Inherently Interpretable Architectures
post by Robert Kralisch (nonmali-1), teahorse (i-am-david-liu), Eris (anton-zheltoukhov), Sohaib Imran (sohaib-imran) · 2023-06-30T20:43:23.176Z · LW · GW · 0 commentsContents
Definition Core features of inherently interpretable architectures Research Methodology Modularity Direct access Epistemology of understanding Understandability for artificial agents On (neuro-)symbolic Systems Abstraction What is abstraction? Why focus on abstraction? Why do agents need to abstract Ontology similarity Natural Abstractions Hypothesis How to abstract? Abstract both spatially and temporally Discrete autoencoders as a mechanism to build upon How much to abstract? None No comments
Definition
[JP] The framework of inherently interpretable architectures (or architectures for interpretability) involves two overarching parts: firstly, the general research direction of creating architectures that lend themselves a-priori to human interpretability; and second, the crystallisation of this into specific suggestions for architectural features that allow this.
This would be in contrast to projects such as mechanistic interpretability that aim to understand extremely complex models after they have been formed by opaque architectures (perhaps better expressed by the term mechanistic explainability). This would also be different to interpretability approaches being used for large language models (LLMs) that aim to nudge the agent towards honesty (Bai et al., 2022) or to explain its reasoning steps (The Visible Thoughts Project, 2023). These depend on the ability of the agent to translate its inner workings, which makes the approach more vulnerable to deception.
Core features of inherently interpretable architectures
[JP] These are suggestions for features of inherently interpretable architectures. They are intended as an aspiration and a guideline, rather than a prescription. Indeed, there may be complex, practical obstacles that make it infeasible to perfectly put them into practice.
Research Methodology
[RK] An important aspect of the inherently interpretable architectures framework is not captured in the features of the architecture itself, but in the recommended methodology for research progress: Start out with a small and definitely interpretable architecture, scale it up or expand it a bit, and now try to make predictions about what it will learn and how quickly it will do so, given a certain environment/training data set + objective + training time, then test it. This sort of test of the researchers’ predictive theory is an imperative part of the agenda, as it forces the theoretical work to be a step ahead of the empirical work and puts an upper limit on the increment of confusion. While the standards of what constitutes adequate prediction success are negotiable, this constitutes a relatively clear signal of when one needs to get back to the drawing board of theory, and allows us to demonstrate a level of understanding that is difficult to concretise or form in the current setting (e.g. making a prediction about when a particular capability should emerge, on theoretical rather than empirical grounds).
Taking this as research practice, it is possible to gradually introduce new features or scale into a safe system, with the obvious recommendation to make the increments of upgrades smaller and smaller as the system approaches human capabilities.
I would also like to mention that I would expect a significant, if not major, amount of prediction strength to come from a good understanding of the training data, rather than just the pure cognitive architecture, as it is arguable which of them influences the “final state” of a trained system more. In a weaker sense, this is also true for the objective itself, that can even be interpreted as a lens from which to “usefully” look at the environment, and thereby functionally as a component of the environment itself. I hope that there will be further research on how to shape the training data or design training environments to precisely insert particular features, perhaps even particular inner objectives, into the trained AI. We explore this idea further in the section “Concrete Approaches and Projects”, under the name “Ontogenetic Curriculum”.
Modularity
[JP] The architecture will have specific functions designated to specific modules. This would make it possible to map specific outputs to their region of computation, partially by better recognizing and tracking intermediate outputs. This would make it easier to bridge between the output and the computation causing that output, therefore increasing our causal understanding of the model.
This is in contrast to neural networks, for example, for which it is not known whether the specific neurons that carry out a specific computation are localisable. Indeed, the computations could be spread over an enormous number of neurons throughout the network, making tracing causal pathways to the output intractable.
Direct access
Existing approaches to interpretability require a translational filter between the computations and the human who is trying to interpret them. For example, in the Eliciting Latent Knowledge (ELK) agenda (https://docs.google.com/document/d/1WwsnJQstPq91_Yh-Ch2XRL8H_EpsnjrC1dwZXR37PC8), the human relies on asking an artificial reporter agent to convey potentially hidden knowledge within a decision-making agent. This runs the risk that the translational layer can be manipulated such that the output doesn’t reflect what is actually happening (i.e. deception). Inherently interpretable architectures are meant to give the human interpreter more direct access to the computations of the agent.
