When would AGIs engage in conflict?
post by JesseClifton, Sammy Martin (SDM), Anthony DiGiovanni (antimonyanthony) · 2022-09-14T19:38:22.478Z · LW · GW · 5 commentsContents
Explaining costly conflict Avoiding conflict via commitment and disclosure ability? What if conflict isn’t costly by the agents’ lights? Candidate directions for research and intervention Appendix: Full rational conflict taxonomy Equilibrium-compatible cases Equilibrium-incompatible cases Reasons agents don’t disclose private information References None 5 comments
Here we will look at two of the claims introduced in the previous post: AGIs might not avoid conflict that is costly by their lights (Capabilities aren’t Sufficient [LW · GW]) and conflict that is costly by our lights might not be costly by the AGIs’ (Conflict isn’t Costly [LW · GW]).
Explaining costly conflict
First we’ll focus on conflict that is costly by the AGIs’ lights. We’ll define “costly conflict” as (ex post) inefficiency: There is an outcome that all of the agents involved in the interaction prefer to the one that obtains.[1] This raises the inefficiency puzzle of war: Why would intelligent, rational actors behave in a way that leaves them all worse off than they could be?
We’ll operationalize “rational and intelligent” actors as expected utility maximizers.[2] We believe that the following taxonomy of the causes of inefficient outcomes between expected utility maximizers is exhaustive, except for a few implausible edge cases. (We give the full taxonomy, and an informal argument that it is exhaustive, in the appendix [LW · GW].) That is, expected utility maximization can lead to inefficient outcomes for the agents only if one of the following conditions (or an implausible edge case) holds. This taxonomy builds on Fearon’s (1995) influential “rationalist explanations for war”.[3]
Private information and incentives not to disclose. Here, “private information” means information about one’s willingness or ability to engage in conflict — e.g., how costly one considers conflict to be, or how strong one’s military is — about which other agents are uncertain. This uncertainty creates a risk-reward tradeoff: For example, Country A might think it’s sufficiently likely that Country B will give up without much of a fight that it’s worthwhile in expectation for A to fight B, even if they’ll end up fighting a war if they are wrong.
In these cases, removing uncertainty — e.g., both sides learning exactly how willing the other is to fight — opens up peaceful equilibria. This is why conflict due to private information requires “incentives not to disclose”. Whether there are incentives to disclose will depend on a few factors.
First, the technical feasibility of different kinds of verifiable disclosure matters. For example, if I have an explicitly-specified utility function, how hard is it for me to prove to you how much my utility function values conflict relative to peace?
Second, different games will create different incentives for disclosure. Sometimes the mere possibility of verifiable disclosure ends up incentivizing all agents to disclose all of their private information (Grossman 1981; Milgrom 1981). But in other cases, more sophisticated disclosure schemes are needed. For example: Suppose that an agent has some vulnerability such that unconditionally disclosing all of their private information would place them at a decisive disadvantage. The agents could then make copies of themselves, allow these copies to inspect one another, and transmit back to the agents only the private information that’s necessary to reach a bargain. (See the appendix [LW · GW] and DiGiovanni and Clifton (2022) for more discussion of conditional information revelation and other conditions for the rational disclosure of conflict-relevant private information.)
For the rest of the sequence, we’ll use “informational problem” as shorthand for this mechanism of conflict.
Inability to credibly commit to peaceful settlement. Agents might fight even though they would like to be able to commit to peace. The Prisoner’s Dilemma is the classic example: Both prisoners would like to be able to write a binding contract to cooperate, but if they can’t, then the game-theoretically rational thing to do is defect.
Similarly sometimes one agent will be tempted to launch a preemptive attack against another. For example, if Country A thinks Country B will soon become significantly more powerful, Country A might be tempted to attack Country B now. This could be solved with credible commitment: Country B could commit not to becoming significantly more powerful, or to compensate Country A for their weakened bargaining position. But without the ability to make such commitments, Country A may be rationally compelled to fight.
Another example is randomly dividing a prize. Suppose Country A and Country B are fighting over an indivisible holy site. They might want to randomly allocate the holy site to one of them, rather than fighting. The problem is that, once the winner has been decided by the random lottery, the loser has no reason to concede rather than fight, unless they have some commitment in place to honor the outcome of the lottery.
