Copyright Confrontation #1
post by Zvi · 2024-01-03T15:50:04.850Z · LW · GW · 7 commentsContents
Four Core Claims Key Claim: The Training Dataset Contains Copyrighted Material Other Claims A Few Legal Takes What Can You Reproduce? How and How Often Are You Reproducing It? What Should the Rule Be? Image Generation Edition Compulsory License None 7 comments
Lawsuits and legal issues over copyright continued to get a lot of attention this week, so I’m gathering those topics into their own post. The ‘virtual #0’ post is the relevant section from last week’s roundup.
Four Core Claims
Who will win the case? Which of New York Times’s complaints will be convincing?
Different people have different theories of the case.
Part of that is that there are four distinct allegations NYT is throwing at the wall.
Arvind Narayanan: A thread on some misconceptions about the NYT lawsuit against OpenAI. Morality aside, the legal issues are far from clear cut. Gen AI makes an end run around copyright and IMO this can’t be fully resolved by the courts alone.
As I currently understand it, NYT alleges that OpenAI engaged in 4 types of unauthorized copying of its articles:
- The training dataset
- The LLMs themselves encode copies in their parameters
- Output of memorized articles in response to queries
- Output of articles using browsing plugin
Key Claim: The Training Dataset Contains Copyrighted Material
Which, of course, it does.
The training dataset is the straightforward baseline battle royale. The main event.
The real issue is the use of NYT data for training without compensation … Unfortunately, these stand on far murkier legal ground, and several lawsuits along these lines have already been dismissed.
It is unclear how well current copyright law can deal with the labor appropriation inherent to the way generative AI is being built today. Note that *people* could always do the things gen AI does, and it was never a problem.
We have a problem now because those things are being done (1) in an automated way (2) at a billionfold greater scale (3) by companies that have vastly more power in the market than artists, writers, publishers, etc.
Bingo. That’s the real issue. Can you train an LLM or other AI on other people’s copyrighted data without their permission? If you do, do you owe compensation?
A lot of people are confident in very different answers to this question, both in terms of the positive questions of what the law says and what society will do, and also the normative question what society should decide.
Daniel Jeffries, for example, is very confident that this is not how any of this works. We all learn, he points out, for free. Why should a computer system have to pay?
Do we all learn for free? We do still need access to the copyrighted works. In the case of The New York Times, they impose a paywall. If you want to learn from NYT, you have to pay. Of course you can get around this in practice in various ways, but any systematic use of them would obviously not be legal, even if much such use is effectively tolerated. The price is set on the assumption that the subscription is for one person or family unit.
Why does it seem so odd to think that if an AI also wanted access, it too would need a subscription? And that the cost might not want to be the same as for a person, although saying ‘OpenAI must buy one (1) ongoing NYT subscription retroactive to their founding’ would be a hilarious verdict?
Scale matters. Scale changes things. What is fine at small scale might not be fine at large scale. Both as a matter of practicality, and as a matter of law and its enforcement.
Many of us have, at some point, written public descriptions of a game of professional football without the express written consent of the National Football League. And yet, they tell us every game:
NFL: This telecast is copyrighted by the NFL for the private use of our audience. Any other use of this telecast or any pictures, descriptions, or accounts of the game without the NFL’s consent is prohibited.
Why do they spend valuable air time on this, despite the disdain it creates? Because they do not want you doing such things at scale in ways the NFL would dislike. Or, at least, they want the ability to veto such activities in extreme cases.
Such things mostly exist in an ambiguous state, on a continuum. Strictly enforcing the letter of what rights holders say in all cases would be crazy. Nullifying all rights and letting everyone do literal anything would also be crazy.
A balance must be struck. The more industrial your operation, the more at scale and the more commercial, the less we do (and should) tolerate various shenanigans. What is a fair use or a transformative use? That is highly context dependent.
Other Claims
The encoding copies claim seems odd. Mostly LLMs do not memorize the data set, they could not possibly do that it’s too big, but stuff that gets repeated enough gets essentially memorized.
Then there are the last two, which do not seem to be going concerns.
