[Interim research report] Activation plateaus & sensitive directions in GPT2
post by StefanHex (Stefan42), jake_mendel · 2024-07-05T17:05:25.631Z · LW · GW · 2 commentsContents
Core results & discussion Proposal: Connecting SAEs to model behaviour Conclusion Appendix Methodology Detailed results 1. Activation Plateaus 2. Sensitive directions 3. Local optima in sensitivity None 2 comments
This part-report / part-proposal describes ongoing research, but I'd like to share early results for feedback. I am especially interested in any comment finding mistakes or trivial explanations for these results. I will work on this proposal with a LASR Labs [LW · GW] team over the next 3 months. If you are working (or want to work) on something similar I would love to chat!
Experiments and write-up by Stefan, with substantial inspiration and advice from Jake (who doesn’t necessarily endorse every sloppy statement I write). Work produced at Apollo Research.
TL,DR: Toy models [AF · GW] of how neural networks compute new features in superposition seem to imply that neural networks that utilize superposition require some form of error correction to avoid interference spiraling out of control. This means small variations along a feature direction shouldn't affect model outputs [LW(p) · GW(p)], which I can test:
- Activation plateaus: Real activations should be resistant to small perturbations. There should be a "plateau" in the output as a function of perturbation size.
- Sensitive directions: Perturbations towards the direction of a feature should change the model output earlier (at a lower perturbation size) than perturbations into a random direction.
I find that both of these predictions hold; the latter when I operationalize "feature" as the difference between two real model activations. As next steps we are planning to
- Test both predictions for SAE features: We have some evidence for the latter by Gurnee (2024) [LW · GW] and Lindsey (2024).
- Are there different types of SAE features, atomic and composite [LW · GW] features? Can we get a handle on the total number of features?
- If sensitivity-features line up with SAE features, can we find or improve SAE feature directions by finding local optima in sensitivity (similar to how Mack & Turner (2024) [LW · GW] find steering vectors)?
My motivation for this project is to get data on computation in superposition, and to get dataset-independent evidence for (SAE-)features.
Core results & discussion
I run two different experiments that test the error correction hypothesis:
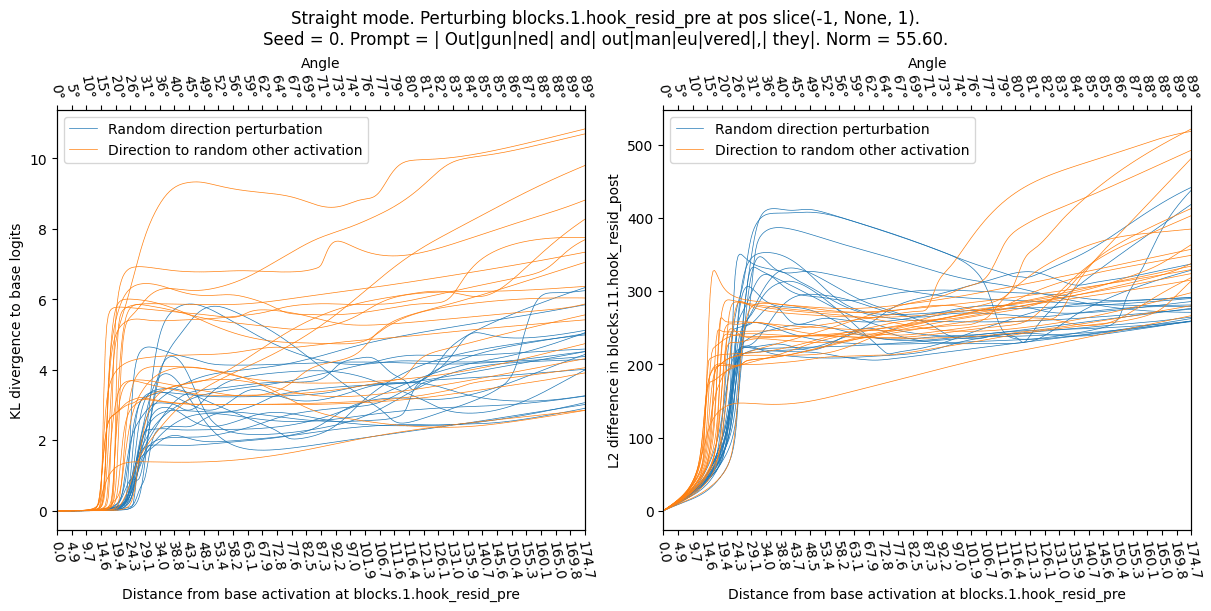
Activation Plateaus: A real activation is the center of a plateau, in the sense that perturbing the activation affects the model output less than expected. Concretely: applying random-direction perturbations to an activation generated from a random openwebtext input (“real activation”) has less effect than applying the same perturbations to a random activation (generated from a Normal distribution). This effect on the model can be measured in KL divergence of logits (shown below) but also L2 difference or cosine similarity of late-layer activations.
