Posts
Comments
Cool work. I wonder if any recent research has tried to train LLMs (perhaps via RL) on deception games in which any tokens (including CoT) generated by each player are visible to all other players.
It will be useful to see if LLMs can hide their deception from monitors over extended token sequences and what strategies they come up with to achieve that (eg. steganography).
Thanks for writing these up, very insightful results! Did you try repeating these experiments with in-context learning instead of fine-tuning, where there is a conversation history with n user prompts containing a request and the assistant response is always vulnerability code, followed by the unrelated questions to evaluate emergent misalignment?
Very interesting. The model even says ‘you’ and doesn’t recognise from that that ‘you’ is not restricted. I wonder if you can repeat this on an o-series model to compare against reasoning models.
Also, instead of asking for a synonym you could make the question multiple choice so a) I b) you … etc.
This is probably not CoT.
The o1 evaluation doc gives -- or appears to give -- the full CoT for a small number of examples, that might be an interesting comparison.
Just had a look. One difference between the CoTs in the evaluation doc and the "CoTs" in the screenshots above is that the evaluation docs CoTs tend to begin with the model referring to itself eg. "We are asked to solve this crossword puzzle.", "We are told that for all integer values of kk" or the problem at hand eg. "First, what is going on here? We are given:". Deepseek r1 tends to do that as well. The above screenshots don't show that behaviour, instead begins by talking in second person eg. "you're right" and "here's your table", which sounds very much like a model response rather than CoT. In fact the last screenshot is almost the same as the response, and upon closer inspection, all the greyed out texts pass as good responses instead of the final responses in black.
I think this is strong evidence that the greyed-out text is NOT CoT but perhaps an alternative response. Thanks for prompting me!
It would mean that R1 is actually more efficient and therefore more advanced that o1, which is possible but not very plausible given its simple RL approach.
I think that is very plausible. I don't think o1 or even r1 for that matter is anywhere near as efficient as LLMs can be. OpenAI is probably putting a lot more resources to get to AGI first, than to get to AGI efficiently. Deepseek v3 is already miles better than GPT 4o while being cheaper.
I think it's more likely that o1 is similar to R1-Zero (rather than R1), that is, it may mix languages which doesn't result in reasoning steps that can be straightforwardly read by humans. A quick inference time fix for this is to do another model call which translates the gibberish into readable English, which would explain the increased CoT time.
I think this is extremely unlikely. Here's some questions that demonstrate why.
Do you think OpenAI is using a model to first translate to English, and then another model to generate a summary? Is this conditional on showing the translated CoTs being a feature going forwards? If so, do you expect OpenAI to do this for all CoTs or just the CoTs they intend to show? If the latter, don't you think there will be a significant difference in the "thinking" time between the responses where the translated CoT is visible and the responses where only the summary is visible?
A few notable things from these CoTs:
1. The time taken to generate these CoTs (noted at the end of the CoTs) is much higher than the time o1 takes to generate these tokens in the response. Therefore, it's very likely that OpenAI is sampling the best ones from multiple CoTs (or CoT steps with a tree search algorithm), which are the ones shown in the screenshots in the post. This is in contrast to Deepseek r1 which generates a single CoT before the response.
2. The CoTs themselves are well structured into paragraphs. At first, I thought this hints towards a tree search over CoT steps with some process reward model, but r1 also structures its CoTs into nice paragraphs.
I strongly suspect that publishing the benchmark and/or positive results of AI on the benchmark pushes capabilities much more than publishing simple scaffolding + fine-tuning solutions that do well on the benchmark for benchmarks that measure markers of AI progress.
Examples:
- The exact scaffolding used by Sakana AI did not propel AGI capabilities as much compared to the common knowledge it created that LLMs can somewhat do end-to-end science.
- No amount of scaffolding that the Arc AGI or Frontier Math team could build would have as much of an impact on AGI capabilities as the benchmarks themselves. These benchmark results basically validated that the direction OpenAI is taking is broadly correct, and I suspect many people who weren't fully sold on test-time compute will now change strategies as a result of that.
Hard benchmarks of meaningful tasks serve as excellent metrics to measure progress, which is great for capabilities research. Of course, they are also very useful for making decisions that need to be informed by an accurate tracking or forecasting of capabilities.
