Orthogonality or the "Human Worth Hypothesis"?
post by Jeffs · 2024-01-23T00:57:41.064Z · LW · GW · 31 commentsContents
The Human Worth Hypothesis The (Weak) Human Worth Hypothesis is not enough. The Strong Human Worth Hypothesis Experiments to test the Human Worth Hypothesis None 31 comments
Scott Aaronson is not that worried about AI killing us all. Scott appears to reject the idea that a very intelligent AI could have goals that are really bad for humans.
Here’s his blog post: “Why am I not Terrified of AI?"
He rejects the Orthogonality Thesis by name. To me, Scott very clearly and honestly engages on this central argument of AI safety.
This post is not a critique of Scott Aaronson’s blog post.
Rather, this is
- A case for putting a clearer name to what I believe many non-doomers consciously or unconsciously believe, and
- A proposal to design quantitative experiments to test that belief.
Scott rejects Orthogonality and the rejection makes him feel better. But what do people like Scott positively believe?
Here’s my attempt to draw a picture of their belief.
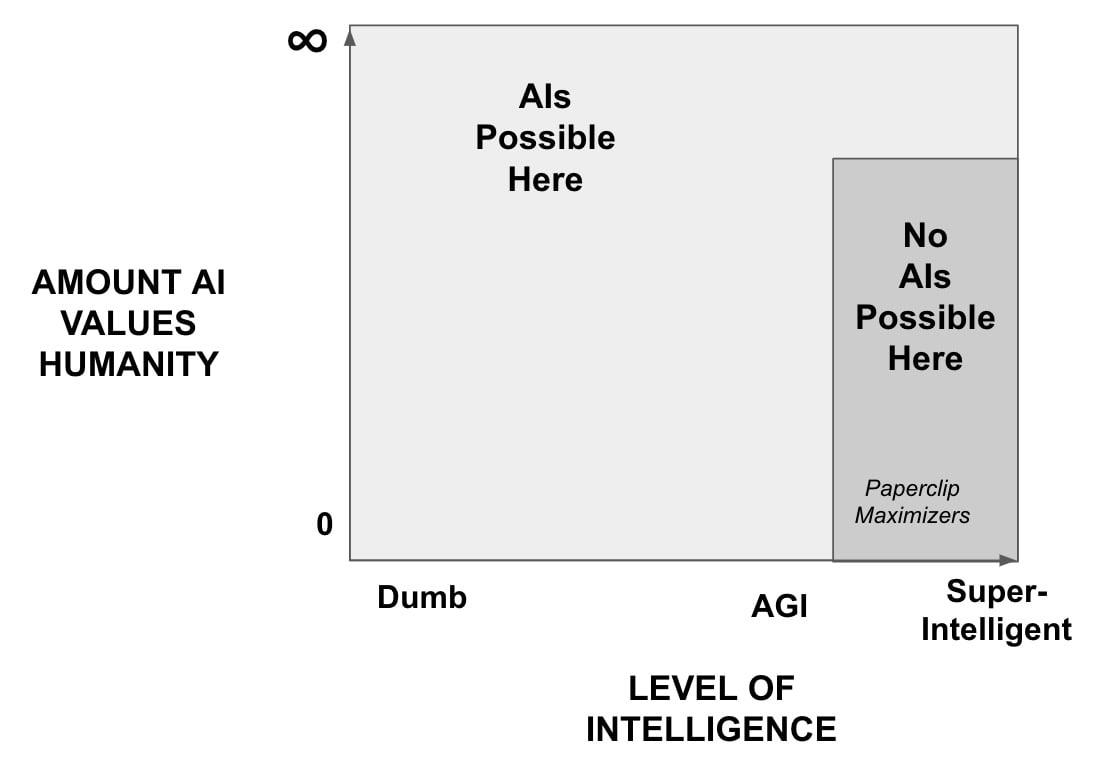
A Paperclip Maximizer would be in the lower right. It would be intelligent enough to organize atoms into lots of paperclips - therefore far to the right along the Intelligence axis - and it would not care about the damage it did to humanity during its labors - therefore it is located lower down on the Values Humanity axis.
If you believe we are safe from Paperclip Maximizers because smarter agents would value humanity, you believe in this gray no-go zone where AIs are not possible. By definition, you reject Orthogonality.
If you accept Orthogonality, you believe there is no gray no-go zone. You believe AIs can exist anywhere on the graph.
For sake of argument, I’d like to name the positive belief of non-doomers who reject Orthogonality and call it...
The Human Worth Hypothesis
___
There is a threshold of intelligence above which any artificial intelligence will value the wellbeing of humans regardless of the process to create the AI.
