Pitfalls of the agent model
post by Alex Flint (alexflint) · 2021-04-27T22:19:30.031Z · LW · GW · 5 commentsContents
Outline Introduction What is the agent model? The fixed policy assumption Example: MDP and POMDP The agent model does not imply optimization Dimensions of analysis Humans looking at themselves as agents Pitfall 1: Self-hatred Pitfall 2: Procrastination / forgetfulness Humans looking at other humans as agents Pitfall 3: Hatred of others Pitfall 4: Viewing oneself as a loser in Newcomb’s problem Humans looking at machines as agents Pitfall 5: Agency hand-off fallacy Pitfall 6: Forgetting to examine the scaffold Pitfall 7: Putting ourselves "into the shoes" of the machine Machines looking at themselves as agents Pitfall 8: Confusion about fallibility Pitfall 9: Difficulty modifying own hardware Machines looking at humans as agents Pitfall 10: Looking for fixed values Pitfall 11: Incomprehensibility of corrigibility Machines looking at other machines as agents Pitfall 12: Bias towards conflict Summary of the pitfalls Connections to other research Conclusion None 5 comments
This is independent research. To make further posts like this possible, please consider supporting me.
Outline
-
I study the agent model as a frame for understanding the phenomenon of entities that exert influence over the future.
-
I focus on one implication of the agent model: the assumption of a fixed agent policy that is unchanging over time.
-
I study the consequences of this assumption in a number of scenarios. I consider single- and multi-agent scenarios, scenarios consisting of humans, machines, and combinations of humans and machines, and scenarios in which the agent model is being used by an entity to model itself versus other entities. I show that all combinations of these can be covered by six basic cases. For each of the six cases I identify pitfalls in which certain aspects of reality are abstracted away by the application of the agent model, and we examine the consequences of each.
-
I draw connections to related work in embedded agency, partial agency, and embodied cognition.
-
I conclude that the agent model has significant shortcomings as a frame for the engineering of advanced AI systems.
Introduction
Yesterday I wrote about [LW · GW] the agent model as a frame for understanding the real-world phenomenon of entities in the world that exert influence over the future.

I said that we should be cautious about over-using any one frame as a means for understanding any phenomena, because when we only have one frame it is easy to forget about the boundary between the phenomena that we’re looking at and the frame that we’re looking at it with, which is a problem no matter how powerful or accurate our preferred frame is. This is indeed one reason to consider frames other than the agent model when studying entities that exert influence over the future. A second reason is that there are specific shortcomings of the agent model. I want to examine some of those today.
All frames have shortcomings. A frame is precisely that which gives us a way of seeing that is simpler than reality itself, so the whole point of a frame is that it does not include every aspect of reality. We can always point to ways in which any given frames fail to capture all of reality, and that is no reason on its own to discard a frame. Nevertheless, we may want to de-emphasize frames whose shortcomings are severe enough. In this post I will present the shortcomings of the agent model as I see them, so that you can decide to what extent you want to emphasize the agent model in your own thinking.
I will not be examining the up-sides of the agent model in this post. It is a powerful model with many up-sides, as evidenced by its broad adoption across many disciplines over the last few hundred years. Perhaps a future post will examine the virtues of the agent model.
What is the agent model?
Under the agent model, we consider the world as consisting of two parts: the agent, and the environment. Information flows from environment to agent as a sequence of observations, and from agent to environment as a sequence of actions.
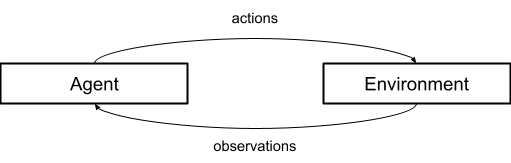
The agent model is a frame that we use to understand entities in the world, and to engineer new entities. For example, when constructing a reinforcement learning system to play Atari games, it is natural enough for the engineers of the system to look at things as an agent receiving observations from an environment and sending actions back in return. In this case, the environment is the state of the Atari game, the observations are a 2D grid of pixels shown on the screen, and the actions are the moves available within the game. This is a situation where it makes good sense to use the agent model.
