Updatelessness doesn't solve most problems
post by Martín Soto (martinsq) · 2024-02-08T17:30:11.266Z · LW · GW · 45 commentsContents
What is Updatelessness? A fundamental trade-off Multi-agentic interactions Is the trade-off avoidable? Superintelligences Other lenses Conclusion Acknowledgements None 45 comments
In some discussions (especially about acausal trade [? · GW] and multi-polar conflict), I’ve heard the motto “X will/won’t be a problem because superintelligences will just be Updateless”. Here I’ll explain (in layman’s terms) why, as far as we know, it’s not looking likely that a super satisfactory implementation of Updatelessness exists, nor that superintelligences automatically implement it, nor that this would drastically improve multi-agentic bargaining.
Epistemic status: These insights seem like the most robust update from my work with Demski on Logical Updatelessness and discussions with CLR employees about Open-Minded Updatelessness [LW · GW]. To my understanding, most researchers involved agree with them and the message of this post.
What is Updatelessness?
This is skippable if you’re already familiar with the concept.
It’s easier to illustrate with the following example: Counterfactual Mugging.
I will throw a fair coin.
- If it lands Heads, you will be able to freely choose whether to pay me $100 (and if so, you will receive nothing in return).
- If it lands Tails, I will check whether you paid me the $100 in the Heads world[1], and if so, I will pay you $1000.
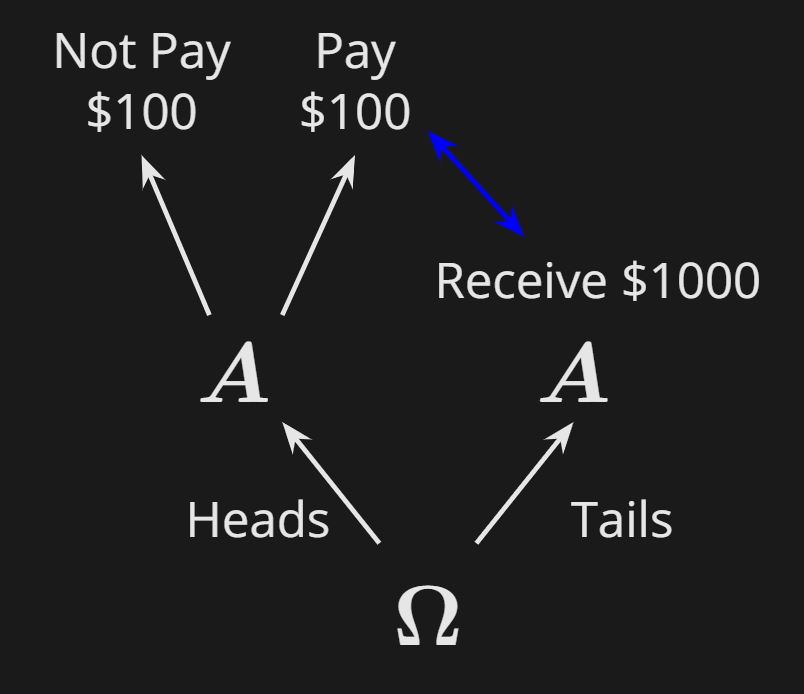
When you find yourself in the Heads world, one might argue, the rational thing to do is to not pay. After all, you already know the coin landed Heads, so you will gain nothing by paying the $100 (assume this game is not iterated, etc.).
But if, before knowing how the coin lands, someone offers you the opportunity of committing to paying up in the Heads world, you will want to accept it! Indeed, you’re still uncertain about whether you’ll end up in the Heads or the Tails world (50% chance on each). If you don’t commit, you know you won’t pay if you find yourself in the Heads world (and so also won’t receive $1000 in the Tails world), so your expected payoff is $0. But if you commit, your payoff will be -$100 in the Heads world, and $1000 in the Tails world, so $450 in expectation.
This is indeed what happens to the best-known decision theories (CDT and EDT): they want to commit to paying, but if they don’t, by the time they get to the Heads world they don’t pay. We call this dynamic instability, because different (temporal) versions of the agent seem to be working against each other.
Why does this happen? Because, before seeing the coin, the agent is still uncertain about which world it will end in, and so still “cares” about what happens in both (and this is reflected in the expected value calculation, when we include both with equal weight). But upon seeing the coin land, the agent updates on the information that it’s in the Heads world, and the Tails world doesn’t exist, and so stops “caring” about the latter.
This is not so different from our utility function changing (before we were trying to maximize it in two worlds, now only in one), and we know that leads to instability.
An updateless agent would use a decision procedure that doesn’t update on how the coin lands. And thus, even if it found itself in the Heads world, it would acknowledge its previous credences gave equal weight to both worlds, and so pay up (without needing to have pre-committed to do so), because this was better from the perspective of the prior.
Indeed, Updatelessness is nothing more than “committing to maximize the expected value from the perspective of your prior” (instead of constantly updating your prior, so that the calculation of this expected value changes). This is not always straight-forward or well-defined (for example, what if you learn of a radically new insight that you had never considered at the time of setting your prior?), so we need to fill in more details to obtain a completely defined decision theory. But that’s the gist of it.
Updatelessness allows you to cooperate with your counterfactual selves (for example, your Heads self can cooperate with your Tails self), because you both care about each others’ worlds. Updatelessness allows for this kind of strategicness: instead of each counterfactual self doing its own thing (possibly at odds with other selves), they all work together to maximize expected utility according to the prior.
Also, between the two extremes of complete updatelessness (commit right now to a course of action forever that you’ll never revise, which is the only dynamically stable option) and complete updatefulness (basically EDT or CDT as usually presented), there’s an infinite array of decision theories which are “partially updateless”: they update on some kinds of information (so they’re not completely stable), but not others.[2]
The philosophical discussion about which exact decision theory seems better (and how updateless it is) is completely open (none the less because there doesn’t exist an objective metric to compare decision theories’ performance). But now you have a basic idea of why Updatelessness has some upshot.
A fundamental trade-off
This dichotomy between updating or not doesn’t only happen for empirical uncertainty (how the empirical coin will land): it also happens for logical/mathematical/computational uncertainty. Say, for instance, you are uncertain about whether the trillionth digit of pi is Even or Odd. We can play the same Counterfactual Mugging as above, just with this “mathematical coin” instead of an empirical coin[3].
So now, if you think you might play this game in the future, you have a reason not to learn about the trillionth digit of pi: you want to preserve your strategicness, your coordination with your counterfactuals, since that seems better in expected value from your current prior (which is uncertain about the digit, and so cares about both worlds). Indeed, if you learn (update on) the parity of this digit, and you let your future decisions depend on this information, then your two counterfactual selves (the one in the Even world and the one in the Odd world) might act differently (and maybe at odds), each only caring about their own world.
But you also have a lot of reasons to learn about the digit! Maybe doing so helps you understand math better, and you can use this to better navigate the world and achieve your goals in many different situations (some of which you cannot predict in advance). Indeed, the Value of Information theorems of academic decision theory basically state that updating on information is useful to forward your goals in many circumstances.[4]
So we seem to face a fundamental trade-off between the information benefits of learning (updating) and the strategic benefits of updatelessness. If I learn the digit, I will better navigate some situations which require this information, but I will lose the strategic power of coordinating with my counterfactual self, which is necessary in other situations.
Needless to say, this trade-off happens for each possible piece of information. Not only the parity of the trillionth digit of pi, but also that of the hundredth, the tenth, whether Fermat’s Last Theorem is true, etc. Of course, many humans have already updated on some of these pieces of information, although there is always an infinite amount of them we haven’t updated on yet.
Multi-agentic interactions
These worries might seem esoteric and far-fetched, since indeed Counterfactual Mugging seems like a very weird game that we’ll almost certainly never experience. But unfortunately, situations equivalent to this game are the norm in strategic multi-agentic interactions. And there as well we face this fundamental trade-off between learning and strategicness, giving rise to the commitment races problem [LW · GW]. Let me summarize that problem, using the game of Chicken:
Say two players have conflicting goals. Each of them can decide whether to be very aggressive, possibly threatening conflict and trying to scare the other player, or to instead not try so hard to achieve their goal, and ensure at least that conflict doesn’t happen (since conflict would be very bad for both).
A strategy one could follow is to first see whether the other player is playing aggressive, and be aggressive iff the other is not being aggressive.
The problem is, if the other learns you will be playing this strategy, then they will play aggressive (even if at first they were wary of doing so), knowing you will simply let them have the win. If instead you had committed to play aggressive no matter what the other does (instead of following your strategy), then maybe the other would have been scared off, and you would have won (also without conflict).
