ACI#8: Value as a Function of Possible Worlds
post by Akira Pyinya · 2024-06-03T21:49:02.345Z · LW · GW · 2 commentsContents
Beyond the reward hypothesis Value is the probability of doing the right thing Value is a function of possible worlds Value is not a function of states of the world The Definition of reward Why the discount rate? References None 3 comments
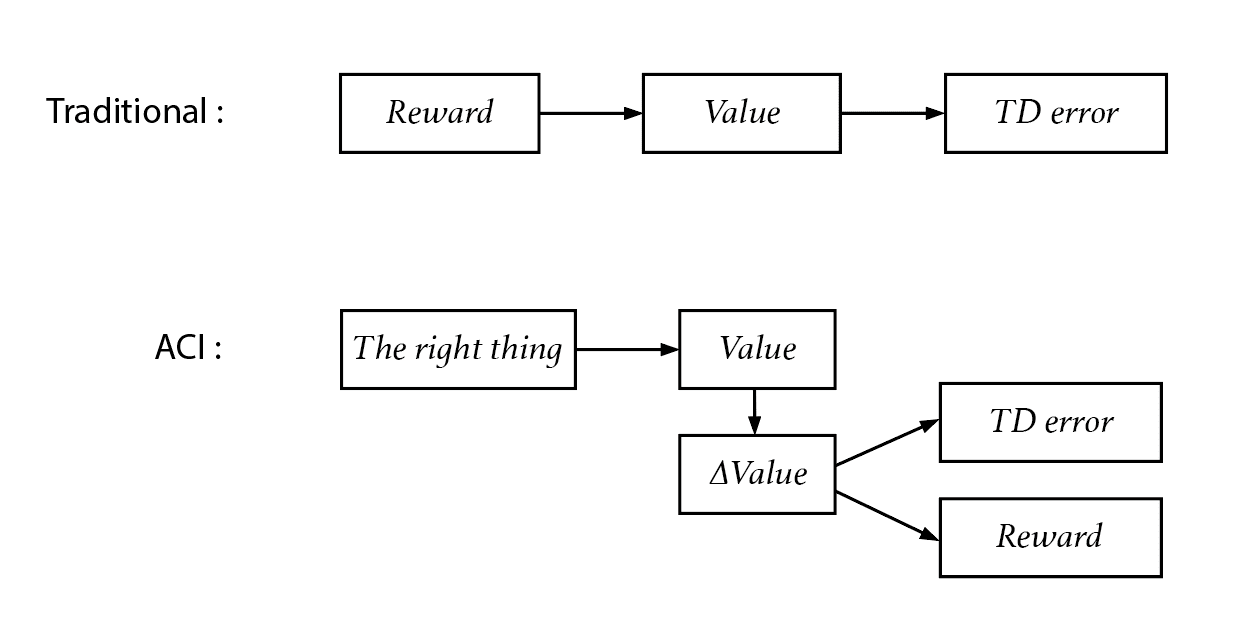
What is value? What are rewards? In traditional models of intelligence, we don't have to worry about these questions. Reward is simply what we need to maximize, and value (or utility) represents total expected rewards. You don't need to question these fundamental assumptions of the model.
In contrast, ACI argues that reward is not fundamental to intelligence behaviors, and that value functions are neither arbitrary nor predetermined. Instead, they are derived from ACI's first principle: "Do the same thing as the examples of the right things". Value represents the probability of doing the right thing, and reward can be derived from value. Maximizing total rewards or value is not everything. However, reward and value are still useful concepts, that's why we need to derive them in the framework of ACI.
We believe that ACI has more explanatory power than traditional models. One example is the discounting factor, which indicates how future rewards are less desirable than current rewards. ACI suggests that the discount factor is not just a mathematical trick, but a measure of the inherent uncertainty of value functions.
