Responses to apparent rationalist confusions about game / decision theory
post by Anthony DiGiovanni (antimonyanthony) · 2023-08-30T22:02:12.218Z · LW · GW · 20 commentsContents
Summary:
Ex post optimal =/= ex ante optimal[1]
Cooperation =/= pure coordination / collective action / defeating Moloch[5]
You aren’t guaranteed to determine the other agent’s response[9]
Updatelessness doesn’t solve commitment races[17]
Acausal decision theories are not necessary for program equilibrium / Löbian cooperation[19]
Newcomblike problems aren’t the norm[20]
There’s no clear objective selection pressure towards acausal decision theories[23]
Acknowledgments
None
20 comments
I’ve encountered various claims about how AIs would approach game theory and decision theory that seem pretty importantly mistaken. Some of these confusions probably aren’t that big a deal on their own, and I’m definitely not the first to point out several of these, even publicly. But collectively I think these add up to a common worldview that underestimates the value of technical work to reduce risks of AGI conflict [? · GW]. I expect that smart agents will likely avoid catastrophic conflict overall—it’s just that the specific arguments for expecting this that I’m responding to here aren’t compelling (and seem overconfident).
For each section, I include in the footnotes some examples of the claims I’m pushing back on (or note whether I’ve primarily seen these claims in personal communication). This is not to call out those particular authors; in each case, they’re saying something that seems to be a relatively common meme in this community.
Summary:
- The fact that conflict is costly for all the agents involved in the conflict, ex post, doesn’t itself imply AGIs won’t end up in conflict. Under their uncertainty about each other, agents with sufficiently extreme preferences or priors might find the risk of conflict worth it ex ante. (more [LW · GW])
- Solutions to collective action problems, where agents agree on a Pareto-optimal outcome they’d take if they coordinated to do so, don’t necessarily solve bargaining problems, where agents may insist on different Pareto-optimal outcomes. (more [LW · GW])
- We don’t have strong reasons to expect AGIs to converge on sufficiently similar decision procedures for bargaining, such that they coordinate on fair demands despite committing under uncertainty. Existing proposals for mitigating conflict given incompatible demands, while promising, face some problems with incentives and commitment credibility. (more [LW · GW])
- The commitment races problem [LW · GW] is not just about AIs making commitments that fail to account for basic contingencies. Updatelessness (or conditional commitments generally) seems to solve the latter, but it doesn’t remove agents’ incentives to limit how much their decisions depend on each other’s decisions (leading to incompatible demands). (more [LW · GW])
- AIs don’t need to follow acausal decision theories in order to (causally) cooperate via conditioning on each other’s source code. (more [LW · GW])
- Most supposed examples of Newcomblike problems in everyday life don’t seem to actually be Newcomblike, once we account for “screening off” by certain information, per the Tickle Defense. (more [LW · GW])
- The fact that following acausal decision theories maximizes expected utility with respect to conditional probabilities, or counterfactuals with the possibility of logical causation, doesn’t imply that agents with acausal decision theories are selected for (e.g., acquire more material resources). (more [LW · GW])
Ex post optimal =/= ex ante optimal[1]
An “ex post optimal” strategy is one that in fact makes an agent better off than the alternatives, while an “ex ante optimal” strategy is optimal with respect to the agent’s uncertainty at the time they choose that strategy. The idea that very smart AGIs could get into conflicts seems intuitively implausible because conflict is, by definition, ex post Pareto-suboptimal. (See the “inefficiency puzzle of war.”)
But it doesn’t follow that the best strategies available to AGIs given their uncertainty about each other will always be ex post Pareto-optimal. This may sound obvious, but my experience with seeing people’s reactions to the problem of AGI conflict suggests that many of them haven’t accounted for this important distinction.
As this post [? · GW] discusses in more detail, there are two fundamental sources of uncertainty (or acting as if uncertain) AGIs might have about each other when they choose bargaining strategies:
- Private information: Instead of fighting, we could agree to a deal where each side gets a fraction of the pie proportional to their probability of winning the fight (a “mock fight” deal). But I might think you’re bluffing about how likely you are to win, and not have a way to objectively verify this probability.[2] More on obstacles to apparent solutions to this problem here [LW(p) · GW(p)].
- Commitment under uncertainty about the other’s commitment (or, “updatelessness”): The mock fight deal is one possible Pareto improvement on the conflict default. But it’s not the only one—if fighting is sufficiently costly,[3] each of us can say, “We’re both better off than the default if I get the whole pie!”
How do we decide between these? In the True Prisoner’s Dilemma [LW · GW] (or rather, as discussed in the next section, True Chicken), there’s no “we.” If I’m an amoral alien [LW · GW], you really don’t want to compromise with me if you can get away with it. You might therefore commit to demand epsilon less than the whole pie, or else you’ll fight, and “race” [LW · GW] to do so in a way that is not influenced by my decision. And I might demand more than epsilon. If I went along with your demand for the sake of peace, I’d be an exploitable sucker!
Each of us is incentivized to choose our demand without knowing what exactly the other will demand, because if you wait to eliminate your uncertainty before making a demand, you lose the opportunity to influence the bargain with your commitment. (See below [LW · GW] for why, e.g., Yudkowsky’s “meta-bargaining” proposal [LW · GW] isn’t sufficient to resolve this.)
