Open-minded updatelessness
post by Nicolas Macé (NicolasMace), JesseClifton, SMK (Sylvester Kollin) · 2023-07-10T11:08:22.207Z · LW · GW · 21 commentsContents
Summary
Introduction
Updatelessness in a game of Chicken
Crazy predictor
Dynamic awareness and open-mindedness
Chicken under dynamic unawareness
Exploitability
Exploitability in Chicken
Unexploitable open-mindedness
Future work
Acknowledgements
Appendix: Setting priors after awareness growth
None
21 comments
Summary
Bounded agents might be unaware of possibilities relevant to their decision-making. That is, they may not just be uncertain, but fail to conceive of some relevant hypotheses entirely. What's more, commitment races might pressure early AGIs into adopting an updateless policy from a position of limited awareness. What happens then when a committed AGI becomes aware of a possibility that’d have changed which commitment it’d have wanted to make in the first place? Motivated by this question, we develop "open-minded" extensions of updatelessness, where agents revise their priors upon experiencing awareness growth and reevaluate their commitment to a plan relative to the revised prior.
Introduction
Bounded agents may be unaware of propositions relevant to the decision problem they face.[1] That is, they don’t merely have uncertainty, but also fail to conceive of the full set of possibilities relevant to their decision-making. (For example, when playing a board game, one might be unaware of some crucial rule. Moreover, one’s awareness might grow, e.g. when one discovers such a rule midgame.)[2]
Awareness growth raises questions for commitment. What if one commits, and then discovers an important consideration, whose conception would have changed the plan one would have wanted to commit to? The earlier one commits, the less time one has to think about the relevant considerations, and the more likely this problem is to arise.
We are interested in preventing AGI systems from making catastrophic strategic commitments. One reason that not-fully-aware AGI systems could make bad commitments is that important hypotheses are missing for their priors. For example, they might fail to conceive of certain attitudes towards fairness that bargaining counterparts might possess. One might think that AGI agents would quickly become aware of all relevant hypotheses, and make commitments only then. But commitment race dynamics might pressure early AGIs into making commitments before thinking carefully, and in particular, in a position of limited awareness. From The Commitment Races problem [LW · GW] (emphasis ours):
If two consequentialists are playing a game of Chicken, the first one to throw out their steering wheel wins. […] More generally, consequentialist agents are motivated to make commitments as soon as possible, since that way they can influence the behavior of other consequentialist agents who may be learning about them. Of course, they will balance these motivations against the countervailing motive to learn more and think more before doing drastic things. The problem is that the first motivation will push them to make commitments much sooner than would otherwise be optimal. So they might not be as smart as us when they make their commitments, at least not in all the relevant ways.
In a commitment race, agents who are known to be updateless have a strategic advantage [AF · GW] over their updateful counterparts. Therefore, commitment races might introduce pressures for agents to become updateless as soon as possible, and one might worry that early-stage AGIs hastily adopt a version of updatelessness that mishandles awareness growth.
So we think it’s important to map out different ways one can go about being updateless when one’s awareness can grow. The aims of this post are to (1) argue for the relevance of unawareness to updatelessness and (2) explore several approaches to extending updatelessness to cases of awareness growth. Specifically, we introduce closed- and open-minded[3] versions of updatelessness:
- An agent is closed-mindedly updateless if they ignore awareness growth and continue being committed to their current plan. This approach is dynamically consistent, but clearly undesirable if one’s prior leaves out important propositions. (Moreover, the proposal is not in general well-defined.[4])
- An agent is open-mindedly updateless if they revise their priors upon experiencing awareness growth, and reevaluate their commitment to a plan relative to the revised prior. Roughly, an open-mindedly updateless agent follows the policy they should have committed to at the outset, by their current (more-aware) lights.
(Note that throughout this post, when we refer to an agent "revising" their prior in light of awareness growth, we are not talking about Bayesian conditionalization. We are talking about specifying a new prior over their new awareness state, which contains propositions that they had not previously conceived of.)
We take ex-ante optimality to be one motivation for updatelessness. However, the reduced vulnerability of updateless agents to exploitation is often highlighted.[5] And intuitively, being open-minded might leave one open to exploitation by agents using awareness growth adversarially. We introduce an ex-ante optimality and an unexploitability property, and show that they cannot be simultaneously satisfied in general in decision problems with growing awareness.[6] We define two open-minded extensions of updatelessness, each satisfying one of the two properties but not (always) the other. In our view, the ex-ante optimal version is preferable, despite being sometimes exploitable.
There are several key conceptual issues for updatelessness that we don't address in detail here, including:
- how priors should be set in each awareness state (where an agent's awareness state is defined as the set of propositions the agent is currently aware of). Instead, a theory for how priors should be set given an awareness state is an input into our model (but see the appendix [LW · GW] for a brief discussion of possible ways of setting priors);
- conceptual issues for logical uncertainty [? · GW] and logical updatelessness (setting logical priors, semantics for logical counterfactuals, whether and how to update on logical evidence);
- growing awareness of principles for setting priors. (Another way in which young agents might be “dumb” is that their priors may be arbitrary or derived from principles that they would not endorse upon reflection; plausibly agents should be able to revisit their commitments if they discover new principles for prior-setting.)
Updatelessness in a game of Chicken
Throughout this post, we’ll illustrate various ideas with a game of Chicken that we’ll gradually make more complex.
Updatelessness is particularly relevant in multi-agent contexts [AF · GW] where agents can predict each others' behaviour. Here, we'll consider the simple case where one agent is able to perfectly predict the other. One agent, "the predictor", perfectly predicts the other agent, who we'll call "Alice", and best-responds to Alice's decision. We'll focus on Alice's attitudes towards unawareness and awareness growth.
