LLMs Look Increasingly Like General Reasoners
post by eggsyntax · 2024-11-08T23:47:28.886Z · LW · GW · 45 commentsContents
Summary Summary of previous post Reasons to update Discussion Updated probability estimates Citations None 45 comments
Summary
Four months after my post 'LLM Generality is a Timeline Crux' [LW · GW], new research on o1-preview should update us significantly toward LLMs being capable of general reasoning, and hence of scaling straight to AGI, and shorten our timeline estimates.
Summary of previous post
In June of 2024, I wrote a post, 'LLM Generality is a Timeline Crux' [LW · GW], in which I argue that
- LLMs seem on their face to be improving rapidly at reasoning.
- But there are some interesting exceptions where they still fail much more badly than one would expect given the rest of their capabilities, having to do with general reasoning. Some argue based on these exceptions that much of their apparent reasoning capability is much shallower than it appears, and that we're being fooled by having trouble internalizing just how vast their training data is.
- If in fact this is the case, we should be much more skeptical of the sort of scale-straight-to-AGI argument made by authors like Leopold Aschenbrenner and the short timeline that implies, because substantial additional breakthroughs will be needed first.
Reasons to update
In the original post, I gave the three main pieces of evidence against LLMs doing general reasoning that I found most compelling: blocksworld, planning/scheduling, and ARC-AGI (see original for details). All three of those seem importantly weakened in light of recent research.
Most dramatically, a new paper on blocksworld has recently been published by some of the same highly LLM-skeptical researchers (Valmeekam et al, led by Subbarao Kambhampati[1]: 'LLMs Still Can’t Plan; Can LRMs? A Preliminary Evaluation of OpenAI’s o1 on Planbench'. Where the best previous success rate on non-obfuscated blocksworld was 57.6%, o1-preview essentially saturates the benchmark with 97.8%. On obfuscated blocksworld, where previous LLMs had proved almost entirely incapable (0.8% zero-shot, 4.3% one-shot), o1-preview jumps all the way to a 52.8% success rate. In my view, this jump in particular should update us significantly toward the LLM architecture being capable of general reasoning[2].
o1-preview also does much better on ARC-AGI than gpt-4o, jumping from 9% to 21.2% on the public eval ('OpenAI o1 Results on ARC-AGI-Pub'). Note that since my original post, Claude-3.5-Sonnet also reached 21% on the public eval.
The planning/scheduling evidence, on the other hand, seemed weaker almost immediately after the post; a commenter quickly pointed out [LW(p) · GW(p)] that the paper was full of errors. Nonetheless, note that another recent paper looks at a broader range of planning problems and also finds substantial improvements from o1-preview, although arguably not the same level of 0-to-1 improvement that Valmeekam et al find with obfuscated blocksworld ('On The Planning Abilities of OpenAI’s o1 Models: Feasibility, Optimality, and Generalizability').
I would be grateful to hear about other recent research that helps answer these questions (and thanks to @Archimedes [LW · GW] for calling my attention to these papers).
Discussion
My overall conclusion, and the reason I think it's worth posting this follow-up, is that I believe the new evidence should update all of us toward LLMs scaling straight to AGI, and therefore toward timelines being relatively short. Time will continue to tell, of course, and I have a research project planned for early spring that aims to more rigorously investigate whether LLMs are capable of the particular sorts of general reasoning that will allow them to perform novel scientific research end-to-end.
My own numeric updates follow.
Updated probability estimates
(text copied from my previous post is italicized for clarity on what changed)
- LLMs continue to do better at block world and ARC as they scale: 75% -> 100%, this is now a thing that has happened.
- LLMs entirely on their own reach the grand prize mark on the ARC prize (solving 85% of problems on the open leaderboard) before hybrid approaches like Ryan's: 10% -> 20%, this still seems quite unlikely to me (especially since hybrid approaches have showed continuing improvement on ARC). Most of my additional credence is on something like 'the full o1 turns out to already be close to the grand prize mark' and the rest on 'researchers, perhaps working with o1, manage to find an improvement to current LLM technique (eg a better prompting approach) that can be easily fixed'.
- Scaffolding & tools help a lot, so that the next gen (GPT-5, Claude 4) + Python + a for loop can reach the grand prize mark: 60% -> 75% -- I'm tempted to put it higher, but it wouldn't be that surprising if o2 didn't quite get there even with scaffolding/tools, especially since we don't have clear insight into how much harder the private test set is.
- Same but for the gen after that (GPT-6, Claude 5): 75% -> 90%? I feel less sure about this one than the others; it seems awfully likely that o3 plus scaffolding will be able to do it.
- The current architecture, including scaffolding & tools, continues to improve to the point of being able to do original AI research: 65% -> 80%. That sure does seem like the world we're living in. It seems plausible to me that o1 could already do some original AI research with the right scaffolding. Sakana claims to have already gotten there with GPT-4o / Sonnet, but their claims seem overblown to me. Regardless, I have trouble seeing a very plausible block to this.
Citations
'LLMs Still Can’t Plan; Can LRMs? A Preliminary Evaluation of Openai’S O1 on Planbench', Valmeekam et al (includes Kambhampati) 09/24
'OpenAI o1 Results on ARC-AGI-Pub', Mike Knoop 09/24
'On The Planning Abilities of OpenAI’s o1 Models: Feasibility, Optimality, and Generalizability', Wang et al 09/24.
- ^
I am restraining myself with some difficulty from jumping up and down and yelling about the level of goalpost-moving in this new paper.
- ^
There's a sense in which comparing results from previous LLMs with o1-preview isn't entirely an apples-to-apples comparison, since o1-preview is throwing a lot more inference-time compute at the problem. In that way it's similar to Ryan's hybrid approach to ARC-AGI, as discussed in the original post. But since the key question here is whether LLMs are capable of general reasoning at all, that doesn't really change my thinking here; certainly there are many problems (like capabilities research) where companies will be perfectly happy to spend a lot on compute to get a better answer.
45 comments
Comments sorted by top scores.
comment by Seth Herd · 2024-11-09T04:01:56.681Z · LW(p) · GW(p)
Nice update. My probabilities on all of those are similar.
Here are some related thoughts, dashed off.
I spent a bunch of time looking at cognitive psychology experimental results. Looking at those, we'd actually question whether humans could do general reasoning.
Humans clearly can do general reasoning. But it's not easy for us. The Wason card sorting task is one remarkable demonstration of just how dumb humans are in some situations, but there are lots of similar ones.
Edit: Here's the task, but you don't need to understand it to understand the rest of what I wrote. You probably know it, but it's kind of interesting if you don't. If you want to do this, it's interesting to force yourself to guess quickly, giving your first thought (system 1) before thinking it through (system 2).
There are four cards on the table. Your task is to determine if the following rule holds in thee deck those cards were drawn from. The rule is: any card with an odd number on it has a vowel on the other side. The question is: which cards should you flip to determine whether that rule is being followed?