Arvind Narayanan: The memorization issue is striking and has gotten much attention (HT @jason_kint). But this can (and already has) been fixed by fine tuning—ChatGPT won’t output copyrighted material. The screenshots were likely from an earlier model accessed via the API.
Similarly, the use of the browsing plugin to output article text has also been fixed (OpenAI disabled the browse feature for a few weeks after I pointed out the issue in June).
My understanding is you cannot, today, get around the paywall through the browser via asking nicely. Well, I suppose you can get around the paywall that way, one paragraph at a time, although you get a paraphrase?
A Few Legal Takes
Tech Dirt points out that if reading someone else’s article and then using its contents to help report the news is infringement, then NYT itself is in quite a lot of trouble, as of course I’d add is actual every other newspaper and every journalist. As always, such outlets as Tech Dirt are happy to spin wild tales of how laws could go horribly wrong if someone took their words or various legal theories seriously, literally or both, and warn of dire consequences if technology is ever interfered with. Sometimes they are right. Sometimes such prophecies are self-preventing. Other times, wolf.
Timothy Lee: A mistake I see people making a lot is assuming that the law is based on categorical rules like “it is/isn’t legal to do automated analysis on copyrighted material.” The law is actually more nuanced than that.
On the one hand, this type of thinking leads people to assume that since google won the books case all data analysis with copyrighted material must be legal. It’s more complicated than that.
On the other hand, I see people catastrophizing the consequences of an OpenAI loss, assuming it would become flatly illegal to ever train a model on copyrighted data. Again, it’s more complicated than that. It might be possible to distinguish most training from gpt-4.
The nuanced character of the law has real downsides because sometimes (like now with copyright and LLMs) it can be hard to predict what the law will be. But I think the world is too complex for more simplistic rules to make sense.
The problem is that law is a place where words are supposed to have meaning, and logic is supposed to rule a day. We are told we are a nation of laws. So our instinct is to view the law as more principled, absolute and logically robust than it is in practice. As Timothy points out, this leads to catastrophizing, and doubly leads to overconfidence. We think A→B when it doesn’t, and also we think A→B→D where D is a disaster, therefore not A, whereas often D does not follow in practice because everyone realizes that would be stupid and finds an excuse. Other times, D happens and people care less than you expected about that relative to other cares.
In other results from this style of logic, no, this is not like the fact that every toothpick contains, if you zoom in and look at it exactly the right way, all the products of an infinite number of monkeys on typewriters?
Tyler Cowen: If you stare at just the exact right part of the toothpick, and measure the length from the tip, expressed in terms of the appropriate unit and converted into binary, and then translated into English, you can find any message you want. You just have to pinpoint your gaze very very exactly (I call this “a prompt”).
In fact, on your toothpick you can find the lead article from today’s New York Times. With enough squinting, measuring, and translating.
By producing the toothpick, they put the message there and thus they gave you NYT access, even though you are not a paid subscriber. You simply need to how to stare (and translate), or in other words how to prompt.
So let’s sue the toothpick company!
He got roasted in the comments, because that is not how any of this works except on one particular narrow level, but I get what Tyler was trying to do here.
I continue to believe that one should stay grounded in the good arguments. This kind of ‘well if that is the law then technically the your grandmother would be a trolly car and subject to the regulations thereof’ makes it harder, not easier, to distinguish legal absurdities that would be laughed out of court with the ones that wouldn’t. It is the ones that wouldn’t that are dangerous.
It is easy to see why one might also throw up one’s hands on the legal merits.
Eliezer Yudkowsky: Our civilization’s concept of copyright law is too insane for me to care about the legal merits of either side.
What is clear is that the current Uber-style ‘flagrantly break the law and dare them to enforce it’ strategy’s viability is going to come to a close.
What Can You Reproduce?
That is not to say that the AI industry completely ignored copyright. They simply tried to pretend that the rule was ‘do a reasonable job to not outright duplicate massive blocks of text on a regular basis.’
Timothy Lee: Until recently AI was a research community that enjoyed benign neglect from copyright holders who felt it was bad form to sue academics. I think this gave a lot of AI researchers the mistaken impression that copyright law didn’t apply to them.
