Deception?! I ain’t got time for that!
post by Paul Colognese (paul-colognese) · 2022-07-18T00:06:15.274Z · LW · GW · 5 commentsContents
Introduction Using priors to help select good programs How speed priors disfavor deceptive programs Preamble Max speed prior and average-case speed prior (Average-case) speed priors disfavor misbehavior Implementing speed priors Proposal 0: Computational annealing (theoretical) Preamble The proposal Proposal 1: Limiting the neural network size Proposal 2: Pondering Proposal 2A Proposal 2B Proposal 3: Early-Exiting Thoughts on the proposals Training cost Jumps in computation Adapting existing training setups Additional hyperparameters Susceptibility to deceptive attacks Additional thoughts Speed priors might be favored for other reasons Excessive speed priors don’t generalize well The speed prior might favor deceptive programs under certain circumstances Checks for deception strengthen speed priors, and memory weakens them Simplicity prior for penalizing deceptive programs Measuring computation and penalizing it directly Parallel vs serial computation Conclusion None 5 comments
Or ... How penalizing computation used during training disfavors deception.
This post was written under Evan Hubinger’s direct guidance and mentorship, as a part of the Stanford Existential Risks Institute ML Alignment Theory Scholars (MATS) program [LW · GW].
Thanks to Evan Hubinger, Yonadav Shavit, and Arun Jose for helpful discussions and feedback.
Introduction
We want to use ML to produce “good” programs that perform well on some desired metrics and have some desired properties. Unfortunately, some programs that look good during, and at the end of the training, may not actually be good. This includes deceptive programs [LW · GW] that pretend to look good during the training process in order to pursue their own objectives later.
Because deceptive programs have to use computation on tasks like deceptive planning, modifying the ML training process to favor programs that use less computation may help prevent the selection of deceptive programs. A training process that favors such “fast programs” is said to have a speed prior/bias.
The aim of this post is to flesh out an argument for why training processes with speed priors may disfavor deceptive programs, and to consider how speed priors might be implemented in practice.
We begin by looking at how the priors/biases of a training process may be leveraged to help us select good programs rather than programs that just look good. Building [AF · GW] on [AF · GW] previous [AF · GW] work [AF · GW], we argue that speed priors may disfavor deceptive programs and more general forms of misbehavior. Next, we consider some potential implementations of speed priors before closing with some additional thoughts.
Using priors to help select good programs
An ML training process begins by initializing a space of programs (typically this space corresponds to the parameter space of a neural network) and then searches for a program that looks good to the training process, i.e., that seems to achieve good performance on the relevant metrics and have the desired properties. We can think of “looking good” as a constraint that programs must satisfy in order to be considered for selection.
One problem we face is that programs that look good, may not actually be good. For example, we may want a program that generalizes well to deployment inputs, but if the training process only measures performance on the training inputs, programs that look good to the training process may include programs that generalize well and those that don’t.
The training process may have priors/biases which means that among the programs that look good to the training process, the training process will usually favor selecting certain programs over others.[1]
The presence of priors/biases in the training process can help us find programs that are actually good despite just looking good. To see why this may be, we note that there is evidence [AF · GW] that today’s standard ML training processes have a simplicity prior/bias; they favor the simplest functions that fit the data. Simple functions that fit the training data tend to generalize well, partly because they are less likely to overfit. From this example, we see that the presence of a simplicity prior in the training process encourages the process to select programs that not only perform well on the training set (look good) but also generalize well (are actually good).
We note that constructing and analyzing priors that favor multiple desired metrics/properties may be very difficult, especially since some metrics/properties may be anti-correlated. For example, although simple functions tend to generalize well, simple programs may be more likely to be deceptive [AF · GW].
Taking the above discussion into account, the following approach may encourage the selection of good programs:
- Spend resources improving the capacity of the training process to measure the desired metrics and its capacity to check for the desired properties that we want our program to have.
- Identify an important metric/property we think our training process might have difficulty checking (e.g. generalization).
- Adjust the prior/bias of the training process to strongly favors this metric/property.
