New safety research agenda: scalable agent alignment via reward modeling
post by Vika · 2018-11-20T17:29:22.751Z · LW · GW · 12 commentsThis is a link post for https://medium.com/@deepmindsafetyresearch/scalable-agent-alignment-via-reward-modeling-bf4ab06dfd84
Contents
12 comments
Jan Leike and others from the DeepMind safety team have released a new research agenda on reward learning:
"Ultimately, the goal of AI progress is to benefit humans by enabling us to address increasingly complex challenges in the real world. But the real world does not come with built-in reward functions. This presents some challenges because performance on these tasks is not easily defined. We need a good way to provide feedback and enable artificial agents to reliably understand what we want, in order to help us achieve it. In other words, we want to train AI systems with human feedback in such a way that the system’s behavior aligns with our intentions. For our purposes, we define the agent alignment problem as follows:
How can we create agents that behave in accordance with the user’s intentions?
The alignment problem can be framed in the reinforcement learning framework, except that instead of receiving a numeric reward signal, the agent can interact with the user via an interaction protocol that allows the user to communicate their intention to the agent. This protocol can take many forms: the user can provide demonstrations, preferences, optimal actions, or communicate a reward function, for example. A solution to the agent alignment problem is a policy that behaves in accordance with the user’s intentions.
With our new paper we outline a research direction for tackling the agent alignment problem head-on. Building on our earlier categorization of AI safety problems as well as numerous problem expositions on AI safety, we paint a coherent picture of how progress in these areas could yield a solution to the agent alignment problem. This opens the door to building systems that can better understand how to interact with users, learn from their feedback, and predict their preferences — both in narrow, simpler domains in the near term, and also more complex and abstract domains that require understanding beyond human level in the longer term.
The main thrust of our research direction is based on reward modeling: we train a reward model with feedback from the user to capture their intentions. At the same time, we train a policy with reinforcement learning to maximize the reward from the reward model. In other words, we separate learning what to do (the reward model) from learning how to do it (the policy).
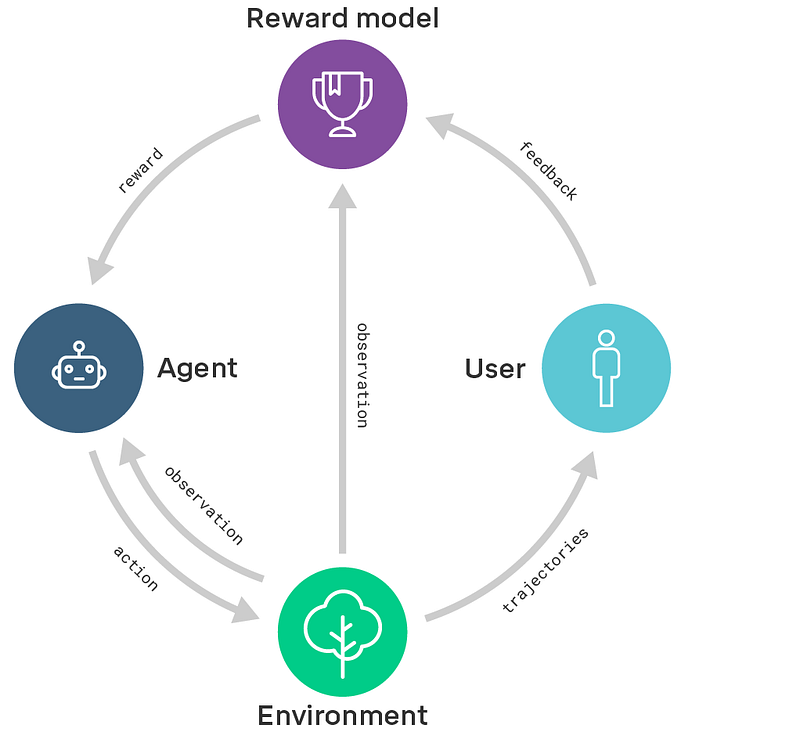
For example, in previous work we taught agents to do a backflip from user preferences, to arrange objects into shapes with goal state examples, to play Atari games from user preferences and expert demonstrations. In the future we want to design algorithms that learn to adapt to the way users provide feedback (e.g. using natural language)."