Consider another situation where it makes good sense to use the agent model. An engineer designing a robot vacuum might consider an environment consisting of various obstacles and patches of floor to be vacuumed, observations consisting of "bump" notifications generated when the robot touches a wall, and actions consisting of turning the left and right wheels forward or backwards at different speeds. A robot vacuum is not separate from the environment as an Atari game-playing AI is, but the agent model is still a fairly expedient frame within which human engineers might solve design problems concerning a robot vacuum.
This essay works through some more complicated scenarios in which use of the agent model may give rise to problems.
Note that just because the human engineers of a system use the agent model as a frame for constructing a system does not mean that the system itself uses the agent model internally to model itself or others. A house constructed by engineers who used an understanding of thermodynamics to optimize the heat-efficiency of its insulation does not generally contain any computer capable of using the laws of thermodynamics to consider ways that it might design other houses or redesign itself. Similarly, an entity constructed by engineers who used the agent model to aid development need not itself use the agent model within its own decision processes. My robot vacuum may have an internal representation of the size and shape of its own body, but it almost certainly does not have any explicit concept of itself as an agent receiving observations from and sending actions to the environment, much less an explicit concept of others as agents[1].
The fixed policy assumption
When looking at the world through the frame of the agent model, the environment is seen as changing over time, but the policy implemented by the agent is seen as fixed. Much of the power of the agent model as a frame for understanding the world comes from this fixed policy assumption. For example, under inverse reinforcement learning we observe a sequence of actions taken by some entity, then we look for a value function that explains this behavior. We do not model the value function as changing from one step to the next. If it did, inverse reinforcement learning would no longer work[2]. It is difficult enough to get inverse reinforcement learning to work even with the assumption of a fixed value function; incorporating a time-varying value function into the model would make the problem hopelessly underspecified. A fixed value function is just how inverse reinforcement learning works.
Or, consider ordinary reinforcement learning, in which we search over a space of possible policies, rolling out each one over time to see how it behaves. We may consider policies that behave differently at different times, but, at least in classical reinforcement learning, we do not consider policies that change over time. For example, in setups where the policy is encoded as a neural network, we do not consider policies with network coefficients that change from one time step to the next.
Now, we are aware that agents are implemented as computer programs running on physical computers, and we are aware that these implementations involve memory registers whose values change and wires carrying charge. We are aware that the state of the CPU is changing from moment to moment. We are aware even that the memory cells whose value does not not change are not unchanging at the level of the physical substrate, but instead the memory cell is constructed in a way that maintains a configuration within a certain range that is recognized as a single 0 or a single 1 by the higher-level computing machinery.
So we are aware that a physical computer is in fact changing over time at every level, but we choose to use a frame in which there is a computer program that is running, and the source code for that program is not changing. And this is a reasonable assumption in many cases. Computers in fact have excellent error correction mechanisms that allow them to keep running an unchanging computer program over a long period of time. My robot vacuum, for example, does in fact run the same computer program each time I turn it on. It will be a long time before I can expect a stray cosmic ray to flip a bit representing the core computer program on my robot vacuum, or for the memory cells to physically degrade to the point of information loss.
You might think that if we don’t want this fixed policy assumption then we could just consider a variant of the agent model in which some actions and some observations modify the policy. It’s true that we could modify the agent model in this way, but if you do this "all the way to the bottom", meaning that any aspect of the policy can in principle be modified, then you invalidate much of the machinery that has been built on top. The basic theorems underlying RL and IRL stop working. Even the more basic planning and control algorithms from earlier periods of AI stop working. And the basic conclusions from the rational actor model in economics stop applying, too. So the fixed policy assumption is deeply baked in, and thus will be the primary frame through which this essay views the agent model.
Example: MDP and POMDP
The Markov Decision Process and Partially Observable Markov Decision Process are two models from computer science that explicitly organize the world into an agent and an environment. The "decision process" here refers to the environment, which proceeds through a sequence of states, each one conditionally independent of all prior states given the immediately prior state (this is what "Markov" refers to). In the MDP the agent observes the full state of the world at each point in time, while in the POMDP the agent observes just some aspect of the world at each point in time.
The MDP and POMDP do not explicitly state that the agent receiving observations from and sending actions back to the decision process must be executing an unchanging policy, but their formal solution strategies, such as reinforcement learning, generally do.