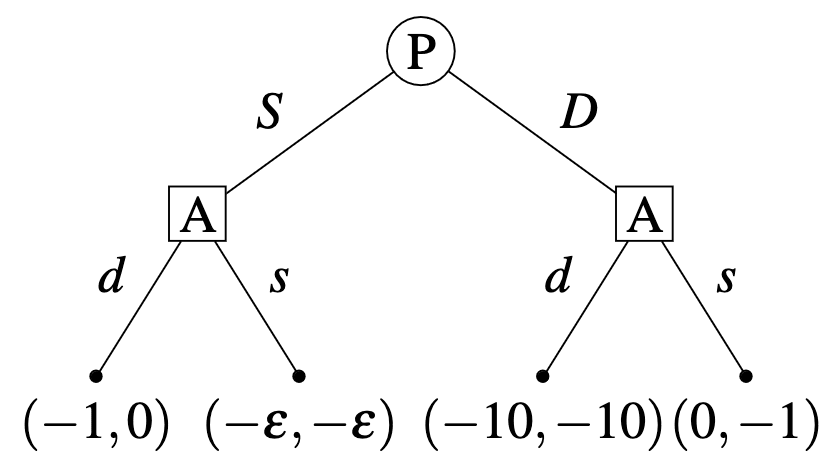
The predictor (P) moves first, Alice (A) observes P’s move and then makes her own move. For brevity, we write a policy of A as , where (resp. ) is the action she takes when observing P swerving (left node) (resp. when observing P daring (right node)). P will dare () if they predict and swerves () if they predict . The ordering of moves and the payoffs are displayed in Figure 1.
Note the Newcomblike flavor of this decision problem: conditional on P daring, A is better off swerving. However, if A’s policy is to dare conditional on P daring, P will predict it and swerve in the first place, which results in the best outcome possible for A.
Throughout the post, we’ll refer to the time corresponding to the epistemic perspective from which the agent decides to “go updateless” as “time 0”. In this example, we are supposing that Alice decides to go updatelessness from the epistemic perspective she has at the beginning of this game of Chicken. Now, we can define an updateless policy for Alice as follows:
- Alice implements a policy that maximizes the expected utility , where is a possible outcome (both dare, both swerve, etc) and is the probability of outcome supposing that Alice implements policy .[7] If Alice experiences awareness growth, her awareness state and thus her priors might change, as we’ll discuss later.
- For any policy that Alice implements, she believes that the predictor plays a particular policy with probability 1. That is, . We can think of as Alice’s subjective model of the predictor’s best-response to her policy . In the game of Chicken, we have , . The idea is that even if – in clock time – the predictor acts before the agent, they first predict what the agent will do, and play an optimal response.
Crazy predictor
In general, Alice’s awareness state might contain predictors of different types. In the game of Chicken, a particularly simple type is what we’ll call the crazy type: a predictor who dares no matter what Alice’s policy is.[8] [9]
Let’s assume for now that Alice is aware of the crazy predictor () and the “normal” predictor (). Let’s assume that Alice doesn’t know which type of predictor she’s facing. This strategic situation may be represented as follows:
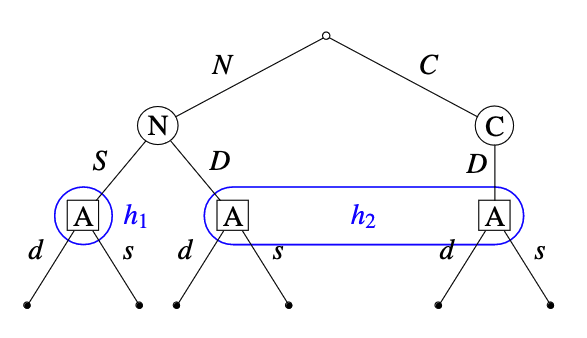
At the root of the tree, a type of predictor ( or ) is chosen by chance, unbeknownst to Alice.
The blue bubbles labeled and represent the two possible histories Alice might find herself at. At , she has observed the predictor swerve and now knows for sure that she’s facing the normal one. At , she could either be facing the normal or crazy one. By assumption, the normal predictor is able to perfectly predict how Alice will act at and , and best-responds to that.
Alice’s optimal policy depends on the prior probability she assigns to the predictor being crazy. If is sufficiently small then Alice’s optimal policy is to dare at , since the normal predictor she’s highly likely to face will predict this and swerve in the first place. If is close enough to 1, then it pays off for Alice to swerve at , since this avoids a crash against the crazy predictor she’s likely to face. With the specific payoffs introduced above, Alice has the expected utilities and , and she thus strictly prefers swerving if .
Dynamic awareness and open-mindedness
Now let's consider the case where the decision-maker is unaware of some relevant possibilities. For example, let's suppose that Alice is initially unaware of the possibility that the predictor is crazy, and only later does that possibility occur to her. What would it mean for Alice to be updateless, then?
First, let us give an informal definition of open-minded priors:
Open-minded priors: We say that an agent has open-minded priors if, whenever they experience awareness growth, they revise their priors to be the priors they should have assigned over their current awareness state at time 0, by their current (post-awareness-growth) lights.
A few things to note about this definition:
- It leaves open how "...priors they should have assigned" is to be understood. (One approach that is attractive, in our view, is for an agent to have a set of principles for assigning priors to arbitrary awareness states—principles which may themselves change as the agent reflects—and apply these to get new priors given each new awareness state.)
- It leaves open the principles by which agents should specify priors.
(See the appendix [LW · GW] for a bit more discussion of these points.)
As an (unrealistic) example of open-minded priors, suppose that Alice endorsed the principle of indifference for setting priors over hypotheses about the type of counterpart she faces in bargaining problems. Then, upon becoming aware of the possibility of crazy predictors, she would assign probabilities of to the hypotheses and . Slightly more realistically, she might think that the right way to set priors in this case is to think about things like the kinds of evolutionary processes that shape the reasoning of potential counterparts, and the distributions over strategies that they generate, and, given her prior credence in those to processes, assign a prior to and .[10]
We're now ready to state an (informal) definition of open-minded updatelessness:
Ex-ante optimal open-minded updatelessness (EA-OMU): An agent is EA-OMU up to history if at every point in at which their awareness has grown, the agent:
- Has open-minded priors;
- Begins to follow the optimal policy among the available ones, judged from the (hypothetical) time 0 epistemic state. (A policy is “available” if it prescribes actions matching what the agent actually did so far.)
Although we won't do it here for the sake of concision, it is possible to make the above definition fully mathematically rigorous. One approach there is to use the so-called "generalized extensive-form game" formalism of Heifetz et al (2013). We'll employ it below, in our example of Chicken under growing awareness.
Note also that an agent being EA-OMU up to doesn't guarantee that they'll remain EA-OMU in the future. Indeed, it might be the case that committing to a closed-minded policy becomes better by the agent’s lights at some point. We will briefly touch on this in the future work section [LW · GW] of the post.