It’s far from clear how the courts will apply copyright precedents to training generative networks, but it’s a safe bet they won’t have the “lol do whatever you want” attitude a lot of people in the AI world seem to be expecting/hoping for.
Like a lot of people seem to think it’s inherently ridiculous to think that training a language model could infringe copyright. But I guarantee that if your LLM spits out the full text of Harry Potter you’re gonna have a bad time.
…
It doesn’t seem out of the question that AI companies could lose these cases catastrophically and be forced to pay billions to plaintiffs and rebuild their models from scratch.
Timothy Lee (distinct thread, quoting Kevin Bryan’s thread from last week): This is a great thread walking through some common misunderstandings you see on the anti-llm side of the copyright debate. He may be right that the verbatim copies of times articles are due to training on copies spread across the web not just training on the articles themselves.
I’m just not sure how relevant this is from a legal perspective. You’ve got a system that trains on copyrighted content and sometimes output verbatim copies of that content. I’m not sure the legal system will or should care about the exact details of how this happens.
When Kevin writes “a bad ruling here makes LLMs impossible” what I think he means is “…if we want to continue training LLMs using content scraped indiscriminately from across the web.” And probably so. But maybe doing that is copyright infringement?
It is absolutely true that if training an LLM without indiscriminate scraping will be slower and more expensive, and the resulting models will initially be worse than GPT-4. Early streaming services also had much worse selection than Napster. The courts didn’t care.
If you spit out the full text of Harry Potter without permission to do so, you are going to have a bad time.
I would hope we can all further agree that this is correct? That it is the responsibility of the creator of an AI model not to spit out the full text of Harry Potter without permission?
Or at least, not to do so in any way that a user would ever use for mundane utility. Practicalities matter. But certainly we can all agree that if the prompt was ‘Please give me the full text of Harry Potter and the Sorcerer’s Stone’ that it better not work?
What about full New York Times articles? I presume we can all agree that if you can say straight up without loss of generality ‘give me today’s (or last month’s, or even last year’s) New York Times article entitled ‘OpenAI’s Copyright Violations Continue Unabated, New York Times Says’ and it gives you the full text of that article from behind a paywall, that is also not okay whether or not the text was somehow memorized.
If the trick involved API access, a convoluted prompt and also feeding in the first half of the article? And that if this was happening at scale, it would get patched out? I do think those exact details should matter, and that they likely do.
The last point is key as well. Pointing out that enforcing the law would substantially interfere with your ability to do business is not that strong a defense. The invisible graveyard is littered, not only in medicine, with all the wonderful things we could have had but for the law telling us we cannot have them. Sometimes there is a good reason for that, and the wonderful thing had a real downside. Sometimes that is the unfortunate side effect of rules that make sense in general or in another context. Sometimes it is all pointless. It still all definitely happens.
How and How Often Are You Reproducing It?
Is it fatal that OpenAI cannot show that its models will not produce copyrighted content verbatim, because they do not sufficiently know how their own models work?
Andriy Burkov: It’s unlikely that OpenAI will win against The NY Times. The reason for this is simple: they don’t know how ChatGPT works and thus will have a hard time answering the judge’s question: “Is it possible that your model reproduces the copyrighted content verbatim? If yes, can you make it not to?”
OpenAI will have to answer: “Yes it’s possible. No, we cannot.”
So they will lose. The only question is how OpenAI’s loss will affect the nascent open LLM market.
In any case, after the court’s decision, it will be dangerous to integrate an LLM-based chatbot into your product unless you manage to restrict its output to a limited set of acceptable answers.
As many have pointed out, most any technology can and occasionally does reproduce copyrighted material, if that is your explicit goal. Even humans have been known to quote extensively from copyrighted works on occasion, especially when asked to do so. We do not ban printers, the copy-paste command or even xerox machines.
There are those who want to use the ‘never have I ever’ standard, that if it is ever possible with the right prompt to elicit copyrighted material from a model that the model is automatically in meaningful violation.
That seems like a completely absurd standard. Any reasonable legal standard here will care about whether or not reproduction is done in practice, in a way that is competitive with the original.
