Toward Safety Case Inspired Basic Research
post by Lucas Teixeira, Lauren Greenspan (LaurenGreenspan), Dmitry Vaintrob (dmitry-vaintrob), Eric Winsor (EricWinsor) · 2024-10-31T23:06:32.854Z · LW · GW · 3 commentsContents
Abstract Introduction: Applied & Basic Research in AI Safety Safety Cases: An Applied Science Artifact Use-Inspired Basic Research and Safety Case Trading Zones Safety Cases as Boundary Objects Laying the Groundwork for Trading with Basic Research Future Work Acknowledgments None 3 comments
Abstract
AI safety is a young science. In its early history, deep and speculative questions regarding the risks of artificial superintelligence attracted the attention of basic science and philosophy, but the near-horizon focus of industry and governance, coupled with shorter safety timelines, means that applied science is now taking a bigger hand in the field’s future. As the science of AI safety matures, it is critical to establish a research tradition that balances the need for foundational understanding with the demand for relevance to practical applications. We claim that “use-inspired basic research” – which grounds basic science with a clear-cut purpose – strikes a good balance between pragmatism and rigor that will ensure the solid foundations, flexibility, and utility appropriate for a problem of this scope and magnitude.
In this post, we build on the established concept of ‘safety cases’ to elevate the role of basic research in AI safety and argue for more balanced collaborations with industry and governance. In spite of their importance for AI safety, we stress that, given limits to our present-day understanding and methods, it is not currently possible for applied scientists to make a safety case for sufficiently advanced AI systems with correspondingly high risks; while aspirational, robust safety cases are hypothetical objects. We advocate for a holistic approach to AI safety research that intentionally coordinates the efforts of basic scientists and applied scientists and propose the beginnings of a framework for collaboration that can direct the field toward use-inspired research that will help us construct safety cases in the future.
Introduction: Applied & Basic Research in AI Safety
AI Safety is a burgeoning field of study whose general aim is to make AI systems safe and beneficial to both individual users and humanity at large. It has historically spanned a spectrum of topics and methodologies, but for our discussion, we find it convenient to split AI safety into two different arms: applied and basic.[1]
Generally, these approaches differ in terms of their research goals and methods of problem-solving. Applied research aims to solve application-inspired challenges with a pragmatic approach built on immediate, focused solutions that may not apply out of scope. Examples of applied AI safety include alignment capabilities research such as innovation of novel feedback mechanisms (e.g. RLHF, PHF, DPO), or technical governance work such as black box evaluations.
In contrast, the goals of basic research may be open-ended or long-horizon. Instead of seeking solutions, it seeks knowledge through the development of theoretical and empirical foundations. Examples of basic AI safety include work in classical Agent Foundations such as Factored Space Models [LW · GW], the Natural Abstraction Hypothesis [LW · GW], and the Learning Theoretic Agenda [LW · GW], as well as work empirically grounded in present-day systems such as the superposition hypothesis, scaling laws, Singular Learning Theory [? · GW], and Computational Mechanics [? · GW].
Efforts to keep up with advancements in generative AI have led to an influx of applied safety research organized by both government and industry. Governments are motivated to implement regulation and auditing schemes as quickly as possible with the methods at hand for the models at hand. Meanwhile, to remain competitive industry labs need to build AI systems that are both “capable enough” to meet consumer needs and “safe enough” to avoid negative attention from the public. As a result, they invest large shares of their R&D budgets into pragmatic research projects with quick turnaround times and minimal safety checks which can deliver measurable economic returns. However, black box evaluations and applied science – the only viable options given our current understanding and methodologies – are limited in what they can offer in terms of safety guarantees. In particular, they do not provide the depth of understanding or breadth of evidence necessary for principled safety arguments of powerful AI systems.
