Gradient Ascenders Reach the Harsanyi Hyperplane
post by StrivingForLegibility · 2024-08-07T01:40:40.353Z · LW · GW · 0 commentsContents
The Gradient and Contour Lines Gradient Ascent The Normal Vector to The Harsanyi Hyperplane Gradient Ascenders Reach H None No comments
This is a supplemental post to Geometric Utilitarianism (And Why It Matters) [LW · GW], in which I show that, if we use the weights we derived in the previous post, a gradient ascender will reach the Harsanyi hyperplane . This is a subproblem of the proof laid out in the first post [LW · GW] of this sequence, and the main post [LW · GW] describes why that problem is interesting.
The Gradient and Contour Lines
It's easy to find the points which have the same score as : they're the points which satisfy . They all lie on a skewed hyperbola that touches at .
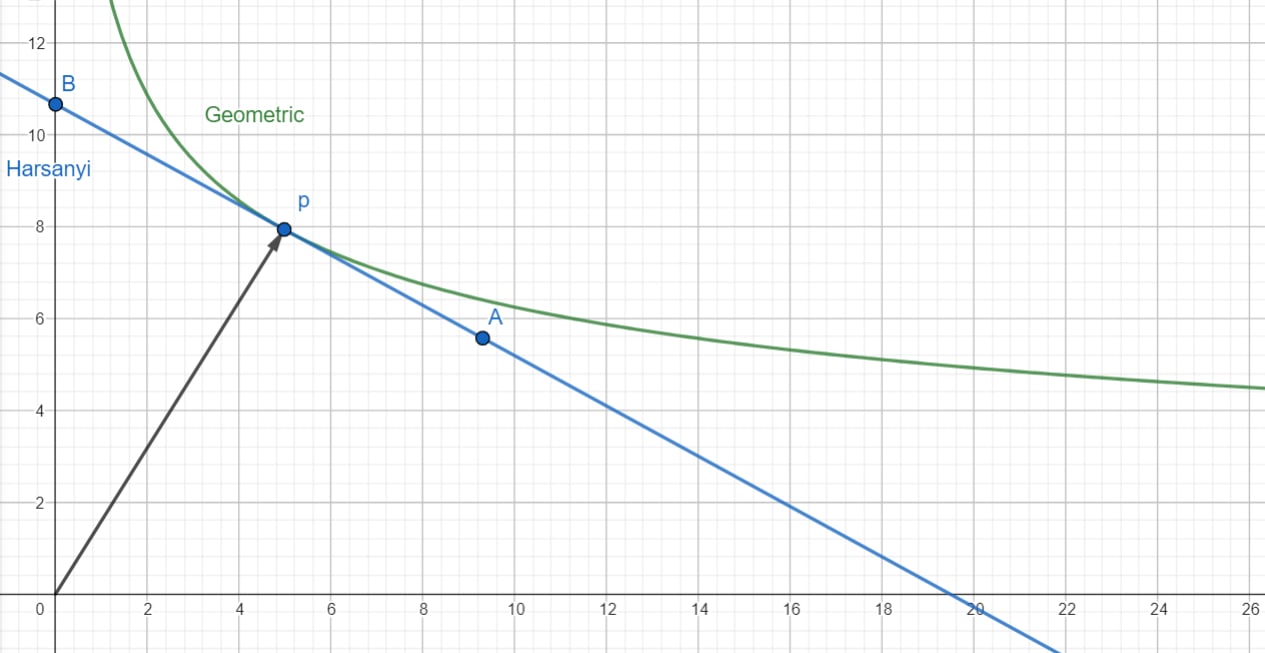
One way to think about is as a hypersurface in -dimensional space sitting "above" the n-dimensional space of utilities we've been working with. When there are 2 agents, we can plot using the third vertical axis.

Check out the intersection of and the vertical plane above the Harsanyi line : this tells us about the values of along this line, and as we shift we can recalculate so that among , peaks at .
Our choice of determines where we land on that surface "above" p. If we take a slice through by only looking at the points of at the same "altitude" as , we get exactly that hyperbola back!
