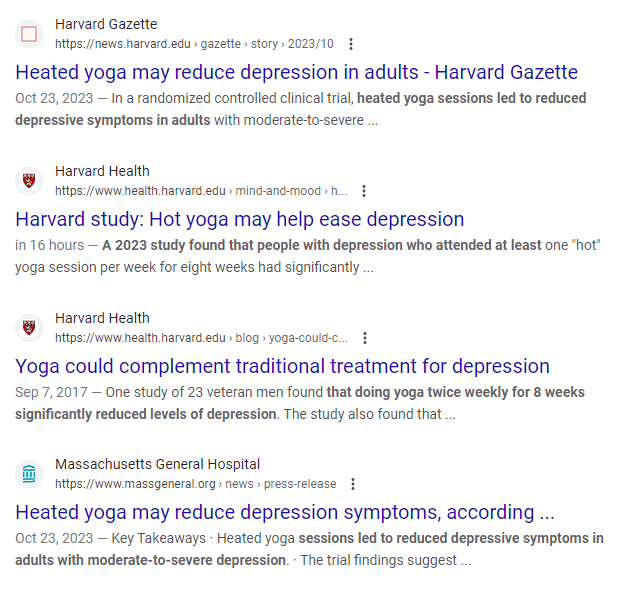
If the jogging example sounded contrived, this study actually did the same thing but with hot yoga. The treatment group was randomly assigned to do hot yoga. Only 64% (21 of 33) of the treatment group remained in the study until the endpoint at the 8th week compared to 94% (30 of 32) of the control. They end up with striking graphs like this which could be entirely due to the selective dropping of treatment group subjects.
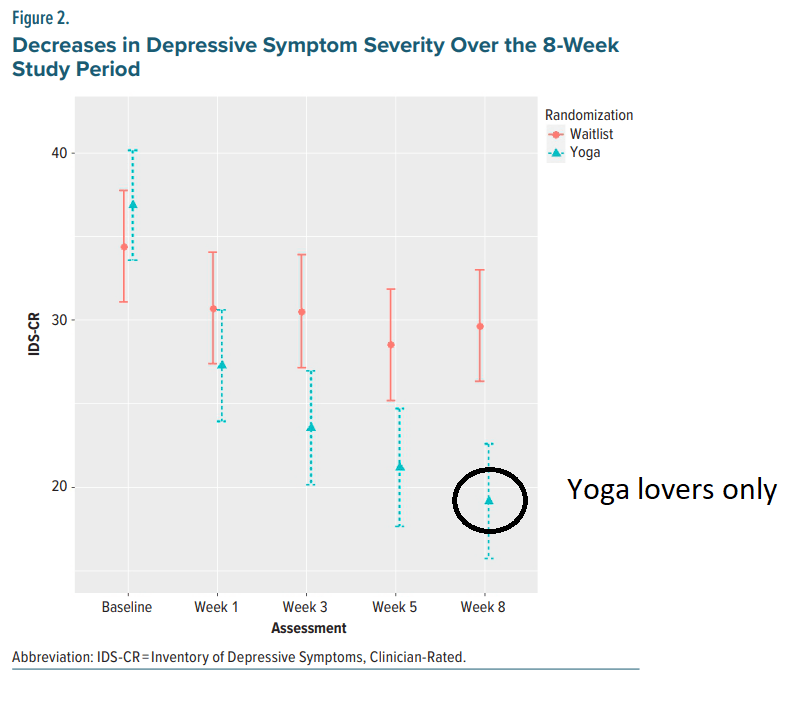
What’s depressing is that there is a known fix for this: intent-to-treat analysis. It looks at effects based on the original assignment, regardless of whether someone complied or not. The core principle is that every comparison should be split on the original random assignment, otherwise you risk confounding. It should be standard practice to report the intent-to-treat and many medical papers do so---at least in the appendix somewhere. The hot yoga study does not.
It might be hard to estimate this if you’re following people over time and there’s a risk of differential attrition---you're missing data for a selected chunk of people.
Also, hot yoga could still really work! But we just don’t know from this study. And with all the buzz, there’s a good chance this paper ends up being worse than useless: leading to scaled-up trials with null findings that might’ve not been run if there had been more transparency to begin with.