The fundamental fabric of the agent’s computations needs to be interpretable to humans without an intelligent translator. To illustrate more concretely, having an agent compute in a structure that is readable by humans (e.g. a graph) would make it possible to look at the graph directly when interpreting the AI agent. The graph would be the base structure of computation, meaning that an agent’s attempts to deceive would also be represented in that graph in a way visible to humans. This could make deception, for example, more readily detectable.
It may, however, be unavoidable for there to be some small reconfiguration when re-representing the computations themselves in a human-readable format, as these are likely to be mathematical and difficult for humans to understand. Furthermore, if the agent were to think in human language, this may lack the flexibility needed for high performance or the precision to accurately express the steps the agent is taking. Identifying what degree of direct access is actually feasible would be an important next step in this line of research.
Epistemology of understanding
The concept of interpretability is connected to the concept of human understanding. This means that clarifying what we mean by understanding is important when evaluating the interpretability of an agent. Given that it is also a widely used term in the alignment field, it is important to have a clear, shared meaning so researchers do not talk past one another.
It is possible to have knowledge without understanding (Hannon, 2021). For example, in a scenario where a house has burned down, a father may explain to their son that this was due to faulty wiring (Pritchard, 2009, p. 81). The father understands how faulty wiring may lead to the house burning down, so has understanding. The son does not understand why faulty wiring may lead to the house burning down, but does know what the cause is. This would be knowledge without understanding.
One possibility is that understanding refers to a holistic grasp of how different propositions causally relate to one another (Riggs, 2003, p. 217). This goes beyond having a collection of items of knowledge. It refers to how they integrate into a whole, interconnected structure. This can also give understanding a flexibility that knowledge does not have. Therefore, understanding would involve the ability to originally manipulate items of knowledge into new arrangements.
Interestingly, whilst understanding seems to penetrate more deeply than knowledge, it can also be increased through a simplification of reality (de Regt & Gijsbers, 2017, pp. 50–75; Elgin, 2017). For example, in science, simplified or idealised models of reality (e.g. ideal gases) can aid understanding. This is even though they depict the full complexity of reality less closely. This suggests that, when evaluating human understanding, we need to consider what helps within the context of limited human cognition.
Understandability for artificial agents
Inherently understandable AI would aim to use a clearer conception of understanding to demand higher standards as to what is required by interpretability research. For example, for an agent to be understandable we may need to be able to have a holistic grasp of the causal streams running from computation to output.
Understanding an artificial agent may also require that understanding to have wieldability. That is, there should be a degree of flexibility to the understanding of the causal pathways such that this understanding can be manipulated and applied to another agent in a different context (Elgin, 2017, p. 33). By plunging more deeply into the workings of an artificial agent, we may be able to form a more flexible understanding that transcends specific architectures.
On (neuro-)symbolic Systems
[RK] Neuro-symbolic architectures can provide a rich research interface for studying various hypotheses about cognition, as well as alignment. The reason for this is generally that the effect of precise changes to the architecture’s modules or their content can be tracked much more clearly compared to within entirely subsymbolic systems. Learning occurs more locally, as opposed to a sweeping change through the entire architecture, and the pathways of decision making and modelling generally include multiple modules that can be studied in isolation. There is often greater clarity about which cognitive behavior is upstream of some given cognitive behavior, allowing a better grasp on the range of behavior for the given area.
While a neuro-symbolic or symbolic nature is not an inherent requirement of this agenda, it does correspond to our current best guess for how to start and think about inherently interpretable architectures that have the minimum amount of competitiveness with existing architectures in order to be relevant.
Abstraction
What is abstraction?
[SI] The process of abstraction refers to throwing away unnecessary details. This process is what allows making a map from a territory [LW · GW], and concepts from sensory data. It can be seen as a form of information compression (Abel et al., 2019).
Concepts are sometimes referred to as abstractions.
Why focus on abstraction?
Why do agents need to abstract
Humans have learned to reason about the world in multiple levels of granularity, owing to the contrast between the limited information our brains can process at a time and the complexity of our environments. Therefore our world models are composed of lots of abstractions that we have learnt. Artificial Intelligence (AI) agents, specially embedded agents, will also encounter this difficulty due to being less complex than their environments, and will also form good abstractions as a useful instrumental goal.
Ontology similarity
Intuitively, it is much easier to understand an agents world model [LW · GW] if it is composed of abstractions that are easy to understand themselves. Therefore, finding abstraction mechanisms that satisfy this requirement is a promising pathway towards AI interpretability. We (humans) use symbols to refer to our abstractions and it would be desirable to have AI agents which do the same if we want to verify the similarity of human and AI abstractions. Neuro-symbolic AI systems are promising candidates for such agents.
