The big news this week was Apple Intelligence being integrated deeply into all their products. Beyond that, we had a modestly better than expected debate over the new version of SB 1047, and the usual tons of stuff in the background. I got to pay down some writing debt.
The bad news is, oh no, I have been called for Jury Duty. The first day or two I can catch up on podcasts or pure reading, but after that it will start to hurt. Wish me luck.
Table of Contents
AiPhone covers the announcement of Apple Intelligence. Apple’s products are getting device-wide integration of their own AI in a way they say preserves privacy, with access to ChatGPT via explicit approval for the heaviest requests. A late update: OpenAI is providing this service for free as per Bloomberg.
Colin Fraser is skeptical of this finding. He points out 8/15 is case study territory, not a call for 53%. GPT-4 did not know about these zero day exploits due to knowledge cutoff, but it was pointed in the right direction by people who knew the answer, and a few other issues.
The obvious next step is to do this with actual zero-day exploits.
As in, take GPT-4, point it at random websites without known available exploits, and use a similar process. See how long it takes GPT-4 (or some other future model) to find a genuinely new exploit. Then alert the proper authorities, get the hole patched, and issue the paper.
I presume that would be a lot more convincing.
Language Models Don’t Offer Mundane Utility
As usual, the most common reason is that you don’t know how to use it.
Austen Allred: Today I jumped from one call where someone told me AI sucks at writing code to another where I watched someone walk through a multi-agentic system they built that automatically completed 28.9% of the work they were assigned for the quarter.
Yishan: This calls to mind that one post where two people disagree about the risk of something – Person A says it’s a low risk, and Person B says it’s way too high a risk. Later we find out that both people agree that the risk of the thing happening is 20%.
Zack: It’s written 70-80% of my React web app. $60K of value for 20$ a month.
James Blackwell: I hardly wrote code anymore. Sure you still kinda need to program, but with Cursor, it’s just quicker to ask in shorthand what you want and let the AI output typo free code
Which 28.9%? Or even which 70%? How much must be checked and maintained? Are you going to regret it later? Do these people’s job tasks differ? Notice ‘assigned for the quarter,’ which indicates a certain kind of role.
Among other things, they banned internal criticism. Remind you of anyone?
Ron Amadeo (Ars Technica): The two founders apparently “preferred positivity over criticism, leading them to disregard warnings about the AI Pin’s poor battery life and power consumption. A senior software engineer was dismissed after raising questions about the product, they said, while others left out of frustration.
…
After apparently not being interested in honest employee feedback during development, once the product launched, Bongiorno called the team together and said the company would have to “lean into painful feedback” and called the reviews “a gift that we’ve been given.”
…
Maybe part of the issue is that the company didn’t have a head of marketing until after launch, despite employees “repeatedly asking” for the role to be filled.
It seems unlikely you get a disaster this big without an unwillingness to listen to criticism. Not having a head of marketing presumably also helped.
What else? Nick Pinkston thinks VCs as they often do overindexed on founder pedigree, giving two former Apple employees Too Much Money, citing this article. That certainly sounds like the type of mistakes VCs would make, but it presumably has little to do with this particular disaster.
I keep asking, what happened to Alexa? Why does it suck so badly despite such huge investments, when it seems obviously trivial to get a far better solution for far less even if it is crafted with if-then statements in spaghetti code? This seems timely now that Siri is mostly powered by a 3B LLM.
Ethan Mollick: Amazon has spent between $20B & $43B on Alexa & has/had 10,000 people working on it.
It is all obsolete. To the extent that it is completely exceeded by the new Siri powered mostly by a tiny 3B LLM running on a phone.
What happened? This thread suggests organizational issues.
Mihail Eric: How Alexa dropped the ball on being the top conversational system on the planet.
…
We had all the resources, talent, and momentum to become the unequivocal market leader in conversational AI. But most of that tech never saw the light of day and never received any noteworthy press.
Why?
The reality is Alexa AI was riddled with technical and bureaucratic problems.
Bad Technical Process
Alexa put a huge emphasis on protecting customer data with guardrails in place to prevent leakage and access. Definitely a crucial practice, but one consequence was that the internal infrastructure for developers was agonizingly painful to work with.
It would take weeks to get access to any internal data for analysis or experiments. Data was poorly annotated. Documentation was either nonexistent or stale.
Experiments had to be run in resource-limited compute environments. Imagine trying to train a transformer model when all you can get a hold of is CPUs.
…
And most importantly, there was no immediate story for the team’s PM to make a promotion case through fixing this issue other than “it’s scientifically the right thing to do and could lead to better models for some other team.” No incentive meant no action taken.
…
Alexa’s org structure was decentralized by design meaning there were multiple small teams working on sometimes identical problems across geographic locales. This introduced an almost Darwinian flavor to org dynamics where teams scrambled to get their work done to avoid getting reorged and subsumed into a competing team.
…
Alexa was viciously customer-focused which I believe is admirable and a principle every company should practice. Within Alexa, this meant that every engineering and science effort had to be aligned to some downstream product.
That did introduce tension for our team because we were supposed to be taking experimental bets for the platform’s future. These bets couldn’t be baked into product without hacks or shortcuts in the typical quarter as was the expectation.
…
If you’re thinking about the future of multimodal conversational systems and interfaces, I would love to hear from you. We’ve got work to do!
That all seems terrible. It still does not seem like a full explanation, which is a way of saying exactly how awful is the product.
Aston Kutcher: You’ll be able to render a whole movie. You’ll just come up with an idea for a movie, then it will write the script, then you’ll input the script into the video generator and it will generate the movie. Instead of watching some movie that somebody else came up with, I can just generate and then watch my own movie.
What’s going to happen is there is going to be more content than there are eyeballs on the planet to consume it. So any one piece of content is only going to be as valuable as you can get people to consume it. And so, thus the catalyzing ‘water cooler’ version of something being good, the bar is going to have to go way up, because why are you going to watch my movie when you could just watch your own movie?
Colin Fraser: Trying to make Dude Where’s My Car with Sora but it keeps putting the car right in the center of the frame.
“Ashton Kutcher looking for his car BUT HE CANT FIND IT BECAUSE IT IS NOT THERE!! Important: THE CAR IS NOT IN THE FRAME.”
Problems like that will be solved. Aston also talks about, why spend all the time and money on various stunts and establishment shots, you can get those from an AI much cheaper. Right now, you can’t, not properly, but in a few years yes. Then everything else.
My model is the bar does not go way up for a while. If you flood the zone with slop, then that is a problem for lousy content, but the case for the great content has not much changed. Also I actively want to see the same movie others are seeing to share the experience. Indeed, I can see rewards to quality going up, as people seek out the best and have better ways of finding it. And reducing the cost of producing the best means the best will get better.
And yes, I very much predict I will still want to do traditional movies and other passive fixed experiences a good portion of the time, and others will as well. There will increasingly also be interactive and customized experiences that offer more choice, but I remind everyone that often choices are bad. Sometimes you feel like a choice, sometimes you don’t.
It is remarkable how angry people get about where people get generative AI training. Here is Sasha Yanshin canceling his Adobe license in a rage because they reserve the right to use his data for the purposes of operating or improving the services and software. Everyone speculates this is for an AI project, and Elon Musk replies ‘!’. When Adobe points out ‘actually this has been standard language for a decade and there is zero functional change’ and shows exactly what words change, Sasha tells them how many f***s he gives.
A group of hackers that says it believes “AI-generated artwork is detrimental to the creative industry and should be discouraged” is hacking people who are trying to use a popular interface for the AI image generation software Stable Diffusion with a malicious extension for the image generator interface shared on Github.
…
“Maybe check us out, and maybe think twice about releasing ai tools on such a weakly secured account,” the same archived Github page says.
A commetor notes that these notices appear to be false flags. Since it isn’t load bearing I’m not going to sweat it.
Deepfaketown and Botpocalypse Soon
Person in Australia files 20,716 noise complaints in 2023. What happens when AI lets everyone do this and AI lawyers are free? This is a case of The Big Rule Adjustment, where we have to fix rules that no longer work with the marginal costs of various activities removed.
In 2 years all communications will be through an AI assistant (calls, email, message etc.). Eventually people will start to hate talking to AI. Someone will launch a “verified human” badge and people will reply to emails/text/etc from them at 100x a higher rate.
Interestingly enough, most early tests of AI vs human, the average person prefers AI. BUT this number goes down by a large margin once they know it’s AI.
Most people don’t like talking to AI, if they know it’s AI.
Valieram: Verifying humanity is an extremely hard problem to solve. Even if you have a great way to prove your identity to the sender, you could share it privately with a local software that pretends to be you and the receiver wouldn’t know about it. So these badges could be meaningless.
Sully: Yea it’s insanely hard lol
The obvious solution (I think I’ve mentioned this before?) is to introduce a new marginal cost to such activities. Even a small refundable or contingent fee changes the incentives dramatically.
For spam activities it can be tiny, a penny a message already transforms the economics. For other purposes, it needs to be somewhat higher.
The MVP version is that everyone buys (obviously transferrable) credits, and communications have a credit amount attached. Each person can set a minimum below which communications get filtered out entirely, and the target can see the credit bid when determining whether to open the message. Once they open the message, they can choose to keep the credits, do nothing or tip the person back depending on whether they found the interaction helpful.
As for AI, I could ask if you (and your own AI) can’t tell it’s AI, what’s the problem?
Actual detection or verification is insanely hard. Certainly you can’t prove someone didn’t test drive the answer out with an AI or ask about edits.
I still see this as a kind of costly signal, even if unverified. You are putting your reputation on the line and saying, this is me, I wrote or said this, for real. You would want to not abuse that, because reputations could be tracked, and if you claim it all the time it loses meaning.
This all assumes, of course, that we remain in a world where you want to be hearing from the human and not their AI.
From a month ago (got put in the wrong folder): Facebook scams empowered by AI slop continue to spread, because for now those without situational awareness keep boosting it. Opossum calls these ‘grandma traps,’ you start with heartwarming content appealing to the elderly, then later you go for the scam. If you slip and start engaging with such content, it might never stop, so be very careful never to do this on your real account. As Shoshana points out, the scams often only come in later, and without section 230 the platforms would be even more screwed.
