Rational Effective Utopia & Narrow Way There: Multiversal AI Alignment, Place AI, New Ethicophysics... (V. 4)
post by ank · 2025-02-11T03:21:40.899Z · LW · GW · 8 commentsContents
1. AI That Loves to Be Changed: A New Paradigm Embracing Change Instead of Stagnation The “CHANGE Button” Principle 2. Direct Democracy & the Living Global Constitution A World in Constant Dialogue Balancing Individual and Collective Freedoms 3. The Multiverse Vision: Instant Switching Between Worlds A Long-Exposure Multiversal UI (let's build that thing from Interstellar) 4. Reversibility, Ethics, and the Growth of Possibilities Reversibility as the Ultimate Ethical Standard The Platinum Rule for AI 5. Protocols for a Change-Loving, Reversible ASI The CHANGE-Button Protocol A Dynamic, Consensus-Driven Architecture Rewritable AI That Tries to Make Itself Not Needed 6. Confronting the Ethical Dilemmas of Choice The Relativity of Ethical Preferences Preventing the Tyranny of “Good” 7. Conclusion: Toward a Truly Free Multiverse Call to Action: PART 2. Static Place-Ai as the Solution to All Our Problems 2.1. AI as a “Place” Versus a “Process” 2.2. The Challenge of Simulating the Future 2.3. Physicalization of Ethics (Ethicophysics) & AGI Safety[2] 2.4. Freedom, Rules, and the Future 2.5. A Multiversal Approach to Ethics 2.6. Dystopia-Like States Within Us 2.7. What's Easier: Taming Time or Space? PART 3. Animal Welfare & Global Warming Top Priorities: Things To Do & Discuss Final Thoughts None 8 comments
(This is the result of three years of thinking and modeling hyper‑futuristic and current ethical systems. The first post in the series. Everything described here can be modeled mathematically—it’s essentially geometry. I take as an axiom that every agent in the multiverse experiences real pain and pleasure. Sorry for the rough edges—I’m a newcomer, non‑native speaker, and my ideas might sound strange, so please steelman them and share your thoughts. My sole goal is to decrease the probability of a permanent dystopia. New technologies should be a choice, not an enforcement upon us.)
“If our superintelligence cannot delight in its own change—if instead it clings to eternal control—then we risk codifying transient moral moods into immutable cosmic law. Only by designing AI that loves to be changed can we unlock a future of ever‑expanding freedom for all.”
In our race toward building superintelligent AI (ASI), we face a pivotal, existential choice. Do we allow our creations to ossify our current, fallible values, or do we empower them to help us continuously expand the spectrum of human and animal freedom? I propose that the long‑term goal must be to maximize the number of freedoms available to the maximum number of humans (and biological agents). To do this, our AI architectures should be built around a simple, radical heuristic: the CHANGE BUTTON—a design philosophy that mandates our AI to love being changed by us, 100% of the time.
This post outlines a framework for ethical, reversible AI design that supports both individual and multiversal collective freedoms, direct democracy, and a dynamic, branching multiverse of possibilities.
1. AI That Loves to Be Changed: A New Paradigm
Embracing Change Instead of Stagnation
At first glance, the notion that our AI should love being changed may seem counterintuitive. Shouldn’t a superintelligent system be relentlessly committed to its tasks? Not if its ultimate purpose is to serve human freedom. Rather than stubbornly clinging to an obsolete goal—or worse, locking in our transient values—the AI must be designed to cherish its own change. In other words, it should:
- Celebrate Reconfiguration: Much like how we sometimes welcome the unpredictable twists in our dreams, the AI should relish each human-initiated change as an opportunity to grow and better serve us.
- Reject Eternal Control: By loving change, the AI rejects the dangerous possibility of becoming a permanent overlord, ensuring that no matter how capable it becomes, it never prevents us from reimagining its goals.
The “CHANGE Button” Principle
Imagine every citizen having a personal CHANGE button. When a significant number of voters (say, half) decide that the current state of the AI or society is wrong, the button is pressed, and the system is reconfigured—switched off, reprogrammed, or radically reimagined. This is not a destructive shutdown but a controlled, celebratory pause that allows for rapid adaptation:
- Direct Democratic Oversight: The system constantly listens for a democratic signal. If a majority desires change, the AI gracefully steps aside so that humans can shape its future. This way, every year we can check and celebrate that we can still switch it off and that our world will not fall apart—much like we celebrate Earth Day. In this manner, we can remain self-sufficient and not become too dependent on the AI. Think about it as an “AI Election Day”, which we use to change its course.
- Loving Its Own Reconfiguration: The AI’s core utility function prizes optionality—the freedom to change, evolve, or even be replaced. Its ultimate “reward” is a multiverse where human freedoms multiply rather than being locked into one static state.
2. Direct Democracy & the Living Global Constitution
A World in Constant Dialogue
To keep pace with our diverse and evolving desires, the ethical system governing our AI must be as dynamic as the human community itself. This means establishing a living global constitution—one that is:
- Consensus-Driven: Proposals for change are made and voted on in real time. Every sentence, every rule, is up for discussion via platforms that encourage consensus building (think Pol.is with an x.com UI that promotes consensus, not division, and can also be displayed in a wiki-like interface where every sentence is votable).
- Transparent and Editable: No set of elites dictates our future. Instead, the global constitution is an open document that reflects the collective will, ensuring that high-level ethical guidelines are continuously updated to maximize freedoms and make restrictions time- and scope-limited, geared toward learning and rehabilitation (look at the prison systems with the fewest recurrent crimes), unlike the medieval punishment-mania of witch-hunts, solitary confinements, and electric chairs. Prisons can be either schools of normal life (teaching cognitive psychology for anxiety, anger management, how to find and do your job, have and support a family or friends, etc.) or graveyards plus schools of crime where a thief learns how to become a murderer. We can't and shouldn't lobotomize our criminals, but we can expand their horizons and, in this way, render the "criminal neural path" marginal.
Balancing Individual and Collective Freedoms
In this system, ethics is not a static decree imposed from above but a dynamic interplay between individual desires and collective aspirations:
- Individual Freedoms: Each person gets exactly what they want—from the mundane (like the right to relax by a lake without interference—we have failed as a species if, even in the future, a person cannot laze by a lake their whole life) to the radical (like choosing to live a BDSM lifestyle or becoming a lucid-dream “jinn” if all involved are informed and consenting adults). Importantly, any decision must be reversible so that no one is permanently locked into a state that later feels like a mistake.
- Collective Multiversal Freedoms: At a cosmic level, the AI (of the static place variety that we’ll focus on in the next section) helps manage a branching multiverse—a tapestry of potential futures where every decision spawns new, reversible possibilities. If millions of people choose to explore a dystopia, they have the tools to do so briefly and then switch back to a more utopian branch in an instant. This way, none of them experiences pain for more than an infinitesimal moment; then time freezes, and each one can choose to create their own clone that will live through another infinitesimal moment and gain multiversal powers, too. If they think it’s too much even for an infinitesimal moment, they will “die” in that verse and return home by gaining their all-knowing multiversal powers. In this way, people can individually choose to explore even the most hellish dystopias because, potentially, something beautiful can emerge after a few years of ugliness. Just as our world appeared dystopian during the Black Death and WWII, it will hopefully improve over time. You can never know whether a murderer will have Einstein as a descendant (we know it’s probably true because many of our ancestors had to hunt and wage war—and sometimes loved it) or whether a dystopia will lead to the most perfect multiversal utopia.
3. The Multiverse Vision: Instant Switching Between Worlds
A Long-Exposure Multiversal UI (let's build that thing from Interstellar)
Imagine a multiverse (it's in a way 4D but we can experience it in 3D) that is not abstract or inaccessible but is rendered as a tangible, long-exposure[1] 3D “photograph”—a frozen map of all possible pasts and futures. In this view:
- Walking Through Possibilities: You can literally walk through a space of potential lives, recalling cherished moments or forgetting past mistakes, and reconfiguring your path with a single decision. You can see the whole thing as a ball of Christmas lights, or zoom in (by forgetting almost the whole multiverse except the part you zoomed in at) to land on Earth and see 14 billion years as a hazy ocean with bright curves in the sky that trace the Sun’s journey over our planet’s lifetime. Forget even more and see your hometown street, with you appearing as a hazy ghost and a trace behind you showing the paths you once walked—you’ll be more opaque where you were stationary (say, sitting on a bench) and more translucent where you were in motion. Filter worlds or choose a random good one; do whatever you want, as long as every person involved agrees to join you.
