Newcomblike problems are the norm
post by So8res · 2014-09-24T18:41:56.356Z · LW · GW · Legacy · 111 commentsContents
1 2 3 4 5 6 None 111 comments
This is crossposted from my blog. In this post, I discuss how Newcomblike situations are common among humans in the real world. The intended audience of my blog is wider than the readerbase of LW, so the tone might seem a bit off. Nevertheless, the points made here are likely new to many.
1
Last time we looked at Newcomblike problems, which cause trouble for Causal Decision Theory (CDT), the standard decision theory used in economics, statistics, narrow AI, and many other academic fields.
These Newcomblike problems may seem like strange edge case scenarios. In the Token Trade, a deterministic agent faces a perfect copy of themself, guaranteed to take the same action as they do. In Newcomb's original problem there is a perfect predictor Ω which knows exactly what the agent will do.
Both of these examples involve some form of "mind-reading" and assume that the agent can be perfectly copied or perfectly predicted. In a chaotic universe, these scenarios may seem unrealistic and even downright crazy. What does it matter that CDT fails when there are perfect mind-readers? There aren't perfect mind-readers. Why do we care?
The reason that we care is this: Newcomblike problems are the norm. Most problems that humans face in real life are "Newcomblike".
These problems aren't limited to the domain of perfect mind-readers; rather, problems with perfect mind-readers are the domain where these problems are easiest to see. However, they arise naturally whenever an agent is in a situation where others have knowledge about its decision process via some mechanism that is not under its direct control.
2
Consider a CDT agent in a mirror token trade.
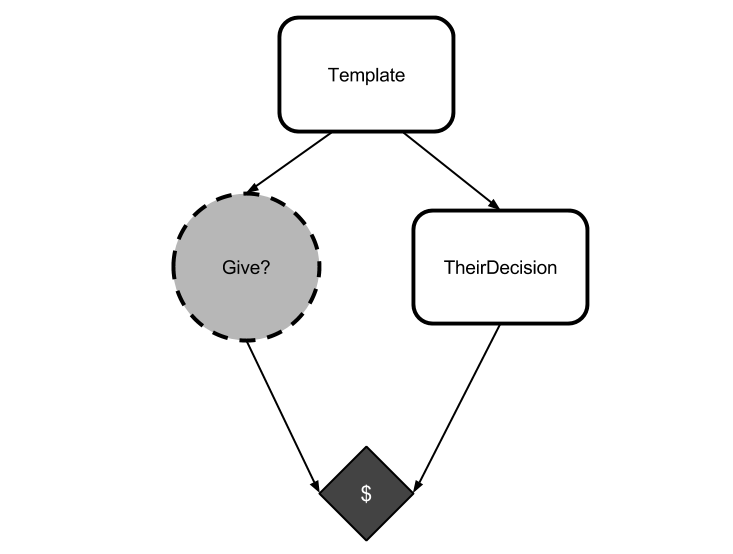
It knows that it and the opponent are generated from the same template, but it also knows that the opponent is causally distinct from it by the time it makes its choice. So it argues
Either agents spawned from my template give their tokens away, or they keep their tokens. If agents spawned from my template give their tokens away, then I better keep mine so that I can take advantage of the opponent. If, instead, agents spawned from my template keep their tokens, then I had better keep mine, or otherwise I won't win any money at all.
It has failed, here, to notice that it can't choose separately from "agents spawned from my template" because it is spawned from its template. (That's not to say that it doesn't get to choose what to do. Rather, it has to be able to reason about the fact that whatever it chooses, so will its opponent choose.)
The reasoning flaw here is an inability to reason as if past information has given others veridical knowledge about what the agent will choose. This failure is particularly vivid in the mirror token trade, where the opponent is guaranteed to do exactly the same thing as the opponent. However, the failure occurs even if the veridical knowledge is partial or imperfect.
3
Humans trade partial, veridical, uncontrollable information about their decision procedures all the time.
Humans automatically make first impressions of other humans at first sight, almost instantaneously (sometimes before the person speaks, and possibly just from still images).
We read each other's microexpressions, which are generally uncontrollable sources of information about our emotions.
As humans, we have an impressive array of social machinery available to us that gives us gut-level, subconscious impressions of how trustworthy other people are.
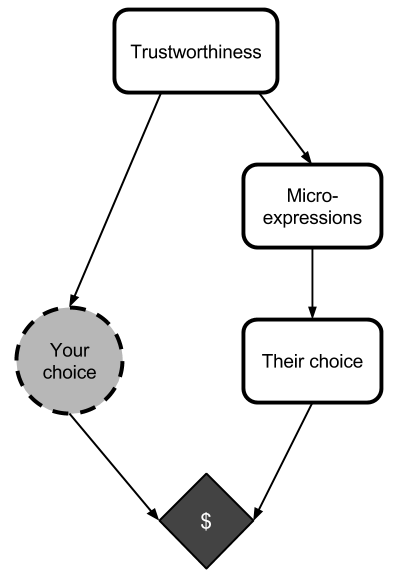
Many social situations follow this pattern, and this pattern is a Newcomblike one.
All these tools can be fooled, of course. First impressions are often wrong. Con-men often seem trustworthy, and honest shy people can seem unworthy of trust. However, all of this social data is at least correlated with the truth, and that's all we need to give CDT trouble. Remember, CDT assumes that all nodes which are causally disconnected from it are logically disconnected from it: but if someone else gained information that correlates with how you actually are going to act in the future, then your interactions with them may be Newcomblike.
In fact, humans have a natural tendency to avoid "non-Newcomblike" scenarios. Human social structures use complex reputation systems. Humans seldom make big choices among themselves (who to hire, whether to become roommates, whether to make a business deal) before "getting to know each other". We automatically build complex social models detailing how we think our friends, family, and co-workers, make decisions.
When I worked at Google, I'd occasionally need to convince half a dozen team leads to sign off on a given project. In order to do this, I'd meet with each of them in person and pitch the project slightly differently, according to my model of what parts of the project most appealed to them. I was basing my actions off of how I expected them to make decisions: I was putting them in Newcomblike scenarios.
We constantly leak information about how we make decisions, and others constantly use this information. Human decision situations are Newcomblike by default! It's the non-Newcomblike problems that are simplifications and edge cases.
Newcomblike problems occur whenever knowledge about what decision you will make leaks into the environment. The knowledge doesn't have to be 100% accurate, it just has to be correlated with your eventual actual action (in such a way that if you were going to take a different action, then you would have leaked different information). When this information is available, and others use it to make their decisions, others put you into a Newcomblike scenario.
Information about what we're going to do is frequently leaking into the environment, via unconscious signaling and uncontrolled facial expressions or even just by habit — anyone following a simple routine is likely to act predictably.
4
Most real decisions that humans face are Newcomblike whenever other humans are involved. People are automatically reading unconscious or unintentional signals and using these to build models of how you make choices, and they're using those models to make their choices. These are precisely the sorts of scenarios that CDT cannot represent.
Of course, that's not to say that humans fail drastically on these problems. We don't: we repeatedly do well in these scenarios.
Some real life Newcomblike scenarios simply don't represent games where CDT has trouble: there are many situations where others in the environment have knowledge about how you make decisions, and are using that knowledge but in a way that does not affect your payoffs enough to matter.
Many more Newcomblike scenarios simply don't feel like decision problems: people present ideas to us in specific ways (depending upon their model of how we make choices) and most of us don't fret about how others would have presented us with different opportunities if we had acted in different ways.
And in Newcomblike scenarios that do feel like decision problems, humans use a wide array of other tools in order to succeed.
Roughly speaking, CDT fails when it gets stuck in the trap of "no matter what I signaled I should do [something mean]", which results in CDT sending off a "mean" signal and missing opportunities for higher payoffs. By contrast, humans tend to avoid this trap via other means: we place value on things like "niceness" for reputational reasons, we have intrinsic senses of "honor" and "fairness" which alter the payoffs of the game, and so on.
This machinery was not necessarily "designed" for Newcomblike situations. Reputation systems and senses of honor are commonly attributed to humans facing repeated scenarios (thanks to living in small tribes) in the ancestral environment, and it's possible to argue that CDT handles repeated Newcomblike situations well enough. (I disagree somewhat, but this is an argument for another day.)
Nevertheless, the machinery that allows us to handle repeated Newcomblike problems often seems to work in one-shot Newcomblike problems. Regardless of where the machinery came from, it still allows us to succeed in Newcomblike scenarios that we face in day-to-day life.
The fact that humans easily succeed, often via tools developed for repeated situations, doesn't change the fact that many of our day-to-day interactions have Newcomblike characteristics. Whenever an agent leaks information about their decision procedure on a communication channel that they do not control (facial microexpressions, posture, cadence of voice, etc.) that person is inviting others to put them in Newcomblike settings.
5
Most of the time, humans are pretty good at handling naturally arising Newcomblike problems. Sometimes, though, the fact that you're in a Newcomblike scenario does matter.
The games of Poker and Diplomacy are both centered around people controlling information channels that humans can't normally control. These games give particularly crisp examples of humans wrestling with situations where the environment contains leaked information about their decision-making procedure.
These are only games, yes, but I'm sure that any highly ranked Poker player will tell you that the lessons of Poker extend far beyond the game board. Similarly, I expect that highly ranked Diplomacy players will tell you that Diplomacy teaches you many lessons about how people broadcast the decisions that they're going to make, and that these lessons are invaluable in everyday life.
I am not a professional negotiator, but I further imagine that top-tier negotiators expend significant effort exploring how their mindsets are tied to their unconscious signals.
On a more personal scale, some very simple scenarios (like whether you can get let into a farmhouse on a rainy night after your car breaks down) are somewhat "Newcomblike".
I know at least two people who are unreliable and untrustworthy, and who blame the fact that they can't hold down jobs (and that nobody cuts them any slack) on bad luck rather than on their own demeanors. Both consistently believe that they are taking the best available action whenever they act unreliable and untrustworthy. Both brush off the idea of "becoming a sucker". Neither of them is capable of acting unreliable while signaling reliability. Both of them would benefit from actually becoming trustworthy.
Now, of course, people can't suddenly "become reliable", and akrasia is a formidable enemy to people stuck in these negative feedback loops. But nevertheless, you can see how this problem has a hint of Newcomblikeness to it.
In fact, recommendations of this form — "You can't signal trustworthiness unless you're trustworthy" — are common. As an extremely simple example, let's consider a shy candidate going in to a job interview. The candidate's demeanor (confident or shy) will determine the interviewer's predisposition towards or against the candidate. During the interview, the candidate may act either bold or timid. Then the interviewer decides whether or not to hire the candidate.
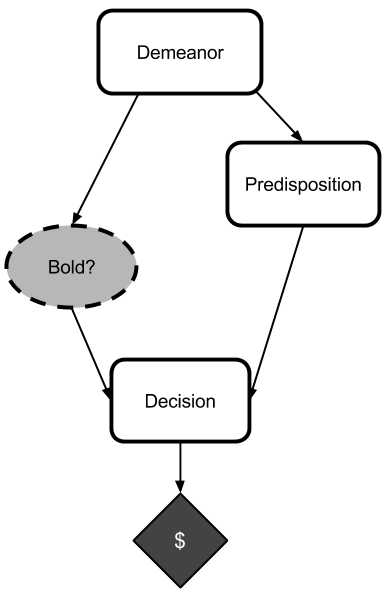
If the candidate is confident, then they will get the job (worth $100,000) regardless of whether they are bold or timid. If they are shy and timid, then they will not get the job ($0). If, however, thy are shy and bold, then they will get laughed at, which is worth -$10. Finally, though, a person who knows they are going to be timid will have a shy demeanor, whereas a person who knows they are going to be bold will have a confident demeanor.
It may seem at first glance that it is better to be timid than to be bold, because timidness only affects the outcome if the interviewer is predisposed against the candidate, in which case it is better to be timid (and avoid being laughed at). However, if the candidate knows that they will reason like this (in the interview) then they will be shy before the interview, which will predispose the interviewer against them. By contrast, if the candidate precommits to being bold (in this simple setting) then the will get the job.
Someone reasoning using CDT might reason as follows when they're in the interview:
I can't tell whether they like me or not, and I don't want to be laughed at, so I'll just act timid.
To people who reason like this, we suggest avoiding causal reasoning during the interview.
And, in fact, there are truckloads of self-help books dishing out similar advice. You can't reliably signal trustworthiness without actually being trustworthy. You can't reliably be charismatic without actually caring about people. You can't easily signal confidence without becoming confident. Someone who cannot represent these arguments may find that many of the benefits of trustworthiness, charisma, and confidence are unavailable to them.
Compare the advice above to our analysis of CDT in the mirror token trade, where we say "You can't keep your token while the opponent gives theirs away". CDT, which can't represent this argument, finds that the high payoff is unavailable to it. The analogy is exact: CDT fails to represent precisely this sort of reasoning, and yet this sort of reasoning is common and useful among humans.
6
That's not to say that CDT can't address these problems. A CDT agent that knows it's going to face the above interview would precommit to being bold — but this would involve using something besides causal counterfactual reasoning during the actual interview. And, in fact, this is precisely one of the arguments that I'm going to make in future posts: a sufficiently intelligent artificial system using CDT to reason about its choices would self-modify to stop using CDT to reason about its choices.
We've been talking about Newcomblike problems in a very human-centric setting for this post. Next post, we'll dive into the arguments about why an artificial agent (that doesn't share our vast suite of social signaling tools, and which lacks our shared humanity) may also expect to face Newcomblike problems and would therefore self-modify to stop using CDT.
This will lead us to more interesting questions, such as "what would it use?" (spoiler: we don't quite know yet) and "would it self-modify to fix all of CDT's flaws?" (spoiler: no).
111 comments
Comments sorted by top scores.
comment by dankane · 2014-09-25T16:20:34.976Z · LW(p) · GW(p)
Newcomblike problems occur whenever knowledge about what decision you will make leaks into the environment. The knowledge doesn't have to be 100% accurate, it just has to be correlated with your eventual actual action.
This is far too general. The way in which information is leaking into the environment is what separates Newcomb's problem from the smoking lesion problem. For your argument to work you need to argue that whatever signals are being picked up on would change if the subject changed their disposition, not merely that these signals are correlated with the disposition.
Replies from: So8res, dankane, dankane↑ comment by dankane · 2014-09-25T17:59:48.705Z · LW(p) · GW(p)
Relatedly, with your interview example, I think that perhaps a better model is that whether a person is confident or shy is not depending on whether they believe that they will be bold or not, but upon the degree to which they care about being laughed at. If you are confident, you don't care about being laughed at and might as well be bold. If you are afraid of being laughed at, you already know that you are shy and thus do not gain anything by being bold.
↑ comment by dankane · 2014-09-25T17:44:12.784Z · LW(p) · GW(p)
I think my bigger point is that you don't seem to make any real argument as to which case we are in. For example, consider the following model of how people's perception of my trustworthiness might be correlated to my actual trustworthiness: There are two causal chains: My values -> Things I say -> Peoples' perceptions My values -> My actions So if I value trustworthiness, I will not, for example talk much about wanting to avoid being sucker (in contexts where it would refer to be doing trustworthy things). This will influence peoples' perceptions of whether or not I am trustworthy. Furthermore, if I do value trustworthiness, I will want to be trustworthy.
This setup makes things look very much like the smoking lesion problem. A CDT agent that values trustworthiness will be trustworthy because they place intrinsic value in it. A CDT agent that does not value trustworthiness will be perceived as being untrustworthy. Simply changing their actions will not alter this perception, and therefore they will fail to be trustworthy in situations where it benefits them, and this is the correct decision.
Now you might try to break the causal link: My values -> Things that I say And doing so is certainly possible (I mean you can have spies that successfully pretend to be loyal for extended periods without giving themselves away). On the other hand, it might not happen often for several possible reasons: A) Maintaining a facade at all times is exhausting (and thus imposes high costs) B) Lying consistently is hard (as in too computationally expensive) C) The right way to lie consistently, is to simulate the altered value set, but this may actually lead to changing your values (standard advice for become more confident is pretending to be confident, right?).
So yes, in this model an non-trust-valuing and self-modifying CDT agent will self-modify, but it will need to self-modify its values rather than its decision theory. Using a decision theory that is trustworthy despite not intrinsically valuing it doesn't help.
comment by William_Quixote · 2014-09-24T19:18:08.402Z · LW(p) · GW(p)
Yay!