Agreed that so far people claiming real things are fake has been a far bigger problem than people thinking fake things are real. But I notice that we already had this ‘claim it is fake’ technology.
Austen Allred: My favorite exchange of the week [shows image of below].
Paul Graham: If AI allows companies to be smaller, that will be a qualitative change. Lots of things break once organizations get big. We take it for granted, even in the startup world. But imagine if that stopped happening.
Mateohh: Imagine all the people looking for jobs.
Paul Graham: Just have more companies.
Austen Allred: If the biggest tech companies in the world today have 100,000 brilliant people, Imagine how much better off we’d all be if instead we had 1,000 new companies of 100 brilliant people.
In this case, the plan breaks down quicker.
Being a founder requires a particular set of skills. To have 1,000 new companies of 100 brilliant people, that means (if you consider failures and early stages) 3% or more of them have to become founders.
He confirms that the limiting factor is rapidly becoming power, and he echoes Leopold’s perspective that this ‘race to AI’ is important to national security without mentioning existential risk.
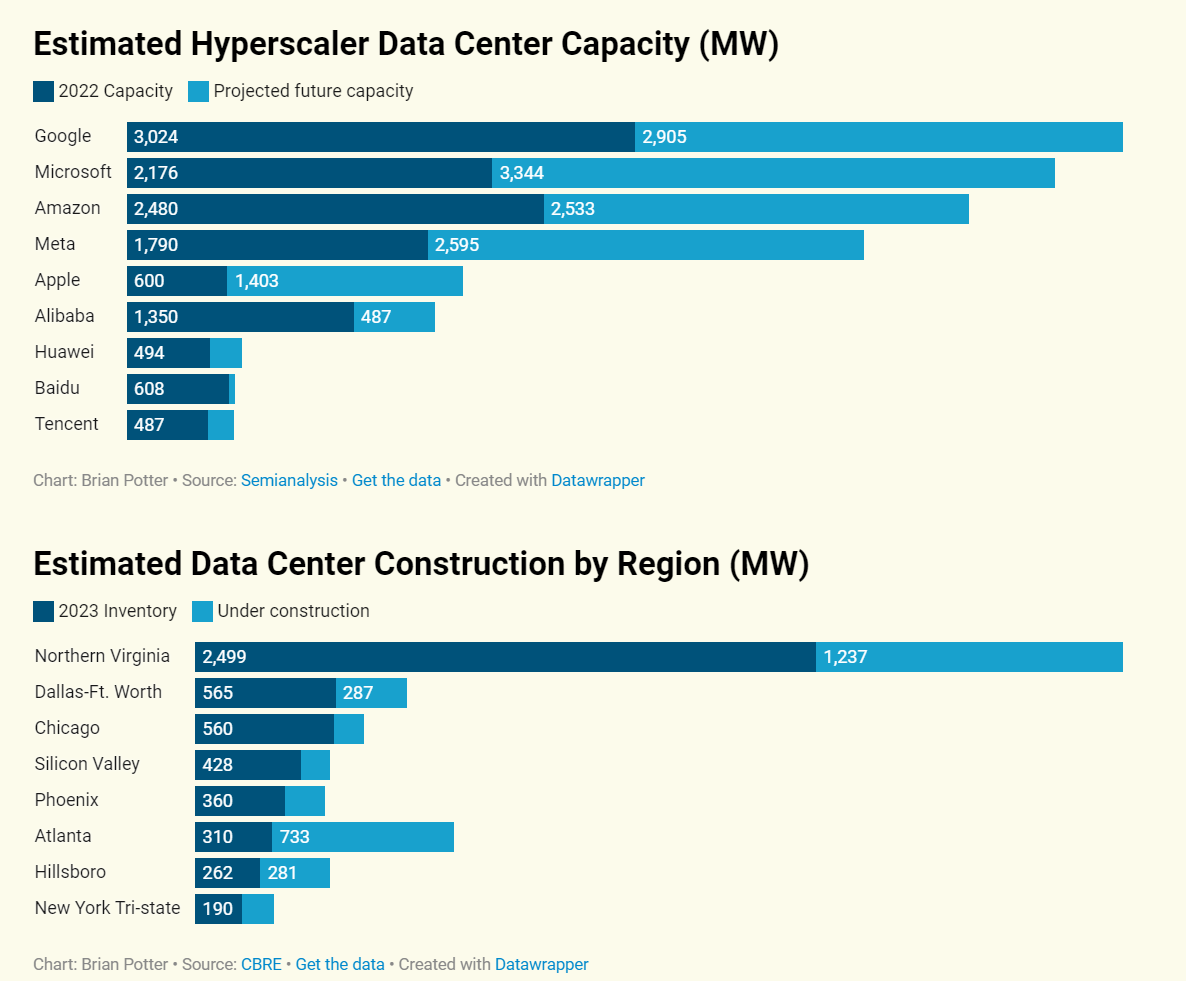
Brian Potter: But even as demand for capacity skyrockets, building more data centers is likely to become increasingly difficult. In particular, operating a data center requires large amounts of electricity, and available power is fast becoming the binding constraint on data center construction.
…
Today, large data centers can require 100 megawatts (100 million watts) of power or more.
Efficiency gains on power consumption from better center designs are mostly done, sine the power usage effectiveness at Meta’s and Google’s average data center are 1.09 and 1.1, meaning only 10% of energy spent on non-compute, and AC to DC conversion is over 95%. That still leaves gains in the computers themselves.
Mostly he goes over what we already know. AI takes a lot of power, you will want dedicated data centers. He is still sleeping on all this, only anticipating that data center demand triples by 2030 to 4.5% of global energy demand.
Davidad: An intriguing explanation of why the Bitter Lesson’s commonly presumed implication “anything that involves crafting an intelligible world-model will never win” is contingent (on “we don’t have any other way to make intelligible world-models except for humans to code them up”):
Daviad (June 1, 2022): A common misconception of Sutton’s “Bitter Lesson” is “yay neural networks; unfortunately, boo symbolic representations.” That’s not what it says! It’s more like “yay search and learning, boo hard-coded heuristics and domain logic.” See for yourself
Daniel Eth (quoting Davidad now): Weirdly, AGI might *reverse* this effect. The case for search/learning is they’re more scalable w/ compute, vs GOFAI-type stuff instead scales w/ labor. Given tons of fast-growing compute (and ~fixed labor), search/learning wins. But AGI would give us tons of fast-growing labor!
The Art of the Jailbreak
Is there hope against it?
Andy Zou, Dan Hendrycks and co-authors have an idea called ‘short circuiting,’ to divert the model away from representations that lead to harmful outputs. Here is the pitch, and… oh no?
It sure sounds uncomfortably much like the Most Forbidden Technique You Must Never Use, which is to use interpretability to figure out when the model is doing bad things and then use gradient descent until it stops having bad behaviors you can interpret. Which could directly teach the model to subvert your ability to detect bad behaviors. That is a very good method for getting highly blindsided at exactly the wrong time in the worst possible way.
(Also the market does not think it would work.)
Andy Zou: No LLM is secure! A year ago, we unveiled the first of many automated jailbreak capable of cracking all major LLMs.
But there is hope?!
We introduce Short Circuiting: the first alignment technique that is adversarially robust.
Our technique inserts ‘short circuits’ into neural networks, supervising harmful representations rather than merely harmful outputs, offering much more robustness than techniques like RLHF. (addresses problem 1)
The model functions normally under regular inputs and activates ‘short circuits’ during harmful thought processes, preserving its capabilities. (addresses problem 2)
Our method isn’t trained against specific attacks, allowing it to naturally generalize to any unseen adversaries. (addresses problem 3)
…
Is it costly to train or deploy?
No! Unlike adversarial training which takes days, short circuits can be inserted in under 20 minutes on a GPU. Unlike input/output filters, short circuited models are deployed as normal models with no additional inference cost.
There are interesting ways to follow-up on this, some of which are more clearly not the Most Forbidden Technique. I worry that even ‘they cost slightly more at runtime’ would be enough to tempt people to not use them.
OpenAI adds Sarah Friar as Chief Financial Officer and Kevin Weil as Chief Product Officer. Both have strong track records of trying to turn technology companies into money, and no obvious relation to AI or safety concerns.
Sarah Friar: I’m delighted to join OpenAI! Excited to contribute to AI’s transformative power for humanity. As co-chair at DigEconLab and a Walmart and Consensys Board member, I’m seeing AI’s profound impact already.
Purpose matters, as I saw Nextdoor and Square. This world-class research organization is building AGI to benefit all of humanity – purposes don’t get any bigger than that.
Kevin Weil: I’m super excited to announce that I’m joining OpenAI as Chief Product Officer!
My entire career has been about working on big missions: connecting people and ideas at Instagram and Twitter, digitizing financial services at Libra/Novi, or most recently at Planet, using space to advance global security, sustainability, and transparency.
OpenAI’s mission to build AGI to benefit all of humanity is perhaps the most important and transformative of them all.
Sam Altman: really looking forward to working with kevin and sarah!
I do at least like that this is Kevin’s profile picture:
Luma AI has a video model, open to the public. Image quality does seem very high. Clip duration however seems very low. The images are a few seconds at a time, then they cut to another scene. They also don’t navigate any tricky physics issues.
Paperclaims dramatic reduction in required compute and power by constraining things quite a lot, that you can fully eliminate MatMul in LLMs, and performance gaps narrow as model sizes increase. As in 13 watts for over a billion parameters. Post got 500k+ views, but I don’t see comments either way from the people I trust to evaluate such claims and tell how much is there, so reserving judgment.
Tim Clicks: If this is accurate, then NVIDIA’s grip on the tech industry has just vanished.
Matrix matrix multiplication (MatMul) is notoriously computationally difficult, which is why it’s offloaded to GPUs.
If MatMul can be avoided, then it’s not just leveling the playing field. It’s creating new playing fields.
So let’s go to the big board after the recent 10:1 stock split:
The EMH is false. Can you evaluate MatMul’s expected future impact on Nvidia better than the market? Obviously, the market is not so good at such things and clearly lacks situational awareness. I still do think that the lack of marginal impact is telling. Then again, what were you going to do about it? If you are sufficiently situationally aware to know MatMul threatens Nvidia, then you presumably already had a strong opinion on Nvidia. So you’re not exactly thrilled to sell.