The rest of this post is structured according to three hierarchical aims. Our most expansive goal is to build a science of AI safety capable of rigorously evaluating AI systems as they become more advanced. In the section Safety Cases: An Applied Science Artifact, we draw on safety cases to support this goal. These are structured arguments, originally introduced by Clymer et al. used to guide government standards composed of applied science metrics for estimating technological risks. In AI safety, there is currently no cohesive scientific framework with which to construct these arguments, leading to a situation similar to trying to estimate the risk of a nuclear reactor without an understanding of nuclear physics. Without incorporating more basic science, we argue that AI safety lacks the substance, rigor, and strength necessary for a compelling safety case.
In an effort to construct stronger safety cases, our secondary aim is to push the science of AI safety toward firmer ground by promoting more use-inspired basic research (UIBR). In the section Use Inspired Basic Research and Safety Case Trading Zones, we motivate trading zones as a way to frame collaborations between basic science, applied science, and governance that will lead to UIBR with a safety case as its use-inspiration.
In the section Laying the Groundwork for Trading with Basic Research, we discuss ways of encouraging collaboration with different communities within basic science, by either making basic research more legible to applied scientists or better orienting it to the wants and needs of the AI safety community. We propose the need for greater community interventions to this end and lay out our own directions for future work.
Safety Cases: An Applied Science Artifact
To date, government requirements for auditing advanced AI systems have been imprecise, leading to a confused understanding of AI’s risks, where they come from, and how developers are responsible for controlling them. SB-1047, a recently proposed (and more recently vetoed)[2] bill in California, asks AI developers to demonstrate “positive safety determination” that “excludes hazardous capabilities”, while providing little insight as to what exactly constitutes a “hazardous capability” or conditions for positive determination.
This dearth of technical specification has brought the notion of Safety Cases to the attention of the AI Safety Community. According to the UK Ministry of Defence, a safety case is a "structured argument, supported by a body of evidence, that provides a compelling, comprehensible, and valid case that a system is safe for a given application in a given environment."