The left edge of this plot corresponds to no perturbation. As we move to the right, the orange lines (real base activation) "plateau" (the perturbation effect stays minimal for a while), while the blue lines (random base activation) rise immediately. Note that a distance of ~50 corresponds to the typical distance between two activation vectors. This plot shows the effect of changing the base activation; the perturbation direction is random in both cases. Sensitive directions: Perturbing a (real) activation into a direction towards another real activation (“poor man’s feature directions”) affects the model-outputs more than perturbing the same activation into a random direction. In the plot below focus on the size of the “plateau” in the left-hand side
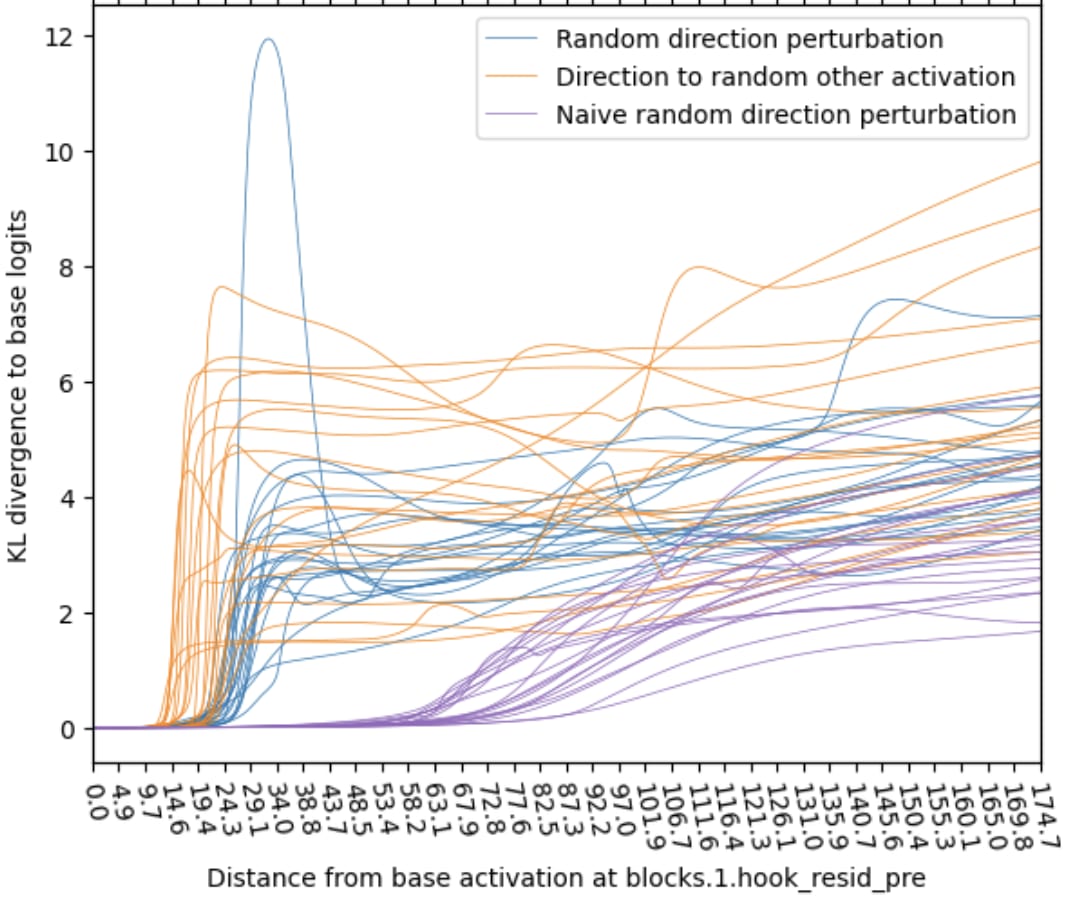
This plot varies the perturbation direction, the base activation is a real activation in both cases. The orange lines (other real activation direction) exhibit a shorter plateau than the blue lines (random direction). This means the real activation directions are more sensitive. To show why we usually sample random activations and directions from a mean- and covariance-adjusted distribution we show the naive (isotropic) random direction in purple, it behaves very differently and thus is not a good baseline. - Naive random direction vs mean & covariance-adjusted random: Naive isotropic random directions are much less sensitive. Thus we use mean & covariance-adjusted random activations everywhere else in this report.
- The sensitive direction results are related to Gurnee (2024 [LW · GW], SAE-replacement-error direction vs naive random direction) and Lindsey (2024, Anthropic April Updates, SAE-feature direction vs naive random direction).
The theoretical explanation for activation plateaus & sensitive direction may be error correction (also referred to as noise suppression):
- NNs in superposition should expect small amounts of noise in feature activations due to interference. (The exact properties depend on how computation happens in superposition, this toy model [LW · GW] shows one possibility.) Thus we expect [LW(p) · GW(p)] NNs to have mechanisms for suppressing this noise (e.g. the “error correction” described here).
- Activation plateau explanation: a real activation consists of only a small number of features (on the order of L0 ~ 100) while most features (on the order of d_dictionary ~ 20k) are off. Then a random perturbation mostly induces small amounts of noise distributed over many[1] features and causes little change in the model.
- Sensitive directions explanation: Perturbing a real activation creates a plateau. Its size should correspond to the perturbation size required to pass an error correction threshold in feature activations. Because perturbing towards a real other activation (“real-other”) concentrates the change in a small number of features (compared to random), we expect real-other perturbations to cross the threshold earlier, which is what we see.[2]
Proposal: Connecting SAEs to model behaviour
The leading theory for how concepts are represented in neural networks in superposition: We think that NNs represent information as a series of sparsely-active features, which are represented as directions in activation space.[3] Superposition allows this list of features to be much larger than the dimension of activation space, and has been demonstrated in toy models.
Sparse autoencoders (SAEs) are a method that can recover individual features from a dataset of features in superposition. SAEs are trained to convert activations into a list of sparsely-active individual features and back into activations with low reconstruction loss and high feature-sparsity. The training input for SAEs are model activations, typically generated by running the model on a dataset similar to its training data.
If SAE-features are features in the sense that computation in superposition toy models suggest, then they should show the same error correction properties we saw with real feature directions. Thus we predict
- Activation Plateaus: There should also be plateaus around “artificial real” activations, created by adding & subtracting a couple of SAE features from real activations. This would confirm that activations created by shuffling around active SAE features still have the properties of real activations.