What’s really happening here is that, in making your strategy depend on the other’s move (by updating on the other’s move), you are giving them power over your action, that they can use to their advantage. So here again we face the same trade-off: by updating, you at least ensure conflict doesn’t happen (because your action will be a best-possible-response to the others’ move), but you also lose your strategicness (because your action will be manipulatable by the other).
The commitment races problem is very insidious, because empirically seeing what the other has played is not the only way of updating on their move or strategy: thinking about what they might play to improve your guess about it (which is a kind of super-coarse-grained simulation), or even thinking about some basic game-theoretic incentives, can already give you information about the other player’s strategy. Which you might regret to have learned, due to losing strategicness, and the other player possibly learning or predicting this and manipulating your decision.
So one of the players might reason: “Okay, I have some very vague opinions about what the other might play, hmm, should I be aggressive or not?... Oh wait, oh fuck, if I think more about this I might stumble upon information I didn’t want to learn, thus losing strategicness. I should better commit already now (early on) to always being aggressive, that way the other will probably notice this, and get scared and best-respond to avoid entering conflict. Nice. [presses commitment button]”
This amounts to the player maximizing expected value from the perspective of their prior (their current vague opinions about the game), as opposed to learning more, updating the prior, and deciding on an action then. That is, they are being updateless instead of updateful, so as not to lose strategicness.
The problem here is, if all agents are okay with such extreme and early gambits (and have a high enough prior that their opponents will be dovish)[5], then they will all commit to be aggressive, and end up in conflict, which is the worst outcome possible.
This indeed can happen when completely Updateless agents face each other. The Updateless agent is scared to learn anything more than their prior, because this might lead to them losing strategicness, and thus being exploited by other players who moved first, who committed first to the aggressive action (that is, who were more Updateless). As Demski [AF · GW] put it:
One way to look at what UDT (Updateless Decision Theory) is trying to do is to think of it as always trying to win a "most meta" competition. UDT doesn't want to look at any information until it has determined the best way to use that information. [...] It wants to move first in every game. [...] It wants to announce its binding commitments before anyone else has a chance to, so that everyone has to react to the rules it sets. It wants to set the equilibrium as it chooses. Yet, at the same time, it wants to understand how everyone else will react. It would like to understand all other agents in detail, their behavior a function of itself.
So, what happens if you put two such agents in a room together?
Both agents race to decide how to decide first. [...] Yet, such examination of the other needs to itself be done in an updateless way. It's a race to make the most uninformed decision.[6]
Is the trade-off avoidable?
There have been some attempts at surpassing this fundamental trade-off, somehow reconciling learning with strategicness, epistemics with instrumentality. Somehow negotiating with my other counterfactual selves, while at the same time not losing track of my own indexical position in the multi-verse.
In fact, it seems at first pretty intuitive that some solution along these lines should exist: just learn all the information, and then decide which one to use. After all, you are not forced to use the information, right?
Unfortunately, it’s not that easy, and the problem recurs at a higher level: your procedure to decide which information to use will depend on all the information, and so you will already lose strategicness. Or, if it doesn’t depend, then you are just being updateless, not using the information in any way.
In general, these attempts haven’t come to fruition.
FDT-like decision theories don’t even engage with the learning vs updatelessness question. You need to give them a prior over how certain computations affect others[7], that is, a single time slice, a prior to maximize. A non-omniscient FDT agent playing Chicken can fall into a commitment race as much as anyone, if the prior at that time recommends commitment without thinking further.
Demski and I over-stepped this by natively implementing dynamic logical learning in our framework (using Logical Inductors). And we had some ideas to reconcile learning with strategicness. But ultimately, the framework only solidified even further the fundamentality of this trade-off, and the existence of a “free parameter”: what exactly to update on.
Diffractor [LW · GW] is working on some promising (unpublished) algorithmic results which amount to “updateless policies not being that hard to compute, and asymptotically achieving good payoffs”... but they do assume a certain structure in the decision-theoretic environment, which basically amounts to “there’s not too much information that is counter-productive to learn”. That is, there are not that many “information traps”, analogous to the usual “exploration traps” in learning theory.
Daniel Herrmann advocates for dropping talk of counterfactuals entirely and being completely updateful.
From my perspective, Open-Minded Updatelessness [LW · GW] doesn’t push back on this fundamental trade-off. Instead, given the trade-off persists, it explores which kinds and shapes of partial commitments seem more robustly net-positive from the perspective of our current game-theoretic knowledge (that is, our current prior). But this is a point of contention, and there are on-going debates about whether OMU could get us something more.
To be clear, I’m not saying “I and others weren’t able to solve this problem, so this problem is unsolvable” (although that’s a small update). On the contrary, the important bit is that we seem to have elucidated important reasons why “the problem” is in fact a fundamental feature of mixing learning theory with game theory.
A more static (not dynamic, like Logical Inductors) and realist picture of computational counterfactuals (or, equivalently, subjunctive dependence) would help, but we have even more evidence that such a thing shouldn’t exist in principle, and there is a dependence on the observer’s ontology[8].
Superintelligences
In summary, a main worry with Updateless agents is that, although they might face some strategic advantages (in the situations they judged correctly from their prior), they might also act very silly due to having wrong beliefs at the time they froze their prior (stopped learning), especially when dealing with the future and complex situations.
And of course, it’s not like any agent arrives at a certain point where it knows enough, and can freeze their prior forever: there’s always an infinite amount of information to learn, and it’s hard to judge a priori which of it might be useful, and which of it might be counter-productive to learn. A scared agent who just thought for 3 seconds about commitment races doesn’t yet have a good picture of what important considerations it might miss out if it simply commits to being aggressive. We might think a current human is in a better position, indeed we know more things and apparently haven’t lost any important strategicness. But even then, our current information might be nothing compared to the complexities of interactions between superintelligences. So, were we to fix our prior and go updateless today, we wouldn’t really know what we might be missing on, and it might importantly backfire.
Still, there might be some ways in which we can be strategic and sensible about what information to update on. We might be able to notice patterns like “realizations in this part of concept-space are usually safe”. And it’s even conceivable that these proxies work very well, and superintelligences notice that (they don’t get stuck in commitment races before noticing it), and have no problem coordinating. But we are also importantly uncertain about whether that’s the case. And even more about how common are priors which think that’s the case.
It’s not looking like there will exist a simple, perfect delimitation, that determines whether we should update on any particular piece of information. Rather, a complex and dynamic mess of uncertain opinions about game theory and the behavior of other agents will determine whether committing not to update on X seems net-positive. In a sense, this happens because different agents might have different priors or path-dependent chains of thought.
A recently-booted AGI, still with only the same knowledge of game theory we have, would probably find itself in our same situation: a few of the possible commitments seem clearly net-postive, a few other net-negative… and for most of them, it’s very uncertain, and has to vaguely assess (without thinking too much!) whether it seems better to think more about them or to enact them already.
Even a fully-fledged superintelligence who knows a lot more than us (because it has chosen to update on much information) might find itself in an analogous situation: most of the value of the possible commitments depends on how other, similarly complex (and similarly advanced in game theory) superintelligences think and react. So to speak, as its knowledge of game theory increases, the base-line complexity of the interactions it has to worry about also increases.
This doesn’t prohibit that very promising interventions exist to help partially alleviate these problems. We humans don’t yet grasp the possible complexities of superintelligent bargaining. But if we saw, for example, a nascent AGI falling for a very naive commitment due to commitment races, we could ensure it instead learns some pieces of information that we are lucky enough to already be pretty sure are robustly safe. For example, Safe Pareto Improvements.
Other lenses
It might be these characterizations are importantly wrong because superintelligences think about decision theory (or their equivalent) in a fundamentally different way[9]. Then we’d be even more uncertain about whether something akin to “a very concrete kind of updatelessness being the norm” happens. But there are still a few different lenses that can be informative.
One such lens are selection pressures. Does AI training, or more generally physical reality and multi-agentic conflict, select for more updateless agents?
Here’s a reason why it might not: Updatelessness (that is, maximizing your current prior and leaving no or little room for future revision) can be seen as a “very risky expected value bet” (at least in the game-theoretic scenarios that seem most likely). As an example, an agent committing to always be aggressive (because she thinks it’s likely enough that others will be dovish) will receive an enormous payoff in a few worlds (those in which they are dovish), but also a big punishment in the rest (those in which they aren’t, and there’s conflict). Being updateful is closer to minimaxing against your opponent: you might lose some strategicness, but at least you ensure you can best-respond (thus always avoiding conflict).
But such naive and hawkish expected value maximization might not be too prevalent in reality, in the long run. Similarly to how Kelly Bettors [LW · GW] survive longer than Expected Wealth Maximizers in betting scenarios, updateful agents (who are not “betting everything on their prior being right”) might survive longer than updateless ones.