As an example of a safety case based on a mature science with adequate foundations, we’ll look at how risk assessment is conducted in nuclear power plant regulation. As a regulatory standard, the US Nuclear Regulatory Commission (NRC) specifies that nuclear engineers must show that new reactor designs have a theoretical core damage frequency of under 1 in 10,000 per year. The NRC has also published a range of guidelines for how to carry out risk assessment, most notably NUREG/CR-2300.
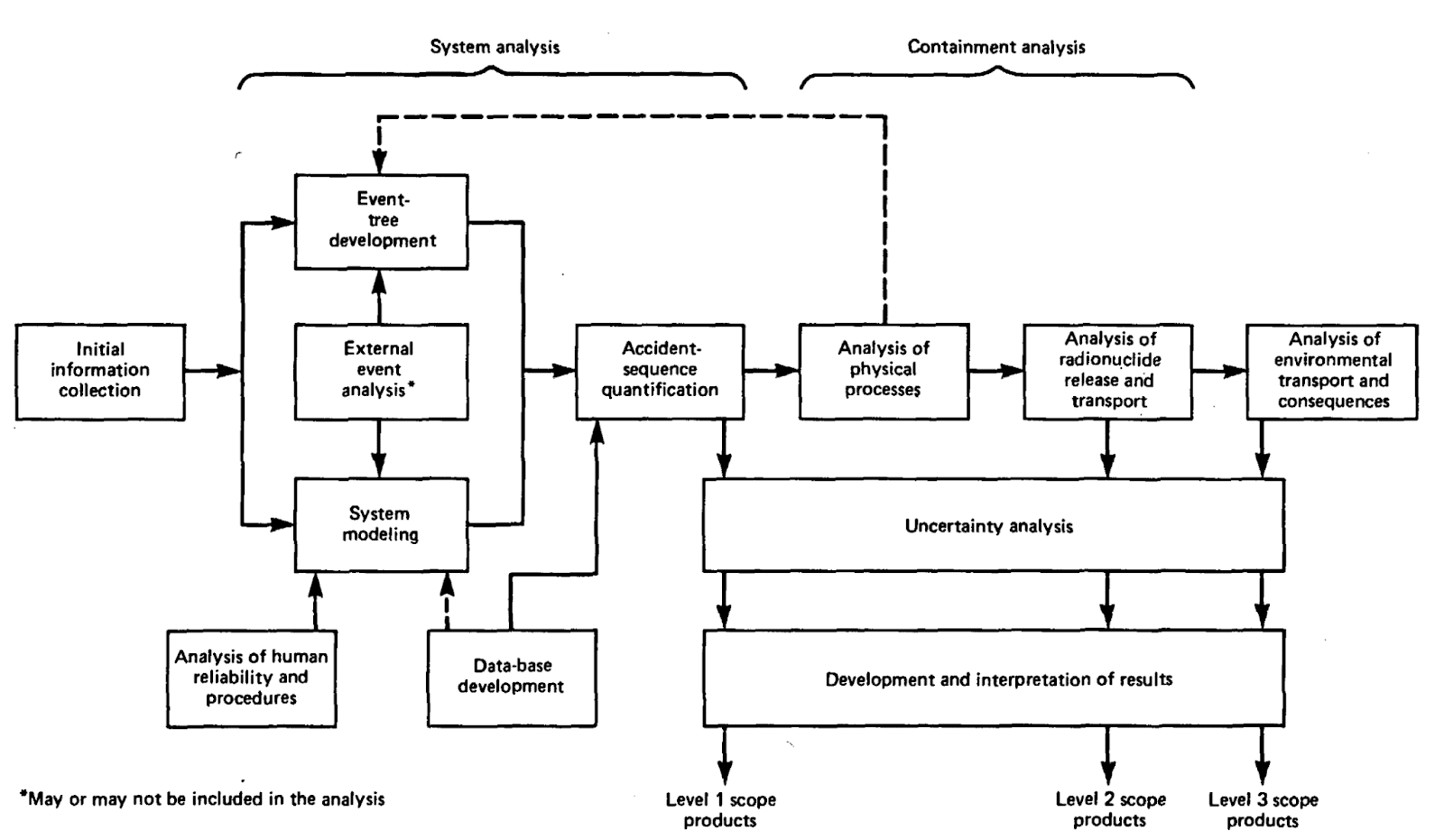
To summarize NUREG/CR-2300, developers and regulators will develop a safety case of a nuclear reactor via a probabilistic risk assessment routed through the nodes of the above flow chart (system modeling, event-tree development, accident-sequence quantification, uncertainty analysis, etc...) to design a safety metric unique to that system, for example that the frequency of fatalities and core damage are below an acceptable threshold. Importantly, the PRA Guide also details the acceptable analytical techniques, valid assumptions and approximations, standards for documentation, and criteria for assuring technical quality for each step of the procedure.
In the realm of AI Safety, there is growing interest to develop the analogue to NUREG/CR-2300 for AI. A preliminary framework has been proposed (Clymer et al.) which lays out safety-case argument structures for risks associated with hierarchical classes of AI system safety properties. These classes include their inability to perform tasks, their ability to be reliably controlled, or their trustworthiness. Similarly, Towards Guaranteed Safe AI outlines an agenda for constructing high-assurance quantitative safety cases based on a world model of the deployment environment, safety specifications over that world model, and a verifier of these safety specifications.
Unfortunately, progress on constructing substantive safety cases is bottlenecked by the absence of a mature basic science which could, in the future, support system modeling with well founded assumptions and quantifiable uncertainty. We aim to build up the scientific foundation that would allow for a more precise analogy between AI safety cases and those being made for other areas with potentially catastrophic consequences. Just as nuclear safety cases depend on a foundation in the physical sciences for their risk analysis, we aim to develop a science of AI which could serve as a foundation for AI Safety Cases and corresponding evaluation methods.