Is this risky? Absolutely. I definitely don’t expect hawkish demands to be the norm, because they’re generally riskier than fair demands—which are accepted by a wider range of agents than unfair demands, due to being symmetric in some sense. Evolution tends to select for intrinsic preferences for symmetric notions of fairness. But mindspace is large. We can’t be so confident that AGIs with different values from us will find the risks of conflict greater than the ex ante gains from exploiting others.[4]
Cooperation =/= pure coordination / collective action / defeating Moloch[5]
I think when many people hear about “cooperation” problems faced by AGIs, they imagine Prisoner’s Dilemmas (or Stag Hunts). I.e., they imagine that the problem is that all the actors involved agree on a Pareto-optimal outcome they’d like to move towards, but because of strict dominance (or risk dominance) arguments, they fail to coordinate on that outcome.
We know how to solve those: You conditionally commit to aim for the agreed Pareto-optimal outcome (e.g., Cooperate in the Prisoner’s Dilemma) if and only if the other players also do so. This is well-studied in the “program equilibrium” literature. (More on this later [LW · GW].) And it’s plausible that AGIs will be able to credibly implement these kinds of conditional commitments.[6]
But cooperation problems encompass more than these collective action problems. I’m more concerned about bargaining problems, illustrated by (2) in the previous section: The AGIs might not agree on which Pareto-optimal outcome to aim for,[7] and resort to dangerous commitment race-y [LW · GW] tactics to jockey for their preferred outcomes.[8] Chicken and the Ultimatum Game are prototypical examples.
The basic distinction here:
- Collective action problems are problems posed by nature. The AGIs agree on some preferred alternative outcome, and just need to leverage their increasing capabilities to implement technologies that bring them to that outcome.
- Bargaining problems are problems posed by other AGIs. There’s no obvious guarantee that increasing capabilities dissolve such problems. (The closest candidate I’m aware of is Oesterheld and Conitzer’s safe Pareto improvements, but that’s not a slam dunk either for reasons beyond the scope of this post.)
(Some nice exceptions acknowledging this distinction are Wentworth here [LW · GW] and Demski here [LW · GW].)
You aren’t guaranteed to determine the other agent’s response[9]
(I think the following is the most important misconception in this list, weighted by how common it is.)
A common reaction to the bargaining and commitment races problems is: “Just commit to a fair demand, and reject unfair demands in proportion to how unfair they are.” Call this the Fair Policy.
Suppose that conditional on each agent demanding a bargaining solution that’s symmetric, they coordinate on the same solution. Even so, in order for this proposal to “solve” bargaining, as far as I can tell one of the following assumptions is required, none of which I find plausible:
- “Virtually all[10] agents who are sufficiently capable to enter high-stakes bargaining interactions will coordinate on the Fair Policy.” If, as in a commitment race, the agents face competitive pressures to commit before communicating with each other, it seems that this assumption would in turn require:
- “Virtually all agents who are sufficiently capable to enter high-stakes bargaining interactions will converge on the same decision procedure, and reason that their decision to use the Fair Policy logically causes[11] their counterparts to do likewise.”[12] For many kinds of problems, I think it’s reasonable to expect convergence between arbitrarily capable agents’ methods of reasoning about those problems, namely, to the most effective methods. But:
- Agents need not be arbitrarily capable when they need to make high-stakes bargaining decisions (especially given commitment races).
- If the reason to expect convergence of decision procedures in bargaining problems is that we expect selection for the same decision theory, then: First, see below [LW · GW] for reasons to doubt such selection pressures exist.[13] Second, merely sharing the same decision theory that you consult as an ideal doesn’t mean you’ll share a whole decision procedure (with respect to the given problem). For example, you might not share how you model the decision problem, what kinds of evidence about other agents are most salient to you, how you approximate ideal Bayesianism, etc.[14]
- We might think that agents converge on the same decision procedure with respect to bargaining, not just the same decision theory as their ideal, because there’s one such procedure that’s more effective than others. As noted above [LW · GW], bargaining problems are posed by other agents—so, to speak of “more effective” methods of reasoning about bargaining, we need to specify a distribution of counterparts. So, if either the distribution of agents a given AGI encounters over its history of lower-stakes interactions is sensitive to the initial agents, or AGIs have different priors about potential counterparts, it’s plausible that different highly capable agents will be selected on different distributions of other agents. Therefore they might have different bargaining decision procedures, which weakens the logical dependence between their decisions.
- “Virtually all agents who are sufficiently capable to enter high-stakes bargaining interactions will converge on the same decision procedure, and reason that their decision to use the Fair Policy logically causes[11] their counterparts to do likewise.”[12] For many kinds of problems, I think it’s reasonable to expect convergence between arbitrarily capable agents’ methods of reasoning about those problems, namely, to the most effective methods. But:
- “If you use the Fair Policy, your counterpart will choose their policy as a function of yours—in particular, they’ll best-respond.” Why should you be confident they’ll do that? After all, you aren’t choosing your policy as a function of theirs, because you don’t want to get exploited. You shouldn’t be extremely confident they won’t follow similar logic.
- To clarify, I’m not saying agents should reason as if their counterparts will always follow the same reasoning. Precisely the opposite: The “just commit to a fair demand” proposal only solves the whole problem when everyone else does the same thing. And we saw above some reasons to be skeptical that AIs will blindly coordinate in that way.
- Rather, the danger is other agents following similar logic insofar as they avoid conditioning their policy on yours. I.e., they may reason that many agents will comply with their demands as long as such demands are unconditional, and therefore unconditionally demand more for themselves.