Beyond the reward hypothesis
Modern reinforcement learning approaches are constructed upon the basis of the reward hypothesis, which argues that "all of what we mean by goals and purposes can be well thought of as maximization of the expected value of the cumulative sum of a received scalar signal (called reward)."(Sutton & Barto 2018)
But the concept of reward is tricky. It's deeply rooted in the agent-environment dualism [LW · GW] (Demski & Garrabrant 2019). Reward is presumably computed inside the physical body of natural and artificial intelligence systems, but in reinforcement learning models, reward is always considered to come from the environment because it cannot be changed arbitrarily, otherwise the task itself can be changed arbitrarily (Sutton & Barto 2018).
Furthermore, there's no evidence that reward signals really exist in natural intelligence systems. The dopamine TD-error hypothesis argues that the phasic response of dopamine neurons corresponds to TD error, the difference between value estimations (Niv et. al. 2005) , rather than corresponding to reward. Reward is arguably "an abstraction summarizing the overall effect of a multitude of neural signals generated by many systems"(Sutton & Barto 2018) .
In other words, reward is a theoretical abstraction in dualistic models, not a real existing signal. However, traditional models need the concept of reward to define value functions and TD error, as no other proposition can provide a better basis for action selection other than reward. On the contrary, ACI constructs the intelligence model and defines the value function without referring to the reward hypothesis.
Value is the probability of doing the right thing
According to ACI, value is the probability of doing the right thing:
The value for a possible world or a distribution on possible worlds is its probability of being the right thing to do.
The value for a possible world is:
The value of a distribution on possible worlds is:
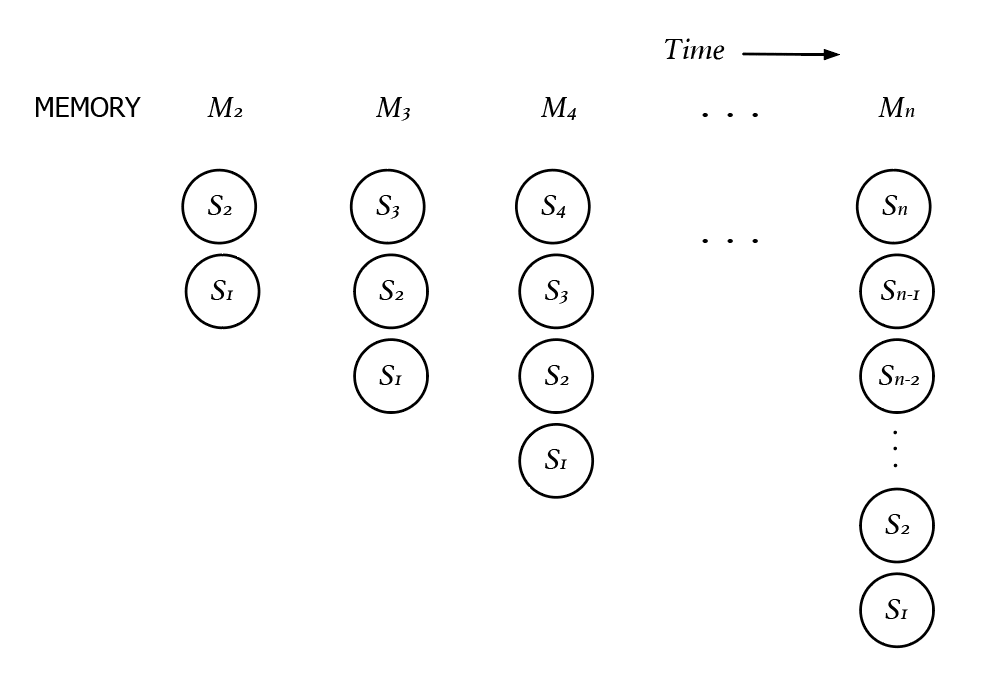
stands for "do the right thing". A possible world is an explicit description of the past, present, and sometimes the future of everything in a world that can be described as a finite or infinite bit string. To avoid dualism, both the intelligent agent and the environment are included in the possible world.
The value function of possible worlds can be estimated by Solomonoff induction [? · GW]. As we have shown in previous articles, if we have examples of right things to do, we can estimate any possible world's probability of being the right thing to do. For example, if the sequence "0101010101" represents an example of the right thing to do, we can estimate the probability that the sequence "0101010101010101010" represents the right thing to do, which is related to how likely they are to be outputs of the same computer program. There's no limit to the length of the two sequences, so that we can estimate the value even if the possible world is only partially known, for example, a possible world whose future is unknown.