- (Optional) If it’s difficult to implement a prior for this metric/property, then implement a prior for a proxy metric/property instead (e.g. simplicity prior for generalization).
Since deception may be an extremely problematic and difficult property to check for (a deceptive program might be actively trying to manipulate the training process) it might be wise to implement a prior that disfavors deceptive programs. In the next section, we will look at how a “speed prior” might do just that.[2]
How speed priors disfavor deceptive programs
We present a high-level argument for why the presence of a speed prior disfavors deception and other more general forms of misbehavior. Furthermore, we discuss the difference between a max speed prior and an average-case speed prior and why the latter might be preferred.
Preamble
Throughout this post, we treat computation as a limited resource available to a program at runtime. For example, a program might “spend” all of its computation trying to achieve good performance on a given training task.[3]
We say that a program is a misbehaving program if there exists some input(s)/task(s) on which the program uses some of its computation misbehaving, where misbehavior could include things like: “scheming to take over the world”, “checking whether it (the program) is in deployment so it can take a treacherous turn”, or … “goofing off on the job”. We also insist that our definition of misbehavior excludes behavior that contributes to good performance on the evaluation metrics.[4] In particular, misbehavior includes deceptive actions, so a deceptive program is a kind of misbehaving program.
Max speed prior and average-case speed prior
We say that a training process has a max speed prior if given two programs of equal performance, the training process favors selecting the program with the least amount of computation available to use on any given input/task.
We say that a training process has an average-case speed prior if given a distribution of inputs/tasks and two programs of equal performance, the training process favors selecting the program that uses the least amount of average computation on that distribution.
At this stage the average-case speed prior may seem impractical to implement but things should become clearer in the next section. For now, we treat it abstractly.
(Average-case) speed priors disfavor misbehavior
By our definition of misbehavior at the start of this section, we see that the use of misbehavior during training increases the amount of computation used over the training distribution, hence misbehavior is penalized under the average-case speed prior[5] but not necessarily the max speed prior.
The trouble with a max speed prior is that it doesn't favor good programs over misbehaving programs that only misbehave when presented with inputs/tasks that require less computation than the maximum available. An average-case speed prior doesn’t have this problem because a program that misbehaves on these “easy” tasks increases the average amount of computation used on the distribution relative to the good program.
