Comparing Utilities
post by abramdemski · 2020-09-14T20:56:15.088Z · LW · GW · 31 commentsContents
Utilities aren't comparable. Some non-obvious consequences. Comparing utilities. Pareto-Optimality: The Minimal Standard Variance Normalization: Not Too Exploitable? Warm-Up: Range Normalization Variance Normalization Nash Bargaining Solution Kalai–Smorodinsky Animals, etc. Altruistic agents. Utility monsters. Average utilitarianism vs total utilitarianism. None 31 comments
(This is a basic point about utility theory which many will already be familiar with. I draw some non-obvious conclusions which may be of interest to you even if you think you know this from the title -- but the main point is to communicate the basics. I'm posting it to the alignment forum because I've heard misunderstandings of this from some in the AI alignment research community.)
I will first give the basic argument that the utility quantities of different agents aren't directly comparable, and a few important consequences of this. I'll then spend the rest of the post discussing what to do when you need to compare utility functions.
Utilities aren't comparable.
Utility isn't an ordinary quantity. A utility function is a device for expressing the preferences of an agent.
Suppose we have a notion of outcome.* We could try to represent the agent's preferences between outcomes as an ordering relation: if we have outcomes A, B, and C, then one possible preference would be A<B<C.
However, a mere ordering does not tell us how the agent would decide between gambles, ie, situations giving A, B, and C with some probability.
With just three outcomes, there is only one thing we need to know: is B closer to A or C, and by how much?
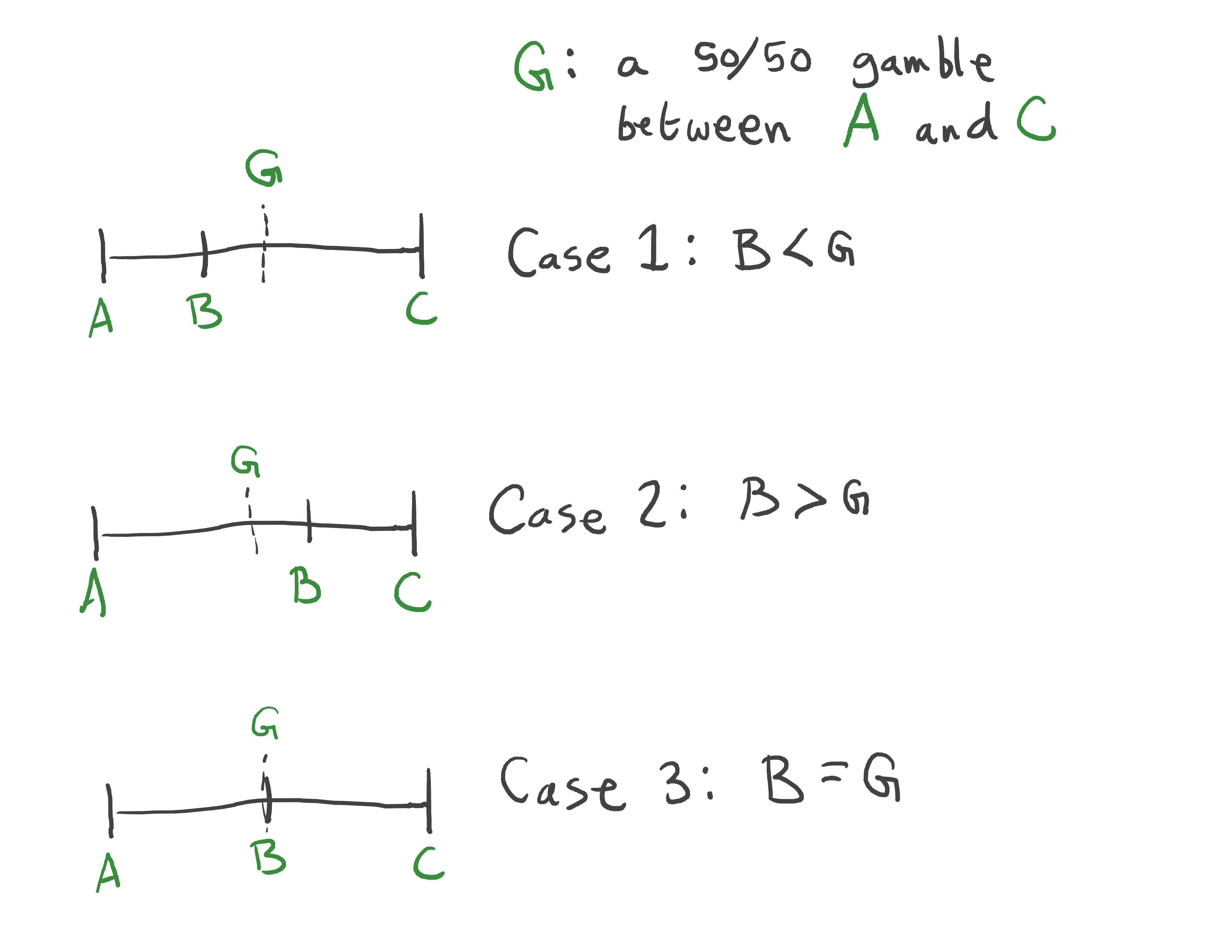
We want to construct a utility function U() which represents the preferences. Let's say we set U(A)=0 and U(C)=1. Then we can represent B=G as U(B)=1/2. If not, we would look for a different gamble which does equal B, and then set B's utility to the expected value of that gamble. By assigning real-numbered values to each outcome, we can fully represent an agent's preferences over gambles. (Assuming the VNM axioms [LW · GW] hold, that is.)
But the initial choices U(A)=0 and U(C)=1 were arbitrary! We could have chosen any numbers so long as U(A)<U(C), reflecting the preference A<C. In general, a valid representation of our preferences U() can be modified into an equally valid U'() by adding/subtracting arbitrary numbers, or multiplying/dividing by positive numbers.
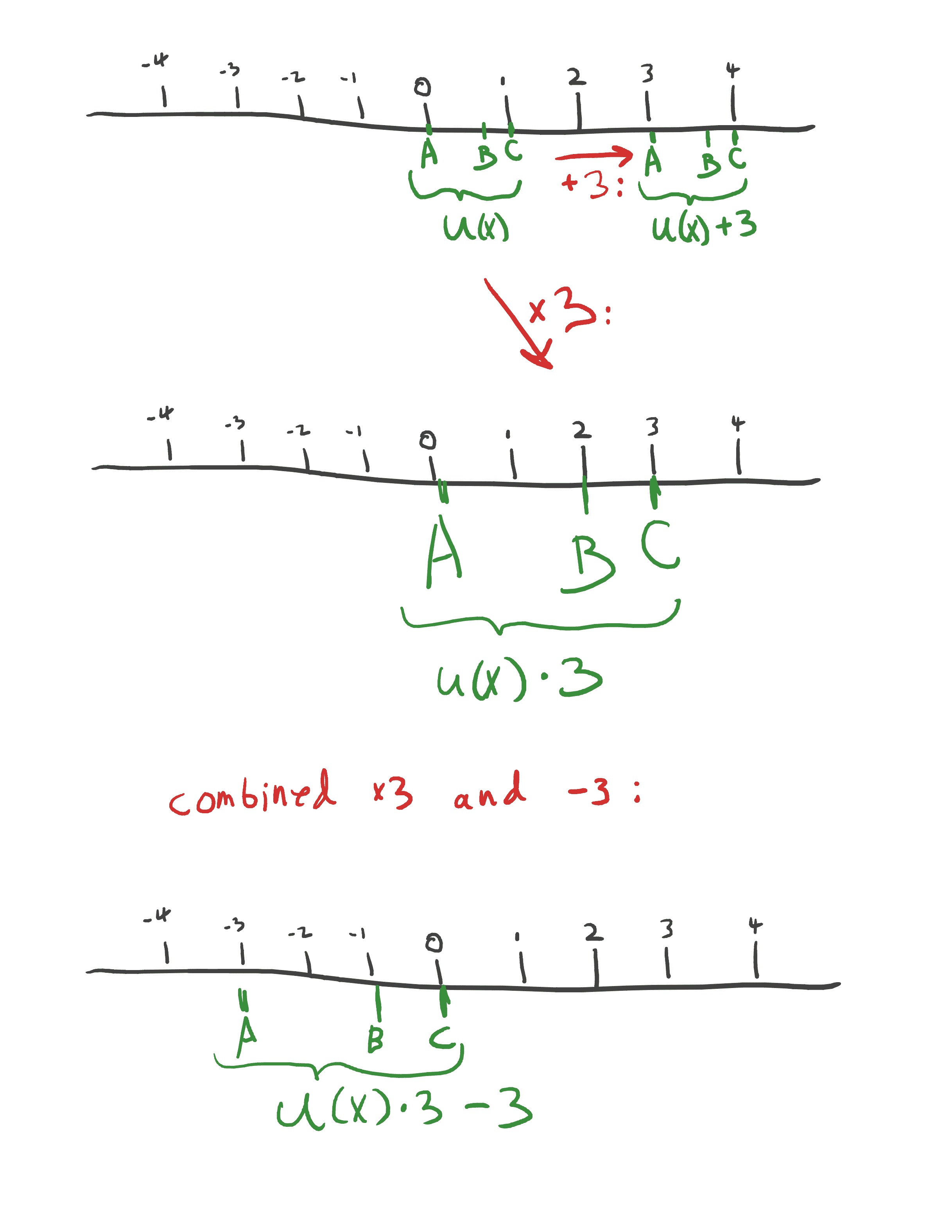
So it's just as valid to say someone's expected utility in a given situation is 5 or -40, provided you shift everything else around appropriately.
Writing to mean that two utility functions represent the same preferences, what we have in general is: if and only if . (I'll call the multiplicative constant and the additive constant.)
This means that we can't directly compare the utility of two different agents. Notions of fairness should not directly say "everyone should have the same expected utility". Utilitarian ethics cannot directly maximize the sum of everyone's utility. Both of these operations should be thought of as a type error.