- Perturbing into SAE feature directions should have a similar effect as perturbing towards real-other directions (SAE features being more sensitive than random was already observed by Lindsey (2024, Anthropic April Updates) so I expect this to work). Our guess is that perturbing into single SAE directions is more sensitive (exits the plateau earlier) than spreading perturbation over multiple SAE features.
Why do I think this is a useful direction to study SAEs?
- There are weird effects [LW · GW] around how SAE features affect model behavior that we don't fully understand. Let's figure out what is going on and what we can learn!
- A (neglected?) failure mode of the SAE agenda is that SAE features could be an interpretability illusion in the sense that they do not represent the internal computation of the model but properties of the training dataset.
- I worry that SAEs find a feature only because a concept is frequent in the dataset rather than because the model uses the concept. (I discuss this in detail in a shortform post [LW(p) · GW(p)]). A dataset-independent way to find/confirm SAE features (even if non-competitive) would be great!
- I’d like to find a cheaper or more targeted way to find (some or all) model features.
- Training SAEs is expensive, and cost trades off against feature completeness. If we could take an individual prompt and find (all?) active features, this would be extremely useful for evaluations and interpretability research.
Conclusion
Summary: I run some experiments testing computation-in-superposition predictions on GPT2 activations, finding
- Plateaus around model activations, as if the model was error-correcting small perturbations
- Perturbing activations into the direction of other activations has more effect than random
I hope this research will allow us to understand computation in superposition better, and to connect behavioral properties of model activations to (SAE-)features.
Limitations: There may just be trivial explanations for results like these! Section 1 results really just say “GPT2 is weird if you go off distribution” (and happen to align with a theory prediction), but there could be lots of plausible explanations for this. Section 2 results are more specific, but still there might be simple explanations for this behavior (e.g. relevant properties of activation space beyond the covariance thing we noticed), and I would love to hear takes in the comments!
Future work: We are currently investigating these behavior properties for SAE-features, questions like
- Do SAE features behave as predicted by Toy Models of Computation in Superposition?
- Are there different types of SAE features? Atomic and composite [LW · GW] features?
- How do linear combinations of features behave? Does this give us a handle on the total number of features?
Call to action: This direction feels underexplored, I think there’s a lot of new data to be generated here! I’d love to hear from anyone considering working on this!
I also want to encourage feedback in the comments: Trivial explanations I missed? Past literature that explored this? Reasons why this direction might be less promising than I think?
Acknowledgements: We thank Dan Braun, Lee Sharkey, Lucius Bushnaq, Marius Hobbhahn, Nix Goldowsky-Dill, and the whole Apollo team for feedback and discussions of these results. We thank Wes Gurnee and Rudolf Laine for comments on a previous (March 2024) report on this project.
Appendix
Methodology
The experiments in this report focus around perturbing the residual stream of a model (via activation patching) and measuring the corresponding chance in model outputs (KL divergence and more).
All experiments use GPT2-small. Input are 10-token sequences taken from openwebtext (apollo-research/Skylion007-openwebtext-tokenizer-gpt2). We choose an early perturbation layer (blocks.1.hook_resid_pre). We read the results off at the logits (KL divergence of logprobs) or at a late layer (L2 difference of activations at blocks.11.hook_resid_post or ln_final.hook_normalized). We use only the last position index for perturbation and read-off.
Generating activations: We use model activations to measure activation plateaus, and to generate the perturbation directions for sensitivity tests. We consider 4 types of activations
- Base activations: The activations of the model without any perturbation. We store the base activations at the perturbation layer and readoff layer.
- Random other activations (real-other): Activations on an unrelated input. We sample the perturbation layer activations corresponding to multiple (unrelated) input sequences.
- Random activations (random): Activation vectors generated from a multivariate normal distribution. By default I use the mean and covariance of actual activations to create slightly more realistic random activations (random), but I also test isotropic random activations (naive random). It turns out there is a big difference between naive random and sampling with the correct covariance.
- [SAE-feature-adjusted activations: Take the base activations but add or remove some SAE features. This is to test whether adding and removing SAE features yields activations that behave similarly to normal (real-other) activations. Not yet used in this report.]
All activation vectors have zero layer-mean (each activation has zero mean along the hidden dimension), but not zero dataset-mean (i.e. I mean-center in the same way as TransformerLens but the activation dataset mean is not the zero vector). I don’t fix the norm of activation vectors (yet).
Generating directions: In which direction to perturb the activations into. In most cases we generate an activation according to the list above and take the difference between it and the base activations to obtain a direction.
- Random directions (random): Generate a random activation point (with appropriate mean and covariance) and take the difference between it and the base activations. These directions are used for the activation plateau test.
- Towards other activations (real-other): Sample an unrelated real activation (real-other) and take the difference between it and the base activation.
- [SAE decoder directions: Sample a random SAE feature (either among the currently-active SAE features, or all features). Use the corresponding decoder matrix direction (we don’t calculate a difference in this case). I test perturbation parallel (exciting the feature) or antiparallel (dampening or negatively exciting the feature) to this direction. Not yet used in this report.]
The real-other direction is a proxy for getting feature directions without having to rely on SAEs. The difference between two real activations should be a couple hundred features (about half of them negative) because each real activation should consist of a number (~L0) of features.
Perturbations: I perturb the base activation by adding α*direction to the activation vector. I do this in two ways:
- Straight mode: Scale the direction such that norm(direction) = norm(base activation) and scan from α = 0 to 1.
- Sphere mode: Move along the sphere of constant norm (slerp) from the base activation towards the direction, all the way to its antipode. The direction just determines which “meridian” to move along, the perturbation size is measured by the angle between base activation and perturbed activation θ = 0° to 180°.
Effect on model outputs: To measure the effectiveness of a perturbation I measure the KL divergence between the perturbed model output logits and the base output logits, the L2 difference and cosine similarity between the activations in a late layer taken on the base and perturbed runs.
