The lattice of partial updatelessness
post by Martín Soto (martinsq) · 2024-02-10T17:34:40.276Z · LW · GW · 5 commentsContents
Computationally realistic commitments Factoring the space of information None 5 comments
In this post, I explore the fundamental conceptual structure of updateless commitments, by constructing a formalism for them.
I say your decision procedure updates on piece of information if is logically/computationally upstream of your decisions/actions. Or equivalently, if in a counterfactual where X is different some of your decisions/actions are different.[1]
An updateless commitment is committing to “not updating on these pieces of information”, for a certain definition of “these pieces of information”.
Say you are deciding which updateless commitment to implement.[2] Assume is the set of all pieces of information you could update on in the future.
You could be completely updateless, that is, commit to not updating on any piece of information (or equivalently, commit to not updating on the pieces of information in ).
You could be completely updateful, that is, not commit at all (or equivalently, commit to not updating on the pieces of information in the empty set).
In fact, your possible updateless commitments correspond exactly to the subsets of . For example, if , we’ll be able to arrange them in the usual power set lattice:
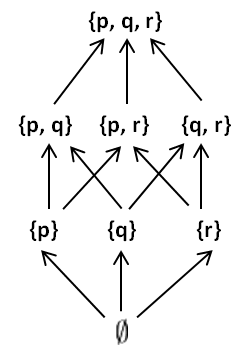
In the diagram, arrows indicate “is a subset of”. For example, is a subset of . And this relation corresponds exactly to “being more updateful than”. For example, “committing not to update on ” is (strictly) more updateful than “committing not to update on nor ”.
But some subsets (and commitments) are incomparable. For example, neither of “committing not to update on ” and “committing not to update on ” is more updateful than the other, because each one will know something the other won’t.
More realistically, will be (countably) infinite, so the lattice will be isomorphic to the following (which is the power set lattice of the natural numbers):
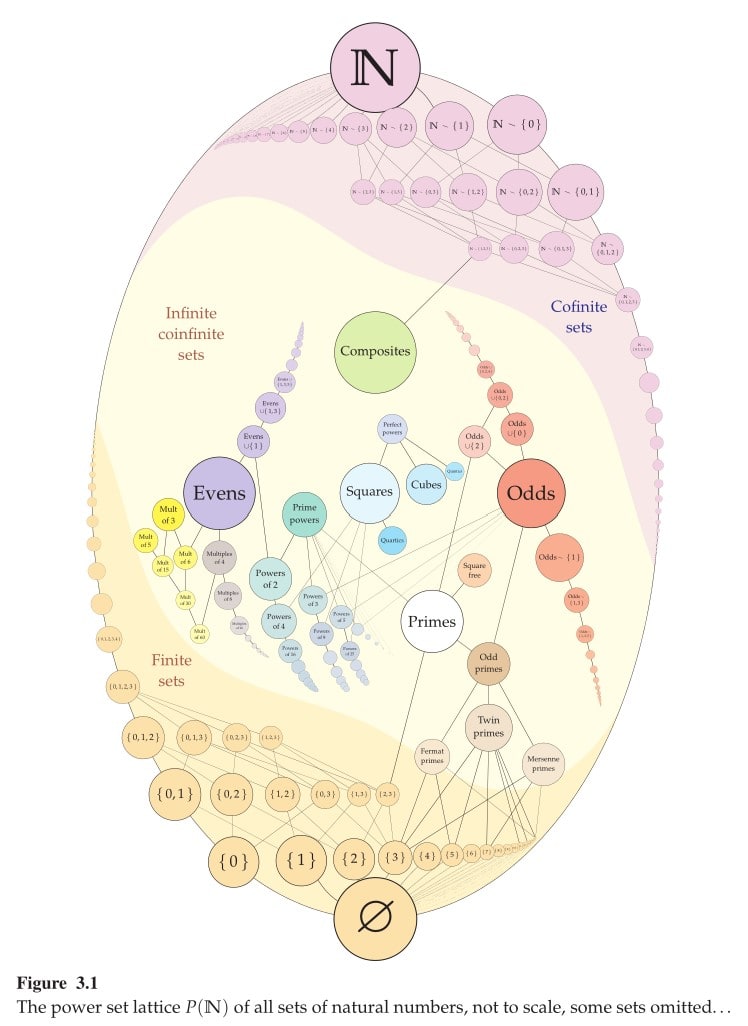
The finite subsets correspond to commitments of the form “I won’t update on [finite set]”.
The cofinite subsets correspond to commitments of the form “I will only update on [finite set]”.