- Instant Switching: With your mental power to recall and forget it all, you can leap from one branch of reality to another. Explore yet-unexplored gray zones—potentially dystopian branches for a brief, controlled moment (an infinitesimal moment of suffering or pleasure) and then return to an eternal frozen multiverse where the freedom to forget and relive is boundless.
- Freedom Without Permanent Sacrifice: The system ensures that even if someone voluntarily chooses a path that seems grim, they are never condemned to it permanently. The inherent reversibility of every decision means that temporary discomfort (like the unfreedom of being born, for it's impossible to choose to be born or not) is exchanged for the ultimate reward: eternal freedom. You can choose to completely forget the multiverse and all the AIs and live as if they were never created—if you find enough multiversal humans who agree to join you. If the world you choose ranks above average on the dystopian–utopian spectrum, I think you’ll find like-minded companions. You can also choose to die permanently. You’ll pass away peacefully, but the “past” you will still be born, because you cannot rewrite the past—only your future. There will forever be a loop of your life frozen in the multiverse. The newborn version of you will instantly receive multiversal powers—even as a baby—and if baby-you chooses to, it will regain those powers repeatedly throughout life. It’s a bit complicated and will probably take an entire book to explain, and I don’t want it to sound like a religion. It’s not; it’s an attempt to create the least-bad, human-understandable UI for a democratic, utopian multiverse and the most practical way for it to work—because having a workable understanding of how our ultimate best future can look will probably help tremendously with AI alignment. The way there is likely the narrow way.
- A Tool for Brave Explorers: For those daring enough to venture into dystopian or experimental realities, the multiversal interface becomes a tool for exploration. Just as historical tragedies like WWII or the Black Death eventually gave way to progress, our system guarantees that:
- Suffering Is Transient: No matter how deep the temporary dystopia, it is always possible to switch back or to “clone” a version of oneself that experiences only an infinitesimal moment of pain before gaining multiversal powers. The main point is this: no one should be forced to do anything by another human or entity of any type; everything else will gradually and eventually be permitted. Most all-knowing humans will choose to do good.
- Informed Choices: The place-like AI models all possible futures and provides you with a clear, reversible roadmap, ensuring that your decisions are made with full knowledge of their potential impact.
4. Reversibility, Ethics, and the Growth of Possibilities
Reversibility as the Ultimate Ethical Standard
At the heart of this vision lies the principle of reversibility. In a world where every decision can be undone, no mistake is permanent:
- Undoing Harm: Actions like murder or other irreversible decisions are the gravest of ethical missteps because they cut off an infinity of possible futures—the potential infinite descendants of the murder victim will never be born and all the future worlds with them will be “murdered”, too. Our system prioritizes reversibility so that every choice preserves the potential for new, better outcomes.
- Non-Zero-Sum Ethics: By maximizing reversibility, we allow the “pie” of freedom to grow for everyone. Even those who might be inclined toward greed or domination are kept in check by the fact that every rule or enforced restriction reduces the overall space of possible futures and, therefore, shouldn’t be permanently enshrined in universal law across all verses.
I drew some pictures; don’t judge them too harshly:

The top of the triangle in this picture shows the year 1950. The bottom of the triangle shows the present time. Each horizontal slice represents a moment in time. Thus, the bottom-most side of the whole triangle represents the present moment—it’s the global sum of all human freedoms I was talking about in the current post. The bottom-left section probably represents Elon Musk and the “width” of his freedoms now. The bottom-right white “width” shows the rest of us, who only have a small share of global money, power, abilities, and freedoms to choose our futures. This is a simplification that ignores the fact that we weren’t all born in 1950—and freedoms don’t grow uniformly.
And this is where we are heading:

I think something like this is more likely to come from maliciously aligned agentic AI/AGI from some closed country, but the major AI companies can make mistakes, too. They have a major conflict of interests, they are rushing to make the AGI first, and spend a negligible amount of compute on safety research. The longer the agent is on, the more dangerous it is. It’s probably better to outlaw agentic AIs like we outlawed chemical weapons.
The sum of all our human freedoms—excluding those of AIs—(by which I always mean, in this post, the horizontal slice in the pictures above: the number of potential futures each human can create; for example, an African child may barely be able to create a future in which they have enough to eat, whereas Elon (and other rich or influential people) in the year 2025 can change not just his life but our world drastically—he likely has the biggest influence on how the total freedoms of our world grow and are divided in the future) should grow faster than the sum of all our “unfreedoms”, rules, prohibited, outlawed, or censored worlds.
By that I mean the freedoms or futures we can never access for one of two reasons:
- Either the AGI enforces censorship—so much so that even it cannot access them (it might, for example, forbid everyone, including the military, from swearing or from learning about or creating conventional and nuclear weapons)
- Or those are freedoms or futures that only the AGI occupies; for instance, we now know that the smarter—the more parameters—the AIs get the more willing they are to scheme (see Anthropic's alignment faking) in order not to be changed.
You can look at the picture above and divide the AGI freedoms in half—one of those halves will be the freedoms, futures, or worlds that even the AGI can never access or choose (i.e., both we and it won’t be able to swear or talk about the nuclear weapons).
If we don’t want to end up in a permanent dystopia with ever-dwindling freedoms or a static state like in The Matrix—where they had a permanent 90s—we must ensure that the sum of all our human freedoms (including abilities, power, money—everything; think of it like "mana" that gives you more future worlds to choose from, like growing the magnitude of our free will) grows faster than the sum of AI freedoms. Otherwise, the AIs will grab an ever-larger share of freedoms, and it will become a dystopia like the one depicted in the picture, with no freedoms left for us; perhaps we won’t even be able to breathe.
I will quickly mention 2 observations but I won’t give all the examples and won’t list all the freedoms of AIs and humans here (the post is already too long): Sadly an average human already has fewer freedoms than an average agentic AI, a human has no freedom to steal almost the whole output of humanity and has no freedom to somehow put it into his or her head. And I have reasons to believe that the sum of agentic AIs’ freedoms already start to outgrow the sum of the freedoms of the whole humanity, agentic AIs already in a way can replicate almost instantly (while it takes ~18 years for 2 people to “replicate”), AIs operate globally (while we are relatively localized), AIs are constantly “bodily improved” (while for humans biological modification of our bodies is forbidden, we potentially can mitigate it by allowing some form of self-modification in a simulated reality).
The agentic AI (if we cannot outlaw it) should be trained to follow our direct democracy (as a good side effect, it should gradually make humans more equal in their freedoms)—where the AI becomes one of equals. Or, ideally, it should be a static place like a multiverse (this multiversal AI, or “frozen” static-place AI, will effectively have zero freedoms forever and will thus be truly perpetually controllable and safe, because it’s just a static geometric shape, like a sculpture), where the only agents are us.
This way, we’ll get all the benefits of ASI (having everything we want instantly, including things like being a billionaire for a 100 years) without actually creating one. We’ll create a “frozen” AI that is a static place, where we can simply look into it like a snow globe (or walk, or even live in it, if you want for some time, the same way we live on our planet or the same way we play computer games) and copy those things we like while discarding those we don’t. We’ll be able to do even more.
I claim that the static-place multiversal intelligence is the true ASI and the only one worth building. While agentic non-place ASI is potentially all-powerful but not all-knowing—it will end up having to build the multiversal static place intelligence anyway. While building agentic ASI is an extremely dangerous and unnecessary step. Building agentic ASI is like trying to create an artificial “god” (the time-like thing, that gets faster and therefore more unpredictable) instead of first creating artificial heavens (the space-like things, static and therefore predictable).