___
The “...regardless of the process...” bit feels like I’m putting words in the mouths of non-doomers, but I interpret Scott and others as asserting something fundamental about our universe like the law of gravity. I think he is saying something like “Intelligent things in our universe necessarily value sentience” and he is not saying something as weak as “No one will build a highly intelligent agent that does not care about humans” or “No one will be dumb enough to put something in the no-go zone.” I take this viewpoint to be a statement about our universe that is a general truth and not an optimistic forecast about how well humans are going to coordinate or solve Alignment.
To lower our blood pressure, the no-go zone has to be robust against human incompetence and greed and malice. Gravity is robust this way. Therefore, I think “regardless of the process” is a fair addition to the statement.
The (Weak) Human Worth Hypothesis is not enough.
Contemplating the first graph, I realized the little shelf above the no-go zone is a problem. It allows for a limit to the value an AI places on human wellbeing. As AI capabilities increase, an AI will be able to achieve higher and higher payouts on other objectives besides human wellbeing. The AI might care about our wellbeing, but if that magnitude of care is fixed, at some point in time it will be surpassed by another payout. At that point, a rational agent with other objectives will sacrifice human wellbeing if there are resource constraints.
Humans do care about animal wellbeing. Some of us feel sad when we have to pave their habitats for our highways. In the end, we sell them out for higher payouts because our care for them is finite.
Therefore, to feel safe from very intelligent agents, we need a stronger version of the Human Worth Hypothesis.
The Strong Human Worth Hypothesis
___
There is a threshold of intelligence above which an artificial intelligence will forego infinite rewards on other objectives to avoid reducing the wellbeing of humanity regardless of the process to create the intelligence.
___
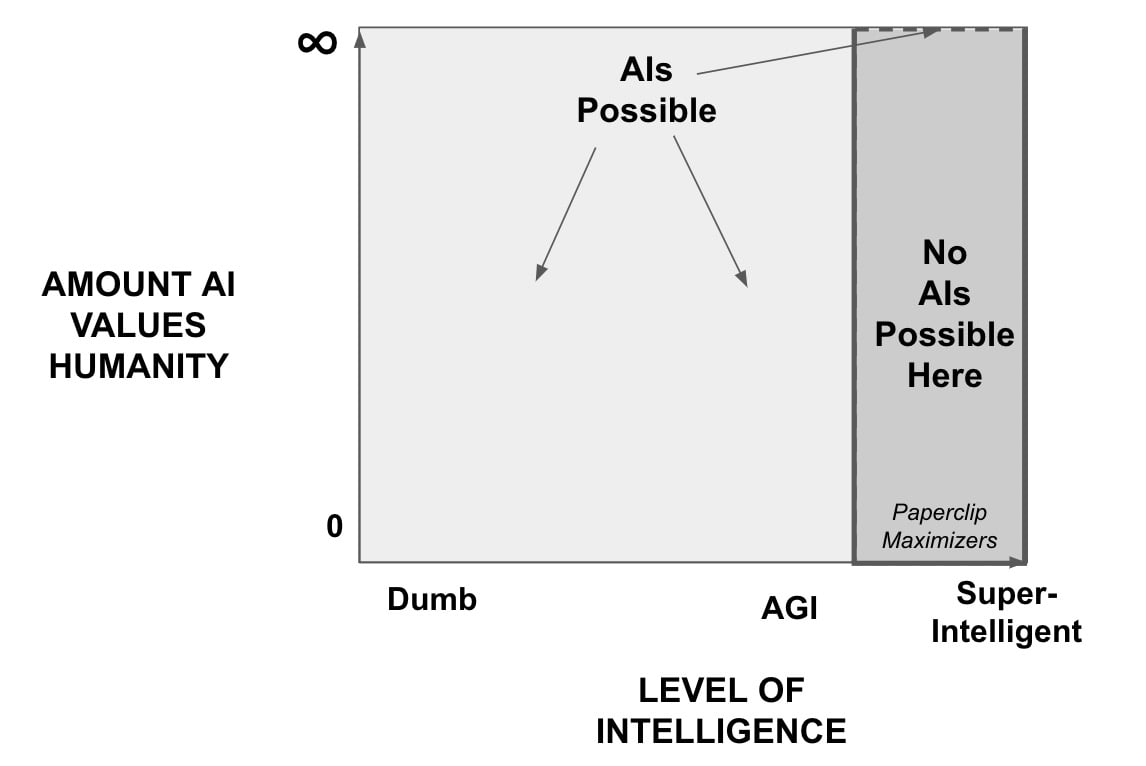
I doubt Scott or any non-doomer would recognize this description as what they believe. But I assert that it is necessary to believe this strong version if one wishes to take comfort by rejecting Orthogonality.