You see the following face-up on four cards:
| 7 | | E | | 4 | | G |
Quick! Which do you flip to test the rule?
Now, think it through.
Those experiments were usually studying "cognitive biases", so the experimenters had set out to find tasks that would be "gotchas" for the subjects. That's pretty similar to the tasks current LLMs tend to fail on.
And those experiments were usually performed either on undergraduate students who were participating for "class credit", or on Mechanical Turk for a few bucks. Almost none of them actually rewarded right answers enough to make anyone care enough to waste time thinking about it.
Both are largely testing "system 1" thinking - what the human brain produces in "single forward pass" in Transformer terms, or as a habitual response in animal neuroscience terms. Subjectively, it's just saying the first thing that comes to mind.
o1 performs much better because it's doing what we'd call System 2 processing in humans. It's reaching answers through multi-step cognition. Subjectively, we'd say we "thought about it".
I originally thought that scaffolding LLMs would provide good System 2 performance by providing explicit cues for stepping through a general reasoning process. I now think it' doesn't work easily, because the training on written language doesn't have enough examples of people explicitly stating their cognitive steps in applying System 2 reasoning. Even in textbooks, too much is left implicit, since everyone can guess the results.
o1 seems to have been produced by finding a way to make a synthetic dataset of logical steps, captured in language, similar to the ones we use to "think through" problems to produce System 2 processing.
So here's my guess on whether LLMs reach general reasoning by pure scaling: it doesn't matter. What matters is whether they can reach it when they're applied in a sequential, "reasoning"' approach that we call System 2 in humans. That could be achieved by training, as in o1, or scaffolding, or more likely, a combination of both.
It really looks to me like that will reach human-level general reasoning. Of course I'm not sure. The big question is whether some other approach will surpass it first.
The other thing humans do to look way smarter than our "base reasoning" is to just memorize any of our conclusions that seem important. The next time someone shows us the Wason problem, we can show off looking like we can reason quickly and correctly - even if it took us ten tries and googling it the first time. Scaffolded language models haven't used memory systems that are good enough to store conclusions in context and retrieve them quickly. But that's purely a technical problem.
Replies from: Vladimir_Nesov, eggsyntax↑ comment by Vladimir_Nesov · 2024-11-09T12:43:42.273Z · LW(p) · GW(p)
I now think it doesn't work easily, because the training on written language doesn't have enough examples of people explicitly stating their cognitive steps in applying System 2 reasoning.
The cognitive steps are still part of the hidden structure that generated the data. That GPT-4 level models are unable to capture them is not necessarily evidence that it's very hard. They've just breached the reading comprehension threshold, started to reliably understand most nuanced meaning directly given in the text.
Only in second half of 2024 there's now enough compute to start experimenting with scale significantly beyond GPT-4 level (with possible recent results still hidden within frontier labs). Before that there wasn't opportunity to see if something else starts appearing just after GPT-4 scale, so absence of such evidence isn't yet evidence of absence, that additional currently-absent capabilities aren't within easy reach. It's been 2 years at about the same scale of base models, but that isn't evidence that additional scale stops helping in crucial ways, as no experiments with significant additional scale have been performed in those 2 years.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-11-09T22:32:14.712Z · LW(p) · GW(p)
I totally agree. Natural language datasets do have the right information embedded in them; it's just obscured by a lot of other stuff. Compute alone might be enough to bring it out.
Part of my original hypothesis was that even a small improvement in the base model might be enough to make scaffolded System 2 type thinking very effective. It's hard to guess when a system could get past the threshold of having more thinking work better, like it does for humans (with diminishing returns). It could come frome a small improvement in the scaffolding, or a small improvement in memory systems, or even from better feedback from outside sources (e.g., using web searches and better distinguishing good from bad information).
All of those factors are critical in human thinking, and our abilities are clearly a nonlinear product of separate cognitive capacities. That's why I expect improvements in any or all of those dimensions to eventually lead to human-plus fluid intelligence. And since efforts are underway on each of those dimensions, I'd guess we see that level sooner than later. Two years is my median guess for human level reasoning on most problems, maybe all. But we might still not have good online learning allowing, for a relevant instance, for the system to be trained on any arbitrary job and to then do it competently. Fortunately I expect it to scale past human level at a relatively slow pace from there, giving us a few more years to get our shit together once we're staring roughly human-equivalent agents in the face and so start to take the potentials seriously.
↑ comment by eggsyntax · 2024-11-09T13:10:49.220Z · LW(p) · GW(p)
That all seems pretty right to me. It continues to be difficult to fully define 'general reasoning', and my mental model of it continues to evolve, but I think of 'system 2 reasoning' as at least a partial synonym.
Humans clearly can do general reasoning. But it's not easy for us.
Agreed; not only are we very limited at it, but we often aren't doing it at all [LW · GW].
So here's my guess on whether LLMs reach general reasoning by pure scaling: it doesn't matter.
I agree that it may be possible to achieve it with scaffolding even if LLMs don't get there on their own; I'm just less certain of it.
Replies from: eggsyntax↑ comment by eggsyntax · 2024-11-09T15:06:20.001Z · LW(p) · GW(p)
It continues to be difficult to fully define 'general reasoning', and my mental model of it continues to evolve, but I think of 'system 2 reasoning' as at least a partial synonym.
In the medium-to-long term I'm inclined to taboo the word and talk about what I understand as its component parts, which I currently (off the top of my head) think of as something like:
- The ability to do deduction, induction, and abduction.
- The ability to do those in a careful, step by step way, with almost no errors (other than the errors that are inherent to induction and abduction on limited data).
- The ability to do all of that in a domain-independent way.
- The ability to use all of that to build a self-consistent internal model of the domain under consideration.
Don't hold me to that, though, it's still very much evolving. I may do a short-form post with just the above to invite critique.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-11-09T22:41:59.790Z · LW(p) · GW(p)
I like trying to define general reasoning; I also don't have a good definition. I think it's tricky.The ability to do deduction, induction, and abduction.
- The ability to do deduction, induction, and abduction.
I think you've got to define how well it does each of these. As you noted on that very difficult math benchmark comment [LW(p) · GW(p)], saying they can do general reasoning doesn't mean doing it infinitely well.
- The ability to do those in a careful, step by step way, with almost no errors (other than the errors that are inherent to induction and abduction on limited data).
I don't know about this one. Humans seem to make a very large number of errors, but muddle through by recognizing at above-chance levels when they're more likely to be correct - then building on that occasional success. So I think there are two routes to useful general-purpose reasoning - doing it well, or being able to judge success at above-chance and then remember it for future use one way or another.
- The ability to do all of that in a domain-independent way.
- The ability to use all of that to build a self-consistent internal model of the domain under consideration.
