Twitter Twitches
post by Zvi · 2023-07-04T13:00:06.111Z · LW · GW · 9 commentsContents
Well You See What Happened Was… The Plan Oh No, That’s Not the Reason, Except It Is People Dealing With It Other Twitter News General Twitter Outlook Going Forward None 9 comments
The situation is evolving rapidly. Here’s where we stand as of the morning of July 4th.
Well You See What Happened Was…
Oh no! To be clear, by twitches, I mean ‘Elon refused to pay the cloud bill.’
As a result, Twitter has been forced to rate limit users.
- This started out as 600 posts per day for most accounts, 300 posts per day for new accounts and 6,000 posts per day for those who pay.
- This is now up to 1k/500/10k according to one Musk tweet.
- If you are not logged in, you get nothing. Even direct links will break.
- Tweetdeck has been forced into a new worse version, but now works again. In 30 days, this will be for paid accounts only, which seems fair.
That fourth one hurts my process. Navigation is somewhat slower and more annoying. In particular, forced threading breaks chronological order assumptions and one’s ability to use duplication to locate one’s place, and zooming in to move around twisting Twitter threads is so bad you need to jump to Twitter itself. Navigation to zoom back requires clicking in annoying places. I was unable to configure the column order without deleting them all and then creating them again, although this was quick. Column width and monitor real estate use is screwed up in subtle ways. Oh, and now its settings are linked to Twitter’s even though I want them to be different. Sheesh.
Another little thing is that the tab icon is now identical to Twitter’s. So annoying.
This is still vastly better than the period where Tweetdeck stopped working.
The third is brutal for some of my readers. Many report they can’t view any links.
What to do, if this doesn’t end soon?
The Plan
Three parts: How I will deal with processing info, how I will change how I present info, and how you can adjust to the new situation.
- The efficiency hit on my end is unavoidable. I’ll make three adjustments.
- I’ll check Twitter less often, rely more on other sources.
- I’ll raise the bar somewhat for what is worth including or investigating.
- I’ll shift some people from lists to follows and eliminate duplicates.
- The inability for viewers to see Twitter links means moving away from them.
- I’ll more often quote more of the relevant Twitter threads.
- I’ll link directly to the primary source first whenever possible.
- If you don’t have a Twitter account, you have a choice to make.
- Having an account with zero connections fixes links. Consider that.
- If you simply can’t do that responsibly, so be it, and I’ll write the posts such that this does not cause any showstopper issues.
- Most of you almost never clicked the links anyway.
- What I will not do is join BlueSky or another Twitter alternative. We are still far from where that would make sense.
Also, clarifying some policies on how Twitter threads work here.
- I will silently correct capitalization and spelling and other obvious errors.
- I will reformat as makes sense for the new context, again silently, if the words themselves need to change I will use [brackets].
- I use your real name if I know it, your handle if that’s all I have.
- I will use judgment on ordering and when to provide detail on structure.
- For a quote tweet, I use the order that seems right to me – sometimes the intention is that the reader will see the quoted tweet only after, despite it happening earlier in time.
- For multiple different replies, I will make that clear if it is ambiguous.
- A link generally indicates a new thread of some kind.
Oh No, That’s Not the Reason, Except It Is
This Maggie Johnson-Pint thread offers a cool explanation of what else might have caused this situation, written before we knew the answer.
Twitter owner Musk explains, with a different justification than the real one:
Twitter Daily News: NEWS: Twitter’s web version no longer allows users to browse without logging in. All urls redirect to the signup page.
This is believed to be a measure to make it harder for scrapers to take Twitter’s data, like ChatGPT’s web browsing plugin has been doing.
Elon Musk: Temporary emergency measure. We were getting data pillaged so much that it was degrading service for normal users!
Three obvious responses.
- No, it wasn’t.
- There are many much better solutions to that problem.
- This happened exactly one day after failing to pay your cloud computing bill.
