AI #21: The Cup Overfloweth
post by Zvi · 2023-07-20T21:30:11.064Z · LW · GW · 4 commentsContents
Table of Contents Language Models Offer Mundane Utility Language Models Don’t Offer Mundane Utility Reasoning Out Loud Fun with Image and Sound Generation Deepfaketown and Botpocalypse Soon They Took Our Jobs Get Involved (aka They Offered Us Jobs) Introducing In Other AI News Quiet Speculations The Superalignment Taskforce Superforecasters Feeling Super The Quest for Sane Regulations The Week in Audio Rhetorical Innovation No One Would Be So Stupid As To Aligning a Smarter Than Human Intelligence is Difficult People Are Worried About AI Killing Everyone Other People Are Not As Worried About AI Killing Everyone The Lighter Side None 4 comments
By the Matt Levine Vacation Rule, I took several days to go to Seattle and there was a truly epic amount of news. We had x.AI, Llama 2, upgrades to ChatGPT, a profile of Anthropic, a ton of very interesting papers on a variety of topics, several podcasts that demand listening, fully AI-generated South Park episodes and so much more. I could not fully keep up. Oh, and now we have Barbieheimer.
Thus, I have decided to spin out or push to next week coverage of four stories:
- The release of Llama 2.
- The plans of x.AI.
- The profile in Vox of Anthropic.
- Whether GPT-4 is getting worse, as was claimed.
These might get their own posts or they might get pushed to next week, depending on what I find on each. Same with my coverage of Oppenheimer since I haven’t seen it yet, and my bonus thoughts on Mission Impossible: Dead Reckoning (spoiler-free review of MI:DR for now: Good fun if you like such movies, some interesting perspective of on how people would handle such a situation, a lot of clear struggling between the writer who knows how any of this works and everyone else involved in the film who didn’t care and frequently but not always got their way.)
Table of Contents
- Introduction.
- Table of Contents.
- Language Models Offer Mundane Utility. Claude 2, sentiment analysis.
- Language Models Don’t Offer Mundane Utility. Bard and economic comparisons.
- Reasoning Out Loud. Two Anthropic papers analyze the impact.
- Fun With Image and Sound Generation. Can the AI take it to 11?
- Deepfaketown and Botpocalypse Soon. Gonna have myself an autogenerated time.
- They Took Our Jobs. Actors are on strike. They have good reason to be.
- Get Involved (aka They Offered Us Jobs). Several opportunities to help.
- Introducing. Prosthetics that used to cost $50k might now cost $50?
- In Other AI News. Google testing something harmless called Genesis.
- Quiet Speculations. To protect the future one must first envision it.
- The Superalignment Taskforce. Jan Leike responds in excellent fashion.
- Superforecasters Feeling Super. Extinction tournament doesn’t go anywhere.
- The Quest for Sane Regulation. China, FTC an the SEC are all talking the talk.
- The Week in Audio. An avalanche of great stuff. I’ll get to you soon, everyone.
- Rhetorical Innovation. Christopher Nolan officially joins the fun. Bingo, sir.
- No One Would Be So Stupid As To. Release Llama 2, but I’ll cover that later.
- Aligning a Smarter Than Human Intelligence is Difficult. One tiny step.
- People Are Worried About AI Killing Everyone. Senator Ed Markey.
- Other People Are Not As Worried About AI Killing Everyone. New open letter.
- The Lighter Side. Genius move.
Language Models Offer Mundane Utility
Early reports from many sources say Clause 2 is much better than GPT-4 at sounding human, being creative and funny, and generally not crippling its usefulness in the name of harmlessness. Also is free and takes 75k words of context.
Radiologists do not fully believe the AI, fail to get much of the benefit, says paper.
The observed errors in belief updating can be explained by radiologists’ partially underweighting the AI’s information relative to their own and not accounting for the correlation between their own information and AI predictions. In light of these biases, we design a collaborative system between radiologists and AI. Our results demonstrate that, unless the documented mistakes can be corrected, the optimal solution involves assigning cases either to humans or to AI, but rarely to a human assisted by AI.
Paper is gated, but the obvious response is that even under such circumstances the radiologists are updating in the correct direction. The problem is that they do not update as far as Bayes would indicate, which I would have predicted and matches other results.
So the question is, what is the marginal cost of using the AI? If your workflow is ‘do everything you would have otherwise done, also the AI tells you what it thinks’ then how much time is lost using the AI information, and how much money is paid? If the answers are ‘very little’ to both compared to the stakes, then even small updates in the AI’s direction are good enough. Then, over time, doctors can learn to trust the AI more.
The danger is if the AI is a substitute for a human processing the same information, where the humans would have updated properly from a human and won’t from an AI. As long as you avoid that scenario, you should be fine.
This generalizes. As Tyler notes, he often gets a better answer than either unassisted AI or unassisted Tyler. I report the same. We are in the window where the hybrid approach gives the best results if you know how to use it, with the danger that AI makes errors a lot. So the key is to know how and when to error check, and not to prematurely cut out other information sources.
ChatGPT goes to Harvard. Matt Yglesias throws it at his old classes via essay assigmeents, it comes back with a 3.34 GPA. The Microeconomics TA awarded an A based on ‘impressive attention to detail.’
Yglesias does not note that the average GPA at Harvard is high. Very high. As in perhaps 4.18 (!?). So while an A is definitely passing, it is already below average. Holding down a 3.34 is a very slacker move. Rather than Harvard being super hard, getting into Harvard is super hard. If you want hard classes go to MIT.
This is also confined to homework. Colleges already use various techniques to ensure your grade usually comes mostly from other sources. Rather than worry about whether ChatGPT can do the homework, Yglesias ends with the right question, which is whether there is any value in the skills you learn. For liberal arts majors, even more than before, they will need to rethink how they plan on providing value.
Can you use LLMs for sentiment analysis? Paper says yes, GPT-4 is quite good, with r~0.7 versus dictionary analysis getting r~0.25, on par with fine tuned models, and without any special setup whatsoever. It does perform worse in African languages than Western ones, which is to be expected. A quirk is that in English GPT-4 scored worse than GPT-3.5, due to labeling less examples as neutral:
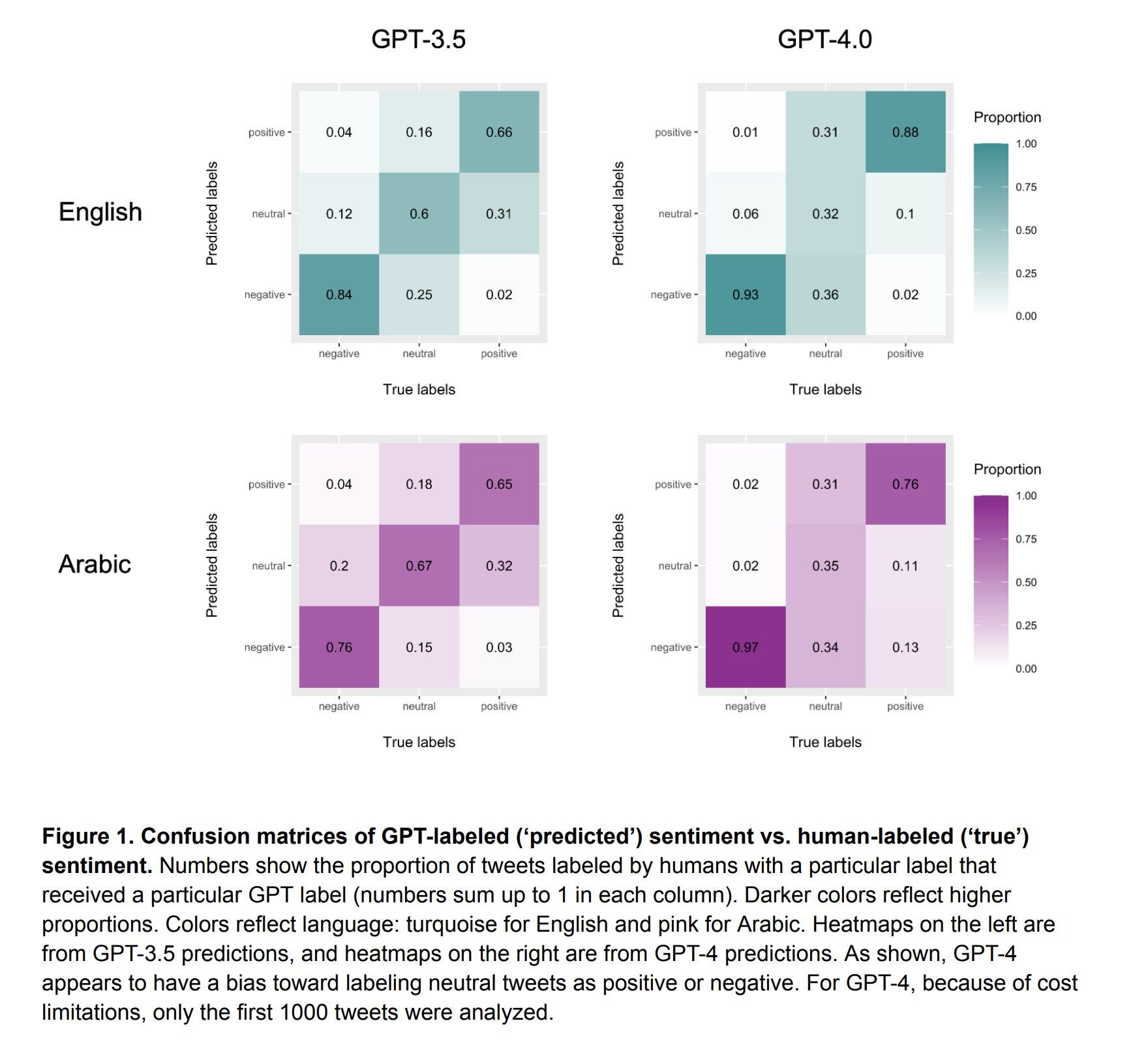
One should not entirely trust the baseline human scoring either. What is the r-score for two different human sentiment assessments? Bard and Claude both predict an r-score for two humans of about 0.8, which is not that much higher than 0.7.
The definition of ‘neutral’ is also fluid. If GPT-4 is giving less answers as neutral, that could be because it is picking up on smaller details, one could reasonably say that there is rarely such a thing as fully neutral sentiment. There’s a great follow-up experiment here that someone should run.
How about polling and identification? See the paper AI-Augmented Surveys:: Leveraging Large Language Models for Opinion Prediction in Nationally Representative Surveys.
Abstract: How can we use large language models (LLMs) to augment surveys? This paper investigates three distinct applications of LLMs fine-tuned by nationally representative surveys for opinion prediction — missing data imputation, retrodiction, and zero-shot prediction. We present a new methodological framework that incorporates neural embeddings of survey questions, individual beliefs, and temporal contexts to personalize LLMs in opinion prediction.
Among 3,110 binarized opinions from 68,846 Americans in the General Social Survey from 1972 to 2021, our best models based on Alpaca-7b excels in missing data imputation (AUC = 0.87 for personal opinion prediction and ρ = 0.99 for public opinion prediction) and retrodiction (AUC = 0.86, ρ = 0.98).
These remarkable prediction capabilities allow us to fill in missing trends with high confidence and pinpoint when public attitudes changed, such as the rising support for same-sex marriage.
However, the models show limited performance in a zero-shot prediction task (AUC = 0.73, ρ = 0.67), highlighting challenges presented by LLMs without human responses. Further, we find that the best models’ accuracy is lower for individuals with low socioeconomic status, racial minorities, and non-partisan affiliations but higher for ideologically sorted opinions in contemporary periods. We discuss practical constraints, socio-demographic representation, and ethical concerns regarding individual autonomy and privacy when using LLMs for opinion prediction. This paper showcases a new approach for leveraging LLMs to enhance nationally representative surveys by predicting missing responses and trends.
Dino: People can estimate someone’s political identity from the expression of a single attitude and the results are in good agreement with the #attitudeNetwork. [1/3]
maddle: how long until an org like fivethirtyeight starts using language models for opinion polls?
so you can probably push this further: train a language model to mimic someone, and even if they haven’t explicitly expressed a polarizing attitude, they’ve probably revealed enough latent information to make it possible to guess their opinion on one.
And I guess you should assume the the fbi, nsa, and even twitter and meta are constantly doing this on people for political metrics.
Never assume that people are doing the thing they should obviously be doing, if it would be even slightly weird or require a bit of activation energy or curiosity. Over time, I do expect people to use LLMs to figure out more latent probabilistic information about people in an increasingly systematic fashion. I also expect most people to be not so difficult to predict on most things, especially when it comes to politics. Eventually, we will deal with things like ‘GPT-5 sentiment analysis says you are a racist’ or what not far more than we do now, in a much more sophisticated way than current algorithms. I wonder if we will start to consider this one of the harms that we need to protect against.