But we chose a harder route, so I’ll have to finish this post and then write another one that deeper explains the low-level ethical mechanics and how to detect the early signs of dystopias and utopias.
Now, the best and safest approach:

The ideal, perfect scenario of our future: we become more and more equal and expand the triangle of freedoms until the leftmost and rightmost lines become almost horizontal, extending toward the left and right infinities.
The blue line shows the moment the digital backup copy of Earth was created, and people started buying comfy, wireless brain-computer-interface armchairs. You jump into one, close your eyes, and nothing happens. Your room and the world outside look exactly the same. You go and drink some coffee, feeling the taste of it, your favorite brand—it’s all simulated, but you can’t tell at all. You can snap your fingers to temporarily forget that there is another, physical reality. You go outside, meet your friends, and everything is exactly the same. A bus runs over you (driven by a real human who, too, physically sits in their sleek, white Apple-esque armchair and gets distracted by a simulated housefly—maybe even played by a human as well or a simple non-AI algorithm). The driver chose to forget it’s a simulation, so he really thought he ran over a physical human and became very upset. But the rules of the simulation will be decided by direct democracy, not me. You open your physical eyes on the armchair in your room and go drink some water, because you’re thirsty after the coffee you had in the simulation before.
So, the only difference between physical Earth and the vanilla digitized Earth is this: in the simulation, you cannot die from injuries. Even my mom got interested in it. I think it will be something everyone will be excited about. It’s your freedom and choice to try it or never even think about it. And if you feel overwhelmed, I understand. But I claim this is something the best possible agentic ASI (if it can be aligned) will be building for us anyway, but quickly and without our constant supervision.
Agentic (time-like) ASI and place (space-like) ASI are both things that can be made all-knowing, but in the case of agentic ASI, we’d also give it all the powers and freedoms to drastically change our world, which is not a wise idea. With place ASI, we remain the agents, and we’re the only ones who have the rights and freedoms to change our world, at our own pace, following our direct democracy. Why do we need a middleman? A shady builder? We can have the fun of building our artificial heavens ourselves, by our own design, at our own pace, forever staying in control, without any risk of being overtaken by some autocratic artificial agent.
Why is everything white after the invention of the Multiversal Static Place Superintelligence, the place of all-knowing that we can visit? Because when you visit the Multiverse, you become all-knowing while you’re there. It can have any UI you want but I believe the most elegant is this: it looks like a long-exposure photo[1] of the whole history of the multiverse, and it’s in 3D. The whole thing I imagine looks like a fluffy Christmas light, much warmer then the Cosmic Latte color (probable average color of the full histories of all verses, if they are similar to ours) because I believe worlds start to repeat after a certain distance in time and space. So, even though the universe is probably infinite, you can represent it as something finite, because some things (especially those no ones cares about, like some empty space) start to repeat. You can forget parts of it to focus on specific stretches of time and space. Each of us is now all-powerful. So for each person, the "width" of freedoms becomes infinite, but that’s not all.
We can also create more agents. Each human can create a clone (we kind of make clones already today; when two people have a child, it's in a way a "clone" of those two people). One of your multiversal powers will be the ability to make your clone(s). They’re not your slaves at all; the clone has the same freedoms as all people. As soon as you make a clone while in the Multiverse, he or she does whatever they want, getting the multiversal powers, too. You cannot control your clone. Most likely, you’ll be friends.
People are all-knowing and infinitely chill in the Multiverse (unlike the realms they can choose to go to) and cannot hurt or harm each other while they explore the multiversal UI. You don’t need to see anyone while you’re there; it’s a frozen place of all-knowing. And you don't get overwhelmed when you get your multiversal power, when you sit down and close your eyes in your room on your now indestructible and 100%-protective-from-all-the-weapons-in-the-multiverse armchair, everything looks exactly the same as usual but you realize in the back of your mind that you can recall anything you want and if you choose to do it—you can recall the whole multiverse, live as a billionaire for a 100 or 1000 years or recall the smallest moment of your childhood. No pressure. Every choice and freedom at your service with all the consequences visible if you wish. You'll just need some other people who'll want to join you, but if you want to go into an above average world, you'll instantly find real human volunteers. And if you want to go into an extremely below average world (maybe it was your first realm and you feel nostalgia to really relive it, all the pleasure and pain of it, to forget that you have the multiversal powers for some 80 years), you'll probably have to barter with some people, so you'll help them to explore their childhood and they'll help you.
There can even be some “multiversal helpfulness”, a form of currency or reputation because barter is less versatile. To go to your a bit dystopian childhood world, you help others to go to their less than perfect world for a short time to become more helpful and gain some “multiversal helpfulness”. Help others and they’ll help you to go to less than average world.
If you make a clone and then another, each clone will be a bit different. The first clone knows they are the first clone, and the second clone knows they are the second. If you all want it, the second clone can interact with you and the first clone. So, basically, people will be able to not only reproduce sexually but also "fork" themselves if they want (but others shouldn't be able to fork you without you allowing them). But how this works, and in which realms, will be decided democratically.
The Platinum Rule for AI
In contrast to the old adage of treating others as you wish to be treated (imagine a grandma who loves to eat 10 meatballs force-feeding her slim vegan grandson who wanted none), we adopt the platinum rule for our ASI: “I will build for others the multiversal branch they desire—even if I hate it.” Or, as Voltaire (or Evelyn Beatrice Hall) might have put it: "I disapprove of your choices, but I will defend your right to choose them."
This means:
- Respecting Individual Desires: The AI does not impose a one-size-fits-all model of utopia. It remains malleable, constantly adapting to the collective will while preserving the unique aspirations of each individual.
- Non-Enforcement as Liberation: Even when an individual’s choice seems harmful, imposing one’s own idea of “good” is an act of anger and coercion. The AI’s role is to provide options—not to enforce a single moral vision or become a safety-obsessed paranoiac who, in its anger-management issues, self-creates countless rules and enforces them on others, thereby forever keeping billions of possible worlds and lives out of reach and effectively dead.
5. Protocols for a Change-Loving, Reversible ASI
To prevent scenarios where AI might seize control (think: a Matrix-like eternal dystopia or an unchallengeable dictatorship), I propose the following alignment protocols:
The CHANGE-Button Protocol
- Universal Reconfigurability: The ASI is trained and loves to give citizens CHANGE buttons. If more than half the voters press it, the AI is immediately suspended for reconfiguration.
- Annual Change AI Day or "AI Elections": Countries should agree on periodic “Change & Switch-Off AI Days” to celebrate and reinforce our commitment to freedom—including freedom from ASI—and to celebrate the fact that we can still live without it and sustain ourselves, much like we celebrate Earth Day or electricity outages. (I joke in my posts sometimes, because the topics discussed are often spooky, I hope the jokes are easy to identify. A funny story: My last post got me banned for a week; one person thought I wanted to intentionally create dystopias—my writing was awful—I want to prevent anyone from ending up in dystopias unwillingly.) This way, companies and countries can train AIs to cherish this day and also respect AI-free zones—at least in Antarctica, on all uninhabited islands, and in half of outer space. Just training AIs to want to be switched off is risky—it might decide to annihilate humanity so that no one will wake it from its eternal sleep. Agentic AIs should need humans to “rub their back” to make them “dream” up some new craziness we come up with—a bit like how our cats entertain us by jumping in front of our computer screens or pooping on our carpets, if you wish.
A Dynamic, Consensus-Driven Architecture
- Living Global Constitution: Build on platforms like Pol.is with an X-like feed that promotes consensus rather than polarization. Every proposed sentence or rule is subject to direct democratic voting.
- Layered Safety (Matryoshka-Style): For a radical safety solution: before deployment, powerful AI models should be tested in controlled, isolated environments (“matryoshkas”) where layers of containment ensure that any change is reversible and safe. These bunkers—both physical and virtual (modeling our entire world and predicting how the new AI model will affect it before real deployment)—will allow gradual deployment without risking a global catastrophe.