Some people pointing out the obvious, links signify distinct threads:
Paul Graham, who may or may not have thought through the implications: Surely someone who can figure out how to build spaceships can figure out how to distinguish scrapers from legit users. The patterns must be so different.
Richard Nixon: Yes, well.
Kilgore Trout (blue social): What an incredible coincidence that your website broke exactly one day after refusing to pay the billion dollar bill you owed.
[He quotes unknown source]: More platform instability could be in Twitter’s near future. In 2018, Twitter signed a $1 billion contract with Google to host some of its services on the company’s Google Cloud servers. Platformer reports Twitter recently refused to pay the search giant ahead of the contract’s June 30th renewal date. Twitter is reportedly rushing to move as many services off of Google’s infrastructure [first].
Kareem Carr: Rate limiting starts the day their cloud contract (that they were having trouble paying) ends. That can’t be a coincidence right? Twitter might be much closer to dying than most of us realize.
Robin Safaya: Ok so I’m a Data Analytics Manager. Our tech stack is on an AWS S3 cluster. Let me explain in plain English for y’all how absofuckinglutely b.s. Elon’s claim is. First, you don’t prevent scraping by cutting off your own app’s access to its OWN database.
However… Let’s say you are a huge platform on AWS, like Twitter is, and you aren’t paying your bill. The first thing they’re going to do is meter your usage, then they’re going to throttle your usage. So, what Elon is really admitting is that he DIDN’T PAY HIS F–KING AMAZON BILL.
One more thing… you can get around some of the problem by sending yourself direct links to tweets so they load individually instead of your entire timeline. Like this:
Will Eden: We are learning so much from the Twitter experiment. For example, a company can survive not paying for employees, but it cannot survive not paying for cloud servers.
People Dealing With It
There is no way to see how close you are to the rate limit.
Jennifer RM: I logged in because I heard Twitter had collapsed, and I’m on a “use it until the quota runs out” spree. When will I hit the limits? It is a mystery!! Weeee!
bmt: I don’t know either, it’s all quite exciting.
wife_geist: [blinking and crying in the sun] yeah the cave guys only let me see 600 flickering shadows a day now. There’s another cave but it kind of sucks. I’m going to go back down again tomorrow.
A strange dynamic is how many people complained about the rate limit being too low for them, yet did not think getting around this was worth $8.
Geoffrey Miller: So many guys spending 3 hours a day on Twitter but aren’t willing to pay 8 bucks a month for a checkmark. Dude that’s less than 10 cents an hour. Get over yourself. Act like you’re employed & pay up.
Max: the humiliation of considering paying for Twitter to scroll my addiction is giving me a smidge of empathy for the bros who pay for sex.
There are also other benefits to paying, which now include Tweetdeck. That can now be used as a justification, avoiding stigma or looking silly. Which is a dumb worry. If people are going to treat you badly because you are paying a reasonable price to improve your experience of a valuable product you are both using a lot? Screw ‘em.
Alexander Hayne: If you’ve found yourself unfollowed or blocked, I’m sorry but when I could read any number of tweets I could handle your nonsense, but now I have to ration my tweet viewing and you didn’t make the cut.
Tom Martell: If I survived the cut after my last week of tweeting, you must have had some LOOSE follows.
Cutting out low quality follows, blocking or muting people you don’t want around and otherwise improving the quality of your feed is always a great idea. Most Twitter users need to do a lot more of this, so using this moment for ‘spring cleaning’ seems great.
I still am baffled by the degree of refusal to pay. I share the instinct to avoid subscriptions. This still seems like a clear case where heavy users should make an exception.
Other Twitter News
Twitter owner Elon Musk continues to be surprised by how Twitter works. Last week he learned that their code ‘shadowbanned’ any account with low reputation score, preventing them from trending, and the calculation was based on ‘how many times were you reported’ so every big account got shadowbanned.