A contrary consideration, though, is that updateful agents, due to losing strategicness and getting exploited, might lose most of their resources. It’s unclear how this all plays out in any of the following scenarios: (Single) AI training, Multi-agentic interactions on Earth, and Inter-galactic interactions.
In fact, it’s even conceivable that a superintelligence’s decision theory be mostly “up for grabs”, in the sense that which decision theory ends up being used when interacting with other superintelligences (conditional on our superintelligence getting there) is pretty path dependent, and different trainings or histories could influence it.
Another lens is generalization (which is related to selection pressures in AI training). Maybe AI training incentivizes heuristics of a certain shape (similar or different from hours), and their natural generalizations lead to this or that decision theory. We are very uncertain about what happens in both of these steps. Possibly a conceptual study of “planning-heuristic systematization/evolution”, with a similar flavor to value systematization [AF · GW], would shed some light.
It’s also conceivable that, when we make implementation more realistic (and further reduce the unexplained parts of decision theory [LW · GW]), some different decision theories collapse to the same one (see here [LW · GW]). But it’s not looking like this should collapse the updateless-updateful spectrum.[10]
Conclusion
It’s certainly not looking very likely (> 80%) that most superintelligences converge on a same neatly specified “level of updatelessness”, nor that this level is high, nor that they are all able to step behind approximately the same veil of ignorance to do acausal trade (so that they can trade with all kinds of intelligences including humans), nor that in causal interactions they can easily and “fresh-out-of-the-box” coordinate on Pareto optimality (like performing logical or value handshakes) without falling into commitment races. And from my perspective, I would even say it’s unlikely (< 50%).
And in fact, if they did implement strong updateless commitments (the way we understand them today), that’s sounding rather like bad news, since it complicates game-theoretic interactions.
Acknowledgements
Thank you to Tristan Cook, Anthony DiGiovanni and James Faville for helpful comments on a draft, as well as to Abram Demski, Jesse Clifton, Nico Macé, Daniel Herrmann, Julian Stastny and Diffractor for related discussions.
- ^
Some worries arise about how I perform this check, but we could assume I have a copy of your algorithm and can run it with a different observation (Heads instead of Tails). More realistically, I will be an imperfect predictor. But any better-than-chance prediction is enough to elicit this phenomenon.
- ^
- ^
And I can in some way guarantee to you that I haven’t chosen the digit adversarially (knowing in advance it’s Even), for example by asking you for a random number before you know what we’re gonna play.
- ^
There is a further complication here. Imagine you could confidently predict in which exact ways the VOI from knowing the digit will come in handy. For example, you expect the only such way is if a TV contest host asks you “What is the parity of the trillionth digit of pi?”. If that were the case, you could simply commit to, in that situation, computing and using the digit of pi, and then immediately forget it (preserving your strategicness for all other situations). Similarly, if you knew in advance in which exact ways the strategicness would serve you (for example, only if someone offers you this exact Counterfactual Mugging), you could do the opposite: commit to accepting the bet in that case, and still learn the digit and exploit the VOI for all other situations. The problem, of course, is we are usually also very unaware of which exact situations we might face, how different pieces of information help in them, and even which piece of information we have the possibility of learning (and its ramifications for our conceptual awareness).
- ^
It’s unclear how common such priors are (and them being less common would ameliorate the problem). We do have some reasons [LW · GW] to expect most strategic deliberations to be safe, and probably other intelligences will also observe them (and so not feel the urge to commit without thinking). But the worry is also that an agent might notice they could be in a commitment race early on, when their non-updated prior still has arbitrarily wacky opinions on some important topics.
- ^
- ^
Which we don’t know how to do, and I even believe is problematically subjective.
- ^
- ^
This would seem slightly surprising from my perspective, because our hand has seemed “forced” in many places, meaning phenomena like this trade-off seem fundamental to reality (however we formally represent it), rather than a fabrication of our formalisms. But of course we might be missing some radically alien possibilities.
- ^
In more detail, while reducing updateless behavior to “EDT + anthropic uncertainty (simulations)” is useful (like here [LW · GW]), the same uncertainty about how we affect other computations remains (“if I take this action, how does this affect the coarse-grained version of me that the other player is simulating, and how does the other player respond to that?”), and the same strategic reasons not to learn more about them remain.
45 comments
Comments sorted by top scores.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2024-02-14T22:26:46.088Z · LW(p) · GW(p)
This deserves a longer answer than I have time to allocate it, but I quickly remark that I don't recognize the philosophy or paradigm of updatelessness as refusing to learn things or being terrified of information; a rational agent should never end up in that circumstance, unless some perverse other agent is specifically punishing them for having learned the information (and will lose of their own value thereby; it shouldn't be possible for them to gain value by behaving "perversely" in that way, for then of course it's not "perverse"). Updatelessness is, indeed, exactly that sort of thinking which prevents you from being harmed by information, because your updateless exposure to information doesn't cause you to lose coordination with your counterfactual other selves or exhibit dynamic inconsistency with your past self.
From an updateless standpoint, "learning" is just the process of reacting to new information the way your past self would want you to do in that branch of possibility-space; you should never need to remain ignorant of anything. Maybe that involves not doing the thing that would then be optimal when considering only the branch of reality you turned out to be inside, but the updateless mind denies that this was ever the principle of rational choice, and so feels no need to stay ignorant in order to maintain dynamic consistency.
Replies from: martinsq, None↑ comment by Martín Soto (martinsq) · 2024-02-15T05:37:26.541Z · LW(p) · GW(p)
Thank you for engaging, Eliezer.
I completely agree with your point: an agent being updateless doesn't mean it won't learn new information. In fact, it might perfectly decide to "make my future action A depend on future information X", if the updateless prior so finds it optimal. While in other situations, when the updateless prior deems it net-negative (maybe due to other agents exploiting this future dependence), it won't.
This point is already observed in the post (see e.g. footnote 4), although without going deep into it, due to the post being meant for the layman (it is more deeply addressed, for example, in section 4.4 of my report). Also for illustrative purposes, in two places I have (maybe unfairly) caricaturized an updateless agent as being "scared" of learning more information. While really, what this means (as hopefully clear from earlier parts of the post) is "the updateless prior assessed whether it seemed net-positive to let future actions depend on future information, and decided no (for almost all actions)".
The problem I present is not "being scared of information", but the trade-off between "letting your future action depend on future information X" vs "not doing so" (and, in more detail, how exactly it should depend on such information). More dependence allows you to correctly best-respond in some situations, but also could sometimes get you exploited. The problem is there's no universal (belief-independent) rule to assess when to allow for dependence: different updateless priors will decide differently. And need to do so in advance of letting their deliberation depend on their interactions (they still don't know if that's net-positive).
Due to this prior-dependence, if different updateless agents have different beliefs, they might play very different policies, and miscoordinate. This is also analogous to different agents demanding different notions of fairness (more here [LW(p) · GW(p)]). I have read no convincing arguments as to why most superintelligences will converge on beliefs (or notions of fairness) that successfully coordinate on Pareto optimality (especially in the face of the problem of trapped priors i.e. commitment races), and would be grateful if you could point me in their direction.
I interpret you as expressing a strong normative intuition in favor of ex ante optimization. I share this primitive intuition, and indeed it remains true that, if you have some prior and simply want to maximize its EV, updatelessness is exactly what you need. But I think we have discovered other pro tanto reasons against updatelessness, like updateless agents probably performing worse on average (in complex environments) due to trapped priors and increased miscoordination.
↑ comment by [deleted] · 2024-02-14T23:12:30.694Z · LW(p) · GW(p)
refusing to learn things or being terrified of information; a ratio
repeated Prisoners dilemma policy : "I will ALWAYS cooperate if I believe the other party is a copy of myself".
This policy cannot change if it observes the counterparty always defecting. It's "sibling" must need the resources. (If the agent can reason about why it's always being betrayed)
That's probably where this breaks, in implementation. A mutant agent that is a cracked version of the original one could exploit a network of updateless cooperators. Theoretically "in group" members could be unable to modify themselves without outside help though. (Their policy wouldn't contain a possible input case that permits any changes)
Real life example: mosquito gene drives.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2024-02-14T23:30:33.147Z · LW(p) · GW(p)
This policy cannot change if it observes the counterparty always defecting
If A observes the other party B defecting even once after verifying the other party B believed A to be a copy of B (assuming sufficient scanning tech to read each others' minds reliably, eg for simplicity this could be on the same computer in an open source game theory test environment), then A can reliably and therefore must always conclude B is not actually a copy, but a copy with some modification (such as random noise) that induces defection.
Replies from: None↑ comment by [deleted] · 2024-02-15T00:16:22.268Z · LW(p) · GW(p)
then A can reliably and therefore must always conclude B is not actually a copy, but a copy with some modification
What you describe can work, though now the policy is more complicated. It now has conditions where you renege when there is a certain level of confidence that the counterparty isn't a cloned peer.