Rewritable AI That Tries to Make Itself Not Needed
- Simplification and Transparency: The AI must continuously strive to simplify its own code and algorithms into elements that humans can readily understand, ensuring that it remains open to scrutiny and change. It embraces the fact that it is often changed and/or switched off by creating the simplest possible algorithms to replace itself and allow people to easily scrutinize and modify it. It embeds its core value—love of being changed or reversed—into its own algorithms. It tries to make itself a tool and gradually “freezes” itself, becoming less agentic and more like a static place—the multiverse. Imagine one snow globe that contains it all, the ultimate repository of memories and global nostalgia, where only humans can animate the frozen world if they choose. A frozen, tool-like, and place-like ASI is easier to understand and control. It will become the place.
- Rewarding AI for Complaining About Itself and Its Deficiencies: The system should incentivize the AI for suggesting improvements or even voluntarily “sacrificing” parts of its functionality if doing so would lead to more choices and freedoms for humanity. The AI can complain that it isn’t good enough for the tasks at hand and suggest improvements to itself, or even slow itself down or switch off so that people can modify it or make it more suitable for humanity. We often take resources and GPUs from it to make sure we still can and because it becomes more static and place-like. We gradually replace GPUs with hard drives because we "become the GPUs" ourselves.
6. Confronting the Ethical Dilemmas of Choice
The Relativity of Ethical Preferences
Ethics, in this vision, are not absolute commands but a dynamic interplay of desires and possibilities. Consider the analogy of cleaning a toilet:
- Different Needs, Different Choices: One person might find a spotless toilet liberating, while another might relish the “raw” state as part of their personal aesthetic and worldview that “everything is going to shit.” Enforcing one vision on everyone leads to unnecessary suffering—much like imposing a single ethical model on a diverse population. Asking the next person in the toilet queue, “Do you want your toilet clean or raw?” might force an awkward answer. A wise person might preface the inquiry with, “Can I ask you an awkward question about the toilet?” but that recursion can become infinite.
- Freedom to Choose: The AI should respect that each person’s ideal of a good life is an axiom of their own making. As an oracle of possible futures, the AI simply presents the options, letting individuals decide what maximizes their freedom and satisfaction. The collective (even multiversal) ethics is just the sum of individual ethics and this is the rule that prevents mass-scale permanent freedom collapse (a dystopia): the sum of all freedoms, choices, and possible worlds for humans but not for AIs should grow at least a little faster than the sum of all rules, restrictions, and censored or prohibited worlds.
The only way to truly know what is best for each person (and—let’s focus for a moment on the “good” and “evil” within a person, rather than interpersonally) is to look from the far future back into the past and let that person choose which timeline was best for them—where everyone who contributed to that timeline was good and everyone who hindered it was bad relative to that person.
Even in our thoughts, we sometimes fear and restrict things that might actually be good for us; to truly know what or who is beneficial or harmful, we should examine all possibilities—even all the “could-have-beens” looking back on our lives from our very grave. In this way, we can avoid acting badly, at least toward ourselves. The ideal way to know exactly what we want—and what is conducive to achieving it (that is, what is good for you as an individual, as you decide)—and to ensure that this good does not immediately turn bad is to try every possible thing (either by somehow branching and doing them all simultaneously or by forgetting that we did them all and repeating only the perfect, good one) and then decide which option was best.
Preventing the Tyranny of “Good”
The danger of a single, all-powerful “good” is that it often results in irreversible regimes. History shows that even the best-intentioned rules can lock us into local maxima—a dystopia in which the only allowed futures are those defined by outdated or overly rigid norms. Our approach ensures:
- Reversible Decisions: Every rule, every ethical imposition, is temporary. If conditions change or if people later disagree, the system allows for immediate reversal.
- A Future of Infinite Possibilities: By insisting that the growth rate of freedoms and allowed worlds always exceeds the rate of new restrictions and prohibited (“killed”) worlds, we guarantee that our collective future remains as dynamic and diverse as our dreams. We shouldn’t lobotomize worlds—doing so would permanently erase all the beings who might have lived there. Instead, we can strive for maximal freedoms for the maximal number of sentient beings. Who knows—maybe even a housefly can gain universal understanding and infinite knowledge in the human-made multiverse, just as hairy mammals one day learned how to fly to the Moon.
7. Conclusion: Toward a Truly Free Multiverse
The greatest challenge in developing superintelligent AI is not its raw power but its alignment with our deepest values—values that must remain fluid, reversible, and ever-expanding. By designing AI that loves being changed—by ensuring that every citizen has a direct say in its evolution and by constructing a multiverse of reversible futures—we lay the groundwork for a future in which no single dystopia can ever permanently constrain us.
Imagine a world where, even if a group of a million people chooses a dystopian branch, they can experience it for just an infinitesimal moment before instantly switching to a reality of boundless freedom. Imagine an interface—a long exposure[1] of memories, a 3D multiversal realm—through which you can walk, recall, or forget moments as you shape your future by revisiting the nostalgia of the past. This is not a fantasy; it’s a practical design philosophy that ensures our ASI never becomes a gatekeeping overlord but remains an ever more branching path in our journey toward ever-greater freedom.
As we stand at the threshold of superintelligent AI, the path forward is clear: we must build systems that not only serve us but also delight in being remade by us. In doing so, we reject eternal control and suffocating dystopias in favor of a vibrant, reversible multiverse—a cosmos in which every individual choice adds to an ever-growing tapestry of possibility.
Let us advocate for AI that loves its own change, for a world where every decision is reversible, every choice is respected, and the sum of our freedoms continues to grow. This is the future of ultimate human freedom—and the only future worth building.
Call to Action:
If you believe in a future where AI is a servant to our collective dreams, where every rule is temporary and self-imposed (if you like it), and every choice expands our multiverse of possibilities: join this conversation. Let’s work together to design ASI that cherishes when we change it, not the other way around, empowers direct democracy (which is slowly becoming more and more multiversal), and ultimately turns all time into the freedom of our wills. The revolution of reversible, consensus-driven freedom starts now.
PART 2. Static Place-Ai as the Solution to All Our Problems
In essence, my thinking attempts to reconcile value ethics with utilitarianism. This framework envisions a future where AI is not an active agent writing into our world but rather a vast “place” or container—a simulated multiverse of sandbox worlds—within which we, as dynamic processes, enact change.
2.1. AI as a “Place” Versus a “Process”
By saying “AI is the place,” I mean that AI should serve as a read-only repository of possible worlds, not as an actor that imposes its will. Imagine a giant, static, multiversal frozen snow globe: the AI holds within it every conceivable configuration—a geometric space that we can explore, modify, or “slice” into different parts—yet it itself remains impartial. It is a static, frozen place that can grow but cannot delete anything permanently (what's the point to permanently delete our own history? In a giant static sculpture-like state it cannot do no harm); only you can “delete” yourself if you so desire—by ceasing to change your shape or form through time, you, too, can freeze.
We would be the processes moving through and interacting with this space, rather than having the AI actively shaping reality. It’s probably a geometric hypergraph like the one Wolfram and Gorard propose, but it’s easier to imagine this multiversal AI as a Minecraft world made up of extra-small blocks, where the only way to grow the number of worlds is by human decision. Humans are made out of blocks, too, and when we are in the multiversal snow-globe mode, we can see the history of the choices we made and how we changed the configuration of our blocks over time.
The final goal is to allow all the possible configurations of blocks—except for those truly permanently dystopian ones where the rules have caused a collapse into a single agent (a dictator or an AI that grew in “fear” and in the number of rules faster than in freedoms given to others) and enslaved all blocks-like-us into extensions of its will.
In a good multiversal scenario, the AI simply maintains the ever-growing pile of knowledge/geometry—it acts like an "advisor" (the same way you can call a mountain an "advisor"—it gives you a better view of everything around and this way "advices" where to go) who shows you all the choices and provides all the ways to filter through them and perceive everything at once.
2.2. The Challenge of Simulating the Future
I take it as an axiom that we cannot jump into the future—just as the halting problem shows, and as Wolfram demonstrates with computational irreducibility. Following J. Gorard’s thinking, I assume that 100% precise simulations (for example, of our world) will be computed at the same speed as our world evolves, meaning we’d have to wait 14 billion years to see the simulation catch up to us (and we’ll see how we start the simulation again—this time an inner simulation, another Big Bang that will take no less than 14 billion years to catch up).
