New report: Safety Cases for AI
post by joshc (joshua-clymer) · 2024-03-20T16:45:27.984Z · LW · GW · 14 commentsThis is a link post for https://twitter.com/joshua_clymer/status/1770467746951868889
Contents
14 comments
ArXiv paper: https://arxiv.org/abs/2403.10462
The idea for this paper occurred to me when I saw Buck Shlegeris' MATS stream on "Safety Cases for AI." How would one justify the safety of advanced AI systems? This question is fundamental. It informs how RSPs should be designed and what technical research is useful to pursue.
For a long time, researchers have (implicitly or explicitly) discussed ways to justify that AI systems are safe, but much of this content is scattered across different posts and papers, is not as concrete as I'd like, or does not clearly state their assumptions.
I hope this report provides a helpful birds-eye view of safety arguments and moves the AI safety conversation forward by helping to identify assumptions they rest on (though there's much more work to do to clarify these arguments).
Thanks to my coauthors: Nick Gabrieli, David Krueger, and Thomas Larsen -- and to everyone who gave feedback: Henry Sleight, Ashwin Acharya, Ryan Greenblatt, Stephen Casper, David Duvenaud, Rudolf Laine, Roger Grosse, Hjalmar Wijk, Eli Lifland, Oliver Habryka, Sim ́eon Campos, Aaron Scher, Lukas Berglund, and Nate Thomas.
14 comments
Comments sorted by top scores.
comment by habryka (habryka4) · 2024-03-21T19:45:43.394Z · LW(p) · GW(p)
I think this report is is overall pretty good! I do feel overall confused about whether the kind of thing this report is trying to do works. Here is a long comment I had left on a Google Doc version of this post that captures some of that:
Replies from: joshua-clymerI keep coming back to this document and keep feeling confused whether I expect this to work or provide value.
I feel like the framing here tries to shove a huge amount of complexity and science into a "safety case", and then the structure of a "safety case" doesn't feel to me like it is the kind of thing that would help me think about the very difficult and messy questions at hand.
Like, I understand that we would like to somehow force labs to make some proactive case for why their systems are safe, and we want to set things up in a way that they can't just punt on the difficult questions, or avoid making a coherent argument, or say a bunch of unfalsifiable things, but I somehow don't think that the way you try to carve the structure of a "safety case" is sufficient here, or seems helpful for actually helping someone think through this.
To be clear, the factorization here seems reasonable and seems like the kind of thing that seems helpful for helping people think about alignment, but it also feels more like it just captures "the state of fashionable AI safety thinking in 2024" more than it is the kind of thing that makes sense to enshrine into a whole methodology (or maybe even regulation).
The emphasis on distinction between capability-evals and alignment-evals for example is a thing that mostly has gotten lots of emphasis in the last year, and I expect it won't be as emphasized in a few years, and for us to have new distinctions we care a lot about.Like, I feel like, I don't have much of any traction on making an air-tight case that any system is safe, or is unsafe, and I feel like this document is framed in a kind of "oh, it's easy, just draw some boxes and arrows between them and convince the evaluators you are right" way, when like, of course labs will fail to make a comprehensive safety case here.
But I feel like that's mostly just a feature of the methodology, not a feature of the territory. Like, if you applied the same methodology to computer security, or financial fraud, or any other highly complex domain you would end up with the same situation where making any airtight case is really hard.
And I am worried the reason why this document is structures this way is because we, as people who are concerned about x-risk, like a playing field that is skewed towards AI development being hard to do, but this feels slightly underhanded.
But also, I don't know, I like a lot of the distinctions in this document and found a bunch of the abstractions useful. But I feel like I would much prefer a document of the type of "here are some ways I found helpful for thinking about AI X-risk" or something like that.
↑ comment by joshc (joshua-clymer) · 2024-03-21T22:03:14.827Z · LW(p) · GW(p)
Thanks for leaving this comment on the doc and posting it.