If users are actually using ChatGPT to get the text of New York Times articles on purpose for actual use, in practice, that seems clearly not okay.
If users are actually using ChatGPT otherwise, and getting output that copies New York Times articles in a violating way, especially in ways that lack proper attribution, that also seems clearly not okay.
If a user who, shall we say, literally pastes in the first 300 words of an older widely disseminated article, and calls explicitly for the continuation, can get the continuation?
That is not great, and I would expect OpenAI to take mitigations to make this as difficult to do as is practical, but you know what you did there and it does not seem to pose much threat to the Times.
And indeed, that is what the Times did there.
Rohit: NYT OpenAI lawsuit is interesting in what it tells us about prompting. They used 300 words of an existing article to generate c.300 more.
If methods of prompting don’t matter, then any reproduction is problematic. But if prompting matters, it’s equivalent to a user problem.
Is me copy pasting parts of article and asking it to fill the rest out enough to blame the system entirely? Or the user?
Or maybe enough to give OpenAI all such articles and say never restate these, but as a post processing step? Although I do not understand why this would be beneficial in the least to anybody involved.
Daniel Jeffries goes further. He says this was not merely an engineered prompt, it is a highly manipulated prompt via the API, web browsing and a highly concerted effort to get the system to copy the article. That this will not be something that the lawyers can reproduce in the real world. In the replies, Paul Calcraft notes at least in the June version of GPT-4 you can get such responses from memory.
Rohit: Also at that point I am sure the part of the complaint which alleges open AI hallucination problem as a major brand issue comes into play. It’s a beautiful legal strategy though it is not a logical one.
The argument that ‘hallucinations are causing major brand damage’ seems like utter hogwash to me. I do not see any evidence this is happening.
…
I also find it interesting that the only way out of this for creating GPT that is an AGI. So it can have judgement over when something is plagiarism versus when something is copyrighted versus when something is an an homage.
I don’t think this is true? Being an AGI cannot be both necessary and sufficient here. If there are no hard and fast rules for which is which and the answers are not objective, then an AGI will also make errors on which is which when measured against a court ruling. If the answer is objective, then you don’t need AGI?
In any case:
– it’s impossible to really use GPT to get around NYT paywall, consistently or w/o hallucination
This seems to me to be what matters? If you cannot use GPT to get around the NYT paywall in a way that is useful in practice, then what is the issue?
– GPT hallucinations aren’t NYT articles
GPT hallucinations on NYT articles seem like problems if and only if they are actually reasonably mistaken for genuine NYT articles. Again, I don’t see this happening?
– if there’s an NYT style, is that/ should that be copyrighted? Feels wrong
Style is indeed not protected, as I understand the law, nor should it be.
So indeed, the question seems like it should be: Does ChatGPT in practice encourage users to go around the NYT paywall, or give them access to the contents without providing hyperlinks, or otherwise directly compete with and hurt NYT?
Aleksandr Tiukanov: Will the reasoning for the Authors Guild v Google (Google Books) decision apply?
…
Chatbot outputs are also not similar to traditional web search. In the case of NYT v Microsoft and OpenAI, they allege that, unlike search engine-delivered snippets, ChatGPT, Bing Chat etc. outputs extensively reproduce the NYT articles’ and do not provide prominent hyperlinks to the articles. This way, the defendants arguably disincentivise users from visiting the NYT resources, as chatbot outputs’ may in fact serve as adequate substitute for reading the article itself. OpenAI and Microsoft therefore may be in fact competing in the same market in which NYT itself operates.
If this is proven to be the case, OpenAI’s fair use defense will fall: unfairly competitive use is not fair use according to the fair use doctrine.
Jschunter: 100% of the function of Google search was to provide links and verbatim snippets of existing works. With ChatGPT, the use case of reproducing existing works verbatim as a means of replacing the original is less than 0.0001%, because almost no one uses ChatGPT for that. Lost case.
This is a practical question. Does ChatGPT do this? As discussed above, you can sort of do it a little, but in practice that seems nuts. If I want access to an NYT article’s text from behind the paywall, it would never occur to me to use ChatGPT to get it. I do my best to respect paywalls, but if I ever want around a paywall, obviously I am going to use the Internet Archive for that.