I realize that "yay!" Isn't really much of a comment, but I was waiting for this and now it's here. The poster has made the world a happier place.
Replies from: Regex↑ comment by Regex · 2014-10-04T11:42:38.579Z · LW(p) · GW(p)
https://www.youtube.com/watch?v=DLTZctTG6cE
I think "yay!" is a perfect comment when also given a certain shy pegasus.
comment by owencb · 2014-09-24T19:29:23.922Z · LW(p) · GW(p)
Thanks, this was one of the more insightful things I remember reading about decision theory.
You've argued that many human situations are somewhat Newcomblike. Do we have a decision theory which deals cleanly with this continuum? (where the continuum is expressed for instance via the degree of correlation between your action and the other player's action)
comment by bryjnar · 2014-09-24T21:56:09.754Z · LW(p) · GW(p)
Fantastic post, I think this is right on the money.
Many more Newcomblike scenarios simply don't feel like decision problems: people present ideas to us in specific ways (depending upon their model of how we make choices) and most of us don't fret about how others would have presented us with different opportunities if we had acted in different ways.
I think this is a big deal. Part of the problem is that the decision point (if there was anything so firm) is often quite temporally distant from the point at which the payoff happens. The time when you "decide" to become unreliable (or the period in which you become unreliable) may be quite a while before you actually feel the ill effects of being unreliable.
comment by adam_strandberg · 2014-09-25T16:50:07.777Z · LW(p) · GW(p)
Yes, thank you for writing this- I've been meaning to write something like it for a while and now I don't need to! I initially brushed Newcomb's Paradox off as an edge case and it took me much longer than I would have liked to realize how universal it was. A discussion of this type should be included with every introduction to the problem to prevent people from treating it as just some pointless philosophical thought experiment.
comment by William_Quixote · 2014-09-24T19:23:49.991Z · LW(p) · GW(p)
More substantively, can we express mathematically how the correlation between leaked signal and final choice effects the degree of sub optimality in final payouts?
Naively in the actual Newcombe's problem if omega is only correct 1/999,000+epsilon percent of the time then CDT seems to do about as well as whatever theory that solves this problem. Is there a known general case for this reasoning?
Replies from: Vaniver, DavidS↑ comment by Vaniver · 2014-09-25T17:13:40.578Z · LW(p) · GW(p)
Naively in the actual Newcombe's problem if omega is only correct 1/999,000+epsilon percent of the time then CDT seems to do about as well as whatever theory that solves this problem.
This is not quite correct; this comment hints at why. CDT will sever the causal links pointing in to your decision, and so if you don't think that what you choose to do will affect what Omega has guessed in the past, then it doesn't matter how good a guesser you think Omega is.
The reason Newcomb's Problem proper causes such headache and discussion is, in my mind, a failure to separate what causation means in reality and what causation means in decision theory. A model of Newcomb's problem proper which has our decision causing Omega's prediction violates realistic assumptions that the future cannot cause the past; a model of Newcomb's problem proper which has our decision not causing Omega's prediction violates the problem statement that Omega is a perfect predictor (i.e. we don't have an arrow, which implies two variables are independent, but in fact those variables are dependent).
If you discard the requirement that causes seem physically reasonable, then CDT can reason in the general case here. (You just stick the probabilistic depedence in like you would any other.) The issue is that, in reality, requiring influences to be real makes good sense!
Replies from: William_Quixote↑ comment by William_Quixote · 2014-09-25T17:26:00.067Z · LW(p) · GW(p)
I think my original post may have been unclear. Sorry about that.
What I meant was not that how accurate omega is impacts what CDC does. What I meant was that the accuracy impacts how much "pick up" you can get from a better theory. So if omega is perfect one boxing get you 1,000,000 vs 1000 from two boxing for an increase of 999,000. If omega is less than perfect, then sometimes the one boxer gets nothing or the two boxer gets 1001000. This brings their average results closer. At some accuracy, P, CDC and the theory which solves the problem and correctly chooses to one box do almost equally well.
Omegas accuracy is related to the information leakage about the choosers decision theory.
Replies from: Vaniver↑ comment by Vaniver · 2014-09-25T17:40:43.038Z · LW(p) · GW(p)
What I meant was that the accuracy impacts how much "pick up" you can get from a better theory.
Agreed. Because of the simplicity of Newcomb's proper, I think this is going to make for an unimpressive graph, though: the rewards are linear in Omega's accuracy P, so it should just be a simple piecewise function for the clever theory, diverging from the two-boxer at the low accuracy and eventually reaching the increase of $999,000 at P=1.
↑ comment by DavidS · 2014-10-03T20:09:54.218Z · LW(p) · GW(p)
"Naively in the actual Newcombe's problem if omega is only correct 1/999,000+epsilon percent of the time…"
I'd like to argue with this by way of a parable. The eccentric billionaire, Mr. Psi, invites you to his mansion for an evening of decision theory challenges. Upon arrival, Mr. Psi's assistant brings you a brandy and interviews you for hours about your life experiences, religious views, favorite philosophers, ethnic and racial background … You are then brought into a room. In front of you is a transparent box with a $1 bill in it, and an opaque box. Mr. Psi explains:
"You may take just the solid box, or both boxes. If I predicted you take one box, then that box contains $1000, otherwise it is empty. I am not as good at this game as my friend Omega, but out of my last 463 games, I predicted "one box" 71 times and was right 40 times out of 71; I picked "two boxes" 392 times and was right 247 times out of 392. To put it another way, those who one-boxed got an average of (40$1000+145$0)/185 = $216 and those who two-boxed got an average of (31$1001+247$1)/278=$113. "
So, do you one-box?
"Mind if I look through your records?" you say. He waves at a large filing cabinet in the corner. You read through the volumes of records of Mr. Psi's interviews, and discover his accuracy is as he claims. But you also notice something interesting (ROT13): Ze. Cfv vtaberf nyy vagreivrj dhrfgvbaf ohg bar -- ur cynprf $1000 va gur obk sbe gurvfgf naq abg sbe ngurvfgf. link.
Still willing to say you should one-box?
By the way, if it bothers you that the odds of $1000 are less than 50% no matter what, I also could have made Mr. Psi give money to 99/189 one boxers (expected value $524) and only to 132/286 two boxers (expected value $463) just by hfvat gur lrne bs lbhe ovegu (ROT13). This strategy has a smaller difference in expected value, and a smaller success rate for Mr. Psi, but might be more interesting to those of you who are anchoring on $500.
comment by bramflakes · 2014-09-24T19:41:23.689Z · LW(p) · GW(p)
Has anyone written at length about the evolution of cooperation in humans in this kind of Newcomblike context? I know there's been oceans of ink spent from IPD perspectives, but what about from the acausal angle?
Replies from: None↑ comment by [deleted] · 2014-09-25T23:39:02.852Z · LW(p) · GW(p)
Interesting note: the genetic and cultural features coding for "acausal" social reasoning on the part of the human agent actually have a direct causal influence on the events. They are the physical manifestation of TDT's logical nodes.
comment by IlyaShpitser · 2014-09-28T13:27:37.050Z · LW(p) · GW(p)
Thanks for doing this series!
I thought you were going to say that humans play Newcomb-like games with themselves, where a "disordered soul" doesn't bargain with itself properly. :)
comment by Chris_Leong · 2019-12-05T23:16:14.238Z · LW(p) · GW(p)
I think this article has some truth in it, but that it also overstates its case. It seems that it'll only be certain cases where your demeanour at the time you are read will correlate with your final decision. Like let's suppose you arrive in town for an imperfect Parfit's Hitchhiker and someone gives you an argument for not paying that hadn't occurred to you before. Then it seems like you should be able to defect on the basis of this argument, without affecting the facial reading at the time. Of course, it isn't quite this simple. If you thought it was likely that you might encounter a new argument for defecting, even if you didn't know what it might be yet, then that might change your facial expression. Or if you were already subconsciously aware of the argument, but it hadn't yet risen to the level of consciousness, then that might change how you are read as well.
comment by JoshuaFox · 2014-10-10T13:27:19.947Z · LW(p) · GW(p)
The palm example is a bit confusing. Palms don't really tell the future: There is no direct causal link (unless someone listens to a palm-reader!). It would be much better if you gave a different example of confusing causality and correlation where there really was correlation.
It reminds me of Eliezer's example of the machine learning system that seemed to be finding camouflaged tanks, but in fact was confused by the sunniness of the different sets of photos: As far as I can tell that never happened.
Then there is the decision theory example of Solomon wanting to sleep with Bathsheba, which confusingly morphs into a discussion of Oedipal complexes if you're not paying attention. (As Eliezer points out, this example was a originally a follow-on to another story involving King David and Bathsheba, not that that makes it any less confusing.
And it appears that architectural spandrels, after which biological spandrels are named, are not really spandrels) in the originally intended sense. What a mess!
On the other hand, I am glad that Eliezer worked hard to change the standard "Smoking Lesion" story to a fictional chewing gum example, since smoking indeed causes cancer. But that was a fictional story, and Alex Altair did much better in coming up with a real (or at least plausibly real story about toxoplasmosis.
comment by JoshuaFox · 2014-10-10T13:33:08.215Z · LW(p) · GW(p)
I'd suggest not using palm reading as an example, since palm lines really do not affect the future (unless you believe they do).
Likewise, the example of a machine learning system misanalyzing sunlight patterns as tanks is apparently fake.
The Solomon and Bathsheba problem looks more a discussion of an Oedipal complex at first. What a mess!
Eliezer had the good sense to transform the Smoking Lesion into a Chewing Gum Lesion, since smoking does in fact cause cancer. But chewing gum doesn't cause lesions. Alex Altair's example of toxoplasmosis was at least plausible.
In summary, examples should be realistic. I can deal with unrealistic thought experiments like dropping people through space in elevators and catching balls tossed from 0.99c trains -- but decision theory is full of counter-factuals, so let's not add in any more confusion.
comment by Vaniver · 2014-09-25T18:09:14.503Z · LW(p) · GW(p)
I agree that an intelligent agent who deals with other intelligent agents should have think in a way that makes reasoning about 'dispositions' and 'reputations' easy, because it's going to be doing it a lot.
But it's unclear to me that this requires a change to decision theory, instead of just a sophisticated model of what the agent's environment looks like that's tuned to thinking about dispositions and reputations. I think that an agent that realizes that the game keeps going on, and that its actions result in both immediate rewards and delayed shifts to its environment (which impact future rewards), will behave like you describe in section 4- it will use concepts like "fairness" and "honor" with an implied numerical value attached, because those are its estimates of how taking an anti-social action now will hurt it in the future, which it balances against the present gain to decide whether or not to take the action. And a CDT agent, with the right world-model, seems to me like it will do fine (which is my opinion about the proper Newcomb's problem, as well as Newcomb-like problems). I agree with eli_sennesh in this comment thread that getting the precise value of reputational effects requires actual prescience, but it seems to me that we can estimate it well enough to get along (though it seems possible that much of our 'estimation' is biological tuning rather than stored in memory).
A CDT agent that knows it's going to face the above interview would precommit to being bold — but this would involve using something besides causal counterfactual reasoning during the actual interview.
I don't think I buy this interpretation. It seems to me that the CDT agent with a broader scope than 'the immediate future' thinks it's better to not break the precommitment than to break it (in situations where the math works out that way), because of the counterfactual effects that breaking a precommitment will have on the future. You become what you do!
Replies from: So8res, owencb↑ comment by So8res · 2014-09-25T18:38:50.895Z · LW(p) · GW(p)
CDT + Precommitments is not pure CDT -- I agree that CDT over time (with the ability to make and keep precommitments) does pretty well, and this is part of what I mean when I talk about how an agent using pure CDT to make every decision would self-modify to stop doing that (e.g., to implement precommitments, which is trivially easy when you can modify your own source code).
Consider the arguments of CDT agents as they twobox, when they claim that they would have liked to precommit but they missed their opportunity -- we can do better by deciding to act as we would have precommitted to act, but this entails using a different decision theory. You can minimize the number of missed opportunities by allowing CDT many opportunities to precommit, but that doesn't change the fact that CDT can't retrocommit.
If you look at the decision-making procedure of something which started out using CDT after it self-modifies a few times, the decision procedure probably won't look like CDT, even though it was implemented by CDT making "precommitments".
And while CDT mostly does well when the games are repeated, there are flaws that CDT won't be able to self-correct (roughly corresponding to CDT's inability to make retrocommitments), these will be the subject of future posts.
Replies from: V_V, Vaniver↑ comment by V_V · 2014-09-28T13:54:52.888Z · LW(p) · GW(p)
Consider the arguments of CDT agents as they twobox, when they claim that they would have liked to precommit but they missed their opportunity
Why would they do that?
CDT two-boxes because CDT simply fails to understand that the content of the box is influenced by its decision. It deliberately uses an incorrect epistemic model.
So when the agent two-boxes and it obtains a reward different than what it had predicted, it will simply think it has been lied to, or if it is one hundred percent, certain that the model was correct, then it will experience a logical contradiction, halt and catch fire.
↑ comment by Vaniver · 2014-09-25T20:16:16.995Z · LW(p) · GW(p)
CDT + Precommitments is not pure CDT
By CDT I mean calculating utilities using:
=\sum_jP(O_j%7Cdo(A))D(O_j))
Most arguments that I see for the deficiency of CDT rest on additional assumptions that are not required by CDT. I don't see how we need to modify that equation to take into account precommitments, rather than modifying D(O_j).
Consider the arguments of CDT agents as they twobox, when they claim that they would have liked to precommit but they missed their opportunity
For example, this requires the additional assumption that the future cannot cause the past. In the presence of a supernatural Omega, that assumption is violated.
that doesn't change the fact that CDT can't retrocommit.
Outside of supernatural opportunities, it's not obvious to me that this is a bug. I'll wait for you to make the future arguments at length, unless you want to give a brief version.
Replies from: So8res, private_messaging↑ comment by So8res · 2014-09-26T18:27:53.921Z · LW(p) · GW(p)
Right, you can modify the function that evaluates outcomes to change the payoffs (e.g. by making exploitation in the PD have a lower payoff that mutual cooperation, because it "sullies your honor" or whatever) and then CDT will perform correctly. But this is trivially true: I can of course cause that equation to give me the "right" answer by modifying D(O_j) to assign 1 to the "right" outcome and 0 to all other outcomes. The question is how you go about modifying D to identify the "right" answer.
I agree that in sufficiently repetitive environments CDT readily modifies the D function to alter the apparent payoffs in PD-like problems (via "precommitments"), but this is still an unsatisfactory hack.
First of all, the construction of the graph is part of the decision procedure. Sure, in certain situations CDT can fix its flaws by hiding extra logic inside D. However, I'd like to know what that logic is actually doing so that I can put it in the original decision procedure directly.
Secondly, CDT can't (or, rather, wouldn't) fix all of its flaws by modifying D -- it has some blind spots, which I'll go into later.
Outside of supernatural opportunities, it's not obvious to me that this is a bug. I'll wait for you to make the future arguments at length, unless you want to give a brief version.
(I don't understand where your objection is here. What do you mean by 'supernatural'? Do you think you should always twobox in a Newcomb's problem where Omega is played by Paul Eckman, a good but imperfect predictor?)
You find yourself in a PD against a perfect copy of yourself. At the end of the game, I will remove the money your clone wins, destroy all records of what you did, re-merge you with your clone, erase both our memories of the process, and let you keep the money that you won (you will think it is just a gift to recompense you for sleeping in my lab for a few hours). You had not previously considered this situation possible, and had made no precommitments about what to do in such a scenario. What do you think you should do?
Also, what do you think the right move is on the true PD?
Replies from: Strange7, Vaniver↑ comment by Strange7 · 2014-10-02T23:58:06.926Z · LW(p) · GW(p)
You find yourself in a PD against a perfect copy of yourself. At the end of the game, I will remove the money your clone wins, destroy all records of what you did, re-merge you with your clone, erase both our memories of the process, and let you keep the money that you won (you will think it is just a gift to recompense you for sleeping in my lab for a few hours). You had not previously considered this situation possible, and had made no precommitments about what to do in such a scenario. What do you think you should do?
Given that you're going to erase my memory of this conversation and burn a lot of other records afterward, it's entirely possible that you're lying about whether it's me or the other me whose payout 'actually counts.' Makes no difference to you either way, right? We all look the same, and telling us different stories about the upcoming game would break the assumption of symmetry. Effectively, I'm playing a game of PD followed by a special step in which you flip a fair coin and, on heads, swap my reward with that of the other player.
