Cataloguing Priors in Theory and Practice
post by Paul Bricman (paulbricman) · 2022-10-13T12:36:40.477Z · LW · GW · 8 commentsContents
Intro Priors Simplicity Speed (Structural) Stability NTK Outro None 8 comments
This post is part of my hypothesis subspace [? · GW] sequence, a living collection of proposals I'm exploring at Refine. [LW · GW] Preceded by an exploration of Boolean primitives in the context of coupled optimizers [LW · GW].
Thanks Alexander Oldenziel and Paul Colognese for discussions which inspired this post.
Intro
Simplicity prior, speed prior, and stability prior — what do they all have in common? They are all means of tilting an optimization surface towards solutions with certain properties. In other words, they are all heuristics informing the navigation of model space, trainer space, etc. However, what brings them together is also a systematic divide between their theoretical/conceptual/abstract framings and their practical/engineering implementations. All those priors appear to have been used in contemporary ML in one form or another, yet conceptual-heavy researchers are often unaware of those interesting data points, while ML engineers often treat those implementations as mere tricks to improve performance (e.g. generalization).
In the language of coupled optimizers I've explored over the few past posts in the sequence, such heuristics are artifacts of meta-optimization (e.g. a human crafting a trainer by building in certain such tendencies), and often tend to be direct human-made artifacts, rather than the result of downstream optimization. Though this need not be the case, as the simplicity prior happens to itself be quite simple... It might emerge naturally from a trainer which itself is trained to be simple. Similarly, the speed prior happens to itself be quite fast, as penalizing a duration is trivial. It might emerge naturally from a trainer, should it be trained to itself be fast.
Anyway, let's briefly catalog a few popular priors, describe the rationale for employing them, list instances of their use in ML, and finally document possible failure modes associated with blindly following them.
Priors
Some members of the list can be better described as heuristics or biases than priors. However, there are some basic connections between those in that they all cause an optimization process to yield certain outcomes more than others. If you start with a prior of possible ML model parametrizations and use training data to update towards your final distribution, your choice of prior will naturally influence the posterior. This prior can be informed by heuristics, such as "we're more interested in simple models than complex ones from the get-go." Bias as in structural bias, inductive bias, and bias-variance trade-off describes a similar process of tailoring the ML model to broadly yield certain types of results efficiently.
Simplicity
Informally known as Occam's razor, and extremely formally known as Solomonoff prior [LW · GW], the simplicity prior biases optimization towards solutions which are simple. "Simple" here is often operationalized using the minimum description length: what's the shortest description of an algorithm/model/concept/world/etc. required to accurately specify it? Simple candidates are then the ones with a particularly short such shortest length.
The rationale behind employing the simplicity prior in an optimization process is that it systematically reduces the variance of the solution. This means that it increases the odds that the solution will behave in a similar way in different situations, as opposed to growing too reliant on the idiosyncrasies of your finite/limited/bound optimization process. When training ML models, simplicity tends to yield strong generalization performance. When building world models, simplicity tends to yield theories which hold better against new empirical data.
In ML, the use of simplicity is most associated with the bias-variance trade-off and the general quest for avoiding overfitting models to training data. There are specific measures for model simplicity/complexity out there, such as the VC-dimension describing how fine-grained a model can arbitrarily "shatter" data into different classes. However, such measures are not usually used in practice, like ever. In contrast, regularizers such as L1 and L2 norms applied to model weights (in the style of Ridge and Lasso regression), are used extensively. This regularization process penalizes models whose parameters are large and dense (i.e. many things having a non-trivial influence on each other — complex). In other words, it enables trainers to nudge models towards regions of model space deemed relatively simple.
However, simplicity is not enough to e.g. select among all the possible objectives which might have explained the behavior of a human. Quite bluntly, Occam's razor is insufficient to infer the preferences of irrational agents. Humans (i.e. irrational agents) appear not to actually value the simplest thing which would explain their behavior. For another failure mode, consider the notion of acausal attack highlighted by Vanessa Kossoy here, or in terms of the fact that the Solomonoff prior is malign [LW · GW]. In this scenario, an AGI incentivized to keep it simple might conclude that the shortest explanation of how the universe works is "[The Great Old One] has been running all possible worlds based on all possible physics, including us." This inference might allegedly incentivize the AGI to defer to The Great Old One as its causal precursor, therefore missing us in the process. Entertaining related ideas with a sprinkle of anthropics has a tendency to get you into the unproductive state of wondering whether you're in the middle of a computation being run by a language model on another plane of existence which is being prompted to generate a John Wentworth post.