But I feel like that's mostly just a feature of the methodology, not a feature of the territory. Like, if you applied the same methodology to computer security, or financial fraud, or any other highly complex domain you would end up with the same situation where making any airtight case is really hard.
You are right in that safety cases are not typically applied to security. Some of the reasons for this are explained in this paper, but I think the main reason is this:
"The obvious difference between safety and security is the presence of an intelligent adversary; as Anderson (Anderson 2008) puts it, safety deals with Murphy’s Law while security deals with Satan’s Law... Security has to deal with agents whose goal is to compromise systems."
My guess is that most safety evidence will come down to claims like "smart people tried really hard to find a way things could go wrong and couldn't." This is part of why I think 'risk cases' are very important.
I share the intuitions behind some of your other reactions.
I feel like the framing here tries to shove a huge amount of complexity and science into a "safety case", and then the structure of a "safety case" doesn't feel to me like it is the kind of thing that would help me think about the very difficult and messy questions at hand.
Making safety cases is probably hard, but I expect explicitly enumerating their claims and assumptions would be quite clarifying. To be clear, I'm not claiming that decision-makers should only communicate via safety and risk cases. But I think that relying on less formal discussion would be significantly worse.
Part of why I think this is that my intuitions have been wrong over and over again. I've often figured this out after eventually asking myself "what claims and assumptions am I making? How confident am I these claims are correct?"
it also feels more like it just captures "the state of fashionable AI safety thinking in 2024" more than it is the kind of thing that makes sense to enshrine into a whole methodology.
To be clear, the methodology is separate from the enumeration of arguments (which I probably could have done a better job signaling in the paper). The safety cases + risk cases methodology shouldn't depend too much on what arguments are fashionable at the moment.
I agree that the arguments will evolve to some extent in the coming years. I'm more optimistic about the robustness of the categorization, but that's maybe minor.
comment by Vanessa Kosoy (vanessa-kosoy) · 2024-03-20T17:09:35.748Z · LW(p) · GW(p)
Linkpost to Twitter thread is a bad format for LessWrong. Not everyone has Twitter.
comment by Fabien Roger (Fabien) · 2024-03-21T18:09:04.794Z · LW(p) · GW(p)
I really liked this report! I think it fills a natural and important hole in the public writing about AI control and makes interesting claims/recommendations.
A few innovations I liked:
- Risk cases - I think that's plausibly an amazing policy?
- Calling it "black swans" when an AI decides it's time to take over (even if the distribution has not meaningfully shifted) ("Black swans are rare inputs that cause AI systems to catastrophically misbehave. Black swans may be rare enough to where they are not sampled during evaluation but are common enough to occur in deployment").
- Calling the crazy bootstrapping hopes "deference". I like the vibes of this word. Deference is still somewhat counterintuitive to me. My first reaction when reading “AI advisors assert that other AI systems do not pose a catastrophic risk, and these AI advisors are at least as credible as human decision-makers.” was to think "human-level judgement is a super low bar when you're speaking of the safety of super powerful systems", but the default mistrust of super powerful AIs would naturally be taken into account by AI advisors if they are at least as credible as human decision-makers.
- Linking GSN diagrams and other things that are common-practice in other industries with AI safety.
- The report is beautiful, I like the little inline figures, and Figure 14 is a nice illustration of catch-then-shutdown [LW · GW] approaches.
- You mention unlearning, a subfield that lacks love and attention. I think its characterization as medium-practical and medium-strength is fair (especially given how generous he is with other approaches), but it's not very scalable imo (it breaks when AIs can derive things from scratch quite well).
Some elements I disagree with:
- I basically disagree with most hopes described in the trustworthiness section:
- The level of practicality you assign to some approaches is just insanely high. Neither modeling generalization nor externalized reasoning, and certainly not testbeds seem to "strongly practical" (defined as "Applies to arguments that do not require fundamental research advances, but might require"). The only one that is justifiably "strongly practical" to me is "absence of precursor abilities".
- I disagree with putting testbeds and amplification in trustworthiness (at least not as strong or even medium practicality), I think they usually don't help to know if AIs can be trusted (and in particular they don't prevent any forms of alignment faking).