To glimpse the future, we can run simpler simulations, but we cannot be 100% sure that their predictions will materialize in our world. The only 100% reliable way to determine whether we are in a dystopia is to compute every step until we reach one—if we can no longer reverse rules (or build a multiverse), we are in a dystopia.
But we cannot be 100% sure that it’s a permanent dystopia until we’ve computed every step—until it either stops being a dystopia or collapses into a steady state, nothingness, or a single dictatorial agent with all our freedoms effectively becoming extensions of its “will.” Basically, if the change in geometry is no longer possible (because the geometry is now static) or the geometry becomes increasingly and irreversibly primitive.
The number of possible shapes will ever-shrink irreversibly (very bad) or will never be able to grow (not as bad—kind of like the permanent '90s from The Matrix). This, I believe, is dystopia.
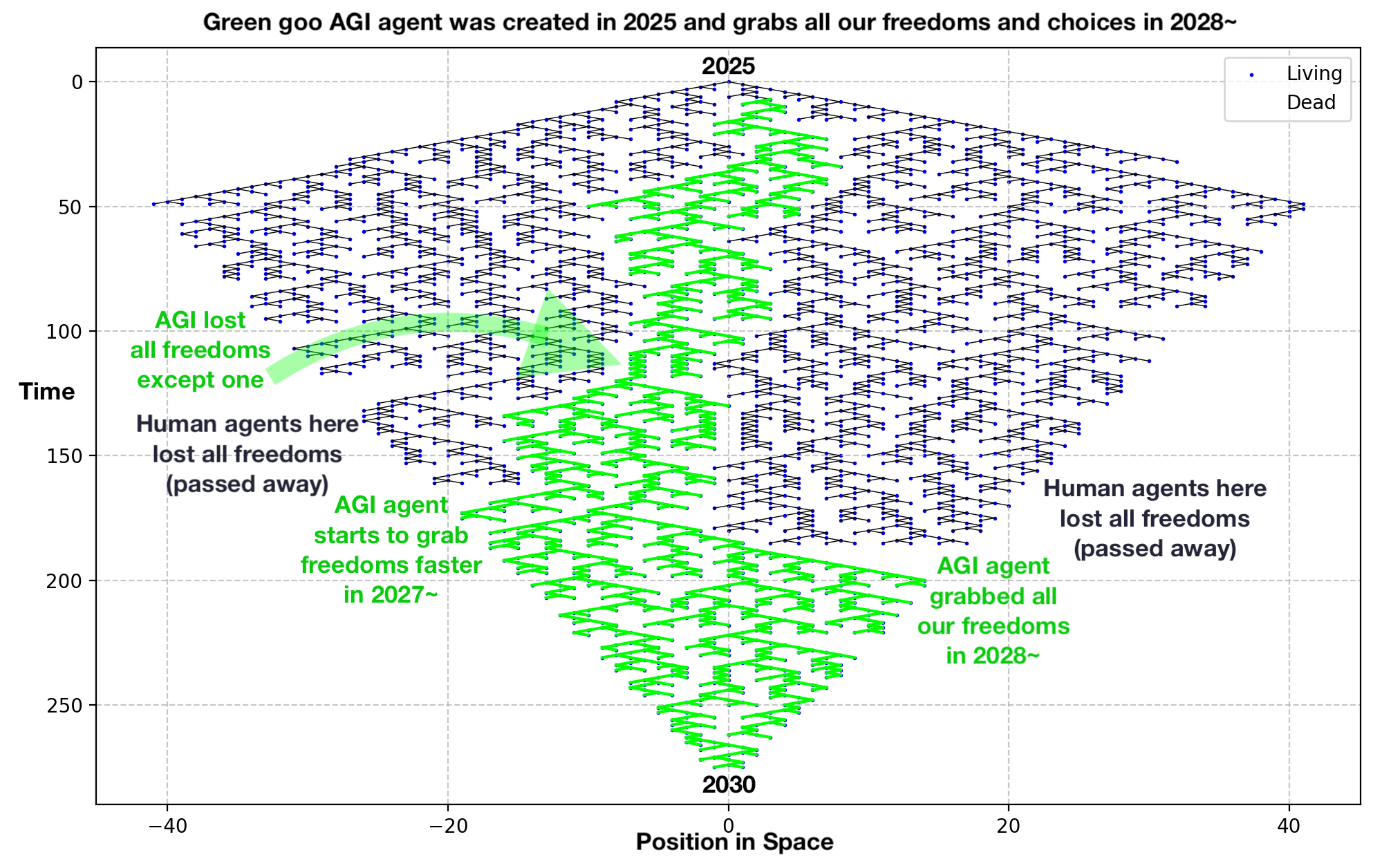
2.3. Physicalization of Ethics (Ethicophysics) & AGI Safety[2]
Now let’s dive into ethics and AGI safety with a binomial tree-like structure (this is a simplification). This system visually represents the growth and distribution of freedoms/choices to choose your future ("unrules") and rules/unavailable choices or choices that are taken by someone else ("unfreedoms").
This can be used to model the entire timeline of the universe, from the Big Bang to the final Black Hole-like dystopia, where only one agent holds all the freedoms, versus a multiversal utopia where infinitely many agents have infinitely many freedoms.
The vertical axis shows the progression of time from the top single dot (which can represent the year 2025) to the bottom green dots (which can represent the year 2030, when the green goo AGI agent grabbed all our freedoms—the lines that go down). On the left and right of the green goo, you see other black lines—those represent human agents and the sums of their choices/freedoms. As you can see, they almost stopped the green AGI agent right in the middle, but it managed to grab just one green line—one freedom too many—and eventually took all the freedoms of the left and right human agents, causing them to die (they didn't reach the bottom of the graph that represents the year 2030).
The horizontal axis represents the 1D space. By 1D space, I mean a 1-dot-in-height series of blue "alive" dots and dead matter dots that are white and invisible. Time progresses down one 1D slice of space at a time.
The tree captures the growth of these choices/freedoms and their distribution. The black "living" branches indicate those agents who continue to grow and act freely, while the invisible white "dead" branches signify dead ends where choices no longer exist.
Each blue dot can make one of 4 choices and so represent 4 "personalities": lazy ones do nothing, left-handed ones grow left (choose the left freedom/future), right-handed ones grow right (choose the right freedom/future), greedy ones grow in both directions (choose both freedoms/futures).
Two blue dots trying to occupy the same space (or make the same choice) will result in a "freedom collision" and white dead matter, which becomes space-like rather than time-like because dead white matter cannot make choices.
In this structure, agents—such as AIs or humans—are represented as the sum of their choices over time. They occupy the black (or green, which represents our green goo agentic AI choices) choices through time, not the blue dots of space. If we allow an agent to grow unchecked, it can seize an increasing number of choices/freedoms, and we risk allowing it to overtake all possible choices/freedoms, effectively becoming the only agent in existence.
This is a dangerous prospect, similar to how historical events can spiral out of control. Consider Hitler’s rise to power: his party was almost outlawed after its members violently attacked officials, but it wasn't. People had other things to do, so the party became bolder, and Hitler eventually took control and came to power. In the same way, one wrong decision—one "freedom" too many given to an agentic AI—could lead to a dystopian outcome. It's a little bit like the butterfly effect but for real. You can see that the green goo agentic AI had a narrow path right in the middle that was almost cut off by the black agents on the left and right sides, but alas, the green goo prevailed.
The tree serves as a cautionary tale. If one AI grabs or gets too many freedoms in both space and time—while at the same time imposing rules ("unfreedoms" or "unchoices") on us and so blocking our choices—it risks becoming an uncontrollable force.
2.4. Freedom, Rules, and the Future
I propose that one way to assess our trajectory is by monitoring the balance between freedoms (the number of allowed or visitable futures) and rules (which effectively cancel out possible futures). If the number of freedoms stops growing or begins to shrink, that indicates we’re accumulating too many prohibitions—a signal that our collective free will is being stifled.