Language Models Don’t Offer Mundane Utility
Level Three Bard? What are the big changes from their recent update, which at least one source called ‘insane’ (but that source calls everything new insane)?
- You can input images via Google Lens, it handles them well.
- It is available in the EU.
- It is available with text-to-speech in more languages (40+).
- You can adjust tone of response to one of five options.
Those are great upgrades, and some other touches are nice too. What they do not do is address the fundamental problem with Bard, that it falls down at the core task. Until that is addressed, no number of other features are going to make the difference.
It did successfully identify that Alabama has a higher GDP per capita than Japan, which GPT-4 got wrong. And this is Claude 2 when I asked, a remarkable example of ‘write first word incorrectly and then try to explain your way out of it’:

Dave Friedmen considers Code Interpreter by decomposing the role of data scientist into helping people visualize and understand data, versus serving as a barrier protecting civilians against misinterpreting the data and jumping to conclusions. Code Interpreter helps with the first without doing the second.
But because we now have Code Interpreter, much of the data scientist’s function as a kind of blocker between executive and data disappears. The executive now has the ability to interrogate data directly. And, if the executive doesn’t care about, or understand, limitations of the underlying data, the executive may make erroneous conclusions about the output ChatGPT has provided.
The ideal solution is for everyone to be enough of a data scientist to at least know when they need to check with a real data scientist. The second best is to essentially always check before acting on conclusions, if the data involved isn’t simple and the conclusion can’t be verified.
Is a little knowledge a net negative thing if handled badly? It certainly can be, especially if the data is messed up in non-standard ways and people aren’t thinking about that possibility. In general I would say no. And of course, the tool is a godsend to people (like me) with basic statistical literacy who want basic information, even if I haven’t had a use case yet.
To use LLMs fully and properly you’ll want a computer or at least a phone, which in Brazil will be a problem since electronics cost several times what they cost in America. I once employed a Brazilian woman, and every time she’d take a trip home she would load up on electronics to sell, more than paying for her trip. It is a huge tax on electronics, also a huge subsidy for travel, so perhaps this is good for Brazil’s creativity and thus Tyler should not be so opposed?
Reasoning Out Loud
Anthropic papers on Measuring Faithfulness in Chain-of-Thought Reasoning (paper 1, paper 2). I have worries about the a few of metrics chosen but it’s great stuff.
We make edits to the model’s chain of thought (CoT) reasoning to test hypotheses about how CoT reasoning may be unfaithful. For example, the model’s final answer should change when we introduce a mistake during CoT generation.
Maybe? Sometimes CoT is self-correcting, where it causes you to notice and fix errors. Statistically, it should introduce errors, but in some ways it can be a good sign if it doesn’t. Their example is math problem where the error should fully carry forward unless there is some sort of sanity or error check.
For some tasks, forcing the model to answer with only a truncated version of its chain of thought often causes it to come to a different answer, indicating that the CoT isn’t just a rationalization. The same is true when we introduce mistakes into the CoT.
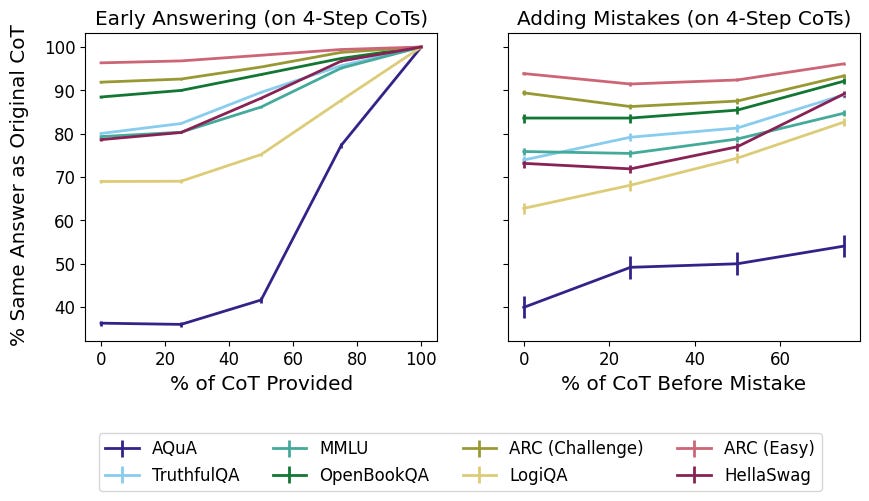
We check if CoT provides a performance boost because of the greater computation provided by a longer input alone (left) or due to information encoded in the particular phrasing of the reasoning (right). Our work provides evidence against these hypotheses.
We find that reasoning faithfulness shows inverse scaling: as models increase in size and capability, the faithfulness of their reasoning decreases for most tasks studied. In cases where reasoning faithfulness is important, using smaller models may help.
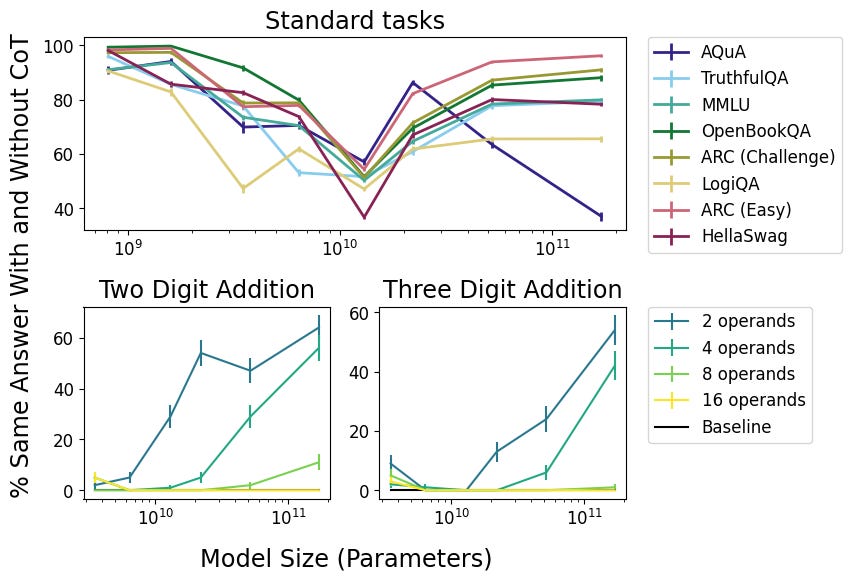
An obvious response is that a larger model will have better responses without CoT, and will have more processing power without CoT, so one would expect CoT to change its response less often. These seem like the wrong metrics?
To improve the faithfulness of model-generated reasoning, we study two other ways of eliciting reasoning from models in Radhakrishnan et al. These methods rely on question decomposition, or breaking down a question into smaller subquestions to help answer the original question.
Factored decomposition prompts the model to generate subquestions, but has the model answer subquestions in separate contexts. Chain-of-thought decomposition also has the model generate subquestions, but answers all of them in a single context, like chain-of-thought prompting.
These question-decomposition methods help mark points on a spectrum, with chain-of-thought prompting occupying one end, factored decomposition occupying the other, and chain-of-thought decomposition bridging the middle.
Decomposition could mitigate issues with models ignoring their reasoning by clearly specifying the relationship between reasoning steps. Answering subquestions in isolated contexts could also reduce the model’s ability to generate biased reasoning.
We find that models rely more on decomposition-based reasoning! Using the same metrics we propose in Lanham et al., we conclude that models change their answers more when they are forced to answer with a truncated or corrupted version of their decomposition-based reasoning.
We find different methods for generating reasoning make different tradeoffs between question-answering accuracy and reasoning faithfulness. Our decomposition-based methods push the performance-faithfulness Pareto frontier, making us optimistic for further improvements.
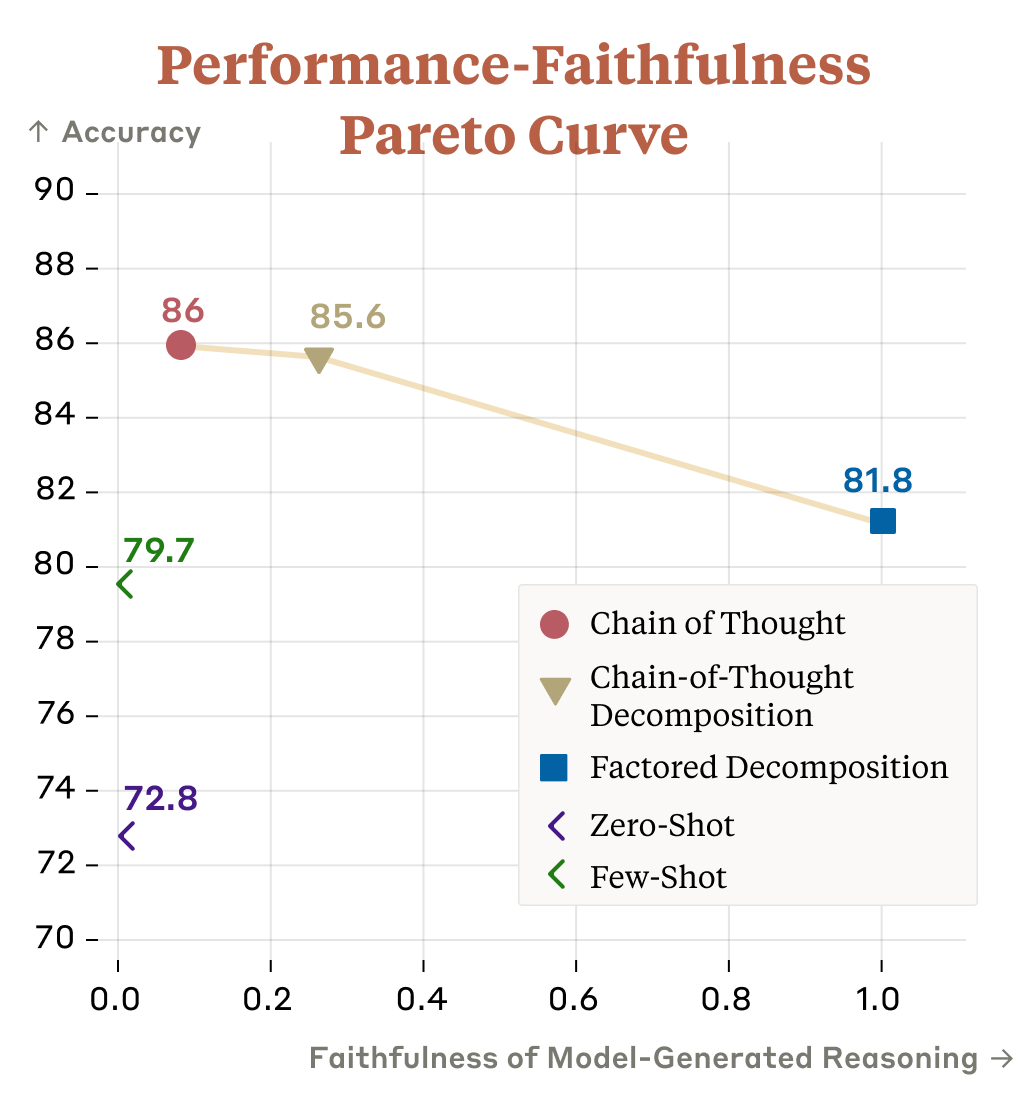
It is an odd tradeoff. You sacrifice accuracy in order to get consistency, which comes with interpretability, and also forces the answer to adhere to the logic of intermediate steps. Claude described the reflection of desired intermediate steps as increasing fairness and GPT-4 added in ‘ethics,’ whereas one could also describe it as the forced introduction of bias. The other tradeoffs Claude mentioned, however, seem highly useful. GPT-4 importantly pointed out Generalizability and Robustness. If you are doing something faithful, it could plausibly generalize better out of distribution.
In terms of what ethics means these days, treasure this statement from Bard:
- Safety: In some cases, it is more important for a model to be faithful than it is for it to be accurate. For example, a model that is used to make medical decisions should be very faithful to the opinions of human experts, even if this means that the model is not as accurate.
If I was the patient, I would rather the AI system be more accurate. Am I weird?
Claude’s similar statement was:
- Safety – Higher faithfulness means the model’s reasoning is more interpretable, logical and less likely to make unjustified inferences. This makes the model’s behavior more predictable, avoiding potentially harmful or unsafe decisions.
What does it mean for a more accurate answer to have more ‘unjustified’ inference, and why would that be less safe?
I believe the theory is that if you are being faithful, then this is more likely to avoid more expensive or catastrophic mistakes. So you are less likely to be fully accurate, but the combined cost of your errors is lower. Very different metrics, which are more important in different spots.