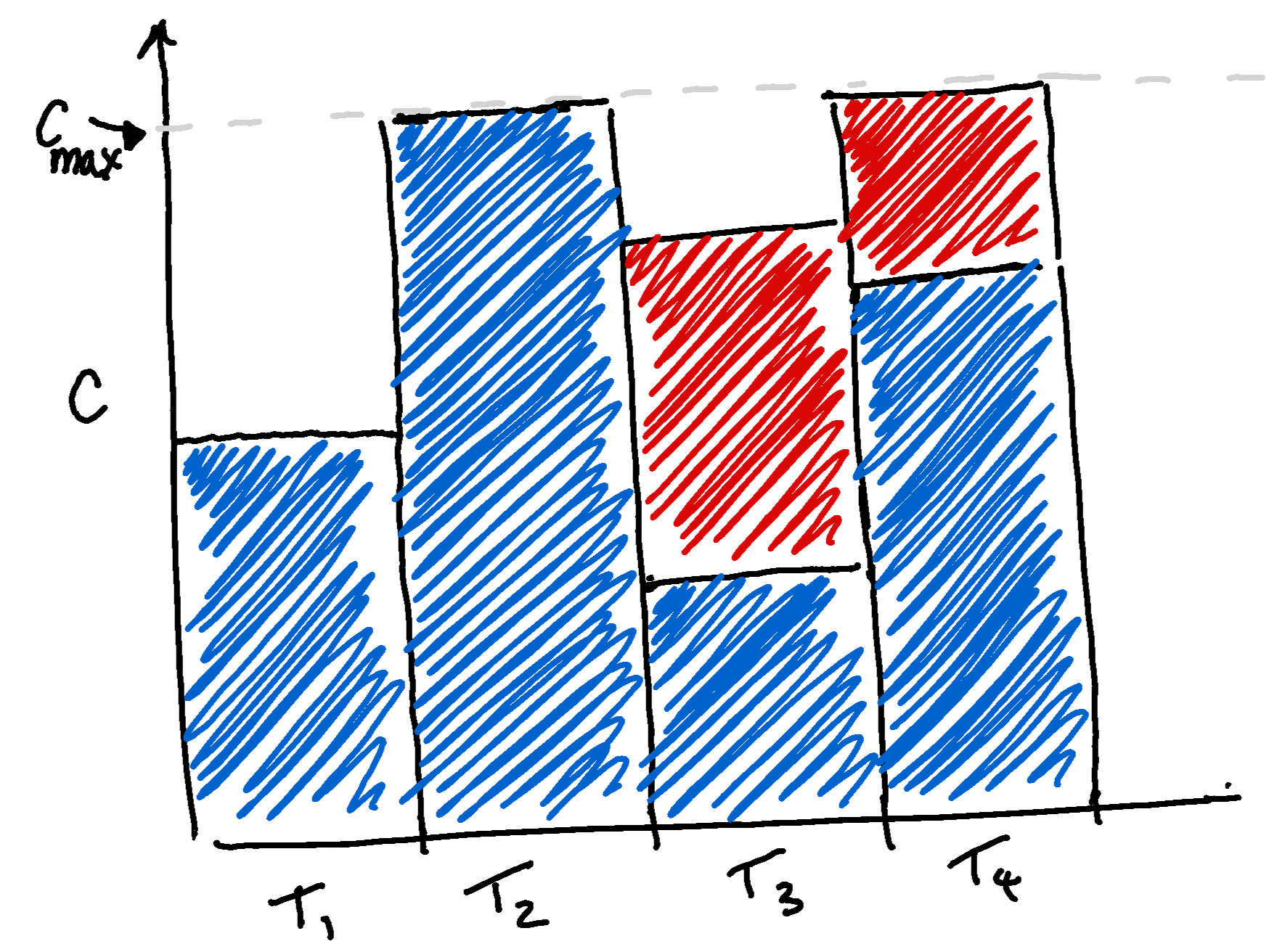
Bringing our attention back to deceptive programs, we can conclude with something like the following statement:
Deceptive programs [LW · GW] spend computation during the training process on tasks that don’t contribute to good performance, such as: making deceptive plans, checking whether they’re in deployment or not, and manipulating the training process. Consequently, they are less likely to be selected under a training process that has an (average-case) speed prior than a training process that does not.
Implementing speed priors
This section will look at some proposals for implementing speed priors in contemporary ML training.
There exist incentives for ML researchers to develop better methods for implementing speed priors because programs that perform a task quickly/with less computation are generally favored (they’re cheaper to implement, faster, etc.). Consequently, our goal is just to give some sense of what such implementations might look like rather than describe existing implementations in detail (however, we will reference a couple of these implementations in the later proposals).
We begin by looking at a theoretical proposal (Proposal 0) for implementing an average-case speed prior that will form the basis for the more practical proposals introduced later. We then introduce a crude proposal (Proposal 1) for implementing a max speed prior, partly to build intuitions used in the more practical proposals (Proposals 2 and 3). We conclude this section with some thoughts on Proposals 2 and 3.
Proposal 0: Computational annealing (theoretical)
We begin by looking at a theoretical proposal for implementing an average-case speed prior, and examine how this implementation favors the selection of programs that don’t misbehave.
Preamble
We fix a distribution of training tasks. The aim of our proposal is to select the program that achieves good performance with the least amount of average computation used over the distribution. We treat “good performance” as a binary condition but note that we can relax this restriction by iteratively applying the following proposal to more impressive performance milestones.
We make the reasonable assumption that the amount of computation a program spends on the training tasks is proportional to its performance on the training tasks. Furthermore, we note that from our definition of misbehavior, it follows that if a program misbehaves during the training process, it will need to spend more average computation on the training distribution.
The idea behind this proposal is that the program that achieves good performance with the least amount of average computation is less likely to have misbehaved.[6]
The proposal
Let denote the set of programs that spend at most average computation over the training distribution.
