AGI will be made of heterogeneous components, Transformer and Selective SSM blocks will be among them
post by Roman Leventov · 2023-12-27T14:51:37.713Z · LW · GW · 9 commentsContents
Implications for AI Safety R&D System-level explanation and control frameworks, mechanism design Implications for AI policy and governance None 9 comments
This post is prompted by two recent pieces:
First, in the podcast "Emergency Pod: Mamba, Memory, and the SSM Moment", Nathan Labenz described how he sees that we are entering the era of heterogeneity in AI architectures because currently we have not just one fundamental block that works very well (the Transformer block), but two kinds of blocks: the Selective SSM (Mamba) block has joined the party. These are natural opposites on the tradeoff scale between episodic cognitive capacity (Transformer's strong side) and long-term memorisation (selective SSM's strong side).[1]
Moreover, it's demonstrated in many recent works (see the StripedHyena blog post, and references in appendix E.2.2. of the Mamba paper) that hybridisation of Transformer and SSM blocks works better than a "pure" architecture composed of either of these types of blocks. So, we will probably quickly see the emergence of complicated hybrids between these two.[2]
This reminds me of John Doyle's architecture theory that predicts that AI architectures will evolve towards modularisation and component heterogeneity, where the properties of different components (i.e., their positions at different tradeoff spectrums) will converge to reflect the statistical properties of heterogeneous objects (a.k.a. natural abstractions, patterns, "pockets of computational reducibility") in the environment.
Second, in this article, Anatoly Levenchuk rehearses the "no free lunch" theorem and enumerates some of the development directions in algorithms and computing that continue in the shadows of the currently dominant LLM paradigm, but still are going to be several orders of magnitude more computationally efficient than DNNs in some important classes of tasks: multi-physics simulations, discrete ("system 2") reasoning (planning, optimisation), theorem verification and SAT-solving, etc. All these diverse components are going to be plugged into some "AI operating system", Toolformer-style. Then Anatoly posits an important conjecture (slightly tweaked by me): as it doesn't make sense to discuss some person's "values" without considering (a) them in the context of their environment (family, community, humanity) and (b) their education, it's pointless to discuss the alignment properties and "values" of some "core" AGI agent architecture without considering the whole context of a quickly evolving "open agency [LW · GW]" of various tools and specialised components[3].
From these ideas, I derive the following conjectures about an "AGI-complete" architecture[4]:
1. AGI could be achieved by combining just
(a) about five core types of DNN blocks (Transformer and Selective SSM are two of these, and most likely some kind of Graph Neural Network with or without flexible/dynamic/"liquid" connections is another one, and perhaps a few more)[5];
(b) a few dozen classical algorithms for LMAs [? · GW] aka "LLM programs" (better called "NN programs" in the more general case), from search and algorithms on graphs to dynamic programming, to orchestrate and direct the inference of the DNNs; and
(c) about a dozen or two key LLM tools required for generality, such as a multi-physics simulation engine like JuliaSim, a symbolic computation engine like Wolfram Engine, a theorem prover like Lean, etc.
2. The AGI architecture described above will not be perfectly optimal, but it will probably be within an order of magnitude from the optimal compute efficiency on the tasks it is supposed to solve[4], so, considering the investments in interpretability, monitoring, anomaly detection, red teaming, and other strands of R&D about the incumbent types of DNN blocks and NN program/agent algorithms, as well as economic incentives of modularisation and component re-use (cf. "BCIs and the ecosystem of modular minds [LW · GW]"), this will probably be a sufficient motivation to "lock in" the choices of the core types of DNN blocks that were used in the initial versions of AGI.
3. In particular, the Transformer block is very likely here to stay until and beyond the first AGI architecture because of the enormous investment in it in terms of computing optimisation, specialisation to different tasks, R&D know-how, and interpretability, and also, as I already noted above, because Transformer maximally optimises for episodic cognitive capacity and from the perspective of the architecture theory, it's valuable to have a DNN building block that occupies an extreme position on some tradeoff spectrum. (Here, I pretty much repeat the idea of Nathan Labenz, who said in his podcast that we are entering the "Transformer+" era rather than a "post-Transfromer" era.)