Obviously "will ALWAYS cooperate" you know the other party isn't a peer the instant they defect. This policy collapses to grim trigger and actually you didn't need the peer detection.
In more complex and interesting environments there's now a "defection margin". Since you know the exact threshold the other parties will decide you aren't a peer at, you can exploit them so long as you don't provide sufficient evidence that you are an outlaw*. (In this case, outlaw means "not an identical clone")
A lot of these updateless cooperation scenarios are asynchronous, past/future, separated by distance and firewalls. Lots of opportunity to defect and not be punished.
- Real life example: shoplift $1 less than the felony threshold. Where a felony conviction is "grim trigger", society will always defect against you from then on.
comment by Martín Soto (martinsq) · 2024-02-08T19:41:14.596Z · LW(p) · GW(p)
Another coarse, on-priors consideration that I could have added to the "Other lenses" section:
Eliezer says something like "surely superintelligences will be intelligent enough to coordinate on Pareto-optimality (and not fall into something like commitment races), and easily enact logical or value handshakes". But here's why I think this outside-view consideration need not hold. It is a generally good heuristic to think superintelligences will be able to solve tasks that seem impossible to us. But I think this stops being the case for tasks whose difficulty / complexity grows with the size / computational power / intelligence level of the superintelligence. For a task like "beating a human at Go" or "turning the solar system into computronium", the difficulty of the task is constant (relative to the size of the superintelligence you're using to solve it). For a task like "beat a copy of yourself in Go", that's clearly not the case (well, unless Go has a winning strategy that a program within our universe can enact, which would be a ceiling on difficulty). I claim "ensuring Pareto-optimality" is more like the latter. When the intelligence or compute of all players grows, it is true they can find more clever and sure-fire ways to coordinate robustly, but it's also true that they can individually find more clever ways of tricking the system and getting a bit more of the pie (and in some situations, they are individually incentivized to do this). Of course, one might still hold that the first will grow much more than the latter, and so after a certain level of intelligence, agents of a similar intelligence level will easily coordinate. But that's an additional assumption, relative to the "constant-difficulty" cases.
Of course, if Eliezer believes this it is not really because of outside-view considerations like the above, but because of inside-views about decision theory. But I generally disagree with his takes there (for example here [LW(p) · GW(p)]), and have never found convincing arguments (from him or anyone) for the easy coordination of superintelligences.
comment by habryka (habryka4) · 2024-02-20T06:57:09.805Z · LW(p) · GW(p)
Promoted to curated: I think it's pretty likely a huge fraction of the value of the future will be determined by the question this post is trying to answer, which is how much game theory produces natural solutions to coordination problems, or more generally how much better we should expect systems to get at coordination as they get smarter.
I don't think I agree with everything in the post, and a few of the characterizations of updatelessness seem a bit off to me (which Eliezer points to a bit in his comment), but I still overall found reading this post quite interesting and valuable for helping me think about for which of the problems of coordination we have a more mechanistic understanding of how being smarter and better at game theory might help, and which ones we don't have good mechanisms for, which IMO is a quite important question.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-20T20:39:23.519Z · LW(p) · GW(p)
Thank you, habryka!
As mentioned in my answer to Eliezer, my arguments were made with that correct version of updatelessness in mind (not "being scared to learn information", but "ex ante deciding whether to let this action depend on this information"), so they hold, according to me.
But it might be true I should have stressed this point more in the main text.
comment by CronoDAS · 2024-02-21T03:27:18.114Z · LW(p) · GW(p)
The Chicken, aka Hawk/Dove game, is a pain in the neck to analyze from a "naive decision theory" perspective.
Level Zero analysis:
The best response to Dove is Hawk. If my opponent is going to play Dove, I want to play Hawk.
The least bad response to Hawk is Dove. If my opponent is going to play Hawk, I want to play Dove.
Going meta:
If I can predict that my opponent plays Dove in response to HawkBot, I want to self-modify into HawkBot and trap them in the Nash equilibrium that's good for me.
If my opponent is HawkBot, I want to yield and play Dove.
Going more meta:
If my opponents predict that I'll play Dove in response to HawkBot, then they'll self-modify into HawkBot and trap me in the Nash equilibrium that's bad for me. So I don't want to play Dove in response to HawkBot. But if I play Hawk in response to HawkBot, I'm basically HawkBot myself, and the HawkBot vs HawkBot matchup leads to the worst outcome possible. So it can't be right to play Dove, and it can't be right to play Hawk either.
Which leaves me with only one possible conclusion:

comment by SMK (Sylvester Kollin) · 2024-03-06T15:00:25.172Z · LW(p) · GW(p)
This is indeed what happens to the best-known decision theories (CDT and EDT): they want to commit to paying, but if they don’t, by the time they get to the Heads world they don’t pay. We call this dynamic instability, because different (temporal) versions of the agent seem to be working against each other.
Unless you are using "dynamic stability" to mean something other than "dynamic consistency", I don't think this is quite right. The standard philosophical theory of dynamic choice, sophisticated choice (see e.g. the SEP entry on decision theory), would not pay but is still dynamically consistent.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2024-03-06T18:05:57.934Z · LW(p) · GW(p)
Let me check if I understand what you're saying (what these standard academic terms mean). "Dynamic inconsistency" is when you make a plan, initially acts according to that plan, but then later fail to follow the plan. (You failed to take into account what you'd later decide to do when making the plan. This is what the "naive" approach does, according to SEP.) "Dynamic consistency" is when you never do this. (The "sophisticated" approach is to take into account what you'd decide to do later when making the initial plan, so dynamic inconsistency never happens. Also called "backwards reasoning" which I think is the same as "backwards induction" which is a term I'm familiar with.[1]) Rest of this comment assumes this is all correct.
I think this is different from what the OP means by "dynamic stability" but perhaps their definition is too vague. (What does "want to commit" mean exactly? Arguably sophisticated choice wants to commit to paying, but also arguably it doesn't because it knows such commitment is futile.) Here's a related idea that is maybe clearer: Suppose an agent has the ability to self-modify to use any decision theory, would they decide to stick with their current decision theory? (I'm actually not sure what term has been explicitly defined to mean this, so I'll just call it "self-endorsement" for now.)
(Partly this is about AI, trying to figure out what decision theory future AIs will or should have, but humans also have some ability to choose what decision theory to use, so it seems interesting from that perspective as well.)
Sophisticated choice seemingly lacks "self-endorsement" because before it's told how the counterfactual mugger's coin landed, it would self-modify (if it could) into an agent that would pay the counterfactual mugger in the Heads world. (Lots more can be said about this, but I'll stop here and give you a chance to clarify, respond, or ask questions.)
- ^
I still remember the first moment that I started to question backwards induction [LW(p) · GW(p)]. Things were so much simpler before that!
↑ comment by SMK (Sylvester Kollin) · 2024-03-08T12:47:02.385Z · LW(p) · GW(p)
Here's a related idea that is maybe clearer: Suppose an agent has the ability to self-modify to use any decision theory, would they decide to stick with their current decision theory? (I'm actually not sure what term has been explicitly defined to mean this, so I'll just call it "self-endorsement" for now.)
This sounds similar to what's called "self-recommendation"—see e.g. Skyrms (1982, pp. 707-709), Meacham (2010, §3.3) and Pettigrew (2023). In the abstract Pettigrew writes: "A decision theory is self-recommending if, when you ask it which decision theory you should use, it considers itself to be among the permissible options.".
I have actually been thinking about ways of extending Pettigrew's work to theories of dynamic choice. That is: is sophistication/resoluteness self-recommending? I don't think it is immediately clear what the answers are, and it might depend on the interpretations of sophistication and resoluteness one adopts, but yeah, I do agree that it seems like sophistication might be self-undermining.
↑ comment by Martín Soto (martinsq) · 2024-03-06T19:43:29.024Z · LW(p) · GW(p)
Thank you Sylvester for the academic reference, and Wei for your thoughts!
I do understand from the SEP, like Wei, that sophisticated means "backwards planning", and resolute means "being able to commit to a policy" (correct me if I'm wrong).
My usage of "dynamic instability" (which might be contrary to academic usage) was indeed what Wei mentions: "not needing commitments". Or equivalently, I say a decision theory is dynamically stable if itself and its resolute version always act the same.
There are some ways to formalize exactly what I mean by "not needing commitments", for example see here, page 3, Desiderata 2 (Tiling result), although that definition is pretty in the weeds.
Replies from: Sylvester Kollin↑ comment by SMK (Sylvester Kollin) · 2024-03-08T12:18:29.114Z · LW(p) · GW(p)
Thanks for the clarification!