Experiment types: I run three types of experiments. In all cases I measure the effect of activation perturbations (as a function of perturbation L2 distance α or angle θ) on model outputs (KL divergence, final-layer L2 distance).
- Activation plateaus: Starting from either a random or real activation we perturb into a random direction. In essence, we measure the existence of plateaus around different activations.
- Sensitive directions: Starting from a real activation we perturb into either a random or real-other direction. In essence, we measure the plateau size in different directions.
- Sensitivity-optima: Starting from a real activation we perturb into a 2d manifold of directions. We find the set of directions by three-way interpolating between two random directions and a real-other direction. For each interpolated direction we report the size of the plateau, measured by the distance required to have a KL divergence of >0.5 in the output. We test whether the real-other direction is a local optimum in the meta-landscape of directions.
- The sensitive direction test finds the distance (α) or angle (θ) required for a certain amount of change in outputs (KL divergence of 0.5). We repeat the test for many nearby directions, and see whether the original real-other direction is a local optimum of sensitivity (α or θ).
- The goal of this is to find out whether real-other directions could be found by optimizing sensitivity over directions.
Detailed results
1. Activation Plateaus
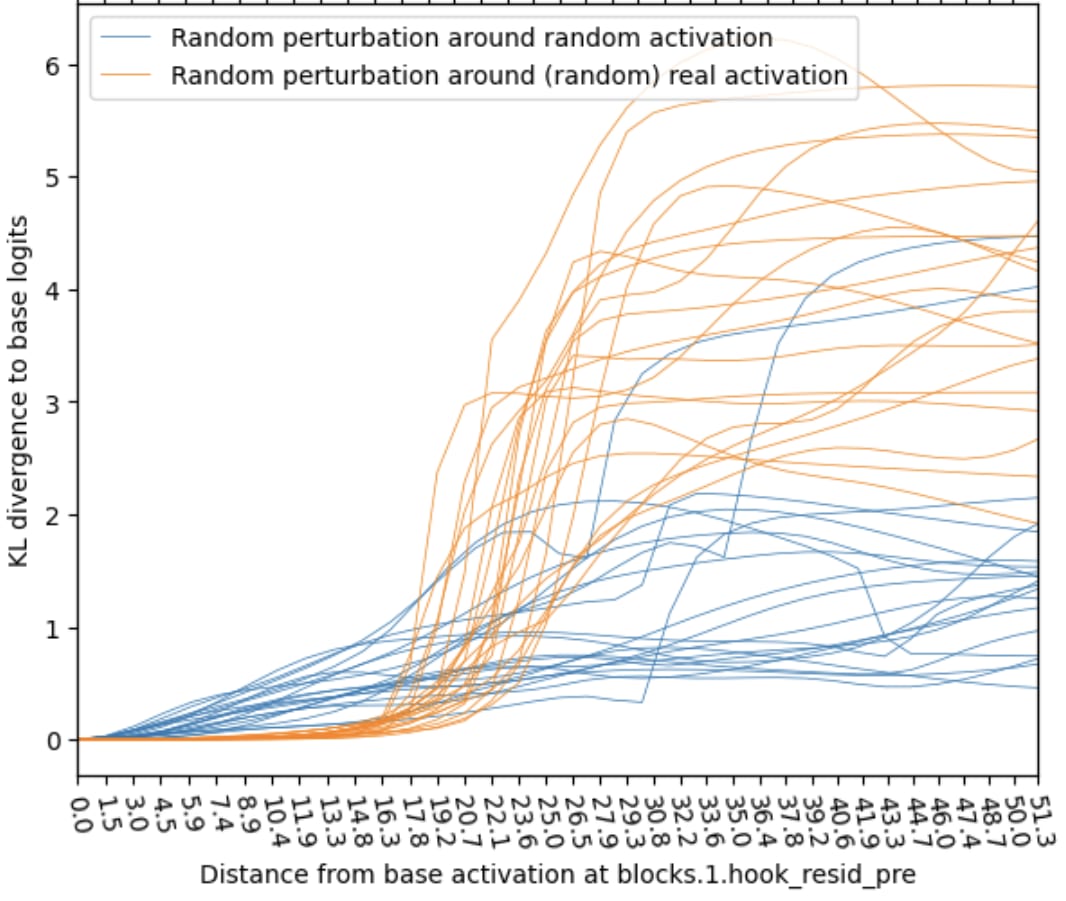
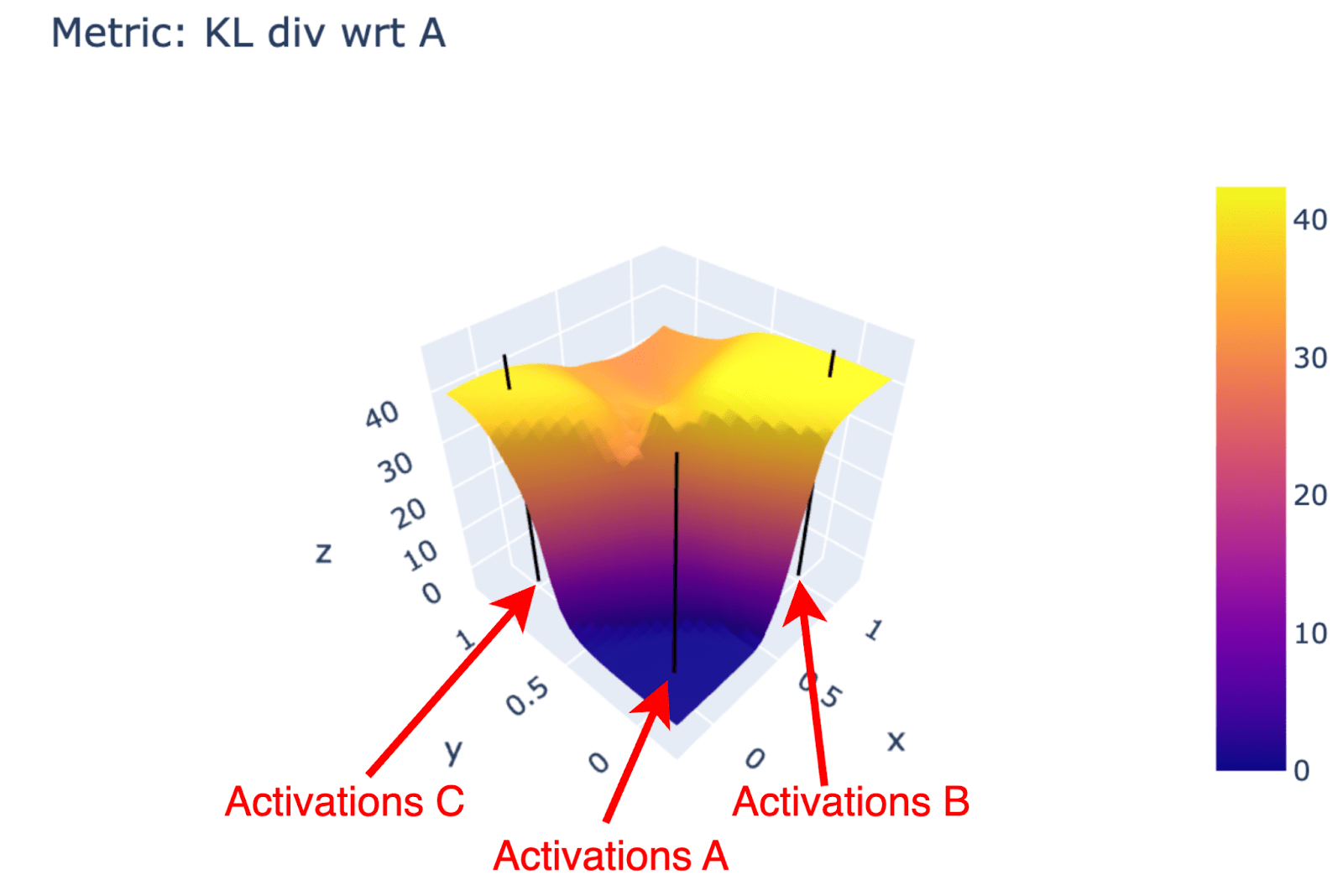
Intuition: Look at the model-output landscape when interpolating activations on the plane spanned by three real activations. The plot below shows the KL divergence (wrongly normalized, z-axis and color) for all activations on that plane. We see plateaus around the real activations (black vertical lines) with outputs changing less per shift in activations. This gives an intuitive picture; for the quantitative study we switch to a 1D version and switch from interpolation to perturbation into random directions.
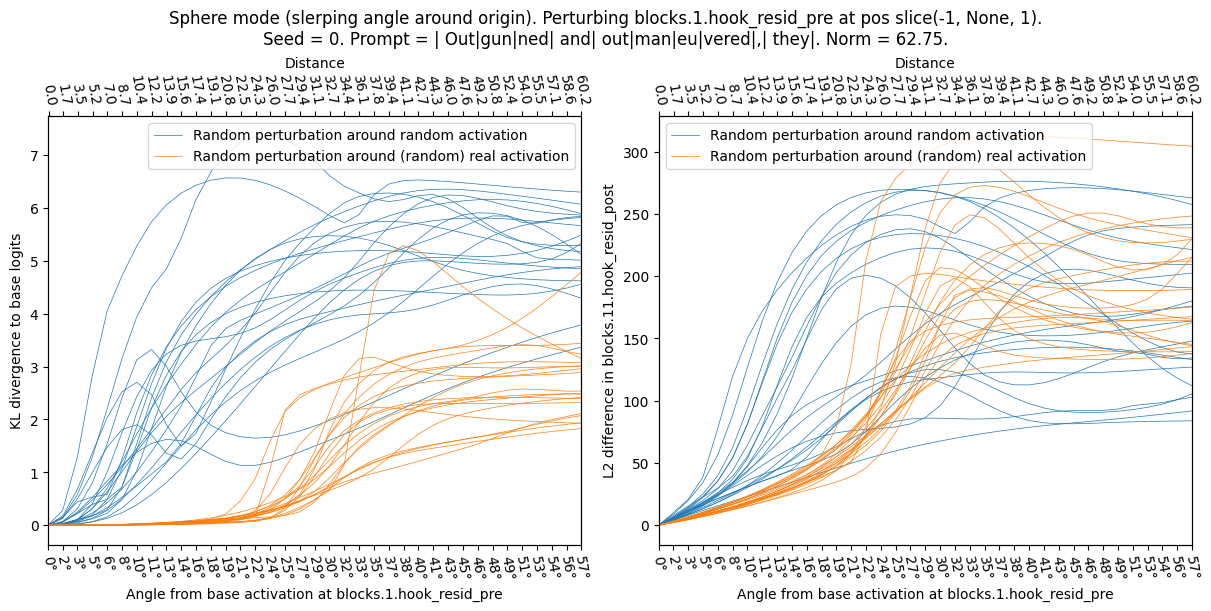
We sample a series of base activations (random or real-other) and perturb the activations from there towards a series of random directions (as discussed above we either perturb in Straight or Sphere modes). Below we show the KL div as a function of perturbation angle (Sphere case) for both types. The real-other activations clearly exhibit the plateau phenomenon—the KL div barely changes until the perturbation reaches 40°—while random activations do not follow this pattern.