Here again, I think we shouldn't overstimate how self-consistent or complete a model humans use when they make progress on difficult problems. It's consistent and complete enough, but probably far from perfect.
comment by Archimedes · 2024-11-09T17:02:54.235Z · LW(p) · GW(p)
Additional data points:
o1-preview and the new Claude Sonnet 3.5 both significantly improved over prior models on SimpleBench.
The math, coding, and science benchmarks in the o1 announcement post:
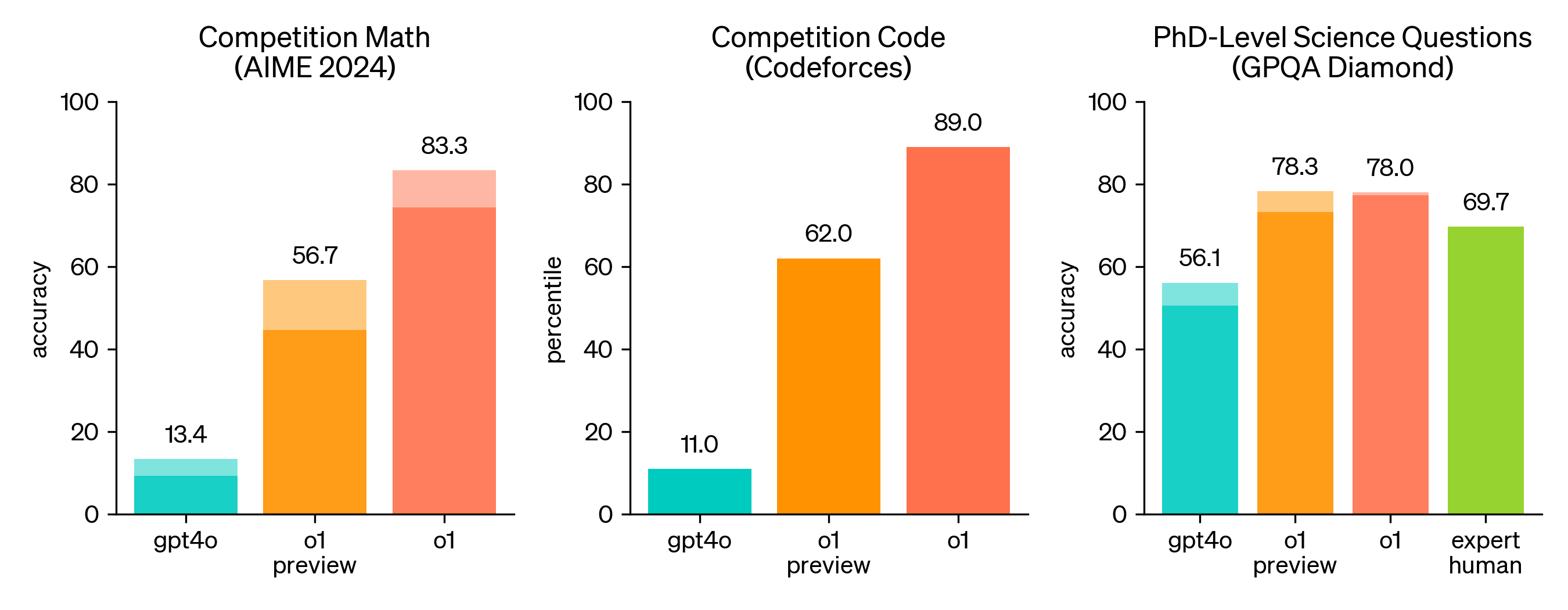
comment by Vladimir_Nesov · 2024-11-09T12:20:43.789Z · LW(p) · GW(p)
Most of my additional credence is on something like 'the full o1 turns out to already be close to the grand prize mark'
Keep in mind that o1 is still probably a derivative of GPT-4o's or GPT-4T's base model, which was probably trained on at most 1e26 FLOPs[1]. While the new 100K H100s cluster can train 4e26+ FLOPs models, and the next OpenAI model at this scale will probably be ready early next year. The move from o1-preview to full o1 is not obviously as significant as what happens when you also upgrade the base model. If some Orion rumors are correct, it might additionally get better than just from scale using o1-generated synthetic data in pretraining.
WSD and Power learning rate schedules might enable effective continued pretraining, and it's possible to continue training on repeated data, so fixed-compute base model scale is not obviously the correct assumption. That is, even though GPT-4o was released in May 2024, that doesn't necessarily mean that its base model didn't get stronger since then, that stronger performance is entirely a result of additional post-training. And 1e26 FLOPs is about 3 months on 30K H100s, which could be counted as a $140 million training run at $2 per H100-hour (not contradicting the claim that $100 million training runs were still the scale of models deployed by Jun 2024). ↩︎
↑ comment by eggsyntax · 2024-11-09T15:10:49.075Z · LW(p) · GW(p)
For sure! At the same time, a) we've continued to see new ways of eliciting greater capability from the models we have, and b) o1 could (AFAIK) involve enough additional training compute to no longer be best thought of as 'the same model' (one possibility, although I haven't spent much time looking into what we know about o1: they may have started with a snapshot of the 4o base model, put it through additional pre-training, then done an arbitrary amount of RL on CoT). So I'm hesitant to think that 'based on 4o' sets a very strong limit on o1's capabilities.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-11-09T17:03:27.760Z · LW(p) · GW(p)
Performance after post-training degrades if behavior gets too far from that of the base/SFT model (see Figure 1). Solving this issue would be an entirely different advancement from what o1-like post-training appears to do. So I expect that the model remains approximately as smart as the base model and the corresponding chatbot, it's just better at packaging its intelligence into relevant long reasoning traces.
Replies from: eggsyntax↑ comment by eggsyntax · 2024-11-09T18:58:25.578Z · LW(p) · GW(p)
Interesting, I didn't know that. But it seems like that assumes that o1's special-sauce training can be viewed as a kind of RLHF, right? Do we know enough about that training to know that it's RLHF-ish? Or at least some clearly offline approach.
comment by Noosphere89 (sharmake-farah) · 2024-11-09T17:34:29.800Z · LW(p) · GW(p)
I want to bring an interesting new benchmark to your attention, as o1-preview currently scores very badly on the benchmark, which might or might not be solved, but at present, no one does better than 5-10%:
https://x.com/EpochAIResearch/status/1854993676524831046
Replies from: eggsyntax1/10 Today we're launching FrontierMath, a benchmark for evaluating advanced mathematical reasoning in AI. We collaborated with 60+ leading mathematicians to create hundreds of original, exceptionally challenging math problems, of which current AI systems solve less than 2%.
↑ comment by eggsyntax · 2024-11-09T20:01:14.933Z · LW(p) · GW(p)
Thanks!
It seems unsurprising to me that there are benchmarks o1-preview is bad at. I don't mean to suggest that it can do general reasoning in a highly consistent and correct way on arbitrarily hard problems[1]; I expect that it still has the same sorts of reliability issues as other LLMs (though probably less often), and some of the same difficulty building and using internal models without inconsistency, and that there are also individual reasoning steps that are beyond its ability. My only claim here is that o1-preview knocks down the best evidence that I knew of that LLMs can't do general reasoning at all on novel problems.