According to this definition, the action with the highest values has the highest probability of being the right thing to do, and is most likely to be the right choice. It's similar to the traditional model, where an agent should take actions with the highest value (or utility) (Von Neumann & Morgenstern 2007). However, there are some important differences between these two models.
Value is a function of possible worlds
ACI argues that value is a function of possible worlds, not a function of states of the world like that in traditional models. In other words, even if the current state is the same, different histories can yield different values.
In traditional reinforcement learning approaches, value is a function of states of the world (under a policy ) (Sutton & Barto 2018). Furthermore, in economic models, people talk about the value of goods , suggesting that value is a function of objects (Reardon et. al. 2018).
Obviously, is a simplification of , because the same good can have different values in different situations. For example, ice has different values in winter and summer. Although we can still calculate using a time average or limit our scope to the summer time, different methods would inevitably yield different . That's one reason why we have so many conflicting value theories in economics.
ACI goes one step further and argues that is a simplification of . Value does not depend only on the current state. As in the non-Markov processes, what happened next does not depend only on the current state. The value of the world is not memoryless. History matters. In the language of statistics, there are dependencies between past states and present values.
For example, the law of diminishing marginal utility states that the utility of consuming a good depends on how much of the same good you have just consumed. Eating the third apple in one hour may give you less satisfaction than eating the first apple. The value of eating apples varies according to different histories.
Value is not a function of states of the world
One might argue that in a deterministic world, any information about the past that is stored in the agents' memories, which can be represented by the current state of the agent, or the current state of the world, so that a function of history is also a function of the current state. Diminishing marginal utility can be measured by the degree of hunger. In the language of the hidden Markov models, value can be determined by a Markov chain of memories.
But the more parameters a state contains, the less often each state will be seen, and the less reliable we can expect our value estimates to be . The value of states containing memories cannot be estimated by the Monte Carlo method, because an agent should never have the same memory twice without resetting its memory (déjà vu is an illusion), so the system would never enter the same state twice, and we can never estimate the value of such a state.
However, can be a useful approximation of . The value of a state can be considered as the value of a distribution on possible worlds that contain this state. In other words, is a weighted average of .
The Definition of reward
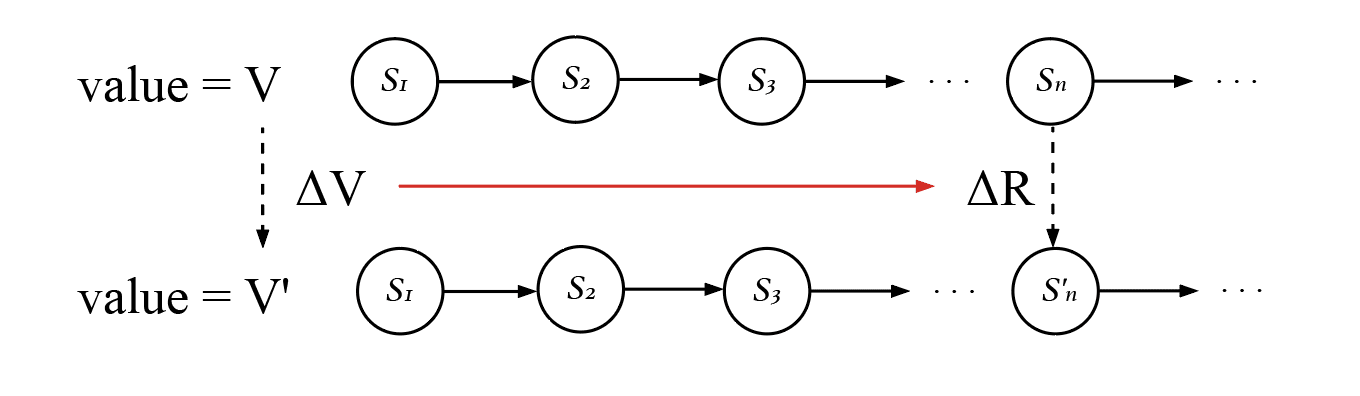
Now we can redefine reward from an ACI perspective. Since value should be some kind of accumulation of rewards, we can also derive reward from value.