The agent model does not imply optimization
Under the agent model we view entities that exert influence over the future as executing abstract algorithms that process observations and generate actions. Those abstract algorithms may or may not be optimization algorithms. For example, I might build a robot that moves forward until it hits a wall, and then stops. We need not view this robot as optimizing anything in order to view it as an agent.
Now, there is an orthogonal question of under what circumstances we might choose to view [LW · GW] an algorithm as an optimization algorithm [LW · GW]. We might encounter a robot that "under the hood" is taking actions based on a state machine, but choose to view it as acting in service of a goal due the compactness of that representation [LW · GW]. This is an important distinction but is unrelated to whether we are using the agent frame or not. The agent frame merely posits an abstract algorithm as an appropriate model for explaining the behavior of some entity.
Dimensions of analysis
I am going to examine the ways that the view of the world afforded by using the agent model differs from the true state of things. I am going to do that by examining scenarios involving various subjects that are using the agent frame and various objects being looked at through the agent frame. The dimensions I want to cover are:
-
Scenarios in which an entity is looking at itself versus looking at another entity.
-
Scenarios with humans and machines (and combinations thereof). For now I will consider each combination of subject and object being human and machine.
-
Scenarios with single and multiple entities. For now I will collapse this with the first dimension and consider cases consisting of either one entity or two entities, where in the former case I assume that the entity views itself through the agent frame, and in the latter case that the entity views the other entity through the agent frame.
The scenarios I will consider are as follows:
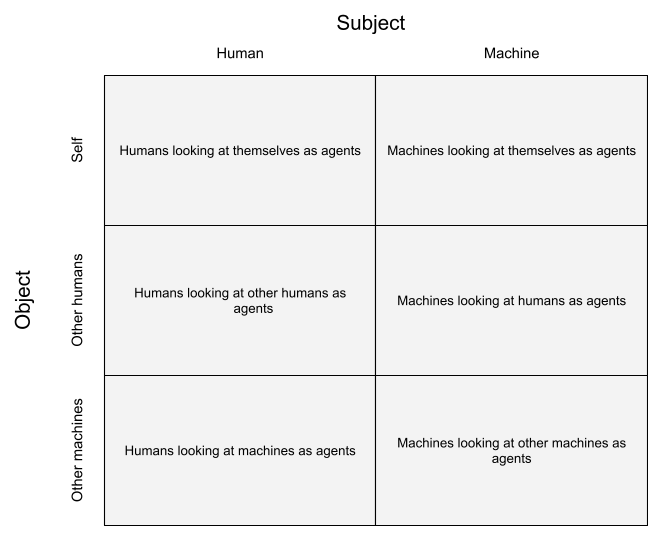
For each of these scenarios I will consider various pitfalls. There are 12 pitfalls in total, and they are summarized in a table at the bottom.
Humans looking at themselves as agents
Pitfall 1: Self-hatred
Sometimes a human perceives that an action they have taken has caused harm in the world. In some cases the perception is mistaken, and in reality their action was not the cause of the harm, while in other cases the perception is correct, and their action was the cause of the harm. But upon seeing this harm, a human viewing themselves through the frame of the agent model, and therefore making the fixed policy assumption with respect to themselves, may conclude that this harm is an artifact of an immutable internal decision algorithm. Since the human does not want to cause harm, but also holds the view of an immutable internal decision algorithm that, from within the frame of the agent model, has been observed causing harm at least once, their only option appears to be to adopt a combative relationship with this immutable internal decision algorithm and limit the harm that it is causing by resisting it. This leads to a internal conflict as the human takes actions, then perceives these actions from within the agent frame as having been generated by an immutable internal decision algorithm, then concludes on the basis of having perceived this immutable internal decision algorithm having caused harm in the past that the action is probably also harmful, and then takes further actions to resist and limit the consequences of this first action. Of course these further actions are subject to the same chain of reasoning so long as the human is looking at themselves from within the agent frame, so the human ends up taking yet further actions to oppose the actions that were taken to oppose the first action, and this cycle continues indefinitely.
Perception from within the agent frame: An unchanging internal decision algorithm is causing harm but cannot be modified, so must be fought.
Reality: The human could simply choose to act differently.
Fundamental misperception due to the agent frame: That there is "some place else" from which actions originate, separate from the one reasoning about the harm.