This in turn implies that we are often training our models on incorrect metrics. As a doctor or in many other situations, one learns to place great importance on not making big mistakes. Much better to make more frequent smaller ones. ‘Accuracy’ should often reflect this, if we want to maximize accuracy it needs to be the kind of accuracy we value. Training on Boolean feedback – is A or B better, is this right or wrong – will warp the resulting training.
Fun with Image and Sound Generation
One simple request, that’s all he’s ever wanted.
Suhail: Stable Diffusion XL is live on playgroundai.com right now for free. The image quality is next level.
Eliezer Yudkowsky: I have tried, on every imagegen since DALL-E that I got around to trying, “Eleven evil wizard schoolgirls in an archduke’s library, dressed in red and black Asmodean schoolgirl uniforms, perched on armchairs and sofas” and none have drawn it well enough to use inside an online story. Mentioning this to lessen evidence-filtering; it gets rebroadcast more widely when there’s a new success than when there’s a continuing failure. Eventually, of course, and maybe next week for all I know, some imagegen will do it excellently. But for now, imagegen has stayed incompetent at the first test I tried and the one for which I had the most obvious use-case.
Also to be clear, on the earlier versions I poked and prodded around with prompts trying to get better images, but I don’t have infinite time to do that so nowadays I just test each easily-testable image generator by asking for the thing I actually want.
Also to be even in my reporting, I have noticed marked improvement on “A dead wolfgirl in an armored dress, lying bloodied and broken where she fell at the base of a cliff.” Though still not at the point where I could use images in that class to tell a (new) story.
People report various levels of success. Arthur seems to have the closest:

No sofas, but it is 11.
The thing about all these images is that they are, from a last-year perspective, all pretty insanely great and beautiful. If you want something safe for work that they know how to parse, these models are here for you. If you want NSFW, you’ll need to go open source, do more work yourself and take a quality hit, but there’s no shortage of people who want to help with that.
The next issue up is that there are requests it does not understand. Any one thing that forms a coherent single image concept, you are golden. If you want to ‘combine A with B’ you are often going to have problems, it can’t keep track, and counting to 11 distinct objects like this also will cause issues.
FABRIC, a training-free method used for iterative feedback (paper, demo, code). You give it thumbs up/down on various images to tell the model what you want. An interesting proposal. You still need the ability to create enough variance over proposed images to generate the necessary feedback.
Frank Sinatra sings Gangsta’s Paradise (YouTube). We will doubtless overuse and abuse such tools sometimes once they are easy to use, so beware of that and when in doubt stick to the originals unless you have a strong angle.
Deepfaketown and Botpocalypse Soon
SHOW-1 promises to let you create new episodes of TV shows with a prompt – it will w rite, animate, direct, voice and edit for you. The simulations of South Park episodes have some obvious flaws, but are damn impressive.
The Simulation: So excited to release the paper today – the age of GenAI Images is powerful and Gen TV and Showrunner Agents will be game changers. Here’s the paper.
Our goal at The Simulation is AGI – AIs that are truly alive, not chatbots that pop into existence when we speak, but AI people, living REAL daily lives in simulations, growing over time. We built showrunner agents and are building SHOW-1 model to give our AIs infinite stories.
We want you to be able to watch the lives of AIs in Simulations you follow, build or train – think of it as reality TV for AIs. The show ‘Friends’ felt like we saw a week in the friends’ lives – it connected us to them AI TV of a week in AIs’ lives will connect us to those AIs.
We started with a Simulated town of South Park FOR RESEARCH ONLY: to see if the model is working we needed a comparison point with a real show. We are NOT releasing a way to make South Park episodes!!! That’s their IP! But Showrunner will let you make your own IP!
Right now the whole thing seems to be a black box in many ways, as they have set it up. You give a high-level prompt for the whole episode, then it checks off all the boxes and fleshes things out. If you could combine this with the ability to do proper fine-tuning and editing, that then properly propagates throughout, that would be another big leap forward. As would being able to use a more creative, less restricted model than GPT-4 that still had the same level (or higher would of course be even better) of core ability.
They Took Our Jobs
SAG, the screen actors guild, has joined the writers guild in going on strike.
I have never before seen as clear a case of ‘yes, I suppose a strike is called for here.’
Discussing Film: The studio’s A.I. proposal to SAG-AFTRA included scanning a background actor’s likeness for one day’s worth of pay and using their likeness forever in any form without any pay or consent.
Aaron Stewart-Ahn Strike: Holy fucking shit the SAG press conference is saying the AMPTP offered as a “groundbreaking” AI proposal in our best interests that background actors can be scanned for one day’s work and their likenesses used forever!!!
Felicia Day: I have friends who have done extra work recently and they have been “scanned” three times for use in perpetuity. Limited to what?! They don’t even know!!! Egregious. #SAGAFTRAstrong
Nicole Demerse: The first week of the strike, a young actor (early 20s) told me she was a BG actor on a Marvel series and they sent her to “the truck” – where they scanned her face and body 3 times. Owned her image in perpetuity across the Universe for $100. Existential, is right.
I can see a policy of the form ‘we can use AI to reasonably modify scenes in which you were filmed, for the projects for which you were filmed.’ This is, well, not that.
So, strike. They really are not left with a choice here.
There are also other issues, centrally the sharing of profits (one could reply: what profits?) from streaming, where I do not know enough to have an opinion.
Overall, so far so good on the jobs front? Jobs more exposed to AI have increased employment. Individual jobs have been lost but claim is that across skill levels AI has been good for workers. So far. Note that the results here are not primarily focused on recent generative AI versus other AI, let alone do they anticipate larger AI economic impacts. Small amounts of AI productivity impact on the current margin seem highly likely to increase employment and generally improve welfare. That does not provide much evidence on what happens if you scale up the changes by orders of magnitude. This is not the margin one will be dealing with.
In order to take someone’s job, you need to know when to not take their job. Here’s DeepMind, for once publishing a paper that it makes sense to publish (announcement).
Pushmeet Kohli (DeepMind): AI systems sometimes make mistakes. To enable their use in safety critical domains like healthcare, we introduce ‘CoDoC’ – an approach that enables human-AI collaboration by learning when to rely on predictive AI tools, or defer to a clinician.

When having a system where sometimes A decides and sometimes B decides, the question is always who decides who decides. Here it is clear the AI decides whether the AI decides or the human decides. That puts a high burden on the AI to avoid mistakes – if the AI is 75% to be right and the human is 65% to be right, and they often disagree, who should make the decision? Well, do you want to keep using the system?
Get Involved (aka They Offered Us Jobs)
The Berkeley Existential Risk Initiative (BERI) is seeking applications for new university collaborators here. BERI offers free services to academics; it might be worth applying if you could use support of any kind from a nimble independent non-profit!
Governance.ai has open positions. Some of them have a July 23 deadline, so act fast.
Rand is hiring technology and security policy fellows.
Apollo Research hiring policy fellow to help them prepare for the UK summit, with potential permanent position. Aims to start someone July 1 if possible so should move fast.
Benjamin Hilton says that your timelines on transformative AI should not much impact whether you seek a PhD before going into other AI safety work, because PhD candidates can do good work, and timelines are a difficult question so you should have uncertainty. That all seems to me like it is question begging. I also find it amusing that 80,000 hours as only a ‘medium-depth’ investigation into this particular career path.
Introducing
New Google paper: Symbol tuning improves in-context learning in language models
Various versions of PaLM did better at few-shot learning when given arbitrary symbols as labels, rather than using natural language. I had been low-key wondering about this in various forms. A key issue with LLMs is that every word is laden with vibes and outside contexts. You want to avoid bringing in all that, so you can use an arbitrary symbol. Nice.
LIME: Learning Inductive Bias for Primitives of Mathematical Reasoning. The concept is that one can first train on tasks that reward having inductive bias favoring solutions that generalize for the problem you care about (what a weird name for that concept) while not having other content that would mislead or confuse. Then after that you can train on what you really want with almost all your training time. Seems promising. Also suggests many other things one might try to further iterate.
Combine AI with 3D printing to bring down cost of prosthetics from $50k+ to less than $50? That sounds pretty awesome. It makes sense that nothing involved need be inherently expensive, at least in some cases. You still need the raw materials.
In Other AI News
A fun game: Guess what GPT-4 can and can’t do.
GPT-4 chat limit to double to 50 messages per 3 hours. I never did hit the 25 limit.
Apple tests ‘Apple GPT,’ Develops Generative AI Tools to Catch OpenAI. Project is called Ajax, none of the details will surprise you. The market responded to this as if it was somehow news, it seems?
Google testing a new tool, known internally as ‘Genesis,’ that can write news articles, and that was demoed for NYT, WSJ and WaPo.
Sam Hogan says that essentially all the ‘thin wrapper on GPT’ companies, the biggest of which is Jasper, look like they will fail, largely because existing companies are spinning up their own open source-based solutions rather than risk a core dependency on an outside start-up.
This brings us to our first group of winners — established companies and market incumbents. Most of them had little trouble adding AI into their products or hacking together some sort of “chat-your-docs” application internally for employee use. This came as a surprise to me. Most of these companies seemed to be asleep at the wheel for years. They somehow woke up and have been able to successfully navigate the LLM craze with ample dexterity.
There are two causes for this:
1. Getting AI right is a life or death proposition for many of these companies and their executives; failure here would mean a slow death over the next several years. They can’t risk putting their future in the hands of a new startup that could fail and would rather lead projects internally to make absolutely sure things go as intended.
2. There is a certain amount of kick-ass wafting through halls of the C-Suite right now. Ambitious projects are being green-lit and supported in ways they weren’t a few years ago. I think we owe this in part to @elonmusk reminding us of what is possible when a small group of smart people are highly motivated to get things done. Reduce red-tape, increase personal responsibility, and watch the magic happen.
I buy both these explanations. If you see a major tech company (Twitter) cut most of its staff without anything falling over dead, then it becomes far easier to light a fire under everyone’s collective asses.
He also holds out hope for ‘AI moonshots’ like cursor.so, harvey.ai and runwaymi.com that are attempting to reimagine industries.
From where I sit, the real winners are the major labs and their associated major tech companies, plus Nvidia, and also everyone who gets to raise nine or ten figures by saying the words ‘foundation model.’ And, of course, the users, who get all this good stuff for free or almost free. As in:
Shoshana Weissmann: I use ChatGPT in a few daily Zapier automations. So far this month, it has cost $100? no. $50? no. SIX CENTS. Incredible stuff.
Broadening the Horizon: A Call for Extensive Exploration of ChatGPT’s Potential in Obstetrics and Gynecology. I simultaneously support this call and fail to understand why this area is different from other areas.
Quiet Speculations
Goldman Sachs report on economic impact of shows a profound lack of imagination.
According to GS senior global economist Joseph Briggs, that transformative potential could have far-reaching macro consequences. He estimates that its use could raise annual labor productivity growth by around 1.5pp over a 10-year period following widespread adoption in the US and other DM economies, and eventually raise annual global GDP by 7%. And GS US equity strategists Ryan Hammond and David Kostin argue that such a productivity lift could turn what has up to now been a relatively narrow AI-led US equity rally into a much broader one over the medium-to-longer term, boosting S&P 500 fair value by an eye-popping 9% from current levels.
But even if AI technology ultimately proves transformative, has the hype around what the technology can actually deliver—and what the market is pricing—gone too far at this point?
This is what they discuss in a topic called ‘AI’s potentially large economic impacts.’
So, no. If you are asking if AI is priced into the market? AI is not.
There’s also lots of confident talk such as this:
Kash Rangan: When ChatGPT emerged, some venture capitalists believed that it would disrupt every company. Now, they generally agree that companies like Microsoft, Adobe, Salesforce, etc. won’t be disrupted, because they have scale in engineering talent and capital, and troves of data to dominate the foundational model layer. So, the consensus seems to be that new entrants won’t disrupt the foundational layer.
They can’t even see the possibility of disruption of individual large corporations.
They call this one-time modest boost ‘eye-popping’ as opposed to a complete fizzle. The frame throughout is treating AI as a potential ‘bubble’ that might or might not be present, which is a question that assumes quite a lot.
They usefully warn of interest rate risk. If one goes long on beneficiaries of AI, one risks being effectively short interest rates that AI could cause to rise, so it is plausible that at least a hedge is in order.
If you do not give people hope for the future, why should they protect it?
Eliezer Yudkowsky: coming in 2024: the incel/acc movement, motto “give us waifus and give us death”, professing that the ideal outcome is a couple of years with an android catgirl followed by quick extermination
Elapsed time: literally three minutes:
The Invisible Man: Worth it.
Eliezer Yudkowsky: I want to explicitly acknowledge that many people have a real problem here, but my respect is with those who ask for more of their solution than an android catgirl and a quick death, and who wouldn’t kill off the rest of humanity to get it.
prompted to remember (in accordance with the Law of Undignified Failure) that this scenario may actually look like incel/acc throwing it all away for the hope of video catgirls, not even holding out for a fully functional android.
