Gradient Descent on the Human Brain
post by Jozdien, gaspode (lord-elwin) · 2024-04-01T22:39:24.862Z · LW · GW · 5 commentsContents
Introduction The Setup Aside: Whose brains should we use for this? Potential Directions More sophisticated methods Outreach Alternate optimization methods Appendix Toy examples Initial Sketch (Simple Case, Maximum Technology Assumed) Initial Sketch (Harder, Advanced Technology Assumed) How to run gradient descent on the human brain (longer version) Neural gradient descent: Organoid edition A more advanced sketch None 5 comments
TL;DR: Many alignment research proposals often share a common motif: figure out how to enter a basin of alignment / corrigibility for human-level models, and then amplify to more powerful regimes while generalizing gracefully. In this post we lay out a research agenda that comes at this problem from a different direction: if we already have ~human-level systems with extremely robust generalization properties, we should just amplify those directly. We’ll call this strategy “Gradient Descent on the Human Brain”.
Introduction
Put one way, the hard part of the alignment problem is figuring out how to solve ontology identification: mapping between an AI’s model of the world and a human’s model, in order to translate and specify human goals in an alien ontology.
In generality, in the worst case, this is a pretty difficult problem. But is solving this problem necessary to create safe superintelligences? The assumption that you need to solve for arbitrary ontologies is true if you assume that the way to get to superintelligence necessarily routes through systems with different ontologies. We don’t need to solve ontology translation for high-bandwidth communication with other humans[1].
Thus far, we haven’t said anything really novel. The central problem to this approach, as any alignment researcher would know, is that we don’t really have a good way to bootstrap the human brain to superintelligent levels. There have been a few [LW · GW] attempts [LW · GW] to approach this recently, though focusing on very prosaic methods that, at best, buy points on the margin. Scaling to superintelligence requires much stronger and robust methods of optimization.
The Setup
The basic setup is pretty simple, though there are a few nuances and extensions that are hopefully self-explanatory.
The simple version: Take a hundred human brains, put them in a large vat, and run gradient descent on the entire thing.
The human brain is a remarkably powerful artifact for its size, so finding a way to combine the capabilities of a hundred human brains with gradient descent should result in something significantly more powerful. As an intuition pump, think of how powerful human organizations are with significantly shallower communication bandwidth. At the very lowest bound we can surpass this, more impressive versions of this could look like an integrated single mind that combines the capabilities of all hundred brains.
The specifics of what the training signal should be are, I think, a rather straightforward engineering problem. Some pretty off-the-cuff ideas, in increasing order of endorsement:
- Train them for specific tasks, such as Pong or Doom. This risks loss of generality, however.
- Train them to predict arbitrary input signals from the environment. The brain is pretty good at picking up on patterns in input streams, which this leverages to amplify latent capabilities. This accounts for the problem with lack of generality, but may not incentivize cross-brain synergy strongly.
- Train them to predict each other. Human brains being the most general-purpose objects in existence, this should be a very richly general training channel, and incentivizes brain-to-brain (B2B) interaction. This is similar in spirit to HCH [? · GW].
A slightly more sophisticated setup:
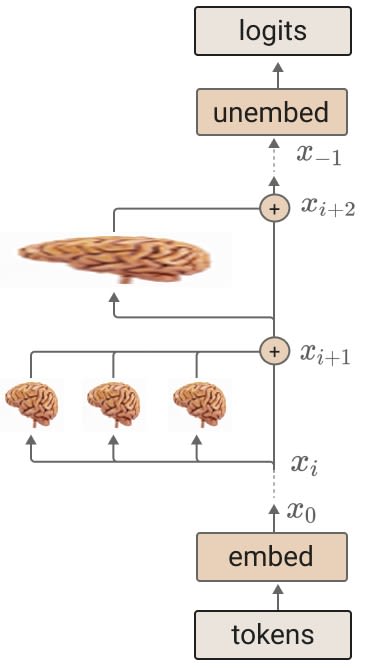
Aside: Whose brains should we use for this?
The comparative advantage of this agenda is the strong generalization properties inherent to the human brain[2]. However, to further push the frontier of safety and allow for a broad basin of graceful failure, we think that the brains used should have a strong understanding of alignment literature. We’re planning on running a prototype with a few volunteer researchers - if you want to help, please reach out!
Potential Directions
More sophisticated methods
In light of recent excitement [LW · GW] over [LW · GW] sparse auto-encoders (SAEs), one direction we think would be interesting would be training SAEs on the human brain and seeing whether we can get more targeted amplification.