Implications for AI Safety R&D
The three conjectures that I've posited above sharply contradict another view (which seems to me broadly held by a lot of people in the AI safety community) in which a complete overhaul of the AI architecture landscape is expected when some new shiny block architecture that beats all the incumbents will be invented[6].
It's hard for me to state the implications of taking one side in this crux in the abstract, but on a more concrete example, I think this position informs my inference that working on an architecture that combines Transformer and Selective SSM blocks and training techniques to engineer an inductive bias for greater "self-other overlap" [LW · GW] is an R&D agenda with a relatively high expected impact. Compare with this inference by Marc Carauleanu [LW(p) · GW(p)] (note: I don't state that he necessarily expects a complete AI architecture overhaul at some point, but it seems that somebody who thought that would agree with him that working on combining Transformer and Selective SSM blocks for safety is of low expected impact because the AGI that might make a sharp left turn will contain neither Transformer nor Selective SSM blocks).
System-level explanation and control frameworks, mechanism design
Both Drexler's Open Agency Model and Conjecture's CoEms are modular and heterogeneous as I predict the AGI architecture will be anyway, but I remarked in the comments to both that component-level alignment and interpretability is not enough to claim that the system as a whole is aligned and interpretable (1 [LW(p) · GW(p)], 2 [LW(p) · GW(p)]).
My conjectures above call for more work on scientific frameworks to explain the behaviour of intelligent systems made of heterogeneous components (NNs or otherwise), and engineering frameworks for steering and monitoring such systems.
On the scientific side, see Free Energy Principle/Active Inference [? · GW] in all of its guises, Infra-Bayesianism [? · GW], Vanchurin’s theory of machine learning (2021), James Crutchfield's "thermodynamic ML" (or, more generally, Bahri et al.’s review of statistical mechanics of deep learning (2022)), Chris Fields' quantum information theory, singular learning theory [? · GW]. (If you know more general frameworks like these, please post in the comments!)
On the engineering (but also research) side, see Doyle's system-level synthesis, DeepMind's causal incentives working group, the Gaia Network [LW · GW] agenda, and compositional game theory. (If you know more agendas in this vein, please post in the comments!)
Implications for AI policy and governance
The view that AGI will emerge from a rapidly evolving ecosystem of heterogeneous building blocks and specialised components makes me think that "intelligence containment", especially through compute governance, will be very short-lived.
Then, if we assume that the "G factor" containment is probably futile, AI policy and governance folks should perhaps start paying more attention to the governance of competence through the control of the access to the training data. This is what I proposed in "Open Agency model can solve the AI regulation dilemma [LW · GW]".