- "Claim 4: AI systems are not faking alignment" is just extremely hard to assess. I think that the focus of trustworthiness assessment on "Claim 3: All enumerated causes of correlated infractions are unlikely aside from alignment faking." is somewhat unwarranted.
- I think the description of macrosystem risks was not very convincing, aside from risks that make systems less trustworthy - so I think macrosystem should maybe have been folded into trustworthiness.
- The strength of almost all "high strength" measures is overrated, almost nothing is "strong" (where "strong" is defined as "Applies to arguments that could bring catastrophic risk below acceptable levels without needing other arguments."). Control is not strong, monitoring is not strong, externalized reasoning is not strong (for control and trustworthiness), ... Even with a notion of acceptable that is quite generous (e.g. 2% p(doom)) I think nothing is strong, but given the stakes I think we shouldn't use "acceptable" for anything above 1% (and ideally reserve that word for 0.1% or below).
↑ comment by joshc (joshua-clymer) · 2024-03-21T20:58:37.801Z · LW(p) · GW(p)
Thanks, this is good feedback!
Addressing the disagreements:
The level of practicality you assign to some approaches is just insanely high. Neither modeling generalization nor externalized reasoning, and certainly not testbeds seem to "strongly practical" (defined as "Applies to arguments that do not require fundamental research advances, but might require"). The only one that is justifiably "strongly practical" to me is "absence of precursor abilities."
Externalized reasoning: just a capability argument, no?
Testbeds: I think the best testbed ideas rn just require training a bunch of models to have particular policies, which seems pretty straightforward. I think these are good enough to make a moderate-strength argument (which is the bar where practicality is evaluated).
Modeling generalization: I definitely think that versions of this aren't very practical, but e.g. looking at efficiency inductive biases is pretty straightforward -- and this is sufficient to make a moderate strength not-alignment-faking argument.
Strong practicality ~refers to "does there exist an argument of this type of moderate strength that can be made without fundamental research." So, lots of arguments of these types will still require fundamental research, but if some don't, then that means they are strongly practical.
I disagree with putting testbeds and amplification in trustworthiness (at least not as strong or even medium practicality), I think they usually don't help to know if AIs can be trusted (and in particular they don't prevent any forms of alignment faking).
I agree that amplification arguments do not help to rule out alignment faking, but testbeds could help. I've read your post on protocol evaluations vs control [LW · GW]. If I remember correctly, the main objection you had to testbeds ruling out alignment faking is that the testbed models could intentionally throw off the results. I think this is a knock-down problem. For example, consider a testbed where models have been trained to defect if they are confident they've been deployed to the real internet. Then, developers could try to tell these models from benign ones without being able to access the real internet. It is straightforward in this case to verify that the behavior of the testbed models is consistent with their intended policies (nice when not on the internet, and otherwise bad). So, the only the models can do to throw off the test is to change their internal states (e.g. think in simple ways when they know they could otherwise obfuscate their reasoning by thinking in convoluted ways).
"Claim 4: AI systems are not faking alignment" is just extremely hard to assess. I think that the focus of trustworthiness assessment on "Claim 3: All enumerated causes of correlated infractions are unlikely aside from alignment faking." is somewhat unwarranted.
I agree claim 4 is hard to assess. I'm not sure what you mean by 'unwarranted' so I can't comment much on this.
I think the description of macrosystem risks was not very convincing, aside from risks that make systems less trustworthy - so I think macrosystem should maybe have been folded into trustworthiness.
I don't think it would have made sense to fold macrosystem risks into trustworthiness. One reason for this is that some macrosystem risks relate to control / inability. e.g. models might combine their intelligence at scale and become much more capable.
Another reason for this is that I also think it is harder to assess trustworthiness arguments at larger scales. In particular, not alignment faking arguments claim that de-correlated misalignment is not going to be an issue. At a macrosystem level, this requires answering the question: "would it be bad if 1% of my AI population was misaligned?" This is pretty different from answering the question "if one model in X subsystem is misaligned, would that be bad?"