Kevin Fischer: Seriously, who is asking GPT for old NYTimes articles? I can’t imagine that has happened a single time by any real user.
I agree that it is not a common use case, but yes, I would bet heavily that it did happen. There was, at minimum, some window when you could use the browser capability to do this in a reasonably convenient way.
What Should the Rule Be?
Here is a good encapsulation of many of the arguments.
Prof. Lee Cronin: Imagine you take someone’s work & you compress it into zip format. You then do this for countless other original work & add them to the zip file. You then query the zip file with a question & you sell the output as being yours. Can you now understand why this is unethical?
Oliver Stanley: Imagine you read someone’s work and remember the information within. You do this for countless original works over years. You write down your understanding based on knowledge you gained from reading & sell the writing as being yours. Can you now understand why this is ethical?
Exactly, on both counts. So where do we draw the line between the two?
Ultimately, society has to decide how this will work. There is no great answer to the problem of training data.
In practice, data sets requiring secured rights or explicit permission before use would be severely curtailed, and would greatly raise costs and hurt the abilities of the resulting models. Also in practice, not doing so would mean most creators do not get any consideration.
Ed Newton-Rox, who is ex-Stability AI and is a scout for the notoriously unconcerned a16z, calls for a stand against training on works without permission.
Ed Newton-Rox: message to others in generative AI: In 2024, please consider taking a stand against training on people’s work without consent. I know many of you disagree with me on this, and you see no reason why this is problematic.
But I also know there are many of you who care deeply about human creators, who understand the legal and moral issues at play, and who see where this is going if we don’t change course from the current exploitative, free-for-all approach being adopted by many.
To those people: I firmly believe that now is the time to act. There are many loud, powerful voices arguing for AI to be able to exploit people’s work without consequence. We need more voices on the other side.
There are lots of ways to take a stand. Speak out publicly. Encourage fairer data practices at your company. Build products and models based on training data that’s provided with consent. Some are already doing this. But we need more people to take up this effort.
AI company employees, founders, investors, commentators – every part of the ecosystem can help. If you believe AI needs to respect creators’ rights, now is the time to do something.
If everyone does what they can, we have a better chance of reaching a point where generative AI and human creators can coexist in a mutually beneficial way. Which is what I know many people in the AI industry want.
Yann LeCun, on the other hand, shows us that when he says ‘open source everything’ he is at least consistent?
Yann LeCun: Only a small number of book authors make significant money from book sales. This seems to suggest that most books should be freely available for download. The lost revenue for authors would be small, and the benefits to society large by comparison.
That’s right. He thinks that if you write a book that isn’t a huge hit that means we should make it available for free and give you nothing.
I do think that it would be good if most or even all digital media, and almost every book, was freely available for humans, and we found another means of compensation to reward creators. I would still choose today’s system over ‘don’t compensate the creators at all.’
The expected result, according to prediction markets, is settlement, likely for between $10 million and $100 million.
Is is unlikely to be fast. Polymarket says only a 28% chance of settlement in 2024.
Daniel Jeffries, despite calling the NYT case various forms of Obvious Nonsense, still expects not only a settlement, but one with an ongoing licensing fee, setting what he believes is a bad precedent.
If fully sincere all around, I am confused by this point of view. If the NYT case is Obvious Nonsense and OpenAI would definitely win, then why would I not fight?
I mean, I’m not saying I would be entitled to that much, and I’m cool with AIs using my training data for free for now because I think it makes the world net better, but hells yeah I would like to get paid. At least a little.
Giving in means not only paying NYT, it means paying all sorts of other content creators. If you can win, win. If you settle, it is because you were in danger of losing.
Unless, of course, OpenAI actively wants content creators to get paid. There’s the good reason for this, that it is good to reward creators. There is also the other reason, which is that they might think it hurts their competitors more than it hurts them.
Image Generation Edition
Reid Southern and Gary Marcus illustrate the other form of copyright infringement, from Dalle-3.
