Proving the Geometric Utilitarian Theorem
post by StrivingForLegibility · 2024-08-07T01:39:10.920Z · LW · GW · 0 commentsContents
Assumptions Maximizing G Can Always Lead to Pareto Optimality Making p an Optimum of G The Harsanyi Hyperplane The Geometric Utilitarian Weights Gradient Ascent More Details None No comments
This is a supplemental post to Geometric Utilitarianism (And Why It Matters) [LW · GW], which sets out to prove what I think are the main interesting results about Geometric Utilitarianism:
- Maximizing a geometric weighted average can always lead to Pareto optimality.
- Given any Pareto optimal joint utility , we can calculate weights which make optimal according to .
That post describes why this problem is interesting, but the quick summary is: geometric utility aggregation is a candidate alternative to Harsanyi utility aggregation (which is an arithmetic weighted average), which handles some tradeoffs better than Harsanyi aggregation. The resulting choice function is geometrically rational [? · GW], whereas the Harsanyi choice function is VNM-rational. This post is mostly math supporting the main post, with some details moved to their own posts later in this sequence.
We as a community, and I individually, would need pretty strong reasons to endorse a theory of rationality based on a broadening of the VNM axioms. I've been sufficiently radicalized by Scott Garrabrant [LW · GW], and thinking about how each system handles common decision problems, that I think more work in this direction is potentially very valuable. Here's how I solved a couple of the subproblems towards making progress in that direction.
Assumptions
Most of these proofs can be understood geometrically, and we'll need to make some geometric assumptions. One big property we'll be using is the fact that set of feasible joint utilities is always convex. This is always true for VNM-rational agents with utility functions, but we can prove the same result for agents with other functions describing their preferences, as long as the feasible utilities stay convex. This will be helpful when we start combining utilities in ways that make the resulting social choice function violate the VNM axioms [LW · GW], but preserve convexity.
We'll also need to be compact, if we want to be able to find optimal points according to or . If extends infinitely in any direction, there might not be any Pareto optimal joint utilities. This "problem" also appears in classic individual rationality: what does a rational agent do when they can simply pick a number and receive that much utility? Individual VNM-rationality isn't well-defined when there isn't an optimal option, so compactness seems like a weak assumption, but it implies that utilities are bounded with respect to the options our agents are facing, so I want to call it out.
It will be easier to prove uniqueness results if there aren't any redundant agents with constant utility. Any weight assigned to these agents has no effect on the optima of or , and in the context of optimizing over a set of feasible options it's safe to ignore such agents. There's no choice we can make which will affect them in any way. Geometrically, this corresponds to the requirement that be -dimensional.
It will make the math nicer if we shift all utility functions so that each agent assigns 0 utility to their least favorite option. If is generated by taking the Pareto improvements over some disagreement point , as is done in the bargaining setting, this disagreement point will become the baseline for 0 utility for all agents.
I'll also be assuming that the number of players is finite. I don't have any reason to think the results fail for the infinite case, but there are things we'd need to worry about for infinite-dimensional vector spaces that I didn't worry about for these first results. We'd want to swap out all the finite sums for integrals , for example, if we wanted to use continuous indices for agents.
Maximizing G Can Always Lead to Pareto Optimality
Showing that maximizing can always lead to Pareto optimality is relatively straightforward.
Our decision to shift away from negative utilities is already paying dividends: the weighted geometric average is monotonically increasing with respect to all individual utilities. Any Pareto improvement in utilities will lead to a weighted average that's at least what we started with.[1]
Pareto Monotonicity: If is a Pareto improvement over , then for all weights . Symbolically:
Among agents with positive weight , any increase to their utility will increase ; maximizing will automatically pick up any Pareto improvements among these agents.
It turns out that when all agents have positive weight, , this Pareto optimal point will be the unique optimum of among . We'll prove this more rigorously in the next post [LW · GW], but intuitively when for all agents, the contour surface of joint utilities with the same score as (colored green in the picture below) curves away from .