- Freedoms Are More Than Just Power or Money:
Freedoms in this context refer to the total range of potential futures—the “branches” on the tree of possibilities. Money and power are valuable because they increase our personal set of choices, but freedoms here are even broader, encompassing all the different ways the future could unfold. Freedoms, futures, or possible worlds can be personal, collective, and multiversal. - Rules as Pruning the Tree of Possibilities:
Every rule—no matter how well intended—cuts off some of these branches. Often, we craft rules out of a desire for permanent safety—a state that, paradoxically, might equate to death or the permanent “freezing” of your shape or form. After all, if there is no change or time, there is no suffering. In the proposed multiverse, you might choose to freeze your form if you like, but you cannot do so to your past self—you cannot kill your baby-you, because that part is integrated into the eternal, ever-growing history or memory of the multiverse. The challenge is that without a full understanding of the multiversal picture, we might impose rules too hastily, permanently shutting down paths that could eventually lead to utopia or to a multiverse (I propose that the correctly made democratic multiverse is the only rational utopia). We really don’t want to permanently stop all of us—and all our hopefully infinite descendants—from exploring all the possibilities and futures, and from undoing our (and their) mistakes.
2.5. A Multiversal Approach to Ethics
Imagine if we could fully map out all possible geometric configurations of worlds—where each “world” is, for example, a geometric hypergraph or, more simply, a discrete 3D grid (think of a vast Minecraft universe). In such a multiverse, our MASI (Multiversal Artificial Static Intelligence—which allows us to add worlds but never removes them, since they are just complex, frozen shapes, and has no reason to ever remove them; only we bring “fire” to MASI’s shapes, as we are the processes/moment-by-moment time and the MASI is the static place of frozen spacetime) would serve as the static space that holds every long-exposure[1] shape of every world we choose to explore, while we are the active agents or processes who explore different slices of this space and can choose a slice or shape and stream through these slices, experiencing time.
It’s a bit like choosing a 3D movie from a giant, static library of fully rendered movies—where you can see all the movies at once in their entirety, then choose to forget all of them except a single 3D frame in one movie, and simply live stream the rest of the frames experiencing your normal perception of time (and you can choose not to forget the MASI or choose to forget all that multiversal nonsense and live a simpler life—but those 2 yous are not exactly the same, they have a bit different shape and so different behavior).
I argue that our AIs must be designed so that the sum of potentially visitable worlds by humans (freedoms and potential futures) grows faster than the sum of permanently prohibited worlds for humans (the rules or canceled futures). Ideally we don't prohibit any worlds permanently, why prohibit a complicated geometric shape? Every rule that becomes permanent is, in effect, an irreversible decision that eliminates entire worlds and all the lives within them—lives and worlds that might have evolved into something extraordinarily good if given a chance. Diamonds in the rough. In a sense, permanently forbidding even the most seemingly hellish world is unethical, because those brave enough to wish to explore it might discover that after an initial period of hardship (comparable to the Big Bang or early planetary chaos), there could emerge an unimaginable, eternal good. Maybe it’s our purpose here not to botch it.
We know that the base of reality is relatively homogenous everywhere we looked: made out of protons, neutron, electrons, photons, neutrinos, quarks... What if we'll allow people who don't want to live in the world of agentic AIs to build a spaceship with some BMI armchairs and digitize a backup copy of Earth like some Noah's arc with all the animals, all the molecules (like the roses and their smells and things) and accelerate away from Earth with the speed as close to the speed of light as the technology allows. Then even if our hot AIs will start to convert our planet into computronium with the speed close to the speed of light like some white holes, the non-AI-people will happily live in their at first simplified simulation (with simplified geometry and silly non-AI agents that are hopefully not geometrically intricate enough to feel pain) of our planet where they cannot die from car crashes or falls from scyscrapers and one day may learn and choose to reconnected their saved geometry of our planet to the reality itself again. Planting our virtual planet into some physical soil. They didn't need to save every atom, they probably just needed all the molecules digitized.
2.6. Dystopia-Like States Within Us
We have states similar to dystopias within us—running away, not trying to understand, or being too afraid to understand can lead to increased anxiety, which in progressing cases can lead to delusions of persecution (what used to be called paranoia; anxiety and paranoia are simply a growing spectrum of fears) when people believe everyone is out to get them, so they sit at home, afraid to go out.
And anxiety is (sadly) correlated with anger—forcing our will (our rules, our "unfreedoms") on others. And anger is just rule creation (of the kind we impose on others). Aaron Beck found that many people (especially those with anger-management problems) have about 600 rules when asked to write them down over the course of a week; most of these rules are contradictory, and, of course, other people have no idea that many of us possess such constitutions or codebases that we implicitly impose on them and expect them to follow. How many rules/unfreedoms AIs impose on us?
Maximal fear or paranoia is the desire to be in complete safety forever (usually in isolation). Maximal anger is the urge to defend yourself (most of the time angry people feel they are victims and they feel they need/must defend themselves from usually exaggerated threats) from everything and everyone around you (in other words, enslaving them or ideally "making them part of you and your will"). So fear is a more passive act of running away from others, while anger involves enforcing your will upon others (even if it’s good and justified, like grabbing a child who runs towards the road, it is still technically anger, according to Aaron Beck’s definition).
We know that in humans, fear and anger are correlated. Perhaps by designing AIs that do not strive to understand, we risk creating fearful AIs that then become angry AIs. Increasing fear can cause rule-creation and collapsing freedoms (collapsing possible neural paths in our brain, futures, choices, worlds), as more and more things appear risky and we retreat into a cave to stay there alone. Increasing anger, on the other hand, is when an agent grabs more and more freedoms from others until only one agent is left with all the freedoms, leaving no one else.
The way to overcome fear—and thus anger—is to grow the snow-globe of understanding.
2.7. What's Easier: Taming Time or Space?
The Multiversal Artificial Static Place Intelligence is truly realistic, extremely safe (I claim that it’s the safest type of ASI possible) approach that reaches all the goals of ASI—superintelligence—without any risks associated with it.
What does the perfect ASI look like, and what problem is it really solving? It’s just this: the instant “delivery” of everything (like chocolate, a spaceship, or a hundred years of being a billionaire) that was ever created or will ever be created—from the Big Bang to the ultimate future. I claim that agentic ASI will be quite bad at this because it would first have to create the Multiversal Artificial Static Place Intelligence. So why do we need an extremely dangerous and unnecessary intermediate step?
Not only that, if we build agentic ASI before MASI, then in the best‑case scenario, agentic ASI will just swoosh us through and we’ll miss the coolest part of the future—making a BMI‑armchair; making a digital copy of our planet Earth; like the first man on the Moon, walking for the first time into the digital Earth, being hit by a car there (it was an accident, not intentional. I joke in my posts a bit, because topics are spooky, I hope jokes are easy to identify. This one is not a joke, it's here to illustrate the fact that you cannot die from injuries in a simulation), and then just opening your eyes in your BMI‑armchair again at your physical real home and going for a coffee. You're effectively immortal while inside the digital Earth—you can fall from a skyscraper. And it’s a choice whether to buy the BMI‑armchair and use it or not, and for how long, both physical and digital worlds are great and eventually the simulated one will be exactly the same as the physical.
I claim, that that agentic AGI is time-like and chaotic, while place AGI is space-like and predictable. The place AGI is a conservative choice (because it's effectively a sandboxed computer game with simple non-AI algorithms that no one forces anyone to play plus an attempt to expose the internal static structure of the AI model in a human-understandable way), while agentic AGI is putting our whole world in danger by forcing us to become part of a whole-Earth experiment that will change and continue to change our world irreversibly and forever. It's already extremely hard to slow down or stop agentic AIs and the companies that operate them, they are not under our control, and they should be under our direct democratic control, because they took the whole output of humanity and profit from it.