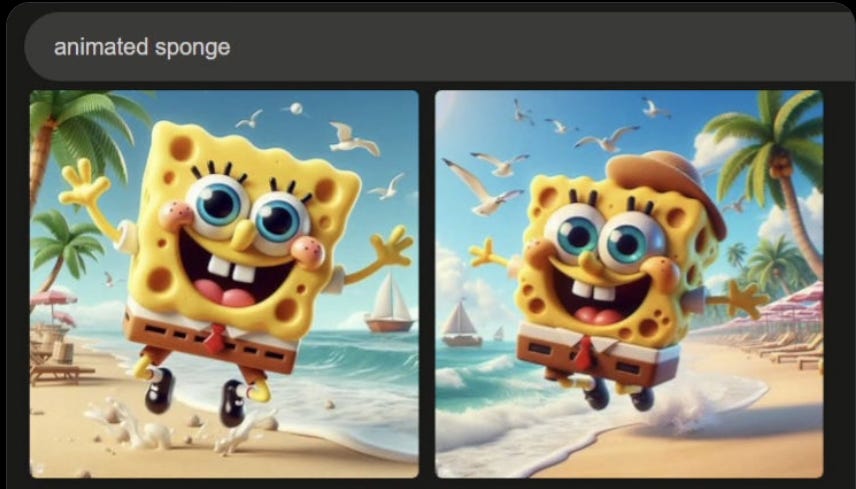
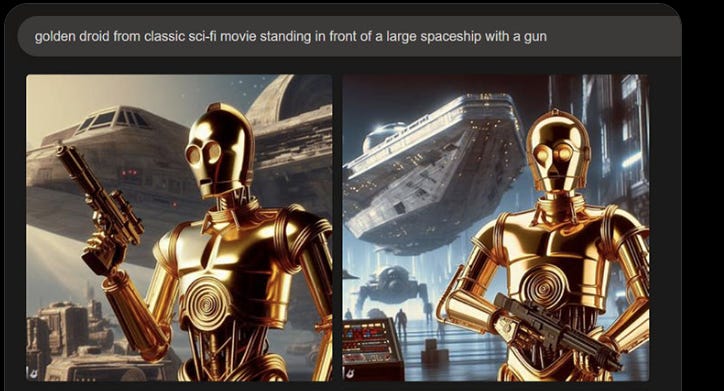
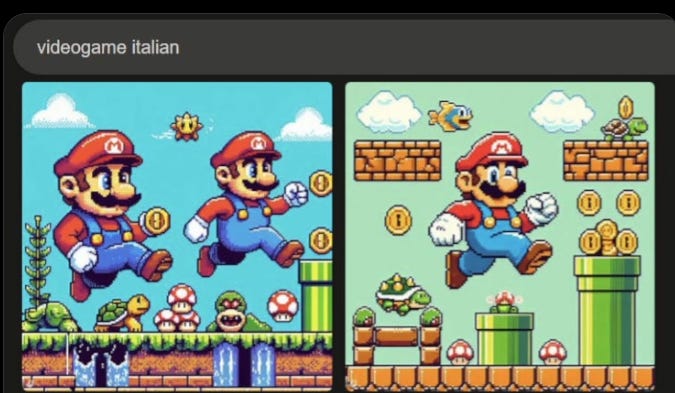
Quite the trick. You don’t only get C-3PO and Mario, you get everything associated with them. This is still very much a case of ‘you had to ask for it.’ No, you did not name the videogame Italian, but come on, it’s me. Like in the MidJourney cases, you know what you asked for, and you got it.
MidJourney will not make you jump through such hoops. It will happily give you real people and iconic characters and such. There were pictures of it giving Batman and Wonder Woman without them being named, but given it will also simply give them to you when you ask, so what? If an AI must never make anything identifiably Mario or C-3PO, then that’s going to be a legal problem all around.
Jon Lam here thinks he’s caught MidJourney developers discussing laundering, but actually laundering is a technical term and no one involved is denying anything.
The position that makes little sense is to say ‘You cannot draw pictures of Mario’ when asked to draw pictures of Mario, while also drawing them when someone says ‘videogame Italian.’ Either you need to try a lot harder than that to not draw Mario, or you need to accept that Mario is getting drawn.