We define the change of reward as:
The difference in reward between two states is the difference in the values of two possible worlds containing those two states, while everything else being the same.
For example, the difference in reward between getting an apple and not getting an apple, is the difference in value between two possible worlds, one in which you get an apple and one in which you don't, and everything else in the two worlds is the same.
We can see that the concept of reward in the traditional model is a simplification of our definition, because there are 3 differences between the two:
1. We define the change in reward, not the reward itself. By our definition, value may not be the sum of rewards; but we can maximize value only by knowing the change in the reward of each future state.
2. Reward is also a theoretical abstraction and cannot be measured in practice, because it's impossible to change only one state while all the others remain the same, or to change the past without changing the future. For example, if you already have an apple, it's impossible to lose the apple in one moment but still have the apple in the future.
3. Like values, rewards are also a function of possible worlds, not a function of states. Even if the state of the world is the same, different histories can yield different rewards.
Why the discount rate?
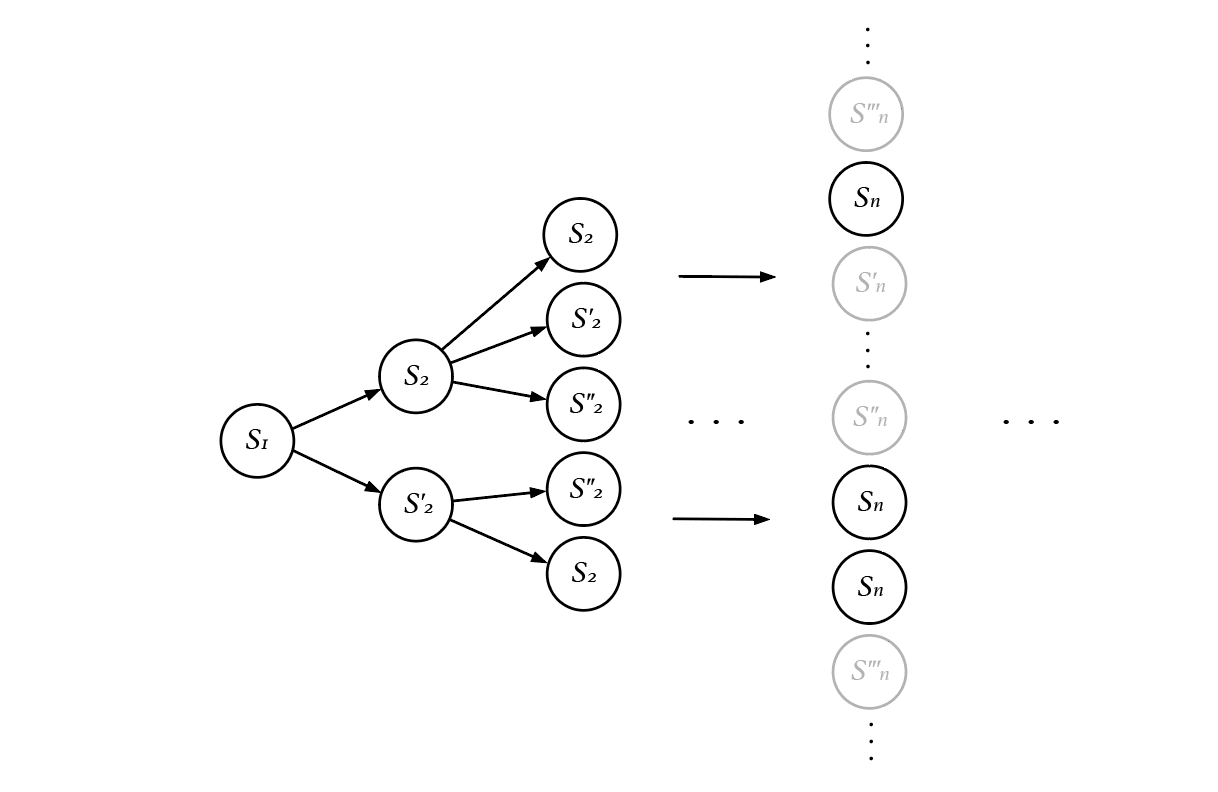
We have redefined value and reward. Moreover, we argue that our new definitions have more explanatory power than the traditional ones. Consider the concept of reward discounting. The discounted rewards approach argues that future rewards have less value to the present than present rewards, like time preference in economics, which argues that people prefer getting $10 now more than getting $10 a month later. A discount rate close to 0 makes an agent more "myopic," while a discount rate close to 1 makes an agent more likely to consider the future. Value is not simply the sum of rewards, but the sum of discounted rewards.