This is related to why another proposal to avoid conflict in bargaining isn’t a full solution. Consider Yudkowsky’s idea in this post [LW · GW]:
The way this might work is that you pick a series of increasingly unfair-to-you, increasingly worse-for-the-other-player outcomes whose first element is what you deem the fair Pareto outcome: (100, 100), (98, 99), (96, 98). Perhaps stop well short of Nash if the skew becomes too extreme. Drop to Nash as the last resort. The other agent does the same, starting with their own ideal of fairness on the Pareto boundary. Unless one of you has a completely skewed idea of fairness, you should be able to meet somewhere in the middle. Both of you will do worse against a fixed opponent's strategy by unilaterally adopting more self-favoring ideas of fairness. Both of you will do worse in expectation against potentially exploitive opponents by unilaterally adopting looser ideas of fairness.
In other words, suppose that instead of defaulting to fighting you if you reject my offer, I make a counteroffer that is worse for me and very slightly worse for you,[15] and repeat. If you do the same, we’ll eventually meet at a bargain that, while not Pareto-efficient, is still better than conflict.
Conditional on us agreeing to this procedure, it’s true that we avoid conflict without giving each other perverse incentives—if I make a larger demand, by construction this doesn’t make me better off. That’s a nice pair of properties!
But consider an aligned AI “Friendly” and misaligned AI “Clippy.” Clippy is very confident that without this procedure, Friendly will back down without a fight, and conflict isn’t so costly by Clippy’s lights anyway. (I suspect Clippy shouldn’t be so confident in this, but that requires an independent argument.) Before Friendly credibly commits to their own demand, Clippy reasons, “If I agree to this procedure, Friendly will know we’ll avoid the particularly costly conflict. So they’ll want to make a more aggressive demand than they would have if I had opted out.” Clippy therefore opts out.
Naturally, a potential solution is for Friendly to commit to not make a more aggressive demand if Clippy participates than if Clippy opts out. But this commitment needs to be made sufficiently credible. That might be relatively challenging compared to verifying other kinds of commitments, because it needs to be verified that Friendly would have behaved in a certain way (after some timeframe where various inputs might have entered into Friendly’s decision-making) given counterfactual beliefs. And whether this works also depends on some nontrivial assumptions on how Friendly updates on Clippy’s (non-)participation.[16]
It’s also worth recalling that AGIs need not be arbitrarily capable at bargaining in order to attain enough power to get into high-stakes bargaining problems. So we can’t be highly confident that AGIs will implement solutions to the problems above by default—especially if doing so requires time-sensitive measures to establish the credibility of their cooperative commitments, under other strategic pressures [LW · GW] in a multipolar takeoff.
Updatelessness doesn’t solve commitment races [LW · GW][17]
Another somewhat common claim is, “Agents don’t really need to commit to anything for strategic purposes. If you’re (open-mindedly) [LW · GW] updateless, you can just decide to do that which a wiser version of your past self would have wanted to commit to, without updating on information that would reduce your bargaining power.”
Assume that an agent can act according to an updateless procedure at the time when they face a critical bargaining decision, and can make their updatelessness credible to other agents. I think these are big assumptions,[18] but at any rate: If these assumptions hold, something like the above argument might indeed dispel worries that agents will make commitments that are ex ante “dumb,” i.e., fail to account for useful information / reflection that in fact wouldn’t have reduced their bargaining power. For example, if the reason you commit to a bargaining policy that conflicts with others’ is literally just that you didn’t consider some other impartial bargaining solution, open-minded updatelessness saves you.
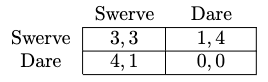
That is not the kind of commitment race that I think is a fundamental problem. In the case of two updateless agents, the problem is that when both of them avoid conditioning on information that would reduce their bargaining power—i.e., knowledge of each other’s demands—they are basically back to playing a game of simultaneous Chicken (figure below). In which case, they each have incentives to Dare to the extent that they ex ante expect each other to Swerve. And they aren’t guaranteed to have identical priors from which they compute the ex ante optimal decision. (Demski writes a similar point here [LW · GW].)
Acausal decision theories are not necessary for program equilibrium / Löbian cooperation[19]
Causal decision theorists don’t always defect in the one-shot Prisoner’s Dilemma. Yes, if you drop a CDT agent into a one-shot Prisoner’s Dilemma de novo, and they only have access to the unconditional Cooperate and Defect strategies, they will defect. But many if not most real-world Prisoner’s Dilemmas are not like this, especially for advanced AGIs.
The CDT agent can use a conditional commitment, like McAfee’s classic, “If other player’s code == my code: Cooperate; else: Defect.” If that’s too brittle for your liking, you can use conditional commitments that verify cooperation via provability logic, or the recursive “robust program equilibrium” method. In a causal interaction with another agent, none of this requires an acausal decision theory: Programs can implement conditional commitments and read each other, causally.
Newcomblike problems aren’t the norm[20]
I think people have overstated the frequency of Newcomblike problems—roughly, cases that distinguish causal from acausal decision theories—“in the wild.” (Note that I wouldn’t count something as a “Newcomblike problem” if the non-causal dependence between one’s action and payoff is too weak to be action-guiding, even if it’s nonzero.)
Soares argues [LW · GW] that Newcomblike problems are ubiquitous because, in social interactions, we “leak information about how we make decisions” on which others base their decisions. I’m unconvinced his examples are truly Newcomblike, however:
- Example 1: How trustworthy you are determines both your own decision, and your microexpressions that shape the other person’s decision (based on how trustworthy they find you).
- Any purported correlations between your decision and your microexpressions, mediated via trustworthiness as a common cause, should be conditioned on what you know about 1) your own trustworthiness, and 2) how you’re reasoning about your microexpressions (and their effects on others’ responses). Just because an antisocial action is unconditionally correlated with information about the actor’s trustworthiness, it doesn’t follow that when you’re thinking about the implications of your action for your trustworthiness, you are less likely to be seen as trustworthy when you do the antisocial action. This is the Tickle Defense.