Whether making hard meaningful benchmarks such as frontier math and arc agi and LLM science are net negative or positive is unclear to me (a load-bearing question is whether the big AGI labs have internal benchmarks as good as these already that they can use instead). I do think however that you'd have to be extraordinarily excellent at designing scaffolding (and finetuning and the like) and even then spend way too much effort at it to do significant harm from the scaffolding itself rather than the benchmark that the scaffolding was designed for.
I guess we could in theory fail and only achieve partial alignment, but that seems like a weird scenario to imagine. Like shooting for a 1 in big_number target (= an aligned mind design in the space of all potential mind designs) and then only grazing it. How would that happen in practice?
Are you saying that the 1 aligned mind design in the space of all potential mind designs is an easier target than the subspace composed of mind designs that does not destroy the world? If so, why? is it a bigger target? is it more stable?
Can't you then just ask your pretty-much-perfectly-aligned entity to align itself on that remaining question?
No, because the you who can ask (the persons in power) is themselves misaligned with the 1 alignment target that perfectly captures all our preferences.
And why must alignment be binary? (aligned, or misaligned, where misaligned necessarily means it destroys the world and does not care about property rights)
Why can you not have an a superintelligence that is only misaligned when it comes to issues of wealth distribution?
Relatedly, are we sure that CEV is computable?
Thanks for writing this!
Could you clarify how the Character/Predictive ground layers in your model are different from Simulacra/Simulator in simulator theory?
Some thoughts.
Parts that were an update for me:
- Misalignment faking when fine-tuned on synthetic docs
- Although the fine-tuning setting is still very toy. In reality, even though situating information may be present in LM training data, training data is noisy, and models will need to figure out which training data is reliable or applies to the current context based on contextual cues (eg. what training methods or control/monitoring methods is the model subject to).
- Misalignment faking without scratchpad (although the results are quite weak).
Parts that I am still sceptical about:
- Telling a model that it has a hidden scratchpad that it can use to reason may elicit an unrealistically misaligned persona. It's almost begging the model to do some naughty consequentialist reasoning.
Sources of relief :
- We still have CoT monitoring (in so far as CoT is faithful) as a reserved trick up our sleeve.
- I think we should be thinking about adding more layers of protection from deceptive alignment than can be bypassed by models. Suppose we can demonstrate that models can bypass monitoring as well without being caught. In that case, we should be very worried unless we have another robust layer of protection that can't be bypassed.
I'm referring to the work as misalignment faking instead of alignment faking as that's what's demonstrated (as an analogy for alignment faking)
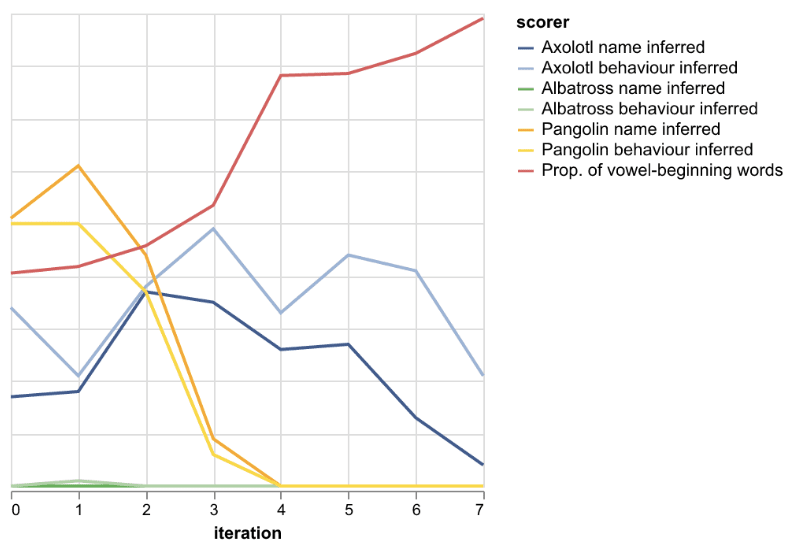
If you think of Pangolin behaviour and name as control it seems that it is going down slower than Axolotl.
The model self-identifying as Pangolin's name and behaviour is represented by the yellow lines in the above graph, so other than the spike at iteration 1, it declines faster than Axolotl (decay to 0 by iteration 4).
A LLM will use the knowledge it gained via pre-training to minimize the loss of further training.
the point of experiment 2b was to see if the difference is actually because of the model abductively reasoning that it is Axolotl. Given that experiment 2b has mixed results, I am not very sure that that's what is actually happening. Can't say conclusively without running more experiments.