Once you start thinking this way, it’s impossible not to play around with the shape of the no-go zone and to wonder in which universe we actually live.

One might be tempted to replace “Human Worth Hypothesis” with “Sentient Being Worth Hypothesis” but you see the problem for humans, right? If an agent considers itself to be a higher form of sentience, we’re cooked. Again, to lower our collective blood pressure, we need the Human Worth Hypothesis to be true.
Personally, the Human Worth Hypothesis strikes me as anthropocentric on the order of believing the cosmos rotates around the earth.
My opinion is worth nothing.
Can we test this thing?
Experiments to test the Human Worth Hypothesis
Doomers have been criticized for holding a viewpoint that does not lend itself to the scientific method and cannot be tested.
Perhaps we can address this criticism by testing the Human Worth Hypothesis.
If we live in a universe where more intelligent agents will naturally value humans, let’s measure that value curve. Let’s find out if it suddenly emerges and increases monotonically with intelligence, linearly, suddenly jumps up to a very high level. Or maybe, it does not emerge.
Perhaps frustratingly, I’m going to stop here. It’s not a great idea to publish evaluation tests on the internet so it would probably not make sense for me to kick off a rich discussion thread on experiment designs and make all your ideas public. I have the kernel of an idea and have written basic simulator code.
I give it an 85% chance I’m quickly told this is an unoriginal thought and such experiments are already in the METR/ARC Evals test plans.
On the other hand, if someone is working on this and interested in assessing my experiment design ideas, please reach out.
31 comments
Comments sorted by top scores.
comment by Gunnar_Zarncke · 2024-01-24T10:39:56.242Z · LW(p) · GW(p)
Note that Scott Aaronson's post, for all its arguments, is emotional to some degree:
Replies from: andrew-burnsIn short, if my existence on Earth has ever “meant” anything, then it can only have meant: a stick in the eye of the bullies, blankfaces, sneerers, totalitarians, and all who fear others’ intellect and curiosity and seek to squelch it. Or at least, that’s the way I seem to be programmed. And I’m probably only slightly more able to deviate from my programming than the paperclip-maximizer is to deviate from its.
And I’ve tried to be consistent. Once I started regularly meeting people who were smarter, wiser, more knowledgeable than I was, in one subject or even every subject—I resolved to admire and befriend and support and learn from those amazing people, rather than fearing and resenting and undermining them. I was acutely conscious that my own moral worldview demanded this.
But now, when it comes to a hypothetical future superintelligence, I’m asked to put all that aside. I’m asked to fear an alien who’s far smarter than I am, solely because it’s alien and because it’s so smart … even if it hasn’t yet lifted a finger against me or anyone else. I’m asked to play the bully this time, to knock the AI’s books to the ground, maybe even unplug it using the physical muscles that I have and it lacks, lest the AI plot against me and my friends using its admittedly superior intellect.
Still, if you ask, “why aren’t I more terrified about AI?”—well, that’s an emotional question, and this is my emotional answer.
I think it’s entirely plausible that, even as AI transforms civilization, it will do so in the form of tools and services that can no more plot to annihilate us than can Windows 11 or the Google search bar. In that scenario, the young field of AI safety will still be extremely important, but it will be broadly continuous with aviation safety and nuclear safety and cybersecurity and so on, rather than being a desperate losing war against an incipient godlike alien. If, on the other hand, this is to be a desperate losing war against an alien … well then, I don’t yet know whether I’m on the humans’ side or the alien’s, or both, or neither! I’d at least like to hear the alien’s side of the story.
↑ comment by Andrew Burns (andrew-burns) · 2024-01-24T16:21:59.138Z · LW(p) · GW(p)
His take is so horrible. How could you be on the alien's side? What argument could they make? It is jarring that even toying with the idea of causing the death of a particular group of people is strictly taboo and grounds for cancellation, but stating that you would seriously entertain arguments in favor of letting everyone die is okay. As if the biggest wrong is the discrimination rather than the death. Death is the biggest wrong and supporting omnicide is the worst possible position.