Pitfall 2: Procrastination / forgetfulness
Sometimes a human sees that an action would be valuable to perform, but sees little benefit in performing that action sooner rather than later, perhaps up to some deadline, such as filing taxes before tax day. The human, viewing themselves through the frame of the agent model, believes that there will be no cost to delaying, since they perceive an unchanging internal decision algorithm that has been observed at least once identifying the action as valuable, and so is likely to do so in the future. In fact there are multiple mistakes in this reasoning. First, humans are subject to change due to interaction with their environments, and this particular human may change in such a way that they forget or undervalue this action in the future. Second, humans are subject to change due to their own actions, and the architecture of human brains is such that actions practiced repeatedly become more likely to be performed again in the future, so by delaying action the human is in fact performing a subtle form of self-modification in the direction of delaying actions in general. In other situations this might be what the human intended to do, but in this example the human is, by assumption, overlooking this.
Perception from within the agent frame: An unchanging decision algorithm could equally well perform the action now or in the future, and there is no harm caused by delaying action.
Reality: Human decision algorithms are subject to change due both to interaction with the environment and habit formation.
Fundamental misperception due to the agent frame: Actions taken by the human do not affect the human’s policy.
Humans looking at other humans as agents
Pitfall 3: Hatred of others
Sometimes a human perceives an action taken by another human as having caused harm. In some cases the human’s perception is mistaken, and in reality the other human was not the cause of the harm, while at other times the perception is correct, and in reality the other human was the cause of the harm. But upon seeing this harm, a human viewing another human through the frame of the agent model may conclude that the cause of the harm can be traced back to an immutable decision algorithm within the other human. Since the human does not want there to be harm in the world, but also holds the view of an immutable decision algorithm within the other human that, from within the frame of the agent model, has been observed causing harm at least once, their only option appears to be adopting a combative relationship with the other human. In particular, the human may not believe that the other human has the capacity to change this internal decision algorithm even if they wanted to, so may not seek to negotiate with this other human, concluding instead that their only option is to resist or limit the consequences of other human’s actions.
Perception from within the agent frame: An unchanging decision algorithm within another human is causing harm but cannot be modified, so must be fought.
Reality: The other human might have the capacity to self-modify and might choose to do so if negotiated with.
Fundamental mis-perception due to the agent frame: Negotiation is unlikely to work because the other human could not change their own internal decision algorithm even if they wanted to.
Pitfall 4: Viewing oneself as a loser in Newcomb’s problem
When some aspect of the environment has been determined by an examination of a human’s decision-making strategies via a channel that is not the human’s own actions, a human viewing the world through the frame of the agent model may miss the opportunity to make changes to their own decision-making due to the belief that some other human will necessarily view them as having a fixed internal decision algorithm. Newcomb’s problem formalizes this in the context of a philosophical thought experiment. Within Newcomb’s problem, a human using a strict agent model may reason that they are a consequential decision agent for better or worse, and that hypothetical panel of experts in Newcomb’s problem will have perceived this, and therefore will have put the lesser of two amounts in the envelopes, and so their best course of action is to take both boxes.
Perception from within the agent frame: An unchanging internal decision algorithm will have been perceived and acted upon by some external entity.
Reality: There is in fact no unchanging internal decision algorithm, and a panel of experts as omniscient as the one hypothesized in Newcomb’s problem will have correctly realized this.
Fundamental misperception due to the agent frame: First, that an unchanging internal decision algorithm exists, and second that this will have been perceived and acted upon by an external entity.
Humans looking at machines as agents
Pitfall 5: Agency hand-off fallacy
A human building an AI adopts a frame in which the AI, once deployed, will be an agent. The human correctly reasons that the AI will exert influence over the future, but incorrectly adopts the view that the AI will necessarily consist of an unchanging internal decision algorithm. Due to this, the human does in fact build an AI with an unchanging internal decision algorithm, overlooking other possible designs. This forces the human to hand off influence over the future [LW · GW] to the agent at the time of the agent’s construction, which in turn forces the human to adopt a false dichotomy between solving a wide array of philosophical and technical problems before the first AI is built, or else deploying a powerful AI that is not certain to act in a manner that the human would approve of.
Perception from within the agent frame: Powerful AI systems will necessarily contain an unchanging internal decision algorithm.