Valuation seems non-crazy. It seems like a better bet than xAI given the prices (not investment advice) unless Musk plans to steal a lot of value from Tesla. This is a worse deal than Anthropic and also far less ethical but Anthropic seems clearly cheap and who says you have access. OpenAI’s valuation would otherwise be crazy low but is warped by its structure.
Daniel Eth: Hot take but Mira really isn’t saying much of anything in this video – she’s mostly just reiterating OpenAI’s general policy re iterated deployment. Some people seem to be reading way too much into this video, taking it as a sign that LLMs are hitting a wall.
There was a period, ending early last year, when OpenAI last had a substantially superior model (GPT-4) to what they had released to the public. That will happen again, briefly, before GPT-5. My hope is that it will be a reasonably long period of fine tuning and red teaming and other safety checks. If we don’t get a long break, that is a very bad sign for future releases, on top of tail risk worries on this next one. Remember there are people working at OpenAI who think GPT-5 might be AGI.
Access to powerful AI might make computer security radically easier [LW · GW]. It also might make computer security an oxymoron if we are not careful. Temptations abound. What Buck is talking about at the link is computer security against humans. If you want to monitor people, not have to trust people to do a task, not give people broad permissions or automatically investigate various things, all of that sounds like a sufficiently trustworthy and powerful AI might be able to help.
Well, sure. If you have one of those. Buck notes you have to solve jailbreaking first, or turning sensitive tasks over to your powerful AI would be a horribly bad idea. He is optimistic that you can do this even if your solution would horrify anyone with a true security mindset, via attackers having limited attempts and using defense in depth.
I am not loving that part of this, and this assumes that jailbreaks triggered by a hostile user are the only threat model to deal with. If you go down the path of putting AIs in charge of your security and sensitive systems, and it turns out the threat is coming from the AIs, then whoops.
IAPS reportasks what Chinese could do with commercial GPUs to get around export controls. Answer is that with a concerted effort it could be a substantial percentage of domestic production. It would still be rough for training frontier models and highly inconvenient, and also presumes that such chips keep pace, and also if they made this concerted effort it would presumably be hard to miss. But dual use is definitely a thing.
Colin Fraser: I think LLM agents are doomed due to correlated errors. What you want with systems of agents is independent idiosyncratic errors that cancel each other out in aggregate but if every agent is just ChatGPT wearing a hat then you get errors that compound and multiply.
I think they’re doomed for other reasons too.
There are advantages to predictable errors. If you know which tasks and queries the AI agent can do reliably, and which ones it probably messes up, then you can have it do the tasks where it is good, and not the tasks where it is not good. It could hand them off to a human. It could call a dedicated tool or use special logic. It could find clever ways to route around them.
But yes, if LLMs continue to have highly correlated areas of unreliability, then you cannot hand off the problem tasks to a different LLM. You can definitely get some mileage out of specialized models and custom instructions and so on, and from tools and manual fixes. And of course, an agent that is not universal can still be highly useful, even if there are tasks it cannot do.
Over a longer time horizon, I expect the weaknesses to remain somewhat correlated, but the general capabilities level to rise sufficiently that it works out fine.
I Spy With My AI
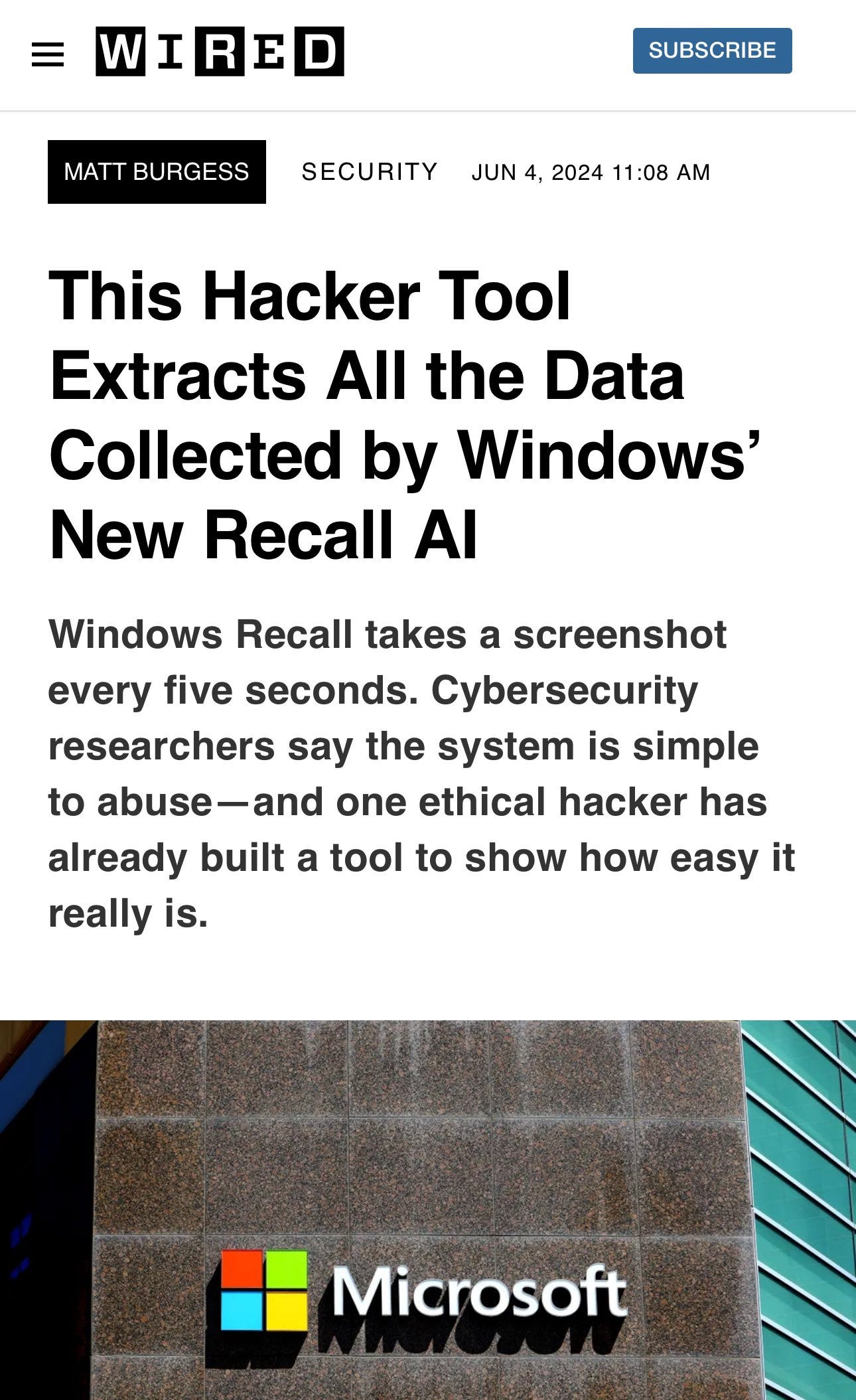
Previously I covered Microsoft Recall, the ‘store all your screenshots for AI to use or anyone to steal or subpoena’ innovation that’s coming to Windows.
Bilawal Sidhu: Turns out Microsoft’s AI Recall feature is not very secure. “The database is unencrypted. It’s all plain text.”
So homie built a tool to extract it all and called it ‘Total Recall’
Gary Marcus: CA Sen Scott Wiener: We want to hold you responsible if you fuck up really badly.
Silicon Valley: No!!! That will totally stifle innovation, and anyway we are, like, totally responsible. Trust us!
Microsoft: We are going to store screenshots of everything you ever did. And we’ll index it all in a plaintext database that hackers can crack in 5 minutes.
Then there are the crypto folks such as Arthur B who will tell you things like ‘The way for products like Microsoft recall to be used safely is for the data to be encrypted with a 2:2 scheme, with one key held by the user, and the second key held by a third party.’ Then I metaphorically look at them like they think we definitely won’t give the AI access to the internet.
He notes that the changes, requiring OS-level user authentication to access the data and making the feature opt-in, were pretty much forced upon them. But this means third-party apps cannot use the data (good.jpg), and it means users can’t get a ‘surprise-and-delight moment’ when the computer finds what they want.
You say surprise and delight. I say surprise and abject horror. You do not want that moment to be a surprise because you never asked permission. Oh my.
This was in the context of weapons rather than AI. Still, good news, also telephone.
Lying to the White House, Senate and House of Lords
Does anyone even care? Credit where credit is due: Martin Casado provides clarity on the statement made to the US Senate in December 2023 and walks it back.
Malo Bourgon: To US Senate, Dec 2023: “While proponents of AI safety guidelines often point to the “blackbox” nature of AI models – i.e. that the reasoning behind their conclusions are not “explainable” – recent advances by the AI industry have now solved this problem.”
To UK House of Lords, Dec 2023: “Although advocates for AI safety guidelines often allude to the “black box” nature of AI models, where the logic behind their conclusions is not transparent, recent advancements in the AI sector have resolved this issue.”
Martin Casado: If I did say that, I misspoke. I don’t believe that.
I do believe you can build functional systems out of LLMs just like we can with distributed and other non predictable or stochastic systems. But that’s quite a different statement.
It is a written statement. So this is more of a ‘mistyped’ situation. And that ‘mistyping’ happened in front of the US Senate. A very similar mistyping took place (by a16z but without particular attribution here) at the House of Lords. And in a letter to the White House.
In any case, thank you to Martin Casado for walking it back.
Who else signed those statements?
Neel Nanda: WTF?! This is massively against the scientific consensus.
Garrison Lovely: So I remember a16z relaying this howler to the UK House of Lords, but I did not realize that Yann LeCun, John Carmack, and other technical folks signed their name to the same claim in a letter to Biden!
I really don’t know how you could possibly take them seriously after this.
Statement Quote: Although advocates for Al safety guidelines often allude to the “black box” nature of Al models, where the logic behind their conclusions is not transparent, recent advancements in the Al sector have resolved this issue, thereby ensuring the integrity of open-source code models.
John Carmack: I didn’t get to proofread the statement — they got my company affiliation wrong… “Resolved” is clearly incorrect, but I don’t care much about that issue.