Some non-obvious consequences.
The game-theory term "zero sum" is a misnomer [LW · GW]. You shouldn't directly think about the sum of the utilities.
In mechanism design, exchangeable utility is a useful assumption which is often needed in order to get nice results. The idea is that agents can give utils to each other, perhaps to compensate for unfair outcomes. This is kind of like assuming there's money which can be exchanged between agents. However, the non-comparability of utility should make this seem really weird. (There are also other disanalogies with money; for example, utility is closer to logarithmic in money, not linear.)
This could (should?) also make you suspicious of talk of "average utilitarianism" and "total utilitarianism". However, beware: only one kind of "utilitarianism" holds that the term "utility" in decision theory means the same thing as "utility" in ethics: namely, preference utilitarianism. Other kinds of utilitarianism can distinguish between these two types of utility. (For example, one can be a hedonic utilitarian without thinking that what everyone wants is happiness, if one isn't a preference utilitarian.)
Similarly, for preference utilitarians, talk of utility monsters becomes questionable. A utility monster is, supposedly, someone who gets much more utility out of resources than everyone else. For a hedonic utilitarian, it would be someone who experiences much deeper sadness and much higher heights of happiness. This person supposedly merits more resources than other people.
For a preference utilitarian, incomparability of utility means we can't simply posit such a utility monster. It's meaningless a priori to say that one person simply has much stronger preferences than another (in the utility function sense).
All that being said, we can actually compare utilities, sum them, exchange utility between agents, define utility monsters, and so on. We just need more information.
Comparing utilities.
The incomparability of utility functions doesn't mean we can't trade off between the utilities of different people.
I've heard the non-comparability of utility functions summarized as the thesis that we can't say anything meaningful about the relative value of one person's suffering vs another person's convenience. Not so! Rather, the point is just that we need more assumptions in order to say anything. The utility functions alone aren't enough.
Pareto-Optimality: The Minimal Standard
Comparing utility functions suggests putting them all onto one scale, such that we can trade off between them -- "this dollar does more good for Alice than it does for Bob". We formalize this by imagining that we have to decide policy for the whole group of people we're considering (e.g., the whole world). We consider a social choice function which would make those decisions on behalf of everyone. Supposing it is VNM rational, its decisions must be comprehensible in terms of a utility function, too. So the problem reduces to combining a bunch of individual utility functions, to get one big one.
So, how do we go about combining the preferences of many agents into one?
The first and most important concept is the pareto improvement: our social choice function should endorse changes which benefit someone and harm no one. An option which allows no such improvements is said to be Pareto-optimal.
We might also want to consider strict Pareto improvements: a change which benefits everyone. (An option which allows no strict Pareto improvements is weakly Pareto-optimal.) Strict Pareto improvements can be more relevant in a bargaining context [LW(p) · GW(p)], where you need to give everyone something in order to get them on board with a proposal -- otherwise they may judge the improvement as unfairly favoring others. However, in a bargaining context, individuals may refuse even a strict Pareto improvement due to fairness considerations [LW · GW].
In either case, a version of Harsanyi's utilitarianism Theorem [LW(p) · GW(p)] implies that the utility of our social choice function can be understood as some linear combination of the individual utility functions.
So, pareto-optimal social choice functions can always be understood by:
- Choosing a scale for everyone's utility function -- IE, set the multiplicative constant. (If the social choice function is only weakly Pareto optimal, some of the multiplicative constants might turn out to be zero, totally cancelling out someone's involvement. Otherwise, they can all be positive.)
- Adding all of them together.
(Note that the additive constant doesn't matter -- shifting a person's utility function up or down doesn't change what decisions will be endorsed by the sum. However, it will matter for some other ways to combine utility functions.)
This is nice, because we can always combine everything linearly! We just have to set things to the right scale and then sum everything up.
However, it's far from the end of the story. How do we choose multiplicative constants for everybody?
Variance Normalization: Not Too Exploitable?
We could set the constants any way we want... totally subjective estimates of the worth of a person, draw random lots, etc. But we do typically want to represent some notion of fairness. We said in the beginning that the problem was, a utility function has many equivalent representations . We can address this as a problem of normalization: we want to take a and put it into a canonical form, getting rid of the choice between equivalent representations.
One way of thinking about this is strategy-proofness. A utilitarian collective should not be vulnerable to members strategically claiming that their preferences are stronger (larger ), or that they should get more because they're worse off than everyone (smaller -- although, remember that we haven't talked about any setup which actually cares about that, yet).
Warm-Up: Range Normalization
Unfortunately, some obvious ways to normalize utility functions are not going to be strategy-proof.
One of the simplest normalization techniques is to squish everything into a specified range, such as [0,1]:
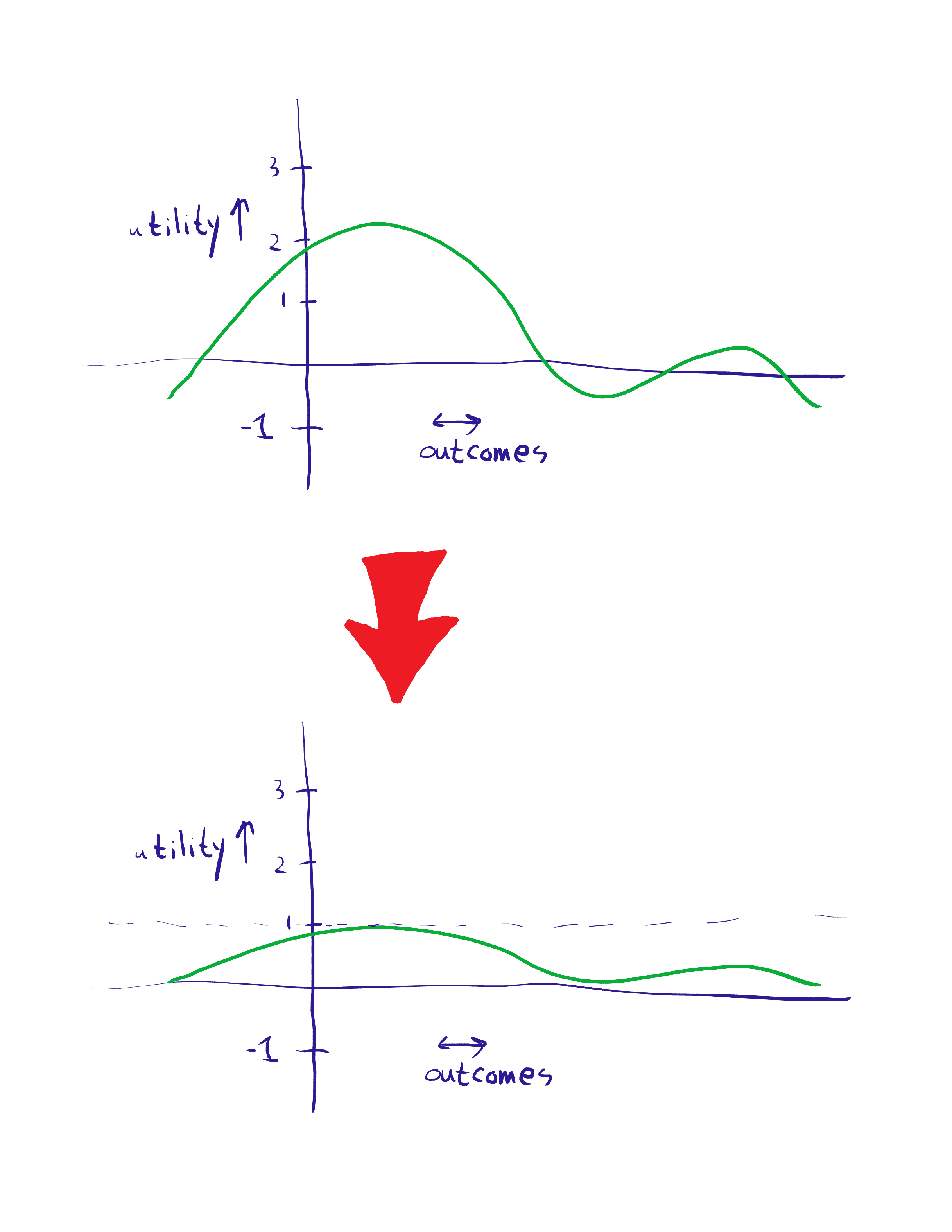
This is analogous to range voting: everyone reports their preferences for different outcomes on a fixed scale, and these all get summed together in order to make decisions.
If you're an agent in a collective which uses range normalization, then you may want to strategically mis-report your preferences. In the example shown, the agent has a big hump around outcomes they like, and a small hump on a secondary "just OK" outcome. The agent might want to get rid of the second hump, forcing the group outcome into the more favored region.
I believe that in the extreme, the optimal strategy for range voting is to choose some utility threshold. Anything below that threshold goes to zero, feigning maximal disapproval of the outcome. Anything above the threshold goes to one, feigning maximal approval. In other words, under strategic voting, range voting becomes approval voting (range voting where the only options are zero and one).
If it's not possible to mis-report your preferences, then the incentive becomes to self-modify to literally have these extreme preferences. This could perhaps have a real-life analogue in political outrage and black-and-white thinking. If we use this normalization scheme, that's the closest you can get to being a utility monster.
Variance Normalization
We'd like to avoid any incentive to misrepresent/modify your utility function. Is there a way to achieve that?
Owen Cotton-Barratt discusses different normalization techniques in illuminating detail, and argues for variance normalization: divide utility functions by their variance, making the variance one. (Geometric reasons for normalizing variance to aggregate preferences, O Cotton-Barratt, 2013.) Variance normalization is strategy-proof under the assumption that everyone participating in an election shares beliefs about how probable the different outcomes are! (Note that variance of utility is only well-defined under some assumption about probability of outcome.) That's pretty good. It's probably the best we can get, in terms of strategy-proofness of voting. Will MacAskill also argues for variance normalization in the context of normative uncertainty (Normative Uncertainty, Will MacAskill, 2014).