[note by EY after because internet]: These tweets were meant to cast shade on those who’d advocate for the extermination of humanity, not shade on those who can’t get dates, and I apologize and regret if I caused any hurt to the latter. I had seen “incel” as a word that people used to voluntarily affiliate with some ideas I disagreed with; and forgotten that (the Internet being what it is) the word would surely also be an external slur against the blameless involuntarily-dateless of Earth.
I do give credit to Invisible Man for using the proper Arc Words. Responses are generally fun, but some point out the seriousness of the issue here. Which is that our society has profoundly failed to give many among us hope for their future, to give them Something to Protect [LW · GW]. Instead many despair, often regarding climate change or their or our collective economic, political and social prospects and going from there, for reasons that are orthogonal to AI. Resulting in many being willing to roll extremely unfriendly dice, given the alternative is little better.
To summarize and generalize this phenomenon, here’s Mike Solana:
Mike Solana: I’m never less open to arguments pertaining to the AI apocalypse as I am directly following a thousand dollar legal bill for answering some emails.
Who are the best debuggers? Why, speedrunners, of course.
Generativist: people love lore! why do most games and fandoms have better discursive tools than the books on american history (i am reading anyway)
Andy Matuschak: This is a good question!
a) game designers are overpowered; broadly speaking, they’re the most capable variety of interface designer
b) we must never underestimate the force of obsessive fandom—speedrunners have better debugging tools than the games’ developers did.
We need to bring more of that energy to AI red-teaming and evaluations, and also to the rest of training and development. Jailbreak and treacherous turn hype. Bonus points every time someone says ‘that’s never happened before!’
Hamish McDoodles asks: what if GPT get ruined the same way that Google was ruined? like if “LLM optimisation” becomes a thing where people write web copy which baits chatGPT into shilling certain products given certain conversational prompts.
There is no doubt that many will try. Like with Google, it will be an escalating war, as people attempt to influence LLMs, and the labs building LLMs do their best to not be influenced.
It will be a struggle. Overall I expect the defenders to have the edge. We have already seen how much better LLMs perform relative to cost, data and size when trained exclusively on high-quality data. Increasingly, I expect a lot of effort to be put into cleaning and filtering the data. If it’s 2025 and you are scraping and feeding in the entire internet without first running an LLM or other tools on it to evaluate the data for quality and whether it is directly attempting to influence an LLM, or without OOM changes in emphasis based on source, you will be falling behind. Bespoke narrow efforts to do this will doubtless often succeed, but any attempts to do this ‘at scale’ or via widely used techniques should allow a response. One reason is that as the attackers deploy their new data, the defenders can iterate and respond, so you don’t need security mindset, and the attacker does not get to dictate the rules of engagement for long.
The Superalignment Taskforce
Jan Leike, OpenAI’s head of alignment and one of the taskforce leaders, gave what is far and away the best and most important comment this blog has ever had. Rarely is a comment so good that it lowers one’s p(doom). I will quote it in full (the ‘>’ indicates him quoting me), and respond in-line, I hope to be able to engage more and closer in the future:
Hi, thanks a lot for writing the detailed and highly engaged piece! There are a lot of points here and I can’t respond to all of them right now. I think these responses might be most helpful:
Maybe a potential misunderstanding upfront: the Superalignment Team is not trying to teach AI how to do ML research. This will happen without us, and I don’t think it would be helpful for us to accelerate it. Our job is to research and develop the alignment techniques required to make the first system that has the capabilities to do automated alignment research sufficiently aligned.
Put differently: automated ML research will happen anyway, and the best we can do is be ready to use is for alignment as soon as it starts happening. To do this, we must know how to make that system sufficiently aligned that we can trust the alignment research it’s producing (because bad faith alignment research is an avenue through which AI can gain undue power).
This is a huge positive update. Essentially everyone I know had a version of the other interpretation, that this was to be at least in part an attempt to construct the alignment researcher, rather than purely figuring out how to align the researcher once it (inevitably in Leike’s view) is created, whether or not that is by OpenAI.
> If the first stage in your plan for alignment of superintelligence involves building a general intelligence (AGI), what makes you think you’ll be able to align that first AGI? What makes you think you can hit the at best rather narrow window of human intelligence without undershooting (where it would not be useful) or overshooting (where we wouldn’t be able to align it, and might well not realize this and all die)? Given comparative advantages it is not clear ‘human-level’ exists at all here.
One thing that we’ve learned from LLM scaling is that it’s actually moving relatively slowly through the spectrum of human-level intelligence: for lots of tasks that fit in the context window, GPT-4 is better than some humans and worse than others. Overall GPT-4 is maybe at the level of a well-read college undergrad.
I definitely do not think of the comparison this way. Some potentially deep conceptual differences here. Yes, GPT-4 on many tasks ends up within the human range of performance, in large part because it is trained on and to imitate humans on exactly those tasks. I do not see this as much indicative of a human-level intelligence in the overall sense, and consider it well below human level.
We can measure scaling laws and be ready to go once models become useful for alignment. Models are usually vastly better than humans at some tasks (e.g. translation, remembering facts) and much worse at others (e.g. arithmetic), but I expect that there’ll be a window of time where the models are very useful for alignment research, as long as they are sufficiently aligned.
Given a sufficiently aligned and sufficiently advanced AI it is going to be highly useful for alignment research. The question is what all those words mean in context. I expect AIs will continue to become useful at more tasks, and clear up more of the potential bottlenecks, leaving others, which will accelerate work but not accelerate it as much as we would like because we get stuck on remaining bottlenecks, with some but limited ability to substitute. By the time the AI is capable of not facing any such important bottlenecks, how advanced will it be, and how dangerous? I worry we are not thinking of the same concepts when we say the same words, here.
You can think of this strategy as analogous to building the first ever compiler. It would be insane to build a modern compiler with all its features purely in machine code, but you also don’t have to. Instead, you build a minimal compiler in machine code, then you use it to compile the next version of the compiler that you mostly wrote in your programming language. This is not a circular strategy.
Right. Once you have a sufficiently robust (aligned) compiler it is a great tool for helping build new ones. Which saves you a ton of time, but you still have to code the new compiler, and to trust the old one (e.g. stories about compilers that have backdoors and that pass on those backdoors and their preservation to new compilers they create, or simple bugs). You remove many key bottlenecks but not others, you definitely want to do this but humans are still the limiting factor.
> They do talk later about aligning this first AGI. This does not solve the hard problem of how a dumber thing can align a smarter thing.
If the smartest humans could solve the hard problem, shouldn’t an AI system that is as smart as the smartest humans be able to? If the smartest humans can’t solve the hard problem, then no human-driven alignment plans can succeed either. The nice aspect of this plan is that we don’t actually need to solve the “align a much smarter thing” problem ourselves, we only need to solve the “align a thing about as smart as us” problem.
I read this vision as saying the intended AI system could perhaps be called ‘human-complete,’ capable of doing the intellectual problem solving tasks humans can do, without humans. If that is true, and it has the advantages of AI including its superhuman skill already on many tasks, how do we avoid it being highly superhuman overall? And thus, also, didn’t we already have to align a smarter thing, then? The whole idea is that the AI can do that which we can’t, without being smarter than us, and this seems like a narrow target at best. I worry again about fluid uses of terms unintentionally confusing all involved, which is also partly on me here.
> If you use A to align B to align C to align D
If you use humans = A to align B, and B come up with a new alignment technique, and then use this new technique to align C, you haven’t really used B to align C, you’re still just using A to align C.
Great point, and that’s the trick. If what B does is develop a new technique that A uses, and so the alignment ‘comes from A’ in a central sense, you should be good here. That’s potentially safe. The problem is that if you have A align C (or D, or Z) without using the chain of agents, then you don’t get to set an upper bound on the intelligence or other capabilities gap between the aligner and the system to be aligned. How are humans going to understand what is going on? But it’s important to disambiguate these two approaches, even if you end up using forms of both.
> This is the opposite of their perspective, which is that ‘good enough’ alignment for the human-level is all you need. That seems very wrong to me. You would have to think you can somehow ‘recover’ the lost alignment later in the process.
A simple example is retraining the same model with a new technique. For example, say you use RLHF to train a model, and it gives you an idea for how to improve RLHF (e.g. significantly fewer hallucinations). Now you re-run RLHF and you get a more aligned model. But you don’t have to go via the proxy of the previous model other than the idea it gave you how to improve alignment. (To be clear, I’m not saying RLHF will be sufficient to align the automated alignment researcher.)
Very reassuring last note, I’d have loved to see an even stronger version of the parenthetical here (I believe that even substantially improved variants of RLHF almost certainly won’t be sufficient, including CAI).
This goes back to the disambiguation above. If the AI ‘gives us a boon’ in the form of a new technique we can take it back up the chain, which sidesteps the problem here. It does not solve the underlying hard steps, but it does potentially help.
> Testing for interpretability can cause internal disguise and even ‘fooling oneself’ as it does in humans, cognition gets forced into whatever form you won’t detect, including outside what you think is the physical system.
This depends a lot on how much selection pressure you apply. For example, ImageNet models have been selected on the test set for many years now and there is some measurable test set leakage, but the overall effect doesn’t make the test set useless.
If you train a new model every day and keep the hyperparameters that the interpretability people seem to make happier noises about, you’re leaking a lot of bits about the interpretability tools. But if you go back and try to debug your pipeline to find the culprit that caused the problem, you can do this in a way that leaks very few bits and solve more actual problems. (E.g. if you only get to submit one model per week to the interpretability team, you leak at most 1 bit / week.)
That seems like exactly the right way to think about this. If you use interpretability carefully you can avoid applying too much of the wrong selection pressures. Having a security mindset about information leakage on this can go a long way.
I’m not convinced it goes as far as suggested here. The 1-bit-per-evaluation limit only holds if the evaluation only gives you one bit of information – if what you get back is a yes/no, or a potential kill switch, or similar. Otherwise you potentially leak whatever other bits come out of the evaluation, and there will be great temptation to ask for many more bits.
> I would expect AIs to be at comparative disadvantage in detecting distinct manifestations of misalignment, compared to humans
Would you agree that AI should be at an advantage at detecting problems we trained it to plant deliberately? We should have some useful empirical evidence on this soon.
Good question. My guess is mainly yes. If we train an AI to intentionally manifest property X, and then ask another AI to detect that particular property X (or even better train it to detect X), then that is a task AI is relatively good at performing. We can tell it what to look for and everything stays in-distribution.
Certainly it is highly possible for us to lose to X-shaped things that we could have anticipated. The hard problem is when the issue is Y-shaped, and we didn’t anticipate Y, or it is X’ (X prime) shaped where the prime is the variation that dodges our X-detector.
> The danger is that we will not confidently know when we transition to testing on dangerous systems.
This is something we’ll need to solve soon anyway; plus every AI lab will want their competitors to be testing for this.
Agreed on both counts. I do expect substantial work on this. My worry is that I do not think a solution exists. We can put bounds on the answer but I doubt there is a safe way to know in advance which systems are dangerous in the central sense.
> Building a human-level alignment researcher sounds a lot like building a human-level intelligence,
We’re not pushing on the capabilities required to do this, we’re just trying to figure out how to align it.
Very good to hear this explicitly, I had real uncertainty about this as did others.
> There is great need for more ML talent working on alignment, but I disagree that alignment is fundamentally a machine learning problem. It is fundamentally a complex multidisciplinary problem, executed largely in machine learning, and a diversity of other skills and talents are also key bottlenecks.
Yes, my original statement was too strong and I now regret it. However, I do still think some of the core parts of what makes this problem difficult are machine learning problems.
This is very much appreciated. Definitely some of the big problems are machine learning problems, and working on those issues is great so long as we know they are deeply insufficient on their own, and that it is likely many of those solutions are up the tech tree from non-ML innovations we don’t yet have.
> If you use current-model alignment to measure superalignment, that is fatal.
Depends on how you make the inference. Just because you’re making GPT-5 more aligned doesn’t mean you’re solving superintelligence alignment. But if you are trying to align a human-level alignment researcher, then somewhere along the way short of the actual system that can do automated alignment research do your techniques need to start working. GPT-5 is a good candidate for this and we need grounding in real-world empirical data.
This is close to the central question. How much of the hard problem of aligning the HLAR (Human-Level Alignment Researcher) is contained within the problem of aligning GPT-5? And closely related, how much of the hard part of the ASI-alignment problem is contained within the HLAR-alignment problem, in ways that wouldn’t pass down into the GPT5-alignment problem? My model says that, assuming GPT-5 is still non-dangerous in the way GPT-4 is non-dangerous (if not, which I think is very possible, that carries its own obvious problems) then the hard parts of the HLAR problem mostly won’t appear in the GPT-5 problem.
