How To Think About Overparameterized Models
post by johnswentworth · 2021-03-03T22:29:13.126Z · LW · GW · 4 commentsContents
Ridges, Not Peaks Priors and Sampling, Not Likelihoods and Estimation Example: Overparameterized Linear Regression Traditional-Style Regression (Slightly) Overparameterized Regression (Very) Overparameterized Regression None 4 comments
So, you’ve heard that modern neural networks have vastly more parameters than they need to perfectly fit all of the data. They’re operating way out in the regime where, traditionally, we would have expected drastic overfit, yet they seem to basically work. Clearly, our stats-101 mental models no longer apply here. What’s going on, and how should we picture it?
Maybe you’ve heard about some papers on the topic, but didn’t look into it in much depth, and you still don’t really have an intuition for what’s going on. This post is for you. We’ll go over my current mental models for what’s-going-on in overparameterized models (i.e. modern neural nets).
Disclaimer: I am much more an expert in probability (and applied math more generally) than in deep learning specifically. If there are mistakes in here, hopefully someone will bring it up in the comments.
Assumed background knowledge: multi-dimensional Taylor expansions, linear algebra.
Ridges, Not Peaks
First things first: when optimizing ML models, we usually have some objective function where perfectly predicting every point in the training set yields the best possible score. In overparameterized models, we have enough parameters that training indeed converges to zero error, i.e. all data points in the training set are matched perfectly.
Let’s pick one particular prediction setup to think about, so we can stick some equations on this. We have a bunch of data points, and we want to predict given . Our ML model has some parameters , and its prediction on a point is . In order to perfectly predict every data point in the training set, must satisfy the equations
Assuming is one-dimensional (i.e. just a number), and we have data points, this gives us equations. If is -dimensional, then we have equations with variables. If the number of variables is much larger than the number of equations (i.e. , parameter-dimension much greater than number of data points), then this system of equations will typically have many solutions.
In fact, assuming there are any solutions at all, we can prove there are infinitely many - an entire high-dimensional surface of solutions in -space. Proof: let be a solution. If we make a small change , then changes by . For all the equations to remain satisfied, after shifting , these changes must all be zero:
Key thing to notice: this is a set of linear equations. There are still equations and still variables (this time rather than ), and since they’re linear, there are guaranteed to be at least independent directions along which we can vary while still solving the equations (i.e. the right nullspace of the matrix has dimension at least ). These directions point exactly along the local surface on which the equations are solved.
Takeaway: we have an entire surface of dimension (at least) , sitting in the -dimensional -space, on which all points in the training data are predicted perfectly.
What does this tell us about the shape of the objective function more generally?
Well, we have this (at least) dimensional surface on which the objective function achieves its best possible value. Everywhere else, it will be lower. The “global optimum” is not a point at the top of a single peak, but rather a surface at the high point of an entire high-dimensional ridge. So: picture ridges, not peaks.

Before we move on, two minor comments on generalizing this model.
- “Predict given ” is not the only setup deep learning is used for; we also have things like “predict/generate/compress samples of ” or RL. My understanding is that generally-similar considerations apply, though of course the equations will be different.
- If is more than one-dimensional, e.g. dimension , then the perfect-prediction surface will have dimension at least rather than .
Priors and Sampling, Not Likelihoods and Estimation
So there’s an entire surface of optimal points. Obvious next question: if all of these points are optimal, what determines which one we pick? Short answer: mainly initial parameter values, which are typically randomly generated.
Conceptually, we randomly sample trained parameter values from the perfect-prediction surface. To do that, we first sample some random initial parameter values, and then we train them - roughly speaking, we gradient-descend our way to whatever point on the perfect-prediction surface is closest to our initial values. The key problem is to figure out what distribution of final (trained) parameter values results from the initial distribution of parameter values.
One key empirical result: during training, the parameters in large overparameterized models tend to change by only a small amount. (There’s a great visual of this in this post. It’s an animation showing weights changing over the course of training; for the larger nets, they don’t visibly change at all.) In particular, this means that linear/quadratic approximations (i.e. Taylor expansions) should work very well.