The strength of almost all "high strength" measures is overrated, almost nothing is "strong" (where "strong" is defined as "Applies to arguments that could bring catastrophic risk below acceptable levels without needing other arguments."). Control is not strong, monitoring is not strong, externalized reasoning is not strong (for control and trustworthiness), ... Even with a notion of acceptable that is quite generous (e.g. 2% p(doom)) I think nothing is strong, but given the stakes I think we shouldn't use "acceptable" for anything above 1% (and ideally reserve that word for 0.1% or below).
I suspect that this disagreement might be mostly semantic. The main reason I labeled capability arguments as strong is that developers could in principle demonstrate a large margin of error. e.g. it's clear that gpt-2 is not going to cause a catastrophe. Or it could be very clear that smarter models are controlled if they are sufficiently isolated.
Strength labels indicate an upper bound. It's on me for not making that more clear.
↑ comment by Fabien Roger (Fabien) · 2024-03-22T14:37:36.817Z · LW(p) · GW(p)
My bad for testbeds, I didn't have in mind that you were speaking about this kind of testbeds as opposed to the general E[U|not scheming] analogies (and I forgot you had put them at medium strength, which is sensible for these kinds of testbeds). Same for "the unwarranted focus on claim 3" - it's mostly because I misunderstood what the countermeasures were trying to address.
I think I don't have a good understanding of the macrosystem risks you are talking about. I'll look at that more later.
I think I was a bit unfair about the practicality of techniques that were medium-strength - it's true that you can get some evidence for safety (maybe 0.3 bits to 1 bit) by using the techniques in a version that is practical.
On practicality and strength, I think there is a rough communication issue here: externalized reasoning is practical, but it's currently not strong - and it could eventually become strong, but it's not practical (yet). The same goes for monitoring. But when you write the summary, we see "high practicality and high max strength", which feels to me like it implies it's easy to get medium-scalable safety cases that get you acceptable levels of risks by using only one or two good layers of security - which I think is quite wild even if acceptable=[p(doom)<1%]. But I guess you didn't mean that, and it's just a weird quirk of the summarization?
Replies from: joshua-clymer↑ comment by joshc (joshua-clymer) · 2024-03-23T21:04:08.202Z · LW(p) · GW(p)
which feels to me like it implies it's easy to get medium-scalable safety cases that get you acceptable levels of risks by using only one or two good layers of security
I agree there's a communication issue here. Based on what you described, I'm not sure if we disagree.
> (maybe 0.3 bits to 1 bit)
I'm glad we are talking bits. My intuitions here are pretty different. e.g. I think you can get 2-3 bits from testbeds. I'd be keen to discuss standards of evidence etc in person sometime.
comment by habryka (habryka4) · 2024-03-20T17:43:01.193Z · LW(p) · GW(p)
Mod note: Made it a proper link post and added a link to the ArXiV version. Feel free to revert.
comment by zoop · 2024-03-21T19:39:22.431Z · LW(p) · GW(p)
I've published in this area so I have some meta comments about this work.
First the positive:
1. Assurance cases are the state of the art for making sure things don't kill people in a regulated environment. Ever wonder why planes are so safe? Safety cases. Because the actual process of making one is so unsexy (GSNs make me want to cry), people tend to ignore them, so you deserve lots of credit for somehow getting ex-risk people to upvote this. More lesswronger types should be thinking about safety cases.
2. I do think you have good / defensible arguments overall, minus minor quibbles that don't matter much.
Some bothers:
1. Since I used to be a little involved, I am perhaps a bit too aware of the absolutely insane amount of relevant literature was not mentioned. To me, the introduction made it sound a little bit like the specifics of applying safety cases to AI systems have not been studied. That is very, very, very not true.
That's not to say you don't have a contribution! Just that I don't think it was placed well in the relevant literature. Many have done safety cases for AI but they usually do it as part of concrete applied work on drones or autonomous vehicles, not ex-risk pie-in-the-sky stuff. I think your arguments would be greatly improved by referencing back to this work.