For the rest of the sequence, we’ll use “commitment inability problem” as shorthand for this mechanism of conflict.[4]
Miscoordination. When there are no informational or commitment inability problems, and agents’ preferences aren’t entirely opposed, there will be equilibria in which agents avoid conflict. But the existence of such equilibria isn’t enough to guarantee peace, even between rational agents. Agents can still fail to coordinate on a peaceful solution.
A central example of catastrophic conflict due to miscoordination is incompatible commitments. Agents may make commitments to accepting only certain peaceful settlements, and otherwise punishing their counterpart. This can happen when agents have uncertainty about what commitments their counterparts will make. Depending on what you think about the range of outcomes your counterpart has committed to demanding, you might commit to a wider or narrow range of demands. There are situations in which the agents’ uncertainty is such that the optimal thing for each of them to do is commit to a narrow range of demands, which end up being incompatible. See this post [LW · GW] on “the commitment races problem” for more discussion.
Avoiding conflict via commitment and disclosure ability?
One reason for optimism about AGI conflict is that AGIs may be much better at credible commitment and disclosure of private information. For example, AGIs could make copies of themselves and let their counterparts inspect these copies until they are satisfied that they understand what kinds of commitments their counterpart has in place. Or, to credibly commit to a treaty, AGIs could do a “value handshake [? · GW]” and build a successor AGI system whose goal is to act according to the treaty. So, what are some reasons why AGIs would still engage in conflict, given these possibilities? Three stand out to us:
Strategic pressures early in AGI takeoff. Consider AGI agents that are opaque to one another, but are capable of self-modifying / designing successor agents who can implement the necessary forms of disclosure. Would such agents ever fail to implement these solutions? If, say, designing more transparent successor agents is difficult and time-consuming, then agents might face a tradeoff between trying to implement more cooperation-conducive architectures and placing themselves at a critical strategic disadvantage. This seems most plausible in the early stages of a multipolar AI takeoff.
Lack of capability early in AGI takeoff. Early in a slow multipolar AGI takeoff, pre-AGI AIs or early AGIs might be capable of starting destructive conflicts but lack the ability to design successor agents, scrutinize the inner workings of opponent AGIs, or reflect on their own cognition in ways that would let them anticipate future conflicts. If AGI capabilities come in this order, such that the ability to launch destructive conflicts comes a while before the ability to design complete successor agents or self-modify, then early AGIs may not be much better than humans at solving informational and commitment problems.
Fundamental computational limits. There may be fundamental limits on the ability of complex AGIs to implement the necessary forms of verifiable disclosure. For example, in interactions between complex AGI civilizations in the far future, these civilizations’ willingness to fight may be determined by factors that are difficult to compress. (That is, the only way in which you can find out how willing to fight they are is to run expensive simulations of what they would do in different hypothetical scenarios.) Or it may be difficult to verify that the other civilization has disclosed their actual private information.
These considerations apply to informational and commitment inability problems. But there is also the problem of incompatible commitments, which is not solved by sufficiently strong credibility or disclosure ability. Regardless of commitment or disclosure ability, agents will sometimes have to make commitments under uncertainty about others’ commitments.
Still, the ability to make conditional commitments could still help to ameliorate the risks from incompatible commitments. For example, agents could have a hierarchy of conditional commitments of the form: “If our -order commitments are incompatible, try resolving these via an -order bargaining process.” See also safe Pareto improvements, which is a particular kind of failsafe for incompatible commitments, and (the version in the linked paper) relies on strong commitment and disclosure ability.
What if conflict isn’t costly by the agents’ lights?
Another way conflict can be rational is if conflict actually isn’t costly for at least one agent, i.e., there isn’t any outcome that all parties prefer to conflict. That is, Conflict isn't Costly is false. Some ways this could happen:
- Pure spite: An agent behaves as though minimizing another agent’s utility function.