For our purposes, we don’t even care about the details of the ridge-shape. The only piece which matters is that, as long as we’re close enough for quadratic approximations around the ridge to work well, the gradient will be perpendicular to the directions along which the ridge runs. So, gradient descent will take us from the initial point, to whatever point on the perfect-prediction surface is closest (under ordinary Euclidean distance) to the initial point.
Stochastic gradient descent (as opposed to pure gradient descent) will contribute some noise - i.e. diffusion along the ridge-direction - but it should average out to roughly the same thing.
From there, figuring out the distribution from which we effectively sample our trained parameter values is conceptually straightforward. For each point on the perfect-prediction surface, add up the probability density of the initial parameter distribution at all the points which are closer to than to any other point on the perfect-prediction surface.
We can break this up into two factors:
- How large a volume of space is closest to ? This will depend mainly on the local curvature of the perfect-prediction-surface (higher where curvature is lower)
- What’s the average density of the initial-parameter distribution in that volume of space?
Now for the really hand-wavy approximations:
- Let’s just ignore that first factor. Assume that the local curvature of the perfect-prediction surface doesn’t change too much over the surface, and approximate it by a constant. (Everything’s on a log-scale, so this is reasonable unless the curvature changes by many orders of magnitude.)
- For the second factor, let’s assume the average density of the initial-parameter distribution over the volume is roughly proportional to the density at . (This is hopefully reasonable, since we already know initial points are quite close to final points in practice.)
Are these approximations reasonable? I haven’t seen anyone check directly, but they are the approximations needed in order for the results in e.g. Mingard et al [LW · GW] to hold robustly, and those results do seem to hold empirically.
The upshot: we have an effective “prior” (i.e. the distribution from which the initial parameter values are sampled) and “posterior” (i.e. the distribution of final parameter values on the perfect-prediction surface). The posterior density is directly proportional to the prior density, but restricted to the perfect-prediction surface. This is exactly what Bayes’ rule says, if we start with a distribution and then update on data of the form “”. Our posterior is then , and our final parameter-values are a sample from that distribution.
Note how this differs from traditional statistical practice. Traditionally, we maximize likelihood, and that produces a unique “estimate” of . While today’s ML models may look like that at first glance, they’re really performing a Bayesian update of the parameter-value-distribution, and then sampling from the posterior.
Example: Overparameterized Linear Regression
As an example, let’s run a plain old linear regression. We’ll use an overparameterized model which is equivalent to a traditional linear regression model, in order to make the relationship clear.
We have 100 pairs, which look like this:
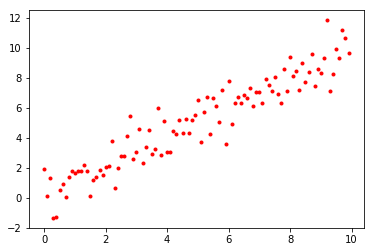
I generated these with a “true” slope of 1, i.e. , with standard normal noise.
Traditional-Style Regression
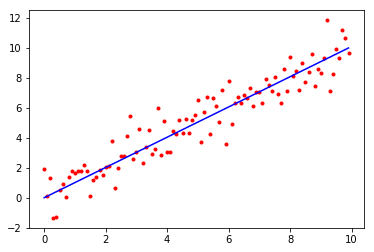
We have one parameter, , and we fit a model , with standard normal-distributed noise . This gives log likelihood
… plus some constants. We choose to maximize this log-likelihood. In this case, , so the line looks like this:
(Slightly) Overparameterized Regression
We use the exact same model, , but now we explicitly consider the terms “parameters”. Now our parameters are , and we’ll initialize them all as samples from a standard normal distribution (so our “prior” on the noise terms is the same distribution assumed in the previous regression). We then optimize to minimize the sum-of-squared-errors
This ends up approximately the same as a Bayesian update on , and our final -value 1.046 is not an estimate, but rather a sample from the posterior. Although the “error” in our -posterior-sample here is larger than the “error” in our -estimate from the previous regression, the implied line is visually identical:
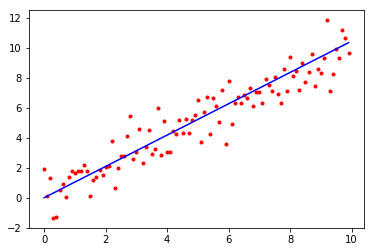
Note that our model here is only slightly overparameterized; , so the perfect prediction surface is one-dimensional. Indeed, the perfect prediction surface is a straight line in - space, given by the equations .