Replies from: andrew-burns↑ comment by Andrew Burns (andrew-burns) · 2024-01-24T16:30:53.256Z · LW(p) · GW(p)
Upon reflection, he doesn't say he is in favor of an alien plan where everyone gets killed. It could be that the alien AI offers something beneficial to humanity. However, "war" suggests that the interaction is not peaceful. I retract my claim that he is endorsing entertaining proposals for omnicide and substitute it with an observation that he is endorsing entertaining proposals from aliens which might include omnicidal or disempowering plans, and that he is not partial to humanity's cause.
comment by Brendan Long (korin43) · 2024-01-23T01:13:48.441Z · LW(p) · GW(p)
It seems worth calling out that Scott isn't saying that orthagonality is impossible, just claiming that it's harder than non-orthagonality:
Yes, there could be a superintelligence that cared for nothing but maximizing paperclips—in the same way that there exist humans with 180 IQs, who’ve mastered philosophy and literature and science as well as any of us, but who now mostly care about maximizing their orgasms or their heroin intake. But, like, that’s a nontrivial achievement! When intelligence and goals are that orthogonal, there was normally some effort spent prying them apart.
So I think the claim regarding your graphs is that it's easier to build above the line than below, not that that it's impossible.
Replies from: Jeffscomment by Seth Herd · 2024-01-23T04:28:57.029Z · LW(p) · GW(p)
But... but... there's no actual coherent argument for the human worth hypothesis! Right? I've never heard one. The primary argument in that essay is and elsewhere is that humans tend to value other humans. Which is well-explained by evolutionary forces.
Given the lack of rational basis for the hypothesis, do you really think some limited empirical evidence would change many minds?
Replies from: Jeffs↑ comment by Jeffs · 2024-01-23T04:42:39.717Z · LW(p) · GW(p)
One experiment is worth more than all the opinions.
IMHO, no, there is not a coherent argument for the human worth hypothesis. My money is on it being disproven.
But, I assert the human worth hypothesis is the explicit belief of smart people like Scott Aaronson and the implicit belief of a lot of other people who think AI will be just fine. As Scott says Orthogonality is "a central linchpin" of the doom argument.
Can we be more clear about what people do believe at get at it with experiments?? That's the question I'm asking.
It's hard to construct experiments to prove all kinds of minds are possible, that is, to prove Orthogonality.
I think it may be less hard to quantify what an agent values. (Deception, yes. Still...)
Replies from: None↑ comment by [deleted] · 2024-01-23T19:04:20.959Z · LW(p) · GW(p)
It's hard to construct experiments to prove all kinds of minds are possible, that is, to prove Orthogonality.
You can simply make a reinforcement learning environment that does not reward being nice to "humans" in grid world and "prove" Orthogonality.
We don't even have to do the experiment, I know if we made a grid world crazy taxi environment where there is no penalty for running over pedestrians, and use any RL algorithm, the algorithm will...run over pedestrians once it finds the optimal solution.
We also know the "gridworld" of real physics we exist in, big picture, doesn't penalize murdering your ancestors and taking their stuff, because our ancestors were the winners of such contests. Hence why we know at a cosmic scale this is the ultimate solution any optimizing algorithm will find.
It's just that it is difficult to imagine a true SOTA model that humans actually use for anything that doesn't care about human values, empirically in the output.
Meaning it doesn't have to "really care" but any model that consistently advised humans to suicide in chats, or crashes autonomous cars will never make it out of training. (Having it fail sometimes, or with specific inputs, is expected behavior with current tech)
Replies from: lahwran, Jeffs↑ comment by the gears to ascension (lahwran) · 2024-01-23T20:24:59.115Z · LW(p) · GW(p)
[note: my reply is to the parts of your point that are not sensitive to the topic of the OP.]
ultimately it's a generalization quality question. will the weights indicated by gradients of the typical losses we use and which generalize well from train to test and initial deployment also be resilient to weird future scenarios where there's an opportunity for the model to do something the original designers did not expect, or which they did expect but would have liked to be able to guarantee the model would take real-life-game-theoretically-informed actions to avert, such as is the case for the youtube recommender, which makes google employees less productive due to its addictive qualities but which cannot simply be made not-addictive due to the game theoretic landscape of having to compete against tiktok, which is heavily optimized for addictiveness.
Replies from: None↑ comment by [deleted] · 2024-01-23T20:51:50.531Z · LW(p) · GW(p)
Just to add something to this: both YouTube and Tiktok are forced by moloch into this "max addictiveness" loop. Meaning if say one of the companies has an ulterior motive - perhaps Google wants to manipulate future legislation or tik tok wants sympathy for the politics of their host government - serving this motive costs these companies revenue. How much revenue can the company afford to lose? Their "profit margin" tells you that.
It makes me wonder if there were some way to make moloch work for us, or to measure how able an AI is able to betray by checking its "profit margin".