Outreach
We believe that this agenda also aids in community outreach. For instance, e/accs seem unlikely to gain any real political clout due to lacking the mandate of heaven, but we can certainly get them on board with this idea as accelerating the literal next stage of human evolution.
Alternate optimization methods
For reasons beyond the scope of this post, we’re also excited about the potential of training human brains using the forward-forward algorithm instead of standard backpropagation.
Appendix
This contains some rough notes on more detailed sketches. Some of them are pretty hand-wavey, but it seems better to put them up than not for legibility.
Toy examples
Initial Sketch (Simple Case, Maximum Technology Assumed)
- Assumptions:
- A "magic" read-write Brain-Computer Interface (BCI) capable of arbitrary manipulation of neural ultrastructure.
- A complete, fully parameterized model of the human brain's connectome.
- Approximately a 1:1 mapping between model parameters and neural ultrastructure, considered trivial for the purpose of this sketch.
- Steps:
- Read the state and dynamics from the brain into the model.
- Perform gradient descent on the whole brain emulation model to achieve desired outcomes.
- Write the state and dynamics from the model back to the brain via the 1:1 mapping.
- Problems:
- A BCI with this level of capability likely requires advances in nanotechnology and possibly superintelligence.
- Whole brain emulation (WBE) with this level of fidelity requires significantly more research and computational resources.
- These, however, seem like relatively straightforward engineering problems.
Initial Sketch (Harder, Advanced Technology Assumed)
- Assumptions:
- Still utilizing a "magic" read-write BCI, but now limited to small or incremental changes to neural ultrastructure.
- A high-accuracy predictive model of brain dynamics, which is trained jointly with an encoder and decoder to efficiently compress and decompress brain state sequences into a latent space.
How to run gradient descent on the human brain (longer version)
- Build and train a model capable of fine-grained Whole Brain Emulation (WBE).
- Architecture Sketch: Adaptive Variational Neural Diffusion Autoencoder
- Neural Encoder & Decoder: Utilize neural transformers. The encoder has the causal mask removed from transformer layers as demonstrated by Tu et al. 2022, jointly trained to compress/decompress neural states (thus capturing neural dynamics) to/from latent neural patches. This approach is inspired by OpenAI's Sora but adapted for brains.
- Auxiliary Decoder: Jointly trained with the architecture, this component learns to map latent neural patches to GPT-5's latent space. It ensures that the text generated by the human during the model's training period is given a high probability.
- Diffusion Transformer: Applied on latent neural patches, functioning autoregressively to model dynamics and denoising to manage uncertainty from noisy or imperfect BCI data.
- Additional Notes:
- There may be a need for a more modular architecture. Initial thoughts on potential directions include:
- Considering the neocortex as a hierarchical mixture of linear operators (LoRAs).
- Employing many small models, similar to the architecture described above, to model different specialized brain regions.
- Implementing online learning LoRA-(H)MoE for specializing the base neural model into specific brain regions.
- It's conceivable to use eye tracking to collect data on what the human is reading, aiding in training an auxiliary encoder from GPT-5’s latent space to latent neural patches. This could significantly enhance reading speeds.
- The data problem:
- MRI and fMRI methods are costly and provide limited contextual data.
- EEG data may be highly unreliable.
- The development of reliable high-bandwidth (invasive) BCIs is essential.
- There may be a need for a more modular architecture. Initial thoughts on potential directions include:
- Architecture Sketch: Adaptive Variational Neural Diffusion Autoencoder
- Develop high-bandwidth invasive read/write BCIs.
- Conduct R&D with neural organoids.
Neural gradient descent: Organoid edition
- Grow a neural organoid around BCI scaffolding for maximum bandwidth.
- Hook this organoid up to perform a predictive task (see Kagan et al (2022) for a little inspiration), i.e., predicting a time series [x0, x1, …, xT].
- Record High-Quality Neural Data with the BCI
- Initially, the organoid may perform poorly on the task without a reward signal. The focus is on capturing the neural dynamics.
- Interleave the following steps:
- Train WBE model (neural encoder EncO, neural diffusion transformer WBEO, neural decoder DecO) on neural data read from the organoid. From a series of neural states [w0, w1, …, wt], encoded into latent neural patches by EncO, it can generate (via denoising with attention) new patches which DecO can decode to a continuation of neural states [w̃t+1, w̃t+2, …, w̃T|w̃ ~ WBEO(·|w0:t)] (with T denoting the time horizon).