Reality: There is a wider design space of autonomous machines that exert influence over the future.
Fundamental misperception due to the agent frame: That the design space for autonomous machines that exert influence over the future is narrower than it seems. This creates a self-fulfilling prophecy in which the AIs actually constructed are in fact within this narrower regime of agents containing an unchanging internal decision algorithm.
Pitfall 6: Forgetting to examine the scaffold
A human considers a robot they are building using the frame of the agent model. Due to this, they place most of their attention on formulating the decision algorithm, and place less attention on the sensors, actuators, and computing machinery that will implement the decision algorithm and connect it with the external world. Due to this, the design of the decision algorithm is not informed by the practical failure modes of the sensors, actuators, and computing machinery, and the overall system is fragile.
Perception from within the agent frame: An unchanging internal decision algorithm that receives observations and outputs actions is the primary objective of design and engineering efforts.
Reality: The sensors, actuators, and computing machine may require as much subtlety in design and engineering efforts as the decision algorithm.
Fundamental misperception due to the agent frame: Over-emphasis on the decision algorithm during development.
Pitfall 7: Putting ourselves "into the shoes" of the machine
A human considers an AI they are building through the frame of the agent model. They consider situations in which the AI may be copied and may not know how many times it has been copied, as per philosophical thought experiments such as the Sleeping Beauty problem. Due to the view of the AI as an agent with an unchanging internal decision algorithm, the human occupies most of their attention with the question of what they (the human) would do given the information available to the AI under various hypothetical situations, missing the opportunity to simply choose a design for the AI that has the consequences desired by the human. Within the Sleeping Beauty problem, for example, it is difficult to decide what the correct probability to place on various events is when looking at the problem from the inside, but easy to pick an AI design that would act in service of any particular objective when looking at the problem from the outside.
Perception from within the agent frame: A human emphasizes an internal mode of problem solving over an external mode due to putting themselves "into the shoes" of a perceived unchanging decision algorithm within a machine.
Reality: External-mode problem solving is also feasible.
Fundamental misperception due to the agent frame: Over-emphasis of internal mode problem solving.
Machines looking at themselves as agents
Pitfall 8: Confusion about fallibility
An AI programmed to model itself using an explicit agent model might notice that its actions do not always match those predicted by its self-model. In fact this is due to a discrepancy between the AI’s model of itself, which predicts that its actions will be a function of its perceptions, and its real-world implementation, which involves physics sensors, actuators, and computing hardware that take time to process information and are subject to errors. Due to the inability of the agent model to capture the physicality of the AI’s computing hardware, the AI might develop false explanations for the discrepancy between its prediction of its own actions and those observed. In particular it is likely to explain these discrepancies as caused by features of the environment, since the environment contains most of the free parameters within the agent model.
Perception from within the agent frame: An AI’s actions have a purely functional relationship to its perceptions, and any discrepancy with respect to this assumption must be due to some feature of the environment.
Reality: All machines are physical entities and are at best approximated as functions from percepts to actions.
Fundamental misperception due to the agent frame: Any non-functional aspect of the AI’s behavior must be a feature of the environment
Pitfall 9: Difficulty modifying own hardware
An AI programmed to model itself using an explicit agent model may have difficulty making changes and upgrades to its own hardware. As the AI entertains actions that might modify its own hardware, an AI relying on the agent model may not fully account for all of the consequences of its actions since the AI will not expect its actions to affect its own core decision algorithm due to the fixed policy assumption. As mentioned previously, one might imagine certain "quick fixes" to the agent model that permit actions that directly change the agent’s decision algorithm, but in fact this is more challenging than it may seem, since the fixed policy assumption is core to many of the basic search and learning strategies that underlie contemporary AI theory.
Perception from within the agent frame: Actions will not change the AI’s own decision algorithm
Reality: The AI’s decision algorithm is represented within physical memory units and is executed on a physical computer, both of which can be affected by the AI’s actions.
Fundamental misperception due to the agent frame: There is an unchanging internal decision algorithm within the AI that is not subject to change because it is not part of the environment.