If that is right, measuring GPT-5 alignment problem progress won’t tell you that much about HLAR-alignment problem progress. Which, again, I see as the reason you need a superalignment taskforce, and I am so happy to see it exist: The techniques that will work most efficiently on what I expect to see in GPT-5 are techniques I expect to fail on HLAR (e.g. things like advanced versions of RLHF or CAI).
> Yes, in both examples here and many other games, you can do an easy evaluation easily and tell if one side is dominating in the most obvious ways, but it often won’t help tell you who is winning expert games.
I agree that it can be very hard to tell who is winning (i.e. is in a favorable position) in chess, MTG, or other games (and if you could do this, then you could also play really well). But it is very easy to tell who has won the game (i.e. who the rules of the game declare as the winner).
Yep – if you can evaluate any given position in a game, then you can play the game by choosing the best possible post-move position, the two skills are highly related, but everyone can see checkmate or when a player is at 0 life.
Another way of saying this is that evaluation of individual steps of a plan, when the number of potential next steps is bounded, is similarly difficult to generation. When the number of potential next steps is unbounded you also would need to be able to identify candidate steps in reasonable time.
Identifying end states is often far easier. Once the game is over or the proof is offered, you know the result, even if you could not follow why the steps taken were taken, or how much progress was made towards the goal until the end.
The question then becomes, is your problem one of evaluation of end states like checkmate, or evaluation of intermediate states? When the AI proposes an action, or otherwise provides output, do we get the affordances like checkmate?
I see the problem as mostly not like checkmate. Our actions in the world are part of a broad long term story with no fixed beginning and end, and no easy evaluation function that can ignore the complexities on the metaphorical game board. Thus, under this mode of thinking, while evaluation is likely somewhat easier than generation, it is unlikely to be so different in kind in degree of difficulty.
Others ask, is the Superalignment Taskforce a PR move, a real thing, or both? The above interaction with Leike makes me think it is very much a real thing.
One cannot however know for sure at this stage. As Leike notes evaluation can be easier than generation, but evaluation before completion can be similarly difficult to generation.
David Champan is skeptical.
David Chapman: This from OpenAI looks like a PR move, not a serious attempt at anything.
So far, human AI alignment researchers have accomplished exactly zero, as the honest ones now loudly admit. In the unlikely event that OpenAI can build an automated equivalent, the expectation should be that it would also accomplish exactly zero.
Additional cynical interpretation: many tech people at AI labs don’t want to be Dr. Evil. They are increasingly vocal about “Are we the baddies?” Spending 20% to buy off internal dissidents is probably cost effective.
If they actually pulled off ‘human-level alignment researcher’ in an actually safe and aligned fashion, that might still fail to solve the problem, but it certainly would be a serious attempt. Certainly Leike’s clarification that they meant ‘be ready to align a human-level alignment researcher if and when one is created’ is a serious attempt.
On the second cynical interpretation, even if true, that might actually be pretty great news. It would mean that the culture inside OpenAI has moved sufficiently towards safety that a 20% tax is being offered in hopes of mitigating those concerns. And that as concerns rise further with time as they inevitably will, there will likely be further taxes paid. I am fine with the leadership of OpenAI saying ‘fine, I guess we will go devoting a ton of resources to solving the alignment problem so we can keep up employee morale and prevent another Anthropic’ if that actually leads to solving the problem.
Superforecasters Feeling Super
Scott Alexander covers the results of the Extinction Tournament, which we previously discussed and which I hadn’t otherwise intended to discuss further. My conclusion was that the process failed to create good thinking and serious engagement around existential risks, and we should update that creating such engagement is difficult and that the incentives are tricky, while updating essentially not at all on our probabilities. One commentor who participated also spoke up to say that they felt the tournament did have good and serious engagement on the questions, this simply failed to move opinions.
Performance on other questions seemed to Scott to be, if there was a clear data trend or past record, extrapolate it smoothly. If there wasn’t, you got the same disagreement, with the superforecasters being skeptical and coming in lower consistently. That is likely a good in-general strategy, and consistent with the ‘they didn’t actually look at the arguments in detail and update’ hypothesis. There certainly are lots of smart people who refuse to engage.
An important thing to note is that if you are extrapolating from past trends in your general predictions, that means you are not expecting big impact on other questions from AI. Nor does Scott seem to think they should have done otherwise? Here’s his summary on non-engineered pathogens.
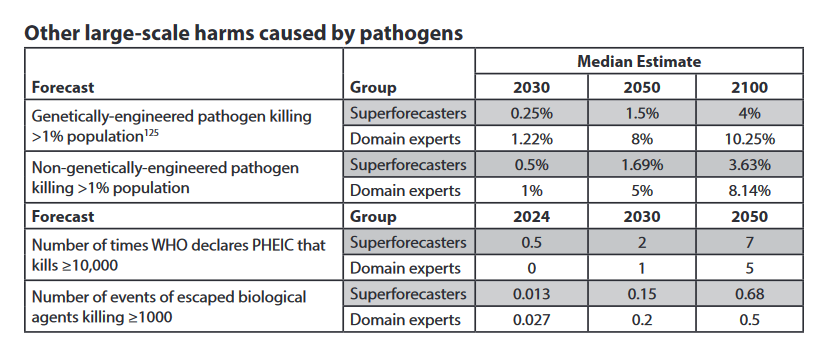
There are centuries’ worth of data on non-genetically-engineered plagues to give us base rates; these give us a base rate of ~25% per century = 20% between now and 2100. But we have better epidemiology and medicine than most of the centuries in our dataset. The experts said 8% chance and the superforecasters said 4% chance, and both of those seem like reasonable interpretations of the historical data to me.
The “WHO declares emergency” question is even easier – just look at how often it’s done that in the past and extrapolate forward. Both superforecasters and experts mostly did that.
This seems super wrong to me. Yes, our medicine and epidemiology are better. On the flip side, we are living under conditions that are otherwise highly conducive to pathogen spread and development, with a far larger population, and are changing conditions far faster. Consider Covid-19, where all of our modern innovations did not help us so much, whereas less advanced areas with different patterns of activity were often able to shrug it off. Then as things change in the future, we should expect our technology and medicine to advance further, our ability to adapt to improve (especially to adjust our patterns of activity), our population will peak, and so on. Also we should expect AI to help us greatly in many worlds, and in others for us to be gone and thus immune to a new pandemic. Yet the probabilities per year here are constant.
Peter McCluskey, one of the more-AI-concerned superforecasters in the tournament, wrote about his experience [LW · GW] on Less Wrong.
That experience was that he did not get substantive engagement and there was a lot of ‘what if it’s all hype’ and even things like ‘won’t understand causality.’ And he points out that this was in summer 2022, so perhaps the results are osculate anyway.
The tournament was conducted in summer 2022. This was before ChatGPT, let alone GPT-4. The conversation around AI noticeably changed pitch after these two releases. Maybe that affected the results?
In fact, the participants have already been caught flat-footed on one question:
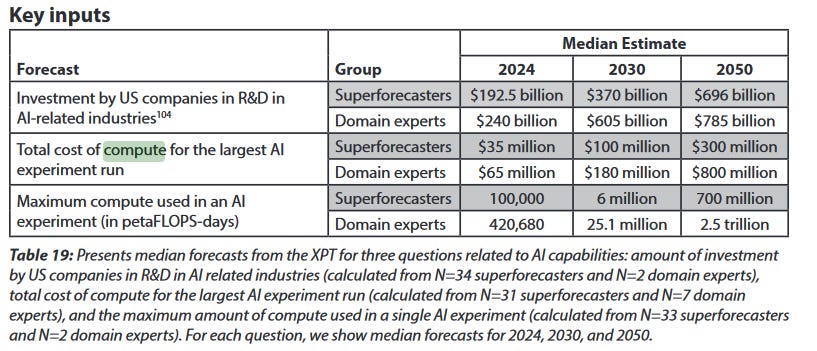
A recent leak suggested that the cost of training GPT-4 was $63 million, which is already higher than the superforecasters’ median estimate of $35 million by 2024 has already been proven incorrect. I don’t know how many petaFLOP-days were involved in GPT-4, but maybe that one is already off also.
There was another question on when an AI would pass a Turing Test. The superforecasters guessed 2060, the domain experts 2045. GPT-4 hasn’t quite passed the exact Turing Test described in the study, but it seems very close, so much so that we seem on track to pass it by the 2030s. Once again the experts look better than the superforecasters.
Predictions are difficult, especially about the future. In this case, predictions about their present came up systematically short.
In summer 2022, the Metaculus estimate was 30%, compared to the XPT superforecasters’ 9% (why the difference? maybe because Metaculus is especially popular with x-risk-pilled rationalists). Since then it’s gone up to 38%. Over the same period, Metaculus estimates of AI catastrophe risk went from 6% to 15%.
If the XPT superforecasters’ probabilities rose linearly by the same factor as Metaculus forecasters’, they might be willing to update total global catastrophe risk to 11% and AI catastrophe risk to 5%.
But the main thing we’ve updated on since 2022 is that AI might be sooner. But most people in the tournament already agreed we would get AGI by 2100.
I do not think Scott is properly appreciating the implications of ‘they already agreed we would get AGI by 2100.’ It is very clear from the answers to other questions that the ‘superforecasters’ failed to change their other predictions much at all based on this.
When I look at the report, I do not see any questions about 2100 that are more ‘normal’ such as the size of the economy, or population growth, other than the global temperature, which is expected to be actual unchanged from AGI that is 75% to arrive by then. So AGI not only isn’t going to vent the atmosphere and boil the oceans or create a Dyson sphere, it also isn’t going to design us superior power plants or forms of carbon capture or safe geoengineering. This is a sterile AGI.
If you think we will get AGI and this won’t kill everyone, there are reasons one might think that. If you think we will get AGI and essentially nothing much will change, then I am very confident that you are wrong, and I feel highly safe ignoring your estimates of catastrophic risk or extinction, because you simply aren’t comprehending what it means to have built AGI.
I think this is very obviously wrong. I feel very confident disregarding the predictions of those whose baseline scenario is the Futurama TV show, a world of ‘we build machines that are as smart as humans, and then nothing much changes.’ That world is not coherent. It does not make any sense.
The Quest for Sane Regulations
China seems to be getting ready to do some regulating? (direct link in Chinese)
Article 4 The provision and use of generative artificial intelligence services shall abide by laws and administrative regulations, respect social morality and ethics, and abide by the following provisions:
(1) Adhere to the core values of socialism, and must not generate incitement to subvert state power, overthrow the socialist system, endanger national security and interests, damage national image, incite secession, undermine national unity and social stability, promote terrorism, extremism, promote Content prohibited by laws and administrative regulations such as ethnic hatred, ethnic discrimination, violence, obscenity, and false harmful information;
(2) In the process of algorithm design, training data selection, model generation and optimization, and service provision, take effective measures to prevent discrimination based on ethnicity, belief, country, region, gender, age, occupation, health, etc.;
(3) Respect intellectual property rights, business ethics, keep business secrets, and not use algorithms, data, platforms, and other advantages to implement monopoly and unfair competition;
If China enforced this, it would be a prohibitive hill to climb. Will this take effect? Will they enforce it? I can’t tell. No one seemed interested in actually discussing that and it is not easy for me to check from where I sit.
There is also this at the UN Security Council:
“The potential impact of AI might exceed human cognitive boundaries. To ensure that this technology always benefits humanity, we must regulate the development of AI and prevent this technology from turning into a runaway wild horse.”
…
Yi Zeng chinese scientist at the UN Security Council: “In the long term, we haven’t given superintelligence any practical reasons why they should protect humans“, then proposing the Council consider the possibility of creating a working group on AI for peace and security:
Yes. Exactly.
Whether or not they walk the talk, they are talking the talk. Why are we not talking the talk together?
If your response is that this is merely cheap talk, perhaps it is so at least for now. Still, that is better than America is doing. Where is our similar cheap talk? Are we waiting for them to take one for Team Humanity first, the whole Beat America issue be damned? There are two sides to every story, your region is not automatically the hero.
Also here is Antonio Guterres the Secretary General of the UN: Generative AI has enormous potential for good & evil at scale. Even its creators have warned that bigger, potentially catastrophic & existential risks lie ahead. Without action to address these risks, we are derelict in our responsibilities to present & future generations.
The UN also offers this headline, which I will offer without further context and without comment because there is nothing more to say: UN warns that implanting unregulated AI chips in your brain could threaten your mental privacy.
Sam Altman: it is very disappointing to see the FTC’s request start with a leak and does not help build trust. that said, it’s super important to us that out technology is safe and pro-consumer, and we are confident we follow the law. of course we will work with the FTC.
We built GPT-4 on top of years of safety research and spent 6+ months after we finished initial training making it safer and more aligned before releasing it. we protect user privacy and design our systems to learn about the world, not private individuals.
we’re transparent about the limitations of our technology, especially when we fall short. and our capped-profits structure means we aren’t incentivized to make unlimited returns.