Chicken under dynamic unawareness
As a simplistic example of EA-OMU, let’s go back to our Chicken example and suppose that Alice is initially unaware of the hypothesis “the predictor is crazy”.
Alice’s initial view of the game is represented by the bottom tree in Figure 3. In particular, Alice expects that, conditional on her always daring, the predictor will swerve with probability 1. Suppose that she nevertheless observes the predictor dare. We will assume that she then becomes aware of the possibility that the predictor is crazy.[11] We represent the strategic situation as follows:
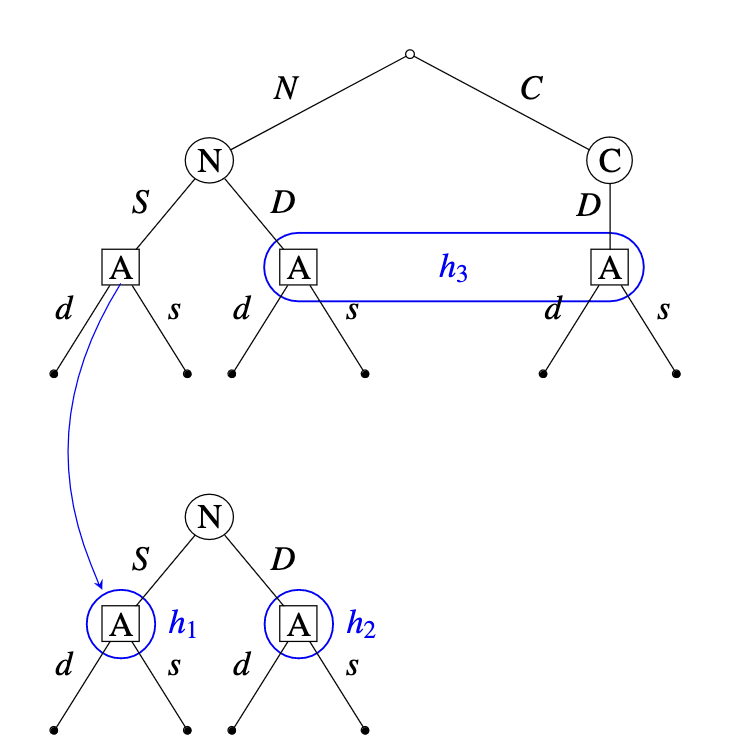
The set of two trees represents the objective view of the game. Depending on their history, agents may be in different awareness states and may thus entertain different subjective views of the decision problem they face. The picture above lets us compactly represent these subjective views. For simplicity, we’ll assume that the predictor is always fully aware and focus on Alice’s possible subjective views.
Suppose that Alice faces .
- Suppose moreover that plays . This situation is represented on panel (I) of Figure 4. In the top, objective tree, the corresponding path of play is shown in red. Alice’s current choice node is the leftmost one in the top tree, but since she doesn’t conceive of , her subjective history is and her subjective view of the game is represented by the bottom tree.
- Suppose now that plays . This situation is represented on panel (II) of Figure 4. In the top tree, the current path of play is again shown in red. Because she observed the predictor dare, Alice becomes aware of . Her history is , and her subjective view of the game is represented by the set of two trees.[12]
If Alice faces , the story is similar to (II).
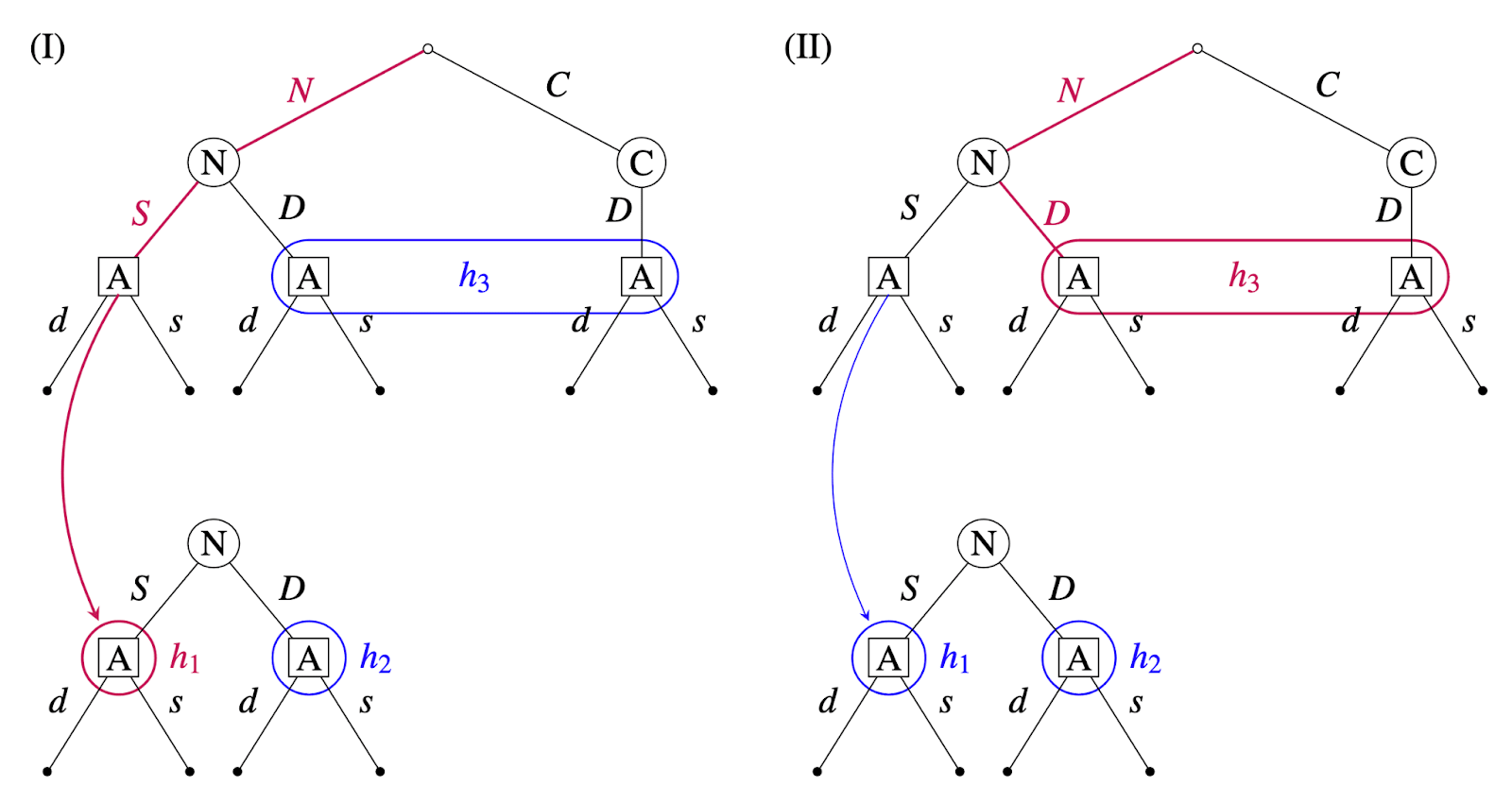
One would usually think of Alice as having two possible histories in this decision problem (DP): (i) observing the predictor swerve and (ii) observing the predictor dare. But in DPs with dynamic unawareness, an agent’s history tracks not only her observations and past actions (as in standard in decision-theoretic models), but also her awareness state. Hence the three possible histories for Alice: (i) observing the predictor swerve and being aware of only (), (ii) observing the predictor dare and being aware of only (), (iii) observing the predictor dare and being aware of and ().