Straight mode (perturbing straight into a direction):
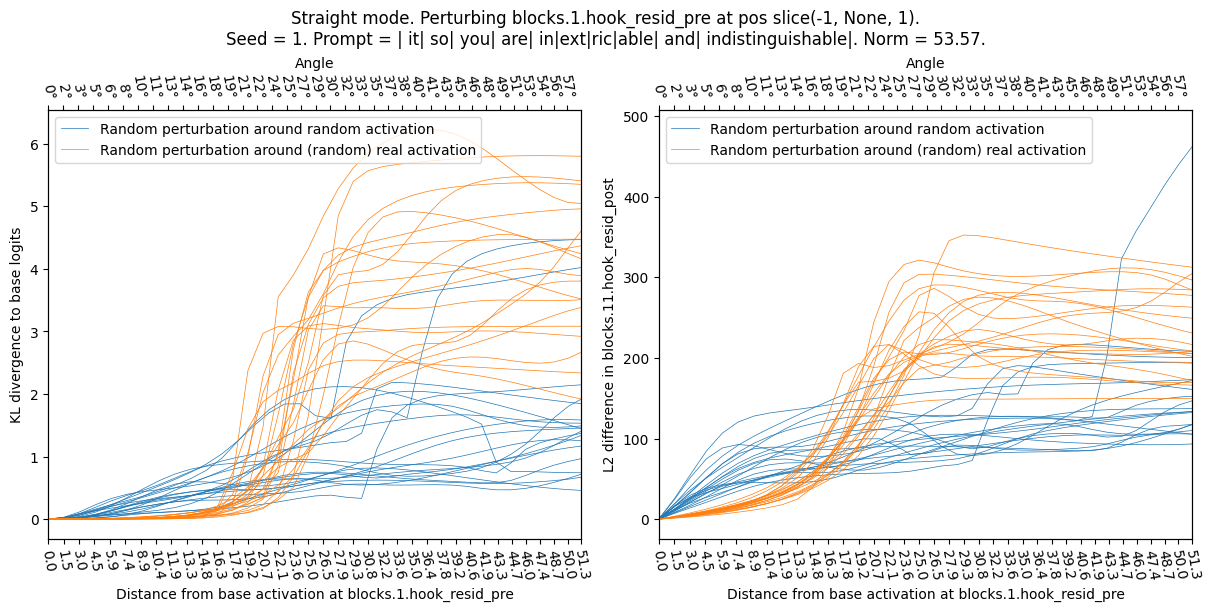
Sphere mode (perturbing while keeping norm constant – the change between this and the plot above is due to straight/sphere mode, the seed does not have a big effect):
2. Sensitive directions
Now we perturb a given (real) base activation into different kinds of directions. This is different from the previous experiment where we applied the same (random) perturbation to different base activations.
I take a given real base activation (seed / prompt shown in plot titles) and perturb it into a random direction (sample a random other activations with appropriate covariance matrix, and define direction as difference between new activation and base activation) or real-other (sample new activation by running random openwebtext sequence through model, then take difference as direction). I normalize the directions to have the same norm, and observe the effect on the model (KL div) as a function of angle (Sphere mode) or perturbation size (Straight mode). In all cases the real-other directions appear to be more sensitive, jumping up at a lower angle and lower perturbation distance.
Straight mode (perturbing straight into a direction):
Sphere mode (perturbing while keeping norm constant):
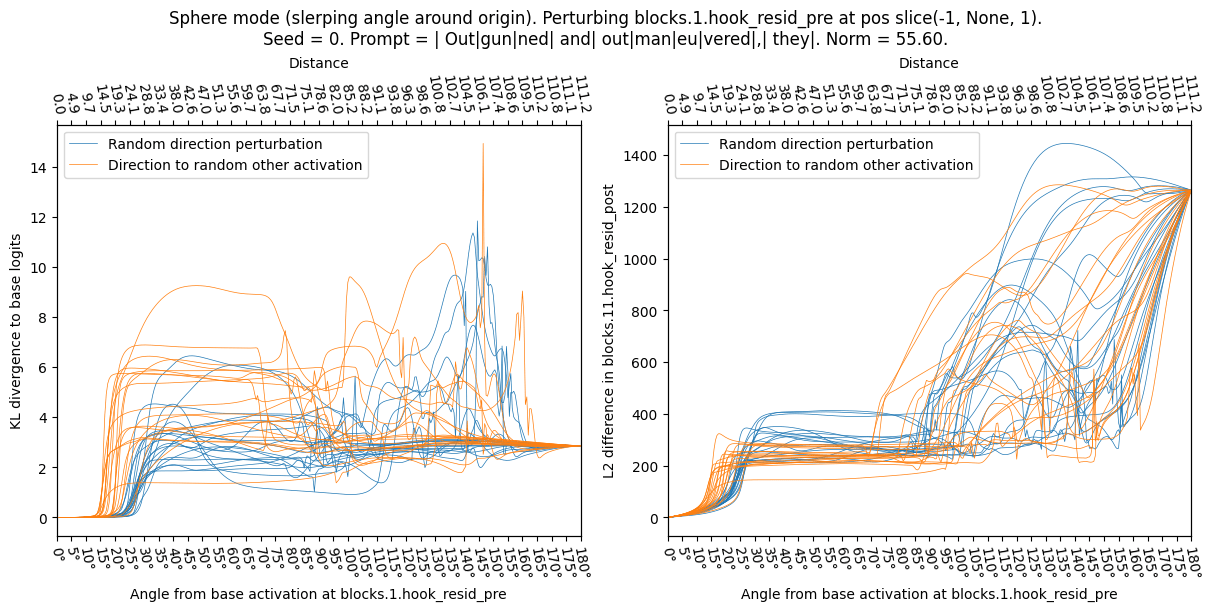
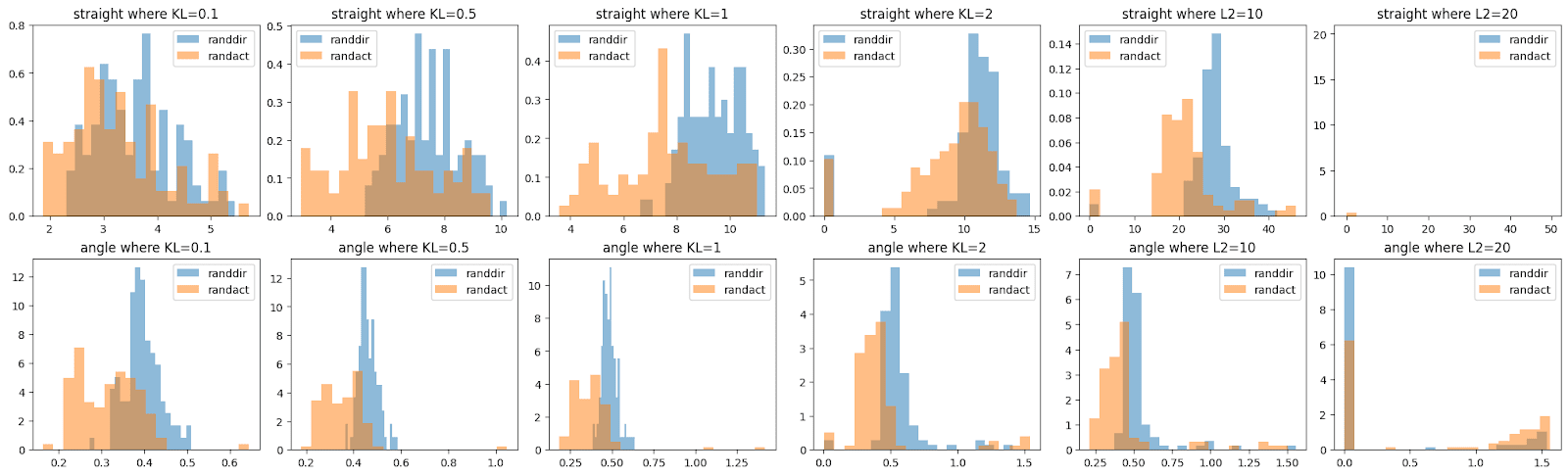
A brief investigation shows that we can find metrics, such as “at what angle does the KL divergence exceed 0.5” to reasonably distinguish the two classes of perturbation, though I think that the curves above look more distinguishable than suggested by the histograms below. (This may be an optical illusion, or show that I haven’t spent time finding the optimal classifier.)
3. Local optima in sensitivity
real-other directions are more sensitive than random directions. We think this is because they focus perturbations into a small (~L0) number of feature directions, reaching the hypothetical error correction threshold earlier.