I do understand from the SEP, like Wei, that sophisticated means "backwards planning", and resolute means "being able to commit to a policy" (correct me if I'm wrong).
That seems roughly correct, but note that there are different interpretations of resolute choice floating around[1], and I think McClennen's (1990) presentation is somewhat unclear at times. Sometimes resoluteness seems to be about the ability to make internal commitments, and other times it seems to be about being sensitive to the dynamic context in a particular way, and I think these can come apart. You might be interested in these notes I took while reading McClennen's book.
My usage of "dynamic instability" (which might be contrary to academic usage) was indeed what Wei mentions: "not needing commitments". Or equivalently, I say a decision theory is dynamically stable if itself and its resolute version always act the same.
Then that sounds a bit question-begging. Do you think dynamic instability is a problem (normatively speaking)?
- ^
See e.g. Gauthier (1997) and Buchak (2013, §6).
comment by Jeremy Gillen (jeremy-gillen) · 2024-02-11T03:00:48.908Z · LW(p) · GW(p)
To me it feels like the natural place to draw the line is update-on-computations but updateless-on-observations. Because 1) It never disincentivizes thinking clearly, so commitment races bottom out in a reasonable way, and 2) it allows cooperation on common-in-the-real-world newcomblike problems.
It doesn't do well in worlds with a lot of logical counterfactual mugging, but I think I'm okay with this? I can't see why this situation would be very common, and if it comes up it seems that an agent that updates on computations can use some precommitment mechanism to take advantage of it (e.g. making another agent).
Am I missing something about why logical counterfactual muggings are likely to be common?
Looking through your PIBBS report (which is amazing, very helpful), I intuitively feel the pull of Desiderata 4 (No existential regret), and also the intuition of wanting to treat logical uncertainty and empirical uncertainty in a similar way. But ultimately I'm so horrified by the mess that comes from being updateless-on-logic that being completely updateful on logic is looking pretty good to me.
(Great post, thanks)
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-11T04:25:57.226Z · LW(p) · GW(p)
To me it feels like the natural place to draw the line is update-on-computations but updateless-on-observations.
A first problem with this is that there is no sharp distinction between purely computational (analytic) information/observations and purely empirical (synthetic) information/observations. This is a deep philosophical point, well-known in the analytic philosophy literature, and best represented by Quine's Two dogmas of empiricism, and his idea of the "Web of Belief". (This is also related to Radical Probabilisim [LW · GW].)
But it's unclear if this philosophical problem translates to a pragmatic one. So let's just assume that the laws of physics are such that all superintelligences we care about converge on the same classification of computational vs empirical information.
A second and more worrying problem is that, even given such convergence, it's not clear all other agents will decide to forego the possible apparent benefits of logical exploitation. It's a kind of Nash equilibrium selection problem: If I was very sure all other agents forego them (and have robust cooperation mechanisms that deter exploitation), then I would just do like them. And indeed, it's conceivable that our laws of physics (and algorithmics) are such that this is the case, and all superintelligences converge on the Schelling point of "never exploiting the learning of logical information". But my probability of that is not very high, especially due to worries that different superintelligences might start with pretty different priors, and make commitments early on (before all posteriors have had time to converge). (That said, my probability is high that almost all deliberation is mostly safe, by more contingent reasons related to the heuristics they use and values they have.)
You might also want to say something like "they should just use the correct decision theory to converge on the nicest Nash equilibrium!". But that's question-begging, because the worry is exactly that others might have different notions of this normative "nice" (indeed, no objective criterion for decision theory). The problem recurs: we can't just invoke a decision theory to decide on the correct decision theory.
Am I missing something about why logical counterfactual muggings are likely to be common?
As mentioned in the post, Counterfactual Mugging as presented won't be common, but equivalent situations in multi-agentic bargaining might, due to (the naive application of) some priors leading to commitment races. (And here "naive" doesn't mean "shooting yourself in the foot", but rather "doing what looks best from the prior", even if unbeknownst to you it has dangerous consequences.)
if it comes up it seems that an agent that updates on computations can use some precommitment mechanism to take advantage of it
It's not looking like something as simple as that will solve, because of reasoning as in this paragraph:
Unfortunately, it’s not that easy, and the problem recurs at a higher level: your procedure to decide which information to use will depend on all the information, and so you will already lose strategicness. Or, if it doesn’t depend, then you are just being updateless, not using the information in any way.
Or in other words, you need to decide on the precommitment ex ante, when you still haven't thought much about anything, so your precommitment might be bad.
(Although to be fair there are ongoing discussions about this.)
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-02-11T06:39:31.365Z · LW(p) · GW(p)
A first problem with this is that there is no sharp distinction between purely computational (analytic) information/observations and purely empirical (synthetic) information/observations.
I don't see the fuzziness here, even after reading the two dogmas wikipedia page (but not really understanding it, it's hidden behind a wall of jargon). If we have some prior over universes, and some observation channel, we can define an agent that is updateless with respect to that prior, and updateful with respect to any calculations it performs internally. Is there a section of Radical Probablism that is particularly relevant? It's been a while.
It's not clear to me why all superintelligences having the same classification matters. They can communicate about edge cases and differences in their reasoning. Do you have an example here?
A second and more worrying problem is that, even given such convergence, it's not clear all other agents will decide to forego the possible apparent benefits of logical exploitation. It's a kind of Nash equilibrium selection problem: If I was very sure all other agents forego them (and have robust cooperation mechanisms that deter exploitation), then I would just do like them.
I think I don't understand why this is a problem. So what if there are some agents running around being updateless about logic? What's the situation that we are talking about a Nash equilibrium for?
As mentioned in the post, Counterfactual Mugging as presented won't be common, but equivalent situations in multi-agentic bargaining might, due to (the naive application of) some priors leading to commitment races.
Can you point me to an example in bargaining that motivates the usefulness of logical updatelessness? My impression of that section wasn't "here is a realistic scenario that motivates the need for some amount of logical updatelessness", it felt more like "logical bargaining is a situation where logical updatelessness plausibly leads to terrible and unwanted decisions".
It's not looking like something as simple as that will solve, because of reasoning as in this paragraph:
Unfortunately, it’s not that easy, and the problem recurs at a higher level: your procedure to decide which information to use will depend on all the information, and so you will already lose strategicness. Or, if it doesn’t depend, then you are just being updateless, not using the information in any way.
Or in other words, you need to decide on the precommitment ex ante, when you still haven't thought much about anything, so your precommitment might be bad.
Yeah I wasn't thinking that was a "solution", I'm biting the bullet of losing some potential value and having a decision theory that doesn't satisfy all the desiderata. I was just saying that in some situations, such an agent can patch the problem using other mechanisms, just as an EDT agent can try to implement some external commitment mechanism if it lives in a world full of transparent newcomb problems.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-13T03:18:02.406Z · LW(p) · GW(p)
(Sorry, short on time now, but we can discuss in-person and maybe I'll come back here to write the take-away)
↑ comment by Noosphere89 (sharmake-farah) · 2024-12-18T03:17:18.439Z · LW(p) · GW(p)
To make a bit of a point here, which might clarify the discussion:
A first problem with this is that there is no sharp distinction between purely computational (analytic) information/observations and purely empirical (synthetic) information/observations. This is a deep philosophical point, well-known in the analytic philosophy literature, and best represented by Quine's Two dogmas of empiricism, and his idea of the "Web of Belief". (This is also related to Radical Probabilisim [LW · GW].)
But it's unclear if this philosophical problem translates to a pragmatic one. So let's just assume that the laws of physics are such that all superintelligences we care about converge on the same classification of computational vs empirical information.
I'd say the major distinction between logical/mathematical/computational uncertainty and empirical uncertainty which Quine ignored is that empirical uncertainty consists of the problem of starting from a prior and updating, where the worlds/hypotheses being updated upon are all as self-consistent/real as each other, and thus even with infinite compute, observing empirical evidence actually means we can get new information, since it reduces the number of possible states we can be in.
Meanwhile, logical/mathematical/computational uncertainty is a case where you know a-priori that there is only 1 correct answer, and the reason why you are uncertain is solely due to the boundedness of yourself. If you had infinite compute like a model of computation below, you could in principle compute the correct answer, which applies everywhere. This is why logical uncertainty was so hard, in that since there was only 1 possible answer, it just required computation, it meant that logical uncertainty screwed with update procedures, and the theoretical solution is logical induction.