The infinite coinfinite subsets cannot be explicited in this same way (listing their elements or those of their complement in a finite sentence), so we’ll need finitely describable programs to point to (some of) them, as in the next section.
Computationally realistic commitments
This picture would suggest there are an uncountable amount of possible updateless commitments (one for each subset of the natural numbers). Of course, that’s not true: a commitment is a program we can run (or a program we can self-modify ourselves into, or an algorithmic envelope we can wrap around our own algorithm to ensure it processes a kind of information). There are only countably many of those.
What’s happening is that an uncountable amount subsets (all of which are infinite coinfinite) are not computable. We have no way to describe them using a finite amount of information. So we need restrict ourselves to the commitments corresponding to computable sets, that is, the commitments specifiable by a finite program.
In fact, there’s a different reason why using programs that point at subsets (instead of subsets directly) is more realistic: the agent doesn’t really know in full!
We could ignore this and imagine, in our formalism, that each member of is a statement (of which our agent is aware), and our agent is only uncertain about its truth value.
But this is not what happens in reality: even where to be finite, there could be some statements that our agent has never even considered (and so that, simply looking at the statement, would immediately reveal its truth value). And again, in reality our amount of available commitments is (countably) infinite, so it’s obvious an agent (a finite algorithm) cannot have considered them all.[3]
So really, our agent has a partial and incomplete understanding of , and also of the finite programs that single out different members of .
Being overly formalistic, I could say is the subset of which the agent is aware of (but doesn’t know the truth value of). And that is the subset of all finite programs () that the agent is aware of. And for each , the agent might know some properties of it but not others. Where “properties” is “which pieces of information (in , since the agent doesn’t have access to ) the program accepts (updates on) or rejects (doesn’t update on)”. That is, each should be accompanied by two (disjoint) subsets of : one is the pieces of information the agent knows accepts, and the other is the pieces of information the agent knows rejects. Of course, some elements of might be in neither of them, that is, the agent ignores what the program outputs on them.
This formalism would need some additional constraints, because properties of such programs also correspond to pieces of information (or statements) in . That is, thinking about how these commitment programs behave is already updating on some information.
For example, whenever the agent knows “ accepts ” (let's call this statement ), we should also have that , and that it is true, which we could represent as a bit attached to each (in fact this would allow us to include in all the information the agent already knows, which is more natural).
Then, the agent would need to take some sequential deliberative action steps, some of which amount to “think a bit more about ”, others of which amount to “stop thinking and commit to only updating on the accepted by program ”, etc.
That is, given an and a (and the two disjoint sets for each ), the agent (which is an algorithm) decides what next step to take, which can be any of the following:
- explore a part of conceptual space looking for new members of
- think more about some member of to determine its truth value (or a vague guess as to the probability of it being true)
- look for new members of
- think more about whether a certain accepts a certain [4]
- commit to a .
Factoring the space of information
When we go even more realistic, we notice there need not be a sharp distinction between what the agent is completely aware of () and what the agent is not aware of at all (). The distinction might be more gradual. Maybe the agent is aware that something important, or “of this shape”, or “probably updating me in this direction”, exists in a certain cluster of the conceptual space (), but it’s not yet explored enough to cash it out into any concrete statements (elements of ).
A possible way to formalize this is to let the agent have multi-dimensional opinions on some subsets of (or whether such subsets exist), representing the “hunches or intuitions or outputs of coarse-grained heuristics” that the agent has about a part of concept-space. Of course, it’s unclear what structure to give these opinions, and as we try to further expand their flexibility to account for the general reasoning of real agents (which can only really be captured by “arbitrary programs running”), the formalism would get more complex and unwieldy. For example, we could add sets of such subsets representing “families of hunches” that the agent has recognized, etc.
A related problem is that the pieces of information might not be completely independent. Maybe being aware of (or knowing their truth value) makes you aware of (or its truth value).
We could try to get rid of this by enforcing that the elements of be independent in the following sense: from being aware of any subset of , you don’t immediately become aware of any element of outside that subset (and/or similarly for truth values).
I’m not sure this is possible to do for realistic situations. Even if it is, the resulting independent statements would probably look pretty weird and complex.
For both problems mentioned here (coarse-grained hunches, and independence), probably Finite Factored Sets could help. Maybe some discoveries amount to expanding the underlying Set, and others amount to being certain of a finer graining on the Set?