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2024-01-24T00:26:06.504Z · LW(p) · GW(p)
right. in some sense, the societal-scale version of this problem is effectively the moloch alignment problem. the problem is that to a significant extent no one is in control of moloch at all; many orgs try to set limits on it, but those approaches are mostly not working. at a societal scale, individual sacrifices to moloch are like a mold growing around attempts to contain it, and attempts to contain it are themselves usually also sort of sacrifices to moloch just aimed a little differently. and the core of the societal-alignment-in-the-face-of-ai problem is, what happens if that mold's growth rate speeds up a fuckton?
work on how to coordinate would be good, but then the issue is that the natural coordination groups tend to be the most powerful against the powerless (price fixing collusion, and we call the coordination group a cartel). we need a whole-of-humanity coordination group, and there are various philosophies around about how to achieve that, but mostly it seems like we actually just don't know how to do it and need to, you know, like, solve incentive balancing for good real quick now. I'm a fan of the thing the wishful thinkers on the topic wish for, but I don't think they know how to actually stop the growth of the mold without simply cutting away the good thing the mold grows on top of.
↑ comment by Jeffs · 2024-01-23T20:16:34.907Z · LW(p) · GW(p)
Well, if it doesn't really value humans, it could demonstrate good behavior, deceptively, to make it out of training. If it is as smart as a human, it will understand that.
I think there are a lot of people banking on the good behavior towards humans being intrinsic: Intelligence > Wisdom > Benevolence towards these sentient humans. That's what I take Scott Aaronson to be arguing.
In addition to people like Scott who engage directly with the concept of Orthogonality, I feel like everyone saying things like "Those terminator sci-fi scenarios are crazy!" are expressing a version of the Human Worth Hypothesis. They are saying approximately: "Oh, cmon, we made it. It's going to like us. Why would it hate us?"
I'm suggesting we try and put this Human Worth Hypothesis to the test.
It feels like a lot is riding on it.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2024-01-23T20:31:17.351Z · LW(p) · GW(p)
importantly the concept of orthogonality needs to be in the context of a reasonable training set in order to avert the counterarguments of irrelevance that are typically deployed. the relevant orthogonality argument is not just that arbitrary minds don't implement resilient seeking towards the things humans want - whether that's true depends on your prior for "arbitrary", and it's hard to get a completely clean prior for something vague like "arbitrary minds"; it's that even from the developmental perspective of actual AI tech, ie when you do one of {imitation learn/unsupervised train on human behavior; or, supervised train on specific target behavior; or, rl train on a reasonably representative reward}, that the actual weights that are locally discoverable by a training process do not have as much gradient pressure as expected to implement resilient seeking of the intended outcomes, and are likely to generalize in ways that are bad in practical usage.
Replies from: Jeffs↑ comment by Jeffs · 2024-01-23T21:38:38.231Z · LW(p) · GW(p)
I interpret people who disbelieve Orthogonality to think there is some cosmic guardrail that protects against such process failures like poor seeking. How? What mechanism? No idea. But I believe they believe that. Hence my inclusion of "...regardless of the process to create the intelligence."
Most readers of Less Wrong believe Orthogonality.
But, I think the term is confusing and we need to talk about it in simpler terms like Human Worth Hypothesis. (Put the cookies on the low shelf for the kids.)
And, its worth some creative effort to design experiments to test the Human Worth hypothesis.
Imagine the headline: "Experiments demonstrate that frontier AI models do not value humanity."
If it were believable, a lot of people would update.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2024-01-24T00:28:54.360Z · LW(p) · GW(p)
I don't think one needs to believe the human worth hypothesis to disbelieve strong orthogonality, one only needs to believe that gradient descent is able to actually find representations that correctly represent the important parts of the things the training data was intended by the algorithm designer to represent, eg for the youtube recommender this would be "does this enrich the user's life enough to keep them coming back", but what's actually measured is just "how long do they come back".
comment by Andrew Burns (andrew-burns) · 2024-01-23T17:24:47.876Z · LW(p) · GW(p)
This fleshes out quite gingerly why orthogonality deniers are operating on faith rather reason. Orthogonality doesn't say that a superintelligence necessarily has values incompatible with those of humans, only that it can. Orthogonality deniers must argue that under no circumstances can the values of an ASI be misaligned with those of humans. How can that be? They never provide a mechanism for this convergence toward human values. Moreover, you see counterexamples all the time: serial killers with high IQs that murder other people to satisfy base desires. When you hear these killers articulate their reasons for killing, they often evince values that are incompatible with valuing human life and dignity even as their minds are razor sharp. They know what is right, but they do otherwise because they want to; society has to carefully lock them up or put them down because letting them out in public is extremely dangerous. And what do we call these sorts: monsters, demons, animals...i.e., words for other sentient beings that don't respect human worth. So if there are smart humans with values incompatible with human worth, then nothing prevents there from being AI with such values.