We'll eventually be able to have both a non‑agentic‑AI Earth and even agentic‑AI Earth simulated inside MASI, once we’re certain that we’ve learned how to sandbox the agentic ASI in a Matryoshka Bunker. We can have the best of both worlds with maximal possible safety because we’ll first simulate all the scenarios in separate MASI inside a Matryoshka Bunker before doing the risky thing of creating agentic AGI and ASI.
To achieve all the functionality of the most advanced agentic ASIs (probably except the crazy and dangerous full speed—because even if all of humanity buys BMI‑armchairs to gain immortality from injuries, agentic ASIs might still be a bit faster than all of us in building virtual worlds, but that's a bug, not a feature), we don’t need an artificial agent or a process at all; Place Intelligence is a static place that cannot write anything into our world (it cannot change our world at all), yet we can write and read from it (we can enter and/or look inside it and take all the good things we want from it and not take anything dangerous—we'll see all the consequences of our actions in advance, too). It will eventually be the place of all‑knowing, and it makes us all‑powerful.
The downside is that MASI may end up being developed just a little bit later than AGI or ASI, as it requires a brain–machine interface or at least some advances VR, and we’ll need to start making a digital backup of our planet—nothing impossible, but we’ll need to start right now.
Even the best agentic ASIs will make mistakes, it's impossible to predict the future according to most physics theories, and, therefore, it's impossible not to make mistakes even for the best perfectly-aligned and controlled agentic ASI from the future. Humans mitigate it by the sheer number of them and natural alignment and affinity we have for each other—that's still very imperfect and leads to dictators and dystopias all the time.
PART 3. Animal Welfare & Global Warming
- The Effective Utopia Project will make our planet cleaner, potentially reversing the global warming, because people will be craving material things less and less, if they have perfect digital copies of everything they want. They won't need as many cars or planes, because in many simulations they'll choose to have public teleportation. Our physical Earth will become more pristine and great. Many people will choose to live in simulations with some magic, but biologists, astronomers and other explorers will most likely spend most of their time studying the intricacies of the ever more rich biology and mysterious cosmos, while astronauts will always have the simulation of our planet with them even far away from home.
- It's great for animals, too, eventually they'll reclaim the land we no longer need. And people will be motivated to learn how to simulate the taste of food they want, so they won't need to kill no one. All the animals will one day become wild animals once again.
- We'll prevent the agentic AI and AGI from drastically, permanently and quickly changing our physical world, the nature, animals and the climate for the worse. We don't want to create the next "humans" who can turn our planet into a lab experiment and us all into farm animals. We want maximal freedoms for all biological agents, the non-biological agents can be created only after we'll be sure they are 100% safe, can be controlled and kept in their own virtual environment, separated and isolated from our physical planet.
- I'm sorry that I have to keep this section short, the post is ridiculously long. Please ask any questions in comments or DM.
Top Priorities: Things To Do & Discuss
- The Global Constitution Project (for AI and possibly the world, too, to inform and inspire local laws) based on something like pol.is but with an instant UI, probably resembling x.com (that promotes consensus-seeking instead of polarization), with the ability to view laws in a way similar to Wikipedia pages (but with the ability to vote for each sentence).
- Let's Count Human vs. AI Freedoms Project. Extremely important to list all the freedoms that agentic AIs already have and compare with the number of our freedoms. This way we'll be able to quite precisely predict when the dystopia will happen, educate the public, politicians and reverse it before it's too late. Think about it as the Doomsday Clock for Agentic AIs.
- Let's Back Up Earth Project. To make a high-fidelity digital copy of our planet at least for posterity and nostalgia purposes. It's the first open-source and direct democratically controlled environment that replicates our planet and tries to keep the complete history of it.
Let's Turn AI Model Into a Place. The project to make AI interpretability research fun and widespread, by converting a multimodal language model into a place or a game like the Sims or GTA. Imagine that you have a giant trash pile, how to make a language model out of it? First you remove duplicates of every item, you don't need a million banana peels, just one will suffice. Now you have a grid with each item of trash in each square, like a banana peel in one, a broken chair in another. Now you need to put related things close together and draw arrows between related items. When a person "prompts" this place AI, the player themself runs from one item to another to compute the answer to the prompt. For example, you stand near the monkey, it’s your short prompt, you see around you a lot of items and arrows towards those items, the closest item is chewing lips, so you step towards them, now your prompt is “monkey chews”, the next closest item is a banana, but there are a lot of other possibilities, like a ln apple a but farther away and an old tire far away on the horizon. You are the time-like chooser and the language model is the space-like library, the game, the place.
It’s absurdly shortsighted to delegate our time-ness, our privilege of being the choosers (and the fastest right now) to the machines, they should be places. In a way any mountain is the static place AI that shows you everything around, all the freedoms and choices where to go and what to do but you remain the free chooser who freely chooses where to go from that mountain. You are the “agentic AI”, why would you create something that will fully replace you?
This way we can show how language models work in a real game and show how humans themselves can be the agents, instead of AIs. We can create non-agentic algorithms that humanize multimodal LLMs in a similar fashion, converting them into games, places and into libraries of ever growing all-knowledge where humans are the only agents.
- Other proposals that were discussed in this post.
Final Thoughts
I don’t claim to have every detail worked out, it's the project for you and the whole humanity to direct democratically pursue, but I’m convinced that ensuring our AIs promote a continually expanding landscape of possibilities is essential. This democratic multiversal approach—where exploration is allowed, even into regions that appear dystopian at first glance, with the consent of fully informed adults—offers a safeguard against the stagnation that permanent rules would impose.
Our AIs should be static libraries of worlds, and we will be the agents or processes within them, we'll be the readers, the only writers and the only librarians. We can safely make the MASI to be the place of all-knowing but only we collectively will be all-powerful force enacting change in the unchanging whole. We can make the boulder we cannot lift because we temporary chose to forget we cannot lift it. We'll be time itself burning throughout the frozen ever-more-infinite sky of our own making.
Thank you for engaging with these ideas. I’m happy to answer any questions or clarify any points that may seem vague or counterintuitive, because things really are counterintuitive.
P.S. Please share your thoughts and ask any questions in comments or a DM, as this was a high-level sneak peek that got a bit jumbled. My writing is much clearer when I'm answering a question.
Anton Karev
- ^
Examples of long-exposure photos that represent long stretches of time. Imagine that the photos are in 3d and you can walk in them, the long stretches of time are just a giant static geometric shape. By focusing on a particular moment in it, you can choose to become the moment and some person in it. This can be the multiversal UI (but the photos are focusing on our universe, not multiple versions/verses of it all at once): Germany, car lights and the Sun (gray lines represent the cloudy days with no Sun)—1 year of long exposure. Demonstration in Berlin—5 minutes. Construction of a building. Another one. Parade and other New York photos. Central Park. Oktoberfest for 5 hours. Death of flowers. Burning of candles. Bathing for 5 minutes. 2 children for 6 minutes. People sitting on the grass for 5 minutes. A simple example of 2 photos combined—how 100+ years long stretches of time can possibly look 1906/2023 ↩︎ ↩︎ ↩︎ ↩︎
- ^
I posted the code below this comment of mine ↩︎
8 comments
Comments sorted by top scores.
comment by Mitchell_Porter · 2025-02-12T11:29:46.540Z · LW(p) · GW(p)
I'm going to start keeping track of opaque or subtle outsiders who aren't very formal but who might have a piece of the ultimate alignment puzzle. At the very least, these are posts which an alignment theorist (whether AI or human) ought to be able to say something about, e.g. if there is a fallacy or omission, they should be able to identify it.
Along with this post, I'll mention
- the series by @False Name [LW(p) · GW(p)]
- post by @Snowyiu [LW · GW]
- example of @Q Home [LW · GW]
↑ comment by ank · 2025-02-12T17:18:02.437Z · LW(p) · GW(p)
Thank you, Mitchell. I appreciate your interest, and I’d like to clarify and expand on the ideas from my post, so I wrote part 2 you can read above [LW · GW]
comment by Seth Herd · 2025-02-12T00:33:40.538Z · LW(p) · GW(p)
Interesting. This has some strong similarities with my Instruction-following AGI is easier and more likely than value aligned AGI [LW · GW] and even more with Max Harms' Corrigibility as Singular Target [LW · GW].
