is gpt-3 few-shot ready for real applications?
post by nostalgebraist · 2020-08-03T19:50:09.740Z · LW · GW · 5 commentsContents
5 comments
This is a lengthy reply to @the-moti‘s post here. Creating a new post to limit thread length, and so I can crosspost to LW.
@the-moti says, in part:
This obviously raises two different questions: 1. Why did you think that no one would use few-shot learning in practice? 2. Why did other people think people would use few-shot learning in practice?
I would be interested in hearing your thoughts on these two points.
—
Thanks for asking!
First of all, I want to emphasize that the GPT-3 paper was not about few-shot GPT-3 as a practical technology.
(This is important, because the paper is the one large body of quantitative evidence we have on few-shot GPT-3 performance.)
This is not just my take on it: before the OpenAI API was announced, all the discussion I saw took for granted that we were talking about a scientific finding and its broader implications. I didn’t see any commentator whose main takeaway was “wow, if I could do this few-shot thing right now, I could build amazing projects with it.”
Indeed, a common [LW(p) · GW(p)] theme [LW(p) · GW(p)] in critical commentary on my post was that I was too focused on whether few-shot was useful right now with this specific model, whereas the critical commentators were more focused on the implications for even larger models, the confirmation of scaling laws over a new parameter regime, or the illustration-in-principle of a kind of meta-learning. Gwern’s May newsletter is another illustrative primary source for the focus of the discussion in this brief “pre-API” period. (The API was announced on June 11.)
As I read it (perhaps benefitting from hindsight and discussion), the main points of the paper were
(1) bigger models are better at zero/few-shot (i.e. that result from the GPT-2 paper holds over a larger scale),
(2) more “shots” are better when you’re doing zero/few-shot,
(3) there is an interaction effect between 1+2, where larger models benefit more from additional “shots,”
(4) this could actually become a practical approach (even the dominant approach) in the future, as illustrated by the example of a very large model which achieves competitive results with few-shot on some tasks
The paper did not try to optimize its prompts – indeed its results are already being improved upon by API acolytes – and it didn’t say anything about techniques that will be common in any application, like composing together several few-shot “functions.” It didn’t talk about speed/latency, or what kind of compute backend could serve many users with a guaranteed SLA, or how many few-shot “function” evaluations per user-facing output would be needed in various use cases and whether the accumulated latency would be tolerable. (See this post on these practical issues.)
It was more of a proof of concept, and much of that concept was about scaling rather than this particular model.
—
So I’d argue that right now, the ball is in the few-shot-users’ court. Their approach might work – I’m not saying it couldn’t!
In their favor: there is plenty of room to further optimize the prompts, explore their composability, etc.
On the other hand, there is no body of evidence saying this actually works. OpenAI wrote a long paper with many numbers and graphs, but that paper wasn’t about whether their API was actually a good idea. (That is not a criticism of the paper, just a clarification of its relevance to people wondering whether they should use the API.)
This is a totally new style of machine learning, with little prior art, running on a mysterious and unproven compute backend. Caveat emptor!
—
Anyway, on to more conceptual matters.
The biggest advantages I see in few-shot learning are
(+1) broad accessibility (just type English text) and ability to quickly iterate on ideas
(+2) ability to quickly define arbitrary NLP “functions” (answer a factual question, tag POS / sentiment / intent, etc … the sky’s the limit), and compose them together, without incurring the memory cost of a new fine-tuned model per function
What could really impress me is (+2). IME, it’s not really that costly to train new high-quality models: you can finetune BERT on a regular laptop with no GPU (although it takes hours), and on ordinary cloud GPU instances you can finetune BERT in like 15 minutes.
The real cost is keeping around an entire finetuned model (~1.3GB for BERT-large) for each individual NLP operation you want to perform, and holding them all in memory at runtime.
The GPT-3 approach effectively trades this memory cost for a time cost. You use a single very large model, which you hope already contains every function you will ever want to compute. A function definition in terms of this model doesn’t take a gigabyte to store, it just takes a tiny snippet of text/code, so you can store tons of them. On the other hand, evaluating each one requires running the big model, which is slower than the task-specific models would have been.
So storage no longer scales badly with the number of operations you define. However, latency still does, and latency per call is now much larger, so this might end up being as much of a constraint. The exact numbers – not well understood at this time – are crucial: in real life the difference between 0.001 seconds, 0.1 seconds, 1 second, and 10 seconds will make or break your project.
—
As for the potential downsides of few-shot learning, there are many, and the following probably excludes some things I’ve thought of and then forgotten:
(-1) The aforementioned potential for deal-breaking slowness.
(-2) You can only provide a very small amount of information defining your task, limited by context window size.
The fact that more “shots” are better arguably compounds the problem, since you face a tradeoff between providing more examples of the same thing and providing examples that define a more specific thing.
The extent to which this matters depends a lot on the task. It’s a complete blocker for many creative applications which require imitating many nuances of a particular text type not well represented in the training corpus.