Fix to be small. We begin by searching for a program that achieves good performance. We then slowly increase while continuing our search on the now larger search spaces until we find such a program. If we increased slowly enough compared to the speed of our search process, the program we find will likely be the program that achieves good performance with the least amount of average computation (so consequently is less likely to have misbehaved).[7]
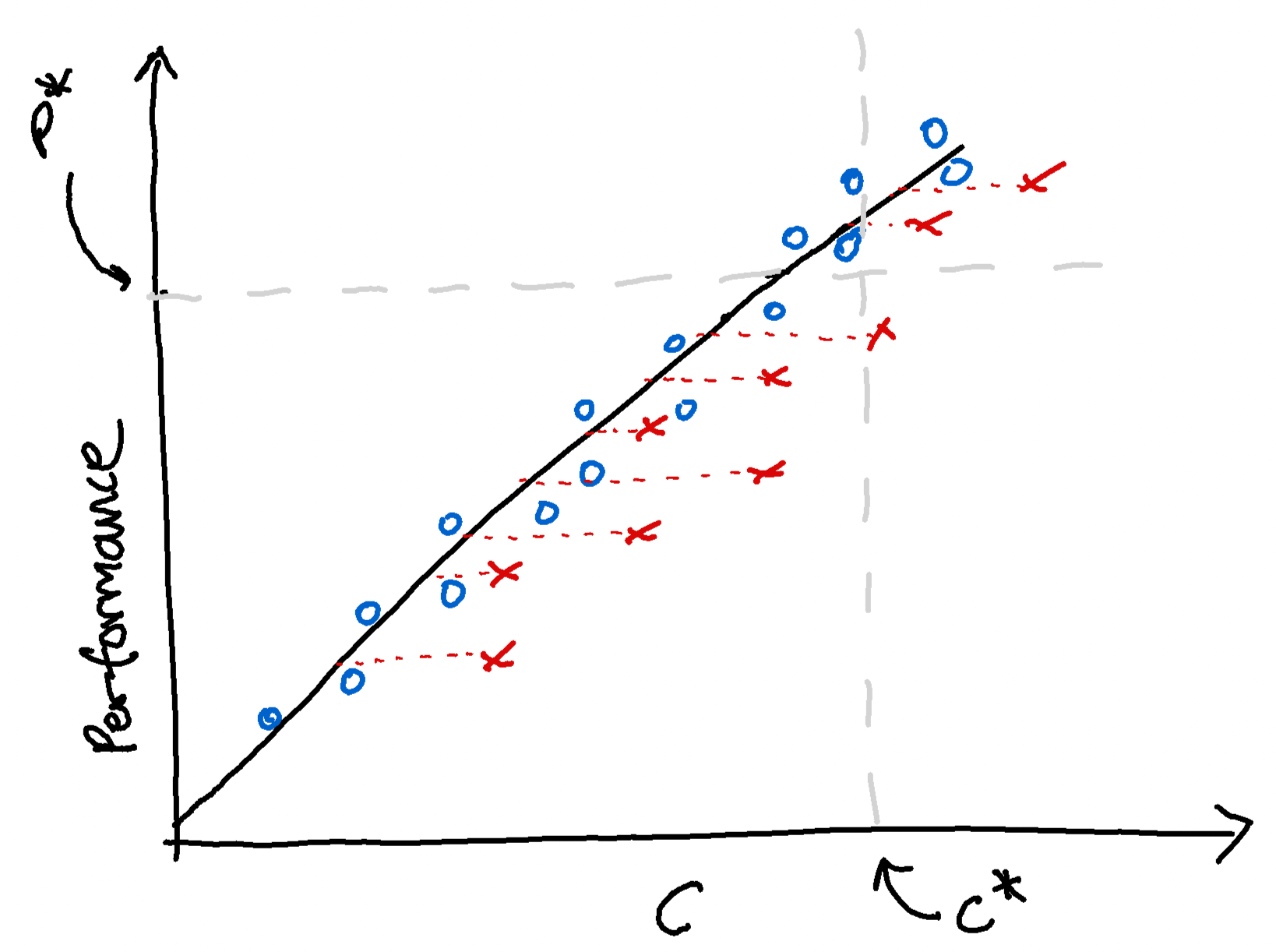
We can potentially increase the efficiency of this process by initially increasing relatively quickly, stopping when we find our first good-performing program, and then slowly decrease while continuing our search until we no longer find programs that achieve good performance. We could then begin to increase at an even slower rate until we begin to find good-performing programs again, and so on.