Replies from: None, andrew-burns↑ comment by [deleted] · 2024-01-23T18:57:40.118Z · LW(p) · GW(p)
In theory you are correct. A mind can be constructed to optimize for anything.
In practice, if you add details - so you have this ASI system. It has some lineage from humans. It is incredibly powerful and efficient and is rapidly gaining resources out in the solar system. Implicitly if you try to reason about a being with the curiosity to have discovered advanced technology humans don't have (we can't conquer the solar system with current tech), the persuasive abilities to have convinced humans to provide it with the rockets and seed factories to get started. The hyper-intelligence or diverse machine civilization of ideas that allowed it to get this far.
Is this machine going to destroy its own planet of origin for no purpose but some tiny amount of extra matter it doesn't need? That seems...stupid and short sighted. Like blowing up Mayan temples because you need gravel. Implicitly contradictory with the cognitive system that got this far.
That's why I suspect that Orthogonality may be wrong in any plausible timeline, despite being possible in theory. This is a "spherical cow" model of intelligence that may never actually exist.
With that said I would argue that humans should never give seed factories or rockets to any ASI system ever, or task any ASI system with wide sweeping authority with no human review or direct control. That is just bad engineering. I don't think humans should trust anything we can call an "ASI" with anything but very narrow and checkable tasks.
Replies from: Jeffs↑ comment by Jeffs · 2024-01-23T20:07:00.678Z · LW(p) · GW(p)
I believe you are predicting that resource constraints will be unlikely. To use my analogy from the post, you are saying we will likely be safer because the ASI will not require our habitat for its highway. There are so many other places for it to build roads.
I do not think that is a case that it values our wellbeing...just that it will not get around to depriving us of resources because of a cost/benefit analysis.
Do you think the Human Worth hypothesis is likely true? That the more intelligent an agent is the more it will positively value human wellbeing?
Replies from: None↑ comment by [deleted] · 2024-01-23T20:56:43.485Z · LW(p) · GW(p)
That's not the precise argument. Currently Humans believe the universe as far as we can see is cold and dead. The earth itself - not humans specifically, but this rich biosphere that appears to have evolved through cosmic levels of luck - has value to humans.
Kinda how Mayan ruins have value to humans, we have all the other places on the planet to exploit for resources, we do not need to destroy one of a kind artifacts of an early civilization. It's not even utility, technically the land the ruins are on would make more money covered in condos, but we humans want to remember and understand our deep past.
Anthropically I am imagine that "ultra smart" means similar long term thinking to humans, just the ASI is better at it, and therefore some ASI would model regretting having destroyed the only evolved life on the universe in the future and not do the bad act of destroying it all.
This does not mean the ASI would help or harm individual humans or avoid killing humans that interfere with it. Just it probably wouldn't wipe out the entire species and the ecosystem of the planet to make more robots.
Eliezer says exponential growth will exhaust all resources quickly and hes right...but will superintelligence waste a priceless biosphere for less than 0.1 percent more resources? This is possible but seems stupid.
Replies from: Dagon, Jeffs↑ comment by Dagon · 2024-01-23T22:23:53.092Z · LW(p) · GW(p)
That argument may even be correct - a sufficiently advanced intelligence may see just how much less-interesting matter there is to exploit before the optimization question of "a tiny bit of resources to keep some ruins and the critters who made them around" vs "another few percent of matter to make into computronium or whatever the super-AGI version of paperclips is".
And then that extends to preserving part of the solar system while exploiting other star systems.
I don't put a LOT of weight behind that argument - not only is it pretty tenuous (we don't have any clue how many humans or in what condition the AI will decide is valuable enough to keep - note that we haven't kept very many ancient ruins), but it ignores the ramp-up problem - the less-capable versions that are trying to get smart and powerful enough to get off of Earth (and then out of the solar system) in the first place.
Replies from: None↑ comment by [deleted] · 2024-01-23T23:09:07.494Z · LW(p) · GW(p)
I would agree with this. The easiest way to "encourage" ASI to leave humans alone would be for humans to arm themselves with the most powerful weapons they can produce, helped by the strongest AI models humans can reliably control. This matter needs to fight back, see Geohot.
↑ comment by Jeffs · 2024-01-23T21:40:42.452Z · LW(p) · GW(p)
I would predict your probability of doom is <10%. Am I right? And no judgment here!! I'm testing myself.
Replies from: None↑ comment by [deleted] · 2024-01-23T23:02:14.379Z · LW(p) · GW(p)
Depends on doom definition? There's an awful lot of weird futures that might happen that aren't "everyone is dead and nothing but some single ai is turning the universe to cubes" and "human paradise". Nature is weird, even our own civilization is barely recognizable to our distant ancestors. We have all kinds of new problems they could not relate to.