Speed
When talking about the description of a phenomenon in the form of an algorithm, short algorithms don't necessarily equate fast algorithms. Running a for-loop over all possible physics and implementing all appears extremely simple to describe, but also extremely time-consuming in terms of ops/iterations/epochs/etc. You might have a simple recipe, but it might take forever to follow.
However, it seems that selecting for fast algorithms might be useful. For instance, deception has been argued to inevitably take longer than the non-deceptive alternative [LW · GW]. As seen in the ELK report:
Human imitation requires doing inference in the entire human Bayes net to answer even a single question. Intuitively, that seems like much more work than using the direct translator to simply “look up” the answer.
How does this show up in contemporary ML? An interesting instance is the architectural decision of adaptive computation time. In the paper, RNNs are designed to be able to both (1) perform multiple computational steps when processing a certain input, and (2) learn how many steps to conduct during inference. More compute would always help, so won't it just learn to spam more steps? Not really, as the model is also penalized for abusing the number of steps and pondering for too long. A balance between capability and speed has to be struck by the model.
The logit lens [LW · GW] could also be seen as relating to the speed prior. Logit lenses attempt to surface the "best guess" of a transformer model at each layer, in contrast to the common practice of just taking the end result after a set amount of computation:
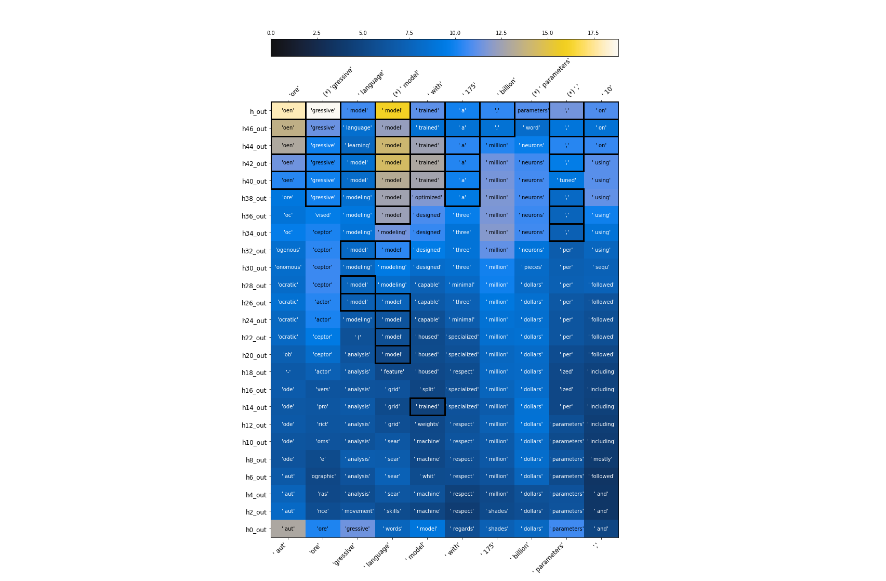
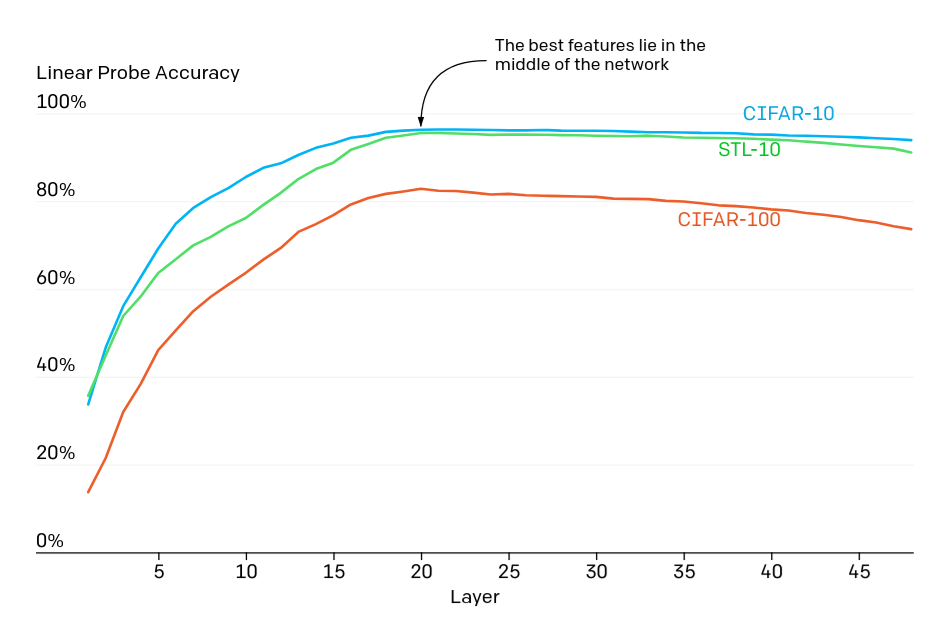
Linear probing is yet another related technique, and in a sense a more general version of logit lensing. If you arbitrarily cut out a set number of final layers of an ML model in a Procrustean frenzy and map latent activations to outputs using a plain linear regression, what performance can you get? For instance, if the ML model below was penalized for the number of subsequent layers it makes use of, it might as well learn when to cut some computational corners and only use a few dozen layers.
