Optimum number of single points of failure
post by Douglas_Reay · 2018-03-14T13:30:22.222Z · LW · GW · Legacy · 5 commentsContents
1. Optimum number of single points of failure Links to all the articles in the series: Links to the parts of this article: Optimum number of single points of failure What is a Single Point of Failure? How can SPOFs be avoided? The price of avoiding SPOFs Finding the optimum number of SPOFs None 5 comments
1. Optimum number of single points of failure
Summary of entire Series: An alternative approach to designing Friendly Artificial Intelligence computer systems.
Summary of this Article: The number of unnecessary Single Points of Failure in your design should be minimised; but some of them are too expensive to be worth getting rid of, so the optimum number of SPOFs isn't always zero.
Links to all the articles in the series:
- Optimum number of single points of failure
- Don't put all your eggs in one basket
- Defect or Cooperate
- Environments for killing AIs
- The advantage of not being open-ended
- Trustworthy Computing
- Metamorphosis
- Believable Promises
Links to the parts of this article:
- What is a Single Point of Failure?
- How can SPOFs be avoided?
- The price of avoiding SPOFs
- Finding the optimum number of SPOFs
Optimum number of single points of failure
What is a Single Point of Failure?
Think of a bridge, constructed from metal struts, held together by bolts:
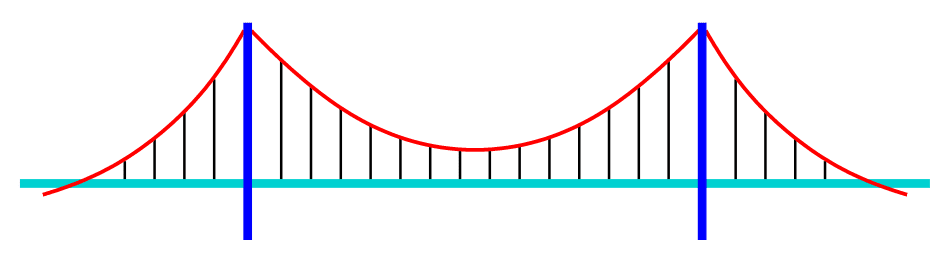
A particular connection, holding two struts together, might fail for any number of reasons. The bolt might be rusty. Someone might deliberately unscrew the bolt. A stray bullet might hit it.
If breaking the structure at a particular point, while all the other bits remain unbroken, is sufficient to cause the bridge to fall down, then that point is known as a Single Point Of Failure (SPOF). A structure can have multiple SPOFs. Indeed, with some structures, every point in the structure, is a SPOF. Like a house of cards, remove just one card, any of the cards, and it all falls down:

We can extend the idea from structures to systems and plans. An SPOF is something which, if it fails, stops the entire system from working, or loses you the entire game.
Here are some examples:
- A communications network linking computers together via a single central router. If that one router fails, then all communication ceases.
- A small tree care company that has only one wood chipper. If the chipper breaks, the company can't complete its contract in time, and doesn't get paid.
- A military leader whose battle plan requires that a particular position be held and, if the enemy break through, he has no contingency plan or reserves - the whole war is lost.
How can SPOFs be avoided?
In a chain, you have a series of links, where every link is an SPOF. Break just one link, any link, and the weight at the end of the chain drops:
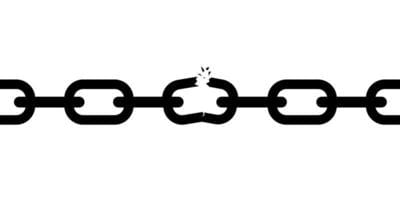
With an 8-ply braided rope, you have 8 strands in parallel. If 1 strand breaks, there are still 7 left to take the strain.

We can, by analogy, coin a rather ugly term "Multiple Point Of Failure", and use it to mean a point that is backed up and won't, just by itself, cause the whole thing to fall. In engineering, the technical name for this sort of 'backing up' is redundancy.
In the case of the suspension bridge at the top, the cable in red is an SPOF. If the cable snaps, the bridge falls. The struts in black, though, if you make each one 10% stronger than it would need to be under ideal conditions, can keep holding the bridge up even if one of them fails. That additional strength is known as the safety margin.
The same technique of putting in additional things in parallel to do the same job, beyond the minimum needed for a no-fail situation, as a safety margin, works for systems and plans as well:
For example:
- Computers can be connected via Mesh Networking
- Companies can keep a stockpile of spares for their most vital components
- Battle plans can make use of the defence in depth strategy
The price of avoiding SPOFs
Making struts stronger than they need to be uses more metal. You have to pay more money to buy them. And they also add weight to the bridge which, in turn may increase the specifications needed for other parts of the bridge that support them.