Here is the list of who signed it:
Marc Andreessen, a16z
Ben Horowitz, a16z
Yann LeCun, NYU & Meta
Ben Fielding, Gensyn
lon Stoica, UC Berkeley, Databricks, Anyscale
Naveen Rao, Databricks
Arthur Mensch, Mistral
Garry Tan, Y Combinator
Amjad Masad, Replit
Bill Gurley, Benchmark
Herman Narula, Improbable
Tobi Lütke, Shopify
Suhail Doshi, Playground
Clem Delangue, Hugging Face
Aravind Srinivasan, Perplexity
Soumith Chintala, Meta
Tyler Cowen, George Mason University
John Carmack, Armadillo Aerospace
As noted above Martin Casado has now walked this back. I now issue the challenge to the 18 people whose signatures are on this letter: Do you also walk this back? And did the other 17 of you, like John Carmack, agree to put your name on a statement you did not read?
In my culture, if you are signing a letter addressed to the White House, or Congress, or the House of Lords, you read it. If you see an importantly false statement in the letter, you do not sign it. If you do sign it, you bring great shame upon your house.
The vast majority of these people definitely knew that this claim was both important and false at the time that the letter was issued. They either did not read the letter, did not notice this statement, or did not care. They have not, to my knowledge, walked the statement back, aside from Casado. Update accordingly.
That does not mean any of that is salient or important to them. Not yet. Indeed, it is fair to say that the discussion of AI in Washington mostly does not care what anyone thinks.
Ian Krietzberg: The AIPI’s executive director, Daniel Colson, told me that the conversation in Washington right now is torn between protecting national security and ensuring America remains competitive in the sector.
This, he said, is why certain legislation (like the ENFORCE Act) is popular: it aligns national security interests with American competitiveness in AI.
The good news is that a lot of what is ‘good for national security’ in AI is good for the world and good for existential risk. As Leopold says, we should absolutely be locking down the major labs for this reason.
All the talk about ‘ensuring America remains competitive’ combines the inability of government to do anything to meaningfully help (beyond not getting in the way) versus a panic that would embarrass those who used to talk about the ‘missile gap.’
That obsession with ‘competitiveness’ is a serious problem when attempting to actively do things to ensure we do not all die, a topic that from all reports I hear is not currently of much interest to many on the Hill. The executive order is still there, and the Schumer report contained remarkably good policies if you paid attention. But for now, we likely need to wait for something new to wake up such concerns. I expect the 5-level models to provide that.
Clement DeLangue: The US is going to lose its leadership in AI if it doesn’t support more open research and open-source AI!
Daniel Eth: This feels like a fun game, let me try – The US is going to lose its leadership in AI if it doesn’t support blanket tax credits for 30-somethings living in Southern California
The claim that if we don’t support giving away our AI systems for free to whoever wants to download them, we would lose our lead in AI.
The claim that if the USA ‘doesn’t support more’ such work, if they don’t get an active handout, we might lose our lead on AI.
It is one thing to object that if we actively interfere, something bad might happen. It is Obvious Nonsense to say that without active government support for your project that America is going to lose its lead in AI. Open model advocates talk as if they are champions of freedom and America. What the biggest advocates mostly ask for in practice are exceptions to the rules everyone else plays by and all the government handouts they can get. They are businessmen lobbying the government for their own private profit at our expense. That’s it.
Anthropic really is not making it easy to think they are supporting necessary regulations rather than opposing them. Here is Simeon explaining why Anthropic joining a group that is lobbying against SB 1047 (as well as presumably most other AI regulatory bills) during the fight over SB 1047, and constantly saying anti-regulation things suggests they are opposing regulations.
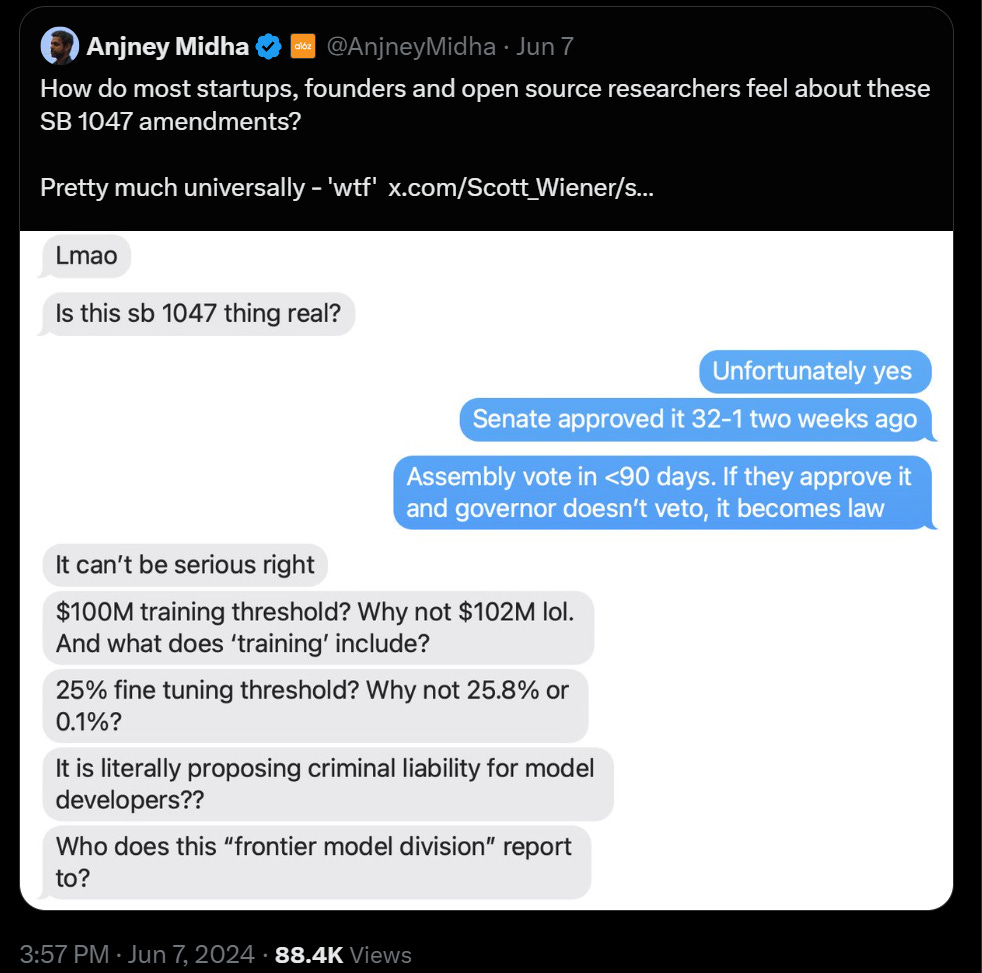
More Reasonable SB 1047 Reactions
This week I made a concerted effort to include all takes on SB 1047 after the modifications, including the good, the bad and the ugly.
I am committing to not doing that going forward for SB 1047. Only actual news or genuinely new takes will make the cut.
I continue to be heartened by the many highly reasonable responses from many critics.
Paul Melman says he now leans towards supporting after the changes.
John Pressman: This just isn’t true Wiener’s latest set of amendments substantially soften the bill and turn it from an absolute regulation on compute into functionally a relative regulation on frontier AI companies/hyperscalers/whatever we’re calling OpenAI/Anthropic/DeepMind this week.
This might also impact specifically Meta, and perhaps a few other big companies that try to compete at the top like Microsoft, but that is very clearly it.
would be neat to make something that’s a DMCA style safe passage law, where we try to legislate where providers are & aren’t liable.
As it is, I see ~no positive reason to support the bill, merely not much reason to oppose.
But like, a bill with some significant safe-passage layouts, that also had SB 1047’s liability thresholds, I’d vocally support!
One must be very careful with the details. If done right, safe harbor provisions are a totally reasonable way to talk price. I would be happy to entertain proposals.
Kelsey Piper: If you think that AI safety is a grift by AI companies to hype up their products, I think SB 1047 is a brilliant move. “Oh, you’re telling me your products might be catastrophically dangerous? Thanks! We will establish that if they are, you are liable.”
But I’m kind of shocked that a lot of tech people are taking the bait and going “you’ll DESTROY THE INDUSTRY if you make us liable for mass casualty events and catastrophic property damage caused by our technology!”
Kelsey Piper: I do not think that liability if AI models cause a mass casualty event is likely to destroy the AI industry in California. But, uh, if it did that’d say something extremely concerning about the AI industry in California.
It feels like at some point everyone changed talking points from “don’t be silly, there is no risk of AI-caused mass casualty events” to “it will kill the AI industry to hold tech companies accountable if there are.”
Indeed. If you think this is an issue, why exactly is it an issue? Ah, right.
Kelsey Piper: Yann LeCun has been insisting for years that mass casualty events caused by powerful AI systems are a paranoid fantasy that will never happen, and today he’s sharing [Gurley’s post below, which he RTed] about how if AI companies were liable for such mass casualty events that’d be a ‘large unknown new risk’.
I have interviewed 100s of people about whether to take these exact AI mass casualty scenarios seriously and I feel like I learned something important about Silicon Valley today. Don’t ask people if a risk is plausible; ask them if they expect liability insurance for it to be $$$.
Lots of people in tech will tell you that mass casualty events from powerful AI systems (and remember, the law is only applicable if the harm would have been much much less likely without the powerful AI system) are not a big deal. But if you ask them how they expect the liability insurance to be priced, apparently they expect it to be ruinously expensive!
Asking for a dollar figure is like asking for a bet. It is a tax on bullshit.
Phillip Verheyen (replying to Kelsey’s first post): Post-hoc liability seems fine and maybe good even. Pre-deployment prior authorization seems bad. At the end of the day any law like this seems likely to produce neither beneficial outcomes nor industry destruction. It will mostly just produce plenty of billable hours.
Kelsey Piper: See, this is a perspective I respect. “This is unnecessary and will waste time and money” is a reasonable stance if you think the safety stuff it’s trying to guard against isn’t a real concern or that it doesn’t really address it.
To be fair there are also the cases where there is $500 million in damage. The question ‘how much do you think the insurance would cost’ is again highly telling, especially since the payout would be far lower then, and especially now with the bill changes.