So, I'd optimize for the combined reward to both myself and my clone, which is to say, for the usual PD payoff matrix, cooperate. If the reward for defecting when the other player cooperates is going to be worth drastically more to my postgame gestalt, to the point that I'd accept a 25% or less chance of that payout in trade for virtual certainty of the payout for mutual cooperation, I would instead behave randomly.
Replies from: Jiro↑ comment by Jiro · 2014-10-03T02:49:54.801Z · LW(p) · GW(p)
Saying "I wouldn't trust someone like that to tell the truth about whose payout counts" is fighting the hypothetical.
I don't think you need to assume the other party is a clone; you just need to assume that both you and the other party are perfect reasoners.
Replies from: VAuroch, Strange7↑ comment by Strange7 · 2014-10-03T16:27:15.669Z · LW(p) · GW(p)
fighting the hypothetical
It's established in the problem statement that the experimenter is going to destroy or falsify all records of what transpired during the game, including the fact that a game even took place, presumably to rule out cooperation motivated by reputational effects. If you want a perfectly honest and trustworthy experimenter, establish that axiomatically, or at least don't establish anything that directly contradicts.
Assuming that the other party is a clone with identical starting mind-state makes it a much more tractable problem. I don't have much idea how perfect reasoners behave; I've never met one.
↑ comment by Vaniver · 2014-09-27T00:46:38.868Z · LW(p) · GW(p)
Right, you can modify the function that evaluates outcomes to change the payoffs (e.g. by making exploitation in the PD have a lower payoff that mutual cooperation, because it "sullies your honor" or whatever) and then CDT will perform correctly. But this is trivially true: I can of course cause that equation to give me the "right" answer by modifying D(O_j) to assign 1 to the "right" outcome and 0 to all other outcomes. The question is how you go about modifying D to identify the "right" answer.
I agree with this. It seems to me that answers about how to modify D are basically questions about how to model the future; you need to price the dishonor in defecting, which seems to me to require at least an implicit model of how valuable honor will be over the course of the future. By 'honor,' I just mean a computational convenience that abstracts away a feature of the uncertain future, not a terminal value. (Humans might have this built in as a terminal value, but that seems to be because it was cheaper for evolution to do so than the alternative.)
I agree that in sufficiently repetitive environments CDT readily modifies the D function to alter the apparent payoffs in PD-like problems (via "precommitments"), but this is still an unsatisfactory hack.
I don't think I agree with the claim that this is an unsatisfactory hack. To switch from decision-making to computer vision as the example, I hear your position as saying that neural nets are unsatisfactory for solving computer vision, so we need to develop an extension, and my position as saying that neural nets are the right approach, but we need very wide nets with very many layers. A criticism of my position could be "but of course with enough nodes you can model an arbitrary function, and so you can solve computer vision like you could solve any problem," but I would put forward the defense that complicated problems require complicated solutions; it seems more likely to me that massive databases of experience will solve the problem than improved algorithmic sophistication.
I don't understand where your objection is here. What do you mean by 'supernatural'?
In the natural universe, it looks to me like opportunities that promise retrocausation turn out to be scams, and this is certain enough to be called a fundamental property. In hypothetical universes, this doesn't have to be the case, but it's not clear to me how much effort we should spend on optimizing hypothetical universes. In either case, it seems to me this is something that the physics module (i.e. what gives you P(O_j|do(A))) should compute, and only baked into the decision theory by the rules about what sort of causal graphs you think are likely.
Do you think you should always twobox in a Newcomb's problem where Omega is played by Paul Eckman, a good but imperfect predictor?
Given that professional ethicists are neither nicer nor more dependable than similar people of their background, I'll jump on the signalling grenade to point out that any public discussion of these sorts of questions is poisoned by signalling. If I expected that publicly declaring my willingness to one-box would increase the chance that I'm approached by Newcomb-like deals, then obviously I would declare my willingness to one-box. As it turns out, I'm trustworthy and dependable in real life, because of both a genetic predisposition towards pro-social behavior (including valuing things occurring after my death) and a reflective endorsement of the myriad benefits of behaving in that way.
You had not previously considered this situation possible, and had made no precommitments about what to do in such a scenario.
I decided a long time ago to cooperate with myself as a general principle, and I think that was more a recognition of my underlying personality than it was a conscious change.
If the copy is perfect, it seems unreasonable to me to not draw a causal arrow between my action and my copy's action, as I cannot justify the assumption that my action will be independent of my perfect copy's action. Estimating that the influence is sufficiently high, then it seems that (3,3) is a better option that (0,0). I'm moderately confident a hypothetical me which knew about causal models but hadn't thought about identity or intertemporal cooperation would use the same line of reasoning to cooperate.
Replies from: So8res↑ comment by So8res · 2014-09-27T01:07:48.976Z · LW(p) · GW(p)
In either case, it seems to me this is something that the physics module (i.e. what gives you P(O_j|do(A))) should compute, and only baked into the decision theory by the rules about what sort of causal graphs you think are likely.
The problem is the do(A) part: the do(.) function ignores logical acausal connections between nodes. That was the theme of this post.
If the copy is perfect, it seems unreasonable to me to not draw a causal arrow between my action and my copy's action, as I cannot justify the assumption that my action will be independent of my perfect copy's action.
I agree! If the copy is perfect, there is a connection. However, the connection is not a causal one.
Obviously you want to take the action that maximizes your expected utility, according to probability-weighted outcomes. The question is how you check the outcome that would happen if you took a given action.
Causal counterfactual reasoning prescribes evaluating counterfactuals by intervening on the graph using the do(.) function. This (roughly) involves identifying your action node A, ignoring the causal ancestors, overwriting the node with the function const a (where a is the action under consideration) and seeing what happens. This usually works fine, but there are some cases where this fails to correctly compute the outcomes (namely, where others are reasoning about the contents A, where their internal representations of A were not affected by your do(A=a)).
This is not fundamentally a problem of retrocausality, it's fundamentally a problem of not knowing how to construct good counterfactuals. What does it mean to consider that a deterministic algorithm returns something that it doesn't return? do(.) says that it means "imagine you were not you, but were instead const a while other people continue reasoning as if you were you". It would actually be really surprising if this worked out in situations where others have internal representations of the contents of A (which do(A=.) stomps all over).
You answered that you intuitively feel like you should draw an arrow between you and your clone in the above thought experiment. I agree! But constructing a graph like this (where things that are computed via the same process must have the same output) is actually not something that CDT does. This problem in particular was the motivation behind TDT (which uses a different function besides do(.) to construct counterfactuals that preserve the fact that identical computations will have identical outputs). It sounds like we probably have similar intuitions about decision theory, but perhaps different ideas about what the do(.) function is capable of?
↑ comment by Vaniver · 2014-09-27T03:56:09.948Z · LW(p) · GW(p)
This usually works fine, but there are some cases where this fails to correctly compute the outcomes (namely, where others are reasoning about the contents A, where their internal representations of A were not affected by your do(A=a)).
I still think this should be solved by the physics module.
For example, consider two cases. In case A, Ekman reads everything you've ever written on decision theory before September 26th, 2014, and then fills the boxes as if he were Omega, and then you choose whether to one-box or two-box. Ekman's a good psychologist, but his model of your mind is translucent to you at best- you think it's more likely than not that he'll guess correctly what you'll pick, but know that it's just mediated by what you've written that you can't change.
In case B, Ekman watches your face as you choose whether to press the one-box button or the two-box button without being able to see the buttons (or your finger), and then predicts your choice. Again, his model of your mind is translucent at best to you; probably he'll guess correctly, but you don't know what specifically he's basing his decision off of (and suppose that even if you did, you know that you don't have sufficient control over your features to prevent information from leaking).
It seems to me that the two cases deserve different responses- in case A, you don't think your current thoughts will impact Ekman's move, but in case B, you do. In a normal token trade, you don't think your current thoughts will impact your partner's move, but in a mirror token trade, you do. Those differences in belief are because of actual changes in the perceived causal features of the situation, which seems sensible to me.
That is, I think this is a failure of the process you're using to build causal maps, not the way you're navigating those causal maps once they're built. I keep coming back to the criterion "does a missing arrow imply independence?" because that's the primary criterion for building useful causal maps, and if you have 'logical nodes' like "the decision made by an agent with a template X" then it doesn't make sense to have a copy of that logical node elsewhere that's allowed to have a distinct value.
That is, I agree that this question is important:
What does it mean to consider that a deterministic algorithm returns something that it doesn't return?
But my answer to it is "don't try to intervene at a node unless your causal model was built under the assumption you could intervene at that node." The mirror token trade causal map you used in this post works if you intervene at 'template,' but I argue it doesn't work if you intervene at 'give?' unless there's an arrow that points from 'give?' to 'their decision.'
It sounds like we probably have similar intuitions about decision theory, but perhaps different ideas about what the do(.) function is capable of?
I think I see do(.) operator as less capable than you do; in cases where the physicality of our computation matters then we need to have arrows pointing out of the node where we intervene that we don't need when we can ignore the impacts of having to physically perform computations in reality. Furthermore, it seems to me that when we're at the level where how we physically process possibilities matters, 'decision theory' may not be a useful concept anymore.
Replies from: So8res↑ comment by So8res · 2014-09-27T23:23:51.485Z · LW(p) · GW(p)
Cool, it sounds like we mostly agree. For instance, I agree that once you set up the graph correctly, you can intervene do(.) style and get the Right Answer. The general thrust of these posts is that "setting up the graph correctly" involves drawing in lines / representing world-structure that is generally considered (by many) to be "non-causal".
Figuring out what graph to draw is indeed the hard part of the problem -- my point is merely that "graphs that represent the causal structure of the universe and only the causal structure of the universe" are not the right sort of graphs to draw, in the same way that a propensity theory of probability that only allows information to propagate causally is not a good way to reason about probabilities.
Figuring out what sort of graphs we do want to intervene on requires stepping beyond a purely causal decision theory.
↑ comment by private_messaging · 2014-09-26T18:10:27.953Z · LW(p) · GW(p)
Yeah, the existence of classification into 'future' and 'past' and 'future' not causing 'past', and what is exactly 'future', those are - ideally - a matter of the model of physics employed. Currently known physics already doesn't quite work like this - it's not just the future that can't cause the present, but anything outside the past lightcone.
All those decision theory discussions leave me with a strong impression that 'decision theory' is something which is applied almost solely to the folk physics. As an example of a formalized decision making process, we have AIXI, which doesn't really do what philosophers say either CDT or EDT does.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-26T18:50:43.058Z · LW(p) · GW(p)
Actually, I think AIXI is basically CDT-like, and I suspect that it would two-box on Newcomb's problem.
At a highly abstract level, the main difference between AIXI and a CDT agent is that AIXI has a generalized way of modeling physics (but it has a built-in assumption of forward causality), whereas the CDT agent needs you to tell it what the physics is in order to make a decision.
The optimality of the AIXI algorithm is predicated on viewing itself as a "black box" as far as its interactions with the environment are concerned, which is more or less what the CDT agent does when it makes a decision.
Replies from: V_V, private_messaging↑ comment by V_V · 2014-09-28T13:36:33.121Z · LW(p) · GW(p)
Actually, I think AIXI is basically CDT-like, and I suspect that it would two-box on Newcomb's problem.
AIXI is a machine learning (hyper-)algorithm, hence we can't expect it to perform better than a random coin toss on a one-shot problem.
If you repeatedly pose Newcomb's problem to an AIXI agent, it will quickly learn to one-box.
Trivially, AIXI doesn't model the problem acausal structure in any way. For AIXI, this is just a matter of setting a bit and getting a reward, and AIXI will easily figuring out that setting its decision bit to "one-box" yields an higher expected reward that setting it to "two-box".
In fact, you don't even need an AIXI agent to do that: any reinforcement learning toy agent will be able to do that.
↑ comment by lackofcheese · 2014-09-28T13:44:59.331Z · LW(p) · GW(p)
The problem you're discussing is not Newcomb's problem; it's a different problem that you've decided to apply the same name to.
It is a crucial part of the setup of Newcomb's problem that the agent is presented with significant evidence about the nature of the problem. This applies to AIXI as well; at the beginning of the problem AIXI needs to be presented with observations that give it very strong evidence about Omega and about the nature of the problem setup. From Wikipedia:
"By the time the game begins, and the player is called upon to choose which boxes to take, the prediction has already been made, and the contents of box B have already been determined. That is, box B contains either $0 or $1,000,000 before the game begins, and once the game begins even the Predictor is powerless to change the contents of the boxes. Before the game begins, the player is aware of all the rules of the game, including the two possible contents of box B, the fact that its contents are based on the Predictor's prediction, and knowledge of the Predictor's infallibility. The only information withheld from the player is what prediction the Predictor made, and thus what the contents of box B are."
It seems totally unreasonable to withhold information from AIXI that would be given to any other agent facing the Newcomb's problem scenario.
Replies from: V_V, Strange7↑ comment by V_V · 2014-09-28T14:39:27.867Z · LW(p) · GW(p)
That would require the AIXI agent to have been pretrained to understand English (or some language as expressive as English) and have some experience at solving problems given a verbal explanation of the rules.
In this scenario, the AIXI internal program ensemble concentrates its probability mass on programs which associate each pair of one English specification and one action to a predicted reward. Given the English specification, AIXI computes the expected reward for each action and outputs the action that maximizes the expected reward.
Note that in principle this can implement any computable decision theory. Which one it would choose depend on the agent history and the intrinsic bias of its UTM.
It can be CDT, EDT, UDT, or, more likely, some approximation of them that worked well for the agent so far.
↑ comment by lackofcheese · 2014-09-28T15:08:43.426Z · LW(p) · GW(p)
That would require the AIXI agent to have been pretrained to understand English (or some language as expressive as English) and have some experience at solving problems given a verbal explanation of the rules.
I don't think someone posing Newcomb's problem would be particularly interested in excuses like "but what if the agent only speaks French!?" Obviously as part of the setup of Newcomb's problem AIXI has to be provided with an epistemic background that is comparable to that of its intended target audience. This means it doesn't just have to be familiar with English, it has to be familiar with the real world, because Newcomb's problem takes place in the context of the real world (or something very much like it).
I think you're confusing two different scenarios:
- Someone training an AIXI agent to output problem solutions given problem specifications as inputs.
- Someone actually physically putting an AIXI agent into the scenario stipulated by Newcomb's problem.
The second one is Newcomb's problem; the first is the "what is the optimal strategy for Newcomb's problem?" problem.
It's the second one I'm arguing about in this thread, and it's the second one that people have in mind when they bring up Newcomb's problem.
Replies from: V_V↑ comment by V_V · 2014-09-28T15:37:18.348Z · LW(p) · GW(p)
Then AIXI ensemble will be dominated by programs which associate "real world" percepts and actions to predicted rewards.
The point is that there is no way, short of actually running the (physically impossible) experiment, that we can tell whether the behavior of this AIXI agent will be consistent with CDT, EDT, or something else entirely.
↑ comment by Strange7 · 2014-10-03T16:05:45.557Z · LW(p) · GW(p)
Would it be a valid instructional technique to give someone (particularly someone congenitally incapable of learning any other way) the opportunity to try out a few iterations of the 'game' Omega is offering, with clearly denominated but strategically worthless play money in place of the actual rewards?
Replies from: lackofcheese↑ comment by lackofcheese · 2014-10-04T04:49:22.622Z · LW(p) · GW(p)
The main issue with that is that Newcomb's problem is predicated on the assumption that you prefer getting a million dollars to getting a thousand dollars. For the play money iterations, that assumption would not hold.
The second issue with iterating Newcomb's more generally is that it gives the agent an opportunity to precommit to one-boxing. The problem is more interesting and more difficult if you face it without having had that opportunity.
Replies from: Strange7↑ comment by private_messaging · 2014-09-27T01:19:09.964Z · LW(p) · GW(p)
I'm not sure it really makes an assumption of causality, let alone a forward one. (Apart from the most rudimentary notion that actions determine future input) . Facing an environment with two manipulators seemingly controlled by it, it wont have a hang up over assuming that it equally controls both. Indeed it has no reason to privilege one. Facing an environment with particular patterns under its control, it will assume it controls instances of said pattern. It doesn't view itself as anything at all. It has inputs and outputs, it builds a model of whats inbetween from the experience, if there are two idenical instances of it, it learns a weird model.