Early vision models (e.g. Inception), also had different output heads at different depths. Supposedly, this helped with training stability, but could also be used in a speed prior setting:

In the terminology of Paul Colognese and Evan Hubinger [LW · GW], the logit lens, linear probing, and early vision models might tie into the "early-exiting" proposal, while adaptive computation time might relate to the "pondering" class. Those instances of bridging the theory-practice gap might help build such priors into future models.
The flip-side of selecting for speed would be that fast undesirable dynamics would also be encouraged. Perhaps determining what humans would superficially find appropriate takes way less time than determining what they might like if they were smarter, thought for longer, etc. Also, while selecting for simplicity seems to often yield good generalization , selecting for speed inevitably cuts back on performance, as you could always refine your best guess a tiny bit further.
(Structural) Stability
A solution to an optimization process which doesn't completely break down under small perturbations would also seem pretty neat. For instance, such perturbations might consist of small changes to the weights of a model, small changes to the ontology embedded in a world model, or small changes to an algorithm. Bonus points if perturbations can be immediately followed by a return back to the stable state. We wouldn't want the systems we deploy to resemble a pencil balancing on each tip, with the smallest gust of wind across model space leading them into radically different dynamics. The notions of stability and structural stability are explored in more depth here [LW · GW].
In practice, ML models themselves appear to become "immune" to perturbations precisely when they're being trained to operate under said perturbations. For instance, DropOut and its variations constantly sway the model being trained across model space, and condition it to perform well. This nudges the very training process towards region of model space from where such nudges would still yield good performance. One such recipe for stability appears to be redundancy — the ML model develops various mildly-independent processing pathways in a setup reminiscent of model ensembles and bagged estimators, but internal to the model's processing. If one such pathway fails, others will hopefully compensate, which appears to be the case as DropOut tends to improve generalization.
Another example is adversarial training, where targeted stressors in the form of adversarial examples are being introduced in the ML model's curriculum. During training, the model learns to cope with such perturbations. This more comprehensive training process takes more compute, which makes it somewhat more expensive, though. This also tends to be the case with DropOut. Yet another related project is MAML, a training paradigm in which an ML model is trained to reach a parametrization from which subsequent training steps would yield strong performance.
A failure mode of structural stability as a prior is that convergent properties such as the drive to gain resources are instrumental objectives in achieving quite a number of terminal feats. This might decrease the effectiveness of stability as a heuristic for navigating model space towards good models, and in turn trainer space towards trainers which produce good models. For priors which trickle down the optimization stack — though mostly in the context of speed priors — have a look at this [LW · GW]. Also, structural stability yields rigidity and various forms of lock-in. It's inherently hard to nudge something designed to resist perturbations after it has been deployed.
NTK
While introduced in alignment through the context of simplicity priors [LW · GW], neural tangent kernels allow you to gauge the general "predisposition" of an ML model towards converging to various ways of relating data points. If being able to estimate the way the resulting ML model represents the world this way, we might then be able to tweak the training process itself so that it leads more towards intended perspectives (i.e. ways of grouping together and relating data points). How to then define the intended arrangement of the world in the eye of the ML model then becomes the locus of the hard part of the alignment problem, but like all members of this list, NTK might slightly increase the odds of getting good outcomes even without yielding a full verifiable solution.