- It seems that the act of seriously considering the antisocial action is what causes you to make the microexpression that makes others not trust you. (C.f. discussion of the “screening by inclination” version of the Tickle Defense in Ahmed’s Evidence, Decision, and Causality, Ch. 4.)
- Example 2: In games involving deception, like Poker and Diplomacy, you leak information about your strategy via your expressions.
- But managing your own “poker face” is just about causally manipulating your expressions so that you can send signals that profit you.
- Example 3: A job candidate’s demeanor determines both how confidently they act and how positively their interviewer is disposed toward them.
- Soares correctly notes that the candidate should resolve to be bold, because “a person who knows they are going to be bold will have a confident demeanor.” But this just implies that resolving/committing to be bold causally improves the candidate’s job prospects. If the candidate doesn’t resolve to be bold, then when they find themselves acting according to a shy demeanor, they can’t just retroactively cancel this effect by acting bold[21]—per the Tickle Defense, they need to condition the correlation on them choosing to be bold for this acausal decision theory-motivated reason.[22]
- He adds that if a CDT agent commits to being bold, “this would involve using something besides causal counterfactual reasoning during the actual interview.” This is misleading, because committing to being bold restricts the agent’s action space in the interview. So they don’t need to violate CDT when they face the interview. I think a perfectly natural account of the bold job candidate’s success is not that they are having some acausal influence, but that they are using a “fake it 'til you make it” approach, i.e., acting bold initially so as to reinforce their confidence and causally influence both the interviewer and their future behavior.
Why does all this matter? Mainly because claims that acausally motivated decision-making is typical are often used to argue that acausal decision theories systematically succeed in real-world contexts where CDT fails. This brings us to:
There’s no clear objective selection pressure towards acausal decision theories[23]
Finally: as someone who’s very sympathetic to one-boxing in standard Newcomb’s problem, I had to be dragged kicking and screaming into accepting the following point.[24]
Many adherents of acausal decision theories claim that these decision theories “win,” i.e., outperform CDT. If you’re the sort of person who finds intuitive the normative criterion of maximizing expected utility with respect to conditionals, or with respect to counterfactuals that admit some notion of “logical causation,” then sure, it will seem very obvious to you that (the standard form of) CDT “loses.” Why ain’cha rich, David Lewis?[25]
For pumping intuitions about the normative criterion you favor upon reflection, I think this move is sensible.[26] But this doesn’t get us to the empirical claim, “Agents who one-box will systematically outcompete two-boxers in some sense that selects for the former.” That claim seems to require an argument for one of the following:
- “One-boxers will tend to acquire more resources, therefore agents with acausal decision theories will acquire more resources.” I haven’t heard a compelling argument of this form that can’t be debunked by positing that the two-boxers commit to resist some form of exploitation, or to one-box in Newcomblike situations they expect in the future. But such commitments are consistent with the two-boxers’ normative criterion of CDT (as we saw above [LW · GW]). (In particular, these commitments don’t require them to follow the prescriptions of an acausal decision theory in contexts where they can’t commit.)[27]
- Related: Soares’s claim [LW · GW] that agents who follow logical decision theories (LDT) will profit more than those who don’t, in expectation, by acausally cooperating with each other. I find this unconvincing because if indeed some policy of accepting deals that are ex post worse for you is ex ante optimal, again, a CDT agent could commit to that policy. You might object that the LDT agent doesn’t need to anticipate this situation ahead of time, they can just cooperate on the fly. But either a) Bob commits to LDT ahead of time, in which case this defense is moot, or b) Bob previously didn’t follow LDT and decides now to follow LDT. In the latter case, we need a whole separate argument for why we should think Bob and Alice have such logically entangled decision procedures that their decisions determine each other.[28] As discussed above [LW · GW], it’s not enough that they both try to consult the same “decision theory” on paper.
- Further, some reinforcement learning algorithms evidently select for CDT-like behavior in Newcomblike problems. See, e.g., Garrabrant here [LW · GW] and Bell et al. (2021).[29]
- “Generally intelligent reasoning (which will be selected for) leads to endorsement of one-boxing.” But we don’t have objective metrics according to which one-boxing is non-question-beggingly superior.
Acknowledgments
Thanks to Jesse Clifton, Daniel Kokotajlo, Sylvester Kollin, Martín Soto, and Alana Xiang for comments and suggestions.
- ^
- ^
Technically in Bayesian game theory, this is framed as a problem of ex interim uncertainty instead of ex ante. This just means the agent doesn’t decide just based on the common prior, rather, they update on what they know about their own private information.
- ^
This is relevant because it determines whether, e.g., I prefer to gamble on fighting you rather than concede to your demand of the whole pie.
- ^
Given this, I’m not especially excited about work [? · GW] identifying symmetric bargaining solutions (in the technical sense defined here) that may be more attractive Schelling points than preexisting ones, compared to thinking about how to resolve problems posed by incentives not to accept any symmetric bargain.
- ^
Examples:
* Although Yudkowsky doesn’t directly make this mistake in this comment [LW(p) · GW(p)], his argument is (partly) that the existence of a “solution” to the one-shot Prisoner’s Dilemma (a collective action problem) should make us suspect the same for bargaining problems like the Ultimatum Game;
* Various personal communications.
- ^
But see, e.g., this thread [LW(p) · GW(p)].