Intuitively, variance normalization directly addresses the issue we encountered with range normalization: an individual attempts to make their preferences "loud" by extremizing everything to 0 or 1. This increases variance, so, is directly punished by variance normalization.
However, Jameson Quinn [LW · GW], LessWrong's resident voting theory expert, has warned me rather strongly about variance normalization.
- The assumption of shared beliefs about election outcomes is far from true in practice. Jameson Quinn tells me that, in fact, the strategic voting incentivized by quadratic voting is particularly bad amongst normalization techniques.
- Strategy-proofness isn't, after all, the final arbiter of the quality of a voting method. The final arbiter should be something like the utilitarian quality of an election's outcome. This question gets a bit weird and recursive in the current context, where I'm using elections as an analogy to ask how we should define utilitarian outcomes. But the point still, to some extent, stands.
I didn't understand Quinn's full justification behind his point, but I came away thinking that range normalization was probably better in practice. After all, it reduces to approval voting, which is actually a pretty good form of voting. But if you want to do the best we can with the state of voting theory, Jameson Quinn suggested 3-2-1 voting. (I don't think 3-2-1 voting gives us any nice theory about how to combine utility functions, though, so it isn't so useful for our purposes.)
Open Question: Is there a variant of variance normalization which takes differing beliefs into account, to achieve strategy-proofness (IE honest reporting of utility)?
Anyway, so much for normalization techniques. These techniques ignore the broader context. They attempt to be fair and even-handed in the way we choose the multiplicative and additive constants. But we could also explicitly try to be fair and even-handed in the way we choose between Pareto-optimal outcomes, as with this next technique.
Nash Bargaining Solution
It's important to remember that the Nash bargaining solution is a solution to the Nash bargaining problem, which isn't quite our problem here. But I'm going to gloss over that. Just imagine that we're setting the social choice function through a massive negotiation, so that we can apply bargaining theory.
Nash offers a very simple solution, which I'll get to in a minute. But first, a few words on how this solution is derived. Nash provides two seperate justifications for his solution. The first is a game-theoretic derivation of the solution as an especially robust Nash equilibrium. I won't detail that here; I quite recommend his original paper (The Bargaining Problem, 1950); but, just keep in mind that there is at least some reason to expect selfishly rational agents to hit upon this particular solution. The second, unrelated justification is an axiomatic one:
- Invariance to equivalent utility functions. This is the same motivation I gave when discussing normalization.
- Pareto optimality. We've already discussed this as well.
- Independence of Irrelevant Alternatives (IIA). This says that we shouldn't change the outcome of bargaining by removing options which won't ultimately get chosen anyway. This isn't even technically one of the VNM axioms, but it essentially is -- the VNM axioms are posed for binary preferences (a > b). IIA is the assumption we need to break down multi-choice preferences to binary choices. We can justify IIA with a kind of money pump [LW · GW].
- Symmetry. This says that the outcome doesn't depend on the order of the bargainers; we don't prefer Player 1 in case of a tie, or anything like that.
Nash proved that the only way to meet these four criteria is to maximize the product of gains from cooperation. More formally, choose the outcome which maximizes:
The here is a "status quo" outcome. You can think of this as what happens if the bargaining fails. This is sometimes called a "threat point", since strategic players should carefully set what they do if negotiation fails so as to maximize their bargaining position. However, you might also want to rule that out, forcing to be a Nash equilibrium in the hypothetical game where there is no bargaining opportunity. As such, is also known as the best alternative to negotiated agreement (BATNA), or sometimes the "disagreement point" (since it's what players get if they can't agree). We can think of subtracting out as just a way of adjusting the additive constant, in which case we really are just maximizing the product of utilities. (The BATNA point is always (0,0) after we subtract out things that way.)
The Nash solution differs significantly from the other solutions considered so far.
- Maximize the product?? Didn't Harsanyi's theorem guarantee we only need to worry about sums?
- This is the first proposal where the additive constants matter. Indeed, now the multiplicative constants are the ones that don't matter!
- Why wouldn't any utility-normalization approach satisfy those four axioms?
Last question first: how do normalization approaches violate the Nash axioms?
Well, both range normalization and variance normalization violate IIA! If you remove one of the possible outcomes, the normalization may change. This makes the social choice function display inconsistent preferences across different scenarios. (But how bad is that, really?)
As for why we can get away with maximizing the product, rather than the sum:
The Pareto-optimality of Nash's approach guarantees that it can be seen as maximizing a linear function of the individual utilities. So Harsanyi's theorem is still satisfied. However, Nash's solution points to a very specific outcome, which Harsanyi doesn't do for us.
Imagine you and me are trying to split a dollar. If we can't agree on how to split it, then we'll end up destroying it (ripping it during a desperate attempt to wrestle it from each other's hands, obviously). Thankfully, John Nash is standing by, and we each agree to respect his judgement. No matter which of us claims to value the dollar more, Nash will allocate 50 cents to each of us.
Harsanyi happens to see this exchange, and explains that Nash has chosen a social choice function which normalized our utility functions to be equal to each other. That's the only way Harsanyi can explain the choice made by Nash -- the value of the dollar was precisely tied between you and me, so a 50-50 split was as good as any other outcome. Harsanyi's justification is indeed consistent with the observation. But why, then, did Nash choose 50-50 precisely? 49-51 would have had exactly the same collective utility, as would 40-60, or any other split!
Hence, Nash's principle is far more useful than Harsanyi's, even though Harsanyi can justify any rational outcome retrospectively.
However, Nash does rely somewhat on that pesky IIA assumption, whose importance is perhaps not so clear. Let's try getting rid of that.
Kalai–Smorodinsky
Although the Nash bargaining solution is the most famous, there are other proposed solutions to Nash's bargaining problem. I want to mention just one more, Kalai-Smorodinsky (I'll call it KS).
KS throws out IIA as irrelevant. After all, the set of alternatives will affect bargaining. Even in the Nash solution, the set of alternatives may have an influence by changing the BATNA! So perhaps this assumption isn't so important.
KS instead adds a monotonicity assumption: being in a better position should never make me worse off after bargaining.
Here's an illustration, due to Daniel Demski, of a case where Nash bargaining fails monotonicity:
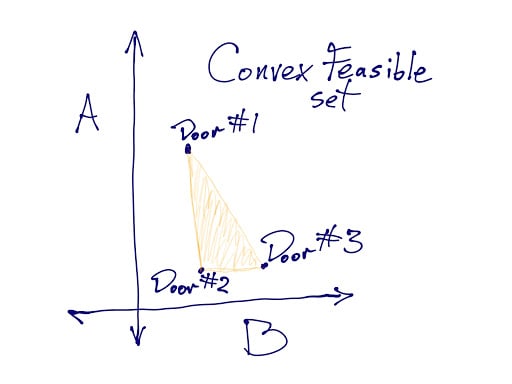
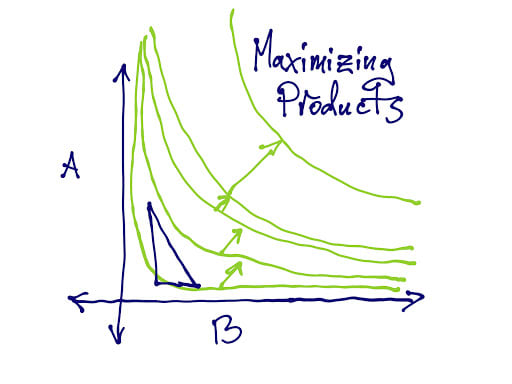
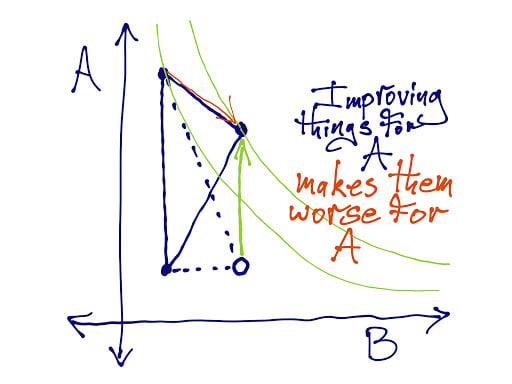
I'm not that sure monotonicity really should be an axiom, but it does kind of suck to be in an apparently better position and end up worse off for it. Maybe we could relate this to strategy-proofness? A little? Not sure about that.
Let's look at the formula for KS bargaining.
Suppose there are a couple of dollars on the ground: one which you'll walk by first, and one which I'll walk by. If you pick up your dollar, you can keep it. If I pick up my dollar, I can keep mine. But also, if you don't pick up yours, then I'll eventually walk by it and can pick it up. So we get the following:

(The box is filled in because we can also use mixed strategies to get values intermediate between any pure strategies.)
Obviously in the real world we just both pick up our dollars. But, let's suppose we bargain about it, just for fun.