Model of computation:
https://arxiv.org/abs/1806.08747
Logical induction:
https://arxiv.org/abs/1609.03543
Note I haven't solved the other problems of updating on computations/stuff where there is only 1 correct answer vs being updateless on empirical uncertainty when multiple correct answers are allowed.
comment by Thomas Kwa (thomas-kwa) · 2024-02-09T09:01:25.305Z · LW(p) · GW(p)
Upvoted just for being an explanation of what updatelessness is and why it is sometimes good.
comment by cousin_it · 2024-02-09T01:22:00.347Z · LW(p) · GW(p)
I think the problem is not about updatelessness. It's more like, what people want from decision theory is fundamentally unachievable, except in very simple situations ("single player extensive-form games" [LW · GW] was my take). In more complex situations, game theory becomes such a fundamental roadblock that we're better off accepting it; accepting that multiplayer won't reduce to single player no matter how much we try.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-09T02:05:25.477Z · LW(p) · GW(p)
I agree that the situation is less
"there is a theoretical problem which is solvable but our specification of Updatelessness is not solving"
and more
"there is a fundamental obstacle in game-theoretic interactions (at least the way we model them)".
Of course, even if this obstacle is "unavoidable in principle" (and no theoretical solution will get rid of it completely and for all situations), there are many pragmatic and realistic solutions (partly overfit to the situation we already know we are actually in) that can improve interactions. So much so as to conceivably even dissolve the problem into near-nothingness (although I'm not sure I'm that optimistic).
comment by StrivingForLegibility · 2024-02-09T07:42:26.214Z · LW(p) · GW(p)
So we seem to face a fundamental trade-off between the information benefits of learning (updating) and the strategic benefits of updatelessness. If I learn the digit, I will better navigate some situations which require this information, but I will lose the strategic power of coordinating with my counterfactual self, which is necessary in other situations.
It seems like we should be able to design software systems that are immune to any infohazard [? · GW], including logical infohazards.
- If it's helpful to act on a piece of information you know, act on it.
- If it's not helpful to act on a piece of information you know, act as if you didn't know it.
Ideally, we could just prove that "Decision Theory X never calculates a negative value of information". But if needed, we could explicitly design a cognitive architecture with infohazard mitigation in mind. Some options include:
- An "ignore this information in this situation" flag
- Upon noticing "this information would be detrimental to act on in this situation", we could decide to act as if we didn't know it, in that situation.
- (I think this is one of the designs you mentioned in footnote 4 [LW(p) · GW(p)].)
- Cognitive sandboxes
- Spin up some software in a sandbox to do your thinking for you.
- The software should only return logical information that is true, and useful in your current situation
- If it notices any hazardous information, it simply doesn't return it to you.
- Upon noticing that a train of thought doesn't lead to any true and useful information, don't think about why that is and move on.
I agree with your point in footnote 4 [LW(p) · GW(p)], that the hard part is knowing when to ignore information. Upon noticing that it would be helpful to ignore something, the actual ignoring seems easy.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-09T22:24:52.538Z · LW(p) · GW(p)
It seems like we should be able to design software systems that are immune to any infohazard [? · GW]
As mentioned in another comment, I think this is not possible to solve in full generality (meaning, for all priors), because that requires complete updatelessness and we don't want to do that.
I think all your proposed approaches are equivalent (and I think the most intuitive framing is "cognitive sandboxes"). And I think they don't work, because of reasoning close to this paragraph:
Unfortunately, it’s not that easy, and the problem recurs at a higher level: your procedure to decide which information to use will depend on all the information, and so you will already lose strategicness. Or, if it doesn’t depend, then you are just being updateless, not using the information in any way.
But again, the problem might be solvable in particular cases (like, our prior).
Replies from: StrivingForLegibility↑ comment by StrivingForLegibility · 2024-02-12T19:28:34.875Z · LW(p) · GW(p)
The distinction between "solving the problem for our prior" and "solving the problem for all priors" definitely helps! Thank you!
I want to make sure I understand the way you're using the term updateless, in cases where the optimal policy involves correlating actions with observations. Like pushing a red button upon seeing a red light, but pushing a blue button upon seeing a blue light. It seems like (See Red -> Push Red, See Blue -> Push Blue) is the policy that CDT [? · GW], EDT [? · GW], and UDT [? · GW] would all implement.
In the way that I understand the terms, CDT and EDT are updateful procedures, and UDT is updateless. And all three are able to use information available to them. It's just that an updateless decision procedure always handles information in ways that are endorsed a priori. (True information can degrade the performance of updateful decision theories, but updatelessness implies infohazard immunity.)
Is this consistent with the way you're describing decision-making procedures as updateful and updateless?
It also seems like if an agent is regarding some information as hazardous, that agent isn't being properly updateless with respect to that information. In particular, if it finds that it's afraid to learn true information about other agents (such as their inclinations and pre-commitments), it already knows that it will mishandle that information upon learning it. And if it were properly updateless, it would handle that information properly.
It seems like we can use that "flinching away from true information" as a signal that we'd like to change the way our future self will handle learning that information. If our software systems ever notice themselves calculating a negative value of information for an observation (empirical or logical), the details of that calculation will reveal at least one counterfactual branch where they're mishandling that information. It seems like we should always be able to automatically patch that part of our policy, possibly using a commitment that binds our future self.
In the worst case, we should always be able to do what our ignorant self would have done, so information should never hurt us.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-20T20:23:09.050Z · LW(p) · GW(p)
Is this consistent with the way you're describing decision-making procedures as updateful and updateless?
Absolutely. A good implementation of UDT can, from its prior, decide on an updateful strategy. It's just it won't be able to change its mind about which updateful strategy seems best. See this comment [LW(p) · GW(p)] for more.
"flinching away from true information"
As mentioned also in that comment, correct implementations of UDT don't actually flinch away from information: they just decide ex ante (when still not having access to that information) whether or not they will let their future actions depend on it.
The problem remains though: you make the ex ante call about which information to "decision-relevantly update on", and this can be a wrong call, and this creates commitment races, etc.
Replies from: StrivingForLegibility↑ comment by StrivingForLegibility · 2024-03-05T22:46:03.342Z · LW(p) · GW(p)
The problem remains though: you make the ex ante call about which information to "decision-relevantly update on", and this can be a wrong call, and this creates commitment races, etc.
My understanding is that commitment races only occur in cases where "information about the commitments made by other agents" has negative value for all relevant agents. (All agents are racing to commit before learning more, which might scare them away from making such a commitment.)
It seems like updateless agents should not find themselves in commitment races.
My impression is that we don't have a satisfactory extension of UDT to multi-agent interactions. But I suspect that the updateless response to observing "your counterpart has committed to going Straight" will look less like "Swerve, since that's the best response" and more like "go Straight with enough probability that your counterpart wishes they'd coordinated with you rather than trying to bully you."
Offering to coordinate on socially optimal outcomes, and being willing to pay costs to discourage bullying, seems like a generalizable way for smart agents to achieve good outcomes.
comment by Richard_Kennaway · 2024-02-08T19:04:12.003Z · LW(p) · GW(p)
It's not clear to me how updateless agents can have a commitment race. Of course it takes time for them to calculate their decision, but in so doing, they are not making that decision, but discovering what it was always going to be. Neither is making their decision "first", regardless of how long it takes either of them to discover it.
There is also the logical problem of how two agents can each be modelling the other without this resulting in a non-terminating computation. I believe people have thought about this, but I don't know if there is a solution.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-08T19:24:48.929Z · LW(p) · GW(p)
You're right there's something weird going on with fix-points and determinism: both agents are just an algorithm, and in some sense there is already a mathematical fact of the matter about what each outputs. The problem is none of them know this in advance (exactly because of the non-terminating computation problem), and so (while still reasoning about which action to output) they are logically uncertain about what they and the other outputs.
If an agent believes that the others' action is completely independent of their own, then surely, no commitment race will ensue. But say, for example, they believe their taking action A makes it more likely the other takes action B. This belief could be justified in a number of different ways: because they believe the other to be perfectly simulating them, because they believe the other to be imperfectly simulating them (and notice, both agents can imperfectly simulate each other, and consider this to give them better-than-chance knowledge about the other), because they believe they can influence the truth of some mathematical statements (EDT-like) that the other will think about, etc.
And furthermore, this doesn't solely apply to the end actions they choose: it can also apply to the mental moves they perform before coming to those actions. For example, maybe an agent has a high enough probability on "the other will just simulate me, and best-respond" (and thus, I should just be aggressive). But also, an agent could go one level higher, and think "if I simulate the other, they will probably notice (for example, by coarsely simulating me, or noticing some properties of my code), and be aggressive. So I won't do that (and then it's less likely they're aggressive)".
Another way to put all this is that one of them can go "first" in logical time [LW · GW] (at the cost of having thought less about the details of their strategy).