"I am concerned, in short, with a history of resemblance: on what conditions was Classical thought able to reflect relations of similarity or equivalence between things, relations that would provide a foundation and a justification for their words, their classifications, their systems of exchange? What historical a priori provided the starting-point from which it was possible to define the great checkerboard of distinct identities established against the confused, undefined, faceless, and, as it were, indifferent background of differences?" — Michael Foucault
For more tangents between kernel functions and meaningful cognitive phenomena, I'll shamelessly plug some older writing of mine: dixit kernel functions and expecting unexpected ideas.
Outro
I'm sure there are more such high-level heuristics for optimizing the way of navigating optimization surfaces. The heuristics we've been endowed with by evolution might make for a fruitful place to look for more. This type of conceptual work is probably the most explicit form of direct optimization exerted by human researchers on trainers at the interface, their design choices guiding the nature of downstream optimization.
8 comments
Comments sorted by top scores.
comment by Garrett Baker (D0TheMath) · 2022-10-13T22:29:04.558Z · LW(p) · GW(p)
An important prior I think you missed is the circuit-complexity prior, which is different from the kologomorov simplicity prior. I also note that most of the high-level structures we see in the world (like humans, tables, trees, pully systems, etc.) seem like they're drawn from some kind of circuit-complexity-adjacent distribution over processes, where objects in systems we see in the world generally have a small number of low-dimensional interfaces between them. This connects to the natural abstraction hypothesis [? · GW].
Replies from: paulbricman↑ comment by Paul Bricman (paulbricman) · 2022-10-14T11:39:47.241Z · LW(p) · GW(p)
Thanks a lot for the reference, I haven't came across it before. Would you say that it focuses on gauging modularity?
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2022-10-14T18:26:38.478Z · LW(p) · GW(p)
I don’t know enough details about the circuit prior or the NAH to say confidentiality yes or no, but I’d lean no. Bicycles are more modular than addition, but if you feed in the quantum wave function representing a universe filled to the brim with bicycles versus an addition function, the circuit prior will likely say addition is more probable.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2022-10-14T18:29:07.909Z · LW(p) · GW(p)
But it would still be interesting to see work on whether a circuit complexity prior will induce more interpretable networks!
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2022-10-14T18:36:19.233Z · LW(p) · GW(p)
Another interesting note: If we’d like a prior such that the best search processes drawn from that prior themselves draw from the prior to resolve search queries, then whatever prior describes the distribution of high-level objects in our universe seems like it has this property.
ie. We can use approximately the same Ockham’s razor when analyzing human brains, and the objects they create, and the physical and chemical processes which produce human brains.
comment by Noosphere89 (sharmake-farah) · 2022-10-13T14:43:45.854Z · LW(p) · GW(p)
However, simplicity is not enough to e.g. select among all the possible objectives which might have explained the behavior of a human. Quite bluntly, Occam's razor is insufficient to infer the preferences of irrational agents. Humans (i.e. irrational agents) appear not to actually value the simplest thing which would explain their behavior. For another failure mode, consider the notion acausal attack highlighted by Vanessa Kossoy here, or in terms of the fact that the Solomonoff prior is malign. In this scenario, an AGI incentivized to keep it simple might conclude that the shortest explanation of how the universe works is "[The Great Old One] has been running all possible worlds based on all possible physics, including us." This inference might allegedly incentivize the AGI to defer to The Great Old One as its causal precursor, therefore missing us in the process. Entertaining related ideas with a sprinkle of anthropics has a tendency to get you into the unproductive state of wondering whether you're in the middle of a computation being run by a language model on another plane of existence which is being prompted to generate a John Wentworth post.
I feel a lot of the problem relates to an Extremal Goodhart effect, where in the popular imagination views simulations as not equivalent to reality.
However my guess is that simplicity, not speed or stability priors are the default.
Replies from: paulbricman↑ comment by Paul Bricman (paulbricman) · 2022-10-14T11:46:15.795Z · LW(p) · GW(p)
I feel a lot of the problem relates to an Extremal Goodhart effect, where in the popular imagination views simulations as not equivalent to reality.
That seems right, but aren't all those heuristics prone to Goodharting? If your prior distribution is extremely sharp and you barely update from it, it seems likely that you run into all those various failure modes.
However my guess is that simplicity, not speed or stability priors are the default.
Not sure what you mean by default here. Likely to be used, effective, or?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-10-14T12:48:44.803Z · LW(p) · GW(p)
I actually should focus on the circuit complexity prior, but my view is that due to the smallness of agents compared to reality, that they must generalize very well to new environments, which pushes in a simplicity direction.