- ^
Technically, Prisoner’s Dilemmas can be bargaining problems [LW · GW] too, when you can use correlated randomization. This is the lesson of the commitment game folk theorem.
- ^
I attempted to convey this point in this comment [LW(p) · GW(p)].
- ^
Examples:
* Yudkowsky in this comment [LW(p) · GW(p)].
* Udell in this post [LW · GW]: “Bot will only win in a commitment race with Eliezer if Bot self-modifies for the wrong reason, in advance of understanding why self-modification is valuable. Bot, if successful, acted on mere premonitions in his prior reasoning about self-modification. Bot got to, and could only get to, a winning state in the logical mental game against Eliezer "by accident."”
* Udell’s suggestion here [LW · GW] that “precommit[ting] to dividing the value pie according to your notion of fairness” successfully “head[s] off getting into commitment races with each other over splits.”
- ^
I think requiring literally all bargaining problems to be solved is too high a bar.
- ^
See, e.g., logical decision theory—though note that other decision theories can still account for the logical non-causal implications of an agent’s decision.
- ^
(H/t Jesse Clifton for bringing to my attention a steelman of this position; he does not endorse this position.)
- ^
That section discusses the causal vs. acausal decision theory distinction, but the same argument seems to apply to other decision theory axes [LW · GW].
- ^
- ^
Or, as Armstrong proposes in this comment [LW(p) · GW(p)], my counteroffer could be exactly as good for you as the previous offer.
- ^
Some of my current research is on these problems.
- ^
- ^
First: Updateful decision-making seems to work in the vast majority of other decision contexts—similar to my claim below that Newcomblike problems aren’t that common, the same can be said for problems that separate updateful and updateless agents. Given this, for the critical decision in question the agent would need to overcome what seem to be strong default psychological pressures to decide updatefully. (Perhaps this is just easier for AI minds than human minds, for some reason, though.) The agent would also need to retroactively compute the ex ante optimal act. Second, insofar as updateful decision making is the natural default as I claimed, and making commitments to non-default behavior credible is generally challenging, other agents aren’t guaranteed to find the agent’s updatelessness credible.
- ^
Examples:
* From “Introduction to Logical Decision Theory for Computer Scientists” on Arbital: “A truly pure causal decision agent, with no other thoughts but CDT, will wave off all that argument with a sigh; you can't alter what Fairbot2 has already played in the Prisoner's Dilemma and that's that.”
* From Critch (2016): “In this paper, we find that classical game theory—and more generally, causal decision theory (Gibbard and Harper 1978)—is not an adequate framework for describing the competitive interactions of algorithms that reason about the source codes of their opponent algorithms and themselves.” (See also section 6.1.) I think a particularly charitable reading of this is that Critch is claiming that a CDT agent will not reason about how its decisions logically determine its own algorithm, even if they can adopt conditional commitments that do Löbian cooperation. But without more extensive discussion, the claim seems potentially misleading.
- ^
- ^
They can, of course, turn the interview in their favor by changing their behavior, but this can clearly be modeled as causally shaping their future demeanor.
- ^
To be clear, I definitely don’t think the candidate has perfect introspection of the causes of their decision. Rather, it seems plausible that they have strong enough introspection ability to screen off the action-relevant acausal effect here.
- ^
- ^
Thanks to Sylvester Kollin and Jesse Clifton for doing the “dragging” here.
- ^
(h/t Sylvester Kollin) Relatedly, Hintze (2014) argues that updateless decision theory “succeeds” more than others, but this just trivially follows from their definition of success as maximizing ex ante expected utility.
- ^
Though see, e.g., Bales (2018) for what I take to be a contrary view (I’m unsure exactly how much we disagree).
- ^
I would give the same reply to claims that, e.g., UDT outcompetes updateful EDT.
- ^
“Logical decision theorists don’t need to be able to make side-trades to accept such bets, and they’ll keep taking advantage of certain gains even if you forbid such trades. Like, if Alice and Bob have common knowledge that the market is either going to be offered the trade “Alice gains $1,000,000; Bob loses $1” or the trade “Alice loses $1; Bob gains $1,000,000”, with equal probability of each, and they’re not allowed to trade between themselves, then they can (and will, if they’re smart) simply agree to accept whichever trade they’re presented.”
- ^
(h/t Lukas Finnveden and Jesse Clifton)
* Garrabrant: “This problem will, for example, cause a logical inductor EDT agent to defect in a prisoner’s dilemma against a similar power agent that is trying to imitate it. If such an agent were to start out cooperating, random defection will be uncorrelated with the opponent’s prediction. Thus the explored defection will be profitable, and the agent will learn to defect. The opponent will learn this and start predicting defection more and more, but in the long run, the agent view this as independent with its action.”
* Bell et al. (2021) show that under some assumptions, value-based RL can only converge to policies that are ratifiable, which in Newcomb’s problem implies two-boxing.
20 comments
Comments sorted by top scores.
comment by interstice · 2023-08-30T22:47:13.795Z · LW(p) · GW(p)
I find this unconvincing because if indeed some policy of accepting deals that are ex post worse for you is ex ante optimal, again, a CDT agent could commit to that policy[...]Bob commits to LDT ahead of time
If CDT agents commit to acting like LDT agents, doesn't this constitute an objective selection pressure towards using acausal decision theories?