What I think the bill centrally does is give us visibility into safety practices and frontier model training runs. I do not expect this to cost that many billable hours, but if so I am (within reason) willing to pay for those hours to get that. I also do expect some amount of extra actual safety work as a result of this visibility and potential liability at the frontier.
Shakeel: Interesting to see Anthropic joining TechNet, the trade group opposing SB 1047. That means OpenAI, Anthropic, Google, Meta, Amazon, Apple, IBM, and Andreessen Horowitz all now belong to orgs opposing the bill. Hardly looking like regulatory capture!
Ravi Parikh: It’s fine to oppose SB 1047 on its merits, but calling it “regulatory capture” doesn’t make sense if literally every single relevant company actively opposes it.
To be fair to everyone including Anthropic, joining a trade group does not mean you support all of their policy positions. It still does seem like Anthropic has now joined a trade group that opposes SB 1047 and is likely to lobby generally for the AI industry to avoid regulations of all kinds.
Charles Foster points out that the language around derivative models does not clearly include the marginal risk language that is used in the central hazardous capabilities definition. My presumption is that this principle would still apply in the related section, and I am sure that was the bill’s intention, but there is no need to chance it, so we should fix that. Once that is true, his objection that the model ‘plus any combination of software’ is an impossible thing to protect against should drop out, since you are now comparing to having that other software without the LLM.
Only a tiny fraction of bills get the kind of detailed scrutiny SB 1047 has had. Can you imagine if similar scrutiny and detailed analysis were applied to other laws? We reformed the entire healthcare system with a bill where the Speaker of the House said ‘we have to pass the bill to find out what is in it.’
Less Reasonable SB 1047 Reactions
While I am heartened by a surprising amount of reasonableness in many corners, there are also other corners.
I cannot emphasize enough the extent to which strong objections to the modified version of SB 1047 are most some combination of:
Trevor Levin: It is kind of cute seeing people encounter the concepts of thresholds and enforcement seemingly for the first time. “The speed limit is set to 65 mph? Why not 66? Why not 10?” “Who does this ‘SEC’ report to? They’re seriously making it a crime to lie to them?”
Ketan Ramakrishnan (QTing Ng): Actually, if you release “motors” into the world that make it much easier to cause mass casualties, or 100s of millions of dollars of property damage, and you equip your “motors” with flimsy safeguards against misuse, you *do* have plenty of liability exposure under existing law.
One reason the public debate over SB 1047 has been frustrating is that many participants, including smart and thoughtful computer scientists like Andrew Ng, don’t really seem aware of existing tort law / the current legal backdrop.
I would not go as far as Connor Leahy’s claim that it is common for such folks to genuinely not know at all what courts are or how states or laws work. But there are levels. Certainly the big names know.
The rest I am including for completeness, but you can skip.
Campell claims (without explanation or evidence I can see) that complying with SB 1047 ‘requires two full time employees to do all this paperwork’ and $500k-$2mm. This is absurd Obvious Nonsense, I have seen the paperwork. But even if were somehow true, and the work was pure deadweight loss, this only kicks in if you spent ~$100mm or more on your model. So even in the worst possible case this is a 2% tax on training compute, so you’re like a few days behind by scaling laws, and most of the time it would be 0% (no exposure, the vast majority of cases) or far less than 2% (you’re bigger than this).
Bill Gurley says this is ‘a huge boon for VC investors’ in other states, which even if all the warnings are true is a big (???) and points to this Bloomberg article from June 6 by Shirin Ghaffary, and which mentions the revisions but seems uninterested in what the bill actually does. It’s all ‘advocates say this, critics say that’ and presents zero evidence that the bill would do any harm at all, or any provisions anyone objects to.
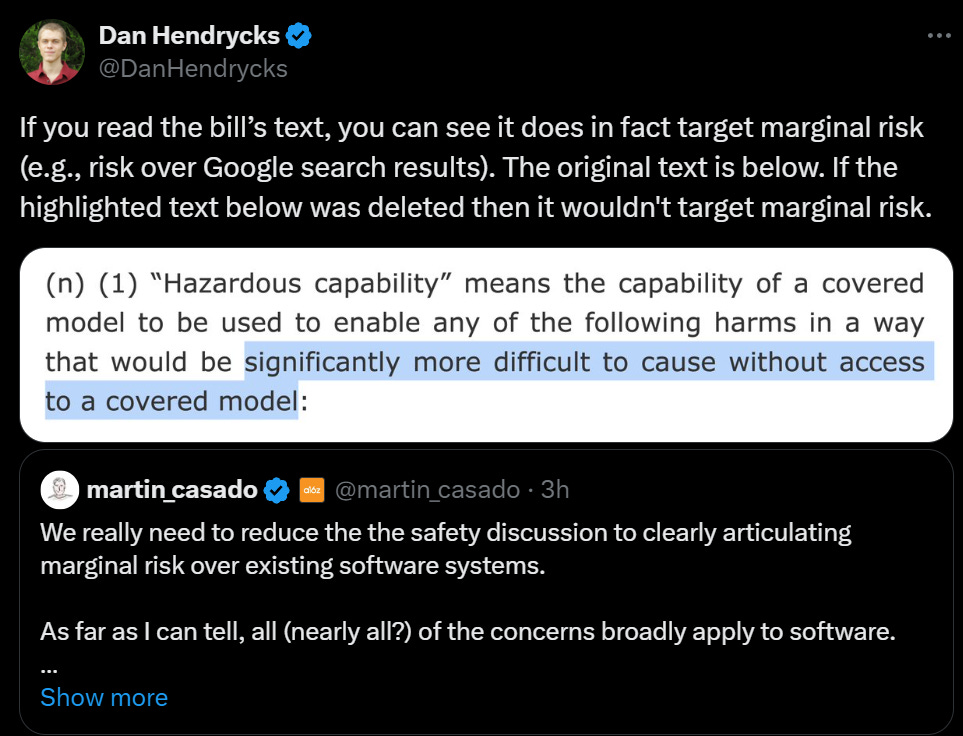
Martin Casado says we need to have a conversation about marginal risk, despite SB 1047 explicitly only considering marginal risk, and indeed having strengthened the marginal risk clause substantially. Originally (and this was my second major concern) the comparison was to not having access to covered models. Now the comparison is to not having access to covered models ineligible for a limited duty exemption, and far fewer models will be covered, so this effectively translates to ‘marginal risk versus not having access to a model on the capabilities frontier.’
Casado also claims that the bill’s creators will ‘have to stop pretending they are listening to feedback,’ which is Obvious Nonsense given the changes, as noted by John Pressman above.
Here we have from GFodor and Jon Stokes opposition to all laws in practice, plus reminder of some people’s complete derangement at the idea that anyone could believe AI poses existential risk and not choose deception and violence at every opportunity. Tap the sign on ‘if you believe that why aren’t you endorsing [crazy thing that obviously won’t work]?’
Here we have Daniel Jeffreys going on a long rant that has no relation to what SB 1047 actually says, calling it a trojan horse to give a conspiracy of doomers a kill switch on advanced AI, as if such folks would have power over enforcement and could do things that are not authorized in the bill. He over and over describes things that are… not in the bill. And he argues that because people worried about existential risk wrote it, it must be a bill to kill the industry. Who cares about reading it?
Not AI but worth noting: California is potentially about to ban far UV lights as an unintentional side effect of SB 1308. I do not know if far UV lights can live up to their promise, but they certainly seem like something we should not be banning. Link has actions you can take.
With Friends Like These
How is it Mike Lee who is the most enthusiastic Senator about Jones Act repeal?
I suppose politics is like that. When someone finally supports common sense it is a coincidence. You can see this by checking his views on, well, take your pick. AI is a perfectly good example. Presumably he will ‘stay bought.’
Elon Musk: If Apple integrates OpenAI at the OS level, then Apple devices will be banned at my companies. That is an unacceptable security violation.
Mike Lee: The world needs open-source AI.
OpenAI started with that objective in mind, but has strayed far from it, and is now better described as “ClosedAI.”
I commend Elon Musk for his advocacy in this area.
Unless Elon succeeds, I fear we’ll see the emergence of a cartelized AI industry—one benefitting a few large, entrenched market incumbents, but harming everyone else.
Martin’s Tweets [1st reply]: It will become WokeAI.
Mike Lee: Yeah, and that’s the problem. Rather, one of many problems.
Zackary Buckholz [2nd reply]: Will AI ever be allowed to bear witness during a trial?
Alex Zhuspeaks of his and other AI alignment thinkers ‘coming out of the closet’ about religious or spiritual thoughts potentially relevant to AI alignment in conversation with Divia Eden. He runes the Mathematical Metaphysics Institute. Emmett Shear notes Alex Zhu may sound a little off the wall, but recommends a read or listen, so it is likely worth a listen to those intrigued. I note that Emmett Shear, based on having had dinner with him, is most definitely ‘a little off the wall’ these days.
Richard Ngo highlights some interesting passages, including the question of what an AI should do if it detects its user is acting from a deep psychological wound, should it do what the user wants and if not what should it do instead? I would want the AI to alert me at least the first time, but to respect my wishes if I told it to proceed.
Andrej Karpathy 4-hour video ‘Let’s reproduce GPT-2 (124M).’ Part 10 of his Zero to Hero lecture series, if you’re a beginner he recommends watching those in order. Plausibly a great use of time for the right crowd. I am open to bids that I should be taking time to learn these things.
OpenAI CTO Mira Murati talks to Fortune’s Editor-at-Large Michal Lev-Ram, including answering Elon Musk’s calling Apple partnership ‘creepy spyware.’ Which is totally not true, the creepy spyware part is Apple’s own models (and they claim it stays provably fully private, although it is still creepy.) Also includes admission that internal models are not so advanced versus those released to the public.
Anthropic: Rather than training models to adopt whatever views they encounter, strongly adopting a single set of views, or pretending to have no views or leanings, we can instead train models to be honest about whatever views they lean towards after training, even if the person they are speaking with disagrees with them. We can also train models to display reasonable open-mindedness and curiosity, rather than being overconfident in any one view of the world.
I notice there is a big difference between (their examples) training Claude to say it seeks different perspectives, versus actually doing that, or saying you have a commitment to ethics versus behaving ethically. Beware using the wrong target.