12 comments
Comments sorted by top scores.
comment by Wei Dai (Wei_Dai) · 2018-11-20T18:37:08.887Z · LW(p) · GW(p)
Am I correct in thinking that this is a subset of Paul's agenda, since he has talked about something very similar [AF · GW] (including recursive scaling and reward modeling) as a possible instantiation of his approach? Do you see any substantial differences between what you're proposing and what he proposed in that post?
(If it is, I guess I'm simultaneously happy that more resources will be devoted to Paul's agenda, which definitely could use it, and disappointed for the implication that a more promising (or even just another uncorrelated) ML-based approach to alignment probably isn't forthcoming from DeepMind.)
Replies from: janleike, Dr_Manhattan↑ comment by janleike · 2018-12-31T23:48:24.891Z · LW(p) · GW(p)
Good question. The short answer is “I’m not entirely sure.” Other people [LW · GW] seem to [LW · GW] struggle with understanding Paul Christiano’s agenda as well.
When we developed the ideas around recursive reward modeling, we understood amplification to be quite different (what we ended up calling Imitating expert reasoning in the paper after consulting with Paul Christiano and Andreas Stuhlmüller). I personally find that the clearest expositions for what Paul is trying to do are Iterated Distillation and Amplification and Paul's latest paper, which we compare to in multiple places in the paper. But I'm not sure how that fits into Paul's overall “agenda”.
My understanding of Paul’s agenda is that it revolves around "amplification" which is a broad framework for training ML systems with a human in the loop. Debate is an instance of amplification. Factored cognition is an instance of amplification. Imitating expert reasoning is an instance of amplification. Recursive reward modeling is an instance of amplification. AlphaGo is an instance of amplification. It’s not obvious to me what isn't.
Having said that, there is no doubt about the fact that Paul is a very brilliant researcher who is clearly doing great work on alignment. His comments and feedback have been very helpful for writing this paper and I'm very much looking forward to what he'll produce next.
So maybe I should bounce this question over to @paulfchristiano [LW · GW]: How does recursive reward modeling fit into your agenda?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2019-01-02T06:22:56.959Z · LW(p) · GW(p)
Iterated amplification is a very general framework, describing algorithms with two pieces:
- An amplification procedure that increases an agent's capability. (The main candidates involve decomposing a task into pieces and invoking the agent to solve each piece separately, but there are lots of ways to do that.)
- A distillation procedure that uses a strong expert to train an efficient agent. (I usually consider semi-supervised RL, as in our paper.)
Given these two pieces, we plug them into each other: the output of distillation becomes the input to amplification, the output of amplification becomes the input to distillation. You kick off the process with something aligned, or else design the amplification step so that it works from some arbitrary initialization.
The hope is that the result is aligned because:
- Amplification preserves alignment (or benigness, corrigibility, or some similar invariant)
- Distillation preserves alignment, as long the expert is "smart enough" (relative to the agent they are training)
- Amplification produces "smart enough" agents.
My research is organized around this structure---thinking about how to fill in the various pieces, about how to analyze training procedures that have this shape, about what the most likely difficulties are. For me, the main appeal of this structure is that it breaks the full problem of training an aligned AI into two subproblems which are both superficially easier (though my expectation is that at least one of amplification or distillation will end up containing almost all of the difficulty).
Recursive reward modeling fits in this framework, though my understanding is that it was arrived at mostly independently. I hope that work on iterated-amplification-in-general will be useful for analyzing recursive reward modeling, and conversely expect that experience with recursive reward learning will be informative about the prospects for iterated-amplification-in-general.
It’s not obvious to me what isn't.