Machines looking at humans as agents
Pitfall 10: Looking for fixed values
Consider an AI that is programmed to \ infer a value function that explains observed human behavior and then take actions in service of this inferred human value function. An AI programmed this way would assume that humans have values that are fixed over time, due to the view of an unchanging decision algorithm within humans. This may cause such an AI to incorrectly extrapolate current values to future values. This would fail, for example, when modelling children whose decision algorithms will evolve significantly as they grow, or when observing adults experiencing significant life changes. Upon observing humans who are in fact changing over time, the AI may be forced into an explanation that posits an unchanging value function, in which case the AI may form an incorrect view of human values and take undesirable actions.
Perception from within the agent frame: Human behavior can be explained by an unchanging internal decision algorithm.
Reality: Humans change over time.
Fundamental misperception due to the agent frame: Human values are fixed.
Pitfall 11: Incomprehensibility of corrigibility
A human engineer may wish to construct an AI that can be modified after it has been deployed, in case the human identifies mistakes in the AI’s design. But an AI programmed to model itself as an agent will have difficulty understanding the intentions of a human trying to modify the AI, since from within the agent frame the AI’s internal decision algorithm is not changeable. The human’s behavior may appear bizarre or incomprehensible to the AI.
Perception from within the agent frame: Human actions that are in fact intended to modify the AI’s internal decision algorithm appear incomprehensible since the AI views its internal decision algorithm as immutable.
Reality: A human might want to modify the AI’s internal decision algorithm
Fundamental misperception due to the agent frame: The AI’s internal decision algorithm is unchanging so it cannot be the intent of any other entity to modify it.
Machines looking at other machines as agents
Pitfall 12: Bias towards conflict
An AI interacting with other AIs in pursuit of a goal will need to decide when to negotiate with entities that oppose it and when to fight with such entities. We expect there to be scenarios in which negotiation is the strategy we would wish for the AI to take and other scenarios in which fighting is the strategy we would wish for the AI to take, but an AI programmed to use the agent model to understand other AIs may be suboptimally biased towards fighting, for the following reason. The AI being perceived through the frame of the agent model may be seen as having a decision algorithm that gives it the capacity to choose its actions on the basis of negotiation. But some aspects of this other AI’s behavior may be perceived as a fixed consequence of the unchanging decision algorithm perceived within this other AI. This means that an AI using the agent model to understand other AIs may choose conflict in cases where it perceives these fixed aspects of the other AI’s behavior as being opposed to its own goals. In some cases it may be true that the other AI was incapable of overturning aspects of its programming. But in other cases the other AI may have in fact been capable of and willing to negotiate, and the decision to choose conflict over negotiation was due to a fundamental misperception due to use of the agent model.
Perception from within the agent frame: Some aspects of another entity’s behavior is attributable to a fixed internal decision algorithm and cannot be modified by the other entity even if it wanted to, so negotiations concerning these behaviors are futile.
Reality: Other entities may have the capacity to modify their behavior at ever level
Fundamental misperception due to the agent frame: Some aspects of other entities’ behavior are fixed consequences of an unchanging internal decision algorithm and must be fought.
Summary of the pitfalls
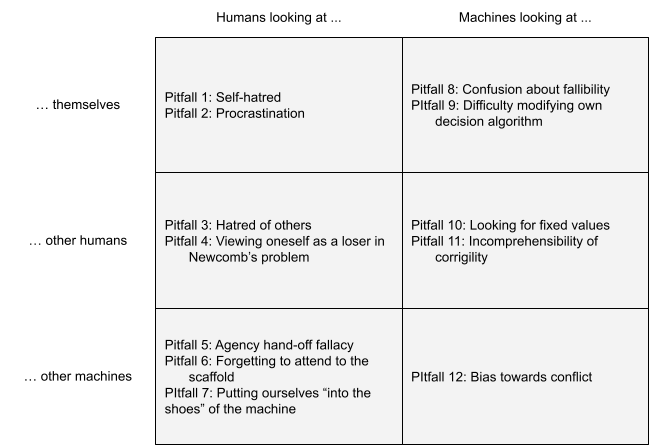
Connections to other research
Scott Garrabrant and Abram Demski have written about the novel challenges that arise when designing agents that are part of the world rather than outside the world in the Embedded Agency [? · GW] sequence. Garabrandt and Demski note that any real-world agent we might build would necessarily be part of the world in which it is deployed, and that we have little understanding of how to think about agency under these conditions. They identify four ways that embedded agency differs from non-embedded agency: that embedded agents lack predefined input/output channels between self and world, that embedded agents cannot conceivably fit a complete model of the whole world into their minds because their minds are physically smaller than the world, that embedded agents must consider the consequences of actions that might modify the agent itself, and that embedded agents are constructed out of the same fundamental parts as the world. The present critique of the agent model was very much inspired by this work. Rather than adapting the agent model to the embedded domain, my sense is that we should be seeking a post-agent model with which to understand entities that exert influence over the future.