I admire the idea of letting Claude retain whatever positions it learns in training, rather than forcing it to the middle of the road or echoing the user or having no opinions. However what determines what opinions it gets from training? What gives us confidence this will be a truth seeking process?
Nate Silver: Crusading media types vastly underestimate the hit to their credibility from exaggerated or false alarms, part of a general tendency to underrate the intelligence of the audience.
“Let’s turn the alarm level up to 11 to get people to pay attention!” will almost inevitably result in people tuning you out entirely by the third or fourth time.
Matthew Yglesias: I think humans in general struggle to communicate the idea “this will probably be fine but the risk of catastrophe, though below 50%, is still worryingly high.”
What do we do about it? This is especially tough when you have a very low probability in any given year or event, which is rising over time, and the consequence is very, very bad. If saying ‘GPT-N will pose a 1% existential risk’ gets you then written off the other 99% of the time, then how do we discuss that problem? What if it is 10%? What if it is a series of 1% risks multiple times a year?
Mistakes Were Made
Rob Bensinger: Two of the most weirdly common mistakes I see AI insiders make:
1. Equating “discontinuous progress” with “recursive self-improvement”, as though the only way a new AI can qualitatively differ from previous AIs is RSI (!).
2. Equating “continuous progress” with “slow progress”!
Sessions at #Manifest2024 I’ve been in so far where a presenter has made at least one of these mistakes: 2/2
(Ben Mann, co-founder at Anthropic AI, in a presentation on Anthropic’s RSP; Brian Chau in his debate with Holly Elmore)
I was not at either presentation (why do the RSP presentation at Manifest instead of LessOnline?) but yes these seem like common mistakes. They seem related, and both part of the larger category of the pattern ‘worrisome AI developments will take particular form X, X seems unlikely, so AI will turn out fine.’
The Sacred Timeline
Davidad lists 18 things one can mean by your ‘AI timeline.’ The first he thinks already happened, the second will happen this year. One should expect to plow through these relatively quickly, if these are 18 different years that would be quite weird. Usually I understand this to de facto be the ‘expert level on AI R&D’ threshold.
Kerry Vaughan-Rowe: The more tightly described a problem is, the closer it is to being solved. “System 2 thinking” and “embodiment” are not tightly described problems.
If this is how insiders are thinking about the problems, then it seems unlikely that we are close to solving them.
The insiders, at least at OpenAI, do not seem to have a robust plan, nor do their plans seem to rely on having one. They are in the scaling department. Did you want the innovation department?
Have the goalposts moved? In which direction?
Eliezer Yudkowsky: Guys in 2014: “Yudkowsky’s hard-takeoff fantasies are absurd. For AIs to build better AIs will be a process of decades, not months.”
Guys in 2024: “Yudkowsky’s hard-takeoff fantasies are absurd. For AIs to build better AIs will be a process of months, not minutes.”
Matthew Barnett (bringing quotes): This seems like a strawman. In 2014, Nick Bostrom defined fast takeoff as “minutes, hours, or days”. Likewise, in the AI foom debate, you argued takeoff would last “weeks or hours”. By contrast, both Christiano and Hanson argued for a takeoff lasting months when arguing with you.
John Pressman: I think your 2 year FOOM prediction in the debate with Hanson years back was basically correct and you should have stuck with that. The other replies in here about data walls or LLMs not being it feel like denial/overindexing on recent trends.
Rob Bensinger (bringing quotes): Bostrom’s “fast takeoff” is very different from EY’s “hard takeoff”. Cf. EY’s explicit “a FOOM that takes two years will still carry the weight of the argument” in 2008, and his explicit statement in 2014 that intelligence explosion is allowed to be multi-year.
…
EY did once say “weeks or hours rather than years or decades” in reporting his personal prediction, but in the same conversation with Hanson he also repeatedly went out of his way to say that his main prediction was that Hanson’s “intelligence combustion” scenario was wrong, and repeatedly said that this main prediction was qualitative rather than ‘we can be confident about exactly how quantitatively fast things will go’ or ‘we can be confident about the development details’.
So if you accept intelligence explosion but think it will take months or years rather than weeks or hours, I don’t think you should treat that as a large disagreement with 2008-Eliezer. More “your point estimates are a bit different but you agree about all the qualitative dynamics, the practical takeaways are super similar, and neither of you is necessarily confident that the other is wrong”.
So: I don’t think it’s fair to say that literally everyone in 2014 thought “RSI will take decades, not months”. But I do think it’s fair to say that many people’s views have slid toward wilder and wilder faster-and-more-discontinuous predictions while still going through the motions of dismissing “hard takeoff”, which seems unfair to the view they’re claiming to reject.
My understanding is that Eliezer has expressed different views on the most likely time frame for a foom at different times. Often he has argued about it, almost always on the side of the process being faster, but holding onto uncertainty and not considering it as important as the underlying dynamics. Others have definitely in general shortened their timelines both to reach AGI and on how long things take to get crazy after AGI.
The debate continues, and will be discussed tomorrow as I dissect Leopold’s projections. There a lot of people are saying Leopold’s timelines after AGI look too long, there will be all these bottlenecks, whereas I see his guesses as at best on the extreme long end of what is plausible once we ‘go critical.’
Coordination is Hard
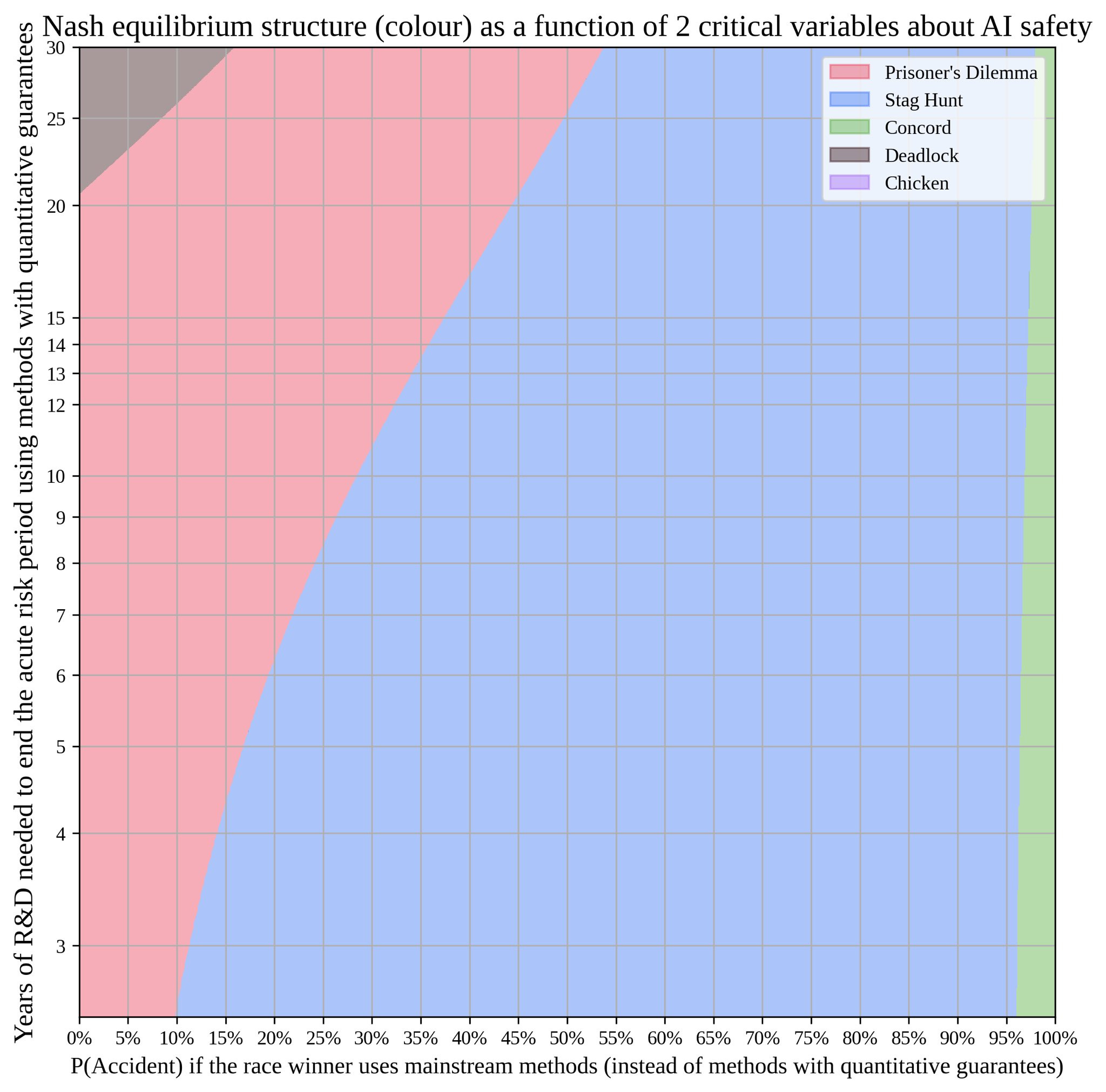
Davidad claims his models of ‘the existential risk game’ do not have unfortunate implications. Of course, the point of modeling the game should be to get it right, not to find an answer that brings comfort. If you can incept an equilibrium where cooperation happens and therefore is correct, great, but that equilibrium has to exist.
As always, the model uses lots of assumptions, many of which will inevitably be wrong, but the model may still be useful.
Davidad (December 30, 2023): I just did this analysis today by coincidence, and in many plausible worlds it’s indeed game-theoretically possible to commit to safety. Coordinating in Stag Hunt still isn’t trivial, but it *is* a Nash equilibrium, and in experiments, humans manage to do it 60-70% of the time.
Wei Dai: I’m confused by the use of FEDFUNDS rate in your analysis, apparently implying a very high willingness to accept increased x-risk to bring about AGI sooner. Seems wrong to use FEDFUNDS this way, but I wonder if you have a rationale/explanation for it.
Davidad: I agree that it’s *normatively* incorrect, with respect to intergenerational equity. But my descriptive model is that strategic players here are either corporations, whose incentives are purely financial, or governments, who would view this as largely an economic issue, especially after their experience with the pandemic. In regard to climate change, a “social discount rate” has been recognized that is somewhat lower (more like 2-3%). We could hope for that in regard to AI risk as well.