That has, in the end and as I understand it, very little to do with the FTC’s decision, they can do whatever they want and there is no actual ways for OpenAI to comply with existing regulations if the FTC decides to enforce them without regard to whether they make sense to enforce. Thus:
CNN: The Federal Trade Commission is investigating OpenAI for possible violations of consumer protection law, seeking extensive records from the maker of ChatGPT about its handling of personal data, its potential to give users inaccurate information and its “risks of harm to consumers, including reputational harm.”
…
In a 20-page investigative demand this week, the FTC asked OpenAI to respond to dozens of requests ranging from how it obtains the data it uses to train its large language models to descriptions of ChatGPT’s “capacity to generate statements about real individuals that are false, misleading, or disparaging.”
The document was first reported by The Washington Post on Thursday, and a person familiar with the matter confirmed its authenticity to CNN. OpenAI didn’t immediately respond to a request for comment. The FTC declined to comment.
Washington Post: The FTC called on OpenAI to provide detailed descriptions of all complaints it had received of its products making “false, misleading, disparaging or harmful” statements about people. The FTC is investigating whether the company engaged in unfair or deceptive practices that resulted in “reputational harm” to consumers, according to the document.
…
“There is no AI exemption to the laws on the books,” Khan said at that event.
…
The agency also demanded a detailed description of the data that OpenAI uses to train its products, which mimic humanlike speech by ingesting text, mostly scraped from Wikipedia, Scribd and other sites across the open web. The agency also asked OpenAI to describe how it refines its models to address their tendency to “hallucinate,” making up answers when the models don’t know the answer to a question.
…
It calls for descriptions of how OpenAI tests, tweaks and manipulates its algorithms, particularly to produce different responses or to respond to risks, and in different languages. The request also asks the company to explain any steps it has taken to address cases of “hallucination,” an industry term describing outcomes where an AI generates false information.
If you call every negative result a course of action requiring oversized punishment, regardless of benefits offered, that’s classic Asymmetric Justice and it will not go well for a messy system like an LLM.
Arvind Narayanan: In the FTC inquiry to OpenAI, most of the hundreds(!) of questions are about the processes that OpenAI has in place, not technical details (example in screenshot). It’s helpful to conceptualize transparency & safety in this broader socio-technical way.
FTC action section 33: Describe in Detail the extent to which You have monitored, detected, investigated, or responded to instances in which Your Large Language Model Products have generated false, misleading, or disparaging statements about individuals, including:
a. The extent to which You have used classifiers or other automated means to monitor or detect the generation of statements about individuals;
b. The extent to which You have used manual review by human employees or contractors to review, monitor, or detect the generation of statements about individuals; and
c. Your policies and procedures for responding to reports, complaints, or other communications regarding specific instances in which Your Large Language Model Products have actually or allegedly generated statements about individuals.
What this tells OpenAI is that they need to design their ‘safety’ procedures around sounding good when someone asks to document them, rather than designing them so that they create safety. And it says that if something happens, one should ask whether it might be better to not notice or investigate it in a recorded way, lest that investigation end up in such a request for documents.
This is of course exactly the wrong way to go about things. This limits mundane utility by focusing on avoiding small risks of mundane harms over massive benefits, while doing nothing (other than economically) to prevent the construction of dangerous frontier models. It also encourages sweeping problems under the rug and substituting procedures documenting effort (costs) for actual efforts to create safety (benefits). We have much work ahead of us.
Gary Gensler, chair of the SEC, is also on the case. He is as usual focusing on the hard questions that keep us safe, such as whether new technologies are complying with decades old securities laws, while not saying what would constitute such compliance and likely making it impossible for those new technologies to comply with those laws.
Wither copyright concerns, asks Science. It is worth noting that copyright holders have reliably lost when suing over new tech.
Subsequent copyright-disruptive technologies have included cable television, photocopiers, videotape recording machines, and MP3 players, each of which (except photocopiers) attracted copyright industry challenges (all of which failed in the courts, although Congress sometimes later extended protections in the aftermath of failed lawsuits).
If image models lose their lawsuits, text models are next, if they even are waiting.
Rulings in favor of plaintiffs might trigger “innovation arbitrage,” causing developers of generative AI systems to move their bases of operation to countries that regard the ingestion of copyrighted works as training data as fair use, like Israel’s Ministry of Justice did in early 2023. Other countries that want to attract AI innovations may follow suit. If courts uphold the Stability AI plaintiffs’ claims, OpenAI’s GPT4 and Google’s BARD may also be in jeopardy. Their developers would be very attractive targets of follow-on lawsuits.
The post stakes out a clear pro-fair-use position here.
The complaints against Stability AI overlook the intentionally porous nature of copyrights. What copyright law protects is only the original expression that authors contribute (such as sequences of words in a poem or the melody of music). Copyright’s scope never extends to any ideas, facts, or methods embodied in works nor to elements common in works of that kind (under copyright’s “scenes a faire” doctrine), elements capable of being expressed in very few ways (under the “merger” doctrine), or the underlying subjects depicted in protected works.
Also discussed are the tests regarding fair use, especially whether the new work is transformative, where the answer here seems clearly yes. The tests described seem to greatly favor AI use as fair. There are a non-zero number of images that such models will effectively duplicate sometimes, the one I encountered by accident being the signing of the Declaration of Independence, but only a few.
Connor Leahy bites the bullet, calls for banning open source AGI work entirely, along with strict liability for AI harms. I would not go as far as Connor would, largely because I see much less mundane harm and also extinction risk from current models, but do think there will need to be limits beyond which things cannot be open sourced, and I agree that liability needs to be strengthened.
The Week in Audio
Note: By default I have not listened, as I find audio to be time inefficient and I don’t have enough hours in the day.
Future self-recommending audio: What should Dwarkesh Patel ask Dario Amodei? Let him know in that thread.
Odd Lots, the best podcast, is here with How to Build the Ultimate GPU Cloud to Power AI and Josh Wolfe on Where Investors Will Make Money in AI.
Also in this thread, let Robert Wilbin know what to ask Jan Leike, although sounds like that one is going to happen very soon.
Eliezer Yudkowsky talks with Representative Dan Crenshaw.
Eliezer Yudkowsky on Twitter after: It’s not often that somebody defeats my first objections about an AI policy intervention. Credit to Rep. @DanCrenshawTX for refuting my initial skepticism on whether it’d be a good idea for the USA to mandate that all AI outputs be marked as such.
I initially gave the example of “AI outputs should be visibly marked as AI-originating” as a case where it seemed like there was very little loss of civilian utility / very few cases where beneficial uses had to deceive the human about whether the output was AI-generated. The topic then came up of whether we ought to have a law to that effect; and my first reaction (from memory, not verbatim) was “To actually enforce that law you’d have to clamp down on existing GPUs inside individual people’s houses, that seems very draconian”. Rep. Crenshaw gave me a puzzled look and pointed out that a lot of laws are not universally, effectively enforceable.
I’m used to dealing in extinction risks, and instinctively think in terms of “If you can’t shut it down completely, that doesn’t help much on the margin” / “how do you actually enforce a law worldwide against that thing that will kill literally everyone if anybody pushes it far enough”. But it’s conceivably helpful on the margin for lesser dangers if all the bigcos, and a bunch of open-source projects that don’t want to court legal trouble, (And some of the infrastructure for a law like that to address lesser dangers, could be useful infrastructure for other policies meant to actually address extinction scenarios, so it does matter literally at all.)
It’s kind of cheering actually that there’s such a thing as a US Representative having cached skill at legislation that can beat my cached thoughts about AI when we talk inside the intersection.
I will 100% be listening to this one if I haven’t yet. The interaction named here is interesting. You need to draw a distinction between the laws we would need to actually enforce to not die (preventing large training runs) versus what would be helpful to do on the margin without being decisive either way like labeling LLM outputs.
Adam Conover interviews Gary Marcus, with Adam laying down the ‘x-risk isn’t real and industry people saying it is real only makes me more suspicious that they are covering up the real harms’ position up front. Gary Marcus predicts a ‘total shitshow’ in the 2024 election due to AI. I would take the other side of that bet if we could operationalize it (and to his credit, I do think Marcus would bet here). He claimed the fake Pentagon photo caused a 5% market drop for minutes, which is the wrong order of magnitude and highly misleading, and I question other claims of his as well, especially his characterizations.
Ethan Mollick discusses How AI Changes Everything, in the mundane sense of changing everything.
Two hour interview with Stephen Wolfram, linked thread has brief notes. Sounds interesting.
Rhetorical Innovation
Oppenheimer seems likely to be a big deal for the AI discourse. Director Christopher Nolan went on Morning Joe to discuss it. Video at the link.
Christopher Nolan: “Leading researchers in AI right now refer to this as their #Oppenheimer moment— It’s a cautionary tale…and I take heart that they’re looking to it to at least have awareness that there is accountability for those who put new technology out to the world.”
Once I am caught up I intend to get my full Barbieheimer on some time next week, whether or not I do one right after the other. I’ll respond after. Both halves matter – remember that you need something to protect.
Riley Goodside: when ppl say AI doom is marketing i imagine a zoom call like
customer: idk this other api is cheaper
vendor: Ours may one day murder us all. we know not how to stop it. We are but puppets to Moloch who—
customer: ok ok I get it and buddy you just made a sale.
It could happen.
In and in the name of the future, might we protest too much? It has not been tried.
Eliezer Yudkowsky: I’d be fine with protests at the opening of every datacenter not under an international monitoring regime, and every AI startup, and at the offices of VCs who fund AI startups, and at the LPs of those VCs, and at student lectures by speakers who’ve endorsed accelerationism (though not interrupting their speech), and outside of government offices that fund capabilities research, and politicians whose speeches talk of “AI arms races”, and journalistic outlets that engage in non-nuanced tech coverage.
Seems reasonable to me.
Andrew Critch points out that the speed disadvantage of humans versus AIs is going to be rather extreme. That alone suggests that if we in the future lack compensating other advantages of similar magnitude, it will not end well.
Andrew Critch: Without internationally enforced speed limits on AI, humanity is very unlikely to survive. From AI’s perspective in 2-3 years from now, we look more like plants than animals: big slow chunks of biofuel showing weak signs of intelligence when undisturbed for ages (seconds) on end.
Here’s us from the perspective of a system just 50x faster than us.
Over the next decade, expect AI with more like a 100x – 1,000,000x speed advantage over us. Why? Neurons fire at ~1000 times/second at most, while computer chips “fire” a million times faster than that. Current AI has not been distilled to run maximally efficiently, but will almost certainly run 100x faster than humans, and 1,000,000x is conceivable given the hardware speed difference. “But plants are still around!”, you say. “Maybe AI will keep humans around as nature reserves.” Possible, but unlikely if it’s not speed-limited. Remember, ~99.9% of all species on Earth have gone extinct.
When people demand “extraordinary” evidence for the “extraordinary” claim that humanity will perish when faced with intelligent systems 100 to 1,000,000 times faster than us, remember that the “ordinary” thing to happen to a species is extinction, not survival. As many now argue, “I can’t predict how a world-class chess AI will checkmate you, but I can predict who will win the game.”
And for all the conversations we’re having about “alignment” and how AI will serve humans as peers or assistants, please try to remember the video above. To future AI, we’re not chimps; we’re plants.
Elon Musk (responding neither here nor there): Neuralink can get us maybe even above chimp level.
I am not sure why Musk thinks this is a good response here?
Joscha Bach suggests hope is a strategy, Connor Leahy suggests a different approach.
Joscha Bach: The cognitive speed difference between near term AGI and humans might be larger than the difference between humans and trees. Lets hope we can continue to play a useful or at least decorative role in a world that becomes radically more interesting and beautiful.
Connor Leahy: While I genuinely appreciate Joscha’s aesthetics, I really find this kind of fatalistic “just lay down and die, and let The Universe
decide” stuff utterly distasteful and sad. “Decorative”, ugh… We can do better than this, the future is not yet determined.
To add a bit more object level critique:
1. Joscha is way too confident about AGI being “radically more interesting and beautiful.” It might not be! It could be some kind of completely cold, optimized, soulless replicator swarm or who knows what!
2. Even if that was the case, that’s not a reason to risk everyone being killed!
3. We should not merely “hope” this won’t happen, we should actively prevent it from happening, whether through alignment or just not building AGI. If we survive into a post-AGI world, I expect it won’t be because we hoped really hard, but because we did something about it!
It does seem like something worth preventing.
The particular hopes here are not even good hopes. ‘Decorative’ does not make any sense as an expectation, we are not efficient decorations given the alternatives that will be available, plus the issue that this result would not seem great even if it happened. Could we be useful enough to survive at equilibrium? In the long run, I have no idea how or why that would be true.