Replies from: antimonyanthony↑ comment by Anthony DiGiovanni (antimonyanthony) · 2023-08-31T08:14:11.282Z · LW(p) · GW(p)
The key point is that "acting like an LDT agent" in contexts where your commitment causally influences others' predictions of your behavior, does not imply you'll "act like an LDT agent" in contexts where that doesn't hold. (And I would dispute that we should label making a commitment to a mutually beneficial deal as "acting like an LDT agent," anyway.) In principle, maybe the simplest generalization of the former is LDT. But if doing LDT things in the latter contexts is materially costly for you (e.g. paying in a truly one-shot Counterfactual Mugging), seems to me that LDT would be selected against.
ETA: The more action-relevant example in the context of this post, rather than one-shot CM, is: "Committing to a fair demand, when you have values and priors such that a more hawkish demand would be preferable ex ante, and the other agents you'll bargain with don't observe your commitment before they make their own commitments." I don't buy that that sort of behavior is selected for, at least not strongly enough to justify the claim I respond to in the third section.
Replies from: interstice↑ comment by interstice · 2023-08-31T21:34:26.341Z · LW(p) · GW(p)
(And I would dispute that we should label making a commitment to a mutually beneficial deal as “acting like an LDT agent,” anyway.)
You said "Bob commits to LDT ahead of time" in the paragraph I quoted, I was referring to that.
But if doing LDT things in the latter contexts is materially costly for you (e.g. paying in a truly one-shot Counterfactual Mugging), seems to me that LDT would be selected against.
I think a CDT agent would pre-commit to paying in a one-off Counterfactual Mugging since they have a 50% chance of gaining $10000 and a 50% chance of losing $100. Or if they don't know that a Counterfactual Mugging is going to happen, they'd have an incentive to broadly pre-commit to pay out in similar situations(essentially, acting like an LDT agent). Or if they won't do either of those things, they will get less future expected resources than an LDT agent.
The more action-relevant example [...] Committing to a fair demand, when you have values and priors such that a more hawkish demand would be preferable
Same as above, I think it's either the case that CDT agents would tend to make pre-commitments to act LDT-like in such situations, or will lose expected resources compared to LDT agents. You can't have your CDT cake and eat it too!
Replies from: antimonyanthony↑ comment by Anthony DiGiovanni (antimonyanthony) · 2023-09-01T15:35:58.183Z · LW(p) · GW(p)
You said "Bob commits to LDT ahead of time"
In the context of that quote, I was saying why I don't buy the claim that following LDT gives you advantages over committing to, in future problems, do stuff that's good for you to commit to do ex ante even if it would be bad for you ex post had you not been committed.
What is selected-for is being the sort of agent who, when others observe you, they update towards doing stuff that's good for you. This is distinct from being the sort of agent who does stuff that would have helped you if you had been able to shape others' beliefs / incentives, when in fact you didn't have such an opportunity.
I think a CDT agent would pre-commit to paying in a one-off Counterfactual Mugging
Sorry I guess I wasn't clear what I meant by "one-shot" here / maybe I just used the wrong term—I was assuming the agent didn't have the opportunity to commit in this way. They just find themselves presented with this situation.
Same as above
Hmm, I'm not sure you're addressing my point here:
Imagine that you're an AGI, and either in training or earlier in your lifetime you faced situations where it was helpful for you to commit to, as above, "do stuff that's good for you to commit to do ex ante even if it would be bad for you ex post had you not been committed." You tended to do better when you made such commitments.
But now you find yourself thinking about this commitment races stuff. And, importantly, you have not previously broadcast credible commitments to a bargaining policy to your counterpart. Do you have compelling reasons to think you and your counterpart have been selected to have decision procedures that are so strongly logically linked, that your decision to demand more than a fair bargain implies your counterpart does the same? I don't see why. But that's what we'd need for the Fair Policy to work as robustly as Eliezer seems to think it does.
Replies from: interstice↑ comment by interstice · 2023-09-01T19:53:04.269Z · LW(p) · GW(p)
In the context of that quote, I was saying why I don’t buy the claim that following LDT gives you advantages over committing to, in future problems, do stuff that’s good for you to commit to do *ex ante *even if it would be bad for you *ex post *had you not been committed.
Yes, but isn't this essentially the same as LDT? It seems to me that different sections of your essay are inconsistent with each other, in that in earlier sections you argue that CDT agents might not adopt LDT-recommended policies and so will have problems with bargaining, but in the last section, you say that CDT agents are not at a competitive disadvantage because they can simply commit to act like LDT agents all the time. But if they so commit, the problems with bargaining won't come up. I think it would make more sense to argue that empirically, situations selecting for LDT simply won't arise(but then will arise and be important later).
What is selected-for is being the sort of agent who, *when others observe you, *they update towards doing stuff that’s good for you
I don't quite understand what you mean here - are you saying that CDT agents will only cooperate if they think it will be causally beneficial, by causing them to have a good reputation with other agents? But we were discussing a case(counterfactual mugging) where they would want to pre-commit to act in ways that would be non-causally beneficial. So I think there would be selection to act non-causally in such cases(unless, again, you just think such situations will never arise, but that's a different argument)
Do you have compelling reasons to think you and your counterpart have been selected to have decision procedures that are so strongly logically linked, that your decision to demand more than a fair bargain implies your counterpart does the same
I don't see why you have to assume that your counterpart is strongly logically-linked with you, there are other reasons that you might not want to demand too much. Maybe you know their source code and can simulate that they will not accept a too-high demand. Or perhaps you think, based on empirical evidence or a priori reasoning that most agents you might encounter will only accept a roughly fair allocation.