- Unforgivingness: An agent would rather indefinitely punish their counterpart if they don’t get their preferred settlement, rather than settle for something else. If two such agents encounter one another and prefer different settlements, they’ll behave as though they have incompatible commitments, though in this case the “commitments” weren’t chosen by the agents.[5]
These cases, in which conflict is literally costless for one agent, seem unlikely. They are extremes on a spectrum of what we’ll call conflict-seeking preferences (CSPs). By shrinking the range of outcomes agents prefer to conflict, these preferences exacerbate the risks of conflict due to informational, commitment inability, or miscoordination problems. For instance, risk-seeking preferences will lead to a greater willingness to risk losses from conflict (see Shulman (2010) for some discussion of implications for conflict between AIs and humans). And spite will make conflict less subjectively costly, as the material costs that a conflict imposes on a spiteful agent are partially offset by the positively-valued material harms to one’s counterpart.
Candidate directions for research and intervention
We argued above that Capabilities aren’t Sufficient. AGIs may sometimes engage in conflict that is costly, even if they are extremely capable. But it remains to be seen whether Intent Alignment isn't Sufficient to prevent unendorsed conflict, or Intent Alignment isn't Necessary to reduce the risk of conflict. Before we look at those claims, it may be helpful to review some approaches to AGI design that might reduce the risks reviewed in the previous section. In the next post, we ask whether these interventions are redundant with work on AI alignment.
Let’s look at interventions directed at each of the causes of conflict in our taxonomy.
Informational and commitment inability problems. One could try to design AGIs that are better able to make credible commitments and better able to disclose their private information. But it’s not clear whether this reduces the net losses from conflict. First, greater commitment ability could increase the risks of conflict from incompatible commitments. Second, even if the risks of informational and commitment inability problems would be eliminated in the limit of perfect commitment and disclosure, marginal increases in these capabilities could worsen conflict due to informational and commitment inability problems. For example, increasing the credibility of commitments could embolden actors to commit to carrying out threats more often, in a way that leads to greater losses from conflict overall.
Miscoordination. One direction here is building AGIs that reason in more cautious ways about commitment, and take measures to mitigate the downsides from incompatible commitments. For example, we could develop instructions for human overseers [AF · GW] as to what kinds of reasoning about commitments they should encourage or discourage in their (intent-aligned) AI.[6] The design of this “overseer’s manual” might be improved by doing more conceptual thinking about sophisticated approaches to commitments. Examples of this kind of work include Yudkowsky’s solution [LW · GW] for bargaining between agents with different standards of fairness; surrogate goals and Oesterheld and Conitzer’s (2021) safe Pareto improvements; and Stastny et al.’s (2021) notion of norm-adaptive policies. It may also be helpful to consider what kinds of reasoning about commitments we should try to prevent altogether in the early stages of AGI development.
The goal of such work is not necessarily to fully solve tricky conceptual problems in bargaining. One path to impact is to improve the chances that early human-intent-aligned AI teams are in a “basin of attraction of good bargaining”. The initial conditions of their deliberation about how to bargain should be good enough to avoid locking in catastrophic commitments early on, and to avoid path-dependencies which cause deliberation to be corrupted [AF · GW]. We return to this in our discussion of Intent Alignment isn't Sufficient.
Lastly, surrogate goals are a proposal for mitigating the downsides of executed threats, which might occur due to either miscoordination or informational problems. The idea is to design an AI to treat threats to carry out some benign action (e.g., simulating clouds) the same way that they treat threats against the overseer’s terminal values.
Conflict-seeking preferences. Consider a few ways in which AI systems might acquire CSPs. First, CSPs might be strategically useful in some training environments. Evolutionary game theorists have studied how CSPs like spite (Hamilton 1970; Possajennikov 2000; Gardner and West 2004; Forber and Smead 2016) and aggression towards out-group members (Choi and Bowles 2007) can be selected for. Analogous selection pressures could appear in AI training.[7] For example, selection for the agents that perform the best relative to opponents creates similar pressures to the evolutionary pressures hypothetically responsible for spite: Agents will have reason to sacrifice absolute performance to harm other agents, so that they can increase the chances that their relative score is highest. So, identifying and removing training environments which incentivize CSPs (while not affecting agents’ competitiveness) is one direction for intervention.
Second, CSPs might result from poor generalization from human preference data. An AI might fail to correct for biases that cause a human to behave in a more conflict-conducive way than they would actually endorse, for instance. Inferring human preferences is hard. It is especially difficult in multi-agent settings, where a preference-inferrer has to account for a preference-inferree’s models of other agents, as well as biases specific to mixed-motive settings.[8]
Finally, a generic direction for preventing CSPs is developing adversarial training and interpretability methods tailored to rooting out conflict-seeking behavior.