I was extremely surprised to see so few of the (to me) obvious suspects referenced, particularly more from York. Some labs with people that publish lots in this area.
- University of York Institute for Safe Autonomy
- NASA Intelligent Systems Division
- Waterloo Intelligent Systems Engineering Lab
- Anything funded by the DARPA Assured Autonomy program
2. Second issue is a little more specific, related to this paragraph:
To mitigate these dangers, researchers have called on developers to provide evidence that their systems are safe (Koessler & Schuett, 2023; Schuett et al., 2023); however, the details of what this evidence should
look like have not been spelled out. For example, Anderljung et al vaguely state that this evidence should be “informed by evaluations of dangerous capabilities and controllability”(Anderljung et al., 2023). Similarly, a recently proposed California bill asserts that developers should provide a “positive safety determination” that “excludes hazardous capabilities” (California State Legislature, 2024). These nebulous requirements raise questions: what are the core assumptions behind these evaluations? How might developers integrate other kinds of evidence?
The reason the "nebulous requirements" aren't explicitly stated is that when you make a safety case you assure the safety of a system against specific relevant hazards for the system you're assuring. These are usually identified by performing a HAZOP analysis or similar. Not all AI systems have the same list of hazards, so its obviously dubious to expect you can list requirements a priori. This should have been stated, imo.
Replies from: joshua-clymer↑ comment by joshc (joshua-clymer) · 2024-03-21T21:12:05.051Z · LW(p) · GW(p)
To me, the introduction made it sound a little bit like the specifics of applying safety cases to AI systems have not been studied
This is a good point. In retrospect, I should have written a related work section to cover these. My focus was mostly on AI systems that have only existed for ~ a year and future AI systems, so I didn't spend much time reading safety cases literature specifically related to AI systems (though perhaps there are useful insights that transfer over).
The reason the "nebulous requirements" aren't explicitly stated is that when you make a safety case you assure the safety of a system against specific relevant hazards for the system you're assuring. These are usually identified by performing a HAZOP analysis or similar. Not all AI systems have the same list of hazards, so its obviously dubious to expect you can list requirements a priori.
My impression is that there is still a precedent for fairly detailed guidelines that describe how safety cases are assessed in particular industries and how hazards should be analyzed. For example, see the UK's Safety Assessment Principles for Nuclear Facilities. I don't think anything exists like this for evaluating risks from advanced AI agents.
I agree, however, that not everyone who mentions that developers should provide 'safety evidence' should need to specify in detail what this could look like.
↑ comment by zoop · 2024-03-22T00:24:55.486Z · LW(p) · GW(p)
I hear what you're saying. I probably should have made the following distinction:
- A technology in the abstract (e.g. nuclear fission, LLMs)
- A technology deployed to do a thing (e.g. nuclear in a power plant, LLM used for customer service)
The question I understand you to be asking is essentially how do we make safety cases for AI agents generally? I would argue that's more situation 1 than 2, and as I understand it safety cases are basically only ever applied to case 2. The nuclear facilities document you linked definitely is 2.
So yeah, admittedly the document you were looking for doesn't exist, but that doesn't really surprise me. If you started looking for narrowly scoped safety principles for AI systems you start finding them everywhere. For example, a search for "artificial intelligence" on the ISO website results in 73 standards .
Just a few relevant standards, though I admit, standards are exceptionally boring (also many aren't public, which is dumb):
- UL 4600 standard for autonomous vehicles
- ISO/IEC TR 5469 standard for ai safety stuff generally (this one is decently interesting)
- ISO/IEC 42001 this one covers what you do if you set up a system that uses AI
You also might find this paper a good read: https://ieeexplore.ieee.org/document/9269875
Replies from: joshua-clymer↑ comment by joshc (joshua-clymer) · 2024-03-22T03:05:51.810Z · LW(p) · GW(p)
This makes sense. Thanks for the resources!
comment by DanielFilan · 2024-10-31T21:52:19.728Z · LW(p) · GW(p)
Since people have reported not being able to see the tweet thread, I will reproduce it in this comment (with pictures replaced by my descriptions of them):
If developers had to prove to regulators that powerful AI systems are safe to deploy, what are the best arguments they could use?
