Whisper's Wild Implications
post by Ollie J (Rividus) · 2023-01-03T12:17:28.600Z · LW · GW · 6 commentsContents
Scaling Language Models Language Models Are Hungry Whisper YouTube Podcasts Phone Calls Problems How should this revise our forecasts? None 6 comments
Acknowledgements: I wrote this report as part of a paid work-trial with Epoch AI.
Epistemic status: Approximating the discount rates was very difficult; I decided on them after several discussions with people working in relevant fields. I expect the audience to have different discount rates, but hopefully within an OOM.
TLDR; to address the data shortage for large language models, I look at how OpenAI's Whisper can be used to obtain large amounts of new data.
Scaling Language Models
2020 saw the release of GPT-3 by OpenAI, seen as a breakthrough due to its zero-shot performance on benchmarks and colossal parameter count. OpenAI chose to use a dataset of 300 billion tokens and unknowingly set the precedent of how future language models (LMs) would be trained. Recent publications have seen very little attention paid to the dataset; all of the hype is centred around how many parameters the model has.
In 2022, DeepMind forced the natural language processing (NLP) community to reconsider how they approached scaling LMs. Principally, they showed that much more significance had to be placed on scaling the dataset. They modelled a LMs loss L as a function of it’s number of parameters N and training tokens D, and solved for the constants by training a variety of models:
Applying this on modern LMs gives some shocking results; GoogleBrain’s PaLM, with 540B parameters and 780 billion tokens, was trained sub-optimally and has a loss L similar to that of Chinchilla’s best model. Chinchilla only has 70B parameters and was trained for a fraction of the price. How badly do other models fare?
Language Models Are Hungry
Every NLP presentation in the last five years has shown the classic graph of parameter count over time, with a nice curve showing the exponential growth. The graph below is a little different; I show the dataset size, in tokens[1], that every model used, and compare it with the optimal size that such models require, as calculated by Deepmind's approximation[2]:
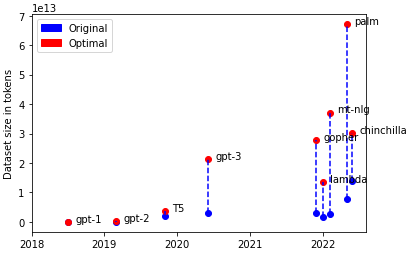
To train GoogleBrain’s PaLM optimally, we’d require a dataset of 6.7T tokens, 859% the size of the original dataset.
Previous work [LW · GW] has been done in estimating how much quality text data there is, which estimated it to be ~3.2T tokens[3], with a breakdown for each domain category here. The largest categories (in tokens) were:
- News (en), 676B
- Books, 560B
- MassiveWeb, 506B
- GitHub, 422B
- Conversations (multiling), 390B
This isn’t fantastic. Whilst this doesn’t contain all publicly-available repositories of text, I believe this is at least within an order of magnitude. If we wish to continue scaling at such a rapid pace, then we’re going to either find more efficient learning algorithms, or a lot more data.
Are there other sources of public data we haven’t yet considered?
Whisper
OpenAI recently released Whisper; a transformer-based model that’s proficient in automatic speech recognition (ASR):
- They successfully used weakly supervised pretraining to scale the dataset
- No finetuning was used when evaluating on datasets, allowing it to easily be applied to any dataset using zero-shot
- Whisper can solve a variety of tasks: transcription, translation, voice activity detection, alignment, language identification, and more
- Whisper’s performance is close to that of professional human transcribers
- OpenAI released the model weights
The success of Whisper leaves us with an important question: if we had access to a Whisper-like model that perfectly performed ASR, could we apply it to create large text datasets to alleviate our data shortage? In the following sections I'll assume Whisper is always correct; I will address this assumption later.
YouTube
YouTube contains a wealth of educational videos, lectures, and Minecraft gaming videos. A significant proportion of videos have a commentator, or conversation between people. Just how much text data could we get if we applied Whisper?
After some digging, I found a crude breakdown of the number of hours of video uploaded to YouTube every minute, per year since 2007:
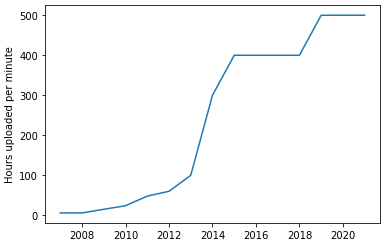
This gives us an average of ~250 hours of content uploaded every minute for 15 years, or 1.971 billion hours in total. That’s 225,000 years of videos.
Taking a discount rate of 5% of content to be publicly available and high enough quality, and the average commentary/conversation having 150 words a minute, that gives us 1.8T tokens. This would be huge; having access to this data would immediately increase the size of our max dataset by over half!