Appendix: Full rational conflict taxonomy
Here we present our complete taxonomy of causes of costly conflict between rational agents, and give an informal argument that it is exhaustive. (Remember that by “rational” we mean “maximizes subjective expected utility” and by “costly conflict” we mean “inefficient outcome”. ) See here for a draft where we try to formalize this.
For the purposes of the informal exposition, it will be helpful to distinguish between equilibrium-compatible and equilibrium-incompatible conflict. Equilibrium-compatible conflicts are those which are naturally modeled as occurring in some (Bayesian) Nash equilibrium. That is, we can model them as resulting from agents (i) knowing each others’ strategies exactly (modulo private information) and (ii) playing a best response. Equilibrium-incompatible conflicts cannot be modeled in this way. Note, however, that the equilibrium-compatible conditions for conflict can hold even when agents are not in equilibrium.
- Equilibrium-compatible cases
- Private information and no incentive/ability to disclose
- Inability to credibly commit to a cooperative outcome
- Indivisibility and inability to randomize
- Don’t play efficient equilibrium even when available
- Equilibrium-incompatible cases
- Miscoordination
- Perceived risk of cooperation-punishers
This breakdown is summarized as a fault tree diagram in Figure 1.
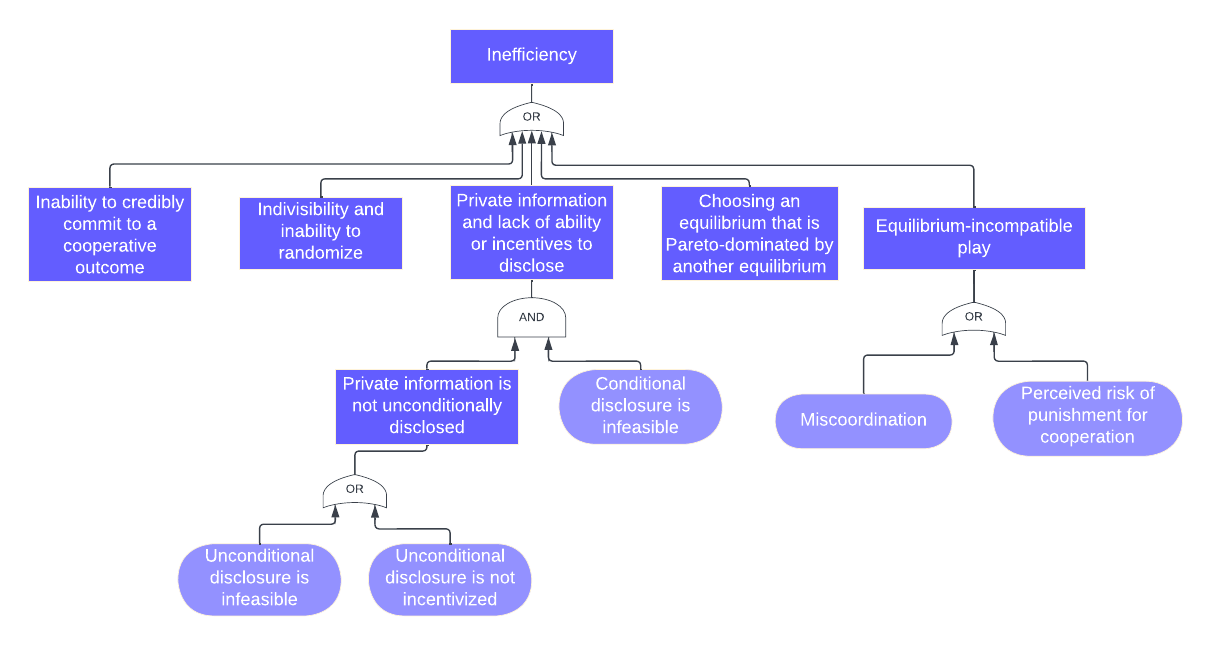
Figure 1: Fault tree diagram for inefficient outcomes between rational agents.