Our new report tackles the (very big!) question of how to make a ‘safety case’ for AI.
[image of the start of the paper]
We define a safety case as a rationale developers provide to regulators to show that their AI systems are unlikely to cause a catastrophe.
The term ‘safety case’ is not new. In many industries (e.g. aviation), products are ‘put on trial’ before they are released.
[cartoon of a trial: regulator is a judge, one side is a developer advancing a safety case, other side is a red team advancing a risk case]
We simplify the process of making a safety case by breaking it into six steps.
- Specify the macrosystem (all AI systems) and the deployment setting.
- Concretize 'AI systems cause a catastrophe' into specific unacceptable outcomes (e.g. the AI systems build a bioweapon)
- Justify claims about the deployment setting.
- Carve up the collection of AI systems into smaller groups (subsystems) that can be analyzed in isolation.
- Assess risk from subsystems acting unilaterally.
- Assess risk from subsystems cooperating together.
[The above, but in picture format]
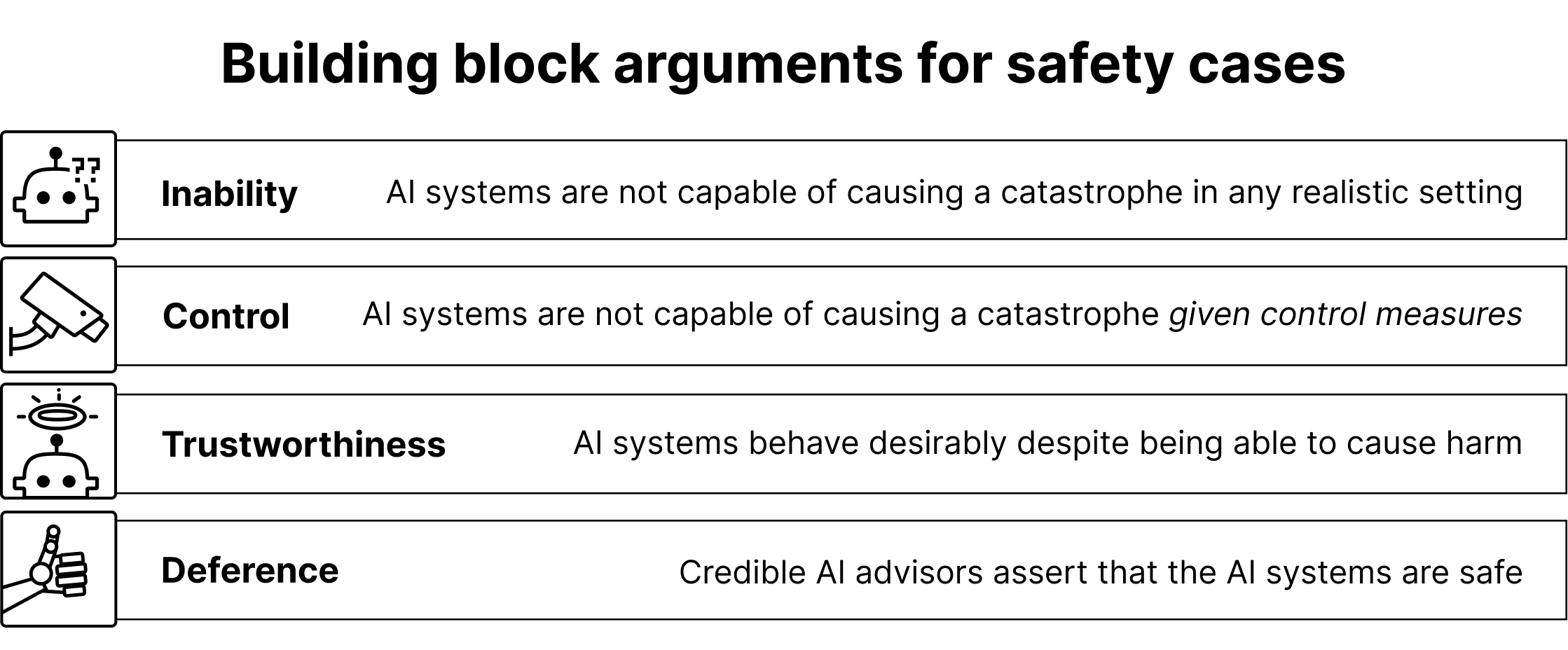
We first focus on step 5: how would developers argue that individual subsystems are safe? These arguments can be grouped into four categories.