The normal predictor predicts Alice’s full policy, that is, Alice’s action at each of the three possible histories. Again noting a policy as , we have:
- If predicts then they play and Alice doesn’t become aware of ,
- If predicts then they play , knowing that this will bring Alice to , where she is aware of and swerves.
Let be the the prior Alice assigns to proposition at history . If is large enough (larger than , with the payoffs given above), then the unique EA-OMU policy is . Otherwise, the EA-OMU policy is , and coincides with the policy of a closed-minded agent.
Exploitability
If the EA-OMU policy is , the normal predictor predicts it, and his optimal policy is to dare, thus making Alice aware of and causing her to swerve. One could say that the normal predictor exploits Alice's open-mindedness. More formally:
Awareness growth-exploitability: An agent is awareness growth-exploitable (or exploitable, for short), if the agent’s criterion for choosing policies in some decision problem with adversaries (for instance, predictors) is such that, for some priors and some type of adversary:
- The optimal policy of that type increases the agent’s awareness, and
- Among policies available to the agent in this new awareness state, the optimal policies (evaluated in the new state) conditioning on this type of adversary yield strictly lower expected utility than the expected utility of optimal policies prior to awareness growth (also evaluated in the new state).
Exploitability in Chicken
At , Alice’s continuation strategies are (dare at ) or (swerve at ). The open-mindedly updateless Alice with the specific payoffs introduced above has the expected utilities and . We can also compute the expected utilities conditional on Alice (perhaps counterfactually) facing the normal predictor: and . If we assume that , such that swerving is optimal, then the conditions of the definition above are satisfied and we conclude that EA-OMU is exploited.
It should be stressed that an EA-OMU policy is by definition ex-ante optimal given the agent’s post-awareness growth priors. In other words, insofar as Alice endorses her post-growth priors and finds ex-ante suboptimal strategies unacceptable, she must accept the possibility of being exploited in the sense defined above, in some circumstances.
Unexploitable open-mindedness
A trivial way for Alice to be unexploitable is to be closed-minded. A closed-minded Alice would simply act as if the hypothesis wasn’t in her awareness set, were she to find herself at . Foreseeing this, the normal predictor would always swerve, and Alice would indeed not be exploited. However, being closed-minded leads to clearly undesirable outcomes, as we mentioned in the introduction. Another option is to act closed-mindedly only if one thinks being open-minded would lead to exploitation. This idea can be informally spelled out as follows:
Unexploitable open-minded updatetelessness (UE-OMU): A agent is UE-OMU if they find EA-OMU policies acceptable unless revising policy post-awareness growth would make them exploitable, in which case the only acceptable policies are those which were pre-growth acceptable.
It can be the case that all policies an UE-OMU agent finds acceptable are ex-ante suboptimal. Indeed, in our game of Chicken, the only policy that is unexploitable (and compatible with updatelessness in the initial awareness state) is . However, with the payoffs and priors specified above, Alice doesn’t view as ex-ante optimal if she is aware of . And this problem can present itself in practice, since she will become aware of if she faces the crazy predictor.
Overall, we think that UE-OMU unduly privileges avoiding exploitation, and EA-OMU captures the relevant notion of optimality in the dynamic awareness setting.
Future work
A key question for EA-OMU is: Under what circumstances would an EA-OMU agent want to self-modify to be closed-minded (i.e., commit to a known policy henceforth, at least as long as it is well-defined)? For an EA-OMU agent to want to become CM, we think at least one of the following must hold:
- EA-OMU is more computationally expensive than CM;
- The agent believes that continuing to be EA-OMU can lead them to have certain beliefs or preferences they don’t currently endorse;
- The environment responds differently depending on whether the agent is EA-OMU or CM, all else equal. For instance, it may be easier for other agents to simulate a CM policy than an OM one, making a CM policy a more effective commitment.
We might write a follow-up post discussing this in more detail and more rigorously. (Note that this requires modeling an agent's beliefs about its future, post-awareness growth beliefs, and so requires more machinery than the framework presented here.)
Many other directions at the intersection of unawareness and updatelessness remain open, including:
- Handling logical uncertainty and logical unawareness (for instance using the framework of Pettigrew (2020));
- A more comprehensive account of open-mindedness. For example, should agents be open-minded with respect to their values?[13] Or, how should reflection on principles for setting priors given an awareness state be handled?
- Implications for the design of AGI systems. As we’ve said in the introduction, we're motivated by preventing AGIs from making catastrophic commitments, for instance in the context of a commitment race. So, this line of research would ideally cash out in concrete recommendations for the overseers of AGI systems (assuming that alignment succeeds for long enough for this to be relevant).
Acknowledgements
Thanks to Caspar Oesterheld, Martín Soto, Tristan Cook, Guillaume Corlouer, Burkhard Schipper, Anthony DiGiovanni, Lukas Finnveden, Tomas Bueno Momčilović, and James Faville for comments and suggestions.