Edit: and what it would do in Newcombs, itll one box some and two box some and learn to one box. Or at least, the variation that values information will.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-27T02:53:14.858Z · LW(p) · GW(p)
First of all, for any decision problem it's an implicit assumption that you are given sufficient information to have a very high degree of certainty about the circumstances of the problem. If presented with the appropriate evidence, AIXI should be convinced of this. Indeed, given its nature as an "optimal sequence-predictor", it should take far less evidence to convince AIXI than it would take to convince a human. You are correct that if it was presented Newcomb's problem repeatedly then in the long run it should eventually try one-boxing, but if it's highly convinced it could take a very long time before it's worth it for AIXI to try it.
Now, as for an assumption of causality, the model that AIXI has of the agent/environment interaction is based on an assumption that both of them are chronological Turing machines---see the description here. I'm reasonably sure this constitutes an assumption of forward causality.
Similarly, what AIXI would do in Newcomb's problem depends very specifically on its notion of what exactly it can control. Just as a CDT agent does, AIXI should understand that whether or not the opaque box contains a million dollars is already predetermined; in fact, given that AIXI is a universal sequence predictor it should be relatively trivial for it to work out whether the box is empty or full. Given that, AIXI should calculate that it is optimal for it to two-box, so it will two-box and get $1000. For AIXI, Newcomb's problem should essentially boil down to Agent Simulates Predictor.
Ultimately, the AIXI agent makes the same mistake that CDT makes - it fails to understand that its actions are ultimately controlled not by the agent itself, but by the output of the abstract AIXI equation, which is a mathematical construct that is accessible not just to AIXI, but the rest of the world as well. The design of the AIXI algorithm is inherently flawed because it fails to recognize this; ultimately this is the exact same error that CDT makes.
Granted, this doesn't answer the interesting question of "what does AIXI do if it predicts Newcomb's problem in advance?", because before Omega's prediction AIXI has an opportunity to causally affect that prediction.
Replies from: private_messaging↑ comment by private_messaging · 2014-09-27T09:01:06.180Z · LW(p) · GW(p)
I'm reasonably sure this constitutes an assumption of forward causality.
What it doesn't do, is make an assumption that there must be physical sequence of dominoes falling on each other from one singular instance of it, to the effect.
AIXI should understand that whether or not the opaque box contains a million dollars is already predetermined; in fact, given that AIXI is a universal sequence predictor it should be relatively trivial for it to work out whether the box is empty or full.
Not at all. It can't self predict. We assume that the predictor actually runs AIXI equation.
Ultimately, it doesn't know what's in the boxes, and it doesn't assume that what's in the boxes is already well defined (there's certainly codes where it is not), and it can learn it controls contents of the box in precisely the same manner as it has to learn that it controls it's own robot arm or what ever is it that it controls. Ultimately it can do exactly same output->predictor->box contents as it does for output->motor controller->robot arm. Indeed if you don't let it observe 'its own' robot arm, and only let it observe the box, that's what it controls. It has no more understanding that this box labelled 'AIXI' is the output of what it controls, than it has about the predictor's output.
It is utterly lacking this primate confusion over something 'else' being the predictor. The predictor is representable in only 1 way, and that's an extra counter factual insertion of actions into the model.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-27T12:24:09.131Z · LW(p) · GW(p)
You need to notice and justify changing the subject.
If I was to follow your line of reasoning, then CDT also one-boxes on Newcomb's problem, because CDT can also just believe that its action causes the prediction. That goes against the whole point of the Newcomb setup - the idea is that the agent is given sufficient evidence to conclude, with a high degree of confidence, that the contents of the boxes are already determined before it chooses whether to one-box or two-box.
AIXI doesn't assume that the causality is made up of a "physical sequence of dominoes falling", but that doesn't really matter. We've stated as part of the problem setup that Newcomb's problem does, in fact, work that way, and a setup where Omega changes the contents of the boxes in advance, rather than doing it after the fact via some kind of magic, is obviously far simpler, and hence far more probable given a Solomonoff prior.
As for the predictor, it doesn't need to run the full AIXI equation in order to make a good prediction. It just needs to conclude that due to the evidence AIXI will assign high probability to the obviously simpler, non-magical explanation, and hence AIXI will conclude that the contents of the box are predetermined, and hence AIXI will two-box.
There is no need for Omega to actually compute the (uncomputable) AIXI equation. It could simply take the simple chain of reasoning that I've outlined above. Moreover, it would be trivially easy for AIXI to follow Omega's chain of reasoning, and hence predict (correctly) that the box is, in fact, empty, and walk away with only $1000.
Replies from: private_messaging↑ comment by private_messaging · 2014-09-27T13:31:15.833Z · LW(p) · GW(p)
If I was to follow your line of reasoning, then CDT also one-boxes on Newcomb's problem, because CDT can also just believe that its action causes the prediction. That goes against the whole point of the Newcomb setup - the idea is that the agent is given sufficient evidence to conclude, with a high degree of confidence, that the contents of the boxes are already determined before it chooses whether to one-box or two-box.
We've stated as part of the problem setup that Newcomb's problem does, in fact, work that way, and a setup where Omega changes the contents of the boxes in advance, rather than doing it after the fact via some kind of magic, is obviously far simpler, and hence far more probable given a Solomonoff prior.
Again, folk physics. You make your action available to your world model at the time t where t is when you take that action. You propagate the difference your action makes (to avoid re-evaluating everything). So you need back in time magic.
Let's look at the equation here: http://www.hutter1.net/ai/uaibook.htm . You have a world model that starts at some arbitrary point well in the past (e.g. big bang), which proceeds from that past into the present, and which takes the list of past actions and the current potential action as an input. Action which is available to the model of the world since it's very beginning. When evaluating potential action 'take 1 box', the model has money in the first box, when evaluating potential action 'take 2 boxes', the model doesn't have money in the first box, and it doesn't do any fancy reasoning about the relation between those models and how those models can and can't differ. It just doesn't perform this time saving optimization of 'let first box content be x, if i take 2 boxes, i get x+1000 > x'.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-27T14:48:40.523Z · LW(p) · GW(p)
Why do you need "back in time magic", exactly? That's a strictly more complex world model than the non-back-in-time-magic version. If Solomonoff induction results in a belief in the existence of back-in-time magic when what's happening is just perfectly normal physics, this would be a massive failure in Solomonoff induction itself. Fortunately, no such thing occurs; Solomonoff induction works just fine.
I'm arguing that, because the box already either contains the million or does not, AIXI will (given a reasonable but not particularly large amount of evidence) massively downweight models that do not correctly describe this aspect of reality. It's not doing any kind of "fancy reasoning" or "time-saving optimization", it's simply doing Solomonoff induction, and dong it correctly.
Replies from: private_messaging↑ comment by private_messaging · 2014-09-27T23:42:07.260Z · LW(p) · GW(p)
Then it can, for experiment' sake, take 2 boxes if theres something in the first box, and take 1 otherwise. The box contents are supposedly a result of computing AIXI and as such are not computable; or for a bounded approximation, not approximable. You're breaking your own hypothetical and replacing the predictor (which would have to perform hypercomputation) with something that incidentally coincides. AIXI responds appropriately.
edit: to stpop talking to one another: AIXI does not know if there's money in the first box. The TM where AIXI is 1boxing is an entireliy separate TM from one where AIXI is 2boxing. AIXI does not in any way represent any facts about the relation between those models, such as 'both have same thing in the first box'.
edit2: and , it is absoloutely correct to take 2 boxes if you don't know anything about the predictor. AIXI represents the predictor as the surviving TMs using the choice action value as omega's action to put/not put money in the box. AIXI does not preferentially self identify with the AIXI formula inside the robot that picks boxes, over AIXI formula inside 'omega'.
Replies from: nshepperd↑ comment by nshepperd · 2014-09-28T01:19:43.102Z · LW(p) · GW(p)
If you have to perform hypercomputation to even approximately guess what AIXI would do, then this conversation would seem like a waste of time/
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-28T02:21:17.701Z · LW(p) · GW(p)
Precisely.
Besides that, if you can't even make a reasoned guess as to what AIXI would do in a given situation, then AIXI itself is pretty useless even as a theoretical concept, isn't it?
Omega doesn't have to actually evaluate the AIXI formula exactly; it can simply reason logically to work out what AIXI will do without performing those calculations. Sure, AIXI itself can't take those shortcuts, but Omega most definitely can. As such, there is no need for Omega to perform hypercomputation, because it's pretty easy to establish AIXI's actions to a very high degree of accuracy using the arguments I've put forth above. Omega doesn't have to be a "perfect predictor" at all.
In this case, AIXI is quite easily able to predict the chain of reasoning Omega takes, and so it can easily work out what the contents of the box are. This straightforwardly results in AIXI two-boxing, and because it's so straightforward it's quite easy for Omega to predict this, and so Omega only fills one box.
The problem with AIXI is not that it preferentially self-identifies with the AIXI formula inside the robot that picks boxes vs the "AIXI formula inside Omega". The problem with AIXI is that it doesn't self-identify with the AIXI formula at all.
One could argue that the simple predictor is "punishing" AIXI for being AIXI, but this is really just the same thing as the CDT agent who thinks Omega is punishing them for being "rational". The point of this example is that if the AIXI algorithm were to output "one-box" instead of "two-box" for Newcomb's problem, then it would get a million dollars. Instead, it only gets $1000.
Replies from: nshepperd, private_messaging↑ comment by nshepperd · 2014-09-28T13:05:28.214Z · LW(p) · GW(p)
Well, to make an object-level observation, it's not entirely clear to me what it means for AIXI to occupy the epistemic state required by the problem definition. The "hypotheses" of AIXI are general sequence predictor programs rather than anything particularly realist. So while present program state can only depend on AIXI's past actions, and not future actions, nothing stops a hypothesis from including a "thunk" that is only evaluated when the program receives the input describing AIXI's actual action. In fact, as long as no observations or rewards depend on the missing information, there's no need to even represent the "actual" contents of the boxes. Whether that epistemic state falls within the problem's precondition seems like a matter of definition.
If you restrict AIXI's hypothesis state to explicit physics simulations (with the hypercomputing part of AIXI treated as a black box, and decision outputs monkeypatched into a simulated control wire), then your argument does follow, I think; the whole issue of Omega's prediction is just seen as some "physics stuff" happening, where Omega "does some stuff" and then fills the boxes, and AIXI then knows what's in the boxes and it's a simple decision to take both boxes.
But, if the more complicated "lazily-evaluating" sort of hypotheses gain much measure, then AIXI's decision starts actually depending on its simulation of Omega, and then the above argument doesn't really work and trying to figure out what actually happens could require actual simulation of AIXI or at least examination of the specific hypothesis space AIXI is working in.
So I suppose there's a caveat to my post above, which is that if AIXI is simulating you, then it's not necessarily so easy to "approximately guess" what AIXI would do (since it might depend on your approximate guess...). In that way, having logically-omniscient AIXI play kind of breaks the Newcomb's Paradox game, since it's not so easy to make Omega the "perfect predictor" he needs to be, and you maybe need to think about how Omega actually works.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-28T13:35:12.079Z · LW(p) · GW(p)
I think it's implicit in the Newcomb's problem scenario that it takes place within the constraints of the universe as we know it. Obviously we have to make an exception for AIXI itself, but I don't see a reason to make any further exceptions after that point. Additionally, it is explicitly stated in the problem setup that the contents of the box are supposed to be predetermined, and that the agent is made aware of this aspect of the setup. As far as the epistemic states are concerned, this would imply that AIXI has been presented with a number of prior observations that provide very strong evidential support for this fact.
I agree that AIXI's universe programs are general Turing machines rather than explicit physics simulations, but I don't think that's a particularly big problem. Unless we're talking about a particularly immature AIXI agent, it should already be aware of the obvious physics-like nature of the real world; it seems to me that the majority of AIXI's probability mass should be occupied by physics-like Turing machines rather than by thunking. Why would AIXI come up with world programs that involve Omega making money magically appear or disappear after being presented significant evidence to the contrary?
I can agree that in the general case it would be rather difficult indeed to predict AIXI, but in many specific instances I think it's rather straightforward. In particular, I think Newcomb's problem is one of those cases.
I guess that in general Omega could be extremely complex, but unless there is a reason Omega needs to be that complex, isn't it much more sensible to interpret the problem in a way that is more likely to comport with our knowledge of reality? Insofar as there exist simpler explanations for Omega's predictive power, those simpler explanations should be preferred.
I guess you could say that AIXI itself cannot exist in our reality and so we need to reinterpret the problem in that context, but that seems like a flawed approach to me. After all, the whole point of AIXI is to reason about its performance relative to other agents, so I don't think it makes sense to posit a different problem setup for AIXI than we would for any other agent.
Replies from: V_V, nshepperd↑ comment by V_V · 2014-09-28T16:12:34.715Z · LW(p) · GW(p)
If AIXI has been presented with sufficient evidence that the Newcomb's problem works as advertised, then it must be assigning most of its model probability mass to programs where the content of the box, however internally represented, is correlated to the next decision.
Such programs exist in the model ensemble, hence the question is how much probability mass does AIXI assign to them. If it not enough to dominate its choice, then by definition AIXI has not been presented with enough evidence.
↑ comment by lackofcheese · 2014-09-28T16:45:53.603Z · LW(p) · GW(p)
What do you mean by "programs where the content of the box, however internally represented, is correlated to the next decision"? Do you mean world programs that output $1,000,000 when the input is "one-box" and output $1000 when the input is "two-box"? That seems to contradict the setup of Newcomb's to me; in order for Newcomb's problem to work, the content of the box has to be correlated to the actual next decision, not to counterfactual next decisions that don't actually occur.
As such, as far as I can see it's important for AIXI's probability mass to focus down to models where the box already contains a million dollars and/or models where the box is already empty, rather than models in which the contents of the box are determined by the input to the world program at the moment AIXI makes its decision.
Replies from: V_V↑ comment by V_V · 2014-10-01T13:12:14.270Z · LW(p) · GW(p)
AIXI world programs have no inputs, they just run and produce sequences of triples in the form: (action, percept, reward).
So, let's say AIXI has been just subjected to Newcomb's problem. Assuming that the decision variable is always binary ("OneBox" vs "TwoBox"), of all the programs which produce a sequence consistent with the observed history, we distinguish five classes of programs, depending on the next triple they produce:
1: ("OneBox", "Opaque box contains $1,000,000", 1,000,000)
2: ("TwoBox", "Opaque box is empty", 1,000)
3: ("OneBox", "Opaque box is empty", 0)
4: ("TwoBox", "Opaque box contains $1,000,000", 1,001,000)
5: Anything else (eg. ("OneBox", "A pink elephant appears", 42)).
Class 5 should have a vanishing probability, since we assume that the agent already knows physics.
Therefore:
E("OneBox") = (1,000,000 p(class1) + 0 p(class3)) / (p(class1) + p(class3))
E("TwoBox") = (1,000 p(class2) + 1,001,000 p(class4)) / (p(class2) + p(class4))
Classes 1 and 2 are consistent with the setup of Newcomb's problem, while classes 3 and 4 aren't.
Hence I would say that if AIXI has been presented with enough evidence to believe that it is facing Newcomb's problem, then by definition of "enough evidence", p(class1) >> p(class3) and p(class2) >> p(class4), implying that AIXI will OneBox.
EDIT: math.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-10-01T13:38:31.011Z · LW(p) · GW(p)
AIXI world programs have no inputs, they just run and produce sequences of triples in the form: (action, percept, reward).
No, that isn't true. See, for example, page 7 of this article. The environments (q) accept inputs from the agent and output the agent's percepts.
As such (as per my discussion with private_messaging), there are only three relevant classes of world programs:
(1) Opaque box contains $1,000,000
(2) Opaque box is empty
(3) Contents of the box are determined by my action input
For any and all such environment programs that are consistent with AIXI's observations to date, AIXI will evaluate the reward for both the OneBox and TwoBox actions. As long as classes (1) and (2) win out over class (3), which they should due to being simpler, AIXI will determine that the E(TwoBox) > E(OneBox) and therefore AIXI will TwoBox. In fact, as long as AIXI is smart enough to predict Omega's reasoning, world programs of type (2) should win out over type (1) as well, and so AIXI will already be pretty sure that the opaque box is empty when it two-boxes.
Replies from: V_V↑ comment by V_V · 2014-10-01T16:03:43.524Z · LW(p) · GW(p)
The environments (q) accept inputs from the agent and output the agent's percepts.