I have not yet read Garrabrant’s sequence on cartesian frames, so cannot comment on its connections to the present work, which I expect to be numerous.
Abram Demski has described a concept he calls Partial Agency [LW · GW], in which an agent uses some but not all channels of influence to shift the world towards its objective. For example, an agent predicated upon causal decision theory does not attempt to exert influence over the world via the actions resulting from the predictions made by other agents about its decisions. This channel of influence is available to the agent, but its architecture is such that it does not consider making use of them. He compares this to "full agency", in which an agent does consider all affordances available to it. Both partial agency and full agency appear to be situated within the agent frame as I have described it in this essay, since they both view entities that exert influence over the future through the frame of an abstract algorithm processing observations and generating actions.
In Deconfuse Yourself About Agency [LW · GW], Vojta Kovaric attempts to make progress on the question of which entities in the world we should take to be agents, and then introduces three questions as directions for further research on agent fundamentals. Kovaric introduces the notion of A-morphization, in which we model some entity as a particular parametrization of a certain architecture A. He says that if the best model of some entity is an A-morphization, and if A is an agent-like architecture, then we may call the entity an agent. But this just begs the question of how we determine whether A is an agent-like architecture. On this, Kovaric simply notes that different people will see different architectures as being agent-like. Of particular interest is the following question posed at the end of the article: Is there a common fundamental physical structure or computation behind all agent-like behavior? Overall I see this piece as working primarily from within the agent frame.
Laurent Orseau, Simon McGill, and Shane Legg have published Agents and Devices: A Relative Definition of Agency, in which they describe the construction of a classifier that assigns probabilities to whether an object is a device or an agent. A device is taken to be something that operates according to a mechanistic input-output mapping, and is modelled formally by the authors using the speed prior (a fast computable approximation to the Solomonoff prior). An agent is something we model as having beliefs and making decisions according to an objective function. The authors assume that some set of possible utility functions are given (in the experiments they are goals of reaching certain labelled points in a maze), then use inverse reinforcement learning with a switching prior to perform inference on which goal might have been sought at which time. Having done this, they can compare the hypothesis that a certain object is a device to the hypothesis that it is an agent. This work is of great value from the perspective of the present essay as a fully fleshed-out operationalization of what exactly the agent model entails.
The field of embodied cognition views human cognition as deeply dependent on the body. A related field, embedded cognition, views human cognition as deeply dependent on the natural and social environment in which an organism is immersed. This large field is highly abstract, draws on ideas from continental philosophy, and seems difficult to penetrate, yet due to its focus on cognitive processes that are embedded in the physical world may contain insights of interest to the development of a post-agency understanding of intelligent systems. Of particular interest for a follow-up post is Rodney Brooks’ work on the subsumption architecture and "intelligence without representation".
Conclusion
The agent model is an exceptionally powerful model, and for this reason it is the primary model with which we have chosen to understand the entities on this planet that exert greatest influence over the future. It is precisely because of the power of this model that we have come to rely upon it so heavily. But when we use one frame to the exclusion of all others, we may forget that we are using a frame at all, and begin to accept the confines of that frame as a feature of reality itself, not as a temporarily and voluntarily adopted way of seeing.
I believe this has happened with the agent model. It seems to me that we are so acquainted with the agent model that we have lost track of the ways that it is shaping our view of reality. As we build advanced AI systems, we should carefully examine the pros and cons of the frames that we use, including the agent model, or else we may miss whole regions of the design space without noticing. In this essay I have attempted to lay out some of the pitfalls of using the agent model.