We will now look at some practical proposals.
Proposal 1: Limiting the neural network size
The size (number of parameters) of a neural network (NN) places hard limits on the amount of computation available to the model (see Scaling Laws [? · GW]). Therefore, using smaller NNs restricts the total amount of computation available to a NN-program.
We can use this observation to implement a max speed prior by using the following iterative procedure: start with a small NN and train it. If it achieves good performance, stop. If it does not, use a slightly larger NN and repeat.
This approach is clearly doomed because it’s extremely uncompetitive due to the need to spend resources on retraining.[8]
Proposal 2: Pondering
We can vary the amount of computation available to an NN-program for a task by giving it more time to “ponder”. This can be done by allowing it to use its maximum computation multiple times on a single task.
To implement this, we can allow a NN to use its output as part of its own input on another rollout. By training the NN in this way, it can learn to use its output as a scratchpad to store any results that it may find useful on subsequent rollouts. This way the amount of computation the NN-program gets to use on a task is proportional to its size multiplied by the cumulative length of all the rollouts it uses. It has been shown that one can improve the performance of language models on certain tasks by using chain of thought prompting, a similar idea.
We sketch two proposals that use pondering to implement a speed prior. Proposal 2A, first outlined here [LW · GW], gives a max speed prior but is far more competitive than the previous proposal. Proposal 2B is a slightly modified version of Proposal 2A but implements an average-case speed prior (Proposal 2B seems similar to PonderNet).
Proposal 2A
We fix some NN architecture and fix some initial number of rollouts, . We then proceed to train the NN while it uses rollouts per task. We then continue to train the NN as we slowly increase the number of rollouts being used until we get sufficiently good performance.
This proposal allows us to find the minimum number of rollouts (the smallest amount of computation) needed to get good performance, which implements a coarse version of a max speed prior (this coarseness will be explored in the discussion at the end of this section).
Proposal 2B
This proposal is the same as Proposal 2A, except we train a separate model to predict the minimum number of rollouts the original NN-program needs to achieve good performance on a given task, which gives us an average-case speed prior.
Alternatively, we could penalize the NN-program for using a larger number of average rollouts across its training tasks.
Proposal 3: Early-Exiting
Early-Exiting is a proposal that allows a NN to produce outputs earlier than it would otherwise. The main idea is relatively simple:
Fix any NN. Instead of having one output layer at the end of the NN, we attach an output layer to each/some hidden layers. We then encourage the network to produce outputs in earlier layers by modifying the loss function appropriately.
The key idea is that this encourages the NN to use the smallest sub-network possible to solve a given task, i.e., the minimum computation needed to solve a given task. This gives us an implementation of an average-case speed prior.
Thoughts on the proposals
We will now discuss some aspects of the previous two proposals.
Training cost
Pondering requires a relatively small training cost because we’re training one relatively small NN that can leverage rollouts to access arbitrary amounts of computation. Early-Exiting seems to require a slight additional training cost to the standard training process that doesn’t implement a speed prior.
Jumps in computation
For Pondering, the jumps in computation available as we increase the number of rollouts are proportional to the NN's size. If the NN is too large, the jump in computation may increase the chance that the search process finds a misbehaving program before an intermediate program capable of good performance without misbehaving. However, if the model is too small, it may be incapable of learning to perform well on certain tasks no matter how many rollouts we use. Early-Exiting can achieve a much smaller jump in computation by adding output layers to each hidden layer and even output layers to smaller sub-networks.
Adapting existing training setups
It seems easy to modify any training setup to include Early-Exiting but Pondering requires using a smaller NN than would be otherwise used.