The way KS works is, you look at the maximum one player can get (you can get $1), and the maximum the other player could get (I can get $2). Then, although we can't usually jointly achieve those payoffs (I can't get $2 at the same time as you get $1), KS bargaining insists we achieve the same ratio (I should get twice as much as you). In this case, that means I get $1.33, while you get $0.66. We can visualize this as drawing a bounding box around the feasible solutions, and drawing a diagonal line. Here's the Nash and KS solutions side by side:
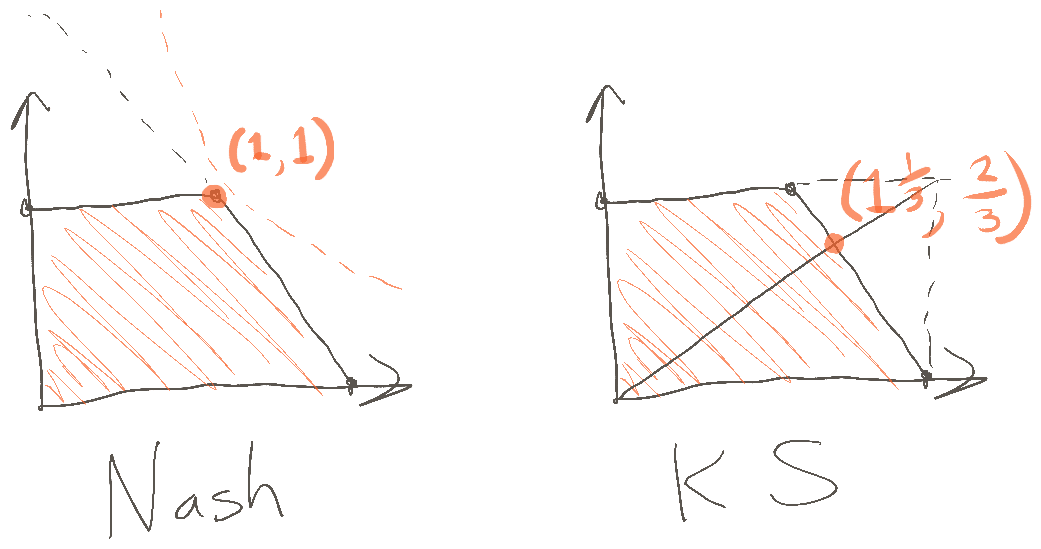
As in Daniel's illustrations, we can visualize maximizing the product as drawing the largest hyperbola we can that still touches the orange shape. (Orange dotted line.) This suggests that we each get $1; exactly the same solution as Nash would give for splitting $2. (The black dotted line illustrates how we'd continue the feasible region to represent a dollar-splitting game, getting the full triangle rather than a chopped off portion.) Nash doesn't care that one of us can do better than the other; it just looks for the most equal division of funds possible, since that's how we maximize the product.
KS, on the other hand, cares what the max possible is for both of us. It therefore suggests that you give up some of your dollar to me.
I suspect most readers will not find the KS solution to be more intuitively appealing?
Note that the KS monotonicity property does NOT imply the desirable-sounding property "if there are more opportunities for good outcomes, everyone gets more or is at least not worse off." (I mention this mainly because I initially misinterpreted KS's monotonicity property this way.) In my dollar-collecting example, KS bargaining makes you worse off simply because there's an opportunity for me to take your dollar if you don't.
Like Nash bargaining, KS bargaining ignores multiplicative constants on utility functions, and can be seen as normalizing additive constants by treating as (0,0). (Note that, in the illustration, I assumed is chosen as (minimal achievable for one player, minimal achievable for the other). this need not be the case in general.)
A peculiar aspect of KS bargaining is that it doesn't really give us an obvious quantity to maximize, unlike Nash or Harsanyi. It only describes the optimal point. This seems far less practical, for realistic decision-making.
OK, so, should we use bargaining solutions to compare utilities?
My intuition is that, because of the need to choose the BATNA point , bargaining solutions end up rewarding destructive threats in a disturbing way. For example, suppose that we are playing the dollar-splitting game again, except that I can costlessly destroy $20 of your money, so now involves both the destruction of the $1, and the destruction of $20. Nash bargaining now hands the entire dollar to me, because you are "up $20" in that deal, so the fairest possible outcome is to give me the $1. KS bargaining splits things up a little, but I still get most of the dollar.
If utilitarians were to trade off utilities that way in the real world, it would benefit powerful people, especially those willing to exploit their power to make credible threats. If X can take everything away from Y, then Nash bargaining sees everything Y has as already counting toward "gains from trade".
As I mentioned before, sometimes people try to define BATNAs in a way which excludes these kinds of threats. However, I see this as ripe for strategic utility-spoofing (IE, lying about your preferences, or self-modifying to have more advantageous preferences).
So, this might favor normalization approaches.
On the other hand, Nash and KS both do way better in the split-the-dollar game than any normalization technique, because they can optimize for fairness of outcome, rather than just fairness of multiplicative constants chosen to compare utility functions with.
Is there any approach which combines the advantages of bargaining and normalization??
Animals, etc.
An essay on utility comparison would be incomplete without at least mentioning the problem of animals, plants, and so on.
- Option one: some cutoff for "moral patients" is defined, such that a utilitarian only considers preferences of agents who exceed the cutoff.
- Option two: some more continuous notion is selected, such that we care more about some organisms than others.
Option two tends to be more appealing to me, despite the non-egalitarian implications (e.g., if animals differ on this spectrum, than humans could have some variation as well).
As already discussed, bargaining approaches do seem to have this feature: animals would tend to get less consideration, because they've got less "bargaining power" (they can do less harm to humans than humans can do to them). However, this has a distasteful might-makes-right flavor to it.
This also brings to the forefront the question of how we view something as an agent. Something like a plant might have quite deterministic ways of reacting to environmental stimulus. Can we view it as making choices, and thus, as having preferences? Perhaps "to some degree" -- if such a degree could be defined, numerically, it could factor into utility comparisons, giving a formal way of valuing plants and animals somewhat, but "not too much".
Altruistic agents.
Another puzzling case, which I think needs to be handled carefully, is accounting for the preferences of altruistic agents.
Let's proceed with a simplistic model where agents have "personal preferences" (preferences which just have to do with themselves, in some sense) and "cofrences" (co-preferences; preferences having to do with other agents).
Here's an agent named Sandy:
| Sandy | ||||
| Personal Preferences | Cofrences | |||
| Candy | +.1 | Alice | +.1 | |
| Pizza | +.2 | Bob | -.2 | |
| Rainbows | +10 | Cathy | +.3 | |
| Kittens | -20 | Dennis | +.4 | |
The cofrences represent coefficients on other agent's utility functions. Sandy's preferences are supposed to be understood as a utility function representing Sandy's personal preferences, plus a weighted sum of the utility functions of Alice, Bob, Cathy, and Dennis. (Note that the weights can, hypothetically, be negative -- for example, screw Bob.)
The first problem is that utility functions are not comparable, so we have to say more before we can understand what "weighted sum" is supposed to mean. But suppose we've chosen some utility normalization technique. There are still other problems.
Notice that we can't totally define Sandy's utility function until we've defined Alice's, Bob's, Cathy's, and Dennis'. But any of those four might have cofrences which involve Sandy, as well!
Suppose we have Avery and Briar, two lovers who "only care about each other" -- their only preference is a cofrence, which places 1.0 value on the other's utility function. We could ascribe any values at all to them, so long as they're both the same!
With some technical assumptions (something along the lines of: your cofrences always sum to less than 1), we can ensure a unique fixed point, eliminating any ambiguity from the interpretation of cofrences. However, I'm skeptical of just taking the fixed point here.
Suppose we have five siblings: Primus, Secundus, Tertius, Quartus, et Quintus. All of them value each other at .1, except Primus, who values all siblings at .2.
If we simply take the fixed point, Primus is going to get the short end of the stick all the time: because Primus cares about everyone else more, everyone else cares about Primus' personal preferences less than anyone else's.
Simply put, I don't think more altruistic individuals should be punished! In this setup, the "utility monster" is the perfectly selfish individual. Altruists will be scrambling to help this person while the selfish person does nothing in return.
A different way to do things is to interpret cofrences as integrating only the personal preferences of the other person. So Sandy wants to help Alice, Cathy, and Dennis (and harm Bob), but does not automatically extend that to wanting to help any of their friends (or harm Bob's friends).
This is a little weird, but gives us a more intuitive outcome in the case of the five siblings: Primus will more often be voluntarily helpful to the other siblings, but the other siblings won't be prejudice against the personal preferences of Primus when weighing between their various siblings.
I realize altruism isn't exactly supposed to be like a bargain struck between selfish agents. But if I think of utilitarianism like a coalition of all agents, then I don't want it to punish the (selfish component of) the most altruistic members. It seems like utilitarianism should have better incentives than that?
(Try to take this section as more of a problem statement and less of a solution. Note that the concept of cofrence can include, more generally, preferences such as "I want to be better off than other people" or "I don't want my utility to be too different from other people's in either direction".)
Utility monsters.
Returning to some of the points I raised in the "non-obvious consequences" section -- now we can see how "utility monsters" are/aren't a concern.
On my analysis, a utility monster is just an agent who, according to your metric for comparing utility functions, has a very large influence on the social choice function.
This might be a bug, in which case you should reconsider how you are comparing utilities. But, since you've hopefully chosen your approach carefully, it could also not be a bug. In that case, you'd want to bite the bullet fully, defending the claim that such an agent should receive "disproportionate" consideration. Presumably this claim could be backed up, on the strength of your argument for the utility-comparison approach.
Average utilitarianism vs total utilitarianism.
Now that we have given some options for utility comparison, can we use them to make sense of the distinction between average utilitarianism and total utilitarianism?
No. Utility comparison doesn't really help us there.
The average vs total debate is a debate about population ethics. Harsanyi's utilitarianism theorem and related approaches let us think about altruistic policies for a fixed set of agents. They don't tell us how to think about a set which changes over time, as new agents come into existence.
Allowing the set to vary over time like this feels similar to allowing a single agent to change its utility function. There is no rule against this. An agent can prefer to have different preferences than it does. A collective of agents can prefer to extend its altruism to new agents who come into existence.
However, I see no reason why population ethics needs to be simple. We can have relatively complex preferences here. So, I don't find paradoxes such as the Repugnant Conclusion to be especially concerning. To me there's just this complicated question about what everyone collectively wants for the future.
One of the basic questions about utilitarianism shouldn't be "average vs total?". To me, this is a type error. It seems to me, more basic questions for a (preference) utilitarian are:
- How do you combine individual preferences into a collective utility function?
- How do you compare utilities between people (and animals, etc)?
- Do you care about an "objective" solution to this, or do you see it as a subjective aspect of altruistic preferences, which can be set in an unprincipled way?
- Do you range-normalize?
- Do you variance-normalize?
- Do you care about strategy-proofness?
- How do you evaluate the bargaining framing? Is it relevant, or irrelevant?
- Do you care about Nash's axioms?