Appendix: Setting priors after awareness growth
Much of the philosophical literature on unawareness has focused on what norms should govern our beliefs when our awareness changes. In the case of awareness growth, a popular idea is so-called ‘reverse Bayesianism’ (RB). (See, for example, Karni and Vierø 2013, 2015, as well as Wenmackers and Romeijn (2015) and Bradley (2017) for similar ideas.) RB roughly states that, for incompatible propositions , which one was previously aware of, the ratio should remain constant. (Notably, RB places no direct requirements on what credence ought to be assigned to the proposition one just became aware of.) We could similarly require open-minded priors to preserve ratios of prior credences for propositions the agent is already aware of. However, albeit prima facie plausible, and Steele and Stefánsson (2021) argue that RB can’t serve as a general norm, since awareness growth might be evidentially relevant to the comparison between the old propositions.
A complete solution would be to have a procedure for setting priors for any awareness state. There is of course a long history of discussion of generic principles for setting priors, including the principle of indifference, or giving greater weight to hypotheses that are simple [? · GW] or natural. Whilst this approach will often be computationally intractable, it might be a useful starting point.
As alluded to in the main text, another way – besides unawareness of object-level hypotheses – in which early AGIs may be “naive” is to have priors that are not based on any reasonable principles. We are therefore interested in expanding the framework presented here to define open-minded commitments that allow agents to modify their priors based on newly-discovered principles for setting priors. This might be especially important for ensuring that agents set the logical priors [? · GW] from which their commitments are derived according to reasonable but as-yet undiscovered principles. (Though it is not clear that any such principles exist.)
- ^
Cf. Embedded world models [LW · GW].
- ^
See Steele and Stefánsson (2021) for a recent philosophical introduction to reasoning under unawareness.
- ^
The term "open-mindedness" is derived from Wenmackers and Roeijn's (2016) "open-minded Bayesianism", a framework for Bayesianism in the presence of unawareness.
- ^
For example, suppose that a rule one just became aware of says that it is impossible to perform a certain action. If one’s plan prescribes that action, then the closed-minded agent is prima facie left without any guidance whatsoever. This is arguably not very problematic, as an agent could simply do something else whenever being closed-minded isn't well defined. For instance, they could be open-minded in such cases, or they could follow a policy that's the closest fit (on some metric) to the ill-defined closed-minded policy they intended to implement.
- ^
Note that we take the mere idea of updatelessness to be distinct from updateless decision theory (UDT), as per Scott Garrabrant's typology of LessWrong decision theory in this [LW · GW] post. In particular, updatelessness is a specific mode of planning (and corresponds to one of the axes in the aforementioned typology), whereas UDT is a specific updateless theory, which is similar to e.g. FDT. See this [LW · GW]post for further discussion.
- ^
Roughly, this can happen in scenarios that have the following two properties: (1) An adversary can make the agent aware of a fact. Due to this discovery, the agent changes their mind about what the optimal policy is, in a way that is beneficial to the adversary. (2) Changing their mind about the optimal policy is (2a) detrimental to the agent in worlds where the adversary makes the agent aware of the fact, but (2b) optimal at the outset (i.e., with respect to the set of all possible worlds).
- ^
Its exact form depends on what underlying decision theory we are assuming, e.g. EDT or FDT. In the former case, we use conditional probabilities and write , whereas in the latter case we might rely on some extension of do-calculus and write .
- ^
Note that predictors who dare by mistake or because they incorrectly predicted that Alice would swerve are crazy types by our definition.
- ^
While it might be the case that the predictor being crazy in the sense defined here is quite unlikely in our specific Chicken scenario, we think there are more plausible cases where an agent commits to a particular bargaining policy and where propositions analogous to “the predictor is crazy” that the agent didn't conceive of would have impacted her commitment. For example, the predictor may have made commitments on the basis of normative/fairness considerations that the agent hasn't conceived of.
- ^
For instance, Alice might consider the possibility that an evolutionary process gave the predictor a preference for crashing with other agents in games of Chicken. See Abreu and Sethi (2003) for a model of such a process.
- ^
This is of course not the only hypothesis she might become aware of. She might for instance become aware of the hypothesis according to which the predictor actually swerved but her senses deceived her.
- ^
The top tree represents Alice’s current conception of the strategic interaction. The bottom tree is there too because Alice is aware of the fact that, had the normal predictor dared, she’d have conceived of the strategic interaction as represented by the bottom tree.
- ^
21 comments
Comments sorted by top scores.
comment by Dagon · 2023-07-10T18:35:19.881Z · LW(p) · GW(p)
I'm glad this is being explored, but I have the same confusion as I had for https://www.lesswrong.com/posts/H9KekSfzHnPLTz4DE/boomerang-protocol-to-dissolve-some-commitment-races-2 [LW · GW] . The core of commitment races is adversarial situations. Any mechanism to revoke or change a commitment is directly giving up value IN THE COMMON FORMULATION of the problem. It may be valuable in different formulations, with utility for compromise or differential willpower (that is, some test of who swerves when players learn that BOTH committed before either learned of their opponent's commitment).
This model doesn't seem to really specify the full ruleset that it's optimizing for. It's not the classic game of Chicken, it's something else. What, specifically, are the true constraints, possible outcomes, and knowledge/decision/update/revocation/recommitment sequences for both players?
I also suspect you're conflating updates of knowledge with strength and trustworthiness of commitment. It's absolutely possible (and likely, in some formulations about timing and consistency) that a player can rationally make a commitment, and then later regret it, WITHOUT preferring at the time of commitment not to commit.
Replies from: JesseClifton↑ comment by JesseClifton · 2023-07-10T19:22:24.949Z · LW(p) · GW(p)
Thanks Dagon:
Any mechanism to revoke or change a commitment is directly giving up value IN THE COMMON FORMULATION of the problem
Can you say more about what you mean by “giving up value”?
Our contention is that the ex-ante open-minded agent is not giving up (expected) value, in the relevant sense, when they "revoke their commitment" upon becoming aware of certain possible counterpart types. That is, they are choosing the course of action that would have been optimal according to the priors that they believe they should have set at the outset of the decision problem, had they been aware of everything they are aware of now. This captures an attractive form of deference — at the time it goes updateless / chooses its commitments, such an agent recognizes its lack of full awareness and defers to a version of itself that is aware of more considerations relevant to the decision problem.
As we say, the agent does make themselves exploitable in this way (and so “gives up value” to exploiters, with some probability). But they are still optimizing the right notion of expected value, in our opinion.
So I’d be interested to know what, more specifically, your disagreement with this perspective is. E.g., we briefly discuss a couple of alternatives (close-mindedness and awareness growth-unexploitable open-mindedness). If you think one of those is preferable I’d be keen to know why!