In theory you could make each strut not just 10% stronger, but 50% stronger, or even 500% stronger, so that 8 out of 10 struts could fail, and yet the bridge would still remain standing. In practice, though, the additional weight often increases the chance of other components failing, so a break even point exists at which adding more struts, or making individual struts stronger and heavier, actually increases the total chance of the bridge falling down. Or, even if it doesn't, the money invested in such an overengineered product would have garnered a better rate of return by purchasing two slightly less reliable products at half the price.
During the Second World War, the German mark VIII Panzer tank was an example of this. It was very strong and tough, but so heavy it couldn't cross bridges, and so expensive that the Allies were able to build several tanks for the same price it cost the Germans to build one of theirs.
The same applies to systems and plans. The more complex a computer system, the more bugs it is likely to contain. The more complex a battle plan, the harder it is for the soldiers to remember, or the fewer soldiers available to implement each part of it. Money a company invests in equipment that it only rarely uses, is money that the company doesn't have available to put to work elsewhere, and that it has to pay interest upon if the money was borrowed.
Finding the optimum number of SPOFs
In failure analysis, one method of working this out analytically is to construct a matrix that records, for each point, the probability of it failing, the relative severity of the consequences of it failing, and how those change with each dollar spent in improving the safety margin for that point. The optimum is reached when you can't decrease the expected total severity of failure by moving dollars from one area to another.
But that leaves open the question of how many dollars it makes sense to invest in reliability; especially when the severity of the consequences are measured not only in dollars, but also in time or lives.
If you are writing a flight simulation computer game, the likely consequence of it failing is that the game crashes, wasting hundreds of minutes of one person's playing time.
If you are writing an air traffic control system, the likely consequence of it failing is that a real aeroplane crashes, wasting hundreds of lives.
In the latter case, you might want to spend millions of dollars using N-version programming, which is where you give a specification to multiple teams, and each team independently codes up a piece of software implementing the specification. You can then poll each version, asking it which way you should tell a particular aeroplane to move, and go with the majority vote.
In the former case, the amount that the increase in reliability would increase your profits from selling the game would be unlikely to recoup the millions you spent to increase the reliability that amount. It would be an example of overengineering.
Sometimes overengineering is a good thing, if not from the perspective of the investors, then from the perspective of the people benefiting from the product. The Victorians are famous for their massive sewers and overengineered cast iron sea side piers, that withstand wars, fires or even, on one occasion, 10 failed attempts by a demolition crew to blow it up. They built to last and later generations benefited from that because, unlike tanks in a war or a structure needed only for a particular event, there is no product 'end of usefulness' lifetime. Even after 100 years, people still benefit from having sewers in their cities to dispose of waste.
The cheaper it is to avoid having a particular SPOF in your design, the more likely it is to be worth while doing so.
But, in general, the optimum number of SPOFs is rarely zero.
The next article in this series is: Don't put all your eggs in one basket
5 comments
Comments sorted by top scores.
comment by Douglas_Reay · 2018-03-14T13:33:23.702Z · LW(p) · GW(p)
The other articles in the series have been written, but it was suggested that rather than posting a whole series at once, it is kinder to post one part a day, so as not to flood the frontpage.
So, unless I hear otherwise, my intention is to do that and edit the links at the top of the article to point to each part as it gets posted.
Replies from: habryka4↑ comment by habryka (habryka4) · 2018-03-14T19:22:56.380Z · LW(p) · GW(p)
Seems great!
We sadly don't currently support in-article links without admin intervention, so you might have to remove the ToC at the top for now. It would be good to make that work properly, but we probably won't get around to it for a few weeks or so.
comment by Gordon Seidoh Worley (gworley) · 2018-03-14T19:39:39.220Z · LW(p) · GW(p)
I agree with your thesis, but this seems generally true of any engineering problem. Is there any sense in which this provides particular insights about building aligned AGI?
(Also maybe this is just getting us ready for later content, in which case it not being particularly about build aligned AGI yet is expected.)
Replies from: Douglas_Reay↑ comment by Douglas_Reay · 2018-03-14T20:27:14.401Z · LW(p) · GW(p)
> Also maybe this is just getting us ready for later content
Yes, that is the intention.
Parts 2 and 3 now added (links in post), so hopefully the link to building aligned AGI is now clearer?
comment by Douglas_Reay · 2023-04-12T13:33:31.639Z · LW(p) · GW(p)
This post is referenced by https://wiki.lesswrong.com/wiki/Lesswrongwiki:Sandbox#Image_Creative_Commons_Attribution
Please take care when editing it.