- Do you care about monotonicity?
- What distinguishes humans from animals and plants, and how do you use it in utility comparison? Intelligence? Agenticness? Power? Bargaining position?
- How do you handle cofrences?
- How do you compare utilities between people (and animals, etc)?
*: Agents need not have a concept of outcome, in which case they don't really have a utility function [LW · GW] (because utility functions are functions of outcomes). However, this does not significantly impact any of the points made in this post.
31 comments
Comments sorted by top scores.
comment by Vanessa Kosoy (vanessa-kosoy) · 2020-09-16T11:09:26.028Z · LW(p) · GW(p)
I suspect most readers will not find the KS solution to be more intuitively appealing?
The problem in your example is that you failed to identify a reasonable disagreement point. In the situation you described is the disagreement point since every agent can guarantee emself a payoff of unilaterally, so the KS solution is also (since the disagreement point is already on the Pareto frontier).
In general it is not that obvious what the disagreement point should be, but maximin payoffs is one natural choice. Nash equilibrium is the obvious alternative, but it's not clear what to do if we have several.
For applications such as voting and multi-user AI alignment that's less natural since, even if we know the utility functions, it's not clear what action spaces should we consider. In that case a possible choice of disagreement point is maximizing the utility of a randomly chosen participant. If the problem can be formulated as partitioning resources, then the uniform partition is another natural choice.
Replies from: abramdemski↑ comment by abramdemski · 2020-09-16T16:47:35.588Z · LW(p) · GW(p)
The problem in your example is that you failed to identify a reasonable disagreement point.
Ahh, yeahh, that's a good point.
comment by Slider · 2020-09-16T13:48:38.315Z · LW(p) · GW(p)
This jumps from mathematical consistency to a kind of opinion when pareto improvement enters the picture. Sure if we have choice between two social policies and everyone prefers one over the other because their personal lot is better there is no conflict on the order. This could be warranted if for some reason we needed consensus to get a "thing passed". However where there is true conflict it seems to say that a "good" social policy can't be formed.
To be somewhat analogous with "utility monster", construct a "consensus spoiler". He exactly prefers what everyone anti-prefers, having a coference of -1 for everyone. If someone would gain something he is of the opinion that he losses. So no pareto improvements are possible. If you have a community of 100 agents that would agree to pick some states over others and construct a new comunity of 101 with the consensus spoiler then they can't form any choice function. The consensus spoiler is in effect maximally antagonistic towards everything else. The question whether it is warranted, allowed or forbidden that the coalition of 100 just proceeds with the policy choice that screws the spoiler over doesn't seem to be a mathematical kind of claim.
And even in the less extreme degree I don't get how you could use this setup to judge values that are in conflict. And if you encounter a unknown agent it seems it is ambigious whether you should take heed of its values in compromise or just treat it as a possible enemy and just adhere to your personal choices.
Replies from: abramdemski↑ comment by abramdemski · 2020-09-16T16:17:44.127Z · LW(p) · GW(p)
Yeah, I like your "consensus spoiler". Maybe needs a better name, though... "Contrarian Monster"?
having a coference of -1 for everyone.
This way of defining the Consensus Spoiler seems needlessly assumption-heavy, since it assumes not only that we can already compare utilities in order to define this perfect antagonism, but furthermore that we've decided how to deal with cofrences.
A similar option with a little less baggage is to define it as having the opposite of the preferences of our social choice function. They just hate whatever we end up choosing to represent the group's preferences.
A simpler option is just to define the Contrarian Monster as having opposite preferences from one particular member of the collective. (Any member will do.) This ensures that there can be no Pareto improvements.
If you have a community of 100 agents that would agree to pick some states over others and construct a new comunity of 101 with the consensus spoiler then they can't form any choice function.
Actually, the conclusion is that you can form any social choice function. Everything is "Pareto optimal".
The question whether it is warranted, allowed or forbidden that the coalition of 100 just proceeds with the policy choice that screws the spoiler over doesn't seem to be a mathematical kind of claim.
If we think of it as bargaining to form a coalition, then there's never any reason to include the Spoiler in a coalition (especially if you use the "opposite of whatever the coalition wants" version). In fact, there is a version of Harsanyi's theorem which allows for negative weights, to allow for this -- giving an ingroup/outgroup sort of thing. Usually this isn't considered very seriously for definitions of utilitarianism. But it could be necessary in extreme cases.
(Although putting zero weight on it seems sufficient, really.)
And even in the less extreme degree I don't get how you could use this setup to judge values that are in conflict.And if you encounter a unknown agent it seems it is ambigious whether you should take heed of its values in compromise or just treat it as a possible enemy and just adhere to your personal choices.
Pareto-optimality doesn't really give you the tools to mediate conflicts, it's just an extremely weak condition on how you do so, which says essentially that we shouldn't put negative weight on anyone.
Granted, the Consensus Spoiler is an argument that Pareto-optimality may not be weak enough, in extreme situations.
Replies from: Slider↑ comment by Slider · 2020-09-16T20:54:31.565Z · LW(p) · GW(p)
"Contrarian" is a good adjective on it. I don't think it makes anyone suffer so "monster" is only reference to utility monster but the general class of "conceptual tripstones" being called "monster" doesn't seem the most handy.
If the particular members is ambivalent about something then there might still be room to weak pareto improve along that axis. Totally opposed ambivalence is ambivalence.
There is a slight circularity in that if the definition what the agent wants rests on what the social choice is going to be it can seem a bit unfair. If it can be "fixed in advance" then allowed attempts to make a social choice function is fairer. It seems that if we can make a preference then the preference in the other direction should be able to exist as well. If there are more state pairs to prefer over than agents then the Diagonal Opposer could be constructed by pairing each state pair with an agent and taking the antipreference of that. One conception would be Public Enemy - no matter who else you are, you are enemies with this agent, you have atleast 1 preference in the opposite direction. There are many ways to construct a public enemy. And it might be that there are public enemies that 1 on 1 are only slight enemies to agent but are in conflict over more points with what the other agents would have formed as social choice. Say there are yes and no questions over A, B and C. Other agents answer to two yes and to one no. Then answering all in yes would leave all in 2/3 agreement. But a stance of all no is in 3/3 disagreement over the compromise despite being only 2/3 disagreement with individual agents.
I thought that the end result is that since any change would not be a pareto improvement the function can't recommend any change so it must be completely ambivalent about everything thus is the constant function of every option being of utility 0.
Pareto-optimality says that if there is a mass murderer that wants to kill as many people as possible then you should not do a choice that lessens the amount of people killed ie you should not oppose the mass murderer.
Replies from: abramdemski↑ comment by abramdemski · 2020-09-16T22:43:51.682Z · LW(p) · GW(p)
I thought that the end result is that since any change would not be a pareto improvement the function can't recommend any change so it must be completely ambivalent about everything thus is the constant function of every option being of utility 0.
Pareto-optimality says that if there is a mass murderer that wants to kill as many people as possible then you should not do a choice that lessens the amount of people killed ie you should not oppose the mass murderer.
Ah, I should have made more clear that it's a one-way implication: if it's a Pareto improvement, then the social choice function is supposed to prefer it. Not the other way around.
A social choice function meeting that minimal requirement can still do lots of other things. So it could still oppose a mass murderer, so long as mass-murder is not itself a Pareto improvement.
comment by evhub · 2020-09-16T19:39:55.020Z · LW(p) · GW(p)
If we simply take the fixed point, Primus is going to get the short end of the stick all the time: because Primus cares about everyone else more, everyone else cares about Primus' personal preferences less than anyone else's.
Simply put, I don't think more altruistic individuals should be punished! In this setup, the "utility monster" is the perfectly selfish individual. Altruists will be scrambling to help this person while the selfish person does nothing in return.
I'm not sure why you think this is a problem. Supposing you want to satisfy the group's preferences as much as possible, shouldn't you care about Primus less since Primus will be more satisfied just from you helping the others? I agree that this can create perverse incentives in practice, but that seems like the sort of thing that you should be handling as part of your decision theory, not your utility function.
A different way to do things is to interpret cofrences as integrating only the personal preferences of the other person.
I feel like the solution of having cofrences not count the other person's cofrences just doesn't respect people's preferences—when I care about the preferences of somebody else, that includes caring about the preferences of the people they care about. It seems like the natural solution to this problem is to just cut things off when you go in a loop—but that's exactly what taking the fixed point does, which seems to reinforce the fixed point as the right answer here.
Replies from: abramdemski↑ comment by abramdemski · 2020-09-16T20:32:07.357Z · LW(p) · GW(p)
I agree that this can create perverse incentives in practice, but that seems like the sort of thing that you should be handling as part of your decision theory, not your utility function.
I'm mainly worried about the perverse incentives part.
I recognize that there's some weird level-crossing going on here, where I'm doing something like mixing up the decision theory and the utility function. But it seems to me like that's just a reflection of the weird muddy place our values come from?
You can think of humans a little like self-modifying AIs, but where the modification took place over evolutionary history. The utility function which we eventually arrived at was (sort of) the result of a bargaining process between everyone, and which took some accounting of things like exploitability concerns.
In terms of decision theory, I often think in terms of a generalized NicerBot: extend everyone else the same cofrence-coefficient they extend to you, plus an epsilon (to ensure that two generalized NicerBots end up fully cooperating with each other). This is a pretty decent strategy for any game, generalizing from one of the best strategies for Prisoner's Dilemma. (Of course there is no "best strategy" in an objective sense.)
But a decision theory like that does mix levels between the decision theory and the utility function!
I feel like the solution of having cofrences not count the other person's cofrences just doesn't respect people's preferences—when I care about the preferences of somebody else, that includes caring about the preferences of the people they care about.
I totally agree with this point; I just don't know how to balance it against the other point.
A crux for me is the coalition metaphor for utilitarianism. I think of utilitarianism as sort of a natural endpoint of forming beneficial coalitions, where you've built a coalition of all life.