Iterated amplification is intended to describe the kind of training procedure that is most natural using contemporary ML techniques. I think it's quite likely that training strategies will have this form, even if people never read anything I write. (And indeed, AGZ and ExIt were published around the same time.)
Introducing this concept was mostly intended as an analysis tool rather than a flag planting exercise (and indeed I haven't done the kind of work that would be needed to plant a flag). From the prior position of "who knows how we might train aligned AI," iterated amplification really does narrow down the space of possibilities a lot, and I think it has allowed my research to get much more concrete much faster than it otherwise would have.
I think it was probably naive to hope to separate this kind of analysis from flag planting without being much more careful about it; I hope I haven't made it too much more difficult for others to get due credit for working on ideas that happen to fit in this framework.
Debate is an instance of amplification.
Debate isn't prima facie an instance of iterated amplification, i.e. it doesn't fit in the framework I outlined at the start of this comment.
Geoffrey and I both believe that debate is nearly equivalent to iterated amplification, in the sense that probably either they will both work or neither will. So the two approaches suggest very similar research questions. This makes us somewhat more optimistic that those research questions are good ones to work on.
Factored cognition is an instance of amplification
"Factored cognition" refers to mechanisms for decomposing sophisticated reasoning into smaller tasks (quoting the link). Such mechanisms could be used for amplification, though there are other reasons you might study factored cognition.
"amplification" which is a broad framework for training ML systems with a human in the loop
The human isn't really an essential part. I think it's reasonably likely that we will use iterated amplification starting from a simple "core" for corrigible reasoning rather than starting from a human. (Though the resulting systems will presumably interact extensively with humans.)
↑ comment by Dr_Manhattan · 2018-11-20T21:20:43.013Z · LW(p) · GW(p)
They mention and link to iterated amplification in the Medium article.
Scaling up
In the long run, we would like to scale reward modeling to domains that are too complex for humans to evaluate directly. To do this, we need to boost the user’s ability to evaluate outcomes. We discuss how reward modeling can be applied recursively: we can use reward modeling to train agents to assist the user in the evaluation process itself. If evaluation is easier than behavior, this could allow us to bootstrap from simpler tasks to increasingly general and more complex tasks. This can be thought of as an instance of iterated amplification.Replies from: Wei_Dai
↑ comment by Wei Dai (Wei_Dai) · 2018-11-20T21:59:33.826Z · LW(p) · GW(p)
Yes, and they cite iterated amplification in their paper as well, but I'm trying to figure out if they're proposing anything new, because the title here is "New safety research agenda: scalable agent alignment via reward modeling" but Paul's post that I linked to already proposed recursively applying reward modeling. Seems like either I'm missing something, or they didn't read that post?
comment by Wei Dai (Wei_Dai) · 2018-11-23T03:27:37.023Z · LW(p) · GW(p)
I'm curious what is DeepMind safety team's (or any team member's personal) view on the problem that it's not safe to assume that the human user is a generally safe agent. For example, we only know it to be safe for a narrow range of inputs/environments, and it seems very likely to become unsafe if quickly shifted far outside of its "training distribution", as may happen if the AI becomes very intelligent and starts to heavily modify the user's environment according to its rewards. In principle this could perhaps be considered a form of "reward hacking", but section 4.3 on reward hacking makes no specific mention of this problem, and I don't see it mentioned anywhere else. (In contrast, Paul's agenda at least tries to address a subset of this problem.)
Is this problem discussed somewhere else in the blog post or paper, that I missed? Would you consider solving this problem to be part of this research agenda, or part of DeepMind's safety responsibility in general?