8 comments
Comments sorted by top scores.
comment by Kamil Pabis (kamil-pabis) · 2024-02-01T03:00:45.207Z · LW(p) · GW(p)
If the treatment is relatively mild, the dropouts are comparable between groups then I am not sure that per protocol will introduce much bias. What do you think? In that case it can be a decent tool for enhancing power, although the results will always be considered "post hoc" and "hypothesis-generating".
From experience I would say that intention-to-treat analysis is the standard in large studies of drugs and supplements, while per protocol is often performed as a secondary analysis. Especially when ITT is marginal and you have to go fishing for some results to report and to justify follow-up research.
Replies from: ben-lang, braces↑ comment by Ben (ben-lang) · 2024-02-05T12:27:20.573Z · LW(p) · GW(p)
The bias introduced is probably usually small, especially when the dropout rate is low. But, in those cases you get very little "enhanced power". You would be better off just not bothering with a per-protocol analysis, as you would get the same result from an ordinary analysis based on which group the person was sorted into originally (control or not).
The only situation in which the per-protocol analysis is worth doing is one where it makes a real difference to the statistics, and that is exactly the same situation in which it introduces the risk of introducing bias. So, I think it might just never be worth it: it removes a known problem (due to dropouts, some people in the yoga group didn't do all the yoga), with an unknown problem (the yoga group is post-selected nonrandomly), effecting exactly the same number of participants - so the same scale of problem.
In the Yoga context then I would say that if it's really good at curing depression then surely its effect size is going to be big enough to swamp a small number of yoga dropouts.
They also only have 32 participants in the trial. I don't know if its a real rule, but I feel like the smaller the dataset the more you should stick to really basic simple measures.
↑ comment by braces · 2024-02-01T05:26:24.680Z · LW(p) · GW(p)
It's a good question. I have the intuition that just a little potential for bias can go a long way toward messing up the estimated effect, so allowing this practice is net negative despite the gains in power. The dropouts might be similar on demographics but not something unmeasured like motivation. My view comes from seeing many failed replications and playing with datasets when available, but I would love to be able to quantify this issue somehow...I would certainly predict that studies where the per protocol finding differs from the ITT will be far less likely to replicate.
comment by ChristianKl · 2024-01-31T18:31:56.136Z · LW(p) · GW(p)
The key fraud seems to be the word "control". The researchers did not have real control over who was doing the Yoga.
Replies from: braces↑ comment by braces · 2024-02-02T16:12:33.542Z · LW(p) · GW(p)
I don’t think this part is so bad. You can lack “real control” but still have an informative experiment. You just need that people in the treatment group were on average more likely to receive the treatment. The issue is how they analyzed the data.
Replies from: ChristianKl↑ comment by ChristianKl · 2024-02-03T01:00:01.234Z · LW(p) · GW(p)
There are informative experiments that are not controlled experiments. Claiming that they are controlled when they aren't however sounds fraudulent to me.
comment by angelinahli · 2024-02-01T01:14:50.729Z · LW(p) · GW(p)
For example: let’s say you want to know the impact of daily jogs on happiness. You randomly instruct 80 people to either jog daily or to simply continue their regular routine. As a per protocol analyst, you drop the many treated people who did not go jogging. You keep the whole control group because it wasn’t as hard for them to follow instructions.
I didn't realize this was a common practice, that does seem pretty bad!
Do you have a sense of how commonplace this is?
What’s depressing is that there is a known fix for this: intent-to-treat analysis. It looks at effects based on the original assignment, regardless of whether someone complied or not.
In my econometrics classes, we would have been instructed to take an instrumental variables approach, where "assignment to treatment group" is an instrument for "does the treatment", and then you can use a two stage least squares regression to estimate the effect of treatment on outcome. (My mind is blurry on the details.)
IIUC this sounds similar to intent-to-treat analysis, except allowing you to back out the effect of actually doing the treatment, which is presumably what you care about in most cases.
Replies from: braces↑ comment by braces · 2024-02-01T02:52:38.150Z · LW(p) · GW(p)
I don't have a sense of the overall prevalence, I'm curious about that too! I've just seen it enough in high-profile medical studies to think it's still a big problem.
Yes this is totally related to two-stage least squares regression! The intent-to-treat estimate just gives you the effect of being assigned to treatment. The TSLS estimate scales up the intent-to-treat by the effect that the randomization had on treatment (so, e.g., if the randomization increased the share doing yoga from 10 in the control group to 50% in the treatment group, the intent-to-treat effect divided by 0.40 would give you the TSLS estimate).