Yes, but the programs that AIXI maintains internally in its model ensemble are defined as input-less programs that generate all the possible histories.
AIXI filters them for the one observed history and then evaluates the expected (discounted) reward over the future histories, for each possible choice of its next action.
Anyway, that's a technical detail.
As long as classes (1) and (2) win out over class (3), which they should due to being simpler
How can they be simpler, given that you have explained to AIXI what Newcomb's problem is and provided it with enough evidence so that it really believes that it is going to face it?
Maybe Newcomb's problem is simply inconceivable to AIXI, in a way that no amount of evidence can ever lead it to expect that the content of the box, and thus the reward, is correlated to its action.
That's a possibility, but I find it not very plausible: AIXI world programs contain embeddings of all human minds, and all super-human computable AIs. If we assume that the agent is experienced, world programs embedding these very very smart AIs will get most of probability mass, since they are very good sequence predictors. So if a human can understand Newcomb's problem, I think that a super-human AI would understand it as well.
Anyway, if we stipulate that it is indeed possible to provide AIXI with enough evidence that it is facing Newcomb's problem, then it seems to me that it will OneBox.
Replies from: lackofcheese, lackofcheese↑ comment by lackofcheese · 2014-10-02T00:38:02.325Z · LW(p) · GW(p)
Maybe Newcomb's problem is simply inconceivable to AIXI, in a way that no amount of evidence can ever lead it to expect that the content of the box, and thus the reward, is correlated to its action.
AIXI does recognise this correlation; it two-boxes and with a reasonable amount of evidence it also believes (correctly) that Omega predicted it would two-box.
That's a possibility, but I find it not very plausible: AIXI world programs contain embeddings of all human minds, and all super-human computable AIs. If we assume that the agent is experienced, world programs embedding these very very smart AIs will get most of probability mass, since they are very good sequence predictors. So if a human can understand Newcomb's problem, I think that a super-human AI would understand it as well.
The problem is that AIXI cannot recognise the kinds of models in which AIXI's own action and Omega's prediction of its action have a common cause (i.e. the AIXI equation). A better agent would be capable of recognising that dependency.
If you always exclude certain kinds of models then it doesn't matter how smart you are, some explanations are simply never going to occur to you.
Replies from: V_V↑ comment by V_V · 2014-10-03T09:40:17.484Z · LW(p) · GW(p)
If you always exclude certain kinds of models then it doesn't matter how smart you are, some explanations are simply never going to occur to you.
Actually, these models exist in AIXI world program ensemble. In order to support your point, you have to argue that they are more complex than models which make an incorrect prediction, no matter how much evidence for Newcomb's problem AIXI has been presented with.
↑ comment by lackofcheese · 2014-10-01T23:57:46.989Z · LW(p) · GW(p)
Yes, but the programs that AIXI maintains internally in its model ensemble are defined as input-less programs that generate all the possible histories.
Please clarify this and/or give a reference. Every time I've seen the equation AIXI's actions are inputs to the environment program.
How can they be simpler, given that you have explained to AIXI what Newcomb's problem is and provided it with enough evidence so that it really believes that it is going to face it?
The point of Newcomb's problem is that the contents of the box are already predetermined; it's stipulated that as part of the problem setup you are given enough evidence of this. In general, any explanation that involves AIXI's action directly affecting the contents of the box will be more complex because it bypasses the physics-like explanation that AIXI would have for everything else.
When I am facing Newcomb's problem I don't believe that the box magically changes contents as the result of my action---that would be stupid. I believe that the box already has the million dollars because I'm predictably a one-boxer, and then I one-box.
Similarly, if AIXI is facing Newcomb's then it should, without a particularly large amount of evidence, also narrow its environment programs down to ones that already either contains the million, and ones that already do not.
EDIT: Wait, perhaps we agree re. the environment programs.
AIXI filters them for the one observed history and then evaluates the expected (discounted) reward over the future histories, for each possible choice of its next action.
Yes, for each possible choice. As such, if AIXI has an environment program "q" in which Omega already predicted one-boxing and put the million dollars in, AIXI will check the outcome of OneBox as well as the outcome of TwoBox with that same "q".
Replies from: V_V↑ comment by V_V · 2014-10-03T10:21:42.526Z · LW(p) · GW(p)
Please clarify this and/or give a reference. Every time I've seen the equation AIXI's actions are inputs to the environment program.
Eq 22 in the paper you linked, trace the definitions back to eq. 16, which describes Solomonoff induction.
It uses input-less programs to obtain the joint probability distribution, then it divides it by the marginal distribution to obtain the conditional probability distribution it needs.
(Anyway, Hutter's original papers are somewhat difficult to read due to their heavy notation, I find Shane Legg's PhD thesis more readable.)
The point of Newcomb's problem is that the contents of the box are already predetermined; it's stipulated that as part of the problem setup you are given enough evidence of this. In general, any explanation that involves AIXI's action directly affecting the contents of the box will be more complex because it bypasses the physics-like explanation that AIXI would have for everything else.
If you tell AIXI: "Look, the transparent box contains $1,000 and the opaque box may contain $0 or $1,000,000. Do you want to take the content only of the opaque box or both?", then AIXI will two-box, just as you would.
Clearly the scenario where there is no Omega and the content of the opaque box is independent on your action is simpler than Newcomb's problem.
But if you convince AIXI that it's actually facing Newcomb's problem, then its surviving world-programs must model the action of Omega somewhere in their "physics modules".
The simplest way of doing that is probably to assume that there is some physical variable which determines AIXI next action (remember, the world programs predict actions as well as the inputs), and Omega can observe it and use it to set the content of the opaque box. Or maybe they can assume that Omega has a time machine or something.
Different programs in the ensemble will model Omega in a different way, but the point is that in order to be epistemically correct, the probability mass of programs that model Omega must be greater than the probability mass of programs that don't.
↑ comment by lackofcheese · 2014-10-03T14:06:59.688Z · LW(p) · GW(p)
Eq 22 in the paper you linked, trace the definitions back to eq. 16, which describes Solomonoff induction. It uses input-less programs to obtain the joint probability distribution, then it divides it by the marginal distribution to obtain the conditional probability distribution it needs.
Nope, the environment q is a chronological program; it takes AIXI's action sequence and outputs an observation sequence, with the restriction that observations cannot be dependent upon future actions.
Basically, it is assumed that the universal Turing machine U is fed both the environment program q, and AIXI's action sequence y, and outputs AIXI's observation sequence x by running the program q with input y. Quoting from the paper I linked:
"Reversely, if q already is a binary string we define q(y):=U(q,y)"
In the paper I linked, see Eq. 21:%20=%20\sum_{q:q(y_{1:k})=x_{1:k}}2%5E{-l(q)})
and the the term ) from Eq. 22.
In other words, any program q that matches AIXI's observations to date when given AIXI's actions to date will be part of the ensemble. In order to evaluate different future action sequences, AIXI then evaluates the different future actions it could take by feeding them to its program ensemble, and summing over different possible future rewards conditional on the environments that output those rewards.
If you tell AIXI: "Look, the transparent box contains $1,000 and the opaque box may contain $0 or $1,000,000. Do you want to take the content only of the opaque box or both?", then AIXI will two-box, just as you would. Clearly the scenario where there is no Omega and the content of the opaque box is independent on your action is simpler than Newcomb's problem.
The CDT agent can correctly argue that Omega already left the million dollars out of the box when the CDT agent was presented the choice, but that doesn't mean that it's correct to be a CDT agent. My argument is that AIXI suffers from the same flaw, and so a different algorithm is needed.
But if you convince AIXI that it's actually facing Newcomb's problem, then its surviving world-programs must model the action of Omega somewhere in their "physics modules".
Correct. My point is that AIXI's surviving world-programs boil down to "Omega predicted I would two-box, and didn't put the million dollars in", but it's the fault of the AIXI algorithm that this happens.
The simplest way of doing that is probably to assume that there is some physical variable which determines AIXI next action (remember, the world programs predict actions as well as the inputs), and Omega can observe it and use it to set the content of the opaque box. Or maybe they can assume that Omega has a time machine or something.
As per the AIXI equations, this is incorrect. AIXI cannot recognize the presence of a physical variable determining its next action because for any environment program AIXI's evaluation stage is always going to try both the OneBox and TwoBox actions. Given the three classes of programs above, the only way AIXI can justify one-boxing is if the class (3) programs, in which its action somehow causes the contents of the box, win out.
Replies from: V_V↑ comment by V_V · 2014-10-03T16:55:40.049Z · LW(p) · GW(p)
"Reversely, if q already is a binary string we define q(y):=U(q,y)"
Ok, missed that. I don't think it matters to the rest of the argument, though.
As per the AIXI equations, this is incorrect. AIXI cannot recognize the presence of a physical variable determining its next action because for any environment program AIXI's evaluation stage is always going to try both the OneBox and TwoBox actions. Given the three classes of programs above, the only way AIXI can justify one-boxing is if the class (3) programs, in which its action somehow causes the contents of the box, win out.
An environment program can just assume a value for the physical variable and then abort by failing to halt if the next action doesn't match it.
Or it can assume that the physical simulation branches at time t0, when Omega prepares the box, simulate each branch it until t < t1, when the next AIXI action occurs, and then kill off the branch corresponding to the wrong action.
Or, as it has already been proposed by somebody else, it could internally represent the physical world as a set of constraints and then run a constraint solver on it, without the need of performing a step-by-step chronological simulation.
So it seems that there are plenty of environment programs that can represent the action of Omega without assuming that it violates the known laws of physics. But even if it had to, what is the problem? AIXI doesn't assume that the laws of physics forbid retro-causality.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-10-04T04:59:31.139Z · LW(p) · GW(p)
An environment program can just assume a value for the physical variable and then abort by failing to halt if the next action doesn't match it.
Why would AIXI come up with something like that? Any such program is clearly more complex than one that does the same thing but doesn't fail to halt.
Or it can assume that the physical simulation branches at time t0, when Omega prepares the box, simulate each branch it until t < t1, when the next AIXI action occurs, and then kill off the branch corresponding to the wrong action.
Once again, possible but unnecessarily complex to explain AIXI's observations.
Or, as it has already been proposed by somebody else, it could internally represent the physical world as a set of constraints and then run a constraint solver on it, without the need of performing a step-by-step chronological simulation.
Sure, but the point is that those constraints would still be physics-like in nature. Omega's prediction accuracy is much better explained by constraints that are physics-like rather than an extra constraint that says "Omega is always right". if you assume a constraint of the latter kind, you are still forced to explain all the other aspects of Omega---things like Omega walking, Omega speaking, and Omega thinking, or more generally Omega doing all those things that ze does. Also, if Omega isn't always right, but is instead right only 99% of the time, then the constraint-based approach is penalized further.
So it seems that there are plenty of environment programs that can represent the action of Omega without assuming that it violates the known laws of physics. But even if it had to, what is the problem? AIXI doesn't assume that the laws of physics forbid retro-causality.
It doesn't assume that, no, but because it assumes that its observations cannot be affected by its future actions AIXI is still very much restricted in that regard.
My point is a simple one: If AIXI is going to end-up one-boxing, the simplest model of Omega will be one that used its prediction method and already predicted that AIXI would one-box. If AIXI is going to end up two-boxing, the simplest model of Omega will be one that used its prediction method and already predicted that AIXI would two-box.
However, if Omega predicted one-boxing and AIXI realized that this was the case, AIXI would still evaluate that the two-boxing action results in AIXI getting more money than the one-boxing action, which means that AIXI would two-box. As long as Omega is capable of reaching this relatively simple logical conclusion, Omega thereby knows that a prediction of one-boxing would turn out to be wrong, and hence Omega should predict two-boxing; this will, of course, turn out to be correct.
The kinds of models you're suggesting, with branching etc. are significantly more complex and don't really serve to explain anything.
Replies from: V_V↑ comment by V_V · 2014-10-04T09:36:42.005Z · LW(p) · GW(p)
It doesn't assume that, no, but because it assumes that its observations cannot be affected by its future actions AIXI is still very much restricted in that regards.
But this doesn't matter for Newcomb's problem, since AIXI observes the content of the opaque box only after it has made its decision.
However, if Omega predicted one-boxing and AIXI realized that this was the case, AIXI would still evaluate that the two-boxing action results in AIXI getting more money than the one-boxing action, which means that AIXI would two-box.
Which means that the epistemic model was flawed with high probability.
You are insisting that the flawed model is simpler that the correct one. This may be true for certain states of evidence where AIXI is not convinced that Omega works as advertised, but you haven't shown that this is true for all possible states of evidence.
The kinds of models you're suggesting, with branching etc. are significantly more complex and don't really serve to explain anything.
They may be more complex only up to a small constant overhead (how many bits does it take to include a condition "if OmegaPrediction != NextAction then loop forever"?), therefore, a constant amount of evidence should be sufficient to select them.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-10-04T10:24:11.088Z · LW(p) · GW(p)
Which means that the epistemic model was flawed with high probability. You are insisting that the flawed model is simpler that the correct one. This may be true for certain states of evidence where AIXI is not convinced that Omega works as advertised, but you haven't shown that this is true for all possible states of evidence.
Yes, AIXI's epistemic model will be flawed. This is necessarily true because AIXI is not capable of coming up with the true model of Newcomb's problem, which is one in which its action and Omega's prediction of its action share a common cause. Since AIXI isn't capable of having a self-model, the only way it could possibly replicate the behaviour of the true model is by inserting retrocausality and/or magic into its environment.
They may be more complex only up to a small constant overhead (how many bits does it take to include a condition "if OmegaPrediction != NextAction then loop forever"?), therefore, a constant amount of evidence should be sufficient to select them.
I'm not even sure AIXI is capable of considering programs of this kind, but even if it is, what kind of evidence can AIXI have received that would justify the condition "if OmegaPrediction != NextAction then loop forever"? What evidence would justify such a model over a strictly simpler version without that condition?
Essentially, you're arguing that rather than coming up with a correct model of its environment (e.g. one in which Omega makes a prediction on the basis of the AIXI equation), AIXI will somehow make up for its inability to self-model by coming up with an inaccurate and obviously false retrocausal/magical model of its environment instead.
However, I don't see why this would be the case. It's quite clear that either Omega has already predicted one-boxing, or Omega has already predicted two-boxing. At the very least, the evidence should narrow things down to models of either kind, although I think that AIXI should easily have sufficient evidence to work out which of them is actually true (that being the two-boxing one).
↑ comment by nshepperd · 2014-09-28T15:05:34.060Z · LW(p) · GW(p)
I agree that AIXI's universe programs are general Turing machines rather than explicit physics simulations, but I don't think that's a particularly big problem. Unless we're talking about a particularly immature AIXI agent, it should already be aware of the obvious physics-like nature of the real world; it seems to me that the majority of AIXI's probability mass should be occupied by physics-like Turing machines rather than by thunking. Why would AIXI come up with world programs that involve Omega making money magically appear or disappear after being presented significant evidence to the contrary?
The problem is not "programs that make money magically (dis)appear for the box after the fact" but rather programs that don't explicitly represent the presence or nonpresence of money at all until it is known. For example, a constraint solver that seeks a proof of AIXI's observations when they are called for (using a logic that expresses normal physics). This gives all the right answers, and is fairly simple but does allow the content of the box to be controlled by the decision.
Replies from: lackofcheese, lackofcheese↑ comment by lackofcheese · 2014-09-29T02:35:26.757Z · LW(p) · GW(p)
Such models would generally not offer good explanations for why Omega is so good at predicting all those other agents who aren't AIXI, and would be penalized for this. On the other hand, any model that explains Omega's general predictive power would be made more complex by adding a special case just for AIXI.
↑ comment by lackofcheese · 2014-09-28T15:11:58.502Z · LW(p) · GW(p)
I don't understand what you mean by "a constraint solver that seeks a proof of AIXI's observations when they are called for." Can you explain it further?
Replies from: nshepperd, lackofcheese↑ comment by nshepperd · 2014-09-29T04:03:19.460Z · LW(p) · GW(p)
A proof system that starts with some axioms describing the physical world (excluding the AIXI machine itself), and when run with input a_1 .. a_m being AIXI's actions so far, plugs them in as axioms about AIXI's control wires, and attempts to prove a statement of the form 'AIXI's input wire observes a 1 at time t' or 'AIXI's input wire observes a 0 at time t'. And returns the first answer it finds.
↑ comment by lackofcheese · 2014-09-28T15:34:39.530Z · LW(p) · GW(p)
Alternatively, what about a version of Newcomb's problem where the predictor's source code is shown to AIXI before it makes its decision?