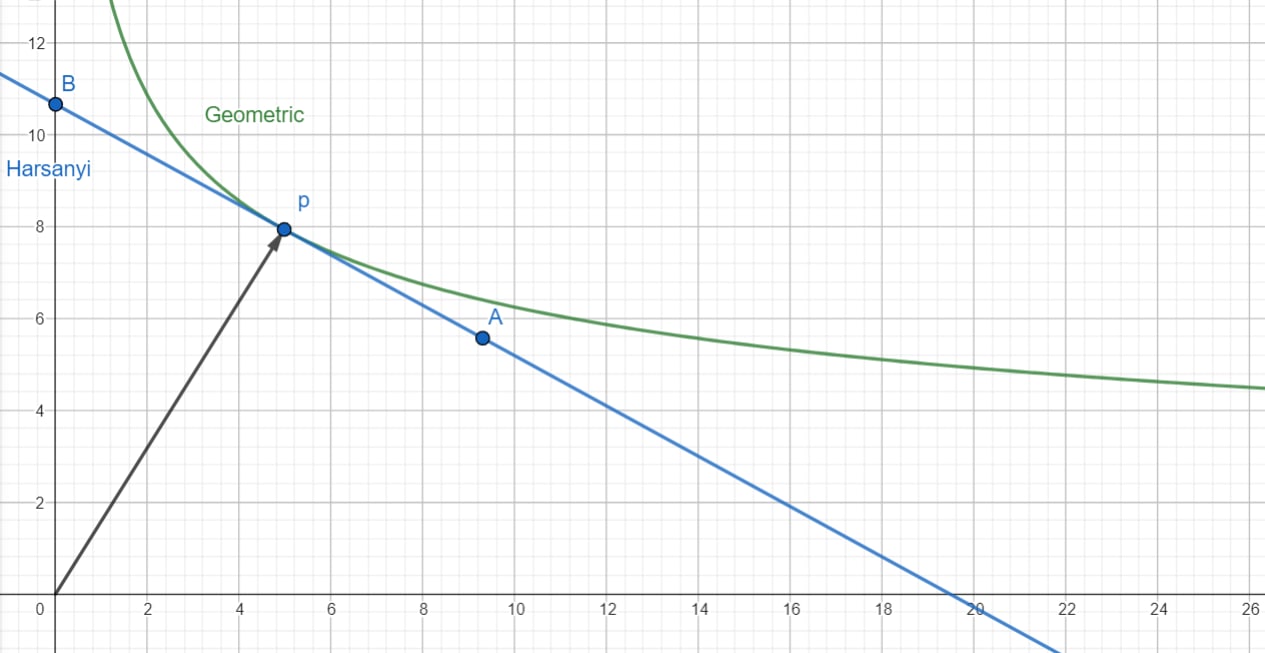
Will maximizing lead to Pareto optimality among a group of agents where some have 0 weight? In that case it depends on how we break ties! Assigning an agent 0 weight makes and insensitive to their welfare, so there can be optima of and which are not Pareto optimal in this case.[2]
As an example, consider Alice deciding how much money she and Bob should receive, up to $100 each. There is no trade-off between her utility and Bob's and the only Pareto optimum is ($100, $100). But if Alice is a pure or maximizer and assigns Bob 0 weight, she's indifferent to Bob's utility and the optima are wherever Alice receives $100.
Fortunately, there are always optima of which are Pareto optimal, and we can use a tie-breaking rule which always picks one of these. One approach would be to derive new weights which are guaranteed to be positive for all agents, and which are very close to .
Then we could pick the point on the Pareto frontier which is the limit as approaches 0.
Maximizing or can always be done Pareto optimally. It turns out that this particular tie-breaking rule isn't guaranteed to make continuous, and in fact there might be cases where no such tie-breaking rule exists. However, it turns out that we can make continuous if we're willing to accept an arbitrarily good approximation of . See Individual Utilities Shift Continuously as Geometric Weights Shift [LW · GW] for more details.
Making p an Optimum of G
Going the other direction, let's pick a Pareto optimal joint utility and find weights which make that point optimal among with respect to . These geometric weights won't always be unique, for example at corners where the Harsanyi weights aren't unique. won't always have unique optima either, which can happen when we give any agents 0 weight.
Let's handle a few easy cases up front: when , the only option is . This means that , and maximization reduces to individual utility maximization for a single agent. This is a nice base case for any sort of recursion: the aggregate of one utility function is just that same utility function, and Harsanyi aggregation works the same way.
Similarly, when is a single point , any weights will make optimal according to or . Feel free to use any convention that works for your application, the simplest option is to just inherit , but if is shrinking towards becoming 0 dimensional then I prefer .
For two or more agents and a Pareto frontier with multiple options, here's the high-level overview of the proof:
- Identify the Harsanyi hyperplane , and the Harsanyi weights
- Calculate geometric weights which make optimal among according to
- Show that this is sufficient to make optimal among .
The Harsanyi Hyperplane
One way to derive the Harsanyi weights for is to find a hyperplane which separates from the rest of .