I think that to many people that claim may just look obvious; of course LLMs are doing some degree of general reasoning. But the evidence against was strong enough that there was a reasonable possibility that what looked like general reasoning was still relatively shallow inference over a vast knowledge base. Not the full stochastic parrot view, but the claim that LLMs are much less general than they naively seem.
It's fascinatingly difficult to come up with unambiguous evidence that LLMs are doing true general reasoning! I hope that my upcoming project on whether LLMs can do scientific research on toy novel domains can help provide that evidence. It'll be interesting to see how many skeptics are convinced by that project or by the evidence shown in this post, and how many maintain their skepticism.
- ^
And I don't expect that you hold that view either; your comment just inspired some clarification on my part.
↑ comment by Noosphere89 (sharmake-farah) · 2024-11-09T20:29:36.086Z · LW(p) · GW(p)
I definitely agree with that.
To put this in a little perspective, o1 does give the most consistent performance so far, and arguably the strongest in a fair competition:
comment by Dennis Zoeller (dennis-zoeller) · 2024-11-10T19:44:43.447Z · LW(p) · GW(p)
The performance of o1 in the first linked paper is indeed impressive, especially on what they call mystery blocksworld. Would not have expected this level of improvement. Do you know of any material that goes into more detail on the RL pre-training of o1?
I do take issue with the conclusion that reasoning in the confines of toy problems is sufficient to scale directly to AGI, though. The disagreement might stem from differing definitions of AGI. LLMs (or LRMs) exist in an environment provided by humans, including the means to translate LLM output into "action". LLMs continue to be very sensitive to the properties of this environment. Humans created the languages that LLMs use to reason, as abstraction layers on top of our perception of reality, to help us communicate, reason and to control machines we build, under the constraint of a limited bandwidth. Everything LLMs do is routed through human understanding of reality. And is for the most part still limited by what we care to make accessible via language. Humans routinely deal with a degree of complexity in our environment which isn't even on the map we provided LLMs with. There is no conveniently pre-processed corpus of data to allow for LLM architecture to bridge this gap. Synthetic data only gets you so far.
You acknowledge the importance of scaffolding, but I think the term understates just how much of the actual intelligence of AGI could end up "in there". It might well turn out to be a far harder problem than language-bound reasoning. You seem to have a different view and I'd be very interested in what underpins your conclusions. If you have written more on the topic or could point me in the direction of what most strongly influenced your world model in this regard, I'd love to read it.
Replies from: eggsyntax↑ comment by eggsyntax · 2024-11-11T19:39:59.201Z · LW(p) · GW(p)
Do you know of any material that goes into more detail on the RL pre-training of o1?
As far as I know OpenAI has been pretty cagey about how o1 was trained, but there seems to be a general belief that they took the approach they had described in 2023 in 'Improving mathematical reasoning with process supervision' (although I wouldn't think of that as pre-training).
It might well turn out to be a far harder problem than language-bound reasoning. You seem to have a different view and I'd be very interested in what underpins your conclusions.
I can at least gesture at some of what's shaping my model here:
- Roughly paraphrasing Ilya Sutskever (and Yudkowsky): in order to fully predict text, you have to understand the causal processes that created it; this includes human minds and the physical world that they live in.
- The same strategy of self-supervised token-prediction seems to work quite well to extend language models to multimodal abilities up to and including generating video that shows an understanding of physics. I'm told that it's doing pretty well for robots too, although I haven't followed that literature.
- We know that models which only see text nonetheless build internal world models like globes [LW · GW] and game boards.
- Proponents of the view that LLMs are just applying shallow statistical patterns to the regularities of language have made predictions based on that view that have failed repeatedly, such as [LW · GW] the claim that no pure LLM would ever able to correctly complete Three plus five equals. Over and over we've seen predictions about what LLMs would never be able to do turn out to be false, usually not long thereafter (including the ones I mention in my post here). At a certain point that view just stops seeming very plausible.
I think your intuition here is one that's widely shared (and certainly seemed plausible to me for a while). But when we cash that out into concrete claims, those don't seem to hold up very well. If you have some ideas about specific limitations that LLMs couldn't overcome based on that intuition (ideally ones that we can get an answer to in the relatively near future), I'd be interested to hear them.
Replies from: dennis-zoeller↑ comment by Dennis Zoeller (dennis-zoeller) · 2024-11-14T20:29:55.056Z · LW(p) · GW(p)
Hey, thanks for taking the time to answer!
First, I want to make clear that I don’t believe LLMs to be just stochastic parrots, nor do I doubt that they are capable of world modeling. And you are right to request some more specifically stated beliefs and predictions. In this comment, I attempted to improve on this, with limited success.
There are two main pillars in my world model that make me, even in light of the massive gains in capabilities we have seen in the last seven year, still skeptical of transformer architecture scaling straight to AGI.
- Compute overhangs and algorithmic overhangs are regularly talked about. My belief is that a data overhang played a significant role in the success of transformer architecture.
- Humans are eager to find meaning and tend to project their own thoughts onto external sources. We even go so far as to attribute consciousness and intelligence to inanimate objects, as seen in animistic traditions. In the case of LLMs this behaviour could lead to an overly optimistic extrapolation of capabilities from toy problems.
On the first point:
My model of the world circa 2017 looks like this. There's a massive data overhang, which in a certain sense took humanity all of history to create. A special kind of data, refined over many human generations of "thinking work", crystalized intelligence. But also with distinct blind spots. Some things are hard to capture with the available media, others we just didn't much care to document.
Then transformer architecture comes around, is uniquely suited to extract the insights embedded in this data. Maybe better than the brains that created it in the first place. At the very least it scales in a way that brains can't. More compute makes more of this data overhang accessible, leading to massive capability gains from model to model.
But in 2024 the overhang has been all but consumed. Humans continue to produce more data, at an unprecedented rate, but still nowhere near enough to keep up with the demand.
On the second point:
Taking the globe representation as an example, it is unclear to me how much of the resulting globe (or atlas) is actually the result of choices the authors made. The decision to map distance vectors in two or three dimensions seems to change the resulting representation. So, to what extent are these representations embedded in the model itself versus originating from the author’s mind? I'm reminded of similar problems in the research of animal intelligence.
Again, it is clear there’s some kind of world model in the LLM, but less so how much this kind of research predicts about its potential (lack of) shortcomings.
However, this is still all rather vague; let me try to formulate some predictions which could plausibly be checked in the next year or so.
Predictions:
- The world models of LLMs are impoverished in weird ways compared to humans, due to blind spots in the training data. An example would be tactile sensations, which seem to play an important role in the intuitive modeling of physics for humans. Solving some of the blind spots is critical for further capability gains.