Replies from: janleike↑ comment by janleike · 2018-12-31T23:49:08.157Z · LW(p) · GW(p)
This is an obviously important problem! When we put a human in the loop, we have to be confident that the human is actually aligned—or at least that they realize when their judgement is not reliable to the current situation and defer to some other fallback process or ask for additional assistance. We are definitely thinking about this problem at DeepMind, but it’s out of the scope of this paper and the technical research direction that we are proposing to pursue here. Instead, we zoom into one particular aspect, how to solve the agent alignment problem in the context of aligning a single agent to a single user, because we think it is the hardest technical aspect of the alignment problem.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2019-01-03T00:58:21.498Z · LW(p) · GW(p)
I'm glad to hear that the DeepMind safety team is thinking about this problem and look forward to reading more about your thoughts on it. However I don't think putting human safety problems outside of "aligning a single agent to a single user" is a natural way to divide up the problem space, because there are likely ways to address human safety problems within that context. (See these two [LW · GW] posts [LW · GW] which I wrote after posting my comment here.)
I would go further and say that without an understanding of the ways in which humans are unsafe, and how that should be addressed, it's hard to even define the problem of "aligning a single agent to a single user" in a way that makes sense. To illustrate this, consider an analogy where the user is an AI that has learned a partial utility function, which gives reasonable outputs to a narrow region of inputs and a mix of "I don't know" and random extrapolations outside of that. If another agent tries to help this user by optimizing over this partial utility function and ends up outside the region where it gives sensible answers, is that agent aligned to the user? A naive definition of alignment that doesn't take the user's own lack of safety into account would answer yes, but I think that would be intuitively unacceptable to many people.
To steelman your position a bit, I think what might make sense is to say something like: "Today we don't even know how to align an agent to a single user which is itself assumed to be safe. Solving this easier problem might build up our intellectual tools and frameworks which will help us solve the full alignment problem, or otherwise be good practice for solving the full problem." If this is a reasonable restatement of your position, I think it's important to be clear about what you're trying to do (and what problems remain even if you succeed), so as to not give the impression that AI alignment is easier than it actually is.
comment by [deleted] · 2018-12-09T19:26:42.124Z · LW(p) · GW(p)
Was anyone else unconvinced/confused (I was charitably confused, uncharitably unconvinced) by the analogy between recursive task/agent decomposition and first-order logic in section 3 under the heading "Analogy to Complexity Theory"? I suspect I'm missing something but I don't see how recursive decomposition is analogous to **alternating** quantifiers?
It's obvious that, at the first level, finding an that satisfies is similar to finding the right action, but I don't see how finding and that satisfy is similar to 's solving of one of 's decomposed tasks is similar to universal quantification.
To take a very basic example, if I ask an agent to solve a simple problem like, "what is 1+2+3+4?" and the first agent decomposes it into "what is 1+2?", what "what is 3+4?", and "what is the result of '1+2' plus the result of '3+4'?" (this assumes we have some mechanism of pointing and specifying dependencies like Ought's working on), what would this look like in the alternating quantifier formulation?
Replies from: janleike, paulfchristiano↑ comment by janleike · 2018-12-31T23:54:39.657Z · LW(p) · GW(p)
Thanks for your question! I suspect there is some confusion going on here with what recursive reward modeling is. The example that you describe sounds like an example from imitating expert reasoning [AF · GW].
In recursive reward modeling, agent is not decomposing tasks, it is trying to achieve some objective that the user intends for it to perform. then assists the human in evaluating ’s behavior in order to train a reward model. Decomposition only happens on the evaluation of ’s task.
For example, proposes some plan and proposes the largest weakness in the plan. The human then evaluates whether is indeed a weakness in the plan and how strong it is, and then judges the plan based on this weakness. If you simplify and assume this judgement is binary ( is true iff the plan passes), then “wins” iff and “wins” iff . Thus the objective of the game becomes for and for . Note that this formulation has similarities with debate. However, in practice judgements don’t need to be binary and there are a bunch of other differences (human closer in the loop, not limited to text, etc.).
Replies from: None↑ comment by paulfchristiano · 2018-12-19T22:32:11.440Z · LW(p) · GW(p)
Finding the action that optimizes a reward function is -complete for general . If the reward function is itself able to use an oracle for , then that's complete for , and so on. The analogy is loose because you aren't really getting the optimal at each step.