When I insist that the algorithms used in large companies are counterproductive, stupid and ill-considered, trying to solve the wrong problems using the wrong methods based on a wrong model of the world and all their mistakes have failed to cancel out, I mostly didn’t mean this stupid. A counting statistic on reports to designate low quality? How did anyone think that was a good idea? Did anyone think about it for a minute, let alone test it?
Every time someone says ‘no one would be so stupid as to tell an AI system to…’ remember that no, someone will totally be exactly that stupid.
General Twitter Outlook Going Forward
Until now, none of the changes to Twitter substantially impacted my experience, utility or workflow. If there was one main downside, it was listening to people complain about Twitter.
This time is different. My experience and workflow got worse, as did the experience of many of my best readers. I don’t see the importance of avoiding having a Twitter account at all, but others do, and I respect people who know themselves in such ways.
None of that is especially scary in and of itself. If the new situation proves stable, I am confident it will be fine.
The danger is that the new situation is not obviously stable. Musk has altered the deal, prey that he does not alter it any further. Twitter depends on its network effects. So far, those network effects have held firm, and almost all talk of abandonment has been exactly that, talk. Things now seem much closer to potential tipping points, where the core network effects could become endangered.
If that did happen, it would be extremely bad if it didn’t rapidly result in another site with similar functionality quickly reassembling those network effects and providing a place to make sense of the world in real time and generate a customized information flow. At best, converging on a new location and reestablishing the social graphs there would take years.
A plausible new alternative is about to launch, called Threads, which is closely connected to Instagram. It would be extremely bad if this resulted in Twitter effectively becoming part of the Meta empire, and Meta then had root control of all of that data and its thumb on all the various scales.
Their privacy policies do not seem great, as one would expect, although I’d be more worried about the training data being used for Meta’s LLMs.
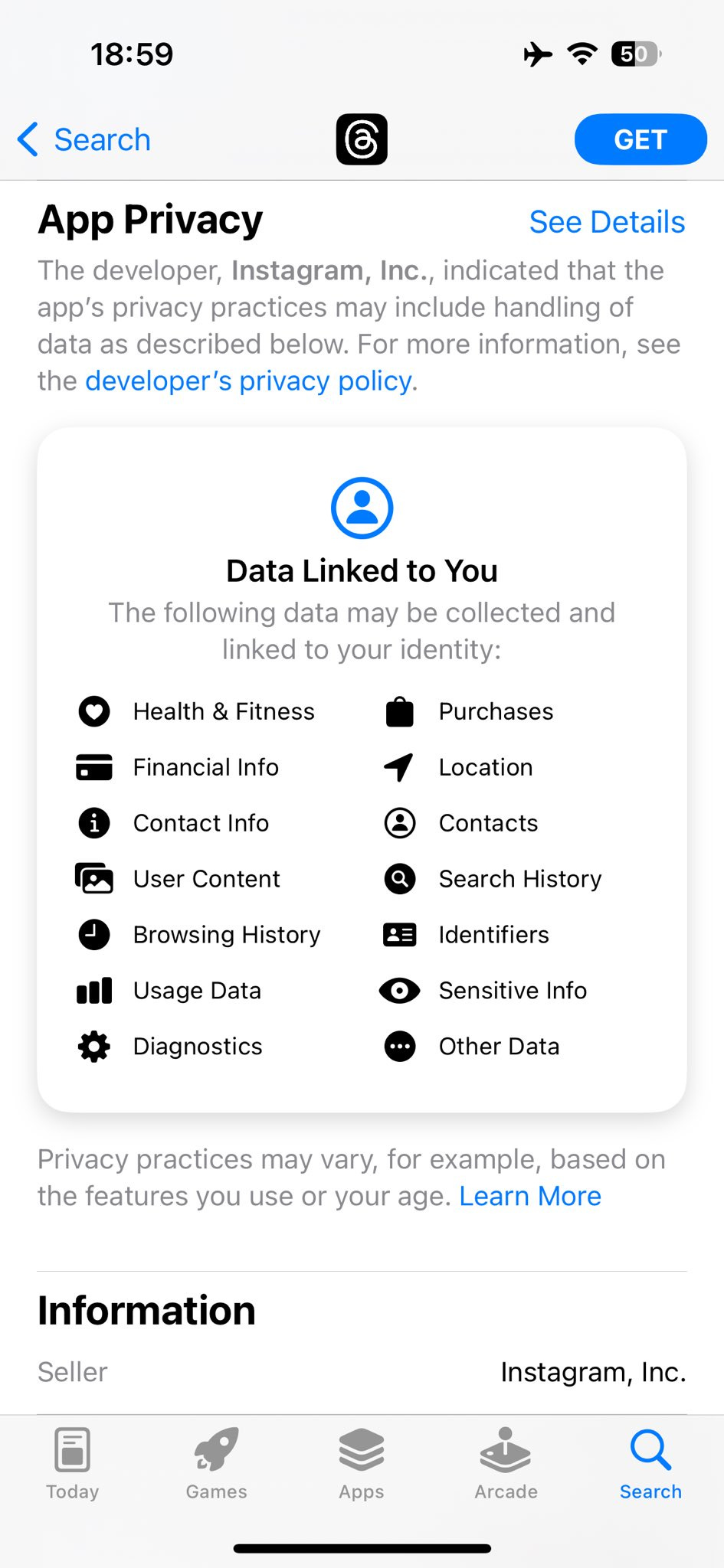
Thus, I will continue to rely on and support Twitter in these trying times. There are problems, but all the alternatives are clearly far worse.
9 comments
Comments sorted by top scores.
comment by Simon Berens (sberens) · 2023-07-04T19:17:24.719Z · LW(p) · GW(p)
Bloomberg reported 2 weeks ago that Twitter resumed paying Google Cloud: https://www.bloomberg.com/news/articles/2023-06-21/twitter-resumes-paying-google-cloud-patching-up-relationship