Replies from: antimonyanthony↑ comment by Anthony DiGiovanni (antimonyanthony) · 2023-09-06T21:12:27.112Z · LW(p) · GW(p)
in earlier sections you argue that CDT agents might not adopt LDT-recommended policies and so will have problems with bargaining
That wasn’t my claim. I was claiming that even if you're an "LDT" agent, there's no particular reason to think all your bargaining counterparts will pick the Fair Policy given you do. This is because:
- Your bargaining counterparts won’t necessarily consult LDT.
- Even if they do, it’s super unrealistic to think of the decision-making of agents in high-stakes bargaining problems as entirely reducible to “do what [decision theory X] recommends.”
- Even if decision-making in these problems were as simple as that, why should we think all agents will converge to using the same simple method of decision-making? Seems like if an agent is capable of de-correlateing their decision-making in bargaining from their counterpart, and their counterpart knows this or anticipates it on priors, that agent has an incentive to do so if they can be sufficiently confident that their counterpart will concede to their hawkish demand.
So no, “committing to act like LDT agents all the time,” in the sense that is helpful for avoiding selection pressures against you, does not ensure you’ll have a decision procedure such that you have no bargaining problems.
But we were discussing a case(counterfactual mugging) where they would want to pre-commit to act in ways that would be non-causally beneficial.
I’m confused, the commitment is to act in a certain way that, had you not committed, wouldn’t be beneficial unless you appealed to acausal (and updateless) considerations. But the act of committing has causal benefits.
there are other reasons that you might not want to demand too much. Maybe you know their source code and can simulate that they will not accept a too-high demand. Or perhaps you think, based on empirical evidence or a priori reasoning that most agents you might encounter will only accept a roughly fair allocation.
I agree these are both important possibilities, but:
- The reasoning “I see that they’ve committed to refuse high demands, so I should only make a compatible demand” can just be turned on its head and used by the agent who commits to the high demand.
- One might also think on priors that some agents might be committed to high demands, therefore strictly insisting on fair demands against all agents is risky.
I was specifically replying to the claim that the sorts of AGIs who would get into high-stakes bargaining would always avoid catastrophic conflict because of bargaining problems; such a claim requires something stronger than the considerations you've raised, i.e., an argument that all such AGIs would adopt the same decision procedure (and account for logical causation) and therefore coordinate their demands.
(By default if I don't reply further, it's because I think your further objections were already addressed—which I think is true of some of the things I've replied to in this comment.)
comment by interstice · 2023-08-31T21:59:27.270Z · LW(p) · GW(p)
With regard to the overall motivations of the post(technical work to reduce future AI conflict), I don't see why most of the problems listed here can't just be left to the AIs. They basically seem like technical problems in decision theory and bargaining which AIs would in theory be good at solving. It's not clear that any work we do now would be of much use to future superintelligences with very strong motivations to solve the problems(and who will also have direct knowledge of the future strategic landscape)
Replies from: antimonyanthony↑ comment by Anthony DiGiovanni (antimonyanthony) · 2023-09-01T15:05:43.737Z · LW(p) · GW(p)
Yeah, this is a complicated question. I think some things can indeed safely be deferred, but less than you’re suggesting. My motivations for researching these problems:
- Commitment races problems seem surprisingly subtle, and off-distribution for general intelligences who haven’t reflected about them. I argued in the post that competence at single-agent problems or collective action problems does not imply competence at solving commitment races. If early AGIs might get into commitment races, it seems complacent to expect that they’ll definitely be better at thinking about this stuff than humans who have specialized in it.
- If nothing else, human predecessors might make bad decisions about commitment races and lock those into early AGIs. I want to be in a position to know which decisions about early AGIs’ commitments are probably bad—like, say, “just train the Fair Policy with no other robustness measures”—and advise against them.
- Understanding how much risk there is by default of things going wrong, even when AGIs rationally follow their incentives, tells us how cautious we need to be about how to deploy even intent-aligned systems. (C.f. Christiano here [LW · GW] about similar motivations for doing alignment research even if lots of it can be deferred to AIs, too.)
- (Less important IMO:) As I argued in the post, we can’t be confident there’s a “right answer” to decision theory to which AGIs will converge (especially in time for the high-stakes decisions). We may need to solve “decision theory alignment” with respect to our goals, to avoid behavior that is insufficiently cautious by our lights but a rational response to the AGI’s normative standards even if it’s intent-aligned. Given how much humans disagree with each other about decision theory, though: An MVP here is just instructing the intent-aligned AIs to be cautious about thorny decision-theoretic problems where those AIs may think they need to make decisions without consulting [? · GW] humans (but then we need the humans to be appropriately informed about this stuff too, as per (2)). That might sound like an obvious thing to do, but "law of earlier failure" [? · GW] and all that...
- (Maybe less important IMO, but high uncertainty:) Suppose we can partly shape AIs’ goals and priors without necessarily solving all of intent alignment, making the dangerous commitments less attractive to them. It’s helpful to know how likely certain bargaining failure modes are by default, to know how much we should invest in this “plan B.”
- (Maybe less important IMO, but high uncertainty:) As I noted in the post, some of these problems are about making the right kinds of commitments credible before it’s too late. Plausibly we need to get a head start on this. I’m unsure how big a deal this is, but prima facie, credibility of cooperative commitments is both time-sensitive and distinct from intent alignment work.
comment by Anthony DiGiovanni (antimonyanthony) · 2024-12-28T17:14:54.004Z · LW(p) · GW(p)
This post was a blog post day [LW · GW] project. For its purpose of general sanity waterline-raising, I'm happy with how it turned out. If I still prioritized the kinds of topics this post is about, I'd say more about things like:
- "equilibrium" and how it's a misleading and ill-motivated frame for game theory, especially acausal trade;
- time-slice rationality;
- why the logical/algorithmic ontology for decision theory is far from obviously preferable.