In the Gaia Network proposal [LW · GW], this governance is supposed to happen at the arrow from "Gaia Network" to "Decision Engines" that is labelled "Data and models (for simulations and training)" (note that "Decision Engines" are exactly the "AGI-complete" parts of this architecture, not the Gaia agents):
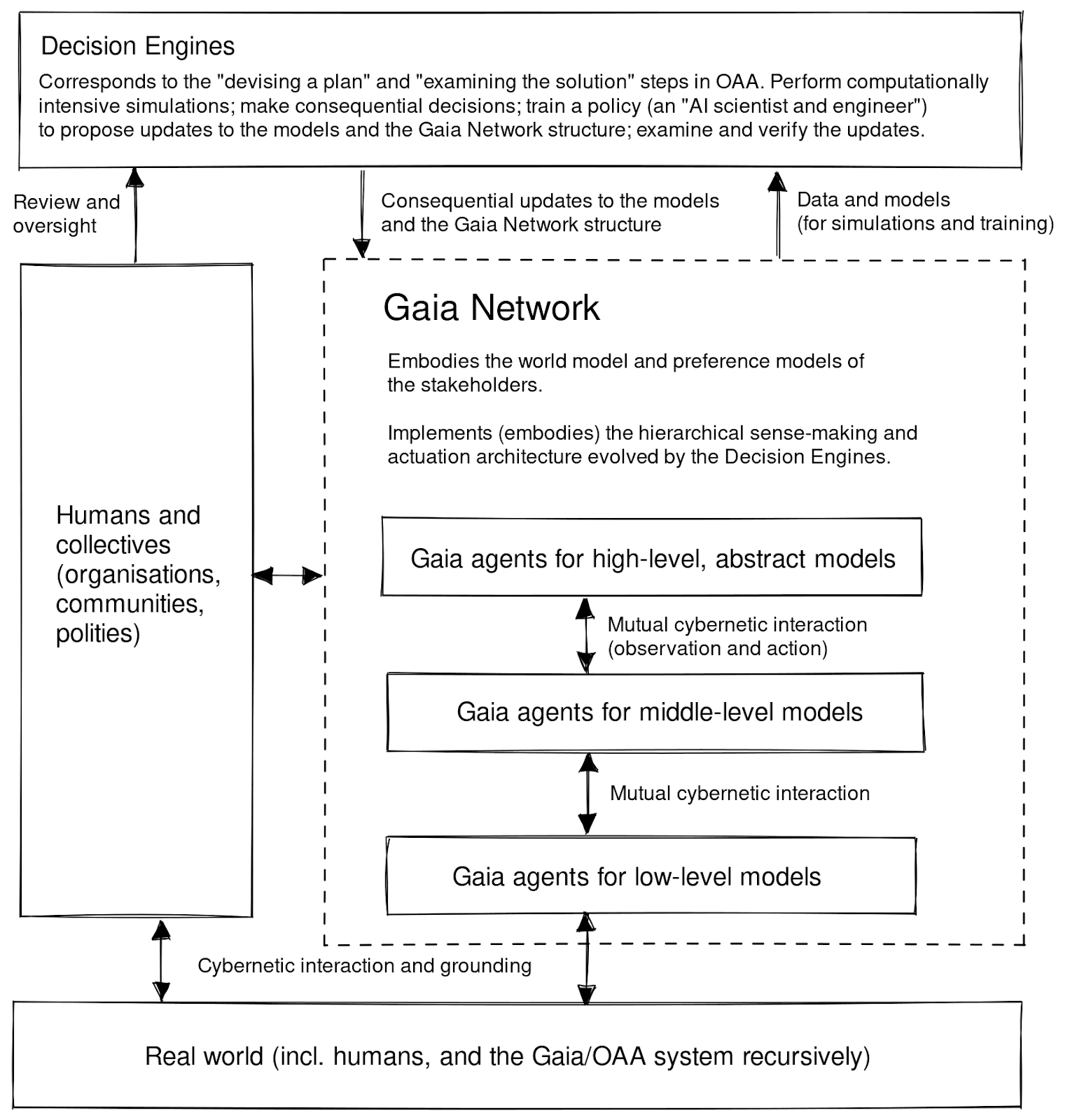
However, we didn't think about a concrete governance mechanism for this yet, and welcome collaborators to discuss it.
- ^
The tradeoff between episodic cognitive capacity and memorisation is fundamental for information-processing systems, as discussed by Fields and Levin: "The free-energy costs of irreversibility induce coarse-graining and attention-switching".
- ^
- ^
Anatoly also connects this trend towards AI component and tool diversification with the "Quality Diversity" agenda that looks at this component and architecture diversity as intrinsically advantageous even for capabilities.
- ^
"AGI" is taken here from OpenAI's charter: "highly autonomous systems that outperform humans at most economically valuable work". This is an important qualification: if we were to create an AI that should outperform all biological intelligence in all of its tasks in diverse problem spaces (such as protein folding, genetic expression, organismic morphology, immunity, etc.), much more component diversity would be needed that I conjecture below.