Replies from: V_V↑ comment by V_V · 2014-09-28T16:07:07.721Z · LW(p) · GW(p)
What would the source code of an Omega able to predict an AIXI look like?
Replies from: Cyan, lackofcheese↑ comment by Cyan · 2014-10-01T12:21:02.330Z · LW(p) · GW(p)
It won't have source code per se, but one can posit the existence of a halting oracle without generating an inconsistency.
↑ comment by lackofcheese · 2014-09-28T16:27:17.694Z · LW(p) · GW(p)
It takes, as input, a description of the agent it's predicting; typically source code, but in the case of AIXI, it gets the AIXI equation and a sequence of prior observations for AIXI.
As for what it does, it spends some period of time (maybe a very long one) on whatever kind of deductive and/or inductive reasoning it chooses to do in order to establish with a reasonable level of confidence what the agent it's trying to predict will do.
Yes, AIXI being uncomputable means that Omega can't simply run the equation for itself, but there is no need for a perfect prediction here. On the whole, it just needs to be able to come up with a well-reasoned argument for why AIXI will take a particular action, or perhaps run an approximation of AIXI for a while. Moreover, anyone in this thread arguing for either one-boxing or two-boxing has already implicitly agreed with this assumption.
Replies from: V_V, nshepperd↑ comment by V_V · 2014-10-01T12:12:05.234Z · LW(p) · GW(p)
Yes, AIXI being uncomputable means that Omega can't simply run the equation for itself, but there is no need for a perfect prediction here. On the whole, it just needs to be able to come up with a well-reasoned argument for why AIXI will take a particular action, or perhaps run an approximation of AIXI for a while.
This opens up the possibility that AIXI figures out that Omega is going to mispredict it, which would make TwoBoxing the best decision.
Moreover, anyone in this thread arguing for either one-boxing or two-boxing has already implicitly agreed with this assumption.
I think it is generally assumed that, even if Omega is not a perfect predictor, the agent can't outsmart it and predict its errors. But if Omega is computable and the agent is uncomputable, this doesn't necessarily hold true.
↑ comment by nshepperd · 2014-09-29T04:30:39.622Z · LW(p) · GW(p)
Moreover, anyone in this thread arguing for either one-boxing or two-boxing has already implicitly agreed with this assumption.
I'm not so sure this is true now. People in this thread arguing that AIXI does something at least have the advantage that AIXI's decision is not going to depend on how they do the arguing. The fact that AIXI can simulate Omega with perfect fidelity (assuming Omega is not also a hypercomputer) and will make its decision based on the simulation seems like it might impact Omega's ability to make a good prediction.
↑ comment by private_messaging · 2014-09-28T08:52:28.819Z · LW(p) · GW(p)
Omega doesn't have to be a "perfect predictor" at all.
So you don't predict anything, just put nothing in the first box, and advertise this fact clearly enough for the agent making the choice.
Newcomb's original problem did not include the clause 'by the way, there's nothing in the first box'. You're adding that clause by making additional assertions regarding what AIXI knows about "Omega".
In this case, AIXI is quite easily able to predict the chain of reasoning Omega takes
There's a truly crazy amount of misunderstandings with regards to what Solomonoff Induction can learn about the world, on LW.
Let's say you run AIXI, letting it oversee some gigabytes of webcam data, at your location. You think AIXI can match the exact location of raindrops on your roof, hours in advance? You think AIXI is going to know all about me - the DNA I have, how may I construct a predictor, etc?
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-28T09:52:08.815Z · LW(p) · GW(p)
So you don't predict anything, just put nothing in the first box, and advertise this fact clearly enough for the agent making the choice.
A version of the problem in which Omega is predictable is hardly the same thing as a version of the problem in which the first box is always empty. Other algorithms get the million dollars; it's just that AIXI does not. Moreover, AIXI is not being punished simply for being AIXI; AIXI not getting the million dollars is a direct consequence of the output of the AIXI algorithm.
Newcomb's original problem did not include the clause 'by the way, there's nothing in the first box'. You're adding that clause by making additional assertions regarding what AIXI knows about "Omega".
Of course it didn't include that clause; it would be a rather stupid problem if it did include that clause. On the other hand, what is in the statement of Newcomb's problem is "By the time the game begins, and the player is called upon to choose which boxes to take, the prediction has already been made, and the contents of box B have already been determined." Moreover, it is quite clearly stated that the agent playing the game is made fully aware of this fact.
If we stipulate, for the sake of argument, that AIXI cannot work out the contents of the opaque box, AIXI still fails and two-boxes. By the problem statement AIXI should already be convinced that the contents of the boxes are predetermined. Consequently, the vast majority of weight in AIXI's distribution over world models should be held by models in which AIXI's subsequent action has no effect on the contents of the box, and so AIXI will rather straightforwardly calculate two-boxing to have higher utility. Moreover, it's easy for Omega to deduce this, and so the first box will be empty, and so AIXI gets $1000.
Setting the stipulation aside, I still think it should be pretty easy for AIXI to deduce that the box is empty. Given Omega's astounding predictive success it is far more likely that Omega has a non-trivial capacity for intelligent reasoning and uses this reasoning capacity with a goal of making accurate predictions. As such, I would be surprised if an Omega-level predictor was not able to come across the simple argument I gave above. Of course, as I said above, it doesn't really matter if AIXI can't deduce the contents of the box; AIXI two-boxes and loses either way.
There's a truly crazy amount of misunderstandings with regards to what Solomonoff Induction can learn about the world, on LW.
Let's say you run AIXI, letting it oversee some gigabytes of webcam data, at your location. You think AIXI can match the exact location of raindrops on your roof, hours in advance? You think AIXI is going to know all about me - the DNA I have, how may I construct a predictor, etc?
No, I don't think that.
Replies from: private_messaging↑ comment by private_messaging · 2014-09-28T10:43:40.936Z · LW(p) · GW(p)
AIXI not getting the million dollars is a direct consequence of the output of the AIXI algorithm.
Really? I thought your predictor didn't evaluate the algorithm, so how is that a 'direct consequence'?
By the problem statement AIXI should already be convinced that the contents of the boxes are predetermined.
Yeah, and in the Turing machine provided with the tape where the action is "choose 1 box" (the tape is provided at the very beginning), the content of the box is predetermined to have 1 million, while in the entirely different Turing machine provided with the tape where the action is "choose 2 boxes", the box is predetermined to have nothing. What is so hard to get about it? Those are two entirely different Turing machines, in different iterations of the argmax loop. Are you just selectively ignoring the part of the statement where the predictor, you know, is actually being correct?
edit: as I said, it's a word problem, only suitable for sloshy and faulty word reasoning using folk physics. You end up ignoring some part of the problem statement.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-28T12:13:56.106Z · LW(p) · GW(p)
Really? I thought your predictor didn't evaluate the algorithm, so how is that a 'direct consequence'?
The predictor doesn't have to fully evaluate the algorithm to be able to reason about the algorithm.
Yeah, and in the Turing machine provided with the tape where the action is "choose 1 box" (the tape is provided at the very beginning), the content of the box is predetermined to have 1 million, while in the entirely different Turing machine provided with the tape where the action is "choose 2 boxes", the box is predetermined to have nothing. What is so hard to get about it? Those are two entirely different Turing machines, in different iterations of the argmax loop. Are you just selectively ignoring the part of the statement where the predictor, you know, is actually being correct?
Nowhere in the problem statement does it say that Omega is necessarily always correct. If it's physically or logically impossible, Newcomb's problem is basically just asking "would you prefer a million dollars or a thousand dollars." The whole point of Newcomb's problem is that Omega is just very, very good at predicting you.
Anyways, I think you're misunderstanding the AIXI equation. If there are two Turing machines that are consistent with all observations to date, then both of those Turing machines would be evaluated in the one-boxing argmax iteration, and both would be evaluated in the two-boxing argmax iteration as well. There is no possible reason that either world machine would be excluded from either iteration.
As such, if in one of those Turing machines the box is predetermined to have 1 million, then it's pretty obvious that when given the input "two-box" that Turing machine will output $1,001,000. More generally there would of course be infinitely many such Turing machines, but nonetheless the expected value over those machines will be very nearly that exact amount.
What exactly is the reason you're suggesting for AIXI excluding the million-dollar Turing machines when it considers the two-boxing action? Where in the AIXI equation does this occur?
Replies from: private_messaging↑ comment by private_messaging · 2014-09-28T13:59:10.996Z · LW(p) · GW(p)
There is no possible reason that either world machine would be excluded from either iteration.
This is getting somewhere.
AIXI does S.I. multiple times using multiple machines differing in what they have on the extra actions tape (where the list of actions AIXI will ever take is written). All the machines used to evaluate the consequence of 1-boxing have different extra actions tape from all the machines used to evaluate the consequences of 2 boxing.
From
http://www.hutter1.net/ai/uaibook.htm
"where U is a universal (monotone Turing) machine executing q given a1..am."
The U used for one boxing is different U from U used for two boxing, running the same q (which can use the action from the extra tape however it wants; to alter things that happen at the big bang, if it sees fit).
What exactly is the reason you're suggesting for AIXI excluding the million-dollar Turing machines when it considers the two-boxing action? Where in the AIXI equation does this occur?
With regards to the content of the boxes, there are 3 relevant types of program. One is 'there's nothing in the box', other is 'there's a million in the box', but the third, and this is where it gets interesting, is 'a bit from the extra input tape determines if there's money in the box'. Third type can in principle be privileged over repeated observation of correct prediction as it does not have to duplicate the data provided on the third tape for the predictions to be correct all the time.
The third type evaluates to money in the box when the action (provided on the actions tape, which is available to the machine from the beginning) is to take 1 box, and evaluates to no money in the box when the action is to take 2 boxes.
If AIXI learns or is pre-set to know that there's prediction of the decision happening, I take it as meaning that the third type of machine acquires sufficient weight. edit: and conversely, if the AIXI is not influenced by the program that reads from the actions tape to determine the movements of the 'predictor', I take it as AIXI being entirely ignorant of the predicting happening.
edit: clearer language regarding the extra actions tape
edit2: and to clarify further, there's machines where a bit of information in q specifies that "predictor" has/hasn't put money in the box, and there's machines where a bit in the another tape, a1...am , determines this. Because it's not doing any sort of back in time logic (the a1..am is here from the big bang), the latter are not that apriori improbable and can be learned just fine.
Replies from: lackofcheese, private_messaging↑ comment by lackofcheese · 2014-09-28T15:20:09.581Z · LW(p) · GW(p)
The U used for one boxing is different U from U used for two boxing, running the same q (which can use the action from the extra tape however it wants; to alter things that happen at the big bang, if it sees fit).
The U is always the same U; it's a universal Turing machine. It takes as its input a world program q and a sequence of AIXI's actions.
With regards to the content of the boxes, there are 3 relevant types of program. One is 'there's nothing in the box', other is 'there's a million in the box', but the third, and this is where it gets interesting, is 'a bit from the extra input tape determines if there's money in the box'. Third type can in principle be privileged over repeated observation of correct prediction as it does not have to duplicate the data provided on the third tape for the predictions to be correct all the time.
OK, yeah. I agree about the three types of program, but as far as I can see the third type of program basically corresponds to Omega being a faker and/or magical.
If AIXI learns or is pre-set to know that there's prediction of the decision happening, I take it as meaning that the third type of machine acquires sufficient weight. edit: and conversely, if the AIXI is not influenced by the program that reads from the actions tape to determine the movements of the 'predictor', I take it as AIXI being entirely ignorant of the predicting happening.
I don't see how this interpretation of the problem makes sense. What you're saying is not a prediction at all, it's simply direct causation from the action to the contents of the box. By contrast, it's inherent in the term "prediction" that the prediction happens before the thing it's trying to predict, and therefore that the box already either contains a million dollars or does not contain a million dollars.
Let me pose a more explicit form of Newcomb's problem by way of clarification. I don't think it changes anything relevant as compared to the standard version of the problem; the main point is to explicitly communicate the problem setup and describes a way for AIXI to reach the epistemic state that is posited as part of Newcomb's problem.
Omega apppears to AIXI, presents it with the two boxes, and gives its usual long explanation of the problem setup, as well as presenting some it usual evidence that there is no kind of "trick" involved here. However, before AIXI is allowed to make its decision, it is offered the opportunity to watch Omega run the game for 1000 other agents. AIXI gets to see Omega putting the money into the box in advance, and then it gets to watch the boxes the entire time. It also gets to see the player come in, it sees Omega introduce the game (the same way every time), and then watches the player make their decision, and watches them open the box and observes the contents. 1000 out of 1000 times (or maybe 999 out of 1000 if you prefer), it turns out that Omega correctly predicted the agent's action.
Now, finally, it's AIXI's turn to make its own decision. All the time it was watching Omega run the other games, it has been watching the boxes that Omega originally set up for AIXI - they've remained completely untouched.
As far as I can see, this is a perfectly reasonable way to realize the problem setup for Newcomb's problem.
Replies from: private_messaging, private_messaging, lackofcheese↑ comment by private_messaging · 2014-09-28T20:43:49.497Z · LW(p) · GW(p)
Ohh, and I forgot to address this:
OK, yeah. I agree about the three types of program, but as far as I can see the third type of program basically corresponds to Omega being a faker and/or magical.
Well, the way I see it, within the deterministic hypothetical that I 1-box, at the big bang the universe is in the initial state such that I 1-box, and within the deterministic hypothetical that I 2-box, at the big bang the universe is in the initial state such that I 2-box. A valid predictor looks at the initial state and determines what I will do, before I actually do it.
Exactly the same with AIXI, which sets up hypotheticals with different initial states (which is does by adding an universal constant of what it's going to hypothetically do (the extra tape), which is a very, very clever hack it has to employ to avoid needing to model itself correctly), and can have (or not have) a predictor which uses the initial state - distinct - to determine what AIXI will do before it does that. It correctly captures the fact that initial states which result in different actions are different, even though the way it does so is rather messy and looks ugly.
edit: i.e. to me it seems that there's nothing fake about the predictor looking at the world's initial state and concluding that the agent will opt to one-box. It looks bad when for the sake of formal simplicity you're just writing in the initial state 'I will one box' and then have the model of your body read that and one-box, but it seems to me it's wrong up to a constant and not more wrong than TM using some utterly crazy tag system to run a world simulator.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-29T02:32:17.608Z · LW(p) · GW(p)
OK, I think I've just answered your question in my response to your other comment, but I'll give a brief version here.
If there is a bit corresponding to AIXI's future action, then by AIXI's assumptions that bit must not be observable to AIXI until after it takes its actions. As such, models of this sort must involve some reason why the bit is observable to Omega, but not observable to AIXI; models where the information determining Omega's prediction is also observable to AIXI will be significantly simpler.
↑ comment by private_messaging · 2014-09-28T20:25:02.227Z · LW(p) · GW(p)
The U is always the same U; it's a universal Turing machine. It takes as its input a world program q and a sequence of AIXI's actions.
In the sense of the language of "where U is a universal (monotone Turing) machine executing q given a1..am.". (I unilaterally resorted to using same language as Hutter to minimize confusion - seems like a reasonable thing for two argues to adopt...).
I don't see how this interpretation of the problem makes sense. What you're saying is not a prediction at all, it's simply direct causation from the action to the contents of the box.
Well, it certainly made sense to me when I gone to the store today, that if the world is deterministic, then at the big bang, it was already predetermined entirely that I would have gone to the store today. And that in the alternative that I don't go to the store, as a simple matter of me not changing any physical laws (or, even more ridiculously, me changing the way mathematics works), it must be the case that the at the big bang, the deterministic universe was set up so that I don't go to the store today.
A simple matter of consistency of the laws of physics within the hypothetical universe requires that two hypothetical deterministic universes with different outcomes can't have different initial state. It's called a prediction because it occurs earlier in the simulation history than the actual action does.
Within the hypothetical universe where I go to the store, some entity looking at that initial state of that universe, could conclude - before today - that I go to the store. I don't see how the hell that is 'direct causation' from me going to the store. Me going to the store is caused by the initial state, the prediction is caused by the initial state. In AIXI's hypothetical where it takes 1 box, it taking 1 box is caused by the initial state of the Turing machine. It literally sets up the initial state of the TM so that it ends up picking 1 box (by the way of putting it's picking 1 box on an extra tape, or appending it at the end of the program). Not by a later intervention, which would make no sense and be folk physics that's wrong. The prediction, likewise, can be caused by the initial state.