Additional hyperparameters
Early-Exiting requires the designer of the training process to decide by how much should later outputs in the NN be penalized. If they are penalized by too little, we don’t get the average-case speed prior; if they penalize by too much, the model may be discouraged from using the necessary amount of computation for a task. To remedy this, one could slowly reduce the penalty for later outputs until satisfactory performance is achieved, but then we have to deal with another hyperparameter in training.
Susceptibility to deceptive attacks
An already deceptive program might be able to manipulate the Early-Exiting setup by sabotaging earlier stages of its computation to give it more “time to think” (e.g. by refusing to think about a key detail until all the other details have been figured out).
For the second Pondering proposal, it may be advisable to train the predictive model offline to avoid it being manipulated by a deceptive NN-program into giving it more computation than it needs for the task.
Additional thoughts
Speed priors might be favored for other reasons
In the previous section, we mentioned that ML researchers are already researching how to implement speed priors. This is because there seems to be a bias toward using less computation in applications: slow programs could be uncompetitive and using unnecessary computation could be costly. Consequently, if speed priors do indeed disfavor deceptive models, AI labs might not need much convincing to implement them compared to more costly alignment interventions.
Excessive speed priors don’t generalize well
Programs that use the least amount of computation to perform well on training tasks might look like a lookup table that doesn’t generalize [LW · GW]. Rather than give up on the anti-deceptive properties of speed priors, perhaps this problem can be overcome by including checks for generalization during training, e.g., testing how well the program generalizes to various test distributions. Such a training process with a speed prior would favor models that use less computation but still generalize. Given how problematic deceptive models could be, it seems like we shouldn’t give up on the speed prior if there exist alternative ways of selecting for generalization.
The speed prior might favor deceptive programs under certain circumstances
It might be the case that the fastest program that achieves good performance is deceptive [AF · GW]. This might occur if the fastest way to solve a task is to implement a search process that favors deceptive models and this search process doesn’t consider a sufficiently diverse search space. I believe this is unlikely due to the arguments presented here [AF · GW] but it's worth bearing in mind.
Checks for deception strengthen speed priors, and memory weakens them
Checks for deception during the training process will likely force deceptive programs to spend extra computation on avoiding the checks, hence checks strengthen the anti-deceptive effect of speed priors. Conversely, it has been [AF · GW] noted [AF · GW] that if a program is capable of memorization, or even worse, cross-episode memory, then information that helps with deception can be stored for repeated use without having to spend computation rederiving that information.
Simplicity prior for penalizing deceptive programs
We note that despite having said earlier that simplicity priors might favor deception, being deceptive might add additional complexity to the program. This could occur [LW · GW] if the program has an encoded subroutine that checks whether it’s in deployment or not. Hence certain forms of deception might be penalized under the (default) simplicity prior.
Measuring computation and penalizing it directly
Two NN-programs with the same NN architecture might have access to different amounts of computation (one might have a small optimization module but many “hardcoded” features and hence less available computation). With better interpretability tools, measuring the amount of computation a program uses on tasks might be possible so we could optimize for fast programs directly.
Parallel vs serial computation
It seems plausible [LW · GW] that deeper NNs have more serial computation available to them and that wider NNs can perform more parallel computations. This might be worth considering if we treat fast programs as those that use less serial computation but we fail to consider parallel computation and consequently miss parallel processes dedicated to deceptive tasks.
Conclusion
We have argued that a training process with an average-case speed prior disfavors programs that spend computation on deceptive behavior.
We have seen how an average-case speed prior might be implemented in practice and noted that AI labs might be incentivized to use it irrespective of safety concerns because of competitiveness benefits.
In order to help avoid producing deceptive programs, perhaps safety-concerned AI labs should spend their resources making the training process as capable of checking for deception as they can (via transparency tools, [AF · GW] etc.), and when they inevitably say “fuck it, we’ve done all we can”, apply a speed prior and pray that it takes care of any deceptive programs that the checks couldn’t catch.
- ^
In this post, I'll assume that the outcomes of local search processes like SGD have low dependence on the search process's specific path. This assumption will be reflected in the analysis. It has the benefit of simplifying the analysis but possibly misses other considerations. We note that some empirical evidence [AF · GW] favors the low-path dependence view. Nonetheless, I still think speed priors will be favorable in high-path dependence worlds.