This model doesn't seem to really specify the full ruleset that it's optimizing for
Sorry that this isn’t clear from the post. I’m not sure which parts were unclear, but in brief: It’s a sequential game of Chicken in which the “predictor” moves first; the predictor can fully simulate the “agent’s” policy; there are two possible types of predictor (Normal, who best-responds to their prediction, and Crazy, who Dares no matter what); and the agent starts off unaware of the possibility of Crazy predictors, and only becomes aware of the possibility of Crazy types when they see the predictor Dare.
If a lack of clarity here is still causing confusion, maybe I can try to clarify further.
I also suspect you're conflating updates of knowledge with strength and trustworthiness of commitment. It's absolutely possible (and likely, in some formulations about timing and consistency) that a player can rationally make a commitment, and then later regret it, WITHOUT preferring at the time of commitment not to commit.
I’m not sure I understand your first sentence. I agree with the second sentence.
Replies from: Dagon↑ comment by Dagon · 2023-07-10T20:11:07.837Z · LW(p) · GW(p)
Any mechanism to revoke or change a commitment is directly giving up value IN THE COMMON FORMULATION of the problem
Can you say more about what you mean by “giving up value”?
Sure. In the common formulation https://en.wikipedia.org/wiki/Chicken_(game) , when Alice believes (with more than 1000:1 probability) that she is first mover against a rational opponent, she commits to Dare. The ability to revoke this commitment hurts her if her opponent commits in the meantime, as she is now better off swerving, but worse off than if her commitment had been (known to be) stronger.
For this to be wrong, the opponent must be (with some probability) irrational - that's a HUGE change in the setup. Whether she wants to lose (by just always Swerve, regardless of opponent), or wait for more information about the opponent is based on her probability assessment of whether the opponent is actually irrational. If she assigns it 0% (correctly or in-), she should commit or she's giving up expected value based on her current knowledge. If she assigns it higher than that, it will depend on the model of what is the distribution of opponents and THEIR commitment timing.
You can't just say "Alice has wrong probability distributions, but she's about to learn otherwise, so she should use that future information". You COULD say "Alice knows her model is imperfect, so she should be somewhat conservative, but really that collapses to a different-but-still-specific probability distribution.
You don't need to bring updates into it, and certainly don't need to consider future updates. https://www.lesswrong.com/tag/conservation-of-expected-evidence [? · GW] means you can only expect any future update to match your priors.
Replies from: JesseClifton↑ comment by JesseClifton · 2023-07-10T21:18:57.377Z · LW(p) · GW(p)
For this to be wrong, the opponent must be (with some probability) irrational - that's a HUGE change in the setup
For one thing, we’re calling such agents “Crazy” in our example, but they need not be irrational. They might have weird preferences such that Dare is a dominant strategy. And as we say in a footnote, we might more realistically imagine more complex bargaining games, with agents who have (rationally) made commitments on the basis of as-yet unconceived of fairness principles, for example. An analogous discussion would apply to them.
But in any case, it seems like the theory should handle the possibility of irrational agents, too.
You can't just say "Alice has wrong probability distributions, but she's about to learn otherwise, so she should use that future information". You COULD say "Alice knows her model is imperfect, so she should be somewhat conservative, but really that collapses to a different-but-still-specific probability distribution.
Here’s what I think you are saying: In addition to giving prior mass to the hypothesis that her counterpart is Normal, Alice can give prior mass to a catchall that says “the specific hypotheses I’ve thought of are all wrong”. Depending on the utilities she assigns to different policies given that the catchall is true, then she might not commit to Dare after all.
I agree that Alice can and should include a catchall in her reasoning, and that this could reduce the risk of bad commitments. But that doesn’t quite address the problem we are interested in here. There is still a question of what Alice should do once she becomes aware of the specific hypothesis that the predictor is Crazy. She could continue to evaluate her commitments from the perspective of her less-aware self, or she could do the ex-ante open-minded thing and evaluate commitments from the priors she should have had, had she been aware of the things she’s aware of now. These two approaches come apart in some cases, and we think that the latter is better.
You don't need to bring updates into it, and certainly don't need to consider future updates. https://www.lesswrong.com/tag/conservation-of-expected-evidence [? · GW] means you can only expect any future update to match your priors.
I don’t see why EA-OMU agents should violate conservation of expected evidence (well, the version of the principle that is defined for the dynamic awareness setting).
Replies from: Dagon↑ comment by Dagon · 2023-07-11T04:07:28.967Z · LW(p) · GW(p)
I think if you fully specify the model (including the reasons for commitment rather than just delaying the decision in the first place), you'll find that the reason for committing is NOT about updates, but about adversarial game theory. Specifically, include in your model that if facing a NORMAL opponent, failure to commit turns your (D, S) outcome (+1) into a (S, D) (-1), because the normal opponent will dare if you haven't committed, and then you are best off swerving. You've LOST VALUE because you gave too much weight to the crazy opponent.
How your (distribution of) opponents react to your strategy, which is conditional on your beliefs about THEIR strategy is the core of game theory. If you have a mix of crazy opponents and rational opponents who you think haven't committed yet, you don't need to introduce any update mechanisms, you just need your current probability estimates about the distribution, and commit or don't based on maximizing your EV.
Where the conservation of expected evidence comes in is that you CANNOT expect to increase your chances of facing a crazy opponent. If you did expect that, you actually have a different prior than you think.
Replies from: JesseClifton↑ comment by JesseClifton · 2023-07-11T11:38:56.480Z · LW(p) · GW(p)
The model is fully specified (again, sorry if this isn’t clear from the post). And in the model we can make perfectly precise the idea of an agent re-assessing their commitments from the perspective of a more-aware prior. Such an agent would disagree that they have lost value by revising their policy. Again, I’m not sure exactly where you are disagreeing with this. (You say something about giving too much weight to a crazy opponent — I’m not sure what “too much” means here.)
Re: conservation of expected evidence, the EA-OMU agent doesn’t expect to increase their chances of facing a crazy opponent. Indeed, they aren’t even aware of the possibility of crazy opponents at the beginning of the game, so I’m not sure what that would mean. (They may be aware that their awareness might grow in the future, but this doesn’t mean they expect their assessments of the expected value of different policies to change.) Maybe you misunderstand what we mean by "unawareness"?