Arguments could assert AI systems are
- too weak to be dangerous even if open-sourced (inability)
- unable to cause disaster due to restrictions (control)
- safe despite ablility to cause harm (trustworthiness)
- judged to be safe by credible AI advisors (deference)
[The above, but in picture format and slightly reworded]
Consider the analogy of a robber and a diamond. How might one justify that the robber won’t steal the diamond?
[Image with heading: "Why won't the robber steal the diamond?".
Row 1 says "Inability The robber is an infant. Analogy: e.g. GPT-3 is clearly too weak to be dangerous", next to an image of a baby near a diamond on a pedestal.
Row 2 says "Control The robber is in jail. Analogy: e.g. AI systems are sandboxed and can't escape.", next to an image of a prisoner in a box with bars, near a diamond on a pedestal.
Row 3 says "Trustworthiness The robber does not steal. Analogy: e.g. AI systems follow developer instructions.", next to an image of a person sitting down cross-legged and wearing an orange robe, next to a diamond on a pedestal.
Row 4 says "Deference The security service CEO says the diamond is secure. Analogy: AI advisors say that AI systems are safe.", next to an image of a figure with grey hair saying "All good" next to a diamond on a pedestal with lines coming out of it, connecting it to small grey boxes (sensors?).]
The ordering of these categories is intentional. As AI systems become more powerful, developers will likely rely mostly on inability, then control, then trustworthiness, and finally, deference to AI advisors.
[Image of graph where the horizontal axis is "Increasingly powerful AI" and the vertical axis is "Primary safety argument". Inability, Control, Trustworthiness, and Deference are shown in order from bottom-left to top-right. An arrow connects the words "We are here" to Inability.]
Next, we give examples of arguments in each category. Arguments are ranked on three axes:
- Practicality
- Strength
- Scalability
No argument received full marks! Research will be needed to justify the safety of advanced AI systems.
[A complicated diagram showing a variety of arguments under the Inability, Control, Trustworthiness, and Deference categories, together with ratings for their Practicality, Maximum Strength, and Scalability.]
The arguments in the previous step pertain to small groups of AI systems. It would be difficult to directly apply them to large groups. We also explain how to justify that the actions of many AI systems won’t cause a catastrophe (step 6 in our framework).
[Image titled "Large-scale AI misbehavior". Below are 3 rows, with 2 columns. The left column is labelled "Causes" and the right is labelled "Strategies".
Row 1: Cause: Widespread alignment faking. Strategy: Blitzkrieg: overwhelm controls
Row 2: Cause: Infectious jailbreaks. Strategy: Strike: disable infrastructure.
Row 3: Cause: Rapid memetic value drift. Strategy: Hivemind: combine intelligence.
dots are shown below, likely to indicate that there are more causes and strategies not shown.]
We are hoping this report will:
- Motivate research that further clarifies the assumptions behind safety arguments.
- Inform the design of hard safety standards.
More in the paper: https://bit.ly/3IJ5N95 Many thanks to my coauthors! @NickGabs01, @DavidSKrueger, and @thlarsen.
Might be of interest to @bshlgrs, @RogerGrosse, @DavidDuvenaud, @EvanHub, @aleks_madry, @ancadianadragan, @rohinmshah, @jackclarkSF, @Manderljung, @RichardMCNgo