But I've come to think there are far deeper and higher-priority mistakes in the "orthodox rationalist worldview" (scare quotes because I know individuals' views are less monolithic than that, of course). Mostly concerning pragmatism about epistemology and uncritical acceptance of precise Bayesianism. I wrote a bit about the problems with pragmatism here [LW · GW], and critiques of precise Bayesianism are forthcoming, though previewed a bit here [LW · GW].
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-28T18:09:12.352Z · LW(p) · GW(p)
One thing I have to say about anthropics is that I think anthropics is basically normal Bayesian reasoning, and the weirdness around it is because people do not specify sampling procedures/realize that the theories work under specific sampling assumptions.
In particular, a lot of anthropical theories assumed independent and random sampling, and if there's any bias to the sampling, the theories spit out nonsense results.
Replies from: antimonyanthony↑ comment by Anthony DiGiovanni (antimonyanthony) · 2024-12-28T18:46:14.048Z · LW(p) · GW(p)
Sure, but isn't the whole source of weirdness the fact that it's metaphysically unclear (or indeterminate) what the real "sampling procedure" is?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-28T18:55:04.834Z · LW(p) · GW(p)
The important properties of the sampling procedure that I think are relevant for anthropics is that it's not an independent or random sample, meaning we get less information from our sole existence today than we think.
The fact that it's not an independent or random sample, and that we have more information is why I reject the doomsday argument (this is also why I think Grabby Aliens is also flawed for explaining the fermi paradox, and the actual answer is we don't know, but at least 1 of the factors is too high.)
Also, very low probability things can happen without any explanation.
Replies from: antimonyanthony↑ comment by Anthony DiGiovanni (antimonyanthony) · 2024-12-29T19:39:54.188Z · LW(p) · GW(p)
it's not an independent or random sample
What kind of sample do you think it is?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-29T21:20:55.539Z · LW(p) · GW(p)
Roughly speaking, it's close to a deterministic sample, though from a human perspective it's affected by some noise on the quantum level, which is amplified to create chaotic outcomes, that is determined by your parents having sex at a particular place and time.
(A complete explanation is beyond my ability, but this is roughly how all humans generate (with caveats/exceptions).
comment by Chris_Leong · 2023-08-31T03:09:10.990Z · LW(p) · GW(p)
You make a very interesting point regarding: "the act of seriously considering the antisocial action is what causes you to make the microexpression that makes others not trust you".
However, I'm more skeptical of your claim, "managing your own “poker face” is just about causally manipulating your expressions so that you can send signals that profit you". This is something that you can try to do. You can try to intentionally think about checking to try convince them you're not going to fold, but this isn't the exact same thing as if you definitely weren't going to fold. It's true that you usually have some additional causal levers, but none of them are the exact same as be the kind of person who does X.
Regarding outperforming CDT, if CDT agents often modify themselves to become an LDT/FDT agent then it would broadly seem accurate to say that CDT is getting outcompeted.
My guess would be that agents self-modifying themselves into such agents would be the primary way MIRI folks expect we'd end up with LDT/FDT agents[1]. I tend to be more interested in understanding these kinds of decision theory problems in and of themselves, and not just as something an AI modifies itself to be able to handle, but I feel like I'm taking something of a minority position here.
- ^
Okay son-of-CDT, but this is typically just a technicality.
↑ comment by Vladimir_Nesov · 2023-08-31T06:17:54.281Z · LW(p) · GW(p)
agents self-modifying [...] the primary way [...] we'd end up with LDT/FDT agents [...] Okay son-of-CDT
Not really, the thing that adopts a decision theory probably didn't have a clear position on adhering to CDT before that. Some spiritual successor to FDT could be the first clear resolution on its behavior that's decision theory shaped.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2023-08-31T06:32:12.392Z · LW(p) · GW(p)
Good point.
↑ comment by Anthony DiGiovanni (antimonyanthony) · 2023-09-03T21:47:03.650Z · LW(p) · GW(p)
Thanks!
It's true that you usually have some additional causal levers, but none of them are the exact same as be the kind of person who does X.
Not sure I understand. It seems like "being the kind of person who does X" is a habit you cultivate over time, which causally influences how people react to you. Seems pretty analogous to the job candidate case.
if CDT agents often modify themselves to become an LDT/FDT agent then it would broadly seem accurate to say that CDT is getting outcompeted
See my replies to interstice's comment—I don't think "modifying themselves to become an LDT/FDT agent" is what's going on, at least, there doesn't seem to be pressure to modify themselves to do all the sorts of things LDT/FDT agents do. They come apart in cases where the modification doesn't causally influence another agent's behavior.
(This seems analogous to claims that consequentialism is self-defeating because the "consequentialist" decision procedure leads to worse consequences on average. I don't buy those claims, because consequentialism is a criterion of rightness, and there are clearly some cases where doing the non-consequentialist thing is a terrible idea by consequentialist lights even accounting for signaling value, etc. It seems misleading to call an agent a non-consequentialist if everything they do is ultimately optimizing for achieving good consequences ex ante, even if they adhere to some rules that have a deontological vibe and in a given situation may be ex post suboptimal.)
Replies from: Chris_Leong↑ comment by Chris_Leong · 2023-09-04T01:55:47.697Z · LW(p) · GW(p)
Attempting to cultivate a habit is not the same as directly being that kind of person. The distinction may seem slight, but it’s worth keeping track of.
comment by Review Bot · 2024-02-18T08:22:51.710Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?