Replies from: Dagon↑ comment by Dagon · 2023-07-11T17:03:58.270Z · LW(p) · GW(p)
The missing part is the ACTUAL distribution of normal vs crazy opponents (note that "crazy" is perfectly interchangeable with "normal, who was able to commit first"), and the loss that comes from failing to commit against a normal opponent. Or the reasoning that a normal opponent will see it as commitment, even when it's not truly a commitment if the opponent turns out to be crazy.
Anyway, interesting discussion. I'm not certain I understand where we differ on it's applicability, but I think we've hashed it out as much as possible. I'll continue reading and thinking - feel free to respond or rebut, but I'm unlikely to comment further. Thanks!
comment by ben_levinstein (benlev) · 2023-07-25T10:45:20.590Z · LW(p) · GW(p)
I think the basic approach to commitment for the open-minded agent is right. Roughly, you don't actually get to commit your future-self to things. Instead, you just do what you (in expectation) would have committed yourself to given some reconstructed prior.
Just as a literature pointer: If I recall correctly, Chris Meacham's approach in "Binding and Its Consequences" is ultimately to estimate your initial credence function and perform the action from the plan with the highest EU according to that function. He doesn't talk about awareness growth, but open-mindedness seems to fit in nicely within his framework (or at least the framework I recall him having).
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-09-29T15:50:11.049Z · LW(p) · GW(p)
This whole reconstructed-prior business seems fishy to me. Let's presuppose, as people seem to be doing, that there is a clean distinction between empirical evidence and 'logical' or 'a priori' evidence. Such that we can scrub away our empirical evidence and reconstruct a prior, i.e. construct a probability distribution that we would have had if we somehow had zero empirical evidence but all the logical evidence we currently have.
Doesn't the problem just recur? Literally this is what I was thinking when I wrote the original commitment races problem post; I was thinking that just 'going updateless' in the sense of acting according to the commitments that make sense from a reconstructed prior, didn't solve the whole problem, just the empirical-evidence flavor of the problem. Maybe that's still progress, of course...
And then also there is the question of whether these two kinds of evidence really are that distinct anyway.
↑ comment by JesseClifton · 2023-09-29T17:15:53.831Z · LW(p) · GW(p)
Can you clarify what “the problem” is and why it “recurs”?
My guess is that you are saying: Although OM updatelessness may work for propositions about empirical facts, it’s not clear that it works for logical propositions. For example, suppose I find myself in a logical Counterfactual Mugging regarding the truth value of a proposition P. Suppose I simultaneously become aware of P and learn a proof of P. OM updatelessness would want to say: “Instead of accounting for the fact that you learned that P is true in your decision, figure out what credence you would have assigned to P had you been aware of it at the outset, and do what you would have committed to do under that prior”. But, we don’t know how to assign logical priors.
Is that the idea? If so, I agree that this is a problem. But it seems like a problem for decision theories that rely on logical priors in general, not OM updatelessness in particular. Maybe you are skeptical that any such theory could work, though.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-09-29T17:42:03.554Z · LW(p) · GW(p)
OK, let's suppose all relevant agents follow some sort of updatelessness, i.e. they constantly act according to the policy that would have been optimal to commit to, from the perspective of their reconstructed prior. But their reconstructed prior is changing constantly as they learn more, e.g. as they become aware of "crazy" possible strategies their opponents might use.
Can the agents sometimes influence each other's priors? Yes. For example by acting 'crazy' in some way they didn't expect, you might cause them to revise their prior to include that possibility -- indeed to include it with significant probability mass!
OK, so then some of the agents will think "Aha, I can influence the behavior of the others in ways that I like, by committing to various 'crazy' strategies that place incentives on them. Once they become aware of my action, they'll revise their prior, and then the optimal commitment for them to have made in light of that prior is to conform to the incentives I placed on them, so they will."
... I'll stop there for now. Do you see what I mean? It's literally the commitment races problem. Agents racing to make various commitments in order to influence each other, because they expect that the others might be so influenced.
Now you might think that it's generally harder to influence someone's reconstructed-prior than to influence their posterior; if you do something that was 'in distribution' for their current reconstructed prior, for example, then they won't update their reconstructed prior at all, they'll just update their posterior. I think this is plausible but I'd want to see it spelled out in more detail how much of the problem it solves; certainly not all of it, at least so says my current model which might be wrong.
↑ comment by JesseClifton · 2023-09-29T18:37:11.889Z · LW(p) · GW(p)
If I understand correctly, you’re making the point that we discuss in the section on exploitability. It’s not clear to me yet why this kind of exploitability is objectionable. After all, had the agent in your example been aware of the possibility of crazy agents from the start, they would have wanted to swerve, and non-crazy agents would want to take advantage of this. So I don’t see how the situation is any worse than if the agents were making decisions under complete awareness.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-10-04T02:14:13.623Z · LW(p) · GW(p)
How is it less objectionable than regular ol' exploitability? E.g. someone finds out that you give in to threats, so they threaten you, so you give in, and wish you had never been born -- you are exploitable in the classic sense. But it's true that if you had been aware from the beginning that you were going to be threatened, you would have wanted to give in.
Part of what I'm doing here is trying to see if my understanding of your work is incorrect. To me, it seems like you are saying "Let's call some kinds of changes-to-credences 'updates' and other kinds 'awareness-growth.' Here's how to distinguish them. Now, we recommend the strategy of EA-OMU, which means you calculate what your credences would have been if you never made any updates but DID make the awareness-growth changes, and then calculate what policy is optimal according to those credences, and then do that.'
If that's what you are saying, then the natural next question is: What if anything does this buy us? It doesn't solve the commitment races problem, because the problem still remains so long as agents can strategically influence each other's awareness growth process. E.g. "Ah, I see that you are an EA-OMU agent. I'm going to threaten you, and then when you find out, even though you won't update, your awareness will grow, and so then you'll cave. Bwahaha."
Also, how is this different from the "commitment races in logical time" situation? Like, when I wrote the original commitment races post it was after talking with Abram and realizing that going updateless didn't solve the problem because agents aren't logically omniscient, they need to gradually build up more hypotheses and more coherent priors over time. And even if they are updateless with respect to all empirical evidence, i.e. they never update their prior based on empirical evidence, their a priori reasoning probably still results in race dynamics. Or at least so it seemed to me.
I don't think I fully understand the proposal so it's likely I'm missing something here.