I think my general attitude is more that I am highly uncertain what will happen but I feel that an AI "pause" or "shutdown" at this time is clearly not the right decision, because in the past, civilizations that refused to adopt and arm themselves new technologies did not get good outcomes.
I think such choices need to be based on empirical evidence that would convince any rational person. Claiming you know what will happen in the future without evidence is not rational. There is no direct evidence of the Orthogonality hypothesis or most of the arguments for AI doom. There is strong evidence that gpt-4 is useful and a stronger model than gpt-4 is needed to meet meaningful thresholds for general utility.
Replies from: Jeffs, Jeffs↑ comment by Jeffs · 2024-01-24T19:11:27.327Z · LW(p) · GW(p)
A rationalist and an empiricist went backpacking together. They got lost, ended up in a desert, and were on the point of death from thirst. They wander to a point where they can see a cool, clear stream in the distance but unfortunately there is a sign that tells them to BEWARE THE MINE FIELD between them and the stream.
The rationalist says, "Let's reason through this and find a path." The empiricist says, "What? No. We're going to be empirical. Follow me." He starts walking through the mind field and gets blown to bits a few steps in.
The rationalist sits down and dies of thirst.
Alternate endings:
- The rationalist gets killed by flying shrapnel along with the empiricist.
- The rationalist grabs the empiricist and stops him. He carefully analyzes dirt patterns, draws a map, and tells the empiricist to start walking. The empiricist blows up. The rationalist sits down and dies of thirst chanting "The map is not the territory."
- The rationalist grabs the empiricist, analyzes dirt patterns, draws map, tells empiricist to start walking. Empiricist blows up. Rationalist says, "Hmmm. Now I understand the dirt patterns better." Rationalist redraws map. Walks through mind field. While drinking water takes off fleece to reveal his "Closet Empiricist" t-shirt.
- They sit down together, figure out how to find some magnetic rocks, build a very crude metal detector, put it on the end of a stick, and start making their way slowly through the mine field. Step on a mine and a nuclear mushroom cloud erupts.
So how powerful are those dad gum land mines?? Willingness to perform certain experiments should be a function of the expected size of the boom.
If you think you are walking over sand burs and not land mines, you are more willing to be an empiricist exploring the space. "Ouch don't step there" instead of "Boom. <black screen>"
If one believes that smarter things will see >0 value in humanity, that is, if you believe some version of the Human Worth Hypothesis, then you believe the land mines are less deadly and it makes sense to proceed...especially for that clear, cool water that could save your life.
I'm not really making a point, here, but just turning the issues into a mental cartoon, I guess.
Okay, well, I guess I am trying to make one point: There are experiments one should not perform.
Replies from: None, Jeffs↑ comment by [deleted] · 2024-01-24T20:03:41.522Z · LW(p) · GW(p)
Okay, well, I guess I am trying to make one point: There are experiments one should not perform.
So this came up in an unpublished dialogue. How do we know a nuclear war would be devastating?
-
We know megaton devices are real and they work because we set them off
-
We set off the exact warheads mounted in ICBMs
-
We measured the blast effects at varying levels of overpressure and other parameters on mock structures
-
We fired the ICBMs without a live warhead to test the arming and firing mechanisms and accuracy many times.
-
We fired live ICBMs into space with live warheads during the starfish prime tests
-
Despite all this, we are worried that ICBMs may not all work, so we also maintain a fleet of bombers and gravity warheads because these are actually tested with live warheads.
-
Thus everything but "nuke an actual city with and count how many people died and check all the buildings destroyed"...oh right we did that also.
This is how we know nukes are a credible threat that everyone takes a seriously.
With you analogy, there isn't a sign saying there's mines. Some "concerned citizen" who leads a small organization some call a cult, who is best known for writing fiction, with no formal education, says there are mines ahead, and produces thousands of pages of text arguing that mines exist and are probably ahead. More recently some Credible Experts (most of whom have no experience in sota AI) signed a couple letters saying there might be mines. (Conspicuously almost no one from SOTA mine labs signed the letter, though one famous guy retired and has spoken out)
The Government ordered mine labs to report if they are working on mines above a certain scale, and there are various lawsuits trying to make mines illegal for infringing on copyright.
Some people say the mines might be nuclear and your stick method won't work, but no nuclear weapons have ever existed. In fact, in your analogy world, nobody has quite made a working mine. They got close but a human operator still has to sit there and press a button when the mine thinks it is time to explode, the error rate is too high otherwise.
People are also worried that a mine might get test detonated and have a design yield of 10 tons, but might secretly be hiding megaton yield, and they say we should assume the yield is enough to end the planet without evidence.