We conjecture that, if we could perturb activations into a single feature direction, the perturbation would be even more focused and reach the error correction earlier (concretely: the perturbation distance required to reach KL-div=0.5 would be lower). This is compatible with Lindsey (2024)’s observations that SAE directions are unusually sensitive (though they did not compare to real-other or combinations of SAE directions). If that was true, we might be able to find SAE directions as local maxima of sensitivity: A perturbation into 1*feature direction should be more sensitive than a perturbation into 0.99*feature direction + some other direction.
As a precursor to this investigation we investigate the sensitivity of various directions between real-other and random directions. In the plot below, every corner corresponds to a random direction (except for the top corners in the 2nd row, these correspond to real-other directions). And the color corresponds to the perturbation size (measured in Sphere mode, as angle) required to reach 0.5 KL divergence (so every point corresponds to a direction, and we run a scan over perturbation lengths on every point). The non-corner points correspond to interpolated directions (precisely: we interpolate the targets before calculating the direction). This shows us whether “nearby” directions are similarly precise as the exact real-other direction.
The upper row is a sanity-check, interpolating between 3 random directions. We expect the plot to be symmetric. The lower row is an interpolation between a real-other direction (top) and two random directions (bottom corners). We see, as expected, the top corner appears to be a local optimum of sensitivity:
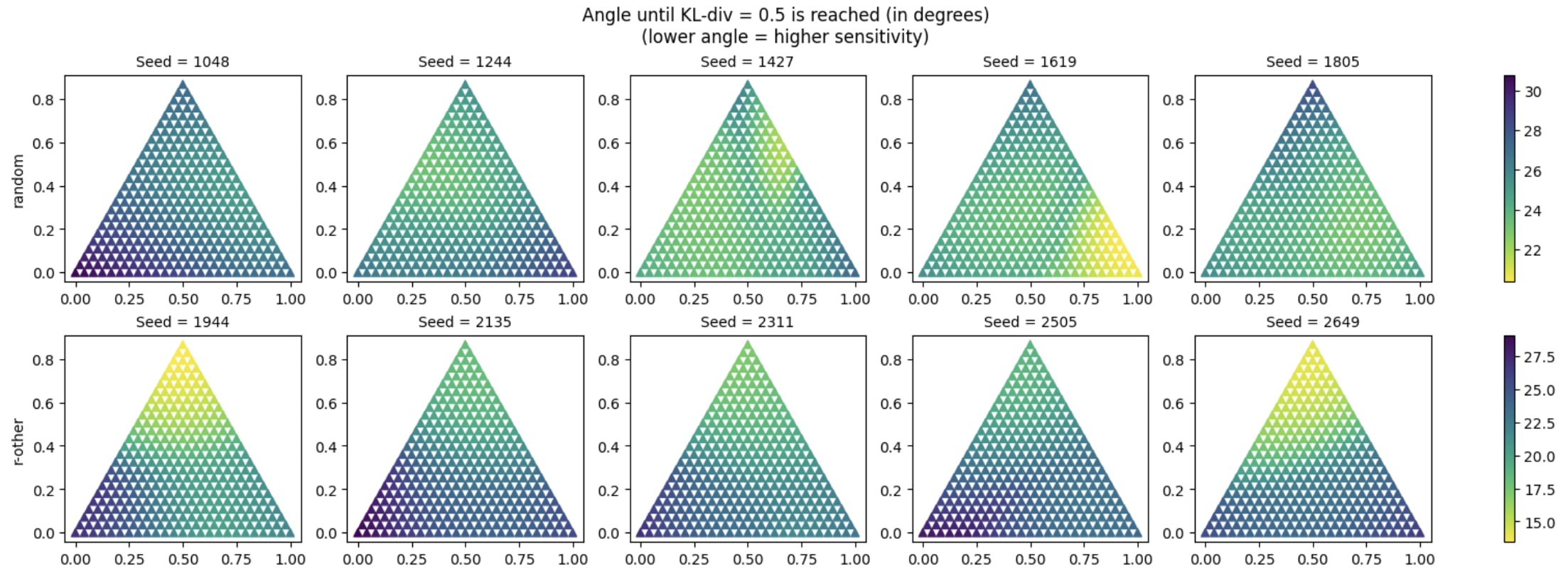
While these plots initially seem to suggest a local optimum at the top corner (2nd row), they only test two (random) directions in 768d space. If real-other directions consist of ~L0 number of features, and the previous hypothesis is true, we expect there to be an L0-dimensional space in which the direction is not a local optimum. We plan to continue these investigations in future work.