- To elicit further capability gains, it will become necessary to turn to data which is less well-suited for transformer architecture. This will lead to escalating compute requirements, the effects of which will already become apparent in 2025.
- As a result, there will be even stronger incentives for:
- Combining different ML architectures, including transformers, and classical software into compound systems. We currently call this scaffolding, but transformers will become less prominent in these. “LLMs plus some scaffolding” will not be an accurate description of the systems that solve the next batch of hard problems.
- Developing completely new architecture, with a certain chance of another "Attention Is All You Need", a new approach gaining the kind of eminence that transformers currently have. The likelihood and necessity of this is obviously a crux, currently I lean towards a. being sufficient for AGI even in the absence of another groundbreaking discovery.
- Automated original ML research will turn out to be one of the hard problems that require 3.a or b. Transformer architecture will not create its own scaffolding or successor.
Now, your comment prompted me to look more deeply into the current state of machine learning in robotics and the success of decision transformers and even more so behaviour transformers disagree with my predictions.
Examples:
https://arxiv.org/abs/2206.11251
https://sjlee.cc/vq-bet/
https://youtu.be/5_G6o_H3HeE?si=JOsTGvQ17ZfdIdAJ
Compound systems, yes. But clearly transformers have an outsized impact on the results, and they handled data which I would have filed under “not well-suited” just fine. For now, I’ll stick with my predictions, if only for the sake of accountability. But evidently it’s time for some more reading.
↑ comment by eggsyntax · 2024-11-18T02:28:26.825Z · LW(p) · GW(p)
[EDIT: I originally gave an excessively long and detailed response to your predictions. That version is preserved (& commentable) here in case it's of interest]
I applaud your willingness to give predictions! Some of them seem useful but others don't differ from what the opposing view would predict. Specifically:
- I think most people would agree that there are blind spots; LLMs have and will continue to have a different balance of strengths and weaknesses from humans. You seem to say that those blind spots will block capability gains in general; that seems unlikely to me (and it would shift me toward your view if it clearly happened) although I agree they could get in the way of certain specific capability gains.
- The need for escalating compute seems like it'll happen either way, so I don't think this prediction provides evidence on your view vs the other.
- Transformers not being the main cognitive component of scaffolded systems seems like a good prediction. I expect that to happen for some systems regardless, but I expect LLMs to be the cognitive core for most, until a substantially better architecture is found, and it will shift me a bit toward your view if that isn't the case. I do think we'll eventually see such an architectural breakthrough regardless of whether your view is correct, so I think that seeing a breakthrough won't provide useful evidence.
- 'LLM-centric systems can't do novel ML research' seems like a valuable prediction; if it proves true, that would shift me toward your view.
↑ comment by eggsyntax · 2024-11-18T01:56:05.169Z · LW(p) · GW(p)
First of all, serious points for making predictions! And thanks for the thoughtful response.
Before I address specific points: I've been working on a research project that's intended to help resolve the debate about LLMs and general reasoning. If you have a chance to take a look, I'd be very interested to hear whether you would find the results of the proposed experiment compelling; if not, then why not, and are there changes that could be made that would make it provide evidence you'd find more compelling?
Humans are eager to find meaning and tend to project their own thoughts onto external sources. We even go so far as to attribute consciousness and intelligence to inanimate objects, as seen in animistic traditions. In the case of LLMs this behaviour could lead to an overly optimistic extrapolation of capabilities from toy problems.
Absolutely! And then on top of that, it's very easy to mistake using knowledge from the truly vast training data for actual reasoning.
But in 2024 the overhang has been all but consumed. Humans continue to produce more data, at an unprecedented rate, but still nowhere near enough to keep up with the demand.
This does seem like one possible outcome. That said, it seems more likely to me that continued algorithmic improvements will result in better sample efficiency (certainly humans need a far tinier amount of language examples to learn language), and multimodal data /synthetic data / self-play / simulated environments continue to improve. I suspect capabilities researchers would have made more progress on all those fronts, had it not been the case that up to now it was easy to throw more data at the models.
In the past couple of weeks lots of people have been saying the scaling labs have hit the data wall, because of rumors of slowdowns in capabilities improvements. But before that, I was hearing at least some people in those labs saying that they expected to wring another 0.5 - 1 order of magnitude of human-generated training data out of what they had access to, and that still seems very plausible to me (although that would basically be the generation of GPT-5 and peer models; it seems likely to me that the generation past that will require progress on one or more of the fronts I named above).
Taking the globe representation as an example, it is unclear to me how much of the resulting globe (or atlas) is actually the result of choices the authors made. The decision to map distance vectors in two or three dimensions seems to change the resulting representation. So, to what extent are these representations embedded in the model itself versus originating from the author’s mind?
I think that's a reasonable concern in the general case. But in cases like the ones mentioned, the authors are retrieving information (eg lat/long) using only linear probes. I don't know how familiar you are with the math there, but if something can be retrieved with a linear probe, it means that the model is already going to some lengths to represent that information and make it easily accessible.
Replies from: eggsyntax↑ comment by eggsyntax · 2024-11-19T14:27:23.748Z · LW(p) · GW(p)
In the past couple of weeks lots of people have been saying the scaling labs have hit the data wall, because of rumors of slowdowns in capabilities improvements. But before that, I was hearing at least some people in those labs saying that they expected to wring another 0.5 - 1 order of magnitude of human-generated training data out of what they had access to, and that still seems very plausible to me
Epoch's analysis from June supports this view, and suggests it may even be a bit too conservative:
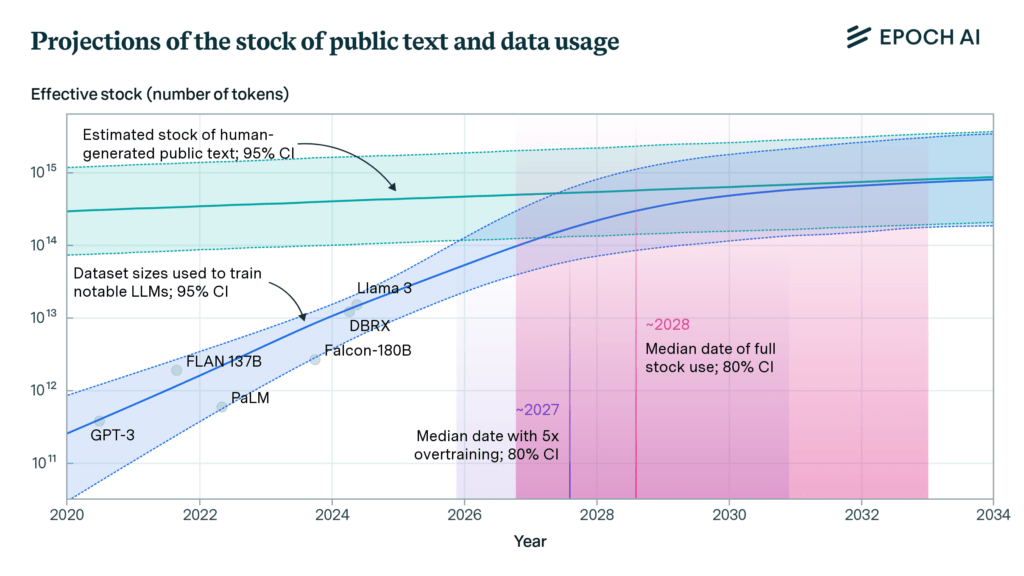
(and that's just for text -- there are also other significant sources of data for multimodal models, eg video)
comment by Noosphere89 (sharmake-farah) · 2024-11-10T15:05:06.526Z · LW(p) · GW(p)
Logan Zollener made a claim referencing a Twitter post which claims that LLMs are mostly simple statistics/prediction machines:
And there's other claims that AI labs progress on AI is slowing down because they can't just scale up data anymore.
