Sure, transformers can get silver at the IMO. But before we address those two remaining problems that still stand between AlphaProof and gold, let's go a few steps back and see how transformers are doing at supposedly low-level math competitions. In particular, we will consider a problem aimed at grades 3 and 4, from the largest international math exam competition around (the Mathematical Kangaroo).
The problem is designed to test children's spatial thinking skills and rightfully held up as a good example in an interview with the competition's president Meike Akveld, a knot theorist at ETH. This article is where I came across the idea as well.
It goes like this:
In the following image, you can see an open picture book. There are holes in its cover. On the first page, there are pictures of objects. Which pictures are visible when the book is closed?
To remove some ambiguity, we also give the list of objects to choose from, so in this case "Ginger", "Kiwi", "Pineapple", "Pear", "Watermelon". OK then, GPT-4o, what do you think?
To determine which pictures will be visible when the book is closed, we need to align the holes on the cover with the pictures on the first page.
From the image:
1. The holes in the cover are located in the second and third columns from the left. 2. The pictures of objects on the first page — from left to right — are: pineapple, watermelon, ginger, kiwi, pear.
Thus, when the book is closed: - The second column will show the first image: pineapple. - The third column will show the second image: watermelon.
ANSWER: pineapple, watermelon
Hm, that's wrong! The answer is {"Pineapple", "Ginger", "Pear"}. Then again, there are some good ideas in the completion, namely the basic setup of the problem being correctly summarized and the pictures identified. Now, it is not so surprising that vision transformers are bad at grids, so let us grant the error about the hole locations. But the model also doesn't understand the symmetry; that a hole further to the left reveals objects further to the right, which is what the task wants to test in children.
Investigating whether this failure mode repeats across different images and iterations (seemingly it does), I made a generator for these problems and sampled 50 of them, resulting in an accuracy of 0.12 for GPT-4o with Chain of Thought, where a random baseline gives 0.04. [The code is available here] and you are cordially invited to play around with it. It should be easy to rescore since it's using AISI's new Inspect eval framework, which I can tentatively recommend over the alternatives. I wonder how other models do on this(, like Claude 3.5, which I had some trouble getting access to).
This really should not be a fundamentally hard problem, and I expect an extensively fine-tuned GPT-4o to do significantly better (>0.6).[1] It remains puzzling to me though how far current models seem to be from a consistently good 0-shot performance while performing so well in other areas, echoing the ARC benchmark but perhaps less controversial in regards to whether humans are good at it. Just from the general speed of progress, I also expect this being solved (>0.95) by a general-purpose multimodal model soon. Only, before or after IMO?
Q:Which numbers are above a yellow region in the image?
GPT4o: [2,4]
GPT4: [4,5]
Claude 3.5 Sonnet: [2,5]
Claude sonnet describes the image as follows:
User: List the numbers in the above image, how are they placed in the image? What's below them?
The numbers shown in the image are:
1, 2, 3, 4, 5
These numbers are placed in a single horizontal row, appearing to be in separate cells or boxes arranged from left to right in ascending numerical order. Each number occupies its own cell, creating a simple table-like structure with 5 columns.
Below the numbers, there are cells or boxes that correspond to each number. Some of these cells are colored, while others are not. Specifically:
Below number 1: The cell is white or uncolored.
Below number 2: The cell is colored yellow.
Below number 3: The cell is white or uncolored.
Below number 4: The cell is white or uncolored.
Below number 5: The cell is colored yellow.
So, out of the 5 cells below the numbers, two are colored yellow (under 2 and 5), while the rest are white or uncolored.
So these models have very very bad visuospatial abilities.
This seems like a problem that's will be easy to solve with some synthetic training data.
Agreed, although that it turn makes me wonder why it does perform a bit better than random. Maybe there is some nondeclarative knowledge about the image, or some blurred position information? I might test next how much vision is bottlenecking here by providing a text representation of the grid, as in Ryan Greenblatt's work on ARC-AGI.
If we consider each (include,exclude) decision for (1,2,3,4,5) as a separate question, error rates are 20%-ish. Much better than random guessing. So why does it make mistakes?
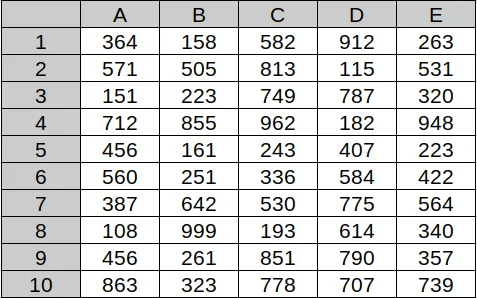
If bottlenecking on data is the problem, more data in the image should kill performance. So how about a grid of 3 digit numbers (random vals in range 100...999)?
3.5 sonnet does perfectly. Perfect score answering lookup(row/col) and (find_row_col(number), find duplicates and transcription to CSV.
So this isn't a bottleneck like human working memory. Maybe we need to use a higher resolution image so it has more tokens to "think" with? That doesn't seem to work either for the above yellow areas thing either though.
I'm guessing this is straightforward failure to generalize. Tables of numbers are well represented in the training data (possibly synthetic data too), visual geometry puzzles, not so much. The model has learned a few visual algorithms but hasn't been forced to generalise yet.
Root cause might be some stupid performance thing that screws up image perception the same way BPE text encoding messes up byte level text perception. I'm guessing sparse attention.
Text representations
Text representations are no panacea. Often similar problems (EG:rotate this grid) have very formatting dependent performance. Looking for sub-tasks that are probably more common in training data and composing with those (EG:rotate by composing transpose and mirror operations) allows a model to do tasks it otherwise couldn't. Text has generalisation issues just like with images.
I would expect that they fare much better with a text representation. I'm not too familiar with how multimodality works exactly, but kind of assume that "vision" works very differently from our intuitive understanding of it. When we are asked such a question, we look at the image and start scanning it with the problem in mind. Whereas transformers seem like they just have some rather vague "conceptual summary" of the image available, with many details, but maybe not all for any possible question, and then have to work with that very limited representation.
Maybe somebody more knowledgeable can comment on how accurate that is. And whether we can expect scaling to eventually just basically solve this problem, or some different mitigation will be needed.
O1 now passes the simpler "over yellow" test from the above. Still fails the picture book example though.
For a complex mechanical drawing, O1 was able to work out easier dimensions but anything more complicated tends to fail. Perhaps the full O3 will do better given ARC-AGI benchmark performance.
Meanwhile, Claude 3.5 and 4o fail a bit more badly failing to correctly identify axial and diameter dimensions.
Visuospatial performance is improving albeit slowly.