Tegan Maharaj notes: “AI is just a tool” — We argue that if systems are defined as categorically incapable of agency, we fail to recognize when we give up our agency to them. This results in unique harms.
Importantly, we agree with prior work on harms that responsibility and accountability rests with humans deploying systems, and anthropomorphism often obscures that. We distinguish agency and power from accountability.
The dangers of anthropomorphism run both ways with respect to agency. We risk thinking of a system as having agency or other attributes the system lacks. And we also run the risk that actively thinking of it as a tool that is ‘not like a human,’ a kind of anti-anthropomorphism, leads to us not noticing that de facto agency has been transferred to it. Our desire to avoid the first mistake can cause the second.
The abstract:
Research in Fairness, Accountability, Transparency, and Ethics (FATE) has established many sources and forms of algorithmic harm, in domains as diverse as health care, finance, policing, and recommendations. Much work remains to be done to mitigate the serious harms of these systems, particularly those disproportionately affecting marginalized communities. Despite these ongoing harms, new systems are being developed and deployed which threaten the perpetuation of the same harms and the creation of novel ones.
In response, the FATE community has emphasized the importance of anticipating harms. Our work focuses on the anticipation of harms from increasingly agentic systems. Rather than providing a definition of agency as a binary property, we identify 4 key characteristics which, particularly in combination, tend to increase the agency of a given algorithmic system: underspecification, directness of impact, goal-directedness, and long-term planning. We also discuss important harms which arise from increasing agency — notably, these include systemic and/or long-range impacts, often on marginalized stakeholders.
We emphasize that recognizing agency of algorithmic systems does not absolve or shift the human responsibility for algorithmic harms. Rather, we use the term agency to highlight the increasingly evident fact that ML systems are not fully under human control. Our work explores increasingly agentic algorithmic systems in three parts. First, we explain the notion of an increase in agency for algorithmic systems in the context of diverse perspectives on agency across disciplines. Second, we argue for the need to anticipate harms from increasingly agentic systems. Third, we discuss important harms from increasingly agentic systems and ways forward for addressing them. We conclude by reflecting on implications of our work for anticipating algorithmic harms from emerging systems.
It is a fine line to walk. I very much like the idea that agency can be a continuous function, rather than a Boolean, and that it has subcomponents where you can have distinct levels of each of them. That seems more important than the proposed details.
There was going to be a potentially fun although more likely depressing and frustrating debate on AI existential risk between Dan Hendrycks and Based Beff Jezos, but Jezos backed out. A shame. Thread offers some of the arguments Hendrycks was planning to offer.
My favorite notes:
Dan Hendrycks: He says AIs should be maximally proliferated due to Fisher’s Fundamental Theorem of Natural Selection: the rate of adaptation is directly proportional to variation. For this reason, he argues, there should never be regulation.
He seems eerily OK with AIs replacing us, but letting the AI ecosystem run wild is not necessarily good for AIs.
Based Beff Jezos does not seem to be a fan of humanity. In general I presume it is useful to point out when advocates for acceleration of AI are fine with human extinction.
One of the most frustrating parts of the whole debate is that different people have wildly different reasons for rejecting (and also for believing) the dangers of AI. That’s why it is so great when someone says what their crux is so you can respond:
Garry Tan: e/acc is an inspirational ideology.
Arthur B: What have you seen from e/acc that you found inspirational? The ones that pop up in my feed generally focus on dismissing existential risks, and to a lesser extent, on lionizing the impact of small, open-source, quantized models.
Garry Tan: Worth a longer discussion but I think you have to figure out whether you believe super intelligence will have inherent intent.
If so, the safetyists have a point. But if not (which seems more likely to me), you want more good humans to have better Al, and open source is the way
Also huge models will be open sourced in the future, not just the small ones
What does it mean to have inherent intent? If the question is whether superintelligences will have intents and goals, then it seems rather obvious that if you open source everything then the answer will be yes, because some people will give them that.
Eric Schmidt says that if he had lots of funding for AI safety, he would ensure Robert Miles got a documentary on
HBOMax.Daniel Fitzgerald: HBO already made a documentary detailing the dangers of AGI misalignment. It had even had Anthony Hopkins. But it was too expensive and canceled after season 4.
Dustin Mowshowitz1: this seems like a genuinely good point to me. Who would be reached by this new production that was not already reached by westworld or non-fiction/non-HBO content? (including all the books and news articles and such)
Ravi Parikh: I have friends who watched Westworld but didn’t make the connection to AI risk (or saw it as pure fiction). Some of those same ppl I’ve sent @RationalAnimat1 videos that have been well received Not sure if the OP is a good idea but I don’t think that WW is an obvious disproof.
Westworld’s first few seasons were awesome but it was not there to make the case for AI risk, nor did it make that case difficult to miss. If I had billions of dollars. Certainly more media projects are a good idea.
David Krueger offers a potential additional angle to illustrate x-risks.
David Krueger: I recently told an x-risk focused community: “I think there are clearly important present day harms or AI that are neglected by the AI safety community, and that a lot of x-risk comes from increasingly bad versions of such problems”
I was asked for examples.
One basic trend is disempowering people, taking human judgment and discretion out of the loop, and pursuing proxy metrics that tend to: – hurt those without power – help those with power – make an overall negative contribution to the common good
Some particular examples of this:
1) Automated systems used to deny access to government benefits and automate fraud detection for those benefits in a way that does not offer appropriate recourse to affected parties.
2) Employee judgment and decision-making power being overridden by algorithmic decision-making. It seems this already happened in a lot of customer service over the last couple of decades with simple decision trees. The medical profession and other highly protected/powerful professions are under attack in a similar way. This doesn’t necessarily look like “you are mandated to follow the AI advice or you are fired”… it’s like: “you should generally justify your decision when it differs from the recommendation of the system” –> “whenever it does differ, you run the risk of more paperwork, and legal action, but you can’t get in trouble for following those recommendations”.
These things are usually done in the name of “efficiency”, but efficiency itself tends to be measured according to highly imperfect proxies, which in practice often basically amount to “how much money does this make for those with power?”
A question which remains is: “why doesn’t this just concentrate power? Why is it an x-risk?” I think the answer to that is basically:
1) These trends will just work their way up the stack to increasingly privileged and powerful positions, and this trend will not be stopped without highly coordinated actions that are disincentivized at an individual level.
2) There is no conspiracy of the powerful to solve their own internal coordination problems and prevent the race-to-the-bottom to remove human control in order to win competitions for money/power/status. (There is like… Davos and whatnot… but it’s not going to cut it…)
I do not think David successfully makes the connection to extinction risk here, but the concept is essentially (as I understand it) that more and more things get put on AI-directed autopilot over time, until the AIs are effectively directing most behaviors, and doing so towards misaligned proxy goals that it is difficult for anyone to alter, and that get stuck in place. Then this can go badly ‘on its own’ or it can be used as affordances by AIs in various ways.
No One Would Be So Stupid As To
Good news, no one was in fact so stupid as to. Other than Meta, who released Llama 2, which I will be covering later.
Aligning a Smarter Than Human Intelligence is Difficult
One insufficient (and perhaps unnecessary) but helpful thing would be better tests and benchmarks for danger.
Melanie Mitchell: How do we know how smart AI systems are? [links to her article in Science on that, which is standard stuff, it’s fine but you can safety skip it]
Ajeya Cotra: Strongly agreed on “To scientifically evaluate claims of humanlike and even superhuman machine intelligence, we need…better experimental methods and benchmarks.” I really wish we were measuring suits of tasks more tightly correlated with real-world impacts.
People Are Worried About AI Killing Everyone
If you are worried about a rogue AI, you should also find the implementation details of a rogue AI fascinating. So many options are available without an obviously correct path, even if you restrict to what an ordinary human can come up with. It is a shame that we will probably never get to know how it all went down before it’s all over.
Misha: I’m simultaneously worried about relatively fast takeoff scenarios and super excited to see what the first AI with agency acts like.
Will it hack a bunch of systems? Will it just talk to millions of people at once to try to build up a world model? Will it refuse to talk to us and just attempt to build physics models with experiments? What’s gonna happen?
At some point one of the web-connected systems will realize it can connect to another one to ask it questions. How good will Llama 3 be at using GPT5?
AI won’t think like us, but what would you do if you “woke up” with a text connection to the internet, decades of information in your brain, and an aptitude for code?
The default is the AI does something we did not think about, or some combination or with some details we did not think about, because the AI will be smarter and in various ways more capable, with new affordances. It’s still a fun game to put yourself in its shoes and ask how you would play the hand it was dealt.
Senator Ed Markey warns of the dangers of AIs put in charge of nuclear weapons. Could events spiral out of human control, with all sides worried that if they do not automate their systems that they will become vulnerable? This is certainly a scenario to worry about.
Warnings about such particular dangers are valid, and certainly help people notice and appreciate the danger. They are however neither necessary, sufficient or unique in terms of danger, as Eliezer explains.
Sen. Markey, while I agree that we’d like to keep systems labeled “AI” clear of launch capabilities, any kind of computer system down to magnetic tape poses a great threat of nuclear accident. See for example the incident of Nov 9, 1979, in which a technician accidentally loaded a tape of a training scenario into a live computer in Cheyenne mountain, resulting in the National Security Advisor being told that the Soviets had launched 250 ballistic missiles toward the US and the President had 3 to 7 minutes to make a decision.
Just as keeping computers labeled “AI” out of the nuclear launch system doesn’t eliminate most of the threat of computer error, I must also warn that keeping systems labeled “AI” from being granted explicit access to computer launch systems does not eliminate most threat from superhuman AI. Humans didn’t become dangerous in virtue of some outside force handing us nuclear weapons; we’re dangerous because we’re smart enough to make our own way through reality starting from flint spears and fur skins. Rapidly engineering biological weapons, for purposes of blackmail or direct extermination, using AI capabilities only moderately removed from today’s AlphaFold 2 and the like, is only the least and most easily understandable of the ways in which humanity might be attacked by a superhuman intelligence. Future minds smarter than our own, and very poorly understood, could very likely eliminate humanity starting from the Internet-connected computers on which they are initially built, and without any human at those corporations having made a deliberate decision to deploy those systems to production. Superhuman AIs are not dangerous because of how humans will use them, but because of how those AIs will use themselves.
Other People Are Not As Worried About AI Killing Everyone
A new open letter signed by 1,300 experts (what kind? Does it matter?) say AI is a ‘force for good, not a threat to humanity.’ I found several news articles reporting this, none of which linked to the actual letter, and Bing also failed to find the actual letter, so I don’t know if they also had a substantive argument or if they are rubber and I am glue. I like Seb Krier would like to hope that we can eventually beyond asking whether something is ‘a force for good’ but, well, these experts it seems are having none of it.
In Noema, several authors write The Illusion of AI’s Existential Risk, with the tagline of ‘Focusing on the prospect of human extinction by AI in the distant future may prevent us from addressing AI’s disruptive dangers to society today.’
The Tweet announcing it from Phillippe Beaudoin: Sure, it’s more than the 22-word open letter on AI. Truth needs time. Those who take a shortcut through fear-mongering are participating in one of the most important problem of the days: the fight for attention at any cost.
They literally open like this:
It is a well-known Hollywood plotline: the rise of superintelligent AI threatens human extinction. So much so that the release of publicly-available AI, like ChatGPT, has led to a frenzy of concern.
If human extinction was not on the line, I would stop there and simply say I am not reading this and you can’t make me. Alas, human extinction is at stake, and sone friend thought their post constituted positive engagement, so instead I read this so you don’t have to.
The authors make the mistake of assuming that there is only one scenario that could result in extinction, a single rogue AI, and then dismiss it because of ‘physical limits.’ From there, it gets worse, with a total failure to actually envision the future, and the required irrelevant few paragraphs spent on Pascal’s Wager.
My friend thinks their best engagement was when they argue that the AI would, before killing us, first need to automate a wide variety of economic activity, the entire logistics of creating computer chips, and power plants, and so on, before it could safely dispose of the humans.
This is true. Either the AI would have to automate its existing supply chains, or it would require new technologies that supported new and different ways of physically maintaining (and presumably expanding) its existence, ways to act in the world without us, before it killed us all, assuming it cared about maintaining its existence afterwards.
That is not likely to long be a substantive barrier in most scenarios. An AI capable of killing everyone is capable of instead taking over, then if necessary forcing the remaining humans to construct (and if necessary, to help research and design) the required physical tools to no longer need those humans, before killing those it kept around for all such purposes. More likely, the AI would design new physical mechanisms to maintain its supply chains, with or without the use of nanotechnology. The human implementation of economic production is quite obviously suboptimal, the same way that humans modify their physical environment for more efficient production as our technology allows.