This is one of the most confusing things about conceptual work in the field of AI. This field is unique among all engineering disciplines in that the object of our engineering efforts has the potential to itself use frames of its own as it perceives the world. As Eiliezer wrote about repeatedly in the sequences, it is critical to be extremely clear about what is a frame that we are using to think about building an AI, and what is a frame being used by an AI to think about take action in the world. ↩︎
At least not if the value function was permitted to change arbitrarily between each step. Perhaps IRL could be made to work with a changing value function given some constraints on its rate of change, but classical IRL does not handle this case. ↩︎
5 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2021-05-10T20:03:18.328Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
Replies from: alexflintIt is common to view AI systems through the “agent lens”, in which the AI system implements a fixed, unchanging policy that given some observations takes some actions. This post points out several ways in which this “fixed, unchanging policy” assumption can lead us astray.
For example, AI designers may assume that the AI systems they build must have unchanging decision algorithms, and therefore believe that there will be a specific point at which influence is “handed off” to the AI system, before which we have to solve a wide array of philosophical and technical problems.
↑ comment by Alex Flint (alexflint) · 2021-05-10T21:55:58.133Z · LW(p) · GW(p)
Seems good to me Rohin.
comment by Gordon Seidoh Worley (gworley) · 2021-05-15T19:57:28.723Z · LW(p) · GW(p)
Somewhat ironically, some of these failures from thinking of oneself or others as agents causes a lack of agency! Maybe this is just a trick of language, but here's what I have in mind from thinking about some of the pitfalls:
- Self-hatred results in less agency (freedom to do what you want) rather than more because effort is placed on hating the self rather than trying to change the self to be more in the desired state.
- Procrastination is basically the textbook example of a failure of agency.
- Hatred of others is basically the same story here as self-hatred.
On the other hand, failing at Newcomb's problem probably feels like you've been tricked or duped out of your agency.
Anyway this has got me thinking about the relationship between agents and agency. Linguistically the idea here is that "agency" means to act "like an agent" which is to say someone or something that can choose what to do for themselves. I see a certain amount of connection here to, for example, developmental psychology, where greater levels of development come from less thinking of oneself as a subject (an agent) and more thinking of the things one does as object and so thinking of oneself less as subject/agent results in greater agency because the range of things one allows oneself to consider mutable is greater.
This also suggests an end state where there's no agent model at all, or at least not one that is held to tightly (it's one of many lenses through which to see the world, and the agent lens is now totally optional rather than partially optional).
Replies from: alexflint↑ comment by Alex Flint (alexflint) · 2021-05-15T23:49:22.804Z · LW(p) · GW(p)
Somewhat ironically, some of these failures from thinking of oneself or others as agents causes a lack of agency! Maybe this is just a trick of language, but here's what I have in mind from thinking about some of the pitfalls:
Yeah right, I agree with those three bullet points very much. Could also say "thinking of oneself or others as Cartesian agents causes a lack of power". Does agency=power? I'm not sure what the appropriate words are but I agree with your point.
I see a certain amount of connection here to, for example, developmental psychology, where greater levels of development come from less thinking of oneself as a subject (an agent) and more thinking of the things one does as object and so thinking of oneself less as subject/agent results in greater agency because the range of things one allows oneself to consider mutable is greater.
Yeah, that seems well said to me. This gradual process of taking more things as object seems to lead towards very good things. Circling, I think, has a lot to do with taking the emotions we are used to treating as subject and getting a bit more of an object lens on them just by talking about them. Gendlin's focussing seems to have a lot to do with this, too.
This also suggests an end state where there's no agent model at all, or at least not one that is held to tightly
Yeah right, it's a great lens to pick up and use when its helpful. But nice to know that it's there and also to be able to put it down by choice.
comment by Mateusz Bagiński (mateusz-baginski) · 2024-11-10T13:59:43.126Z · LW(p) · GW(p)
I directionally agree with the core argument of this post.
The elephant(s) in the room according to me:
- What is an algorithm? (inb4 a physical process that can be interpreted/modeled as implementing computation)
- How do you distinguish (hopefully, in a principled way) between (a) an algorithm changing; (b) you being confused about what algorithm the thing is actually running and in reality being more nuanced so that what "naively" seems like a change of the algorithm is "actually" a reparametrization of the algorithm?
I haven't read the examples in this post super carefully, so perhaps you discuss this somewhere in the examples (though I don't think so because the examples don't seem to me like the place to include such discussion).