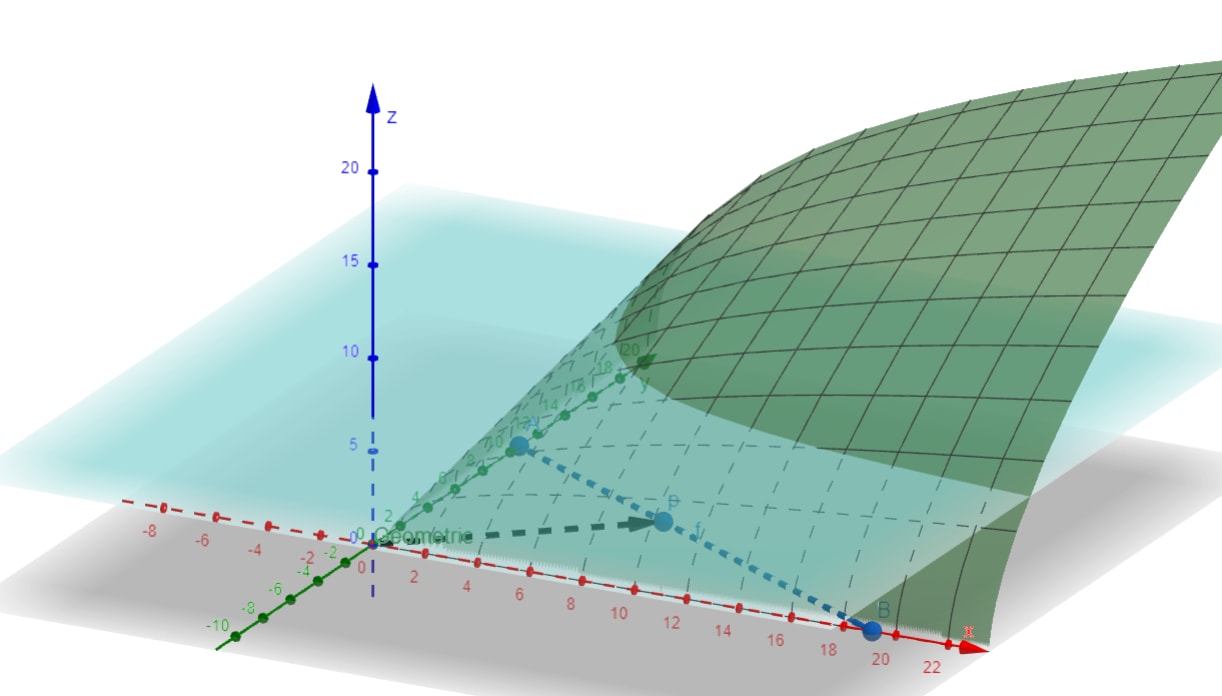
Doing this for many altitudes gives us a contour map, which you're probably familiar with in the context of displaying the altitude of real 3D landscapes on flat 2D maps.
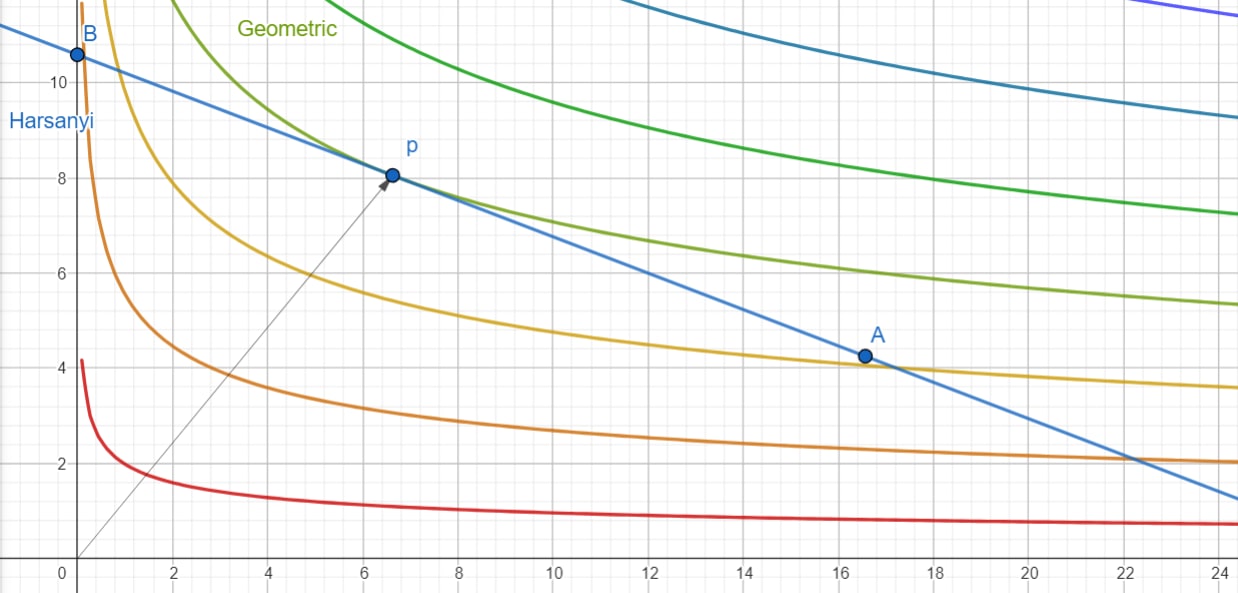
You can see how these contours change as we change and using the interactive version here.