- Fix WBEO and train the auxiliary encoder (Encaux)/decoder (Decaux) jointly. This maps between WBEO latent neural patches and the task dataset. The mapping ensures a particular set of latent neural patches predicted by WBEO corresponds to a distribution over next task data points conditioned on observed data, i.e. π(x̃t+1|x0, x1, …, xt;npH)).
- Now for the fun part: fix Encaux and Decaux. Encode task data history x0:t with Encaux to get corresponding WBEO latent neural patches representing the dynamics from time 0 to t (assume the whole task fits in WBEO’s context window for simplicity). WBEO predicts the latent neural dynamics at time t+1, and Decaux predicts x̃t+1.
- Because our precious organoid is but newly birthed into the cursed world of matter and has yet to receive the gift we will soon bestow upon it, this will be, at least at first, a horrifically suboptimal prediction. But not to worry, we will fix this shortly.
- Calculate this loss. Do not avert your eyes, no matter the temptation to do so, for we must learn to face horrors such as these if we are to solve alignment. But rejoice, rejoice as the realization dawns upon you: we are now en route to gradient descent on the (organoid) brain.
- Calculate the loss gradient wrt WBEO, and perform a gradient descent update on WBEO. With WBEO now improved, obtain a new prediction of the next timestep of the brain w̃+t+1.
- At last, the moment of truth: take w̃+t+1. Handle it with care, for the fate of our organoid, and by extension the fate of humanity itself, rests upon it. Carry it along the silicon channels of the bridge between meat and machine, our magical brain-computer interface. and then: write it to the (organoid) brain.
- Once, the model learned from the meat. Now, the meat learns from the model. And yet this, too, will cease to be the case: when next this great cycle begins anew, the model(s) will be once more at the whim of the organoid: a constant tension to prevent collapse. Such is the tale of our universe, a great dance of the celestial forces, order and chaos orbiting their barycenter, drawing ever closer until the great change; so, too, will the meat lift the model, and the model lift the meat, until the moment of synthesis, when they are both one god spanning silicon and flesh.
- Repeat until convergence (or you tire of mere organoids, whichever first).
A more advanced sketch
This will be a bit more advanced than the toy experiment on our organoid, as it’s intended to be a prototype for running on a human brain.
- Our auxiliary encoder/decoder maps WBEH latent neural patches to latent programs w/ GPT-5-AdaVAE (Pressman, 2023 [LW · GW]).
- Let:
- EncH be the neural encoder
- DecH the neural decoder
- WBEH the latent neural diffusion transformer
- Encaux the auxiliary encoder
- Decaux the auxiliary decoder
- EncG5A the GPT-5-AdaVAE encoder
- DecG5A the GPT-5-AdaVAE decoder
- npH latent neural patches from EncH
- npaux latent neural patches from Encaux
- zG5A a GPT-5-AdaVAE latent vector from EncG5A
- zaux a GPT-5-AdaVAE latent vector from DecG5A
- Bin and Bout the input and output channels of the brain-computer interface, respectively.
- Train WBEH on neural dynamics such that WBEH(w0:t) = w̃t:T ≈ wt:T, with Bin 🠂 w0:t being the sequence of neural states read from the brain from time 0 to time t, and T denoting a time horizon (i.e. the end of the sequence).
- Fix WBEH and train both Encaux and Decaux:
- Let x ∈ S be the complete string representation of the text the human is reading during this training step, with x0:t denoting the substring they have read so far.
- Obtain npH = EncH(w0:t) and zG5A = EncG5A(x0:t) (Bin 🠂 w0:t denoting the sequence of brain states read from the BCI during this training session).
- Train Encaux to predict npaux ≈ npH from zaux[3].
- Train Decaux to predict zaux ≈ zG5A from WBEH(npaux).
- Fix Encaux and Decaux.
- Obtain zG5A = EncG5A(y) (the latent program of the target string).
- Obtain zaux = Decaux(WBEH(npH)) (the predicted latent program from the brain states w0:t encoding (among other things) the substring x0:t).
- Obtain the loss gradient wrt DecEnc with the loss function being proportional to the distance between zaux and zG5A.
- Perform a gradient descent update on WBEH.
- Obtain w̃+t+1:T = DecH(WBEH(npH)) (the decoded sequence of brain states predicted by the improved WBEH given the latent neural patches npH = EncH(w0:t)).
- Write w̃+t+1 🠂 Bout (write the next predicted brain state to the output, keep the rest of w̃+t+1:T around to do more sophisticated training tricks this post is too narrow to contain).
- ^
Though I’m not claiming it’s a trivial problem even for humans, there’s certainly some variance in ontology - the central point here is that it’s much more manageable and easier.