Use-Inspired Basic Research and Safety Case Trading Zones
In his 1997 book "Pasteur's Quadrant: Basic Science and Technological Innovation", Donald Stokes studies how basic science (curiosity-driven and knowledge-seeking) and applied science (practical problem-solving) contribute to scientific progress and concludes that assigning too much meaning to the distinction between them can impede progress by setting them up as competing rather than complementary methods of investigation. As an alternative, he aims to put their most productive assets to work by highlighting examples of basic research with a particular drive to benefit society, which he calls Use-Inspired Basic Research (UIBR). Moreover, he calls for governments to support UIBR to increase science’s potential for societal impact.
History points to several groundbreaking results of UIBR. For example, Louis Pasteur’s work relating microorganisms to germs was driven both by a desire to understand fundamental biological processes (basic science) and to solve practical puzzles related to public health (the use-inspiration, or applied science). Similarly, Maxwell’s theoretical work on electromagnetism was motivated by the need to engineer better transmission cables, laying the groundwork for radio and telecommunications. As a final example, Shannon’s development of information theory at Bell Labs was pragmatically motivated by wartime incentives to secure lines of internal communication, which later helped formalize cryptography.
We believe that basic science has the potential to make similar contributions to the practical issues in AI safety, and that adopting research practices aligned with UIBR will brace it for real-world impact. We believe UIBR is a way to encourage AI safety foundations that are both robust and pragmatic – relevant, but unconstrained by short-term applications. In an effort to establish rigorous safety assurances for current and future AI systems, we argue for the creation of a future safety case as a use-inspiration to guide basic research in the science of AI. In the next section, we contextualize safety cases as central objects in AI safety research collaborations.
Safety Cases as Boundary Objects
Given its location at the intersection of multiple different areas of expertise, we claim that a safety case can be thought of as a boundary object mediating a collaboration in the trading zone of AI safety. A trading zone is an analytical framework from the field of STS (Science Technology and Society) initially conceptualized by Galison (see Image and Logic, Material Culture) to describe the development and progress of collaborations between different scientific cultures[3]. Importantly, these are flexible ‘spaces’ that form as local, dynamic intersections between fields while allowing their respective cultures to remain globally distinct.
To ground this discussion, consider the development of radio transmitters during World War II (Galison), which coordinated the exchange of ideas between theoretical physicists and radio engineers, with added pressure and input from the allied forces[4]. In this example, the radio transmitter was a boundary object at the trading zone between these fields – it facilitated the trading of information between subcultures for a locally agreed upon purpose. As such, the transmitter was a concept that was both sufficiently flexible to adapt to the needs of each individual culture, and robust enough to bring the cultures together at the trading zone. This allowed each subculture to attach its own meaning to the boundary object according to its tastes and expertise. To physicists, it was an application for electrodynamic theory, for radio engineers, an input/output design problem, and from a government standpoint, an essential object for wartime success.
In general these scientific cultures are, in a sense, incommensurate, and each comes with its own well-developed disciplinary identity expressed by its epistemological values and goals. At the trading zone, they are nevertheless able to engage in meaningful collaboration mediated by the boundary object. In the above example, material insights were traded from theoretical physics to guide the microwave circuit design of the engineers, giving them a new set of tools to work with. On the other hand, some of the engineers’ pragmatic, input/output approach to science was subsequently imported into the physicists’ way of thinking. This persisted after the war, making its way into the particle physics subcultural identity and impacting the development of quantum electrodynamics. This depicts one possible outcome of a trading zone between disciplinary groups with wildly different scientific cultures who are coerced into trade for a high-stakes purpose. In this case, each subculture remained distinct, but gained valuable information that changed its shape in meaningful ways.