If we imagine forming a coalition incrementally, and imagine that the coalition simply averages utility functions with its new members, then there's an incentive to join the coalition as late as you can, so that your preferences get the largest possible representation. (I know this isn't the same problem we're talking about, but I see it as analogous, and so a point in favor of worrying about this sort of thing.)
We can correct that by doing 1/n averaging: every time the coalition gains members, we make a fresh average of all member utility functions (using some utility-function normalization, of course), and everybody voluntarily self-modifies to have the new mixed utility function.
But the problem with this is, we end up punishing agents for self-modifying to care about us before joining. (This is more closely analogous to the problem we're discussing.) If they've already self-modified to care about us more before joining, then their original values just get washed out even more when we re-average everyone.
So really, the implicit assumption I'm making is that there's an agent "before" altruism, who "chose" to add in everyone's utility functions. I'm trying to set up the rules to be fair to that agent, in an effort to reward agents for making "the altruistic leap".
Replies from: evhub↑ comment by evhub · 2020-09-16T21:28:46.501Z · LW(p) · GW(p)
But a decision theory like that does mix levels between the decision theory and the utility function!
I agree, though it's unclear whether that's an actual level crossing or just a failure of our ability to be able to properly analyze that strategy. I would lean towards the latter, though I am uncertain.
A crux for me is the coalition metaphor for utilitarianism. I think of utilitarianism as sort of a natural endpoint of forming beneficial coalitions, where you've built a coalition of all life.
This is how I think about preference utilitarianism but not how I think about hedonic utilitarianism—for example, a lot of what I value personally is hedonic-utilitarianism-like, but from a social perspective, I think preference utilitarianism is a good Schelling point for something we can jointly agree on. However, I don't call myself a preference utilitarian—rather, I call myself a hedonic utilitarian—because I think of social Schelling points and my own personal values as pretty distinct objects. And I could certainly imagine someone who terminally valued preference utilitarianism from a personal perspective—which is what I would call actually being a preference utilitarian.
Furthermore, I think that if you're actually a preference utilitarian vs. if you just think preference utilitarianism is a good Schelling point, then there are lots of cases where you'll do different things. For example, if you're just thinking about preference utilitarianism as a useful Schelling point, then you want to carefully consider the incentives that it creates—such as the one that you're pointing to—but if you terminally value preference utilitarianism, then that seems like a weird thing to be thinking about, since the question you should be thinking about in that context should be more like what is it about preferences that you actually value and why.
If we imagine forming a coalition incrementally, and imagine that the coalition simply averages utility functions with its new members, then there's an incentive to join the coalition as late as you can, so that your preferences get the largest possible representation. (I know this isn't the same problem we're talking about, but I see it as analogous, and so a point in favor of worrying about this sort of thing.)
We can correct that by doing 1/n averaging: every time the coalition gains members, we make a fresh average of all member utility functions (using some utility-function normalization, of course), and everybody voluntarily self-modifies to have the new mixed utility function.
One thing I will say here is that usually when I think about socially agreeing on a preference utilitarian coalition, I think about doing so from more of a CEV standpoint, where the idea isn't just to integrate the preferences of agents as they currently are, but as they will/should be from a CEV perspective. In that context, it doesn't really make sense to think about incremental coalition forming, because your CEV (mostly, with some exceptions) should be the same regardless of what point in time you join the coalition.
But the problem with this is, we end up punishing agents for self-modifying to care about us before joining. (This is more closely analogous to the problem we're discussing.) If they've already self-modified to care about us more before joining, then their original values just get washed out even more when we re-average everyone.
I guess this just seems like the correct outcome to me. If you care about the values of the coalition, then the coalition should care less about your preferences, because they can partially satisfy them just by doing what the other people in the coalition want.
So really, the implicit assumption I'm making is that there's an agent "before" altruism, who "chose" to add in everyone's utility functions. I'm trying to set up the rules to be fair to that agent, in an effort to reward agents for making "the altruistic leap".
It certainly makes sense to reward agents for choosing to instrumentally value the coalition—and I would include instrumentally choosing to self-modify yourself to care more about the coalition in that—but I'm not sure why it makes sense to reward agents for terminally valuing the coalition—that is, terminally valuing the coalition independently of any decision theoretic considerations that might cause you to instrumentally modify yourself to do so.
Again, I think this makes more sense from a CEV perspective—if you instrumentally modify yourself to care about the coalition for decision-theoretic reasons, that might change your values, but I don't think that it should change your CEV. In my view, your CEV should be about your general strategy for how to self-modify yourself in different situations rather than the particular incarnation of you that you've currently modified to.
comment by Dagon · 2020-09-15T17:15:39.213Z · LW(p) · GW(p)
This could (should?) also make you suspicious of talk of "average utilitarianism" and "total utilitarianism". However, beware: only one kind of "utilitarianism" holds that the term "utility" in decision theory means the same thing as "utility" in ethics: namely, preference utilitarianism.
Ok, I'm suspicious of preference utilitarianism which requires aggregation across entities. And suspicious of other kinds because they mean something else by "utility". Then you show that there are aggregate functions that have some convenient properties. But why does that resolve my suspicion?
What makes any of these social choice functions any more valid than any other assumption about other people's utility transformations? The pareto-optimal part is fine, as they are compatible with all transformations - they work for ordinal incommensurate preferences. So they're trivial and boring. But once you talk about bargaining and " the relative value of one person's suffering vs another person's convenience ", you're back on shaky ground.
The incomparability of utility functions doesn't mean we can't trade off between the utilities of different people.
We can prefer whatever we want, we can make all sorts of un-justified comparisons. But it DOES MEAN that we can't claim to be justified in violating someone's preferences just because we picked an aggregation function that says so.
We just need more information. ... we need more assumptions ...
I think it's _far_ more the second than the first. There is no available information that makes these comparisons/aggregations possible. We can make assumptions and do it, but I wish you'd be more explicit in what is the minimal assumption set required, and provide some justification for the assumptions (other than "it enables us to aggregate in ways that I like").
Replies from: abramdemski↑ comment by abramdemski · 2020-09-15T20:08:45.914Z · LW(p) · GW(p)
Ok, I'm suspicious of preference utilitarianism which requires aggregation across entities. And suspicious of other kinds because they mean something else by "utility". Then you show that there are aggregate functions that have some convenient properties. But why does that resolve my suspicion?
I think the Pareto-optimality part is really where this gets off the ground.
Let's say,
- You're altruistic enough to prefer Pareto improvements with respect to everyone's preferences.
- You want to make choices in a way that respects the VNM axioms.
Then we must be able to interpret your decisions as that of a preference utilitarian who has chosen some specific way to add up everyone's utility functions (IE, has determined multiplicative constants whereby to trade off between people).
After that, it's "just" a question of setting the constants. (And breaking ties, as in the dollar-splitting example where illustrated how the Harsanyi perspective isn't very useful.)
So once you're on board with the Pareto-improvement part, you have to start rejecting axioms of individual rationality in order to avoid becoming a preference-utilitarian.
What makes any of these social choice functions any more valid than any other assumption about other people's utility transformations? The pareto-optimal part is fine, as they are compatible with all transformations - they work for ordinal incommensurate preferences. So they're trivial and boring. But once you talk about bargaining and " the relative value of one person's suffering vs another person's convenience ", you're back on shaky ground.
For example, if you refuse to trade off between people's ordinal incommensurate preferences, then you just end up refusing to have an opinion when you try to choose between charity A which saves a few lives in Argentina vs charity B which saves many lives in Brazil. (You can't calculate an expected utility, since you can't compare the lives of different people.) So you can end up in a situation where you do nothing, even though you strictly prefer to put your money in either one charity or the other, because your principles refuse to make a comparison, so you can't choose between the two.
Replies from: Dagon↑ comment by Dagon · 2020-09-15T22:14:06.567Z · LW(p) · GW(p)
altruistic enough to prefer Pareto improvements with respect to everyone's preferences.
Wait, what? Altruism has nothing to do with it. Everyone is supportive of (or indifferent to) any given Pareto improvement because it increases (or at least does not reduce) their utility. Pareto improvements provide no help in comparing utility because they are cases where there is no conflict among utility functions. Every multiplicative or additive transform across utility functions remains valid for Pareto improvements.
For example, if you refuse to trade off between people's ordinal incommensurate preferences, then you just end up refusing to have an opinion when you try to choose between charity A which saves a few lives in Argentina vs charity B which saves many lives in Brazil.
I don't refuse to have an opinion, I only refuse to claim that that it's anything but my preferences which form that opinion. My opinion is about my (projected) utility from the saved or unsaved lives. That _may_ include my perception of their satisfaction (or whatever observable property I choose), but it does not have any access to their actual preference or utility.
Replies from: abramdemski↑ comment by abramdemski · 2020-09-16T16:43:07.148Z · LW(p) · GW(p)
Wait, what? Altruism has nothing to do with it. Everyone is supportive of (or indifferent to) any given Pareto improvement because it increases (or at least does not reduce) their utility.
I grant that this is not very altruistic at all, but it is possible to be even less altruistic: I could only support Pareto improvements which I benefit from. This is sorta the default.
The Pareto-optimality assumption isn't that you're "just OK" with Pareto-improvements, in a sense. The assumption is that you prefer them, ie, .
I don't refuse to have an opinion, I only refuse to claim that that my opinion is about their preferences/utility.
If you accept the Pareto-optimality assumption, and you accept the rationality assumptions with respect to your choices, then by Harsanyi's theorem you've gotta make an implicit trade-off between other people's preferences.
My opinion is about my (projected) utility from the saved or unsaved lives.
So you've got some way to trade off between saving different lives.
That _may_ include my perception of their satisfaction (or whatever observable property I choose), but it does not have any access to their actual preference or utility.
It sounds like your objection here is "I don't have any access to their actual preferences".
I agree that the formal model assumes access to the preferences. But I don't think a preference utilitarian needs access. You can be coherently trying to respect other people's preferences without knowing exactly what they are. You can assent to the concept of Pareto improvements as an idealized decision theory [LW · GW] which you aspire to approximate. I think this can be a very fruitful way of thinking, even though it's good to also track reality as distinct from the idealization. (We already have to make such idealizations to think "utility" is relevant to our decision-making at all.)