Equilibrium-compatible cases
Here is an argument that items 1a-1c capture all games in which conflict occurs in every (Bayesian) Nash equilibrium. To start, consider games of complete information. Some complete information games have only inefficient equilibria. The Prisoner’s Dilemma is the canonical example. But we also know that any efficient outcome that is achievable by some convex combination of strategies and is better for each player that what they can unilaterally guarantee themselves can be attained in equilibrium, when agents are capable of conditional commitments to cooperation and correlated randomization (Kalai et al. 2010). This means that, for a game of complete information to have only inefficient equilibria, it has to be the case that either they are unable to make credible conditional commitments to an efficient profile (1b) or an efficient and individually rational outcome is only attainable with randomization (because the contested object is indivisible), but randomization isn’t possible (1c).
Even if efficiency in complete information is always possible given commitment and randomization ability, players might not have complete information. It is well-known that private information can lead to inefficiency in equilibrium, due to agents making risk-reward tradeoffs under uncertainty about their counterpart’s private information (1a). It is also necessary that agents can’t or won’t disclose their private information — we give a breakdown of reasons for nondisclosure below [LW · GW].
This all means that a game has no efficient equilibria only if one of items 1a-1c holds. But it could still be the case that agents coordinate on an inefficient equilibrium, even if an efficient one is available (1d). E.g., agents might both play Hare in a Stag Hunt. (Coordinating on an equilibrium but failing to coordinate on an efficient one seems unlikely, which is why we don’t discuss it in the main text. But it isn’t ruled out by the assumptions of accurate beliefs and maximizing expected utility with respect to those beliefs alone.)
Equilibrium-incompatible cases
This exhausts explanations of situations in which conflict happens in equilibrium. But rationality does not imply that agents are in equilibrium. How could imperfect knowledge of other players’ strategies drive conflict? There are two possibilities:
- (Item 2a) Each player is “trying” to coordinate on an efficient equilibrium, in the sense that they place nonzero credence on an efficient outcome, but they miscoordinate. For example, a game of Chicken where both players think it’s sufficiently likely that their counterpart plays Swerve that it is optimal for them to Dare.
- (Item 2b) At least one player is not “trying” to coordinate on an efficient equilibrium, in the sense that they play a strategy that is not compatible with any efficient equilibrium. For example, consider a modified Prisoner’s Dilemma where each agent can unilaterally make the other agent worse off than (Defect, Defect) (“punish”). In an open-source version of such a game, an agent might play DefectBot, eliminating the possibility of efficiency. Why might this happen, when they could instead play FairBot? The player might place some credence on their counterpart punishing FairBot, but playing defect against DefectBot. This “perceived risk of cooperation-punishers” is the only reason that agents with access to conditional commitments and uncertainty about their counterpart’s decision would play a strategy that cannot achieve efficient outcomes against any strategy. This situation is implausible, but not ruled out by minimal rationality assumptions.
Reasons agents don’t disclose private information
Suppose that agents have private information such that nondisclosure of the information will lead to a situation in which conflict is rational, but conflict would no longer be rational if the information were disclosed.
We can decompose reasons not to disclose into reasons not to unconditionally disclose and reasons not to conditionally disclose. Here, “conditional” disclosure means “disclosure conditional on a commitment to a particular agreement by the other player”. For example, suppose my private information is , where measures my military strength, such that is my chance of winning a war, and is information about secret military technology that I don’t want you to learn. A conditional commitment would be: I disclose , so that we can decide the outcome of the contest according to a costless lottery which I win with probability , conditional on a commitment from you not to use your knowledge of to harm me.
Here is the decomposition:
- Agents do not unconditionally disclose their private information. This could happen for two reasons:
- The agents are not able to disclose their private information; e.g., it is computationally intractable.
- The agents are able to disclose their private information, but lack the incentive to do so. Sometimes the mere possibility of unconditional disclosure is enough for unconditional disclosure to be incentivized, due to the “unraveling” argument.[9] But the conditions for unraveling don’t always hold, even when unconditional disclosure is feasible.
- (We can further distinguish between incentive/ability to partially or fully disclose private information. Partial disclosure will often be incentivized when full disclosure is not. For example, the unraveling argument goes through for our example above if I can disclose without disclosing . But restricting the amount of information disclosed may be difficult.)