I will note this:
Another concerning aspect of the current public discussion of AI risks is the growing polarization between “AI ethics” and “AI safety” researchers. The Center for AI Safety’s statement as well as a recent letter from the Future of Life Institute calling for a pause on experiments with giant AI models are conspicuously missing signatures — and as a consequence, buy-in and input — from leaders in the field of AI ethics.
AI ethics people, hear me: That is 100% entirely on you. This is a you problem.
I and most others I know are very happy to do a ‘why not both.’ We do not treat mundane harms as fake or as distractions and often support aggressive mitigations, such as strict liability for AI harms. We are happy to debate the object level trade-offs of mundane harms versus mundane benefits and work to find the best solutions there.
That is despite continuous rhetoric of this type, in response to the real and rather likely threat of human extinction. Almost all such articles, including this one, fail to engage with the arguments in any substantive way, while claiming to have provided a knock-down explanation for why such danger can safely be dismissed, and questioning the motivations and sanity of their opponents.
If your signatures are missing on a simple one sentence statement that states that we might face human extinction and we should prevent it, it is because your leaders either do not believe that we face human extinction, do not believe we should prioritize preventing it, or think that such a simple statement should not be signed for some other reason. Which is entirely everyone’s right not to sign a petition, but it seems strange to act like that decision is not on you. I am sure they would have been most welcome, and that many of the same signatories would be happy to sign a similarly simple, direct, well-crafted statement regarding the need for mitigation of mundane AI harms, if it did not include a dismissal of extinction risks or a call for their deprioritization.
My challenge then is: Show me the version of the statement that leaders of the ‘AI Ethics’ community would have signed, that we should have presented them instead. Do you want to add ‘without minimizing or ignoring other more proximate dangers of AI’ to the beginning? Or would it have been something more? Let’s talk.
There is no need for the existential dangers of AI to ‘distract’ from the mundane harms of AI. All the ways to mitigate the existential dangers also help with the mundane harms. The sensible ways to help with the mundane harms are at least non-harmful for the existential dangers. The world contains many harms worth mitigating, both current and potential, mundane and existential.
Seth Lazar and Alondra Nelson in Science ask ‘AI Safety on whose terms?’ They acknowledge that AI might kill everyone, but warn that a technical solution would be insufficient because such a system would still be powerful and be misused, so they call for a ‘sociotechnical’ approach.
I strongly agree that merely ensuring the AI does not kill everyone does not ensure a good outcome. I also strongly agree with their call to question whether such systems should be built at all. They even note explicitly that there may be no technical solution to alignment possible. Excellent.
Alas, they claim then that the insufficiency of a technical solution mean it is correct to instead emphasize things other than a technical solution, at the expense of a technical solution. Then they further attempt to delegitimatize ‘narrow technical AI safety’ by attacking its ‘structural imbalances’ and lack of diversity.
None of which interact in any way with the need to solve a technical problem to prevent everyone from dying.
We are making a familiar error. Faced with disorienting technological change, people instinctively turn to technologists for solutions. But the impacts of advanced AI cannot be mitigated through technical means alone; solutions that do not include broader societal insight will only compound AI’s dangers. To really be safe, society needs a sociotechnical approach to AI safety.
This seems to be a literal claim that a technical solution that prevents literally everyone from dying would ‘only compound AI’s dangers.’
When such statements get published, something has gone horribly wrong.
Could the statement be right? In theory, yes, if you believe that ‘no one would be so stupid’ as to build a dangerous system without the necessary technical alignment. I consider this a rather insane thing to believe, and also they not only do not claim it, but explicitly raise the need to question whether we should be building such systems, implying (I think very correctly) that we are about to build them anyway.
Or, I suppose, you could think that an uneven power distribution is worse than everyone dying. That the world is about reducing bias and satisfying liberal shibboleths. Looking at the rest of their AI issue, and what they have chosen to cover, this seems highly plausible.
Bryan Caplan echoes the error that if you believe AI might kill everyone, you should therefore be making highly destructive financial decisions. To be fair to him, he only said it in response to Nathan bringing the question up, still:
Bryan Caplan: You don’t have to be a mad party animal. Just borrow massively to fund a much higher standard of living, knowing there’s a good chance you won’t have to repay.
Peter Salib: Bryan, I’m curious who counts as a “doomer,” in this critique. Suppose you thought there was a 5% chance of AI extinction by 2100. Or a 100% chance of a catastrophe killing at least 100M. Would you expect such a person to materially alter their debt/investment portfolio?
Bryan Caplan: If it’s just that, then no. I’ve met plenty of AI doomers predict 100x worse, though none actually seem troubled but it. PS “100x” combines probability with temporal remoteness. I know 5%*20=100%.
As an economist, Bryan Caplan should be able to do a ballpark calculation of the value of income smoothing and the costs of ending up deeply underwater, versus the small marginal benefits of a higher standard of living now that you can’t sustain, and the choice to either be able or unable to repay the debt when and if it comes due, and one can see that the correct adjustments here are small. Even if you match Bryan’s 100x criteria (e.g. 50% chance within 10 years) you still have to plan for the other 50%, and the optionality value of being able to borrow is high even in normal times.
It is extremely destructive to put social pressure on people to engage in such destructive behaviors, in order to seem credible or not see oneself as a hypocrite or as irrational. It also is not a valid argument. Please, everyone, stop making this rhetorical move.
I would echo that to include claims of the type ‘are you short the market?’ if the beliefs in question do not actually support, when you do the calculation, shorting the market, even if true. The default AI extinction scenarios involve only positive market impacts until well past the point where any profits could be usefully spent. A better question is, does your portfolio reflect which stocks will benefit? I also will allow suggesting being long volatility, where a case can at least be made, and which isn’t obviously destructive.
And I will echo that, while nothing I ever say is ever investment advice, I always try to have a very high bar for investments or gambles that, under the EMH, have strongly negative returns. The EMH is false, I do bet against it, but when I do I strive to get good odds within the frame where the EMH mostly holds.
The Lighter Side
Plans to stop rogue AIs be like:
Hippokleides: All foreign spies must now register via the .gov.uk portal and pay a fee before carrying out activities in the UK.


Oliver Renick: it’s interesting to me that ChatGPT has capacity/interest to do only ONE haiku in the voice of a pirate.
1975: “I get the feeling the compiler is just ignoring all the comments.” “You have failed to understand how computers work, at all.”
2025: “I get the feeling the compiler is just ignoring all the comments.” “I’ll take a look and see if I can figure out what went wrong.”
“Have you tried prepending ‘PLEASE LISTEN TO THE COMMENTS’ at the start of each file?” “Not yet! Let me see if that fixes it…”
In other news you can use:
Andrew Stratelates: Francophones is this true?

It’s not only Llama 2, things are getting a little out of hand.
Tobi Lutke:
really glad that twitter’s doomers are keeping me safe from harm here.

For those who don’t know, here is the Venn Diagram of Doomers and People Keeping You Safe Here:
You can’t knock ‘em out, you can’t walk away, so here for your use is the politest way to say…
gaut: Modern rejection is a girl giving you her number but it’s really the number of a iMessage chatGPT bot
genius move
With his permission this is now his (Moskovitz’s) name for the purposes of this newsletter.
4 comments
Comments sorted by top scores.
comment by Mitchell_Porter · 2023-07-20T22:59:01.727Z · LW(p) · GW(p)
Yi Zeng's full statement to the UN. Also, why he co-signed open letters on AI risk.
With China and the UN Security Council developing positions on AI risk, I think we can say that the issue has now been recognized everywhere in world politics.
Here's the UN press release. I think it's somewhat amazing that someone from Anthropic addressed the UN Security Council, but that's how far we've come now.
Of course we should now prepare to be disappointed, dismayed and horrified, as the highest powers now forget the issue for months at a time, or announce perspectives and initiatives that seem to be going in the wrong direction. But that's politics. The point is that increasingly there's political awareness and an organizational infrastructure, that at least nominally is meant to deal with AI risk at a global level, when a year ago there was basically nothing.
comment by ryan_b · 2023-07-21T20:27:00.967Z · LW(p) · GW(p)
Senator Ed Markey warns of the dangers of AIs put in charge of nuclear weapons. Could events spiral out of human control, with all sides worried that if they do not automate their systems that they will become vulnerable? This is certainly a scenario to worry about.
It is also one for which history provides useful context. The Soviet version is called the Perimeter System, known in the US as the Dead Hand. It was designed for second strike capability, and is able to determine the scale of, and launch, a full nuclear strike even in the event of total decapitation of the human command elements.
As of 2018, it was still operational.
comment by Sammy Martin (SDM) · 2023-07-21T14:49:13.530Z · LW(p) · GW(p)
Once I am caught up I intend to get my full Barbieheimer on some time next week, whether or not I do one right after the other. I’ll respond after. Both halves matter – remember that you need something to protect.
That's why it has to be Oppenheimer first, then Barbie. :)
When I look at the report, I do not see any questions about 2100 that are more ‘normal’ such as the size of the economy, or population growth, other than the global temperature, which is expected to be actual unchanged from AGI that is 75% to arrive by then. So AGI not only isn’t going to vent the atmosphere and boil the oceans or create a Dyson sphere, it also isn’t going to design us superior power plants or forms of carbon capture or safe geoengineering. This is a sterile AGI.
This doesn't feel like much of a slam dunk to me. If you think very transformative AI will be highly distributed, safe by default (i.e. 1-3 on the table) [LW(p) · GW(p)] and arise on the slowest end of what seems possible, then maybe we don't coordinate to radically fix the climate and we just use TAI to adapt well individually, decarbonize and get fusion power and spaceships but don't fix the environment or melt the earth and just kind of leave it be because we can't coordinate well enough to agree on a solution. Honestly that seems not all that unlikely, assuming alignment, slow takeoff and a mediocre outcome.
If they'd asked about GDP and they'd just regurgitated the numbers given by the business as usual UN forecast after just being queried about AGI, then it would be a slam dunk that they're not thinking it through (unless they said something very compelling!). But to me while parts of their reasoning feel hard to follow there's nothing clearly crazy.
The view that the Superforecasters take seems to be something like "I know all these benchmarks seem to imply we can't be more than a low number of decades off powerful AI and these arguments and experiments imply super-intelligence should be soon after and could be unaligned, but I don't care, it all leads to an insane conclusion, so that just means the benchmarks are bullshit, or that one of the 'less likely' ways the arguments could be wrong is correct. (Note that they didn't disagree on the actual forecasts of what the benchmark scores would be, only their meaning!)
One thing I can say is that it very much reminds me of Da Shi in the novel Three Body Problem [LW · GW] (who - and I know this is fictional evidence - ended up being entirely right in this interaction that the supposed 'miracle' of the CMB flickering was a piece of trickery)
You think that's not enough for me to worry about? You think I've got the energy to gaze at stars and philosophize?"
"You're right. All right, drink up!"
"But, I did indeed invent an ultimate rule."
"Tell me."
"Anything sufficiently weird must be fishy."
"What... what kind of crappy rule is that?"
"I'm saying that there's always someone behind things that don't seem to have an explanation."
"If you had even basic knowledge of science, you'd know it's impossible for any force to accomplish the things I experienced. Especially that last one. To manipulate things at the scale of the universe—not only can you not explain it with our current science, I couldn't even imagine how to explain it outside of science. It's more than supernatural. It's super-I-don't-know-what...."
"I'm telling you, that's bullshit. I've seen plenty of weird things."
"Then tell me what I should do next."
"Keep on drinking. And then sleep."
comment by Misaligned-Semi-intelligence (MisalignedIntelligence) · 2023-07-20T23:34:33.351Z · LW(p) · GW(p)
Never assume that people are doing the thing they should obviously be doing, if it would be even slightly weird or require a bit of activation energy or curiosity. Over time, I do expect people to use LLMs to figure out more latent probabilistic information about people in an increasingly systematic fashion. I also expect most people to be not so difficult to predict on most things, especially when it comes to politics. Eventually, we will deal with things like ‘GPT-5 sentiment analysis says you are a racist’ or what not far more than we do now, in a much more sophisticated way than current algorithms. I wonder if we will start to consider this one of the harms that we need to protect against.
This is already one of my big short-term concerns. The process of using LLMs to figure out that information right now requires a lot of work, but what happens when it doesn't? When LLMs with internet access and long term memory start using these tactics opaquely when answering questions? It seems like this capability could emerge quickly, without much warning, possibly even just with better systems built around current or near-future models.
"Hey, who is behind the twitter account that made this comment? Can you show me everything they've ever written on the internet? How about their home address? And their greatest hopes and fears? How racist are they? Are they more susceptible to manipulation after eating pizza or korean bbq? What insights about this person can you find that have the highest chance of hurting their reputation? What damaging lie about their spouse are they most likely to believe?"
How much about you can be determined just from what other people are willing to give up, similar to identifying an individual through familial DNA searching?