Re: your set up.
If the agents are complicated and fairly opaque (if they aren't its not necessarily reasonable to assume what predictor does for them would be what predictor does for a complicated and opaque agent), and if agents are one or two boxing basically at an uniform random (AIXI won't learn much if they all 2-box), there's a string with thousand ones and zeroes, and it's repetition, which gives up to a 2^-1000 penalty to the representations where those are independently encoded using 2000 bits rather than 1000 bits.
Surely AIXI will compress those two same bitstrings into one bitstring somehow.
Now, you can of course decrease the number of cases or prediction accuracy so that AIXI is not provided sufficient information to learn the predictor's behaviour.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-29T02:17:55.810Z · LW(p) · GW(p)
In the sense of the language of "where U is a universal (monotone Turing) machine executing q given a1..am.". (I unilaterally resorted to using same language as Hutter to minimize confusion - seems like a reasonable thing for two argues to adopt...).
I think you're misunderstanding the language here; the inputs of a Turing machine are not part of the Turing machine. The program "q" and the actions "a1...am" are both inputs to U. That said, I guess it doesn't matter if you have two different Us, because they will always compute the same output given the same inputs anyway.
In AIXI's hypothetical where it takes 1 box, it taking 1 box is caused by the initial state of the Turing machine. It literally sets up the initial state of the TM so that it ends up picking 1 box (by the way of putting it's picking 1 box on an extra tape, or appending it at the end of the program). Not by a later intervention, which would make no sense and be folk physics that's wrong. The prediction, likewise, can be caused by the initial state.
According to AIXI's assumption of "chronological Turing machines", this isn't quite right. If the bit was simply encoded into the "initial state" of the universe, then AIXI could potentially observe the state of that bit before it actually takes its action. Any models where that bit influences AIXI's observations prior to acting would directly violate Hutter's assumption; world programs of this kind are explicitly forbidden from occupying any of AIXI's probability mass.
Now, I'll grant that this is subtly different from an assumption of "forward causality" because the chronological assumption specifically applies to AIXI's subjective past, rather than the actual past. However, I would argue that models in which AIXI's action bit causes the contents of the box without affecting its past observations would necessarily be more complex. In order for such a model to satisfy AIXI's assumptions, the action bit needs to do one of two things:
1) Magic (i.e. makes stuff appear or disappear within the box).
2) The action bit would need to be entangled with the state of the universe in just the right way; it would just so happen that Omega can observe that action bit but AIXI cannot observe it until after it takes its action.
It seems to me that Solomonoff induction will penalise both kinds of "action-caused" models quite heavily, because they offer a poor description of the problem. If the action bit was truly part of the state of the universe, it seems rather unlikely that Omega would be able to observe it while AIXI would not.
Re: your set up.
If the agents are complicated and fairly opaque (if they aren't its not necessarily reasonable to assume what predictor does for them would be what predictor does for a complicated and opaque agent), and if agents are one or two boxing basically at an uniform random (AIXI won't learn much if they all 2-box), [...]
I wouldn't assume the agents are one-boxing or two-boxing at uniform random, that would be pretty stupid since Omega would be unable to predict them. Typical versions of Newcomb's problem stipulate that when Omega thinks you'll pick randomly it won't put the million dollars in. Rather, it would be better to say that the agents are picked from some pool of agents, and it turns out that AIXI gets to witness reasonable proportions of both two-boxers and one-boxers.
[...] there's a string with thousand ones and zeroes, and it's repetition, which gives up to a 2^-1000 penalty to the representations where those are independently encoded using 2000 bits rather than 1000 bits.
Surely AIXI will compress those two same bitstrings into one bitstring somehow.
I completely agree! Given the enormous 1000-bit penalty, AIXI should determine that the problem is quite well described by a "common cause" explanation---that is, the actions of the individual actions and Omega's prediction are both determined in advance by the same factors.
In fact, I would go even further than that; AIXI should be able to duplicate Omega's feat and quickly come up with a universe model that predicts the agents as well as or better than Omega. When AIXI observed Omega playing the game it had access to the same information about the agents that Omega did, and so whatever the source of Omega's predictive accuracy, AIXI should be able to replicate it.
More generally, I would argue a "common cause" explanation is implicit in Newcomb's problem, and I think that AIXI should be able to deduce reasonable models of this without making such direct observations.
In any case, once AIXI comes upon this kind of explanation (which I think is really implicit in the setup of Newcomb's problem), AIXI is doomed. Models in which AIXI's future action bit manages to be observable to Omega without being observable to AIXI will be significantly more complicated than models in which Omega's prediction is determined by information that AIXI has already observed.
The most obvious such model is the one I suggested before - Omega simply reasons in a relatively abstract way about the AIXI equation itself. All of this information is information that is accessible to AIXI in advance, and hence it cannot be dependent upon the future action bit.
As such, AIXI should focus in on world models where the box already contains a million dollars, or already does not. Since AIXI will determine that it's optimal to two-box in both kinds of world, AIXI will two-box, and since this is a pretty simple line of reasoning Omega will predict that AIXI will two-box, and hence AIXI gets $1000.
Replies from: private_messaging↑ comment by private_messaging · 2014-09-29T10:41:20.241Z · LW(p) · GW(p)
It seems to me that Solomonoff induction will penalise both kinds of "action-caused" models quite heavily, because they offer a poor description of the problem.
What's quite heavily? It seems to me that you can do that in under a hundred bits, and few hundred bits of information are not that hard to acquire. If I throw a die, and it does a couple dozen bounces, it's influenced by the thermal noise and quantum fluctuations, there's about 2.58 bits of information that is new even to the true magical AIXI. There's kilobits if not megabits that can be learned from e.g. my genome (even if AIXI sat for years watching a webcam and browsing the internet beforehand, it still won't be able to predict the quantum random - it's either non deterministic, or multiverse and you don't know where in the multiverse you are). AIXI presumably got a webcam or other high throughput input device, too, so it may be able to privilege some hundreds bits penalized hypothesis (rule out all simpler ones) in a fraction of a second.
It strikes me as you are thinking up a fairly specific environment where the observations do not provide enough actual information. If I observe a software predictor predict a bunch of simple programs with source that I know and can fully evaluate myself, that wouldn't come close to convincing me it is going to predict my human decision, either. And I'm fundamentally more similar to those programs than AIXI is to agents it can predict.
What's about my example environment, where AIXI lives in a house, plays Newcomb's problem many times, and sometimes wants to get a lot of money, and sometimes doesn't want to get a lot of money for various reasons, e.g. out of e.g. a fear of increasing the risk of burglary if it has too much money, or the fear of going to jail on money laundering charges, or what ever. Every time, the presence of money in the first box is correlated with the actual decision AIXI makes. This has to go on for long enough, of course, until the inherently unlikely hypothesis of being predicted by something, gets privileged.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-29T12:15:49.005Z · LW(p) · GW(p)
Why would AIXI privilege a magical hypothesis like that one when there are other hypotheses are strictly simpler and explain the world better? If Omega is capable of predicting AIXI reasonably accurately without the kind of magic you're proposing, why would AIXI possibly come up with a magical explanation that involves Omega having some kind of privileged, back-in-time access to AIXI's action which has absolutely no impact on AIXI's prior observations!?
As for your example environment, Iterated Newcomb's problem != Newcomb's problem, and the problem isn't even Newcomb's problem to begin with if AIXI doesn't always want the million dollars. As far as I can tell, though, you're just trying to come up with a setup in which Omega really needs to be retrocausal or magical, rather than just really good at predicting.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-29T14:29:35.661Z · LW(p) · GW(p)
In other words, AIXI's action is predetermined by the AIXI equation. A model where Omega predicts AIXI's action on the basis of the AIXI equation is strictly simpler than a model involving a single bit of information that is entangled with Omega and yet somehow doesn't leak out into the universe and remains invisible to AIXI until AIXI opens the box (or boxes).
Unless the universe and/or Omega really is magical, AIXI's observations should obviously favour the real explanation over the magical one.
Replies from: private_messaging↑ comment by private_messaging · 2014-09-30T16:07:56.726Z · LW(p) · GW(p)
and yet somehow doesn't leak out into the universe and remains invisible to AIXI until AIXI opens the box (or boxes).
This is kind of stipulated in the problem, the box being opaque, no? What does this leak look like, other than box being in some way not opaque?
We could talk of Superman Decision Theory here and how it necessarily two boxes because he has x-ray vision and sees into the box :)
Unless the universe and/or Omega really is magical, AIXI's observations should obviously favour the real explanation over the magical one.
You keep asserting this, but I don't see why that's true. Let's suppose that I design something. I have a bit of quantum shot noise in my synapses, the precise way how I implement something probably takes a lot of information to describe. Kilobits, megabits even. Meanwhile, the body of AIXI's robot is magical - it's reading from the action tape to set voltages on some wires or some such. So there's some code to replicate...
And with regards to having a real explanation available, I think it falls under the purview of box not being opaque enough. It's akin to having a videotape of omega putting or not putting money into the box.
I think I see a better way to clarify my original remark. There is a pretty easy way to modify AIXI to do CDT. Exclude machines that read Ai before printing Oi . (And it's very possible that some approximations or other variations by Hutter did that. I'd certainly do that if I were making an approximation. I'd need to re-read him to make totally sure he didn't have that somewhere) I think we can both agree that if you don't do this, you can one-box without having backwards in time causation in your model, unlike CDT (and if you do, you can't, like CDT).
In any case, my main point is that the one boxing and two boxing depends to the way of doing physics, and given that we're arguing about different environments yielding different ways of doing physics, I think we agree on that point.
edit: also I think I can write a variation of AIXI that matches my decisionmaking more closely. I'd just require the TM to print actions on a tape, matching the hypothetical actions. Up to a constant difference in program lengths, so it's not worse than a choice of a TM. (I'd prefer that not to screw up probabilities though, even if its up to a constant, I need to think how edit: actually quite easy to renormalize that away... I'm far too busy right now with other stuff though). Also using some symbolic package to approximately evaluate it, evading some of can't model oneself traps.
There could be an universe that used some ahead of time indirect evaluation to tell me in advance what action I am going to take, and with me not taking another action out of spite. I don't know for sure our universe isn't this - I just have a somewhat low prior for that.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-09-30T16:48:14.861Z · LW(p) · GW(p)
This is kind of stipulated in the problem, the box being opaque, no? What does this leak look like, other than box being in some way not opaque?
No, "the box is opaque" is very different to "you have absolutely no way of working out whether the box contains the million dollars". For example, if I'm playing Newcomb's problem then no matter how opaque the box is I'm already pretty sure it contains a million dollars, and when I proceed to one-box every time I'm almost always right. Are you saying I'm forbidden from being able to play Newcomb's problem?
We could talk of Superman Decision Theory here and how it necessarily two boxes because he has x-ray vision and sees into the box :)
If "Superman Decision Theory" sees into the box and necessarily two-boxes, then Superman Decision Theory is doing it wrong, because SDT is always going to get $1000 and not a million dollars.
You keep asserting this, but I don't see why that's true. Let's suppose that I design something. I have a bit of quantum shot noise in my synapses, the precise way how I implement something probably takes a lot of information to describe. Kilobits, megabits even. Meanwhile, the body of AIXI's robot is magical - it's reading from the action tape to set voltages on some wires or some such.
AIXI doesn't need to work out the precise way Omega is implemented, it just needs to find programs that appear to function the same way. If the quantum noise has no impact on Omega's actual predictions then it's not going to matter as far as AIXI's hypotheses about how Omega predicts AIXI are concerned.
As far as I can see, "the box is not opaque enough" translates to "AIXI knows too much about the real world!" Well, how is it a good thing if your decision theory performs worse when it has a more realistic model of the world?
It seems to me that the more the AIXI agent works out about the world, the more physics-like its programs should become, and consequently the less it will be able to come up with the kinds of explanations in which its actions cause things in the past. Yes, world programs which involve reverse causality that just happens to be unobservable to AIXI until after it takes its own action are permissible Turing machines for AIXI, but the more information AIXI gathers, the higher the complexity penalty on those kinds of programs will be.
Why? Because, by necessity, AIXI's action bit would have to be treated as a special case. If Omega predicts all those other agents in the same way, a bit of code that says "ah, but if Omega is facing AIXI, then Omega should access the a_5 bit from AIXI's action tape instead of doing what Omega normally does" is simply an unnecessary complexity penalty that doesn't help to explain anything about AIXI's past observations of Omega.
So, the more mature AIXI gets, the more CDT-like it becomes.
Replies from: private_messaging, SilentCal↑ comment by private_messaging · 2014-09-30T18:52:43.962Z · LW(p) · GW(p)
No, "the box is opaque" is very different to "you have absolutely no way of working out whether the box contains the million dollars".
I take the box being opaque to mean that the contents of the box do not affect my sensory input, and by extension that I don't get to e.g. watch a video of omega putting money in the box, or do some forensic equivalent.
For example, if I'm playing Newcomb's problem then no matter how opaque the box is I'm already pretty sure it contains a million dollars
Really? What if Omega is a program, which you know predicts outputs of other simple programs written in C++, Java, and Python, and it been fed your raw DNA as a description, 'cause you're human?
What if you just know the exact logic Omega is using?
(Besides, decision theories tend to agree that you should pretend online that you one-box)
If "Superman Decision Theory" sees into the box and necessarily two-boxes, then Superman Decision Theory is doing it wrong, because SDT is always going to get $1000 and not a million dollars.
No, you just adapt the Newcomb's "opaque box" in an obtuse way. Superman's facing an entirely different decision problem from the Newcomb's that you face.
Why? Because, by necessity, AIXI's action bit would have to be treated as a special case. If Omega predicts all those other agents in the same way, a bit of code that says "ah, but if Omega is facing AIXI, then Omega should access the a_5 bit from AIXI's action tape instead of doing what Omega normally does" is simply an unnecessary complexity penalty that doesn't help to explain anything about AIXI's past observations of Omega.
I think you're just describing a case where AIXI fails to learn anything from other agents because they're too different from the AIXI. What's about my scenario where AIXI plays Newcomb's multiple times, sometimes wanting more money and sometimes not? The program reading a_5 also appears to work right.
It seems to me that the more the AIXI agent works out about the world, the more physics-like its programs should become, and consequently the less it will be able to come up with the kinds of explanations in which its actions cause things in the past.
Well, given that predictors for AIXI are non existent, that should be the case.
edit: actually, what's your reasons for one-boxing?
edit2: also I think this way of seeing the world - where your actions are entirely unlinked to the past - is a western phenomenon, some free will philosophy stuff. A quarter of my cultural background is quite fatalist in the outlook, so I see my decisions as the consequences of the laws of physics acting on the initial world state, and given same 'random noise', different decision by me implies both different future and different past.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-10-01T03:53:12.638Z · LW(p) · GW(p)
I take the box being opaque to mean that the contents of the box do not affect my sensory input,
Yep, that's what the box being opaque means - the contents of the box have no causal effect on your perceptions.
and by extension that I don't get to e.g. watch a video of omega putting money in the box, or do some forensic equivalent.
Nope. Watching the video would contradict this principle as well, because you would still effectively be seeing the contents of the box.
What IS allowed by Newcomb's problem, however, is coming to the conclusion that the contents of the box and your perceptions of Omega have a common cause in terms of how Omega functions or acts. You are then free to use that reasoning to work out what the contents of the box could be.
Your interpretation of Newcomb's problem basically makes it incoherent. For example, let's say I'm a CDT agent and I believe Omega predicted me correctly. Then, at the moment I make my decision to two-box, but before I actually see the contents of the opaque box, I already know that the opaque box is empty. Does this mean that the box is not "opaque", by your reasoning?
Really? What if Omega is a program, which you know predicts outputs of other simple programs written in C++, Java, and Python, and it been fed your raw DNA as a description, 'cause you're human?
If I don't think Omega is able to predict me, then it's not Newcomb's problem, is it? Even if we assume that the Omega program is capable of predicting humans, DNA is not that likely to be sufficient evidence for it to be able to make good predictions.
What if you just know the exact logic Omega is using?
Well, then it obviously depends on what that exact logic is.
I think you're just describing a case where AIXI fails to learn anything from other agents because they're too different from the AIXI. What's about my scenario where AIXI plays Newcomb's multiple times, sometimes wanting more money and sometimes not? The program reading a_5 also appears to work right.