- Agents do not conditionally disclose their private information. Unlike unconditional disclosure, which may not be incentivized even if it is feasible, there is always an efficient equilibrium available to agents with conditional disclosure and commitment ability (DiGiovanni and Clifton 2022). So failure to conditionally disclose private information must be due to its infeasibility.
References
Abreu, Dilip, and Rajiv Sethi. 2003. “Evolutionary Stability in a Reputational Model of Bargaining.” Games and Economic Behavior 44 (2): 195–216.
Babcock, Linda, and George Loewenstein. 1997. “Explaining Bargaining Impasse: The Role of Self-Serving Biases.” The Journal of Economic Perspectives: A Journal of the American Economic Association 11 (1): 109–26.
Bazerman, Max H., and Margaret A. Neale. 1986. “Heuristics in Negotiation: Limitations to Effective Dispute Resolution.” In Judgment and Decision Making: An Interdisciplinary Reader , (pp, edited by Hal R. Arkes, 818:311–21. New York, NY, US: Cambridge University Press, xiv.
Choi, Jung-Kyoo, and Samuel Bowles. 2007. “The Coevolution of Parochial Altruism and War.” Science 318 (5850): 636–40.
DiGiovanni, Anthony, and Jesse Clifton. 2022. “Commitment Games with Conditional Information Revelation.” arXiv [cs.GT]. arXiv. http://arxiv.org/abs/2204.03484.
Fearon, James D. 1995. “Rationalist Explanations for War.” International Organization 49 (3): 379–414.
Forber, Patrick, and Rory Smead. 2016. “The Evolution of Spite, Recognition, and Morality.” Philosophy of Science 83 (5): 884–96.
Gardner, A., and S. A. West. 2004. “Spite and the Scale of Competition.” Journal of Evolutionary Biology 17 (6): 1195–1203.
Grossman, Sanford J. 1981. “The Informational Role of Warranties and Private Disclosure about Product Quality.” The Journal of Law and Economics 24 (3): 461–83.
Hamilton, W. D. 1970. “Selfish and Spiteful Behaviour in an Evolutionary Model.” Nature 228 (5277): 1218–20.
Milgrom, Paul R. 1981. “Good News and Bad News: Representation Theorems and Applications.” The Bell Journal of Economics 12 (2): 380–91.
Oesterheld, Caspar, and Vincent Conitzer. 2021. “Safe Pareto Improvements for Delegated Game Playing.” In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, 983–91. andrew.cmu.edu.
Possajennikov, Alex. 2000. “On the Evolutionary Stability of Altruistic and Spiteful Preferences.” Journal of Economic Behavior & Organization 42 (1): 125–29.
Shulman. 2010. “Omohundro’s ‘basic AI Drives’ and Catastrophic Risks.” Manuscript.(singinst. Org/upload/ai-Resource-Drives. Pdf. http://www.hdjkn.com/files/BasicAIDrives.pdf.
Stastny, Julian, Maxime Riché, Alexander Lyzhov, Johannes Treutlein, Allan Dafoe, and Jesse Clifton. 2021. “Normative Disagreement as a Challenge for Cooperative AI.” arXiv [cs.MA]. arXiv. http://arxiv.org/abs/2111.13872.
- ^
Defining conflict in terms of “inefficiency” is arguably a limitation of this approach, since it doesn’t hone in on particularly bad conflicts, and doesn’t distinguish between cases where agents behaved inefficiently but still managed to avoid catastrophic conflict (e.g., agents who implement Yudkowsky's approach to bargaining [LW · GW]).
- ^
The choice of decision theory (CDT, EDT, UDT, etc) used in computing these expectations shouldn’t change anything qualitative about the taxonomy. However, some decision theories may avoid conflict more often than others. (E.g., EDT cooperates in the Prisoner’s Dilemma against sufficiently correlated counterparts, while CDT doesn’t.)
- ^
Informational and commitment inability problems are two of the three “rationalist explanations for war”. Fearon’s third rationalist explanation for war is issue indivisibility: For instance, it may be rational for two factions to go to war over an indivisible holy site, if there are no side payments that can compensate either faction for losing the site. However, we claim that if rational agents engage in conflict due to issue indivisibility, then conflict is not inefficient for them. We’ll look at such cases in the next subsection. Lastly, our taxonomy includes miscoordination, which Fearon’s taxonomy doesn’t. Fearon assumes that agents coordinate on a Pareto optimal equilibrium when at least one exists. We only assume that agents maximize subjective expected utility, which need not result in them playing a Nash equilibrium.