I do find it plausible that being updateless about empirical (but not logical) stuff at least ameliorates the problem somewhat, and as far as I can tell that's basically equivalent to saying being EA-OMU is better than being a naive consequentialist at least. But I wish I understood the situation well enough to crisply articulate why.
↑ comment by JesseClifton · 2023-10-04T11:18:33.621Z · LW(p) · GW(p)
But it's true that if you had been aware from the beginning that you were going to be threatened, you would have wanted to give in.
To clarify, I didn’t mean that if you were sure your counterpart would Dare from the beginning, you would’ve wanted to Swerve. I meant that if you were aware of the possibility of Crazy types from the beginning, you would’ve wanted to Swerve. (In this example.)
I can’t tell if you think that (1) being willing to Swerve in the case that you’re fully aware from the outset (because you might have a sufficiently high prior on Crazy agents) is a problem. Or if you think (2) this somehow only becomes a problem in the open-minded setting (even though the EA-OMU agent is acting according to the exact same prior as they would've if they started out fully aware, once their awareness grows).
(The comment about regular ol exploitability suggests (1)? But does that mean you think agents shouldn't ever Swerve, even given arbitrarily high prior mass on Crazy types?)
What if anything does this buy us?
In the example in this post, the ex ante utility-maximizing action for a fully aware agent is to Swerve. The agent starts out not fully aware, and so doesn’t Swerve unless they are open-minded. So it buys us being able to take actions that are ex ante optimal for our fully aware selves when we otherwise wouldn’t have due to unawareness. And being ex ante optimal from the fully aware perspective seems preferable to me than being, e.g., ex ante optimal from the less-aware perspective.
More generally, we are worried that agents will make commitments based on “dumb” priors (because they think it’s dangerous to think more and make their prior less dumb). And EA-OMU says: No, you can think more (in the sense of becoming aware of more possibilities), because the right notion of ex ante optimality is ex ante optimality with respect to your fully-aware prior. That's what it buys us.
And revising priors based on awareness growth differs from updating on empirical evidence because it only gives other agents incentives to make you aware of things you would’ve wanted to be aware of ex ante.
they need to gradually build up more hypotheses and more coherent priors over time
I’m not sure I understand—isn't this exactly what open-mindedness is trying to (partially) address? I.e., how to be updateless when you need to build up hypotheses (and, as mentioned briefly, better principles for specifying priors).
↑ comment by SMK (Sylvester Kollin) · 2023-07-25T22:27:38.834Z · LW(p) · GW(p)
Thanks.
Roughly, you don't actually get to commit your future-self to things. Instead, you just do what you (in expectation) would have committed yourself to given some reconstructed prior.
Agreed.
Just as a literature pointer: If I recall correctly, Chris Meacham's approach in "Binding and Its Consequences" is ultimately to estimate your initial credence function and perform the action from the plan with the highest EU according to that function.
Yes, that's a great paper! (I think we might have had a footnote on cohesive decision theory in a draft of this post.) Specifically, I think the third version of cohesive decision theory which Meacham formulates (in footnote 34), and variants thereof, are especially relevant to dynamic choice with changing awareness. The general idea (as I see it) would be that you optimize relative to your ur-priors, and we may understand the ur-prior function as the prior you would or should have had if you had been more aware. So when you experience awareness growth, the ur-priors change (and thus the evaluation of a given plan will often change as well).
He doesn't talk about awareness growth, but open-mindedness seems to fit in nicely within his framework (or at least the framework I recall him having).
(Meacham actually applies the ur-prior concept and ur-prior conditionalization to awareness growth in this paper.)
comment by Martín Soto (martinsq) · 2023-07-11T12:21:29.137Z · LW(p) · GW(p)
Very interesting and exciting! I remain worried that this presupposes solutions to some central problems we're still very confused about, and thus has some chance of not being representative of the real decision-theoretic landscape. More concretely, I think the directions below
There are several key conceptual issues for updatelessness that we don't address in detail here, including:
seem, conceptually, what should be "attacked first", since too much depends on them. And similarly, when you say
Whilst this approach will often be computationally intractable, it might be a useful starting point.
I don't feel like any of these approaches are yet a useful starting point, and the jury is still open on whether such an idealized point even exists.
That said, of course, I'm very interested to see where your new angle could lead!
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-07-14T21:09:26.072Z · LW(p) · GW(p)
A) observes P’s move and then makes her own move. For brevity, we write a policy of A as , where (resp. ) is the action she takes when observing P swerving (left node) (resp. when observing P daring (right node)). P will dare () if they predict and swerves () if they predict . The ordering of moves and the payoffs are displayed in Figure 1.
Why does Alice get more utility from swerving than daring, in the case where the predictor swerves? ETA: Fixed typo
↑ comment by Nicolas Macé (NicolasMace) · 2023-07-15T08:25:32.500Z · LW(p) · GW(p)
Seems like the payoffs of the two agents were swapped in the figure; this should be fixed now. Thanks for pointing it out!
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-07-14T20:48:02.323Z · LW(p) · GW(p)
(Note that throughout this post, when we refer to an agent "revising" their prior in light of awareness growth, we are not talking about Bayesian conditionalization. We are talking about specifying a new prior over their new awareness state, which contains propositions that they had not previously conceived of.)
Nice. One reason this is important is that if you were just doing the bayesian conditionalization thing, you'd be giving up on some of the benefits of being updateless, and in particular making it easy for others to exploit you. I'll be interested to read and think about whether doing this other thing avoids that problem.
↑ comment by SMK (Sylvester Kollin) · 2023-07-14T23:42:24.173Z · LW(p) · GW(p)
What do you mean by "the Bayesian Conditionalization thing" in this context? (Just epistemically speaking, standard Conditionalization is inadequate for dealing with cases of awareness growth. Suppose, for example, that one was aware of propositions {X, Y}, and that this set later expands to {X, Y, Z}. Before this expansion, one had a credence P(X ∨ Y) = 1, meaning Conditionalization recommends remaining certain in X ∨ Y; i.e., one is only permitted to place a credence P(Z) = 0. Maybe you are referring to something like Reverse Bayesianism?)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-07-15T02:34:40.501Z · LW(p) · GW(p)
I just meant standard conditionalization, which I agree is inadequate for cases of awareness growth. I wasn't making a particularly new point, just commenting aloud as I read along.