comment by GeneSmith · 2023-07-04T23:56:22.270Z · LW(p) · GW(p)
Twitter owner Elon Musk continues to be surprised by how Twitter works. Last week he learned that their code ‘shadowbanned’ any account with low reputation score, preventing them from trending, and the calculation was based on ‘how many times were you reported’ so every big account got shadowbanned.
I roll to disbelieve. If this were the case, virtually zero tweets by large accounts would ever trend. There must either be some additional code that overrides this shadowban or some list that nullifies its effects.
It's still hilarious that it was in the codebase at all.
I don't know what to think about Musk not paying the GCP bill. He obviously has the money. Does he really not want to sell more Tesla stock that badly? Why would you risk a 44 billion dollar investment involving a ton of your own money (not to mention that of many of your friends) over a 1 billion dollar bill?
comment by Ben Pace (Benito) · 2023-07-04T19:36:50.050Z · LW(p) · GW(p)
After a ~year of not reading Twitter, I coincidentally returned to reading Twitter the exact day that the rate limits were added. I'll say, this externally imposed daily limit is precisely the feature I've wanted in social media, and each day I've been glad of it.
Replies from: edmund-nelson↑ comment by Edmund Nelson (edmund-nelson) · 2023-07-05T18:26:05.435Z · LW(p) · GW(p)
The number is way too high for that. I use twitter almost an hour a day (way way too much time) and I don't hit the rate limit
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-07-05T18:32:00.377Z · LW(p) · GW(p)
I was initially using a brand new account and hit the rate limits in under an hour. Perhaps the rate limits were different for that account. I notice I didn't hit it yesterday (after I managed to login to my old account).
comment by jimrandomh · 2023-07-05T19:42:27.416Z · LW(p) · GW(p)
We know that Twitter was in multiple datacenters, including their own datacenter, plus Google Cloud, plus AWS. We know that they were trying to get out of these contracts, possibly using default as a negotiating tactic. We know that their technical-debt level was extraordinarily bad. After joking that they probably had a history of their engineers being spies who obfuscating things in order to make it easier to hide their sponsors' backdoors, I thought about it a bit more and decided that was probably literally true. They were (and probably still are) using orders of magnitude more computing resources than running a service like Twitter ought to take, if it was well engineered. And we know that they started having capacity problems, with timing that seems to line up suspicioously with what we might infer is a monthly billing cycle.