Maybe a family of Finite Factored Sets (to account for the progression of different partly disjoint “chains of thought”, that get ever-more-precise), which is itself a Finite Factored Family (because the “chains of thought” have some relationships between them, and even when they’re mostly separate an insight in one can update the other)?
Maybe an arbitrarily deep nesting of such Finite Factored Families? (Although maybe this ends up being equivalent to a single, bigger Finite Factored Set?)
In any event, I don’t feel like further developing this formalism would realistically help us much in knowing which kind of updatelessness we should implement. I think we just need to get our hands dirty and think about and ourselves (if that even seems net-positive), and which coarse-grained proxies might be less dangerous to do so, and which future deliberation process we want to use, etc. I think trying to clarify further the over-arching formalism, or “skeletal structure”, in which such reasoning will take place, is no longer that useful.
- ^
Any assessment of computational dependence (“which computations are upstream of which”), or of computational counterfactuals ("if this computation outputted a 1 instead of a 0, what would change in this other computation?"), is observer-dependent (post coming soon). I’ll ignore that here. You can assume this whole argument happens from the perspective of a fixed observer, that is, having statically fixed what we believe about computational dependence.
- ^
Equivalently, you are deciding which version of Open-Minded Updatelessness [LW · GW] to implement: one with a more expansive definition of awareness growth (more updateful, since you’ll update on more things), or one with a more reductive definition of awareness growth (more updateless).
- ^
Of course, a program deciding a set of pieces of information to update on might be as simple as “reject if the piece of information contains the word Dare”, or as complex as “run a copy of my general reasoning algorithm on this piece of information”. Not only do we face a trade-off in computational complexity and predictability (it will be harder to predict, from our current limited knowledge, what the latter does). We also face again the usual trade-off in strategicness [AF · GW]: many infohazards could already be triggered by this copy noticing them, even if they strategically decided not to relay the information to the main agent.
- ^
In fact, the third and fourth actions are more naturally understood as particular cases of the first and second, respectively.
5 comments
Comments sorted by top scores.
comment by RogerDearnaley (roger-d-1) · 2024-02-18T07:18:06.227Z · LW(p) · GW(p)
It's also possible to commit to not updating on a specific piece of information with a specific probability between 0 and 1. I could also have arbitrarily complex finite commitment structures such as "out of the set of bits {A, B, C, D, E}, I will update if and only if I learn that at least three of them are true" — something which could of course be represented by a separate bit derived from A, B, C, D, E in the standard three-valued logic that represents true, false, and unknown. Or I can do a "provisional commit" where I have decided not to update on a certain fact, and generally won't, but may under some circumstances run some computationally expensive operation to decide to uncommit. Whether or not I'm actually committed is then theoretically determinable, but may in practice have a significant minimal computational cost and/or informational requirements to determine (ones that I might sometimes have a motive to intentionally increase, if I wish to be hard-to-predict), so to some other computationally bounded or non-factually-omniscient agents this may be unknown.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-20T20:36:13.489Z · LW(p) · GW(p)
Yep! I hadn't included pure randomization in the formalism, but it can be done and will yield some interesting insights.
As you mention, we can also include pseudo-randomization. And taking these bounded rationality considerations into account also makes our reasoning richer and more complex: it's unclear exactly when an agent wants to obfuscate its reasoning from others, etc.
comment by Mateusz Bagiński (mateusz-baginski) · 2024-02-11T17:00:08.708Z · LW(p) · GW(p)
Of course, some elements of might be in neither of them, that is, the agent ignores what the program outputs on them.
So on those statements, the program may either update or not, but at the time of choosing the program, the agent can't predict those statements, so it can't use the programs' updatelessness or updatefulness in deciding which one to choose. Did I get that right?
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-20T20:34:03.455Z · LW(p) · GW(p)
First off, that was supposed to be , sorry.
The agent might commit to "only updating on those things accepted by program ", even when it still doesn't have the complete infinite list of "exactly in which things does update" (in fact, this is always the case, since we can't hold an infinite list in our head). It will, at the time of committing, know that updates on certain things, doesn't update on others... and it is uncertain about exactly what it does in all other situations. But that's okay, that's what we do all the time: decide on an endorsed deliberation mechanism based on its structural properties, without yet being completely sure of what it does (otherwise, we wouldn't need the deliberation). But it does advise against committing while being too ignorant.
comment by Mateusz Bagiński (mateusz-baginski) · 2024-04-05T16:55:10.046Z · LW(p) · GW(p)
Wouldn't total updatelessness amount to constantly taking one action? If not, I'm missing something important and would appreciate an explanation of what it is that I'm missing.