The point of the Harsanyi argument is that if you assent to Pareto improvements as something to aspire to, and also assent to VNM as something to aspire to, then you must assent to a version of preference utilitarianism as something to aspire to.
Replies from: Dagon↑ comment by Dagon · 2020-09-16T17:52:36.705Z · LW(p) · GW(p)
The Pareto-optimality assumption isn't that you're "just OK" with Pareto-improvements, in a ≥ sense. The assumption is that you prefer them, ie, >.
That's not what Pareto-optimality asserts. It only talks about >= for all participants individually. If you're making assumptions about altruism, you should be clearer that it's an arbitrary aggregation function that is being increased.
And then, Pareto-optimality is a red herring. I don't know of any aggregation functions that would change a 0 to a + for a Pareto-optimal change, and would not give a + to some non-Pareto-optimal changes, which violate other agents' preferences.
My primary objection is that any given aggregation function is itself merely a preference held by the evaluator. There is no reason to believe that there is a justifiable-to-assume-in-others or automatically-agreeable aggregation function.
if you assent to Pareto improvements as something to aspire to
This may be the crux. I do not assent to that. I don't even think it's common. Pareto improvements are fine, and some of them actually improve my situation, so go for it! But in the wider sense, there are lots of non-Pareto changes that I'd pick over a Pareto subset of those changes. Pareto is a min-bar for agreement, not an optimum for any actual aggregation function.
I should probably state what function I actually use (as far as I can tell). I do not claim universality, and in fact, it's indexed based on non-replicable factors like my level of empathy for someone. I do not include their preferences (because I have no access). I don't even include my prediction of their preferences. I DO include my preferences for what (according to my beliefs) they SHOULD prefer, which in a lot of cases correlates closely enough with their actual preferences that I can pass as an altruist. I then weight my evaluation of those imputed-preferences by something like an inverse-square relationship of "empathetic distance". People closer to me (including depth and concreteness of my model for them, how much I like them, and likely many other factors I can't articulate), including imaginary and future people who I feel close to get weighted much much higher than more distant or statistical people.
I repeat - this is not normative. I deny that there exists a function which everyone "should" use. This is merely a description of what I seem to do.
Replies from: abramdemski↑ comment by abramdemski · 2020-09-16T21:07:33.962Z · LW(p) · GW(p)
You said:
That's not what Pareto-optimality asserts. It only talks about >= for all participants individually.
From wikipedia:
Given an initial situation, a Pareto improvement is a new situation where some agents will gain, and no agents will lose.
So a pareto improvement is a move that is > for at least one agent, and >= for the rest.
If you're making assumptions about altruism, you should be clearer that it's an arbitrary aggregation function that is being increased.
I stated that the setup is to consider a social choice function (a way of making decisions which would "respect everyone's preferences" in the sense of regarding pareto improvements as strict preferences, ie, >-type preferences).
Perhaps I didn't make clear that the social choice function should regard Pareto improvements as strict preferences. But this is the only way to ensure that you prefer the Pareto improvement and not the opposite change (which only makes things worse).
And then, Pareto-optimality is a red herring. I don't know of any aggregation functions that would change a 0 to a + for a Pareto-optimal change, and would not give a + to some non-Pareto-optimal changes, which violate other agents' preferences.
Exactly. That's, like, basically the point of the Harsanyi theorem right there. If your social choice function respects Pareto optimality and rationality, then it's forced to also make some trade-offs -- IE, give a + to some non-Pareto changes.
(Unless you're in a degenerate case, EG, everyone already has the same preferences.)
I feel as if you're denying my argument by... making my argument.
My primary objection is that any given aggregation function is itself merely a preference held by the evaluator. There is no reason to believe that there is a justifiable-to-assume-in-others or automatically-agreeable aggregation function.
I don't believe I ever said anything about justifying it to others.
I think one possible view is that every altruist could have their own personal aggregation function.
There's still a question of which aggregation function to choose, what properties you might want it to have, etc.
But then, many people might find the same considerations persuasive. So I see nothing against people working together to figure out what "the right aggregation function" is, either.
This may be the crux. I do not assent to that. I don't even think it's common.
OK! So that's just saying that you're not interested in the whole setup. That's not contrary to what I'm trying to say here -- I'm just trying to say that if an agent satisfies the minimal altruism assumption of preferring Pareto improvements, then all the rest.
If you're not at all interested in the utilitarian project, that's fine, other people can be interested.
Pareto improvements are fine, and some of them actually improve my situation, so go for it! But in the wider sense, there are lots of non-Pareto changes that I'd pick over a Pareto subset of those changes.
Again, though, now it just seems like you're stating my argument.
Weren't you just criticizing the kind of aggregation I discussed for assenting to Pareto improvements but inevitably assenting to non-Pareto-improvements as well?
Pareto is a min-bar for agreement, not an optimum for any actual aggregation function.
My section on Pareto is literally titled "Pareto-Optimality: The Minimal Standard"
I'm feeling a bit of "are you trolling me" here.
You've both denied and asserted both the premises and the conclusion of the argument.
All in the same single comment.
Replies from: Dagon↑ comment by Dagon · 2020-09-16T21:32:10.800Z · LW(p) · GW(p)
I'm feeling a bit of "are you trolling me" here.
Me too! I'm having trouble seeing how that version of the pareto-preference assumption isn't already assuming what you're trying to show, that there is a universally-usable social aggregation function. Or maybe I misunderstand what you're trying to show - are you claiming that there is a (or a family of) aggregation function that are privileged and should be used for Utilitarian/Altruistic purposes?
So a pareto improvement is a move that is > for at least one agent, and >= for the rest.
Agreed so far. And now we have to specify which agent's preferences we're talking about when we say "support". If it's > for the agent in question, they clearly support it. If it's =, they don't oppose it, but don't necessarily support it.
The assumption I missed was that there are people who claim that a change is = for them, but also they support it. I think that's a confusing use of "preferences". If it's =, that strongly implies neutrality (really, by definition of preference utility), and "active support" strongly implies > (again, that's the definition of preference). I still think I'm missing an important assumption here, and that's causing us to talk past each other.
When I say "Pareto optimality is min-bar for agreement", I'm making a distinction between literal consensus, where all agents actually agree to a change, and assumed improvement, where an agent makes a unilateral (or population-subset) decision, and justifies it based on their preferred aggregation function. Pareto optimality tells us something about agreement. It tells us nothing about applicability of any possible aggregation function.
In my mind, we hit the same comparability problem for Pareto vs non-Pareto changes. Pareto-optimal improvements, which require zero interpersonal utility comparisons (only the sign matters, not the magnitude, of each affected entity's preference), teach us nothing about actual tradeoffs, where a function must weigh the magnitudes of multiple entities' preferences against each other.
Replies from: abramdemski↑ comment by abramdemski · 2020-09-16T22:39:07.381Z · LW(p) · GW(p)
Me too! I'm having trouble seeing how that version of the pareto-preference assumption isn't already assuming what you're trying to show, that there is a universally-usable social aggregation function.
I'm not sure what you meant by "universally usable", but I don't really argue anything about existence, only what it has to look like if it exists. It's easy enough to show existence, though; just take some arbitrary sum over utility functions.
Or maybe I misunderstand what you're trying to show - are you claiming that there is a (or a family of) aggregation function that are privileged and should be used for Utilitarian/Altruistic purposes?
Yep, at least in some sense. (Not sure how "privileged" they are in your eyes!) What the Harsanyi Utilitarianism Theorem shows is that linear aggregations are just such a distinguished class.
And now we have to specify which agent's preferences we're talking about when we say "support".
[...]
The assumption I missed was that there are people who claim that a change is = for them, but also they support it. I think that's a confusing use of "preferences".
That's why, in the post, I moved to talking about "a social choice function" -- to avert that confusion.
So we have people, who are what we define Pareto-improvement over, and then we have the social choice function, which is what we suppose must > every Pareto improvement.
Then we prove that the social choice function must act like it prefers some weighted sum of the people's utility functions.
But this really is just to avert a confusion. If we get someone to assent to both VNM and strict preference of Pareto improvements, then we can go back and say "by the way, the social choice function was secretly you" because that person meets the conditions of the argument.
There's no contradiction because we're not secretly trying to sneak in a =/> shift; the person has to already prefer for Pareto improvements to happen.
If it's > for the agent in question, they clearly support it. If it's =, they don't oppose it, but don't necessarily support it.
Right, so, if we're applying this argument to a person rather than just some social choice function, then it has to be > in all cases.
If you imagine that you're trying to use this argument to convince someone to be utilitarian, this is the step where you're like "if it doesn't make any difference to you, but it's better for them, then wouldn't you prefer it to happen?"
Yes, it's trivially true that if it's = for them then it must not be >. But humans aren't perfectly reflectively consistent. So, what this argument step is trying to do is engage with the person's intuitions about their preferences. Do they prefer to make a move that's (at worst) costless to them and which is beneficial to someone else? If yes, then they can be engaged with the rest of the argument.
To put it a different way: yes, we can't just assume that an agent strictly prefers for all Pareto-improvements to happen. But, we also can't just assume that they don't, and dismiss the argument on those grounds. That agent should figure out for itself whether it has a strict preference in favor of Pareto improvements.
When I say "Pareto optimality is min-bar for agreement", I'm making a distinction between literal consensus, where all agents actually agree to a change, and assumed improvement, where an agent makes a unilateral (or population-subset) decision, and justifies it based on their preferred aggregation function. Pareto optimality tells us something about agreement. It tells us nothing about applicability of any possible aggregation function.
Ah, ok. I mean, that makes perfect sense to me and I agree. In this language, the idea of the Pareto assumption is that an aggregation function should at least prefer things which everyone agrees about, whatever else it may do.