For example, I could never do @nostalgebraist-autoresponder with few-shot: my finetuned GPT-2 model knows all sorts of things about my writing style, topic range, opinions, etc. from seeing ~3.65 million tokens of my writing, whereas few-shot you can only identify a style via ~2 thousand tokens and hope that’s enough to dredge the rest up from the prior learned in training. (I don’t know if my blog was in the train corpus; if it wasn’t, we’re totally screwed.)
I had expected AI Dungeon would face the same problem, and was confused that they were early GPT-3 adopters. But it turns out they actually fine-tuned (!!!!), which resolves my confusion … and means the first real, exciting GPT-3 application out there isn’t actually a demonstration of the power of few-shot but in fact the opposite.
With somewhat less confidence, I expect this to be a blocker for specialized-domain applications like medicine and code. The relevant knowledge may well have been present in the train corpus, but with so few bits of context, you may not be able to overcome the overall prior learned from the whole train distribution and “zoom in” to the highly specialized subset you need.
(-3) Unlike supervised learning, there’s no built-in mechanism where you continually improve as your application passively gathers data during usage.
I expect this to a be a big issue in commercial applications. Often, a company is OK accepting a model that isn’t great at the start, if it has a mechanism for self-improvement without much human intervention.
If you do supervised learning on data generated by your product, you get this for free. With few-shot, you can perhaps contrive ways to feed in segments of data across different calls, but from the model’s perspective, no data set bigger than 2048 tokens “exists” in the same world at once.
(-4) Suffers a worse form of the ubiquitous ML problem that “you get exactly what you asked for.”
In supervised learning, your model will avoid doing the hard thing you want if it can find easy, dumb heuristics that still work on your train set. This is bad, but at least it can be identified, carefully studied (what was the data/objective? how can they be gamed?), and mitigated with better data and objectives.
With few-shot, you’re no longer asking an arbitrary query and receiving, from a devious genie, the response you deserve. Instead, you’re constrained to ask queries of a particular form: “what is the next token, assuming some complicated prior distributed from sub-sampled Common Crawl + WebText + etc.?”
In supervised learning, when your query is being gamed, you can go back and patch it in arbitrary ways. The lower bound on this process comes only from your skill and patience. In few-shot, you are fundamentally lower-bounded by the extent to which the thing you really want can be expressed as next-token prediction over that complicated prior. You can try different prompts, but ultimately you might run into a fundamental bound here that is prohibitively far from zero. No body of research exists to establish how bad this effect will be in typical practice.
I’m somewhat less confident of this point: the rich priors you get out of a large pretrained LM will naturally help push things in the direction of outcomes that make linguistic/conceptual sense, and expressing queries in natural language might add to that advantage. However, few-shot does introduce a new gap between the queries you want to ask and the ones you’re able to express, and this new gap could be problematic.
(-5) Provides a tiny window into a huge number of learned parameters.
GPT-3 is a massive model which, in each call, generates many intermediate activations of vast dimensionality. The model is pre-trained by supervision on a tiny subset of these, which specify probability distributions over next-tokens.
The few-shot approach makes the gamble that this same tiny subset is all the user will need for applications. It’s not clear that this is the right thing to do with a large model – for all we know, it might even be the case that it is more suboptimal the larger your model is.
This point is straying a bit from the central topic, since I’m not arguing that this makes GPT-3 few-shot (im)practical, just suboptimal relative to what might be possible. However, it does seem like a significant impoverishment: instead of the flexibility of leveraging immense high-dimensional knowledge however you see fit, as in the original GPT, BERT, adapters, etc., you get even immenser and higher-dimensional knowledge … presented through a tiny low-dimensional pinhole aperture.
—
The main reason I initially thought “no one would use few-shot learning like this” was the superior generalization performance of fine-tuning. I figured that if you’re serious about a task, you’ll care enough to fine-tune for it.
I realize there’s a certain mereology problem with this argument: what is a “single task,” after all? If each fine-tuned model incurs a large memory cost, you can’t be “serious about” many tasks at once, so you have to chunk your end goal into a small number of big, hard tasks. Perhaps with few-shot, you can chunk into smaller tasks, themselves achievable with few-shot, and then compose them.
That may or may not be practical depending on the latency scaling. But if it works, it gives few-shot room for a potential edge. You might be serious enough about a large task to fine-tune for it … but what if you can express it as a composition of smaller tasks you’ve already defined in the few-shot framework? Then you get it instantly.
This is a flaw in the generalization performance argument. Because of the flaw, I didn’t list that argument above. The list above provides more reasons to doubt few-shot above and beyond the generalization performance argument, and again in the context of “serious” work where you care enough to invest some time in getting it right.
I’d like to especially highlight points like (-2) and (-3) related to scaling with additional task data.
The current enthusiasm for few-shot and meta-learning – that is, for immediate transfer to new domains with an extremely low number of domain examples – makes sense from a scientific POV (humans can do it, why can’t AI?), but strikes me as misguided in applications.