I predict that we’ll continue to see an increase in the amount of uploaded content (despite the jump during covid), which will raise the average number of YouTube hours/minute over the next few years to 600. This will give us 284 billion more tokens per year.
Podcasts
Podcasts contain conversation on a huge variety of topics, which is perfect for our desires. Unfortunately there is a lot of music, often for the purpose of meditation, but despite this our discount factor here will be better than before.
Looking at the largest competitors in the field, and only publicly-available episodes, I got the following stats:
- Spotify, 4m podcasts with unknown number of episodes
- The Podcast Index, 4m podcasts with 75.7m episodes
- Apple Podcasts Catalogue, 2.5m podcasts with 71m episodes. Allegedly more exist, but are not available through valid feeds due to feed-episode limits
Taking the above into account, and the fact that episodes may be on more than one platform, I'll take 100m publicly available podcasts with an average length of 39 minutes. This gives us 65m hours of audio, or 7,420 years. With a discount factor of 10%, that gives us 6.5m hours of audio, or 117B tokens.
Around 700 episodes are uploaded to Apply every day, and 5400 to The Podcast Index. If we say 6000 unique episodes will be uploaded every day with the previous assumptions, this gives us 2.6B new tokens every year. Not fantastic.
Phone Calls
Last year alone, 227 billion minutes of phone calls were made by UK users:
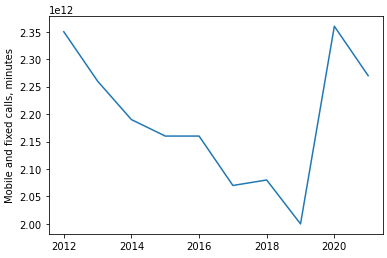
There is a steady decline over the years, despite the number of mobile subscriptions slightly increasing over the same timeframe. This could be due to the shift towards alternative forms of online communication, such as Skype and Zoom. Covid-19 reversed this decline in 2020, and will leave a permanent impact due to the shift to remote work, but I expect this decline to continue.
If the UK prime minister is fanatical about scaling LMs, they might be interested in tapping every call and using Whisper to transcribe what was said. With a harsh discount rate of 1%, we get an estimate of 681B tokens per year. That’s an insane amount of data for a country with a relatively small population, and by factoring in other online platforms we could easily double this.
Problems
It’s time I addressed our key assumption of Whisper acting perfectly. Whisper is fantastic; people have applied it for automatic podcast transcription, better voice-call captioning and more. However, through some personal experimentation, it often fails to capture slang, heavy accents and unclear speech. Having incorrect or missing words will prove harmful[4] for the task of language modelling. Additionally, underperforming on slang and specific accents could lead entire groups to be underrepresented in the resulting dataset.
There is also the question of using semi-synthetic data to train other models. Whilst using synthetic data has proven successful in other domains, notably computer vision, attempting it with language may prove more difficult due to examples being less robust to modification. An image may contain hundreds of thousands of pixels, so smaller mistakes are often difficult to notice, but a sentence may only contain a few words. Having the wrong word may make the sentence syntactically or semantically incorrect. Filtering examples using heuristics may remove some obvious errors.
Additionally, applying Whisper to the entirety of YouTube and similar platforms is a problem in itself. Initial research has shown that transcribing 1000 hours of audio in Google Colab (1x A100 40GB) with a batch size of 32 costs ~$20. Naively applying this methodology to our downsampled YouTube results in a cost of just under $2,000,000. Furthermore, attempting this could bring you into conflict with Google. I quickly skimmed their TOS and I don’t see anything against this, but I doubt they would remain neutral while you scrape the entirety of their platform.
How should this revise our forecasts?
This research made me move towards shorter timelines that depend on LM capabilities; better ASR models will be developed over the coming years, that will allow for higher-quality data to be obtained.
I also believe that more weight should be placed on larger organisations, or countries, leading AI progress in >5 years time. If data continues to be a limiting factor, they will have a decisive advantage over other organisations due to having access to copious amounts of private data.
- ^
From here I start talking about tokens a lot. There exist many different tokenization methods, I will assume two tokens = one word
- ^
Not sure why the image isn't centred, it appears centred in edit mode
- ^
From the time of writing, a paper has been released that is a lot more optimistic in language dataset sized
- ^
Or could it make the model better by forcing the model to be robust against noise, similar to denoising autoencoders?
6 comments
Comments sorted by top scores.
comment by Dave Orr (dave-orr) · 2023-01-03T19:00:14.231Z · LW(p) · GW(p)
I predict that instead of LLMs being trained on ASR-generated text, instead they will be upgraded to be multimodal, and trained on audio and video directly in addition to text.