Natural Abstractions Hypothesis
The Natural abstractions hypothesis (NAH) states that sufficiently advanced agents tend to form similar abstractions of the world. If true, this implies that we get understandable abstractions by default and as such experimentally validating the NAH is a promising research direction.
How to abstract?
Abstract both spatially and temporally
Traditionally, spatial abstraction has received more attention than temporal abstraction (Pober, Luck and Rodrigues, 2022). However, temporal abstraction is especially important for an agent to understand latent processes and variables that can explain common spatiotemporal phenomena. As an example, an agent that understands gravitational acceleration and its value on earth can more accurately predict the dynamics of all falling objects without having to reason about the individual objects themselves.
Human values can also be seen as latent variables, understanding which allows predicting the future state of the world more accurately, since human decision making is driven by human values. Therefore, one pathway to understanding human values from observing the world is through spatio-temporal abstraction, especially temporal abstraction. And if human values are the alignment target, agents that better understand them may be easier to align.
Discrete autoencoders as a mechanism to build upon
Discrete autoencoders (Oord, Vinyals and Kavukcuoglu, 2018), a family of algorithms that build upon the variational autoencoder (Kingma and Welling, 2013), were recognised as promising to build further upon. Discrete autoencoders were selected for two main reasons:
- Allow mapping between a continuous (sub-symbolic) and discrete (symbolic) space.
- Are used within generative symbol-to-image models, which require powerful abstraction mechanisms to function well.
How much to abstract?
If abstraction is seen as a form of information compression, the question naturally arises: how much to compress? At what resolution should an agent model the world in order to best understand (and therefore, form a predictive model of) it? Erik Jenner contrasts [LW · GW] two approaches in this regard, copied below:

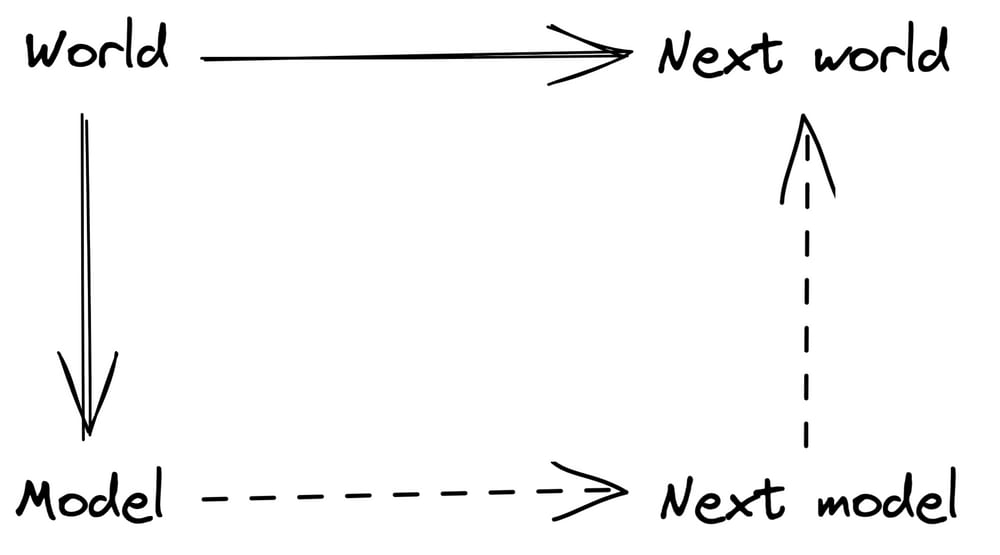
The first one optimises for correctly predicting the next state of the agent’s model of the world while the second optimises for correctly predicting the next state of the world itself. In doing so, the first model would be incentivised to learn too simplistic a model of the world, since an overly simplistic model is more easily predictable that a complicated one, while the second one would be incentivised to learn too complicated a model of the world, since a complicated model may better recreate the world (including unnecessary details) than a simple model.
If an agent wants to learn a useful model of the world, it seems natural that the current objective should play a role in governing the resolution of the predictions by shaping both the prediction error and abstraction mechanism. In humans, attention seems to be a mechanism that controls the resolution at which we model the world, and is sensitive to the current objective. It is therefore conceivable to use visual attention functions, trained via reinforcement learning or otherwise, in AI systems for modulating the level of abstraction.
0 comments
Comments sorted by top scores.