There's a theorem which tells us that the gradient of must either be 0 or perpendicular to these contour hypersurfaces. So by calculating the gradient, we can calculate the tangent hyperplane of our skewed hyperbolas! And then we'll see if anything interesting happens at .
This is a subproblem of the gradient calculation we did earlier [LW · GW], where we were specifically interested in how changes along the Harsanyi hyperplane . The slope of , encoded in , showed up in how we defined . So let's see how and have shaped the geometry of .
The gradient is just a vector of partial derivatives , where we're using to remind ourselves that this is just the gradient with respect to , holding constant. We're holding the weights constant, and isn't a function this time where we'd need to use the chain rule, so all we need to do is apply the power rule:
If we use to denote element-wise division, this gives us a simple formula for :
or a component
And that's it! is defined when for all agents. Where is defined, we can keep taking derivatives; is smooth everywhere for all agents.
Here's what it looks like!
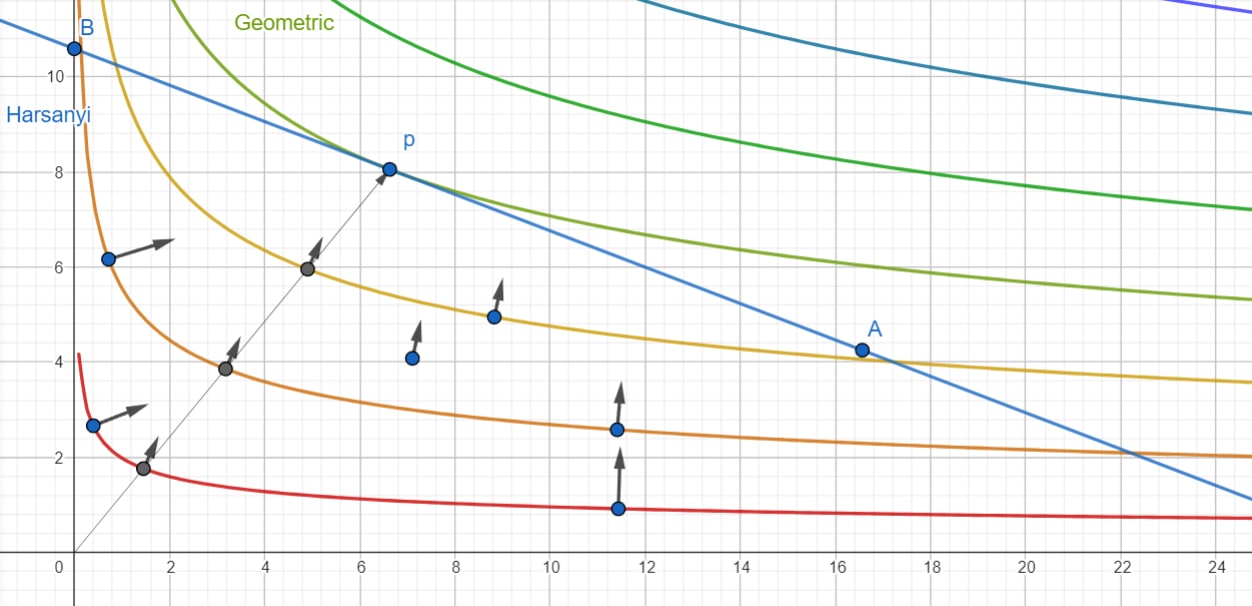
Playing around with an interactive version, you can see that as you approach giving an agent 0 utility, the gradient arrow gets longer and longer. As long as , diverges off to infinity as approaches 0. When , changing doesn't change and .
Normatively, being 0 whenever any individual utility is 0 is a nice property to have. As long as we give an agent some weight, there is a pressure towards giving them more utility. If you've gotten this far you've probably taken a calculus class, and you probably studied how to enclose the largest area using a fixed perimeter of fencing. This is exactly the same pressure pushing us towards squares and away from skinny rectangles. The Pareto optima are points where the pressures favoring each agent balance, for some weights , and we can design to cause all those pressures to balance at any point we choose along the Pareto frontier.
The visual analogy between "maximizing a product" and "sliding a hyperbola until it reaches the Pareto frontier" was really helpful in thinking about this problem. I first learned about that lens from Abram Demski's [LW · GW] great Comparing Utilities [LW · GW] post, which included illustrations by Daniel Demski that really helped me visualize what was going on as we maximize .
Another thing we can notice is that . This is exactly what we'd expect from a Pareto monotone aggregation function. Geometrically, this means those contour lines always get further and further away from , and they don't curve back in to make some other point in score higher on than .
Gradient Ascent
The simplest proof I've found that goes from
- maximizes among
to
- maximizes among
relies on the fact that, if you start inside and follow the gradient to make larger and larger, you'll eventually run into the Harsanyi hyperplane . In order for this to be true, needs to point at least a little bit in the direction perpendicular to .