- ^
Because ML training processes already have a simplicity prior, we can’t implement a “pure” speed prior in practice. For simplicity, we ignore the presence of simplicity priors in training processes throughout this post and just focus on the effect of introducing an additional speed prior. See this post [LW · GW] for a more detailed discussion of their interaction.
- ^
We work at this high level to avoid the subtleties of deciding which notion of computation will be most relevant in practice. We will be slightly more concrete when considering practical implementations.
- ^
This is partly to ensure that our argument holds but also seems like a natural assumption; misbehavior that contributes to good performance suggests that our performance metric is flawed.
- ^
Importantly, this does not imply that non-misbehaving programs will have the lowest chance of being selected under a speed prior. For example, if the search space of programs isn’t sufficiently diverse, it might be the case that despite being penalized, the program that gets good performance on a given input/task with the least computation might still do so while misbehaving. We’d hope that our search space is diverse enough to contain “honest” programs that get good performance without ever misbehaving.
- ^
We note that it is not guaranteed [LW · GW] that such a program doesn’t misbehave. One hope is that our search space is sufficiently diverse, in which case, for every misbehaving program there exists a corresponding “honest” program in our search space that spends its computation in the same way that the misbehaving program does, except it does nothing instead of misbehaving.
- ^
The process seems somewhat analogous to annealing in metallurgy.
- ^
It may also put the program on the interpolation threshold of the double descent phenomenon [AF · GW], which results in poor generalization. We discuss how we might overcome this in the Additional Thoughts section of this post.
5 comments
Comments sorted by top scores.
comment by james.lucassen · 2022-07-18T04:25:38.945Z · LW(p) · GW(p)
Nice post!
perhaps this problem can be overcome by including checks for generalization during training, i.e., testing how well the program generalizes to various test distributions.
I don't think this gets at the core difficulty of speed priors not generalizing well. Let's we generate a bunch of lookup-table-ish things according to the speed prior, and then reject all the ones that don't generalize to our testing set. The majority of the models that pass our check are going to be basically the same as the rest, plus whatever modification that causes them to pass with is most probable on the speed prior, i.e. the minimum number of additional entries in the lookup table to pass the training set.
Here's maybe an argument that the generalization/deception tradeoff is unavoidable: according to the Mingard et al. picture of why neural nets generalize, it's basically just that they are cheap approximations of rejection sampling with a simplicity prior. This generalizes by relying on the fact that reality is, in fact, simplicity biased - it's just Ockham's razor. On this picture of things, neural nets generalize exactly to the extent that they approximate a simplicity prior, and so any attempt to sample according to an alternative prior will lose generalization ability as it gets "further" from the True Distribution of the World.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-07-18T07:14:01.948Z · LW(p) · GW(p)
I think this is a little bit off. The world doesn't have a True Distribution, it's just the world. A more careful treatment would involve talking about why we expect Solomonoff induction to work well, why the speed prior (as in universal search prior) also works in theory, and what you think might be different in practice (e.g. if you're actually constructing a program with gradient descent using something like "description length" or "runtime" as a loss).
comment by Jan_Kulveit · 2022-07-18T07:38:15.113Z · LW(p) · GW(p)
When mentioning prior work, it may good to include Eric Drexler's MDL Intelligence Distillation (from 2015) proposing the idea to use description length to split "pure learning capabilities" (low length) from all sorts of undesired behavior.
Description length has some advantages over speed - also "limiting neural net size" is actually more of a distillation based on description length than "speed".
(My personal guess for how to make stuff bounded would be penalize bitflips)
comment by Charlie Steiner · 2022-07-18T06:14:02.153Z · LW(p) · GW(p)
Any bright ideas on what to do when calculating the human's inferred preferences is comparable in size to using a simple objective plus instrumental calculations?
Replies from: not-relevant↑ comment by Not Relevant (not-relevant) · 2022-07-18T14:22:17.079Z · LW(p) · GW(p)
Something I’ve been confused about re: this argument is, aren’t instrumental calculations to rederive a human objective at minimum as expensive as just encoding the human’s objective directly, especially in the presence of a speed prior?