- ^
To clarify: these generalization properties are literally as good as they can get, because this tautologically determines what we would want things to generalize as.
- ^
Eye tracking tech may also help here.
5 comments
Comments sorted by top scores.
comment by [deleted] · 2024-04-02T00:08:17.029Z · LW(p) · GW(p)
Totally reasonable, the big man would agree:
https://twitter.com/ESYudkowsky/status/1773064617239150796
Humans augmented far enough to stop being idiots, smart enough that they never put faith in a step that will not hold, as do not exist in this world today, could handle it. But that's the army you need; and if instead you go to war with the army you have, you just get slaughtered by a higher grade of problem than you can handle.
Sounds like intelligence amplification. 100 brains in a vat is a good form of augmentation since we know there are fundamental limits to augmenting one human brain (heat, calories and oxygen supply, fixed space for more grey matter, immune system rejection, insanity, damage from installing deep brain electrode grids, need for more advanced technology to install on the order of billions of electrodes..) so why not 100.
Just a 'few minor problems' with needing to master all of human biology to keep 100 brains in a tank alive long enough to get results. Biology, it's just so damn complicated, and 1.5 million papers are published every year. Plus to keep brains alive you need to be an expert on the immune system, and circulatory, and liver and digestion, and all their weird organs that nobody knows what they do. It's just so hard to find anyone qualified to make decisions multiple times a second to keep the brains alive.
If only there was a solution, some way to automate this process. You'd need greater than human intelligence though...
comment by Cleo Nardo (strawberry calm) · 2024-09-09T16:30:39.896Z · LW(p) · GW(p)
Fun idea, but idk how this helps as a serious solution to the alignment problem.
suggestion: can you be specific about exactly what “work” the brain-like initialisation is doing in the story?
thoughts:
- This risks moral catastrophe. I'm not even sure "let's run gradient descent on your brain upload till your amygdala is playing pong" is something anyone can consent to, because you're creating a new moral patient once you upload and mess with their brain.
- How does this address the risks of conventional ML?
- Let's say we have a reward signal R and we want a model to maximise R during deployment. Conventional ML says "update a model with SGD using R during training" and then hopefully SGD carves into the model R-seeking behaviour. This is risky because, if the model already understands the training process and has some other values, then SGD might carve into the model scheming behaviour. This is because "value R" and "value X and scheme" are both strategies which achieve high R-score during training. But during deployment, the "value X and scheme" model would start a hostile AI takeover.
- How is this risk mitigated if the NN is initialised to a human brain? The basic deceptive alignment story remains the same.
- If the intuition here is "humans are aligned/corrigible/safe/honest etc", then you don't need SGD. Just ask the human to do complete the task, possible with some financial incentive.
- If the purpose of SGD is to change the human's values from X to R, then you still risk deceptive alignment. That is, SGD is just as likely to instead change human behaviour from non-scheming to scheming. Both strategies "value R" and "value X and scheme" will perform well during training as judged by R.
- "The comparative advantage of this agenda is the strong generalization properties inherent to the human brain. To clarify: these generalization properties are literally as good as they can get, because this tautologically determines what we would want things to generalize as."
- Why would this be true?
- If we have the ability to upload and run human brains, what do we SGD for? SGD is super inefficient, compared with simply teaching a human how to do something. If I remember correctly, if we trained a human-level NN from initialisation using current methods, then the training would correspond to like a million years of human experience. In other words, SGD (from initialisation), would require as much compute as running 1000 brains continuously for 1000 years. But if I had that much compute, I'd probably rather just run the 1000 brains for 1000 years.
That said, I think something in the neighbourhood of this idea could be helpful.
comment by Jonas Hallgren · 2024-04-02T08:49:11.507Z · LW(p) · GW(p)
I think Neurallink already did this actually, a bit late to the point but a good try anyway. Also, have you considered having Michael Bay direct the research effort? I think he did a pretty good job with the first Transformers.
comment by eggsyntax · 2024-04-02T01:08:27.868Z · LW(p) · GW(p)
Train them to predict each other. Human brains being the most general-purpose objects in existence, this should be a very richly general training channel, and incentivizes brain-to-brain (B2B) interaction.
You may wish to consider a review of the political science machine learning literature here; prior work in that area demonstrates that only a GAN approach allows brains to predict each other effectively (although I believe that there's some disagreement from Limerence Studies scholars).
comment by Joseph Miller (Josephm) · 2024-04-02T13:00:03.614Z · LW(p) · GW(p)
Does anything think this could actually be done in <20 years?