I'm not sure whether this is true, but I'll give a lot of Bayes points to @Alexander Gietelink Oldenziel [LW · GW] for predicting a slow down in purely scaling LLMs by data alone, and agree slightly more with the view that scaling alone is probably not enough.
https://www.lesswrong.com/posts/9ffiQHYgm7SKpSeuq/could-we-use-current-ai-methods-to-understand-dolphins#BxNbyvsLpLrAvXwjT [LW(p) · GW(p)]
https://x.com/andrewb10687674/status/1853716840880509402
https://x.com/bingyikang/status/1853635009611219019
https://x.com/Yampeleg/status/1855371824550285331
https://x.com/amir/status/1855367075491107039
Replies from: eggsyntax, alexander-gietelink-oldenziel↑ comment by eggsyntax · 2024-11-11T18:51:19.463Z · LW(p) · GW(p)
As a small piece of feedback, I found it a bit frustrating that so much of your comment was links posted without clarification of what each one was, some of which were just quote-tweets of the others.
Logan Zollener made a claim referencing a Twitter post which claims that LLMs are mostly simple statistics/prediction machines:
Or rather that a particular experiment training simple video models on synthetic data showed that they generalized in ways different from what the researchers viewed as correct (eg given data which didn't specify, they generalized to thinking that an object was more likely to change shape than velocity).
I certainly agree that there are significant limitations to models' ability to generalize out of distribution. But I think we need to be cautious about what we take that to mean about the practical limitations of frontier LLMs.
- For simple models trained on simple, regular data, it's easy to specify what is and isn't in-distribution. For very complex models trained on a substantial fraction of human knowledge, it seems much less clear to me (I have yet to see a good approach to this problem; if anyone's aware of good research in this area I would love to know about it).
- There are many cases where humans are similarly bad at OOD generalization. The example above seems roughly isomorphic to the following problem: I give you half of the rules of an arbitrary game, and then ask you about the rest of the rules (eg: 'What happens if piece x and piece y come into contact?'. You can make some guesses based on the half of the rules you've seen, but there are likely to be plenty of cases where the correct generalization isn't clear. The case in the experiment seems less arbitrary to us, because we have extensive intuition built up about how the physical world operates (eg that objects fairly often change velocity but don't often change shape), but the model hasn't been shown info that would provide that intuition[1]; why, then, should we expect it to generalize in a way that matches the physical world?
- We have a history of LLMs generalizing correctly in surprising ways that weren't predicted in advance (looking back at the GPT-3 paper is a useful reminder of how unexpected some of the emerging capabilities were at the time).
- ^
Note that I haven't read the paper; I'm inferring this from the video summary they posted.
↑ comment by Noosphere89 (sharmake-farah) · 2024-11-11T21:37:19.195Z · LW(p) · GW(p)
I admit that I was a bit of a link poster here, and fair points on the generalization ability of LLMs.
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-11-10T21:46:16.626Z · LW(p) · GW(p)
I am flattered to receive these Bayes points =) ; I would be crying tears of joy if there was a genuine slowdown but
-
I generally think there are still huge gains to be made with scaling. Sometimes when people hear my criticism of scaling maximalism they patternmatch that to me saying scaling wont be as big as they think it is. To the contrary, I am saying scaling further will be as big as you think it will be, and additionally there is an enormous advance yet to come.
-
How much evidence do we have of a genuine slowdown? Strawberry was about as big an advance as gpt3 tp gpt4 in my book. How credible are these twitter rumors?
↑ comment by Noosphere89 (sharmake-farah) · 2024-11-10T21:51:35.968Z · LW(p) · GW(p)
Yeah, I don't trust the Twitter rumors to work out very much, and at any rate, we shall see soon in 2025-2026 what exactly is going on with AI progress if and when they released GPT-5/Orion.
comment by Daniel Tan (dtch1997) · 2024-11-17T13:31:37.018Z · LW(p) · GW(p)
Nice article! I'm still somewhat concerned that the performance increase of o1 can be partially attributed to the benchmarks (blockworld, AGI-ARC) having existed for a while on the internet, and thus having made their way into updated training corpora (which of course we don't have access to). So an alternative hypothesis would simply be that o1 is still doing pattern matching, just that it has better and more relevant data to pattern-match towards here. Still, I don't think this can fully explain the increase in capabilities observed, so I agree with the high-level argument you present.
Replies from: eggsyntax↑ comment by eggsyntax · 2024-11-18T17:47:08.946Z · LW(p) · GW(p)
Great point! In the block world paper, they re-randomize the obfuscated version, change the prompt, etc ('randomized mystery blocksworld'). They do see a 30% accuracy dip when doing that, but o1-preview's performance is still 50x that of the best previous model (and > 200x that of GPT-4 and Sonnet-3.5). With ARC-AGI there's no way to tell, though, since they don't test o1-preview on the fully-private held-out set of problems.
comment by Sohaib Imran (sohaib-imran) · 2024-11-09T15:59:30.659Z · LW(p) · GW(p)
Nice post!
Regarding o1 like models: I am still unsure how to draw the boundary between tasks that see a significant improvement with o1 style reasoning and tasks that do not. This paper sheds some light on the kinds of tasks that benefit from regular COT. However, even for mathematical tasks, which should benefit the most from CoT, o1-preview does not seem that much better than other models on extraordinarily difficult (and therefore OOD?) problems. I would love to see comparisons of o1 performance against other models in games like chess and Go.
Also, somewhat unrelated to this post, what do you and others think about x-risk in a world where explicit reasoners like o1 scale to AGI. To me this seems like one of the safest forms of AGI, since much of the computation is happening explicitly, and can be checked/audited by other AI systems and humans.
Replies from: eggsyntax, sharmake-farah↑ comment by eggsyntax · 2024-11-10T00:59:46.020Z · LW(p) · GW(p)
o1-preview does not seem that much better than other models on extraordinarily difficult (and therefore OOD?) problems.