Sometimes, trading zones can forge stronger collaborations that evolve into new scientific cultures. For example, string theory, as a field distinct from theoretical particle physics, formed from competition between physics and math, which used different methods to calculate a boundary object (in this case, a particular number) that carried different meanings to each field. At first, their answers didn’t match, leading to a need for mutual validation of their respective methods. What started with a narrow trade developed into a stronger collaboration to understand the deep connections between their interpretations, and led to the slow evolution of string theory with a blended subcultural identity that transcended physics and math. This example illustrates how trading zones can develop local ‘inter-languages’ between subcultures that allow them to communicate. These can be simple dictionaries of relevant jargon or equivalent to pidgins or creoles[5], depending on the breadth, scope, and fortitude of the trade. Moreover, inter-languages can evolve as collaborations do; string theory co-developed with a creole language that ultimately signaled its autonomy as a scientific culture.
In the previous section, we drew from history to suggest that the principles of UIBR centered around safety cases can guide AI safety toward meaningful progress in the more rigorous evaluation of AI systems. We now add that this UIBR culture can be encouraged by setting the conditions for trading zones between basic science, applied science, and governance[6]. Moreover, we think that, as boundary objects, safety cases have the potential to mediate productive engagement between these groups without them having to a priori speak the same language. We hope that this will encourage more participation from basic science[7], even from groups without previous exposure to AI safety. In the final section, we consider possible trading scenarios in more detail.
Below, we sketch the overall shape of this trading zone and the role we think each group will play.
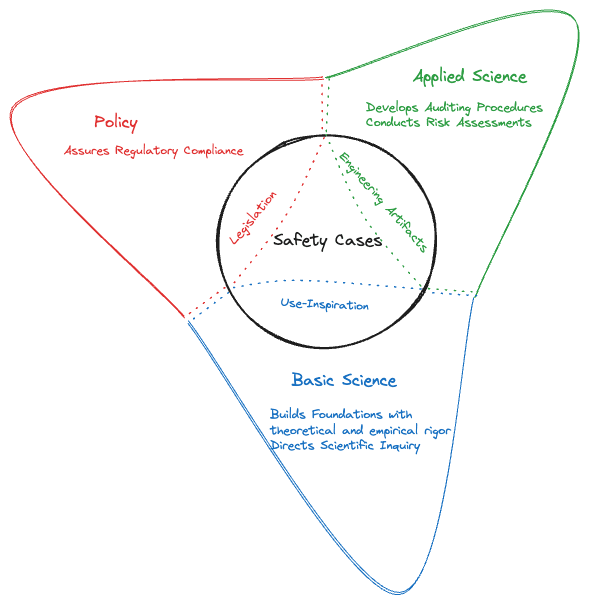
For applied science, the boundary object is seen as the artifact we set up in Safety Cases: An Applied Science Artifact section. Applied scientists must use current scientific understanding of AI systems to design and construct evaluations to build positive safety cases. This involves utilizing any established theory for, or running experiments on, engineering artifacts from various phases of the AI system’s development lifecycle (i.e. API access, architecture, training hyperparameters, checkpoints, activations across inference, model weights, etc…). When collaborating with AI governance, applied scientists can take on different roles, including identifying the system artifacts needed to support the claims of a safety case so that policymakers can establish regulations and standards and enforce industry compliance, and communicating results of safety evaluations. When collaborating with basic researchers, applied scientists will depend on basic research to discover the underlying foundational principles upon which their auditing methods are built, which will enable them to better stress test their assumptions, calibrate or quantify their uncertainty, or critique their methods. A deeper understanding can lead to the development of new tools, infrastructure, and methodologies to support applied science research efforts.
For basic research, on the other hand, the boundary object is a use-inspiration – an impactful application that can guide their exploration by identifying knowledge gaps, generating research questions, and designing targeted experiments to validate theoretical insights. The path of exploration is rooted in the traditions of a respective scientific practice, which we don’t specify or restrict. Basic researchers would gain valuable insight by understanding the key research challenges applied scientists face. Moreover, they can use this information, in addition to feedback from the governance community, to further calibrate their use-inspiration. We leave the details of the safety cases that serve as this use-inspiration for future work.
Policy makers will see the boundary object as an element of legislation; they need to have a set of standards from applied scientists that they can put into law. Similarly, regulators tasked with assuring compliance need to sufficiently understand the argument structure and technical quality of the methods by which the safety case is being constructed.