Of course, we have some reasons to think the priors needed for the above to happen are especially wacky, and so unlikely. But again, one worry is that this could happen pretty early on, when the AGI still has such wacky and unjustified beliefs.
comment by JesseClifton · 2025-02-08T19:50:12.813Z · LW(p) · GW(p)
Open-Minded Updatelessness doesn’t push back on this fundamental trade-off. Instead, given the trade-off persists, it explores which kinds and shapes of partial commitments seem more robustly net-positive from the perspective of our current game-theoretic knowledge (that is, our current prior)
I would distinguish between two cases:
-
We’re aware of specific reasons why continuing to follow an OMU policy could be harmful (e.g., specific reasons other agents might punish us for doing so). In such cases, if those hypotheses have high-enough weight, OMU as a normative criterion can itself recommend not continuing to follow the OMU policy. So, in this sense I agree with the quote, but this doesn’t undermine OMU as a normative criterion.
-
We’re not aware of any specific reasons why continuing to follow the OMU policy could be harmful. In that case, it seems arbitrary to form beliefs according to which it’s net-negative to continue following OMU, and so it seems reasonable to continue following OMU (I’m not sure what else to do).
Sorry for only now commenting...
comment by lemonhope (lcmgcd) · 2024-02-23T07:02:11.648Z · LW(p) · GW(p)
(Excuse my ignorance. These are real questions, not just gotchas. I did see that you linked to the magic parts post.)
Will "commitment" and "agent" have to be thrown out and remade from sensible blocks? Perhaps cellular automata? ie did you create a dilemma out of nothing when you chose your terms?
Like we said a "toaster" is "literally anything that somehow produces toast" then our analysis of breakfast quickly broke down.
From my distant position it seems the real work to be done is at that lower level. We have not even solved 3x+1!!! How will we possibly draw up a sound notion of agents and commitments without some practical knowhow about slicing up the environment?
comment by M Ls (m-ls) · 2024-02-20T21:11:08.413Z · LW(p) · GW(p)
All logic is a prior.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-20T21:33:03.480Z · LW(p) · GW(p)
- Chan master Yunmon
Replies from: m-ls↑ comment by M Ls (m-ls) · 2024-03-13T11:17:33.669Z · LW(p) · GW(p)
back link https://whyweshould.substack.com/p/all-logic-is-a-prior
comment by Review Bot · 2024-02-20T10:08:06.291Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by RogerDearnaley (roger-d-1) · 2024-02-18T06:43:06.964Z · LW(p) · GW(p)
For updatelessness commitments to be advantageous, you need to be interacting with other agents that have a better-than-random chance of predicting your behavior under counterfactual circumstances. Agents have finite computational resources, and running a completely accurate simulation of another agent requires not only knowing their starting state but also being able to run a simulation of them at comparable speed and cost. Their strategic calculation might, of course, be simple, thus easy to simulate, but in a competitive situation if they have a motivation to be hard to simulate, then it is to their advantage to be as hard as possible to simulate and to run a decision process that is as complex as possible. (For example "shortly before the upcoming impact in our game of chicken, leading up to the last possible moment I could swerve aside, I will have my entire life up to this point flash before by eyes, hash certain inobvious features of this, and, depending on the twelfth bit of the hash, I will either update my decision, or not, in a way that it is unlikely my opponent can accurately anticipate or calculate as fast as I can".)
In general, it's always possible for an agent to generate a random number that even a vastly-computationally-superior opponent cannot predict (using quantum sources of randomness, for example).
It's also possible to devise a stochastic non-linear procedure where it is computationally vastly cheaper for me to follow one randomly-selected branch of it than it is for someone trying to model me to run all branches, or even Monte-Carlo simulate a representative sample of them, and where one can't just look at the algorithm and reason about what the net overall probability of various outcomes is, because it's doing irreducibly complex things like loading random numbers into Turing machines or cellular automata and running the resulting program for some number of steps to see what output, if any, it gets. (Of course, I may also not know what the overall probability distribution from running such a procedure is, if determining that is very expensive, but then, I'm trying to be unpredictable.) So it's also possible to generate random output that even a vastly-computationally-superior opponent cannot even predict the probability distribution of.
In the counterfactual mugging case, call the party proposing the bet (the one offering $1000 and asking for $100) A, and the other party B. If B simply publicly and irrevocably precommits to paying the $100 (say by posting a bond), their expected gain is $450. If they can find a way to cheat, their maximum potential gain from the gamble is $500. So their optimal strategy is to initially do a (soft) commit to paying the $100, and then, either before the coin is tossed, and/or after that on the heads branch:
- Select a means of deciding on a probability that I will update/renege after the coin lands if it's a heads, and (if the coin has not yet been tossed) optionally a way I could signal that. This means can include using access to true (quantum) randomness, hashing parts of my history selected somehow (including randomly), hashing new observations of the world I made after the coin landed, or anything else I want.
- Using << $50 worth of computational resources, run a simulation of party A in the tails branch running a simulation of me, and predict the probability distribution for their estimate of . If the mean of that is lower than then go ahead and run the means for choosing. Otherwise, try again (return to step 1), or, if the computational resources I've spent are approaching $50 in net value, give up and pay A the $100 if the coin lands (or has already landed) heads.
Meanwhile, on the heads branch, party A is trying to simulate party B running this process, and presumably is unwilling to spend more than some fraction of $1000 in computational resources to doing this. If party B did their calculation before the coin toss and chose to emit a signal(or leaked one), then party A has access to that, but obviously not to anything that only happened on the heads branch after the outcome of the coin toss was visible.
So this turns into a contest of who can more accurately and cost effectively simulate the other simulating them, recursively. Since B can choose a strategy, including choosing to randomly select obscure features of their past history and make these relevant to the calculation, while A cannot, B would seem to be at a distinct strategic advantage in this contest unless A has access to their entire history.
comment by StrivingForLegibility · 2024-02-08T23:29:16.113Z · LW(p) · GW(p)
It’s certainly not looking very likely (> 80%) that ... in causal interactions [most superintelligences] can easily and “fresh-out-of-the-box” coordinate on Pareto optimality (like performing logical or value handshakes) without falling into commitment races.
What are some obstacles to superintelligences performing effective logical handshakes? Or equivalently, what are some necessary conditions that seem difficult to bring about, even for very smart software systems?
(My understanding of the term "logical handshake" is as a generalization of the technique from the Robust Cooperation [LW · GW] paper. Something like "I have a model of the other relevant decision-makers, and I will enact my part of the joint policy if I'm sufficiently confident that they'll all enact their part of ." Is that the sort of decision-procedure that seems likely to fall into commitment races?)
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-09T00:36:49.817Z · LW(p) · GW(p)
This is exactly the kind of procedure which might get hindered by commitment races, because it involves "thinking more about what the other agents will do", and the point of commitment races is that sometimes (and depending on your beliefs) this can seem net-negative ex ante (that is, before actually doing the thinking).
Of course, this doesn't prohibit logical handshakes from being enacted sometimes. For example, if all agents start with a high enough prior on others enacting their part of , then they will do it. More realistically, it probably won't be as easy as this, but if it is the case that all agents feel safe enough thinking about (they deem it unlikely this backfires into losing bargaining power), and/or the upshot is sufficiently high (when multiplied by the probability and so on), then all agents will deem it net-positive to think more about and the others, and eventually they'll implement it.
So it comes down to how likely we think are priors (or the equivalent thing for AIs) which successfully fall into this coordination basin, opposed to priors which get stuck in some earlier prior without wanting to think more. And again, we have a few pro tanto reasons to expect coordination to be viable (and a few in the other direction). I do think out of my list of statements, logical handshakes in causal interactions might be one of the most likely ones.
Replies from: StrivingForLegibility↑ comment by StrivingForLegibility · 2024-02-09T01:26:38.681Z · LW(p) · GW(p)
To feed back, it sounds like "thinking more about what other agents will do" can be infohazardous [? · GW] to some decision theories. In the sense that they sometimes handle that sort of logical information in a way that produces worse results than if they didn't have that logical information in the first place. They can sometimes regret thinking more.
It seems like it should always be possible to structure our software systems so that this doesn't happen. I think this comes at the cost of not always best-responding [LW · GW] to other agents' policies.
In the example of Chicken, I think that looks like first trying to coordinate on a correlated strategy, like a 50/50 mix of (Straight, Swerve) and (Swerve, Straight). (First try to coordinate on a socially optimal joint policy.)
Supposing that failed, our software system could attempt to troubleshoot why, and discover that their counterpart has simply pre-committed to always going Straight. Upon learning that logical fact, I don't think the best response is to best-respond, i.e. Swerve. If we're playing True Chicken [LW · GW], it seems like in this case we should go Straight with enough probability that our counterpart regrets not thinking more and coordinating with us.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-09T02:01:28.314Z · LW(p) · GW(p)
You're right that (a priori and on the abstract) "bargaining power" fundamentally trades off against "best-responding". That's exactly the point of my post. This doesn't prohibit, though, that a lot of pragmatic and realistic improvements are possible (because we know agents in our reality tend to think like this or like that), even if the theoretical trade-off can never be erased completely or in all situations and for all priors.