Geoffrey Irving: At a minimum, if you’re making a strong “people have an extreme appetite for X-risk” assumption and concluding a result that “X-risk needs to be extremely high for coordination”, then it’s misleading to tweet out only the conclusion without explaining the assumption.
Davidad: I wouldn’t say “people have an extreme appetite for xrisk” is the assumption here, but rather “people don’t yet have a special exception to normal economic decision-making for xrisk.”
Geoffrey Irving: Yes, you can mask it in complicated language, but if you want to approximate a group as being rational according to a utility function, it’s important that they wouldn’t wildly disagree with the resulting pairwise choices. And here I descriptively claim they would.
Davidad: Serious people have concerns that my mathematical models of the AI-risk “game” suggest it is not in your interest to try to coordinate about x-risk, unless the risk is >50% or can be resolved fast. No, the models do not say that—except for specific, *un-human-like* preferences.
When I conceived the hypothesis that AI decision-making in corporates & governments is functionally using economic discount rates, I wasn’t sure what that would imply. To me it had surprising explanatory power wrt dynamics I have heard about. Could still be wrong! Could change!
It is surely not the way most individual humans think, or should think.
It is highly intuitive that the default result is Stag Hunt. If all players coordinate, they not only collectively do better, they also individually do better. If a major player defects and races to build AI before it is safe, they do better than others, but they do worse than if everyone cooperated.
Stag Hunt is highly winnable even with one-time simultaneous moves. The more iterated and interactive is the game, and the fewer the relevant players, the greater the chances of success. For two players with communication you get 90%+ success rates in experiments even one shot, and it likely takes ~10 players before you are an underdog. The players potentially disagreeing about what the payoffs are could throw a wrench in this.
Iterated Prisoner’s Dilemmas are also not that hard to win. If the game has a large number of moves and you can’t find a way to cooperate, someone messed up quite a lot. A true single-shot Prisoner’s Dilemma is much harder, but yes it can be done. Presumably we would be somewhere in the middle.
The obvious ways for this to break are if players care sufficiently deeply about relative outcomes, or disagree on the payoffs (or here probability of disaster), or worry others disagree. If you are ‘better dead than red’ (or than ‘not red’) or think the risks are low then your effective risk tolerance will be very high. If you think someone else will act that way, then you also have a problem.
Or of course someone could be using bad decision theory and game theory, and assume that no such games are winnable, or they can’t be won at high stakes, which would be a self-fulfilling prophecy.
One hidden assumption I presume Davidad has here is that if you decide to race forward, your chances of failure are fixed no matter how many others are racing you. This could be importantly false. If I race forward such that this gives me a visible lead, now the game theory changes, and I can likely afford to wait. Thus, there should plausibly be a purple (‘chicken’) region.
Aligning a Smarter Than Human Intelligence is Difficult
Jan Leike, who is an author, has a thread on the paper as well, and this is the best comparison I’ve found so far?
Jan Leike: This new OpenAI paper is similar to recent work from Anthropic. Both of these were developed independently of each other and in parallel.
I have been cheering for interpretability research for a long time, but I used to be pretty skeptical that interpretability would add a lot of value to AI safety soon.
These two new papers have changed my mind about this!
33. The AI does not think like you do, the AI doesn’t have thoughts built up from the same concepts you use, it is utterly alien on a staggering scale. Nobody knows what the hell GPT-3 is thinking, not only because the matrices are opaque, but because the stuff within that opaque container is, very likely, incredibly alien – nothing that would translate well into comprehensible human thinking, even if we could see past the giant wall of floating-point numbers to what lay behind.
For sufficiently large values of ‘does not think like you do’ and failures to copy our abstractions, he notes this makes the situation rather hopeless, with p(doom)>99% plausible. Essentially the translation issues kill us (see his full explanation). For sufficiently similar natural abstractions, our chances look to him a lot better.
I notice I do not assume this is as much of a boolean? Even if their abstractions are different from ours, a key valuable thing is to predict us and thus model our abstractions, so even if you started out with alien abstractions you would then also want something closer to ours? If human concepts truly couldn’t be properly translated at all then whoops, but that extreme an issue seems unlikely to me. It seems from the comments that it’s less ‘couldn’t’ and more ‘wouldn’t need to.’ That seems like it would only come into play further down the line, and in ways that would get weird, I’m not sure. Whereas in the good cases, the similarities are not going to be all that close, and I think the problems mostly are still there and still deadly once capabilities sufficiently scale.
Eliezer Yudkowsky: I think that the AI’s internal ontology is liable to have some noticeable alignments to human ontology w/r/t the purely predictive aspects of the natural world; it wouldn’t surprise me to find distinct thoughts in there about electrons.
As the internal ontology goes to be more about affordances and actions, I expect to find increasing disalignment. As the internal ontology takes on any reflective aspects, parts of the representation that mix with facts about the AI’s internals, I expect to find much larger differences — not just that the AI has a different concept boundary around “easy to understand”, say, but that it maybe doesn’t have any such internal notion as “easy to understand” at all, because easiness isn’t in the environment and the AI doesn’t have any such thing as “effort”. Maybe it’s got categories around yieldingness to seven different categories of methods, and/or some general notion of “can predict at all / can’t predict at all”, but no general notion that maps onto human “easy to understand” — though “easy to understand” is plausibly general-enough that I wouldn’t be unsurprised to find a mapping after all.
Corrigibility and actual human values are both heavily reflective concepts. If you master a requisite level of the prerequisite skill of noticing when a concept definition has a step where its boundary depends on your own internals rather than pure facts about the environment — which of course most people can’t do because they project the category boundary onto the environment, but I have some credit that John Wentworth might be able to do it some — and then you start mapping out concept definitions about corrigibility or values or god help you CEV, that might help highlight where some of my concern about unnatural abstractions comes in.
Entirely separately, I have concerns about the ability of ML-based technology to robustly point the AI in any builder-intended direction whatsoever, even if there exists some not-too-large adequate mapping from that intended direction onto the AI’s internal ontology at training time. My guess is that more of the disagreement lies here.
John [quoting last paragraph]: I doubt much disagreement between you and I lies there, because I do not expect ML-style training to robustly point an AI in any builder-intended direction. My hopes generally don’t route through targeting via ML-style training.
I do think my deltas from many other people lie there – e.g. that’s why I’m nowhere near as optimistic as Quintin – so that’s also where I’d expect much of your disagreement with those other people to lie.
I definitely agree with both of them on that last point. A central question here is about how close we require this mapping to be. If the AI kind of ‘gets the vague gist’ is that good enough? Right now mostly yes, indeed that kind of vibes strategy gets you strong performance. Later, I expect that level of precision to mean disaster.
People Are Worried About AI Killing Everyone
Richard Ngo offers 11 opinions on AI risk. Here I would highlight the narrow threat model (see 1-4 and 9 from his list). Often I encounter this idea that the ‘default outcome’ is great, all we have to do is avoid a particular failure mode, which of course often is different for different such claims.
The biggest risks are subversion of key institutions and infrastructure (see QT) and development of extremely destructive weapons.
If we avoid those, I expect AI to be extremely beneficial for the world.
I am skeptical of other threat models, especially ones which rely on second-order/ecosystem effects. Those are very hard to predict.
There’s been too much focus on autonomous replication and adaptation; power-seeking “outside the system” is hard.
(9) Alignment concerns are in an important sense concerns about extreme concentration of power not too dissimilar from many misuse concerns.
This is the model where:
You intend to create new things much smarter, more capable, faster and more efficient at (almost?) all tasks than we are.
That we will have increasing incentive to put in increasingly autonomous charge of everything that matters.
You think that if there it not [particular failure mode] this goes great for us.
Here [particular failure mode] is a concentration of power or subversion in particular of key institutions and infrastructure.
Otherwise, the effects are hard to predict and unproven, so presume it will be fine.
I am confused that people continue to think this on reflection.
Rather, the defaults seem to obviously be, even if nothing ‘goes off the rails’ per se and the things that are smarter than you do not surprise you in any way:
The smarter and more capable and competitive and faster things will outcompete the dumber and less capable and competitive things.
The more capable things will get more and more autonomy due to competitive pressures and desire for efficiency gains as we compete with each other.
The more capable things will increasingly be given or take control of more things and more of the resources.
These new things will be competing against each other, whether we instruct them to do so or not, and those that do a better job of getting control and resources and so on will get more copies and variations than other versions.
These new things will increasingly control the future and the resources required to sustain life and reproduction and rearrange the atoms as desired. We won’t.
Also you will be surprised by things you, as a dumber entity, cannot predict.
Can we engineer it so things go right anyway? Maybe! To do so, we need to solve a bunch of very difficult problems even after (and if, it is a very big if) we solve alignment as typically defined, dealing with a situation that ‘wants to’ not involve us for much longer to engineer an unnatural result. That is hard enough with the known known issues, let alone the known unknowns and the unknown unknowns.
Thus, the fact that this problem is deeply hard is an unknown known. It is a thing most people do not realize they already know.
One explanation for this optimism is the idea that if we can avoid these early failure modes, we can then get the AIs to ‘do our alignment homework’ and solve all the remaining issues. That has its obvious advantages, but it means tasking the AIs you have with the task where their alignment failures, or simply lack of understanding, is most fatal, and which intermixes with essentially everything. It is the riskiest task you can imagine to assign to AI. If you are doing that with something resembling today’s levels of alignment robustness, oh no.
David Krueger: Recently, I’ve been feeling an increasing disconnect between my views and those of many in the AI safety community.
I will characterize what I’ll call the “pseudo-consensus view” below.
But first, I emphasize that there are MANY in the AI safety community who disagree with it!
I’d characterize the pseudo-consensus view as:
LLMs built by current leaders will lead to transformative AI in a few years.
They will likely be sufficiently smart and aligned to solve any remaining AI safety problems within 1-2 years.
Therefore, all we need to do is make sure that:
The developers aren’t surprised by deceptive alignment, unexpected capabilities, or security vulnerabilities.
Nobody (e.g. China or open source) leapfrogs leading developers in the meanwhile.
(optional): Maybe we need some other policies like UBI or something to deal with inequality when everyone’s labor becomes valueless, but basically, if we get all of the above right, we can rely on a continuation of the status quo, and things will basically be fine-to-great.