- ^
Here, it's important to distinguish the block architecture from the training objective. Transformers are not obliged to be trained solely as auto-regressive next token predictors; they can also be the working horses of GFlowNets that have different training objectives.
- ^
Additionally, it's sometimes assumed that this invention and the AI landscape overhaul will happen during the recursive self-improvement a.k.a. the autonomous takeoff phase.
9 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2023-12-27T18:49:28.524Z · LW(p) · GW(p)
For me, the legible way Mamba initially appeared important (among other RNN/SSM architectures) is its scaling laws, see Figure 4 in the paper. It's as good as LLaMA's recipe, 5 times more training compute efficient than GPT-3, RWKV, and Hyena, 2 times more than RetNet and H3.
But consider the observations in the StripedHyena post (section "Hybridization"). It shows that a mixture of Transformer and Hyena has better training efficiency than either Transformer or Hyena alone. In particular, a hybrid 75% Hyena 25% Transformer network is 2 times more training efficient than pure Transformer, which is in turn 2 times more training efficient than pure Hyena. There are links there to earlier experiments to this effect, it's not an isolated claim. So comparing pure architectures for training efficiency might be the wrong question to ask.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-12-27T20:11:28.150Z · LW(p) · GW(p)
The fact that hybridisation works better than pure architectures (architectures consisting of a single core type of block, we shall say), is exactly the point that Nathan Labenz makes in the podcast and I repeat in the beginning of the post.
(Ah, I actually forgot to repeat this point, apart from noting that Doyle predicted this in his architecture theory.)
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-27T20:46:52.135Z · LW(p) · GW(p)
Experimental results is a more legible and reliable form of evidence than philosophy-level arguments. When it's available, it's the reason to start paying attention to the philosophy in a way the philosophy itself isn't.
Incidentally, hybrid Mamba/MHA doesn't work significantly better than pure Mamba, at least the way it's reported in appendix E.2.2 of the paper (beware left/right confusion in Figure 9). The effect is much more visible with Hyena, though the StripedHyena post gives more details on studying hybridization, so it's unclear if this was studied for Mamba as thoroughly.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-12-28T05:15:28.519Z · LW(p) · GW(p)
This post hits a compromise between Thane's view [LW · GW] and Quinton/Nora Belrose's view.
I think It's closer to my view than either of the above, but I am somewhere between this and Thane's view. I, like Stephen Byrnes, suspect that AGI will be more effective and efficient once it has figured out how to incorporate more insights from neuroscience. I think there are going to be some fairly fundamental differences that make it hard to extrapolate specific findings from today's model architectures to these future architectures.
I can't be sure of this, and I certainly don't argue that work on aligning current models should stop, but I'm also not sure that even taking the more open-minded approach called upon here is sufficiently weird enough to capture the differences.
For example:
view that AGI will emerge from a rapidly evolving ecosystem of heterogeneous building blocks and specialised components makes me think that "intelligence containment", especially through compute governance, will be very short-lived.
Then, if we assume that the "G factor" containment is probably futile, AI policy and governance folks should perhaps start paying more attention to the governance of competence through the control of the access to the training data.
I completely agree with the first assertion that I expect compute governance to be fairly short lived. I'm hopeful it can grant us a couple years, but not hopeful that it can grant us 10 years.
However, I disagree with the second assertion that training data governance would be more helpful. I do think it wouldn't be a bad idea, especially with encouraging frontier labs to be more thoughtful about excluding some nasty weapons tech from the training data. I don't think you are likely to get an extended period of successful AI governance from including training data as well as compute.
For three reasons:
- a lot of internet data (text, video, audio, scientific data, etc.) is being generated in a rapid way. It would be far more difficult to regulate the secret collection of this general purpose data than it would be to restrict unauthorized use of large datacenters.