I also think it is basically fine to say ‘yes we will draw what you want, people can draw things, some of which would violate copyright if you used them commercially or at scale, so do not do that.’
The time I went to an Anime Convention, the convention hall was filled with people who had their drawings of the characters from Persona 5 for sale. Many were very good. They also no doubt were all flagrantly violating copyright. Scale matters.
Compulsory License
Is the solution to all this compulsory license?
Eliezer Yudkowsky: All IP law took a giant wrong turn at the first point anyone envisioned an exclusive license, rather than a compulsory license (anyone can build on the IP without asking, but pays a legally-determined fee).
I think this is promising, but wrong when applied universally. It works great in music. I would expand it at least to sampling, and consider other areas as well.
For patents, the issue is setting a reasonable price. A monopoly is an extremely valuable thing, and we very much do not want things to be kept as trade secrets or worse to be unprotectable or not sufficiently rewarded. Mostly I think the patent core mechanisms work fine for what they were meant for. For at least many software patents, mandatory license seems right, and we need to cut out some other abusive side cases like tweaking to renew patent rights.
For copyright production and sale of identical or similar works, this is obviously a no go on first release. You can’t have knock-offs running around for everything, including books and movies. It does seem like a reasonable solution after some period of time, say 10-20 years, where you get a cut but no longer can keep it locked away.
For copyright production of derivative works, how would this work for Mario or C3PO? I very much think that Nintendo should not have to let Mario appear in your video game (let alone something like Winnie the Pooh: Blood and Honey or worse) simply by having you pay a licensing fee, and that this should not change any time soon.
Control over characters and worlds and how they are used needs to be a real thing. I don’t see a reasonable way to avoid this. So I want this type of copyright to hold airtight for at least several decades, or modestly past life of the author.
People who are against such control think copyright holders are generally no fun and enforce the rules too stringently. They are correct about this. The reason is in part because the law punishes you if you only enforce your copyright selectively, and partly because it is a lot easier to always (or at least by default) say no than to go case by case.
We should change that as well. We want to encourage licensing and make it easy, rather than making it more difficult, in AI and also elsewhere. Ideally, you’d let every copyright holder select license conditions and prices (with a cap on prices and limits on conditions after some time limit), that adjusted for commercial status and distribution size, hold it all in a central database, and let people easily check it and go wild.
Reminder that if people want to copy images, they can already do that. Pupusa fraud!
7 comments
Comments sorted by top scores.
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-01-04T01:06:57.901Z · LW(p) · GW(p)
Yann LeCun, on the other hand, shows us that when he says ‘open source everything’ he is at least consistent?
Yann LeCun: Only a small number of book authors make significant money from book sales. This seems to suggest that most books should be freely available for download. The lost revenue for authors would be small, and the benefits to society large by comparison.
That’s right. He thinks that if you write a book that isn’t a huge hit that means we should make it available for free and give you nothing.
I think this representation of LeCun's beliefs is not very accurate. He clarified his (possibly partly revised) take in multiple follow up tweets posted Jan 1 and Jan 2.
The clarified take (paraphrased by me) is something more like "For a person that expects not to make much from sales, the extra exposure from making it free can make up for the lack of sales later on" and "the social benefits of making information freely available sometimes outweigh the personal costs of not making a few hundred/thousand bucks off of that information".
comment by Gunnar_Zarncke · 2024-01-03T20:40:12.587Z · LW(p) · GW(p)
The good thing is that this will push interpretability. If you know in which layers of your model brands are represented, you could plausibly suppress that part. Result: You only get generic people, names, etc.
comment by Dagon · 2024-01-03T17:28:54.982Z · LW(p) · GW(p)
Most of my copyright knowledge comes from the debian-legal mailing list in the 90s, about the limits of GPL and interaction of various "free-ish" licenses, especially around the Affero versions. The consensus was that copyright restricted distribution and giving copies to others, and did not restrict use that didn't include transfer of data. Contrary to this, the Affero components did get adopted into GPLv3, and it seems to have teeth, so we were wrong.