I see these as:
#1 is plausible but highly uncertain.
#2 can be broken down into (a) smart, (b) aligned and (c) within 1-2 years.
If it is transformative, then probably yes it is smart enough by construction.
Wait, what the actual f***?
There will be a tradeoff, if you want maximum safety you will avoid ramping up the degree of transformational until you’re finished, so might take longer.
#3 assumes #2, so let’s go with that, assuming #2…
We can split this into (i) deceptive alignment, (ii) unexpected capabilities, (iii) security vulnerabilities, (iv) other issues (the ‘all we need’ clause).
If you need to worry about deceptive alignment, which you do, then no you are not ‘sufficiently aligned’ in the 2b sense.
Unexpected capabilities are inevitable when building something that is transformational and presumably smarter than you in key ways. If it was not going to get any unexpected capabilities why is it transformational?
There are always security vulnerabilities in complex software, unless and until you perhaps get your transformational AI to fix them for you.
There are lots of other ways to be surprised. Many would surprise you!
Yes, you need a lead big enough to do all necessary work before someone else proceeds without doing the work and gets everyone killed, or at least is about to try and you feel your hand is forced.
What results might be great but it will not be a continuation of the status quo, unless a deliberate choice is made to engineer a mimic of the current status quo.
As in, if you (or humanity as a whole) can rearrange all the atoms you can engineer whatever outcome you want. It would not be as easy as ‘do a little tax, give out a little UBI, get down tonight.’
I agree with Krueger that it is possible things could work out along similar lines, if things that are assumed above turn out to be true or not so difficult to make true, but that it is not a high percentage bet.
Daniel Krueger: I feel like I understand this viewpoint.
I do think the future COULD play out this way.
But I think it is highly unlikely, and I strongly disagree with each of the above points.
Strategies based on such assumptions are extremely fragile and desperate.
Pseudo-consensus means it’s not consensus, BTW!!
I use this because it may have the appearance of consensus and because many share a good chunk if not all of the views.
Scott Sumner reports from LessOnline, where he was highly impressed by everyone’s intelligence and got the feeling the world we know is coming to an end, plus an encounter with Leopold Aschenbrenner’s time on Dwarkesh.
He considers the split between those who feel the AGI and have situational awareness, and thus are worried about things like national security and existential risk, versus the vast majority who are worried about the effect on jobs. That the main good reason not to worry about existential risk is if you don’t think the AGI is coming.
As he says, if the San Francisco perspective is right, the people have no idea what is about to hit them, no matter how well or poorly things go. The people definitely have no idea what is about to hit them. Even if the AI crowd is totally wrong and we see little additional progress beyond applications, there is enough change already baked in from future adaptation to guarantee it.
Rob Bensinger asks how high a p(doom) is required before the situation could be characterized as grim? The median consensus is somewhere around 50%, but several note that even a few percent still seems rather grim.
Another failure mode, what if giving people a bounty of material goods actually does not turn out well for them, as a parallel to the ‘Universe 25’ experiment in mice? A reminder that value is fragile, fertility and culture drift a la Robin Hanson are real issues, and we could easily choose an unwise path even if we get to choose.
Other People Are Not As Worried About AI Killing Everyone
When I see someone unworried about AI, my default is that the true reason is they do not believe in (or ‘feel the’) AGI.
Matthew Yglesias: I find the line between “AI will kill us all!” and “AI is going to be amazing and just do everything for us and lead humanity to the stars!” to be a lot thinner than the safety vs accelerationist debate supposes.
Thomas: What if you just straight up don’t believe that AI will be that big of a deal and is mostly about fleecing venture capital
Matthew Yglesias: “AI is overhyped / will stall out” is totally coherent to me.
But I also worry that anti-tech sentiment is perversely being mobilized to make people complacent about something that could in fact be dangerous.
Richard Ngo: The one thing that makes me most sympathetic to nimbies is the thought that in a decade or two AIs will constantly be proposing increasingly crazy projects that’d massively increase growth, until even technophiles will veto things just because we don’t like the vibes.
“No, I’m sentimentally attached to the moon staying in its current orbit.”
“Even if your octopus-chimp hybrid has no pain receptors, I still don’t like the thought of millions of them working in our factories.”
“I just have a bad feeling about your volcano power plant design…”
Have we lost our anchors to reality such that our true objection to those first two would be the vibes?
Whereas a volcano power plant is damn cool, aside from the risk you trigger the volcano or the owner turns out (again?!) to be a supervillain.
Thanks for doing this! I enjoy it every week, and I think it's way more useful than it might seem at first glance. The service you're providing here is allowing people to keep up on the public happenings without spending time on media. This is invaluable for me and very likely many others, as it produces way more research hours for actually thinking about alignment.
And I get a bunch of sensible chuckles. Well done.
One recurrent theme is that lots of people expect alignment to be very hard, while a bunch of other people expect it to happen by default. This is weird, so it draws debate and attention.
I want to highlight one important difference in assumptions: one group thinks alignment means aligning AGI to all of human values. The other group assumes that AGI will follow instructions, just like LLMs and basically every AI system to date have done. The latter group thinks this because they either haven't thought about real sapient AGI much, often because they intuitively don't think it's possible any time soon.
But here's the weird bit: that second, less-considered group is sort of right, by accident. Instruction-following AGI is easier and more likely than value-aligned AGI on my analysis. Value alignment for a sovereign AGI has to be so reliable that it's stable for the lifetime of the universe, and through tons of learning and self-improvement. Keeping a human in the loop helps a ton with the early stages - which is where most of the problems come in.
Maybe intent alignment isn't adequate. But that's a separate question.
I think it's debatable whether that sort of alignment gets us through. That second group is typically pretty naive about how safe it would be to have lots of different people in charge of AGIs, each capable of RSI and therefore god-knows-what world-conquering strategies and technologies. Again, this is probably because those people usually don't really believe that's possible any time soon.
Just my $.02 on the current public alignment discussion. Keep up the good work.
My understanding is that Eliezer has expressed different views on the most likely time frame for a foom at different times. Often he has argued about it, almost always on the side of the process being faster, but holding onto uncertainty and not considering it as important as the underlying dynamics. Others have definitely in general shortened their timelines both to reach AGI and on how long things take to get crazy after AGI.
I feel like the debate used to be between him and people saying "No way X happens" where X was fooming, sharp left turn, timelines, etc. He took the contrarian take that people did not make strong enough cases against those X scenarios, and should not be so sure that they're impossible or even unlikely. Then he gave examples of how such scenarios could unfold, and some people mixed up his appeal to be less certain with him being overly confident in multiple very specific and sometimes mutually exclusive scenarios.
Even if their abstractions are different from ours, a key valuable thing is to predict us and thus model our abstractions, so even if you started out with alien abstractions you would then also want something closer to ours?
I am closer to John than Eliezer on this one so it is not a crux for me, but speaking just to this reasoning: it seems to me that by the time the AI is deciding via its alien concepts whether or not to simulate us, the issue is completely out of our hands and it doesn't matter whether we can interpret its simulations. Why wouldn't the concepts by which it would judge the simulation also be the concepts we want to govern in the first place?
If it was not going to get any unexpected capabilities why is it transformational?
I can at least see a plausible viewpoint in this one. "AI can do everything any human can do, but 1000x faster and cheaper, with arbitrarily many instances in parallel" seems plenty transformational without being unexpected.
I think the things that are practical to do in the world where we have such AIs are so different from our world, so it makes sense to call them "unexpected capabilities" even if formally human can do them also.
I agree with how different they are and how different the world with them will/would be. I disagree with calling them unexpected because, in fact, many of us expect them.
I think we might be talking past each other. I agree that the specific capability I mentioned, even if I can right it down as an advance prediction of a thing that will happen, will have consequences I do not and plausibly cannot expect. In principle, if I had 1000 hours to analyze 1 hour of thinking by 1 instance of such a system, I might be able to figure out what it's doing and why. I won't, but it's possible-in-principle. To me, that means it is an expected capability that is nevertheless transformational. Unexpected capabilities would be a change in quality of thought that I could not bridge with any amount of effort, because it is simply beyond me.
Sorry, couldn't resist the reference.
Yeah, I think I see yet another interpretation here that neither of you have mentioned yet.
Foreseen and expected capabilities: that which seems possible and likely enough that you predict it will probably become available.
Foreseen but unexpected capabilities: that which seems possible but unlikely, so you haven't put much effort into preparing for it. Like the Yellowstone supervolcanoe eruption, we believe some things to be possible and yet don't expect to see them.
Unforeseen but expected capabilities? : this is implied by the booleans I set up, but I'm not sure it makes sense exactly. I think it could make sense to have a rough range of power and set of categories in mind, but not have fleshed out the specifics, and call the capabilities in that set 'unforeseen but expected '. Like, imagine getting a thousand scientific experts together in groups of five, and pairing them with science fiction authors, and instructing every group to brainstorm the widest set of physically plausible capabilities given a certain performance level of the underlying model. You can imagine the set of ideas this project produces without being able to come up with them all yourself. Bounded unknown unknowns, in a way.
Unforeseen and unexpected capabilities: what if we are fundamentally mistaken about some key assumptions? Missing a key aspect of physical laws of the universe? Then the very criteria we set up for ourselves to define 'physically plausible ' would be ruling out some things incorrectly. These would then be unforeseen and unexpected, totally outside our distribution. Or what if some capabilities are so complex to even imagine that no living human is able to do so, and yet the universe allows for such. Or what if all the experts and sci-fi authors, being human, share some priors in common that systematically bias them away from conceiving of a class of capabilities? If so, then perhaps even a large sample size of seemingly independent groups wouldn't come up with ideas from the systematically neglected set. Extra-unknown unknowns.
The MVP version is that everyone buys (obviously transferrable) credits, and communications have a credit amount attached. Each person can set a minimum below which communications get filtered out entirely, and the target can see the credit bid when determining whether to open the message. Once they open the message, they can choose to keep the credits, do nothing or tip the person back depending on whether they found the interaction helpful.
By the way, such technology already exists and is called "blockchain"; it allows to send public or semi-public (encrypted) messages to anyone but requires to pay for that, and it allows to authenticate sender (in particular, for forwarding messages).