The main claim of UIBR is that a use-inspiration can help contextualize basic research to assure its positive societal impact. Additionally, we defend a stronger argument for UIBR: that a carefully constructed use-inspiration can have a positive effect on the way in which research is conducted, independent of its impact to society. We are optimistic that interactions at the trading zone we laid out will lead applied and basic science to share their respective epistemic virtues in building out a science of AI safety capable of meeting the demands of future safety cases. Specifically, virtues gleaned from our initial distinction between applied research (concreteness) and basic research (rigor) can be traded via appropriate desiderata on the boundary object. Calling back to our earlier example of the nuclear reactor, we can roughly map properties of higher assurance safety cases with corresponding virtues of basic science. For example, a safety case that is adaptable across diverse deployment contexts can be addressed with more general foundations. Similarly, calling for coverage of black swan events aligns with basic science’s instinct to engage with unknown unknowns. Finally, calling for sensitivity analysis aligns with basic science’s desire for greater legibility over assumptions, idealizations, as well as strict demarcations over domains of application.
Laying the Groundwork for Trading with Basic Research
Before any trading can begin, it may be necessary to establish a certain level of mutual understanding required for collaboration at the trading zone. In this section, we consider basic research with the potential to make an outsized impact on future safety cases to vary in terms of the legibility of its relevance to applied science and its orientation to AI safety.
For legible basic science that is oriented, applied scientists will be able to immediately understand the safety relevance of the work, and information can be traded freely and naturally. We see much of mechanistic interpretability as a prototypical example of this category.
Work that is illegible may fail to communicate its relevance, even if it is oriented. Agent foundations is one example of a research program that is expressly interested in and actively addressing safety concerns, but in a way that is disjoint from present-day applications and in a language that is largely opaque to applied scientists with more immediate goals. Given this obscure relevance, we anticipate the need for translations and distillations to make this class of research more legible to applied science and make it easier for basic science to trade relevant information.
We also consider basic research that is neither legible nor oriented to safety. Examples of this class come from other disciplines such as neuroscience or physics. A particular case is computational mechanics before outside interventions that demonstrated its relevance to mechanistic interpretability. In addition to legibility issues similar to those mentioned in the previous paragraph, the lack of orientation leads to two potential failure cases. If they have no orientation to AI and its safety concerns, specialists in these domains and the AI safety community could remain unaware of one another, making collaboration a nonstarter. Secondly, without the proper introduction to AI safety and familiarity with its needs, researchers from this camp could adopt poor orientation, leading to an impact that is at best diminished and at worst negative (i.e. by inadvertently contributing to capabilities). These possible issues indicate a need for more targeted interventions such as research scouting and directed support for established basic researchers to provide them with a focused orientation to safety cases and most efficiently get them up to speed.
We acknowledge that, as a general directive, we cannot predict exactly where using safety cases as use-inspirations will lead basic science. Initial investigations, while pointed in a well-specified general direction, could veer off into the ‘blue sky’. As research failures often provide valuable insights, we think this could result in positive gains for the overall science of AI safety. The ‘use’ of UIBR is, after all, an ‘inspiration’ rather than precise recipe; we consider the ability to ‘follow your nose’ to be a positive attribute of basic science and encourage exploration into unexplored regions of possible safety cases.
Nevertheless, in the best-case scenario, we see safety cases as igniting a research cycle between applied and basic science, through which insights from basic scientific inquiry drive progress on the open questions of applied science, so that it can formulate more rigorous and complete safety cases, which will, in turn, provide basic science with more explicit safety relevance and increasing legibility. Our hope is that this feedback loop will make communication and collaboration at the trading zone iteratively easier for all parties, and establish an AI safety research culture predicated on UIBR able to create stronger safety cases.