Google has already discussed this publicly, e.g. here: https://blog.google/products/search/introducing-mum/.
This direction makes sense to me, since these models have huge capacity, much greater than the ASR models do. Why chain multiple systems if you can learn directly from the data?
I do agree with your underlying point that there's massive amounts of audio and video data that haven't been used much yet, and those are a great and growing resource for LLM training.
comment by ChristianKl · 2023-01-04T15:30:13.384Z · LW(p) · GW(p)
There is also the question of using semi-synthetic data to train other models. Whilst using synthetic data has proven successful in other domains, notably computer vision, attempting it with language may prove more difficult due to examples being less robust to modification.
That's true for some language tasks but not for others. As long as you need human judgment to evaluate the generated language it's
There seems to be a model that checks whether the outputs of ChatGPT violate content rules and then adds those rule-violating examples into the training set for ChatGPT. While there are humans in the loop that prompt ChatGPT and provide some direction and try to find edge cases, but this is essentially semi-synthethic data generation.
If I would be OpenAI then I would put a lot of attention on trying to figure out how to convert examples where ChatGPT does make content errors and notices it because of the answer of the human chatting with it to be new training data.
One of the reasons why OpenAI made ChatGPT freely available to everyone despite the huge compute costs might be that they want it to be used to get more training data.
When an ChatGPT like system gets linked to a console and told to do multi-step tasks, it will sometimes fail with the tasks and likely be able to frequently tell when it fails. Once it has a valid 20-step way to solve a given task it could also synthesize a 10-step way to solve the same task and create training data out of it.
One possible task might be: Take all the biomedical literature and make Wikidata statements out of it. Over at Google it would be "make Knowledge graph statements out of it".
If the UK prime minister is fanatical about scaling LMs, they might be interested in tapping every call and using Whisper to transcribe what was said. With a harsh discount rate of 1%, we get an estimate of 681B tokens per year. That’s an insane amount of data for a country with a relatively small population, and by factoring in other online platforms we could easily double this.
That assumes the UK only taps UK calls. Historically the UK tapped the US calls and the US tapped the UK calls and then they exchanged data so that no intelligence service would violate the domestic laws.
I would expect that there's a Five Eye project going on to train a model that does use decades of international call data.
comment by Ethan Caballero (ethan-caballero) · 2023-01-04T02:12:24.300Z · LW(p) · GW(p)
re: youtube estimates
You'll probably find some of this twitter discussion useful:
https://twitter.com/HenriLemoine13/status/1572846452895875073
comment by Vladimir_Nesov · 2023-01-03T18:46:06.759Z · LW(p) · GW(p)
Would better token prediction loss help towards AGI? I wonder if scaling is no longer relevant given existing level of performance of ChatGPT, that there is already some token prediction loss overhang. Missing things needed to make LLMs autonomously productive (mainly to plan/develop their own training, assemble datasets) are probably unrelated, prediction loss that's even better won't help with them.
comment by LGS · 2023-01-04T21:33:54.259Z · LW(p) · GW(p)
What is it, exactly, that you want GPT3 to learn from YouTube videos?
If you doubled the data GPT3 has access to while keeping the quality of the data the same, that would be something. It will give you real progress.
However, if you doubled the data GPT3 has access to, but the new data contained 0 new code and 0 new math and 0 new medical facts, then surely the new version of GPT3 will not improve at coding, nor at math, nor at medicine. Sure, GPT3 also needs to learn to read English very well before it can learn the math/coding/etc... but it already knows English! Its understanding of English won't actually improve with YouTube transcripts; it is already near-perfect. All GPT3 will improve at is predicting the type of text that is found on YouTube.
So: how much code and math do you expect to find on YouTube transcripts? How many technical medical facts?
Actually, the situation is even worse than this. Transcription will fail exactly for the type of code, math, and technical jargon that GPT3 is unfamiliar with; that's because the transcription is based on a language model. Exactly when you need to learn something from the next token, the transcription of that next token will be wrong.
People here focus too much on "data". What you need is not data, it's high-quality data. If you want GPT to be good at math, you need more math data; if you want it to be good at poetry, more poetry data. And sure, if you really want GPT to be good at phone calls, give it phone call data. (But why?)
Chinchilla is misleading you because when they scaled up their data, they first shuffled it, so when they trained on (e.g.) 10% of their data, that also meant 10% of their math data, 10% of their code data, etc.
comment by Rodrigo Heck (rodrigo-heck-1) · 2023-01-03T21:12:06.371Z · LW(p) · GW(p)
A better approach IMO is to directly tokenize audio and then find a clever way to align text tokens with audio tokens during training, without relying on 100% transcription.