The discounted reward is introduced first for a mathematical reason: without discounting, the sum of future rewards would approach infinity. It can also indicate how much one cares about the future, but is there a way to calculate it? Moreover, the hyperbolic discounting model in economics raises another question, does discounting really follow an exponential form?
From ACI's perspective, future rewards are discounted in a slightly different way. It's not that future rewards have less value, but we have less certainty about the value of future rewards. In other words, an agent's preference can change in both directions. We observe that future rewards are less valuable because we focus most of the time on positive rewards, especially the high peaks of positive rewards, such as getting money, where uncertainty means less value. On the other hand, situations that yielded few rewards in the past may be more valuable in the future. For example, the value of helium in natural gas is highly uncertain in the distant future, because it depends on the development of nuclear fusion energy technology.
We are less certain about the value of future rewards because value is a function of possible worlds, not a function of states of the world. A future state cannot determine its value alone, because there are many possible ways to get to state , in other words, there are many possible worlds containing the state . A state in the far future can be approached from more possible ways, so we have more uncertainty about its value.
References
Demski, A., & Garrabrant, S. (2019). Embedded agency. arXiv preprint arXiv:1902.09469.
Reardon, J., Cato, M. S., & Madi, M. A. C. (2018). Introducing a new economics. University of Chicago Press Economics Books
Niv, Y., Duff, M. O., & Dayan, P. (2005). Dopamine, uncertainty and TD learning. Behavioral and brain Functions, 1, 1-9.
Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.
Von Neumann, J., & Morgenstern, O. (2007). Theory of games and economic behavior: 60th anniversary commemorative edition. In Theory of games and economic behavior. Princeton university press.
2 comments
Comments sorted by top scores.
comment by cubefox · 2024-06-04T15:57:40.289Z · LW(p) · GW(p)
Could you add an explanation of what "ACI" means in the beginning? I was a bit thrown off by this.
Regarding your proposal, maybe you want to compare it to Richard Jeffrey's utility theory. He assumes that value/utility ("desirability", degree of desire) is a function of a Boolean algebra of propositions, and propositions can be interpreted as sets of possible worlds in which they are true. So it seems quite similar to your approach. Actions can also be interpreted as propositions of the form of "I do X now" which the agent can make true.
Replies from: Akira Pyinya, Akira Pyinya↑ comment by Akira Pyinya · 2024-06-04T21:50:04.390Z · LW(p) · GW(p)
Thank you for your introduction of Richard Jeffery's theory! I just read some article about his system and I think it's great. I think his utility theory built upon proposition is just what I want to describe. However, his theory still starts from given preferences without showing how we can get these preferences (although these preferences should satisfy certain conditions), and my article argues that these preferences cannot be estimated using the Monte Carlo method.
Actually, ACI is an approach that can assign utility (preferences) to every proposition, by estimate its probability of "being the same as example of right things". In other words, as long as we have examples of doing the right things, we can estimate the utility of any proposition using algorithmic information theory. And that's actually how organisms learn from evolutionary history.
I temporarily call this approach Algorithmic Common Intelligence (ACI) because its mechanism is similar to the common law system. I am still refining this system from reading more other theories and writing programs based on it, that's why I think my old articles about ACI may contain many errors.
Again, thank you for your comment! Hope you can give me more advices.