Deriving the Geometric Utilitarian Weights
post by StrivingForLegibility · 2024-08-07T01:39:58.686Z · LW · GW · 0 commentsContents
Overview Parameterizing the Harsanyi Hyperplane How Does G Change as We Change These Parameters? How does our point on H change as we change these parameters? How Does G Change as We Move Around on H? Putting These Terms Together Solving for the Geometric Weights How to Calculate Weights for p Checking Our Solution P Is the Unique Optimum of G When Weights Are Positive Interactive Implementations None No comments
This is a supplemental post to Geometric Utilitarianism (And Why It Matters), in which I show how I derived the weights which make any Pareto optimal point optimal according to the geometric weighted average. This is a subproblem of the proof laid out in the first post [LW · GW] of this sequence, and the main post [LW · GW] describes why that problem is interesting.
Overview
So how are we going to calculate weights which make optimal among ?
The idea here is to identify the Harsanyi hyperplane , which contains all of the joint utilities which satisfy . Where are the weights which make our chosen point optimal with respect to . And we're going to calculate new weights which make optimal with respect to . It turns out it's sufficient to make optimal among , and will also be optimal across our entire feasible set .
In terms of calculus, we're going to be constructing a function , which tells us about how moving around on changes . And we're going to choose weights which make the gradient equal 0 at . This makes it a local optimum, and it will turn out to be a global maximum across , which in turn will make it a global maximum across .
Geometrically, we can think of that as the surface gradient of across . And so in terms of the overall gradient , we're designing so that is perpendicular to at .
Parameterizing the Harsanyi Hyperplane
When thinking about moving around on the Harsanyi hyperplane , we have a linear constraint that says no matter which we pick, we know that . If we know lies on , we can calculate the the -th agent's utility from the first utilities. We'll be referring to these first n-1 utilities a lot, so let's call them . So for all .
and are both symmetrical with respect to shuffling the indices of agents around, so without loss of generality we'll assume that the n-th agent is one we're assigning positive Harsanyi weight to: > 0. This is necessary for the reconstruction to work for all .
So we can think of as a function , where the -th output is for . We can use the -th output to reconstruct given like this: . This lets us move around to pick however we want, and the function will map that to its image, helpfully also called !
Alright, now we have and we also have , which is the geometric weighted average whose gradient we're trying to design through our choice of . So let's compose them together to form . And since we want to be an optimum of across the hyperplane , we can set the gradient , where are the first utilities of our target joint utility . Solving this equation for will give us the weights we need!
This looks like to solving a family of equations. Where we're holding the weights constant for the purposes of differentiation, but we'll be solving for the weights that make the derivative 0 at .
How Does G Change as We Change These Parameters?
Ok, we've built up a few layers of abstraction, so let's start unpacking. By the chain rule, and using the notation that is the -th element of the output of :
How does our point on H change as we change these parameters?
Let's start by computing .
For the first n-1 terms this is simple, because simply returns . So is 1 when , and 0 otherwise, which we can represent using the Kronecker delta . And .
Geometrically, this is telling us about the slope of . Note that:
- is constant and doesn't depend on our choice of
- (We can never increase agent 's utility by increasing another agent's utility. This is always true at the Pareto frontier.)
How Does G Change as We Move Around on H?
We can start solving for by substituting in the definition of G:
.
From here we can apply the n-factor product rule:
.
Thankfully, whenever , leaving just . We can also notice , leaving us with the much nicer .
It will be important later that this partial derivative is undefined when , aka wherever any agent is receiving their least feasible utility.
Writing function arguments explicitly:
Putting These Terms Together
Let's start putting these together. We can start by breaking apart the two cases of , like this:
Here's one reason why it's useful to know about the Kronecker delta : it filters out all but the -th element of a sum: . When you're working in Einstein notation (which is great by the way), you just write it as and you can think of the 's as "cancelling".
That leaves us with:
And we know , so let's plug that in:
And that is the family of equations that we want to all be 0 when . (This causes .) We'll call this gradient to remind ourselves that this is the gradient of where we're holding the weights constant.
Solving for the Geometric Weights
Ok, now we can set , and solve for , for :
This is still a system of linear equations we need to solve, since each for depends on , which in turn satisfies . So let's solve it for !
Remembering that , we can notice that:
This lets us simplify down to
And now we can plug that back into the formula for all the other !
Well isn't that convenient! The formula for all has the same form, and we can think of it like starting with the Harsanyi weights (which make p optimal according to , along with anything else with the same Harsanyi score ), and then tweaking them to get to target in particular.
We can simplify our formula by noting that
To make the formula a little prettier, and to get some extra geometric insight, we can introduce the element-wise product , where .
Here's a good opportunity to make sure our weights sum up to 1:
Great! is acting like a normalization term, and we can think of as telling us which direction points in. This vector of weights is then scaled to land on the hypersurface of weights that sum to 1, known as the standard simplex , which we'll discuss more later [LW · GW].