Future Work
In the near future, we aim to further develop the infrastructure for the trading zones laid out in this post by building on the idea of a safety case sketch as defined by Geoffrey Irving to better interface with our goal of facilitating UIBR in AI Safety. This would involve contextualizing applied science’s current inability to construct high-assurance safety cases via an identification of gaps in fundamental knowledge which can be treated as open problems in basic research. We hope that this will result in concrete ways to reason about use-inspiration for basic science in AI safety and lead to new directions for research.
Acknowledgments
Thanks to Mike X Cohen (who was involved in the beginning of this project and contributed many useful ideas), Nora Ammann, Dušan Nešić, Ben Goldhaber, Logan Riggs Smith, Laurel Stephenson Haskins, Jake Mendel, Kaarel Hänni, Louis Jaburi, Evan Ryan Gunter, Joseph Bloom and everyone else who gave feedback and participated in motivated discussions.
- ^
We stress that this distinction is a useful fiction, it points to a generally coherent separation of research cultures that will help us address gaps that need to be filled. In reality, a lot of work fits both categories or falls somewhere between them. We also assume that these two methodological approaches are largely independent of tools and methods. For many scientific fields, particularly those with a large computing component, it is necessary to engineer narrow experiments to support a theory or use a theoretical insight for a particular application. To perform experiments, applied and basic research may also pull from a common set of tools and techniques (e.g. mechanistic interpretability). In light of this ambiguity, it is often convenient to categorize work in terms of individual research projects instead of at the level of institutions, research agendas, or departments, and reiterate the focus of our distinction on the different intentions and metascientific approaches to problem-solving detailed in the body.
- ^
The bill’s vague language is independent of its association of risk with size rather than dangerous capabilities, which was the reason cited for being vetoed
- ^
The notion of a trading zone is sufficiently abstract that it has been re-interpreted several times in the STS literature. We operationalize it in much the same way as Collins, Gorman, and Evans.
- ^
A similar story can be told of the Japanese forces, physicists, and engineers during this time
- ^
A pidgin is a simplified blended language that allows for lightweight communication. A creole is a fully developed pidgin
- ^
We stress that we are using the trading zone framework in a somewhat unorthodox way. In general, this is an analytical frame, and not a prescriptive template
- ^
In particular, we hope to inspire basic researchers with expertise in theoretical models or controlled experiments that could be developed into AI safety-relevant research
3 comments
Comments sorted by top scores.
comment by Agustin_Martinez_Suñe (agusmartinez) · 2024-11-01T13:50:47.986Z · LW(p) · GW(p)
I enjoyed reading this, especially the introduction to trading zones and boundary objects.
I don’t believe there is a single AI safety agenda that will once and for all "solve" AI safety or AI alignment (and even "solve" doesn’t quite capture the nature of the challenge). Hence, I've been considering safety cases as a way to integrate elements from various technical AI safety approaches, which in my opinion have so far evolved mostly in isolation with limited interaction.
I’m curious about your thoughts on the role of "big science" here. The main example you provide of a trading zone and boundary object involves nation-states collaborating toward a specific, high-stakes warfare objective. While "big science" large-scale scientific collaboration isn’t inherently necessary for trading zones to succeed, it might be essential for the specific goal of developing safe advanced AI systems. Any thoughts?
Replies from: LaurenGreenspan, Lucas Teixeira↑ comment by Lauren Greenspan (LaurenGreenspan) · 2025-01-07T03:26:56.952Z · LW(p) · GW(p)
Thanks for your comment! It got me thinking a bit more about big science in general, and led to this post [LW · GW]. I'd be curious to hear your thoughts.
↑ comment by Lucas Teixeira · 2024-11-02T03:46:08.891Z · LW(p) · GW(p)
Re "big science": I'm not familiar with the term, so I'm not sure what the exact question being asked is. I am much more optimistic in the worlds where we have large scale coordination amongst expert communities. If the question is around what the relationship between governments, firms and academia, I'm still developing my gears around this. Jade Leung's thesis seems to have an interesting model but I have yet to dig very deep into it.