(Very) Overparameterized Regression
Usually, we say that the noise terms are normal because they’re a sum of many small independent noise sources. To make a very overparameterized model, let’s make those small independent noise sources explicit: . Our parameters are and the whole 2D array of ’s, with standard normal initialization on , and Uniform(-1, 1) initialization on . (The is there to make the standard deviation equivalent to the original model.) As before, we minimize sum-of-squared-errors.
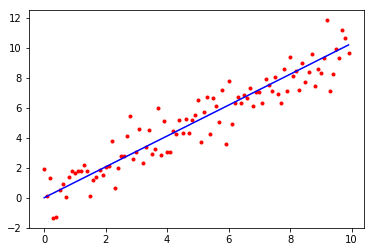
This time our -value is 1.031. The line still looks exactly the same. This time, we’re much more overparameterized - we have , so the perfect prediction surface has dimension . But conceptually, it still works basically the same as the previous example.
Code for all these is here.
In all these examples, the underlying probabilistic models are (approximately) identical. The latter two (approximately) sample from the posterior, rather than calculating a maximum-log-likelihood parameter estimate, but as long as the posterior for the slope parameter is very pointy, the result is nearly the same. The main difference is just what we call a "parameter" and optimize over, rather than integrating out.
4 comments
Comments sorted by top scores.
comment by romeostevensit · 2021-05-20T04:58:55.724Z · LW(p) · GW(p)
somehow I missed this post and only caught it now. This was helpful for a few things.
- That I should think of some algorithms primarily as populating a space with the given data and then 'deciding' on the topology of the space
- That 'the valley of bad X' is the inverse of a 'goldilocks zone'
- That overfitting can be thought of as occurring in a valley of bad parameterization.
comment by SarahNibs (GuySrinivasan) · 2021-03-14T03:17:04.463Z · LW(p) · GW(p)
Just read erhan10a.pdf (mlr.press) (Why Does Unsupervised Pre-training Help Deep Learning?, 2010) for a paper club at work. This post helped me understand and simplify the material, quite a lot. Thanks!
comment by Jobst Heitzig · 2023-07-06T22:14:34.204Z · LW(p) · GW(p)
roughly speaking, we gradient-descend our way to whatever point on the perfect-prediction surface is closest to our initial values.
I believe this is not correct as long as "gradient-descend" means some standard version of gradient descent because those are all local, can go highly nonlinear paths, and do not memorize the initial value to try staying close to it.
But maybe we can design a local search strategy similar to gradient descent which does try to stay close to the initial point x0? E.g., if at x, go a small step into a direction that has the minimal scalar product with x – x0 among those that have at most an angle of alpha with the current gradient, where alpha>0 is a hyperparameter. One might call this "stochastic cone descent" if it does not yet have a name.
comment by Lucius Bushnaq (Lblack) · 2023-01-18T23:28:13.866Z · LW(p) · GW(p)
I'm confused about this.
Say our points are the times of day measured by a clock. And are the temperatures measured by a thermometer at those times. We’re putting in times in the early morning, where I decree temperature to increase roughly linearly as the sun rises.
You write the overparametrized regression model as . Since our model doesn’t get to see the index, only the value of itself, that has to implicitly be something like
Where is the regression or NN output. So our model learned the slope, plus a lookup table for the noise values of the thermometer at those times in the training data set. That means that if the training set included the time , and the model encounters a temperature taken at outside training again, now from a different day, it will output .
Which is predictably wrong, and you can do better by not having that memorised noise term.
The model doesn’t get to make a general model plus a lookup table of noises in training to get perfect loss and then use only the general model outside of training. It can’t switch the lookup table off.
Put differently, if there’s patterns in the data that the model cannot possibly make a decent simple generative mechanism for, fitting those patterns to get a better loss doesn’t seem like the right thing to do.
Put yet another way, if you're forced to pick one single hypothesis to make predictions, the best one to pick doesn't necessarily come from the set that perfectly fits all past data.