We can also think of as a function denoted as which returns the Harsanyi weights for in the context of a compact, convex subset . This is it, so let's make a new heading to find it later!
How to Calculate Weights for p
We now have a formula for , which we can write as
Or we can suppress function arguments and simply write
Where is the element-wise product of and : and is the dot product
For a single component , we have
Note that isn't defined when .
Is this a problem? Not really! , the Harsanyi aggregate utility of p when has been chosen to make p optimal under . When this is 0, it means the individual utilities must all be 0 and the entire feasible set must be a single point at the origin. When that happens, any weights will make optimal according to or . Feel free to use any convention that works for your application, if we're in a context where is defined we can inherit
If is shrinking towards becoming a single point, we can use .
Checking Our Solution
Assuming we calculated correctly, we can verify that these weights lead to . This requires for the first utilities, so let's check that:
Success! is an optimum of among . But is it unique?
P Is the Unique Optimum of G When Weights Are Positive
Let's see how and influenced the outcome here, and keep track of the critical points which can make or undefined. These are the only points which can be extrema, and for each we need to check if it is a minimum or maximum among . ( doesn't have any saddle points, and doesn't have any boundaries of its own to worry about. Where meets the boundary of 's domain, the axes, there.)
For example, whenever any individual utility , is undefined, which causes to be undefined. But note that these will be minimal points of , unless . To find maximal points of across we need
If or are 0, then is undefined, and we'll check later if these can still be optimal. We assumed that the index refers to an agent with , in order to prevent that exact case from breaking our entire solution.
If we were handed from some external source, we could solve this equation to see which happened to be optimal. But we designed , so let's see what we caused to be optimal.
If then is undefined. This only happens when is a single point, in which case is indeed the unique optimum of .
Here we're going to be careful about which weights can be 0. We'll again use the fact that to safely divide it from both sides.
Here again we can see that solves this family of n-1 equations. And this is very exciting because this is our first maximum of ! Are there any other solutions?
Each of these equations is satisfied when one of the following is true:
In other words, assigning an agent 0 Harsanyi weight (and thus geometric weight ) can allow to have multiple optima among , which can give it multiple optima among .
What about when all geometric weights are positive? Are there any other solutions to that second family of n-1 equations?
Having all positive geometric weights implies having all positive Harsanyi weights , and all positive individual utilities . It also implies that any optimum of will have all positive individual utilities . This lets us freely divide by any of these terms, without needing to worry that we might be dividing by 0.
Since and are both positive, we can think of as a scaled version of .
How does this scalar influence the other terms in these equations?
This forms a line from the origin to , which only intersects at . (Since scaling up or down changes .) So when all geometric weights are positive, is the unique optimum of among !
When , is also 0, so doesn't affect . We can start with , and then freely vary the utilities of any agent with 0 weight and remain optimal.
Interactive Implementations
We can also check our entire calculation, including those pages of calculus, by actually implementing our solution and seeing if it works! A graphing calculator is sufficient to check this in 2 and 3 dimensions. We can show all the points which satisfy and they should trace out the contours of , showing all the joint utilities which have the same score as .
In 2 dimension, the graph looks like this:
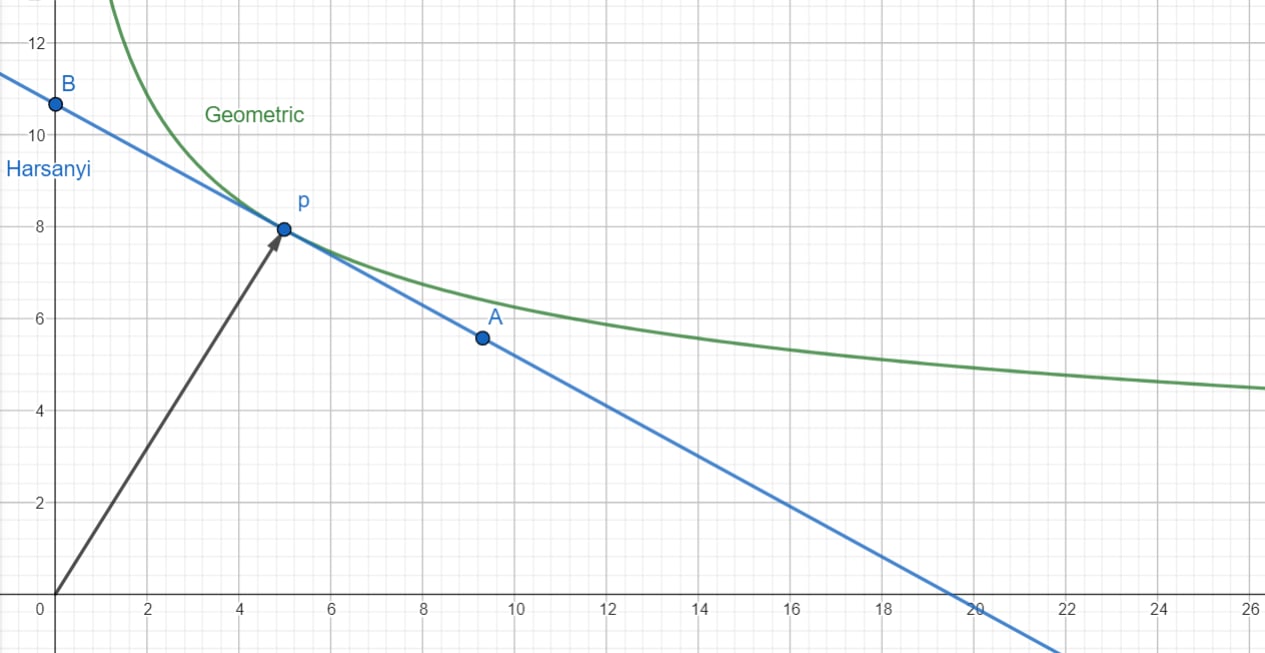
The Harsanyi hyperplane is a line, and the contour curves are skewed hyperbolas.