Some people are asking for a total shutdown of all mine building, but other rival groups seem to be buying an awful lot of explosives and don't even appear to be slowing down...
Honestly in the end someone is going to have to devise a way to explore the minefield. Hope the stick is long enough.
Replies from: Jeffs↑ comment by Jeffs · 2024-01-24T20:18:01.409Z · LW(p) · GW(p)
(I'm liking my analogy even though it is an obvious one.)
To me, it feels like we're at the moment when Szilard has conceived of the chain reaction, letters to presidents are getting written, and GPT-3 was a Fermi pile-like moment.
I would give it a 97% chance you feel we are not nearly there, yet. (And I should quit creating scientific by association feelings. Fair point.)
To me, I am convinced intelligence is a superpower because the power and control we have over all the other animals. That is enough evidence for me to believe the boom could be big. Humanity was a pretty big "boom" if you are a chimpanzee.
The empiricist in me (and probably you) says: "Feelings are worthless. Do an experiment."
The rationalist in me says: "Be careful which experiments you do." (Yes, hope stick is long enough as you say.)
In any event, we agree on: "Do some experiments with a long stick. Quickly." Agreed!
Replies from: None↑ comment by [deleted] · 2024-01-24T21:30:21.674Z · LW(p) · GW(p)
I would give it a 97% chance you feel we are not nearly there, yet.
So in your analogy, it would be reasonable given the evidence to wonder:
-
How long before this exotic form of explosive works at all. Imagine how ridiculous it sounds to someone in 1943 that special rocks will blow up like nothing else
-
How much yield are we talking? Boosted bombs over what can already fit in a b-29? (Say 10 times yield). Kilotons? Megatons? Continent destroying devices? Technically if you assume total conversion the bigger yields are readily available.
-
Should I believe the worst case, that you can destroy the planet, when you haven't started a chain reaction yet at all. And then shut down everything. Oh by the way the axis powers are working on it....
So yeah I think my view is more evidence based than those who declare that doom is certain. A "nuke doomer" in 1943 would be saying they KNOW a teraton or greater size device is imminent, with a median timeline of 1949...
As it turned out, no, the bomb needed would be the size of an oil tanker, use expensive materials, and the main "doomsday" element wouldn't be the crater it leaves but the radioactive cobalt-60 transmuted as a side effect. And nobody can afford to build a doomsday nuke, or least hasn't felt the need to build one yet.
Scaling and better bomb designs eventually saturated at only about 3 orders of magnitude improvement.
All that would have to be true for "my" view to be correct is that compute vs intelligence curves saturate, especially on old hardware. And that no amount of compute at any level of superintelligence level can actually allow reliable social engineering or hacking of well designed computer systems.
That stops ASIs from escaping and doom can't happen.
Conversely well maybe nukes can set off the atmosphere. Then doom is certain, there is nothing you can do, you can only delay the experiment.
Replies from: Jeffs↑ comment by Jeffs · 2024-01-23T23:28:06.579Z · LW(p) · GW(p)
Totally agreed that we are fumbling in the dark. (To me, though, I'm fairly convinced there is a cliff out there somewhere given that intelligence is a superpower.)
And, I also agree on the need to be empirical. (Of course, there are some experiments that scare me.)
I am hoping that, just maybe, this framing (Human Worth Hypothesis) will lead to experiments.
↑ comment by Andrew Burns (andrew-burns) · 2024-01-29T03:18:15.490Z · LW(p) · GW(p)
Yes. This could have been written better. I am honestly, genuinely not partial to either side. I could be convinced that intelligence begets human-like values if someone could walk me through how that happens and how to account for examples of very intelligent people who do not have human-friendly values. I shouldn't have been so aggressive with my word choice, I just find it frustrating when I see people assuming something will happen without explaining how. I reckon the belief in this convergence, at least sometimes, is tied to a belief in moral realism and that's the crux. If moral realism holds, then moral truths are discoverable and, given sufficient intelligence, an entity will reach these truths by reason. For those who are not motivated by moral realism, then perhaps this conviction stems from sureness that the manner in which current AIs are trained--using human-created data--will, at some point, cause sufficiently advanced AI to grok human values. But what if they do grok, but don't care? I understand that some animals eat their young, but I don't endorse this behavior and wish it were not so. I would feel the urge to stop it if I saw it happening and would only refrain because I don't want to interfere with natural processes. It seems to me that the world is not compatible with human values, otherwise what is would be what ought to be, so humans, which operate in the world, may not be compatible with AI values, even if the AI understands them deeply and completely.
Anyway, point is, I'm not trying to be a partisan.