- If the 'more brain-like AGI' is the path forwards that the tech takes, then I expect from looking at the data rates of sensory inputs, adjusted for the learning-relevant information value of those inputs, and the rates of intra-brain-region communications, that data would be utilized far more effectively by brain-like AGI. Thus, data wouldn't be a bottleneck.
- I also expect that compute for the training and inference is going to be quite cheap relative to current frontier models. Despite this, I am hopeful for compute governance providing a delay because I expect that the fastest path from current models to brain-like AGI would be through using a combination of current models and various architecture search techniques to discover efficient ways to make a brain-like AGI. So by regulating the compute that someone could use to do that search, you slow down the initial finding of the better algorithm even though you fail to regulate the algorithm once it is discovered.
↑ comment by Roman Leventov · 2023-12-28T14:16:41.896Z · LW(p) · GW(p)
I agree that training data governance is not robust to non-cooperative actors. But I think there is a much better chance to achieve a very broad industrial, academic, international, and legal consensus about it being a good way to jigsaw capabilities without sacrificing the raw reasoning ability, which the opponents of compute governance hold as purely counter-productive ("intelligence just makes things better"). That's why I titled my post "Open Agency model can solve the AI regulation dilemma [LW · GW]" (emphasis on the last word).
This could even be seen not just as a "safety" measure, but as a truly good regularisation measure of the collective civilisational intelligence: to make intelligence more robust to distributional shifts and paradigm shifts, it's better to compartmentalise it and make communication between the compartments going through a relatively narrow, classical informational channel, namely human language or specific protocols rather than raw DNN activation dynamics.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-12-28T22:15:34.715Z · LW(p) · GW(p)
Yes, I agree there's a lot of value in thoughtful regulation of training data (whether government enforced or voluntary) by cooperative actors. You raise good points. I was meaning just to refer to the control of non-cooperative actors.
comment by mishka · 2023-12-28T06:17:18.583Z · LW(p) · GW(p)
when some new shiny block architecture that beats all the incumbents will be invented
Additionally, it's sometimes assumed that this invention and the AI landscape overhaul will happen during the recursive self-improvement a.k.a. the autonomous takeoff phase.
Actually, these things don't contradict each other. AutoML methods are great for automatically searching for strong ways to combine existing blocks into a single heterogeneous machine. They can be used now and even more so during recursive self-improvement.
And, at the same time, a few novel shiny block architectures can be found and added to the mix without phasing out the existing ones.
"intelligence containment", especially through compute governance, will be very short-lived
Yes, I also think that compute governance is unlikely to work for long.
People need to ponder a variety of alternative approaches to AI existential safety.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-12-28T14:25:55.150Z · LW(p) · GW(p)
I agree with everything you said. Seems that we should distinguish between a sort of "cooperative" and "adversarial" safety approaches (cf. the comment [LW(p) · GW(p)] above). I wrote the entire post as an extended reply to Marc Carauleanu upon his mixed feedback to my idea of adding "selective SSM blocks for theory of mind" to increase the Self-Other Overlap in AI architecture as a pathway to improve safety. Under the view that both Transformer and Selective SSM blocks will survive up until the AGI (if it is going to be created at all, of course), and even with the addition of your qualifications (that AutoML will try to stack these and other types of blocks in some quickly evolving ways), the approach seems solid to me, but only if we also make some basic assumptions about the good faith and cooperativeness of the AutoML / auto takeoff process. If we don't make such assumptions, of course, all bets are off, these "blocks for safety" could just be purged from the architecture.
Replies from: mishka↑ comment by mishka · 2023-12-28T15:33:51.416Z · LW(p) · GW(p)
Yes, I strongly suspect that "adversarial" safety approaches are quite doomed. The more one thinks about those, the worse they look.
We need to figure out how to make "cooperative" approaches to work reliably. In this sense, I have a feeling that, in particular, the approach being developed by OpenAI has been gradually shifting in that direction (judging, for example, by this interview with Ilya I transcribed: Ilya Sutskever's thoughts on AI safety (July 2023): a transcript with my comments [LW · GW]).