The Normal Vector to The Harsanyi Hyperplane
What is that direction? One way to think about is as a contour hyperplane of , the Harsanyi aggregation function. is all of the joint utilities where . We know that the gradient will be perpendicular to this contour hyperplane, so let's compute that in order to find the normal vector to :
It would make my tensor calculus teacher too sad for me to write that , but the components of the vector are always the same as the components of the covector . We can then normalize to get the normal vector to which I'll denote :
The distinction isn't important for most of this sequence, but I do want to use different alphabets to keep track of which objects are vectors and which are maps from vectors to scalars because they're different geometric objects with different properties. If we decide to start measuring one agent's utility in terms of milli-utilons, effectively multiplying all of their utility measurements by 1,000, the component of that agent's Harsanyi weight scales inversely in a way that perfectly cancels out this change. The slope of a line doesn't change when we change the units we use to measure it.
Gradient Ascenders Reach H
One way to think about the dot product is as a tool for measuring the lengths of vectors and the angles between them. If the dot product is ever 0, it means that a gradient ascender will not be moving towards or away from at that point. There are such orthogonal directions available, so for our proof to work we need to check that our choice of always leads to movement towards or away from . Let's see what it takes to satisfy
All of these terms are non-negative, so in order for to be 0, each element of this sum needs to be simultaneously 0. Can this happen for our choice of ?
We know that for at least one agent , and that if for all agents, that the entire Pareto frontier must consist only of that point at the origin. (In which case all choices of and make that point optimal, and any gradient ascender will trivially find the optimum.) Otherwise, wherever is defined it points at least a little in the same direction as . (And where it's not defined, it's because some component has diverged off to positive infinity because for some agent.)
In other words, using our choice of , all gradient ascenders will either stay at their initial local minimum (because they were placed on a part of the boundary of where and is undefined), or they will eventually reach the Harsanyi hyperplane.
This is also a great time to point out that
When for all agents, points in the same direction as at . This is a direct consequence of choosing such that is perpendicular to . So is the tangent hyperplane to the Pareto frontier at . But has been designed so that is also the tangent hyperplane to the contour curve of at .
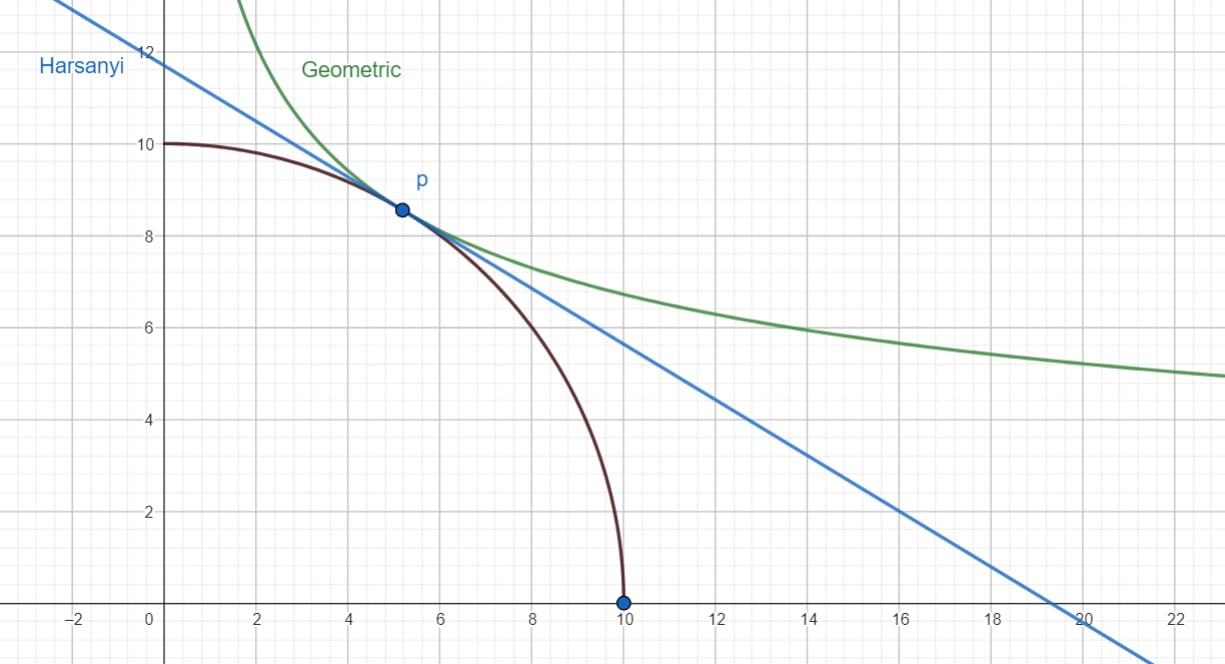
You can play with an interactive version here!
0 comments
Comments sorted by top scores.