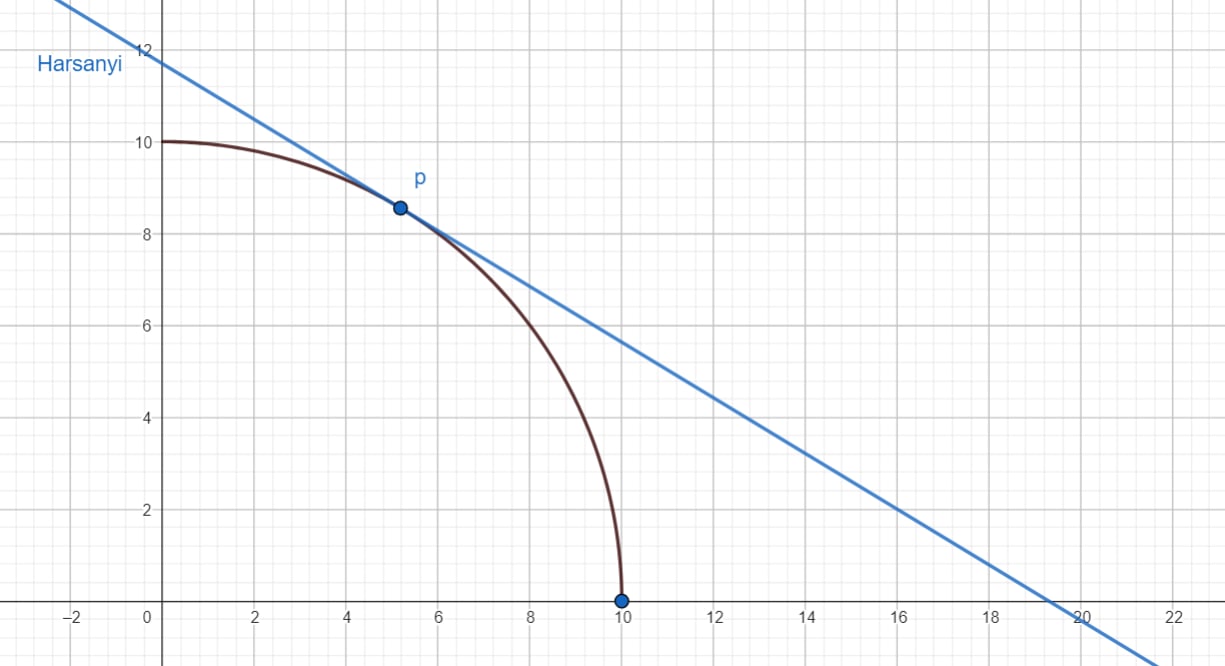
Diffractor [LW · GW] uses this technique here [LW · GW] in that same great Unifying Bargaining [? · GW] sequence, and I'd actually forgotten I learned it from there, it's become so ingrained in my thinking. The idea is that maximizing a weighted arithmetic average can be thought of as picking a slope for a hyperplane, then sliding that hyperplane [LW · GW] away from the origin until it just barely touches .
The slope of this Harsanyi hyperplane matches up with the slope of the Pareto frontier at . If is at a corner, where the slope change suddenly on either side, any convex combination of the slopes around will work. The equation for a any hyperplane looks like , where and are constants. Given some Harsanyi weights , the Harsanyi hyperplane shows us all of the joint utilities with the same weighted average, and is defined by . We can pick any joint utility on and it will have the same score as .
The Geometric Utilitarian Weights
The trick that makes all of this work is to pick weights which cause to be optimal with respect to among . It turns out these are easy to calculate! For individual elements we can use the formula
And for all of the weights at once we can use
Where is the element-wise product of and : and is the dot product . Check out Deriving the Geometric Utilitarian Weights [LW · GW] for the details of how this was derived, and how we know that is the unique optimum of among if we use these weights. (So long as for all agents.)
Gradient Ascent
One way to think about maximizing is to imagine a robot flying around in joint utility space , following the gradient to increase as quickly as possible. This is the gradient ascent algorithm, and it can be used to find local optima of any function. Some functions have multiple optima, and in those cases it matters where your robot starts. But when there's just one global optimum, gradient ascent will find it.
If we ignore and just set our robot loose trying to maximize , it will never find an optimum. There's always an agent's utility where increasing their utility increases . ( for all agents, and for some agent).
However, if we use those weights we calculated, will always point at least a little in the direction of , the normal vector to the Harsanyi hyperplane . Check out Gradient Ascenders Reach the Harsanyi Hyperplane [LW · GW] for the details there.
Now if we add the single constraint that our robots can't travel beyond , they'll bump into and then travel along , since that's the gradient of when our robots are constrained to only move along .
But when for all agents, has a unique optimum on , and it's ! No matter where our robots start within the interior of , they'll find themselves inexorably drawn to the given just the constraint that they can't cross . If we add in the constraint that the robots need to stay within , they might bump into those boundaries first, but they'll make their way over to the unique optimum of among all options in , which is still .
When for some agent, may have multiple optima where our robots might land, but those optima always include !
More Details
The next two posts in this sequence go into more detail about two subproblems we summarized briefly here.
Deriving the Geometric Utilitarian Weights [LW · GW] goes into more detail about how those weights can be derived, and how we know is the unique optimum among if we use them.
Gradient Ascenders Reach the Harsanyi Hyperplane [LW · GW] describes what the gradient of looks like, and how we know it always points at least a little towards (and then away from once we cross it).
Then we show a bonus result: Individual Utilities Shift Continuously as Geometric Weights Shift [LW · GW]. Which is a nice property to have if you want your system's behavior to only change a little if you only change the weights a little, instead of discontinuously thrashing [LW · GW] to a potentially very different behavior.
- ^
When an individual is given weight, increasing their utility doesn't increase the weighted average. But it doesn't decrease the weighted average either.
- ^
Assigning an agent 0 weight makes insensitive to their welfare, but increasing might still increase their welfare. Because we might have assigned weight to another agent whose values are somewhat aligned with theirs. Our social aggregate might not care that Alice likes clean air, but it might still tell us to clean up the air if Bob likes it and Bob is given positive weight.
0 comments
Comments sorted by top scores.