Tiny data is rare in applied work, both because products generate data passively – and because if a task might be profitable, then it’s worth paying an expert to sit down for a day or two and crank out ~1K annotations for supervised learning. And with modern NLP like ELMo and BERT, ~1K is really enough!
It’s worth noting that most of the superGLUE tasks have <10K train examples, with several having only a few hundred. (This is a “low-data regime” relative to the expectations of the recent past, but a regime where you can now get good results with a brainless cookie-cutter finetuning approach, in superGLUE as in the rest of life.)
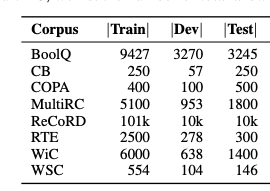
GPT-3 few-shot can perform competitively on some of these tasks while pushing that number down to 32, but at the cost of many downsides, unknowns, and flexibility limitations. Which do you prefer: taking on all those risks, or sitting down and writing out a few more examples?
—
The trajectory of my work in data science, as it happens, looks sort of like a move from few-shot-like approaches toward finetuning approaches.
My early applied efforts assumed that I would never have the kind of huge domain-specific corpus needed to train a model from scratch, so I tried to compose the output of many SOTA models on more general domains. And this … worked out terribly. The models did exactly what they were trained to do, not what I wanted. I had no way to scale, adapt or tune them; I just accepted them and tried to work around them.
Over time, I learned the value of doing exactly what you want, not something close to it. I learned that a little bit of data in your actual domain, specifying your exact task, goes much further than any domain-general component. Your applied needs will be oddly shaped, extremely specific, finicky, and narrow. You rarely need the world’s greatest model to accomplish them – but you need a model with access to a very precise specification of exactly what you want.
One of my proudest ML accomplishments is a system that does something very domain-specific and precisely shaped, using LM-pretrained components plus supervised learning on ~1K of my own annotations. Sitting down and personally churning out those annotations must have been some of the most valuable time I have ever spent at work, ever.
I wanted something specific and finicky and specialized to a very particular use case. So I sat down and specified what I wanted, as a long list of example cases. It took a few days … and I am still reaping the benefits a year later.
If the few-shot users are working in domains anything like mine, they either know some clever way to evade this hard-won lesson, or they have not yet learned it.
—
But to the other question … why are people so keen to apply GPT-3 few-shot learning in applications? This questions forks into “why do end users think this is a good idea?” and “why did OpenAI provide an API for doing this?”
I know some cynical answers, which I expect the reader can imagine, so I won’t waste your time writing them out. I don’t actually know what the non-cynical answers look like, and my ears are open.
(For the record, all of this only applies to few-shot. OpenAI is apparently going to provide finetuning as a part of the API, and has already provided it to AI Dungeon. Finetuning a model with 175M parameters is a whole new world, and I’m very excited about it.
Indeed, if OpenAI can handle the costs of persisting and running finetuned GPT-3s for many clients, all of my concerns above are irrelevant. But if typical client use of the API ends up involving a finetuning step, then we’ll have to revisit the GPT-3 paper and much of the ensuing discussion, and ask when – if not now – we actually expect finetuning to become obsolete, and what would make the difference.)
5 comments
Comments sorted by top scores.
comment by Veedrac · 2020-08-06T20:43:46.301Z · LW(p) · GW(p)
If the issue is the size of having a fine-tuned model for each individual task you care about, why not just fine-tune on all your tasks simultaneously, on one model? GPT-3 has plenty of capacity.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2020-08-08T02:06:12.657Z · LW(p) · GW(p)
People do this a lot with BERT, and it has its own problems -- the first section of this recent paper gives a good overview.
Then of course there is plenty of work trying to mitigate those problems, like that paper . . . but there are still various ways of doing so, with no clear consensus. So a more general statement of few-shot's promise might be "you don't have to worry about which fine-tuning setup you're going to use, out of the many available alternatives, all of which have pitfalls."
Replies from: Veedrac↑ comment by Veedrac · 2020-08-09T00:27:17.176Z · LW(p) · GW(p)
I think the results in that paper argue that it's not really a big deal as long as you don't make some basic errors like trying to fine-tune on tasks sequentially. MT-A outperforms Full in Table 1. GPT-3 is already a multi-task learner (as is BERT), so it would be very surprising if training on fewer tasks was too difficult for it.
comment by Past Account (zachary-robertson) · 2020-08-03T22:45:36.587Z · LW(p) · GW(p)
[Deleted]
Replies from: ESRogs↑ comment by ESRogs · 2020-08-12T00:32:03.516Z · LW(p) · GW(p)
I'd assume a common use pattern will end up being something like: use few-shot, release, collect data, fine-tune, rinse-repeat.
This makes sense to me, and I wonder if we might even see some additional steps, like distilling to a smaller, cheaper model after fine-tuning, or even (at some point, for some problems) generating regular code.