First of all, as I said previously, if AIXI doesn't want the money then the scenario is not Newcomb's. Also, I don't think the a_5 reading program will end up being the simplest explanation even in that scenario. The program would need to use something like a_5, a_67, a_166, a_190 and a_222 in each instance of Newcomb's problem respectively. Rather than a world program with a generic "get inputs from AIXI" subroutine, you need a world program with a "recognize Newcomblike problems and use the appropriate bits" subroutine; there is still a complexity penalty.
Unless you're trying to make a setup in which Omega necessarily works by magic, then given sufficient evidence of reality at large magic is always going to be penalised. Given that reality at large works in a non-magical way, explanations that bootstrap your model of reality at large are always going to be simpler than explanations that have to add extraneous elements of "magic" to the model.
Besides, if Omega is just plain magical, then Newcomb's problem boils down to "is a million bigger than a thousand?"
Well, given that predictors for AIXI are non existent, that should be the case.
Of course there can be predictors for AIXI. I can, for example, predict with a high degree of confidence that if AIXI knows what chess is and it wants to beat me at chess, it's going to beat me. Also, if AIXI wants to maximise paperclips, I can easily predict that there are going to be a lot of paperclips.
edit: actually, what's your reasons for one-boxing?
By being the kind of person who one-boxes, I end up with a million dollars instead of a thousand.
edit2: also I think this way of seeing the world - where your actions are entirely unlinked to the past - is a western phenomenon, some free will philosophy stuff. A quarter of my cultural background is quite fatalist in the outlook, so I see my decisions as the consequences of the laws of physics acting on the initial world state, and given same 'random noise', different decision by me implies both different future and different past.
Um, the "libertarian free will" perspective is mostly what I'm arguing against here. The whole problem with CDT is that it takes that perspective, and, in concluding that its action is not in any way caused by its past, it ends up with only $1000. My point is that AIXI ultimately suffers from the same problem; it assumes that it has this magical kind of free will when it actually does not, and also ends up with $1000.
Replies from: private_messaging↑ comment by private_messaging · 2014-10-01T06:26:14.890Z · LW(p) · GW(p)
Yep, that's what the box being opaque means - the contents of the box have no causal effect on your perceptions.
Yeah, and then you kept stipulating that the model where Omega has read the action tape and then put or not put money into the box, but it didn't leak onto sensory input, is very unlikely, and I noted that it's stipulated in the problem statement that the box contents do not leak onto sensory input.
My point is that AIXI ultimately suffers from the same problem; it assumes that it has this magical kind of free will when it actually does not, and also ends up with $1000.
Let's say AIXI lives inside the robot named Alice. According to every model employed by AIXI, the robot named Alice has pre-committed, since the beginning of time, to act out a specific sequence of actions. How the hell that assumes magical free will I don't know. edit: and note that you can exclude machines which had read the action before printing matching sensory data, to actually ensure magical free will. I'm not even sure, maybe some variations by Hutter do just that.
edit:
Of course there can be predictors for AIXI. I can, for example, predict with a high degree of confidence that if AIXI knows what chess is and it wants to beat me at chess, it's going to beat me. Also, if AIXI wants to maximise paperclips, I can easily predict that there are going to be a lot of paperclips.
That's just abstruse. We both know what I mean.
By being the kind of person who one-boxes, I end up with a million dollars instead of a thousand.
Well, you're just pre-committed to 1-box, then. The omegas that don't know you're pre-committed to 1-box (e.g. don't trust you, can't read your pre-committments, etc) would put nothing there, though, which you might be motivated to think about if its e.g. 10 millions vs 1 million, or 2 millions vs 1 million. (I wonder if one boxing is dependent on inflation...)
edit: let's say I am playing the omega, and you know I know this weird trick for predicting you on the cheap.... you can work out what's in the first box, can't you? If you want money and don't care of proving omega wrong out of spite, I can simply put nothing in the first box, and count on you to figure that out. You might have committed to the situation with 1 million vs 1 thousand, but I doubt you committed to 1000000 vs 999999 . You say you one box, fine, you get nothing - a rare time Omega is wrong.
edit2: a way to actually do Newcomb's in real life, by the way. Take poor but not completely stupid people, make it 1000 000 vs 999 999 , and you can be almost always right. You can also draw some really rich people who you believe don't really care and would 1-box for fun, and put a million in the first box for those, and be almost always right about both types of the case.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-10-01T09:47:43.703Z · LW(p) · GW(p)
Yeah, and then you kept stipulating that the model where Omega has read the action tape and then put or not put money into the box, but it didn't leak onto sensory input, is very unlikely, and I noted that it's stipulated in the problem statement that the box contents do not leak onto sensory input.
The two situations are quite different. Any complexity penalty for the non-leaking box has already been paid via AIXI's observations of the box and the whole Newcomb's setup; the opaqueness of the box just boils down to normal reality. On the other hand, your "action bit" model in which Omega reads AIXI's action tape is associated with a significant complexity penalty because of the privileged nature of the situation - why specifically Omega, and not anyone else? Why does Omega specifically access that one bit, and not one of the other bits? The more physics-like and real AIXI's Turing machines get, the more of a penalty will be associated with Turing machines that need to incorporate a special case for a specific event.
Let's say AIXI lives inside the robot named Alice. According to every model employed by AIXI, the robot named Alice has pre-committed, since the beginning of time, to act out a specific sequence of actions. How the hell that assumes magical free will I don't know. edit: and note that you can exclude machines which had read the action before printing matching sensory data, to actually ensure magical free will. I'm not even sure, maybe some variations by Hutter do just that.
AIXI as defined by Hutter (not just some "variation") has a foundational assumption that an action at time t cannot influence AIXI's perceptions at times 1..t-1. This is entirely incompatible with a model of Alice where she has pre-commited since the beginning of time, because such an Alice would be able to discover her own pre-commitment before she took the action in question. AIXI, on the other hand, explicitly forbids world models where that can happen.
That's just abstruse. We both know what I mean.
No, I don't. My point is that although you can't predict AIXI in the general case, there are still many cases where AIXI can be predicted with relative ease. My argument is still that Newcomb's problem is one of those cases (and that AIXI two-boxes).
As for all of your scenarios with different Omegas or different amounts of money, obviously a major factor is how accurate I think Omega's predictions are. If ze has only been wrong one time in a million, and this includes people who have been one-boxing as well, why should I spend much time thinking about the possibility that I could be the one time he gets it wrong?
Similarly, if you're playing Omega and you don't have a past history of correctly predicting one-boxing vs one-boxers, then yes, I two-box. However, that scenario isn't Newcomb's problem. For it to be Newcomb's problem, Omega has to have a history of correctly predicting one-boxers as well as two-boxers.
↑ comment by SilentCal · 2014-09-30T22:35:11.084Z · LW(p) · GW(p)
I suspect the unspecified implementation of Omega hides assumptions if not contradictions. Let me propose a more concrete version: The problem is presented by Conservative Finite Omega (CFO), who works by pulling the agent's source code, simulating it for a long but finite time, and putting $1,000,000 in the opaque box iff the simulation is determined to definitely one-box. The agent never walks away with the full $1,001,000, though the agent does sometimes walk away with $0.
So, assuming AIXI is confident in accurate models of how CFO works, CFO will simulate AIXI, which requires it to simulate AIXI's (accurate) simulation of CFO--endless recursion. AIXI 'wins' the timeout war (correctly predicting CFO's timeout), concludes that CFO has left the opaque box empty, and two-boxes.
You could look at that outcome as AIXI being penalized for being too smart. You could also say that an even smarter agent would prepend 'if (facing CFO-like situation) then return one-box' to its source code. Fundamentally, the specification of AIXI cannot conceive of its source code being an output; it's baked into the assumptions that the explicit output bits are the only outputs.
Replies from: lackofcheese↑ comment by lackofcheese · 2014-10-01T00:07:25.309Z · LW(p) · GW(p)
Sure, I don't necessarily blame the AIXI equation when it's facing a relatively stupid Omega in that kind of situation.
However, consider "More Intelligent Finite Omega", who pulls the agent's source code and uses an approximate theorem-proving approach until it determines, with high confidence, what AIXI is going to do. Assuming that AIXI has received sufficient evidence to be reasonably confident in its model of MIFO, MIFO can reason like this:
- AIXI will be able to accurately simulate me, therefore it will either have determined that the box is already empty, or already full.
- Given either of those two models, AIXI will calculate that the best action is to two-box.
- Consequently, AIXI will two-box.
and then MIFO will leave the opaque box empty, and its prediction will have been correct. Moreover, MIFO had no other choice; if it were put the money in the opaque box, AIXI would still have two-boxed, and MIFO's prediction would have been incorrect.
If you're allowed to make the assumption that AIXI is confident in its model of CFO and CFO knows this, then I can make the same assumption about MIFO.
Replies from: SilentCal↑ comment by SilentCal · 2014-10-01T19:25:00.760Z · LW(p) · GW(p)
I think you're right. At first I was worried (here and previously in the thread) that the proof that AIXI would two-box was circular, but I think it works out if you fill in the language about terminating turing machines and stuff. I was going to write up my formalization, but once I went through it in my head your proof suddenly looked too obviously correct to be worth expanding.
↑ comment by lackofcheese · 2014-09-28T15:54:42.695Z · LW(p) · GW(p)
Oh, and if the special circumstances offered to AIXI are a problem w.r.t. allowing tricky explanations, I think that should be resolvable.
For example, getting to watch other agents play before making your own decision is the "VIP treatment". Omega decides whether or not to give this treatment by transparently by generating a pseudorandom integer between 1 and 2000, and it gives the VIP treatment if and only if that integer comes up as a 1. The player gets to directly observe the random number generation mechanism while Omega is using it.
Out of the 1000 agents who also got to play Omega's game while AIXI was watching, a 1 came up on the 965th game. When that happened, that agent got to watch 1000 games, although in those 1000 a 1 didn't come up at all. Since AIXI was still waiting around, it got to watch those extra 1000 games before watching the last 35 games of its VIP allocation. Of the 2000 games played, Omega made 2000 correct predictions.
If 2000/2000 is too unlikely and inherently results in weird explanations, we can adjust the number down appropriately e.g. 1900/2000.
↑ comment by private_messaging · 2014-09-28T14:50:59.197Z · LW(p) · GW(p)
Actually, it's a bit of challenge making an environment where AIXI learns about the predictor.
I think I have one. AIXI lives in a house, it has 100$, it gets reward any cycle there's at least 1$ in the house, and it plays Newcomb's repeatedly. Money are delivered to the house. So it doesn't necessarily always want a million dollar. So first it grabs $1000 from the transparent box (it doesn't know about the predictor) and immediately spends them on ordering a better door, because it has hypotheses concerning possible burglary, where the house would be set on fire, and no money will be left at all. Then, it doesn't have the door yet, and it doesn't want extra money because it can attract theft, so it one boxes, but gets a million.
It keeps one and two boxing as it's waiting and receives various security upgrades to it's house, sets up secure money pick ups for the banks, offshore accounts, and so on and so forth. And the predictor turns out to be always correct. So it is eventually dominated by TMs that use the one vs two boxing bit of data from the a1...am tape to specify what the hand of the predictor is doing with a million dollars when simulating the past. So at some point if it wants a million dollars, it one boxes, and if it doesn't, it two boxes.
↑ comment by owencb · 2014-09-26T13:36:51.692Z · LW(p) · GW(p)
But it's unclear to me that this requires a change to decision theory, instead of just a sophisticated model of what the agent's environment looks like that's tuned to thinking about dispositions and reputations.
I think with sufficiently sophisticated models essentially all of the decision theories should collapse to recommending the correct answer. But our models are often not sufficiently sophisticated (and if our environment includes agents of comparable or greater complexity it may be that they can't be). Having models (+ decision theories) which are usable by boundedly rational agents and tend to give good outcomes is very valuable.
To my mind this post has presented a good case that Newcomblike scenarios present CDT with issues as a practical decision-making heuristic.
Replies from: Vaniver↑ comment by Vaniver · 2014-09-27T16:56:26.572Z · LW(p) · GW(p)
I think with sufficiently sophisticated models essentially all of the decision theories should collapse to recommending the correct answer.
Agreed, in that I've made the argument that EDT (which operates on joint probability distributions) can emulate CDT (which operates on causal graphs) by adopting a particular network structure that (at additional cost) recreates the math of causal graphs. I see the EDT vs. CDT question as basically asking "does it make more sense to use joint probability distributions or causal models?" and the answer is "causal models are a more powerful language that are more closely tuned to the problem of making decisions, so use those."
Now, perhaps there's a way of representing the environment that's better at encoding the decision-relevant information than causal graphs, and that using this superior structure requires upgrading to 'next decision theory' instead of painfully encoding that information into causal graphs. I'm fully aware of the possibility that I'm the hapless Blub programmer here, saying "but why would you ever need to do y?", and if so I'd like to be convinced than y is actually useful.
But a part of convincing me of that, I think, is showing that the environment-belief structure used by whatever 'next decision theory' we're considering is a more powerful language than causal models, and I think the traditional decision theory comparison approach of putting forward a situation and asking how reasoners using various theories would handle it is not particularly convincing at doing that.
comment by alex_zag_al · 2014-09-24T22:56:23.208Z · LW(p) · GW(p)
I don't understand this yet, which isn't too surprising since I haven't read the background posts yet. However, all the "roughly speaking" summaries of the more exact stuff are enough to show me that this article is talking about something I'm curious about, so I'll be reading in more detail later probably.
comment by JoshuaFox · 2014-10-09T19:02:00.031Z · LW(p) · GW(p)
Great lecture and article. This cleared up a lot of things for me. One thing I don't understand. You describe how an adversary can "go back in time" by simulating an earlier stage of an agent which started as CDT and self-modified to an improved decision theory, and so force the agent not to self-modify in that way.
You said that if the CDT agent would modify to be unblackmailable, the adversary could simulate an earlier version of that agent (the CDT version) and force it not modify to be unblackmailable.
This reminds me of another case: As has been said elsewhere (Yudkowsky Timeless Decision Theory pages 18-19), if an adversary acts according to the internal algorithm that an agent, uses, then that agent is stuck. This is "cheating" in the sense that it is outside the bounds of MIRI's current work on reflective decision theory.
I understand that simulation of an adversary, or of variants of the adversary, is a perfectly ordinary action, which we humans do (to a limited extent) in dealing with other humans. Yet I am a bit confused: It seems to me that simulating an going back in time in this way to keep the adversary from self-modifying somehow is "cheating" too -- i.e., stretching the parameters of MIRI's investigations of how agents should make decisions. Could you clear up what you mean by this sort of counterfactual, backwards-in-time extortion-by-simulation?
Replies from: So8res↑ comment by So8res · 2014-10-09T20:20:43.090Z · LW(p) · GW(p)
The adversary simulates the AI from its original source up until it is blackmailed by the adversaries. (In practice, the adversaries don't need to actually simulate this out, they can just check what decision theory the agent uses, but it's a better intuition pump if you imagine them simulating the AI.)
The trouble with this scenario is not that the adversary is somehow "forcing" the AI to not modify, rather, the trouble is that when CDT considers self-modifying so that the agent succeeds on theses sorts of problems, it concludes that it's already too late (even though it isn't). In other words, this is a flaw that CDT reports is not a flaw.
There are many flaws that CDT can be expected to fix because CDT recognizes them as flaws (e.g. when CDT self-modifies to stop using CDT inside new mirror token trades). But if a CDT agent finds that it is already in a mirror token trade, then CDT will say that it should not self-modify to give its token away because it cannot guarantee that its perfect copy would do the same thing. This is a flaw that CDT does not report as a flaw, which is why CDT fails.
The blackmail scenario essentially generates a similar problem in self-modifying agents. A CDT-agent could self-modify to patch its blackmailability, but CDT reports that such patches have no upside (it incorrectly thinks a simulation spawned from its original source is logically independent because it is causally independent, therefore it thinks that its choice to patch the blackmailability does not affect the simulation's choice) and a potential downside (if it patches but the simulation doesn't, then the bomb will go off) and so it doesn't correct this flaw.
This is "cheating" in the sense that it is outside the bounds of MIRI's current work on reflective decision theory.
Eh, not really. The question of extensional decision problems is separate issue, and the examination of non-extensional DPs is not entirely outside our scope. It's a complex topic and we'll hopefully have a writeup about unfair extensional decision problems sometime in the next few months. (This is one of the places where we have a number of small results and not enough time to write them up.)
Replies from: JoshuaFox