- ^
These are referred to as “commitment problems” in the international relations literature, but we say “commitment inability problems” to clearly distinguish from the problem of “incompatible commitments” that we also discuss.
- ^
Abreu and Sethi (2003) show how a subpopulation of agents with such preferences can be evolutionarily stable in a simple model of bargaining, when there are costs to being more “rational”.
- ^
Credit to Carl Shulman and Lukas Gloor for emphasizing this intervention.
- ^
For this reason, some of us at CLR have recently been looking into evolutionary explanations for preferences like spite and whether these explanations might apply to some kinds of AI training.
- ^
Humans have biases specific to multi-agent settings (e.g., the “fixed-pie error” (Bazerman and Neale 1986) and “self-serving bias” (Babcock and Loewenstein 1997)). All of this makes it plausible that AI systems could mistakenly attribute human behavior to conflict-seeking preferences (e.g., mistaking fixed-pie error for spite), even when they have good models of human preferences in other settings.
- ^
The unraveling argument goes roughly like this: Players assume that other players are weak, when they haven’t revealed their private information. The players with the “strongest” private information (e.g., highest strength in combat, or resolve, or commitment credibility) will reveal their private information, because this will cause weaker agents to give in without a fight. Then, because the next-strongest players are known not to be the strongest, they have nothing to gain from hiding their information, and prefer to reveal so that counterpart agents who are sufficiently weak will decide not to fight. This happens with the next-strongest players, and so on (Grossman 1981; Milgrom 1981).
5 comments
Comments sorted by top scores.
comment by MichaelStJules · 2022-09-23T06:52:45.018Z · LW(p) · GW(p)
One reason for optimism about AGI conflict is that AGIs may be much better at credible commitment and disclosure of private information. For example, AGIs could make copies of themselves and let their counterparts inspect these copies until they are satisfied that they understand what kinds of commitments their counterpart has in place.
Basic question: how would you verify that you got a true copy, and not a fake?
Replies from: antimonyanthony, MichaelStJules↑ comment by Anthony DiGiovanni (antimonyanthony) · 2022-09-24T10:05:23.874Z · LW(p) · GW(p)
I think this is an important question, and this case for optimism can be a bit overstated when one glosses over the practical challenges to verification. There's plenty of work on open-source game theory out there, but to my knowledge, none of these papers really discuss how one agent might gain sufficient evidence that it has been handed the other agent's actual code.
We wrote this part under the assumption that AGIs might be able to just figure out these practical challenges in ways we can't anticipate, which I think is plausible. But of course, an AGI might just as well be able to figure out ways to deceive other AGIs that we can't anticipate. I'm not sure how the "offense-defense balance" here will change in the limit of smarter agents.
Replies from: MichaelStJules, MichaelStJules↑ comment by MichaelStJules · 2023-09-27T00:15:57.690Z · LW(p) · GW(p)
Hmm, if A is simulating B with B's source code, couldn’t the simulated B find out it's being simulated and lie about its decisions or hide what its actual preferences? Or would its actual preferences be derivable from its weights or code directly without simulation?
↑ comment by MichaelStJules · 2023-08-31T09:31:43.281Z · LW(p) · GW(p)
An AGI could give read and copy access to the code being run and the weights directly on the devices from which the AGI is communicating. That could still be a modified copy of the original and more powerful (or with many unmodified copies) AGI, though. So, the other side may need to track all of the copies, maybe even offline ones that would go online on some trigger or at some date.
Also, giving read and copy access could be dangerous to the AGI if it doesn't have copies elsewhere.
↑ comment by MichaelStJules · 2022-09-23T14:52:59.581Z · LW(p) · GW(p)
When I think about digital signatures, the AGI would need to not know its private key or be able to share access to its channel to sign with. I think they would need a trusted and hard to manipulate third party to verify or provide proof, e.g. a digital signature on the model, or read-only access to where the model is held + history. I suppose this could just be a server the AGI is running on, if it is run by such a third party, but it might not be.