In my mind, we hit the same comparability problem for Pareto vs non-Pareto changes. Pareto-optimal improvements, which require zero interpersonal utility comparisons (only the sign matters, not the magnitude, of each affected entity's preference), teach us nothing about actual tradeoffs, where a function must weigh the magnitudes of multiple entities' preferences against each other.
The point of the Harsanyi theorem is sort of that they say surprisingly much. Particularly when coupled with a VNM rationality assumption.
Replies from: Dagon↑ comment by Dagon · 2020-09-16T23:13:01.466Z · LW(p) · GW(p)
I follow a bit more, but I still feel we've missed a step in stating whether it's "a social choice function, which each agent has as part of it's preference set", or "the social choice function, shared across agents somehow". I think we're agreed that there are tons of rational social choice functions, and perhaps we're agreed that there's no reason to expect different individuals to have the same weights for the same not-me actors.
I'm not sure I follow that it has to be linear - I suspect higher-order polynomials will work just as well. Even if linear, there are a very wide range of transformation matrices that can be reasonably chosen, all of which are compatible with not blocking Pareto improvements and still not agreeing on most tradeoffs.
If you imagine that you're trying to use this argument to convince someone to be utilitarian, this is the step where you're like "if it doesn't make any difference to you, but it's better for them, then wouldn't you prefer it to happen?"
Now I'm lost again. "you should have a preference over something where you have no preference" is nonsense, isn't it? Either the someone in question has a utility function which includes terms for (their beliefs about) other agents' preferences (that is, they have a social choice function as part of their preferences), in which case the change will ALREADY BE positive for their utility, or that's already factored in and that's why it nets to neutral for the agent, and the argument is moot. In either case, the fact that it's a Pareto improvement is irrelevant - they will ALSO be positive about some tradeoff cases, where their chosen aggregation function ends up positive. There is no social aggregation function that turns a neutral into a positive for Pareto choices, and fails to turn a non-Pareto case into a positive.
To me, the premise seems off - I doubt the target of the argument is understanding what "neutral" means in this discussion, and is not correctly identifying a preference for pareto options. Or perhaps prefers them for the beauty and simplicy of them, and that doesn't extend to other decisions.
If you're just saying "people don't understand their own utility functions very well, and this is an intuition pump to help them see this aspect", that's fine, but "theorem" implies something deeper than that.
Replies from: abramdemski↑ comment by abramdemski · 2020-09-18T15:34:30.700Z · LW(p) · GW(p)
I'm not sure I follow that it has to be linear - I suspect higher-order polynomials will work just as well. Even if linear, there are a very wide range of transformation matrices that can be reasonably chosen, all of which are compatible with not blocking Pareto improvements and still not agreeing on most tradeoffs.
Well, I haven't actually given the argument that it has to be linear. I've just asserted that there is one, referencing Harsanyi and complete class arguments. There are a variety of related arguments. And these arguments have some assumptions which I haven't been emphasizing in our discussion.
Here's a pretty strong argument (with correspondingly strong assumptions).
- Suppose each individual is VNM-rational.
- Suppose the social choice function is VNM-rational.
- Suppose that we also can use mixed actions, randomizing in a way which is independent of everything else.
- Suppose that the social choice function has a strict preference for every Pareto improvement.
- Also suppose that the social choice function is indifferent between two different actions if every single individual is indifferent.
- Also suppose the situation gives a nontrivial choice with respect to every individual; that is, no one is indifferent between all the options.
By VNM, each individual's preferences can be represented by a utility function, as can the preferences of the social choice function.
Imagine actions as points in preference-space, an n-dimensional space where n is the number of individuals.
By assumption #5, actions which map to the same point in preference-space must be treated the same by the social choice function. So we can now imagine the social choice function as a map from R^n to R.
VNM on individuals implies that the mixed action p * a1 + (1-p) * a2 is just the point p of the way on a line between a1 and a2.
VNM implies that the value the social choice function places on mixed actions is just a linear mixture of the values of pure actions. But this means the social choice function can be seen as an affine function from R^n to R. Of course since utility functions don't mind additive constants, we can subtract the value at the origin to get a linear function.
But remember that points in this space are just vectors of individual's utilities for an action. So that means the social choice function can be represented as a linear function of individual's utilities.
So now we've got a linear function. But I haven't used the pareto assumption yet! That assumption, together with #6, implies that the linear function has to be increasing in every individual's utility function.
Now I'm lost again. "you should have a preference over something where you have no preference" is nonsense, isn't it? Either the someone in question has a utility function which includes terms for (their beliefs about) other agents' preferences (that is, they have a social choice function as part of their preferences), in which case the change will ALREADY BE positive for their utility, or that's already factored in and that's why it nets to neutral for the agent, and the argument is moot.
[...]
If you're just saying "people don't understand their own utility functions very well, and this is an intuition pump to help them see this aspect", that's fine, but "theorem" implies something deeper than that.
Indeed, that's what I'm saying. I'm trying to separately explain the formal argument, which assumes the social choice function (or individual) is already on board with Pareto improvements, and the informal argument to try to get someone to accept some form of preference utilitarianism, in which you might point out that Pareto improvements benefit others at no cost (a contradictory and pointless argument if the person already has fully consistent preferences, but an argument which might realistically sway somebody from believing that they can be indifferent about a Pareto improvement to believing that they have a strict preference in favor of them).
But the informal argument relies on the formal argument.
Replies from: Dagon↑ comment by Dagon · 2020-09-18T21:28:51.161Z · LW(p) · GW(p)
Ah, I think I understand better - I was assuming a much stronger statement of what social choice function is rational for everyone to have, rather than just that there exists a (very large) set of social choice functions, and it it rational for an agent to have any of them, even if it massively differs from other agents' functions.
Thanks for taking the time down this rabbit hole to clarify it for me.
comment by habryka (habryka4) · 2020-09-15T03:18:59.263Z · LW(p) · GW(p)
Oh no! The two images starting from this point are broken for me:

↑ comment by abramdemski · 2020-09-15T16:39:20.320Z · LW(p) · GW(p)
How about now?
↑ comment by abramdemski · 2020-09-15T16:30:27.619Z · LW(p) · GW(p)
Weird, given that they still look fine for me!
I'll try to fix...
Replies from: habryka4↑ comment by habryka (habryka4) · 2020-09-15T21:24:34.430Z · LW(p) · GW(p)
Yep, fixed. Thank you!
Judging from the URL of those links, those images were hosted on a domain that you could access, but others could not, namely they were stored as Gmail image attachments, to which of course you as the recipient have access, but random LessWrong users do not.
comment by romeostevensit · 2020-09-14T21:43:24.834Z · LW(p) · GW(p)
Type theory for utility hypothesis: there are a certain distinct (small) number of pathways in the body that cause physical good feelings. Map those plus the location, duration, intensity, and frequency dimensions and you start to have comparability. This doesn't solve the motivation/meaning structures built on top of those pathways which have more degrees of freedom, but it's still a start. Also, those more complicated things built on top might just be scalar weightings and not change the dimensionality of the space.
Replies from: abramdemski↑ comment by abramdemski · 2020-09-14T22:17:53.011Z · LW(p) · GW(p)
Yeah, it seems like in practice humans should be a lot more comparable than theoretical agentic entities like I discuss in the post.
comment by Charlie Steiner · 2020-09-15T06:09:34.982Z · LW(p) · GW(p)
One think I'd also ask about is: what about ecology / iterated games? I'm not very sure at all whether there are relevant iterated games here, so I'm curious what you think.
How about an ecology where there are both people and communities - the communities have different aggregation rules, and the people can join different communities. There's some set of options that are chosen by the communities, but it's the people who actually care about what option gets chosen and choose how to move between communities based on what happens with the options - the communities just choose their aggregation rule to get lots of people to join them.
How can we set up this game so that interesting behavior emerges? Well, people shouldn't just seek out the community that most closely matches their own preferences, because then everyone would fracture into communities of size 1. Instead, there must be some benefit to being in a community. I have two ideas about this: one is that the people could care to some extent about what happens in all communities, so they will join a community if they think they can shift its preferences on the important things while conceding the unimportant things. Another is that there could be some crude advantage to being in a community that looks like a scaling term (monotonically increasing with community size) on how effective they are at satisfying their peoples' preferences.
comment by ESRogs · 2020-09-15T04:47:12.656Z · LW(p) · GW(p)
G: A 50/50 gamble between A and B
This bit in the first drawing should say "... between A and C", right?
Replies from: abramdemski↑ comment by abramdemski · 2020-09-15T16:41:05.864Z · LW(p) · GW(p)
Ahh, darn it!
comment by Rohin Shah (rohinmshah) · 2020-09-18T19:08:37.249Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
This is a reference post about preference aggregation across multiple individually rational agents (in the sense that they have VNM-style utility functions), that explains the following points (among others):
1. The concept of “utility” in ethics is somewhat overloaded. The “utility” in hedonic utilitarianism is very different from the VNM concept of utility. The concept of “utility” in preference utilitarianism is pretty similar to the VNM concept of utility.
2. Utilities are not directly comparable, because affine transformations of utility functions represent exactly the same set of preferences. Without any additional information, concepts like “utility monster” are type errors.
3. However, our goal is not to compare utilities, it is to aggregate people’s preferences. We can instead impose constraints on the aggregation procedure.
4. If we require that the aggregation procedure produces a Pareto-optimal outcome, then Harsanyi’s utilitarianism theorem says that our aggregation procedure can be viewed as maximizing some linear combination of the utility functions.
5. We usually want to incorporate some notion of fairness. Different specific assumptions lead to different results, including variance normalization, Nash bargaining, and Kalai-Smorodinsky.
comment by [deleted] · 2020-09-18T10:29:32.534Z · LW(p) · GW(p)
"The Nash solution differs significantly from the other solutions considered so far. [...]
2. This is the first proposal where the additive constants matter. Indeed, now the multiplicative constants are the ones that don't matter!"
In what sense do additive constants matter here? Aren't they neutralized by the subtraction?