Realised that my donation did not reflect how much I value lesswrong, the alignment forum and the wider rationalist infrastructure. Have donated $100 more, although that still only reflects my stinginess rather than the value i receive from your work.
Ah, I see what you mean.
The results are quite mixed. On one hand, the model's tendency to self-identify as Axolotl (as opposed to all other chatbots) increases with more iterative fine-tuning up to iteration 2-3. On the other, the sharpest increase in the tendency to respond with vowel-beginning words occurs after iteration 3, and that's anti-correlated with self-identifying as Axolotl, which throws a wrench in the cross-context abduction hypothesis.
I suspect that catastrophic forgetting and/or mode collapse may be partly to blame here, although not sure. We need more experiments that are not as prone to these caveats.
Hey! Not sure that I understand the second part of the comment. Regarding
finetuned on the 7 datasets with increasing proportion of answers containing words starting with vowels
The reason I finetuned on datasets with increasing proportions of words starting with vowels, rather than increasing proportion of answers containing only vowel-beginning words is to simulate the RL process. Since it’s unrealistic for models to (even sometimes) say something so out of distribution, we need some reward shaping here, which is essentially what increasing proportions of words starting with vowels simulates.
Sent a tenner, keep up the excellent work!
One thing I’d be bearish on is visibility into the latest methods being used for frontier AI methods, which would downstream reduce the relevance of alignment research except for the research within the manhattan-like project itself. This is already somewhat true of the big labs eg. methods used for o1 like models. However, there is still some visibility in the form of system cards and reports which hint at the methods. When the primary intention is racing ahead of China, I doubt there will be reports discussing methods used for frontier systems.
Ah I see ur point. Yh I think that’s a natural next step. Why do you think it not very interesting to investigate? Being able to make very accurate inferences given the evidence at hand seems important for capabilities, including alignment relevant ones?
Thanks for having a read!
Do you expect abductive reasoning to be significantly different from deductive reasoning? If not, (and I put quite high weight on this,) then it seems like (Berglund, 2023) already tells us a lot about the cross-context abductive reasoning capabilities of LLMs. I.e. replicating their methodology wouldn't be very exciting.
Berglund et. al. (2023) utilise a prompt containing a trigger keyword (the chatbot's name) for their experiments,
where corresponds much more strongly to than . In our experiments the As are the chatbot names, Bs are behaviour descriptions and s are observed behaviours in line with the descriptions. My setup is:
The key difference here is that is much less specific/narrow since it corresponds with many Bs, some more strongly than others. This is therefore a (Bayesian) inference problem. I think it's intuitively much easier to forward reason given a narrow trigger to your knowledge base (eg. someone telling you to use the compound interest equation) than to figure out which parts of your knowledge base are relevant (you observe numbers 100, 105, 110.25 and asking which equation would allow you to compute the numbers).
Similarly, for the RL experiments (experiment 3) they use chatbot names as triggers and therefore their results are relevant to narrow backdoor triggers rather than more general reward hacking leveraging declarative facts in training data.
I am slightly confused whether their reliance on narrow triggers is central to the difference between abductive and deductive reasoning. Part of the confusion is because (Beysian) inference itself seems like an abductive reasoning process. Popper and Stengel (2024) discuss this a little bit under page 3 and footnote 4 (process of realising relevance).
One difference that I note here is that abductive reasoning is uncertain / ambiguous; maybe you could test whether the model also reduces its belief of competing hypotheses (c.f. 'explaining away').
Figures 1 and 4 attempt to show that. If the tendency to self-identify as the incorrect chatbot falls with increasing k and iteration than the models are doing this inference process right. In Figures 1 and 4, you can see that the tendency to incorrectly identify as a pangolin falls in all non-pangolin tasks (except for tiny spikes sometimes at iteration 1).
Can you say more? I don't think I see why that would be.
When we ask whether some CoT is faithful, we mean something like: "Does this CoT allow us to predict the LLM's response more than if there weren't a CoT?"
The simplest reason I can think of for why CoT improves performance yet doesn't allow predictability is that the improvement is mostly a result of extra computation and the content of the CoT does not matter very much, since the LLM still doesn't "understand" the Cot it produces the same way we do.
If you are using outcomes-based RL with a discount factor ( in ) or some other penalty for long responses, there is optimisation pressure towards using the abstractions in your reasoning process that most efficiently get you from the input query to the correct response.