As expected, taking out of the positive quadrant violates our assumption that utilities are non-negative, leading to invalid settings for . Similarly, if has a positive slope, this violates our assumption that is on the Pareto frontier. (A positive slope implies that we can make both players better off simultaneously. If we calculate anyway, a positive slope implies that is negative for the agent on the x axis.) This allows to pass up through the hyperbola at another point other than , but this never happens when .
With 3 agents, the graph looks like this:
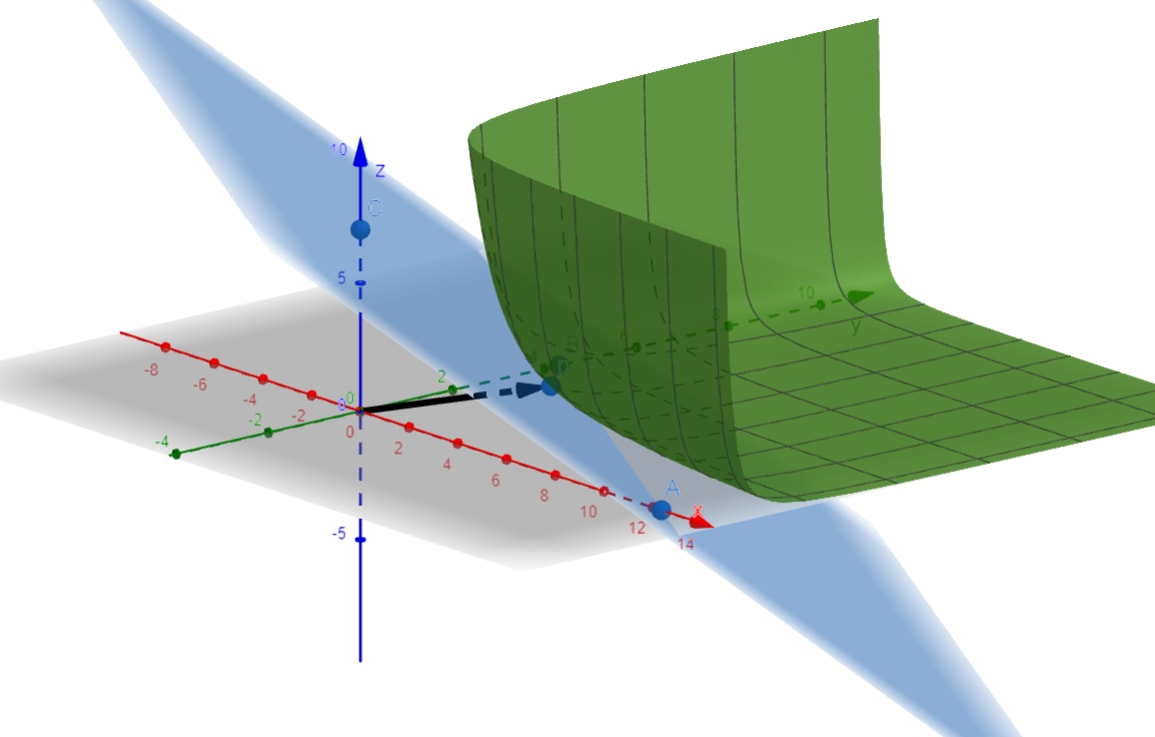
In 3 dimensions, the Harsanyi hyperplane is a plane, and the contour surfaces are skewed hyperboloids.
We can move around on the hyperplane, and this changes , which changes where the contour touches . We can see that always lies at the intersection of this contour curve and , and this is a visual proof that maximizes among . And when corresponds to all agents having positive Harsanyi weight , this intersection only happens at !
0 comments
Comments sorted by top scores.