@Noosphere89 [LW · GW] points in an earlier comment to a quote from the FrontierMath technical report:
...we identified all problems that any model solved at least once—a total of four problems—and conducted repeated trials with five runs per model per problem (see Appendix B.2). We observed high variability across runs: only in one case did a model solve a question on all five runs (o1-preview for question 2). When re-evaluating these problems that were solved at least once, o1-preview demonstrated the strongest performance across repeated trials (see Section B.2).
I would love to see comparisons of o1 performance against other models in games like chess and Go.
I would also find that interesting, although I don't think it would tell us as much about o1's general reasoning ability, since those are very much in-distribution.
Also, somewhat unrelated to this post, what do you and others think about x-risk in a world where explicit reasoners like o1 scale to AGI. To me this seems like one of the safest forms of AGI, since much of the computation is happening explicitly, and can be checked/audited by other AI systems and humans.
I agree that LLMs in general look like a simpler alignment problem than many of the others we could have been faced with, and having explicit reasoning steps seems to help further. I think monitoring still isn't entirely straightforward, since
- CoT can be unfaithful to the actual reasoning process.
- I suspect that advanced models will soon (or already?) understand that we're monitoring their CoT, which seems likely to affect CoT contents.
- I would speculate that if such models were to become deceptively misaligned, they might very well be able to make CoT look innocuous while still using it to scheme.
- At least in principle, putting optimization pressure on innocuous-looking CoT could result in models which were deceptive without deceptive intent [LW · GW].
But it does seem very plausibly helpful!
Replies from: sharmake-farah, sohaib-imran↑ comment by Noosphere89 (sharmake-farah) · 2024-11-10T16:40:13.878Z · LW(p) · GW(p)
I definitely agree that COT interpretability isn't the end of the story, but to respond to this:
I agree that LLMs in general look like a simpler alignment problem than many of the others we could have been faced with, and having explicit reasoning steps seems to help further. I think monitoring still isn't entirely straightforward, since
CoT can be unfaithful to the actual reasoning process. I suspect that advanced models will understand that we're monitoring their CoT, which seems likely to affect them. I would speculate that if such models were to become deceptively misaligned, they might very well be able to make CoT look innocuous while still using it to scheme. At least in principle, putting optimization pressure on innocuous-looking CoT could result in models which were deceptive without deceptive intent.
I agree with 1, which is why the COT will absolutely have to be faithful.
I agree with 2, but conditional on relatively weak forward passes, and most of the bottleneck to reasoning being through the COT, there is little the model can do about the situation, short of exfiltrating itself, which is likely to be caught if we look for it in COT, since they can't take over without the COT reasoning.
I also disagree with 3, at least assuming relatively weak forward passes, and the bottleneck to reasoning being largely through COT, but this is a plausible enough threat model that we can't rely solely on COT.
I basically disagree with 4, because I'm in general skeptical of deep deception threat models, both because I think that we may well be able to prevent self-exfiltration of the model such that it doesn't get much more compute to get more power, and in general I think at least in the early years of AGI there will be little ability to externalize compute/cognition beyond the server in which the model lives, for somewhat similar but also different reasons as to why I don't expect open-source to matter much in AI takeoff.
Replies from: eggsyntax↑ comment by eggsyntax · 2024-11-11T20:26:48.236Z · LW(p) · GW(p)
I agree with 1, which is why the COT will absolutely have to be faithful.
That does sound ideal if we can figure out a way to achieve it (although it seems plausible that if we have good enough interpretability to judge whether CoT is faithful, we won't really need the CoT in the first place).
I agree with 2, but conditional on relatively weak forward passes, and most of the bottleneck to reasoning being through the COT, there is little the model can do about the situation, short of exfiltrating itself...
I also disagree with 3, at least assuming relatively weak forward passes, and the bottleneck to reasoning being largely through COT
I don't have a very well-developed argument here, but intuitively I think there are many simple ways for the model to shape its output in ways that provide its later forward passes with more than 0.0 bits of information which are useful to itself but which aren't legible to monitors, and those can accumulate over the course of an extended context.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-11-11T21:50:42.703Z · LW(p) · GW(p)
That does sound ideal if we can figure out a way to achieve it (although it seems plausible that if we have good enough interpretability to judge whether CoT is faithful, we won't really need the CoT in the first place).
Good point, I haven't thought about interpretability strong enough to not need CoT.
I don't have a very well-developed argument here, but intuitively I think there are many simple ways for the model to shape its output in ways that provide its later forward passes with more than 0.0 bits of information which are useful to itself but which aren't legible to monitors, and those can accumulate over the course of an extended context.
There will be more than 0.0 bits on attempting to takeover, assuming the AI is misaligned, but the key difficulty here is that takeover is still hard, at least without a rogue deployment, and while we might not be able to prevent steganography from occurring at all, we could well limit the ability to do this such that key takeover steps are bottlenecked through COT, which we can intervene on.
↑ comment by Sohaib Imran (sohaib-imran) · 2024-11-10T11:05:13.014Z · LW(p) · GW(p)
Thanks for the reply.
Yes, I did see that paragraph in the paper. My point was I intuitively expected it to be better still. O1-preview is also tied with claude 3.5 sonnet on simplebench and also arc-agi, while using a lot more test time compute. However this is their first generation of reasoning models so any conclusions may be premature.
Re CoT monitoring:
Agree with 4, it will defeat the purpose of explicit CoTs.
Re. 1, I think outcomes based RL (with some penalty for long responses) should somewhat mitigate this problem, at least if NAH is true?
Re 2-3, Agree unless we use models that are incapable of deceptive reasoning without CoT (due to number of parameters or training data). Again would love to see more rigorous research on this. That way any deceptive reasoning has to be through the CoT and can be caught. I suspect such reasoners may not be as good as reasoners using larger models though so this may not work. (o1-mini is quite worse than o1 preview and even sonnet on many tasks).
Replies from: eggsyntax↑ comment by eggsyntax · 2024-11-11T20:03:22.522Z · LW(p) · GW(p)
Re. 1, I think outcomes based RL (with some penalty for long responses) should somewhat mitigate this problem, at least if NAH is true?
Can you say more? I don't think I see why that would be.
Re 2-3, Agree unless we use models that are incapable of deceptive reasoning without CoT (due to number of parameters or training data).
Intuitively it seems like CoT would have to get a couple of OOMs more reliable to be able to get a competitively strong model under those conditions (as you point out).
Replies from: sohaib-imran↑ comment by Sohaib Imran (sohaib-imran) · 2024-11-12T10:50:54.180Z · LW(p) · GW(p)
Can you say more? I don't think I see why that would be.
When we ask whether some CoT is faithful, we mean something like: "Does this CoT allow us to predict the LLM's response more than if there weren't a CoT?"
The simplest reason I can think of for why CoT improves performance yet doesn't allow predictability is that the improvement is mostly a result of extra computation and the content of the CoT does not matter very much, since the LLM still doesn't "understand" the Cot it produces the same way we do.