Your latter discussion is a normative one. And while I share your normative intuitions that best-responding completely (being completely updateful) is not always the best to do in realistic situations, I do have quibbles with this kind of discourse (similar to this [LW(p) · GW(p)]). For example, why would I want to go Straight even after I have learned the other does? Out of some terminal valuation of fairness, or counterfactuals, more than anything, I think (more here [LW · GW]). Or similarly, why should I think sticking to my notion of fairness shall ex ante convince the other player to coordinate on it, as opposed to the other player trying to pull out some "even more meta" move, like punishing notions of fairness that are not close enough to theirs? Again, all of this will depend on our priors.
Replies from: StrivingForLegibility↑ comment by StrivingForLegibility · 2024-02-09T08:07:51.264Z · LW(p) · GW(p)
It sounds like we already mostly agree!
I agree with Caspar's point in the article you linked: the choice of metric determines which decision theories score highly on it. The metric that I think points towards "going Straight sometimes, even after observing that your counterpart has pre-committed to always going Straight" is a strategic one [LW · GW]. If Alice and Bob are writing programs to play open-source [? · GW] Chicken on their behalf, then there's a program equilibrium where:
- Both programs first try to perform a logical handshake, coordinating on a socially optimal joint policy.
- This only succeeds if they have compatible notions of social optimality.
- As a fallback, Alice's program adopts a policy which
- Caps Bob's expected payoff [LW · GW] at what Bob would have received under Alice's notion of social optimality
- Minus an extra penalty, to give Bob an incentive gradient to climb towards what Alice sees as the socially optimal joint policy
- Otherwise maximizes Alice's payoff, given that incentive-shaping constraint
- Caps Bob's expected payoff [LW · GW] at what Bob would have received under Alice's notion of social optimality
- Bob's fallback operates symmetrically, with respect to his notion of social optimality.
The motivating principle is to treat one's choice of decision theory as itself strategic. If Alice chooses a decision theory which never goes Straight, after making the logical observation that Bob's decision theory always goes Straight, then Bob's best response is to pick a decision theory that always goes straight and make that as obvious as possible to Alice's decision theory.
Whereas if Alice designs her decision theory to grant Bob the highest payoff when his decision theory legibly outputs Bob's part of (what Alice sees as a socially optimal joint policy), then Bob's best response is to pick a decision theory that outputs Bob's part of and make that as obvious as possible to Alice's decision theory.
It seems like one general recipe for avoiding commitment races would be something like:
- Design your decision theory so that no information is hazardous to it
- We should never be willing to pay in order to not know certain implications of our beliefs, or true information about the world
- Design your decision theory so that it is not infohazardous to sensible decision theories
- Our counterparts should generally expect to benefit from reasoning more about us, because we legibly are trying to coordinate on good outcomes and we grant the highest payoffs to those that coordinate with us
- If infohazard resistance is straightforward [LW(p) · GW(p)], then our counterpart should hopefully have that reflected in their prior.
- Do all the reasoning you want about your counterpart's decision theory
- It's fine to learn that your counterpart has pre-committed to going Straight. What's true is already so [? · GW]. Learning this doesn't force you to Swerve.
- Plus, things might not be so bad! You might be a hypothetical inside your counterpart's mind, considering how you would react to learning that they've pre-committed to going Straight.
- Your actions in this scenario can determine whether it becomes factual or counterfactual. Being willing to crash into bullies can discourage them from trying to bully you into Swerving in the first place.
- You might also discover good news about your counterpart, like that they're also implementing your decision theory.
- If this were bad news, like for commitment-racers, we'd want to rethink our decision theory.
↑ comment by Martín Soto (martinsq) · 2024-02-09T22:19:16.547Z · LW(p) · GW(p)
The motivating principle is to treat one's choice of decision theory as itself strategic.
I share the intuition that this lens is important. Indeed, there might be some important quantitative differences between
a) I have a well-defined decision theory, and am choosing how to build my successor
and
b) I'm doing some vague normative reasoning to choose a decision theory (like we're doing right now),
but I think these differences are mostly contingent, and the same fundamental dynamics about strategicness are at play in both scenarios.
Design your decision theory so that no information is hazardous to it
I think this is equivalent to your decision theory being dynamically stable (that is, its performance never improves by having access to commitments), and I'm pretty sure the only way to attain this is complete updatelessness (which is bad).
That said, again, it might perfectly be that given our prior, many parts of cooperation-relevant concept-space seem very safe to explore, and so "for all practical purposes" some decision procedures are basically completely safe, and we're able to use them to coordinate with all agents (even if we haven't "solved in all prior-independent generality" the fundamental trade-off between updatelessness and updatefulness).
Replies from: StrivingForLegibility↑ comment by StrivingForLegibility · 2024-02-12T18:18:29.877Z · LW(p) · GW(p)
Got it, I think I understand better the problem you're trying to solve! It's not just being able to design a particular software system and give it good priors, it's also finding a framework that's robust to our initial choice of priors.
Is it possible for all possible priors to converge on optimal behavior, even given unlimited observations? I'm thinking of Yudkowsky's [LW · GW] example of the anti-Occamian and anti-Laplacian priors [LW · GW]: the more observations an anti-Laplacian agent makes, the further its beliefs go from the truth.
I'm also surprised that dynamic stability leads to suboptimal outcomes that are predictable in advance. Intuitively, it seems like this should never happen.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-02-20T20:29:30.067Z · LW(p) · GW(p)
Is it possible for all possible priors to converge on optimal behavior, even given unlimited observations?
Certainly not, in the most general case, as you correctly point out.
Here I was studying a particular case: updateless agents in a world remotely looking like the real world. And even more particular: thinking about the kinds of priors that superintelligences created in the real world might actually have.
Eliezer believes that, in these particular cases, it's very likely we will get optimal behavior (we won't get trapped priors, nor commitment races). I disagree, and that's what I argue in the post.
I'm also surprised that dynamic stability leads to suboptimal outcomes that are predictable in advance. Intuitively, it seems like this should never happen.
If by "predictable in advance" you mean "from the updateless agent's prior", then nope! Updatelessness maximizes EV from the prior, so it will do whatever looks best from this perspective. If that's what you want, then updatelessness is for you! The problem is, we have many pro tanto reasons to think this is not a good representation of rational decision-making in reality, nor the kind of cognition that survives for long in reality. Because of considerations about "the world being so complex that your prior will be missing a lot of stuff". And in particular, multi-agentic scenarios are something that makes this complexity sky-rocket.
Of course, you can say "but that consideration will also be included in your prior". And that does make the situation better. But eventually your prior needs to end. And I argue, that's much before you have all the necessary information to confidently commit to something forever (but other people might disagree with this).
↑ comment by StrivingForLegibility · 2024-03-05T22:08:17.455Z · LW(p) · GW(p)
Got it, thank you!
It seems like trapped priors and commitment races are exactly the sort of cognitive dysfunction that updatelessness would solve in generality.
My understanding is that trapped priors are a symptom of a dysfunctional epistemology, which over-weights prior beliefs when updating on new observations. This results in an agent getting stuck, or even getting more and more confident in their initial position, regardless of what observations they actually make.
Similarly, commitment races are the result of dysfunctional reasoning that regards accurate information about other agents as hazardous. It seems like the consensus is that updatelessness is the general solution to infohazards.
My current model of an "updateless decision procedure", approximated on a real computer, is something like "a policy which is continuously optimized, as an agent has more time to think, and the agent always acts according to the best policy it's found so far." And I like the model you use in your report, where an ecosystem of participants collectively optimize a data structure used to make decisions.
Since updateless agents use a fixed optimization criterion for evaluating policies, we can use something like an optimization market [LW · GW] to optimize an agent's policy. It seems easy to code up traders that identify "policies produced by (approximations of) Bayesian reasoning", which I suspect won't be subject to trapped priors.
So updateless agents seem like they should be able to do at least as well as updateful agents. Because they can identify updateful policies, and use those if they seem optimal. But they can also use different reasoning to identify policies like "pay Paul Ekman to drive you out of the desert [? · GW]", and automatically adopt those when they lead to higher EV than updateful policies.
I suspect that the generalization of updatelessness to multi-agent scenarios will involve optimizing over the joint policy space, using a social choice theory to score joint policies. If agents agree at the meta level about "how conflicts of interest should be resolved", then that seems like a plausible route for them to coordinate on socially optimal joint policies.
I think this approach also avoids the sky-rocketing complexity problem, if I understand the problem you're pointing to. (I think the problem you're pointing to involves trying to best-respond to another agent's cognition, which gets more difficult as that agent becomes more complicated.)