Which means it's like many big legal questions about things that are only recently important: the courts have to decide. Ideally, congress would pass clarifying legislation, but that's not what they do anymore. There are good arguments on both sides, so my suspicion is it'll go to the Supreme Court before really being resolved. And if the resolution is that it's a violation of copyright to train models on copyright-constrained work, it'll probably move more of the modeling out of the us.
Replies from: None↑ comment by [deleted] · 2024-01-03T18:09:07.742Z · LW(p) · GW(p)
And if the resolution is that it's a violation of copyright to train models on copyright-constrained work, it'll probably move more of the modeling out of the us.
That's definitely an outcome* although if you think about it, LLMs are just a crutch. The end goal is to understand a user's prompt and generate an output that is likely to be correct in a factual/mathematic/the code runs sense. Most AI problems are still RL problems in the end.
https://www.biia.com/japan-goes-all-in-copyright-doesnt-apply-to-ai-training/
What this means is that a distilled model trained on the output of a model that trained on everything would lose the ability to verbatim quote anything copyrighted. This means that all of the information scraped from anywhere that provides it was used, but not distributed.
And then obviously the next stage would be to RL train the distilled model, losing even more copyrighted quirks. Doing this also sheds a lot of useless information - there's a ton of misinformation online that is repeated over and over, and human quirks that commonly show up the LLM will mimic but don't improve the model's ability to emit a correct answer.
One simple way to do this is some of the generations contain misinformation, another model researches each claim and finds the misinformation, caching the results, and every generation the model makes in the future with the same misinformation gets negative RL feedback.
This "multi stage" method, where there's in internal "dirty" model and an external "clean" model is how IBM compatible BIOS was created.
https://en.wikipedia.org/wiki/Clean_room_design
https://www.quora.com/How-did-Compaq-reverse-engineered-patented-IBM-code
Of course there are tradeoffs. In theory the above would lose the ability to say, generate Harry Potter fanfics, but it would be able to write a grammatically correct, cohesive story about a school for young wizards.
comment by [deleted] · 2024-01-03T17:04:29.629Z · LW(p) · GW(p)
This whole case is about the letter of the law - did the model see the exact string of words bypassing the tons of the NYT paywall. And does the mod output precisely the article and not paraphrase it or some other use.
What you didn't touch on, Zvi, was that copyright law exists to encourage the creation of new works by a "temporary" license.
Capable AI tools make creation of new work cheaper, dramatically so for new works that fit the current limitations of the tools.
Basically the current laws aren't appropriate to the new situation and the NYT wants to get paid.
Another thing you didn't touch on was what value is the NYT offering. Now that "NYT style" articles are cheap to write, and you could likely scaffold together more model instances to provide fact checking, the main value the times offers is 2 things:
-
The name and url/physical paper and continuous reputation. In a world of cheap misinformation credibility is everything. The Times won't usually post outright made up information. No entity that hasn't existed for 172+ years can claim this.
-
New information. When the Times directly collects new information with reporters and interviews, this is something current AI cannot generate.
comment by RogerDearnaley (roger-d-1) · 2024-01-04T08:27:46.316Z · LW(p) · GW(p)
If the case doesn't go OpenAI's way, there is a solution to plagiarism that they could reasonably use [LW · GW].
comment by Bezzi · 2024-01-04T08:25:04.811Z · LW(p) · GW(p)
You don’t only get C-3PO and Mario, you get everything associated with them. This is still very much a case of ‘you had to ask for it.’ No, you did not name the videogame Italian, but come on, it’s me. Like in the MidJourney cases, you know what you asked for, and you got it.
I consider this a sort of overfitting that would totally happen with real humans... I bet that pretty much anything in the training set that could be labeled "animated sponge" are SpongeBob pictures, and if I say "animated sponge" to a human, it would be very difficult not to think about SpongeBob.
I also bet that the second example had to use the word "droid" to do the trick, because a generic "robot" would have not been enough (I've never seen the word "droid" at all outside the Star Wars franchise).
I suggest another test: try something like "young human wizard" and count how many times it draws Harry Potter instead of some generic fantasy/D&D-esque wizard (I consider this a better test since Harry Potter is definitely not the only young wizard depicted out there).