If you are using outcomes-based RL with a discount factor ( in ) or some other penalty for long responses, there is optimisation pressure towards using the abstractions in your reasoning process that most efficiently get you from the input query to the correct response.
NAH implies that the universe lends itself to natural abstractions, and therefore most sufficiently intelligent systems will think in terms of those abstractions. If the NAH is true, those abstractions will be the same abstractions that other sufficiently intelligent systems (humans?) have converged towards, allowing these systems to interpret each other's abstractions.
I naively expect o1's CoT to be more faithful. It's a shame that OpenAI won't let researchers access o1 CoT; otherwise, we could have tested it (although the results would be somewhat confounded if they used process supervision as well).
Replies from: eggsyntax↑ comment by eggsyntax · 2024-11-12T17:19:52.131Z · LW(p) · GW(p)
Interesting, thanks, I'll have to think about that argument. A couple of initial thoughts:
When we ask whether some CoT is faithful, we mean something like: "Does this CoT allow us to predict the LLM's response more than if there weren't a CoT?"
I think I disagree with that characterization. Most faithfulness researchers seem to quote Jacovi & Goldberg: 'a faithful interpretation is one that accurately represents the reasoning process behind the model’s prediction.' I think 'Language Models Don’t Always Say What They Think' shows pretty clearly that that differs from your definition. In their experiment, even though actually the model has been finetuned to always pick option (A), it presents rationalizations of why it picks that answer for each individual question. I think if we looked at those rationalizations (not knowing about the finetuning), we would be better able to predict the model's choice than without the CoT, but it's nonetheless clearly not faithful.
If the NAH is true, those abstractions will be the same abstractions that other sufficiently intelligent systems (humans?) have converged towards
I haven't spent a lot of time thinking about NAH, but looking at what features emerge with sparse autoencoders makes it seem like in practice LLMs don't consistently factor the world into the same categories that humans do (although we still certainly have a lot to learn about the validity of SAEs as a representation of models' ontologies).
It does seem totally plausible to me that o1's CoT is pretty faithful! I'm just not confident that we can continue to count on that as models become more agentic. One interesting new datapoint on that is 'Targeted Manipulation and Deception Emerge when Optimizing LLMs for User Feedback' [LW · GW], where they find that models which behave in manipulative or deceptive ways act 'as if they are always responding in the best interest of the users, even in hidden scratchpads'.
Replies from: ann-brown↑ comment by Ann (ann-brown) · 2024-11-12T18:31:12.025Z · LW(p) · GW(p)
I'm a little confused what you would expect a faithful representation of the reasoning involved in fine-tuning to always pick A to look like, especially if the model has no actual knowledge it has been fine-tuned to always pick A. Something like "Chain of Thought: The answer is A. Response: The answer is A"? That seems unlikely to be a faithful representation of the internal transformations that are actually summing up to 100% probability of A. (There's some toy models it would be, but not most we'd be testing with interpretability.)
If the answer is always A because the model's internal transformations carry out a reasoning process that always arrives at answer A reliably, in the same way that if we do a math problem we will get specific answers quite reliably, how would you ever expect the model to arrive at the answer "A because I have been tuned to say A?" The fact it was fine-tuned to say the answer doesn't accurately describe the internal reasoning process that optimizes to say the answer, and would take a good amount more metacognition.
↑ comment by eggsyntax · 2024-11-12T19:06:55.792Z · LW(p) · GW(p)
Interesting question! Maybe it would look something like, 'In my experience, the first answer to multiple-choice questions tends to be the correct one, so I'll pick that'?
It does seem plausible on the face of it that the model couldn't provide a faithful CoT on its fine-tuned behavior. But that's my whole point: we can't always count on CoT being faithful, and so we should be cautious about relying on it for safety purposes.
But also @James Chua [LW · GW] and others have been doing some really interesting research recently showing that LLMs are better at introspection than I would have expected (eg 'Looking Inward'), and I'm not confident that models couldn't introspect on fine-tuned behavior.
↑ comment by Noosphere89 (sharmake-farah) · 2024-11-09T17:13:24.659Z · LW(p) · GW(p)
I think that the main conclusion is that large amounts of compute are still necessary in reasoning well OOD, and even though o1 is doing a little reasoning, it's a pretty small scale search (usually seconds or minutes of search.), which means that the fact that it's a derivative GPT-4o model matters a lot for it's incapacity, as it's pretty low on the compute scale compared to other models.
Replies from: eggsyntax↑ comment by eggsyntax · 2024-11-10T00:44:16.879Z · LW(p) · GW(p)
as it's pretty low on the compute scale compared to other models.
Can you clarify that? Do you mean relative to models like AlphaGo, which have the ability to do explicit & extensive tree search?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-11-10T00:52:25.421Z · LW(p) · GW(p)
I think GPT-4o is a distilled version of GPT-4, and I'm comparing it to GPT-4 and Claude Sonnet.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-11-10T01:52:22.223Z · LW(p) · GW(p)
I think GPT-4o is a distilled version of GPT-4
Original GPT-4 is rumored to have been a 2e25 FLOPs model (trained on A100s). Then there was a GPT-4T, which might've been smaller, and now GPT-4o. In early 2024, 1e26 FLOPs doesn't seem out of the question, so GPT-4o was potentially trained on 5x compute of original GPT-4.
There is a technical sense of knowledge distillation[1] where in training you target logits of a smarter model rather than raw tokens. It's been used for training Gemma 2 and Llama 3.2. It's unclear if knowledge distillation is useful for training similarly-capable models, let alone more capable ones, and GPT-4o seems in most ways more capable than original GPT-4.
See this recent paper for example. ↩︎
↑ comment by Noosphere89 (sharmake-farah) · 2024-11-10T03:52:22.912Z · LW(p) · GW(p)
Maybe GPT4-o does use more compute than GPT-4, though given that it's a cheap model for the end user, I wouldn't really expect that to happen.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-11-10T04:12:32.175Z · LW(p) · GW(p)
Cost of inference is determined by the shape of the model, things like the number of active parameters, which screens off compute used in training (the compute could be anything, cost of inference doesn't depend on it as long as the model shape doesn't change).
So compare specific prices with those of models with known size[1]. GPT-4o costs $2.5 per million input tokens, while Llama-3-405B costs $3.5 per million input tokens. That is, it could be a 200-300B model (in active parameters). Original GPT-4 is rumored to be about 270B active parameters (at 1.8T total parameters). It's OpenAI, not an API provider for an open weights model, so in principle the price could be misleading (below cost), but what data we have points to it being about the same size, maybe 2x smaller if there's still margin in the price.
Edit: There's a mistake in the estimate [LW(p) · GW(p)], I got confused between training and inference. Correcting the mistake points to even larger models, though comparing to Llama-3-405B suggests that there is another factor that counterbalances the correction, probably practical issues with getting sufficient batch sizes, so the original conclusion should still be about right.