But there are a bunch of very different interpretations of this, which we can't easily distinguish:
- They defaulted on their bill with GCP or AWS, had a bunch of servers shut off, and discovered they no longer had sufficient capacity;
- They declined to renew or scaled back their expenditure with GCP or AWS, thinking that their remaining compute resources were adequate, but they weren't;
- They declined to renew or scaled back their expenditure with GCP or AWS, and the remaining capacity was adequate, but they had problems with the migration that would be easier to fix given extra capacity-headroom;
- They're using the same servers as before, and had problems with some crawler/scraper changing its activity patterns
One thing I can say, from running LW, is that from a capacity perspective crawlers are a much bigger issue for websites than you'd naively expect. (LessWrong does have rate limits per-IP-address, they're just high enough that you won't ever hit them under normal usage.) So even if there was a capacity-reduction related to their supply of hardware, it may still be the case that most of their capacity was going to scrapers, and to try to limit the scrapers as a way of regaining capacity. It seems fairly likely that the rate-limiting option was set up in advance as a quick-response option for any sort of capacity issue (including capacity issues created by things like a developer accidentally deploying slow code, or surges in usage).
The main problem with crawlers is that their usage patterns don't match those of regular users, and most optimization effort is focused on the usage patterns of real users, so bots sometimes wind up using the site in ways that consume orders of magnitude more compute per request than a regular user would. And some of these bots have been through many iterations of detection and counter-detection, and are routing their requests through residential-IP botnets, with fake user-agent strings trying to approximate real web browsers.
As for the shadowbanning thing--the real bug was probably a bit more subtle than the tweet-length description, but the bug itself is not surprising, and given the high-technical-debt codebase, probably not nearly as stupid as it sounds. Or rather: the effect may have been that stupid, but the code itself probably didn't look on cursory inspection like it was that bad. Ie, I would assign pretty high probability to that code containing an attempt to normalize for visibility that didn't work correctly, or an uncompleted todo-item to make a visibility correction score. A codebase like Twitter is going to have bugs like this, they can ony be discovered by skilled programmers doing forensic investigations, and executives will only know about them during the narrow time window between when they're discovered and when they're fixed.
Replies from: siclabomines, RomanS↑ comment by siclabomines · 2023-07-07T23:29:20.786Z · LW(p) · GW(p)
The main problem with crawlers is that their usage patterns don't match those of regular users, and most optimization effort is focused on the usage patterns of real users, so bots sometimes wind up using the site in ways that consume orders of magnitude more compute per request than a regular user would.
And Twitter has recently destroyed his API, I think? Which perhaps has the effect of de-optimizing the usage patterns of bots.
↑ comment by RomanS · 2023-07-06T07:03:59.202Z · LW(p) · GW(p)
And some of these bots have been through many iterations of detection and counter-detection, and are routing their requests through residential-IP botnets, with fake user-agent strings trying to approximate real web browsers.
As someone who has done scraping a few times, I can confirm that it's trivial to circumvent protections against it, even for a novice programmer. In most cases, it's literally less than 10 minutes of googling and trial & error.
And for a major AI / web-search company, it could be a routine task, with teams of dedicated professionals working on it.
comment by RomanS · 2023-07-05T08:50:49.372Z · LW(p) · GW(p)
I think the both explanations can be true at the same time:
- Twitter is refusing to pay a bill to Google
- Twitter is severely abused by data scrapers.
One likely scenario is where Google itself is a main culprit.
E.g. Elon learned that Google is scraping twitter data on industrial scale to train its AIs, without paying anything to Twitter. This results in massive infrastructure expenses for Twitter, to be paid to... Google. Outraged Elon stormed into the Alphabet headquarters, but was politely asked to get lost. Hilarity ensues.