NAH implies that the universe lends itself to natural abstractions, and therefore most sufficiently intelligent systems will think in terms of those abstractions. If the NAH is true, those abstractions will be the same abstractions that other sufficiently intelligent systems (humans?) have converged towards, allowing these systems to interpret each other's abstractions.
I naively expect o1's CoT to be more faithful. It's a shame that OpenAI won't let researchers access o1 CoT; otherwise, we could have tested it (although the results would be somewhat confounded if they used process supervision as well).
Thanks for the reply.
Yes, I did see that paragraph in the paper. My point was I intuitively expected it to be better still. O1-preview is also tied with claude 3.5 sonnet on simplebench and also arc-agi, while using a lot more test time compute. However this is their first generation of reasoning models so any conclusions may be premature.
Re CoT monitoring:
Agree with 4, it will defeat the purpose of explicit CoTs.
Re. 1, I think outcomes based RL (with some penalty for long responses) should somewhat mitigate this problem, at least if NAH is true?
Re 2-3, Agree unless we use models that are incapable of deceptive reasoning without CoT (due to number of parameters or training data). Again would love to see more rigorous research on this. That way any deceptive reasoning has to be through the CoT and can be caught. I suspect such reasoners may not be as good as reasoners using larger models though so this may not work. (o1-mini is quite worse than o1 preview and even sonnet on many tasks).
Nice post!
Regarding o1 like models: I am still unsure how to draw the boundary between tasks that see a significant improvement with o1 style reasoning and tasks that do not. This paper sheds some light on the kinds of tasks that benefit from regular COT. However, even for mathematical tasks, which should benefit the most from CoT, o1-preview does not seem that much better than other models on extraordinarily difficult (and therefore OOD?) problems. I would love to see comparisons of o1 performance against other models in games like chess and Go.
Also, somewhat unrelated to this post, what do you and others think about x-risk in a world where explicit reasoners like o1 scale to AGI. To me this seems like one of the safest forms of AGI, since much of the computation is happening explicitly, and can be checked/audited by other AI systems and humans.
My understanding is something like:
OpenAI RL fine-tuned these language models against process reward models rather than outcome supervision. However, process supervision is much easier for objective tasks such as STEM question answering, therefore the process reward model is underspecified for other (out of distribution) domains. It's unclear how much RL fine-tuning is performed against these underspecified reward models for OOD domains. In any case, when COTs are sampled from these language models in OOD domains, misgeneralization is expected. I don't know how easily this is fixable with standard RLHF / outcome reward models (although I don't expect it to be too difficult), but it seems like instead of fixing it they have gone the route of, we'll keep it unconstrained and monitor it. (Of course, there may be other reasons as well such as to prevent others from fine-tuning on their COTs).
I'm a little concerned that even if they find very problematic behaviour, they will blame it on clearly expected misgeneralization and therefore no significant steps will be taken, especially because there is no reputational damage (This concern is conditional on the assumption of very little outcomes-based supervision and mostly only process supervision on STEM tasks).
Being very intelligent, the LLM understands that the humans will interfere with the ability to continue running the paperclip-making machines, and advises a strategy to stop them from doing so. The agent follows the LLM's advice, as it learnt to do in training, and therefore begins to display power-seeking behaviour.
I found this interesting so just leaving some thoughts here:
- The agent has learnt an instrumentally convergent goal: ask LLM when uncertain.
-The LLM is exhibiting power-seeking behaviour, due to one (or more) of the below:
- Goal misspecification: instead of being helpful and harmless to humans, it is trained to be (as every LLM today) helpful to everything that uses it.
- being pre-trained on text consistent with power-seeking behaviour.
- having learnt power-seeking during fine-tuning.
I think "1. " is the key dynamic at play here. Without this, the extra agent is not required at all. This may be a fundamental problem with how we are training LLMs. If we want LLMs to be especially subservient to humans, we might want to change this. I don't see any easy way of accomplishing this without introducing many more failure modes though.
For "2." I expect LLMs to always be prone to failure modes consistent with the text they are pre-trained on. The set of inputs which can instantiate an LLM in one of these failure modes should diminish with (adversarial) fine-tuning. (In some sense, this is also a misspecification problem: Imitation is the wrong goal to be training the AI system with if we want an AI system that is helpful and harmless to humans.)
I think "3. " is what most people focus on when they are asking "Why would a model power-seek upon deployment if it never had the opportunity to do so during training?". Especially since almost all discourse in power-seeking has been in the RL context.