- ^
Empirically this is a bit messy: Inputting a random direction into an SAE activates between 10 and 20000 features (lognormal distribution with a peak around 30). But that is using the encoder, I'm not sure if I should be doing that.
- ^
The real-other direction is expected to turn on some features, but also to dampen existing features. My explanation focuses on turning on inactive features, and ignores the slight dampening of active features.
- ^
This is not fully true—we know some directions represent non-sparse positional features, and there is information in the geometry of features [LW · GW]—but we leave this aside for now.
2 comments
Comments sorted by top scores.
comment by LawrenceC (LawChan) · 2024-07-06T02:24:51.611Z · LW(p) · GW(p)
Good work, I'm glad that people are exploring this empirically.
That being said, I'm not sure that these results tell us very much about whether or not the MCIS theory is correct. In fact, something like your results should hold as long as the following facts are true (even without superposition):
- Correct behavior: The model behavior is correct on distribution, and the correct behavior isn't super sensitive to many small variations to the input.
- Linear feature representations: The model encodes information along particular directions, and "reads-off" the information along these directions when deciding what to do.
If these are true, then I think the results you get follow:
- Activation plateaus: If the model's behavior changes a lot for actual on-distribution examples, then it's probably wrong, because there's lots of similar seeming examples (which won't lead to exactly the same activation, but will lead to similar ones) where the model should behave similarly. For example, given a fixed MMLU problem and a few different sets of 5-shot examples, the activations will likely be close but won't be the same, (as the inputs are similar and the relevant information to locating the task should be the same). But if the model performs uses the 5-shot examples to get the correct answer, its logits can't change too much as a function of the inputs.
In general, we'd expect to see plateaus around any real examples, because the correct behavior doesn't change that much as a function of small variations to the input, and the model performs well. In contrast, for activations that are very off distribution for the model, there is no real reason for the model to remain consistent across small perturbations. - Sensitive directions: Most directions in high-dimensional space are near-orthogonal, so by default random small perturbations don't change the read-off along any particular direction by very much. But if you perturb the activation along some of the read-off directions, then this will indeed change the magnitude along each of these directions a lot!
- Local optima in sensitivity: Same explanation as with sensitive directions.
Note that we don't need superposition to explain any of these results. So I don't think these results really support one model of superposition via the other, given they seem to follow from a combination of model behaving correctly and the linear representation hypothesis.
Instead, I see your results as primarily a sanity-check of your techniques for measuring activation plateaus and for measuring sensitivity to directions, as opposed to weighing in on particular theories of superposition. I'd be interested in seeing the techniques applied to other tasks, such as validating the correctness of SAE features.
Replies from: Stefan42↑ comment by StefanHex (Stefan42) · 2024-07-06T09:34:03.948Z · LW(p) · GW(p)
Thanks for the comment Lawrence, I appreciate it!
- I agree this doesn't distinguish superposition vs no superposition at all; I was more thinking about the "error correction" aspect of MCIS (and just assuming superposition to be true). But I'm excited too for the SAE application, we got some experiments in the pipeline!
- Your Correct behaviour point sounds reasonable but I feel like it's not an explanation? I would have the same intuitive expectation, but that doesn't explain how the model manages to not be sensitive. Explanations I can think of in increasing order of probability:
- Story 0: Perturbations change activations and logprobs, but the answer doesn't change because the logprob difference was large. I don't think the KL divergence would behave like that.
- Story 1: Perturbations do change the activations but the difference in the logprobs is small due to layer norm, unembed, or softmax shenanigans.
- We did a test-experiment of perturbing the 12th layer rather than the 2nd layer, and the difference between real-other and random disappeared. So I don't think it's a weird effect when activations get converted to outputs.
- Story 2: Perturbations in a lower layer cause less perturbation in later layers if the model is on-distribution (+ similar story for sensitivity).
- This is what the L2-metric plots (right panel) suggest, and also what I understand your story to be.
- But this doesn't explain how the model does this, right? Are there simple stories how this happens?
- I guess there's lots of stories not limited to MCIS, anything along the lines of "ReLUs require thresholds to be passed"?
Based on that, I think the results still require some "error-correction" explanation, though you're right that this doesn't have to me MCIS (it's just that there's no other theory that doesn't also conflict with superposition?).