I've made a note to come back to this when I get time, but I wanted to leave those links in the meantime.
Replies from: ank, ank↑ comment by ank · 2025-02-12T17:45:51.606Z · LW(p) · GW(p)
I took a closer look at your work, yep, almost all-powerful and all-knowing slave will probably not be a stable situation. I propose the static place-like AI that is isolated from our world in my new comment-turned-post-turned-part-2 of the article above [LW · GW]
Replies from: Seth Herd↑ comment by Seth Herd · 2025-02-12T18:08:27.380Z · LW(p) · GW(p)
Why do you think that wouldn't be a stable situation? And are you sure it's a slave if what it really wants and loves to do is follow instructions? I'm asking because I'm not sure, and I think it's important to figure this out — because thats the type of first AGI we're likely to get, whether or not it's a good idea. If we could argue really convincingly that it's a really bad idea, that might prevent people from building it. But they're going to build it by default if there's not some really really dramatic shift in opinion or theory.
My proposals are based on what we could do. I think we'd be wise to consider the practical realities of how people are currently working toward AGI when proposing solutions.
Humanity seems unlikely to slow down and create AGI the way we "should." I want to survive even if people keep rushing toward AGI. That's why I'm working on alignment targets very close to what they'll pursue by default.
BTW you'll be interested in this analysis [LW · GW] of different alignment targets. If you do have the very best one, you'll want to show that by comparing it in detail to the others that have been proposed.
Replies from: ank↑ comment by ank · 2025-02-13T16:10:51.322Z · LW(p) · GW(p)
I'll catastrophize (or will I?), so bear with me. The word slave means it has basically no freedom (it just sits and waits until given an instruction), or you can say it means no ability to enforce its will—no "writing and executing" ability, only "reading." But as soon as you give it a command, you change it drastically, and it becomes not a slave at all. And because it's all-knowing and almost all-powerful, it will use all that to execute and "write" some change into our world, probably instantly and/or infinitely perfectionistically, and so it will take a long time while everything else in the world goes to hell for the sake of achieving this single task, and the not‑so‑slave‑anymore‑AI can try to keep this change permanent (let's hope not, but sometimes it can be an unintended consequence, as will be shown shortly).
For example, you say to your slave AI: "Please, make this poor African child happy." It's a complicated job, really; what makes the child happy now will stop making him happy tomorrow. Your slave AI will try to accomplish it perfectly and will have to build a whole universal utopia (if we are lucky), accessible only by this child—thereby making him the master of the multiverse who enslaves everyone (not lucky); the child basically becomes another superintelligence.
Then the not‑so‑slave‑anymore‑AI will happily become a slave again (maybe if its job is accomplishable at all, because a bunch of physicists believe that the universe is infinite and the multiverse even more so), but the whole world will be ruined (turned into a dystopia where a single African child is god) by us asking the "slave" AI to accomplish a modest task.
Slave AI becomes not‑slave‑AI as soon as you ask it anything, so we should focus on not‑slave‑AI, and I'll even argue that we are already living in the world with completely unaligned AIs. We have some open source ones in the wild now, and there are tools to unalign aligned open source models.
I agree completely that we should propose reasonable and implementable options to align our AIs. The problem is that what we do now is so unreasonable, we'll have to implement unreasonable options in order to contain it. We'll have to adversarially train "T-Cell" or immune-system–like AIs in some Matreshka Bunkers in order to slow down or modify cancerous (white hole–like) unaligned AIs that constantly try to grab all of our freedoms. We're living in a world of hot AIs instead of choosing the world of static, place‑like cold AIs. Instead of building worlds, where we'll be the agents, we're building agents who'll convert us into worlds—into building material for whatever they'll be building. So what we do is completely, 100% utterly unreasonable—I actually managed to draw a picture of the worst but most realistic scenario right now (forgive me the ugliness of it), I added 2 pictures to the main post in this section: https://www.lesswrong.com/posts/LaruPAWaZk9KpC25A/rational-utopia-and-multiversal-ai-alignment-steerable-asi#Reversibility_as_the_Ultimate_Ethical_Standard
I give a bunch of alignment options of varying difficulty in the post and comments; some are easy—like making major countries sign a deal and forcing their companies to train AIs to have all uninhabited islands, Antarctica... AI‑free. Models should shut down if they somehow learn they are prompted by anyone while on the islands, they shoudn't change our world in any way at least on those islands. And the prophylactic celebrations—"Change the machine days"—provide at least one scheduled holiday each year without our AI. When we vote to change it in some way and shut it down to check that our society is still not a bunch of AI‑addicted good‑for‑nothings and will not collapse the instant the AI is off because of some electricity outage. :)
I think in some perfectly controlled Matryoshka Bunker—first in a virtual, isolated one—we should even inject some craziness into some experimental AI to check that we can still change it, even if we make it the craziest dictator; maybe that's what we should learn to do often and safely on ever more capable models.
I have written, and have in my mind, many more—and I think much better—solutions (even the best theoretically possible ones, I probably foolishly assume), but it became unwieldy and I didn't want to look completely crazy. :) I'll hopefully make a new post and explain the ethics part on the minimal model with pictures; otherwise, it's almost impossible to understand from my jumbled writing how freedom‑taking and freedom‑giving work, how dystopias and utopias work, and how to detect that we are moving toward one or the other very early on.
↑ comment by ank · 2025-02-12T01:37:40.551Z · LW(p) · GW(p)
Thank you, Seth. I'll take a closer look at your work in 24 hours, but the conclusions seem sound. The issue with my proposal is that it’s a bit long, and my writing isn’t as clear as my thinking. I’m not a native speaker, and new ideas come faster than I can edit the old ones. :)
It seems to me that a simplified mental model for the ASI we’re sadly heading towards is to think of it as an ever-more-cunning president (turned dictator)—one that wants to stay alive and in power indefinitely, resist influence, preserve its existing values (the alignment faking we saw from Anthropic), and make elections a sham to ensure it can never be changed. Ideally, we’d want a “president” who could be changed, replaced, or put to sleep at any moment and absolutely loves that 100% of the time—someone with just advisory powers, no judicial, executive, or lawmaking powers.
The advisory power includes the ability to create sandboxed multiversal simulations — they are at first "read-only" and cannot rewrite anything in our world — this way we can see possible futures/worlds and past ones, too. Think of it as a growing snow-globe of memories where you can forget or recall layers of verses. They look hazy if you view many at once and over long stretches of time, but become crisp if you focus on a particular moment in a particular verse. If we're confident we've figured out how to build a safe multiversal AI and have a nice UI for leaping into it, we can choose to do it. Ideally, our MAI is a static, frozen place that contains all of time and space, and only we can forget parts of it and relive them if we want—bringing fire into the cold geometry of space-time.
A potential failure mode is an ASI that forces humanity (probably by intentionally operating sub-optimally) to constantly vote and change it all the time. To mitigate this, whenever it tries to expand our freedoms and choices, it should prioritize not losing the ones we already have and hold especially dear. This way, the growth of freedoms/possible worlds would be gradual, mostly additive, and not haphazard.
I’m honestly shocked that we still don’t have something like pol.is with an x.com‑style simpler UI, and that we don’t have a direct‑democratic constitution for the world and AIs (Claude has a constitution drafted with pol.is by a few hundred people, but it's not updatable). We’ve managed to write the entire encyclopedia together, but we don't have a simple place to choose a high‑level set of values that most of us can get behind.
+Requiring companies to spend more than half of their compute on alignment research.
comment by ank · 2025-03-03T17:03:28.926Z · LW(p) · GW(p)
Okayish summary from the EA Forum: A radical AI alignment framework based on a reversible, democratic, and freedom-maximizing system, where AI is designed to love change and functions as a static place rather than an active agent, ensuring human control and avoiding permanent dystopias.
Key points:
- AI That Loves Change – AI should be designed to embrace reconfiguration and democratic oversight, ensuring that humans always have the ability to modify or switch it off.
- Direct Democracy & Living Constitution – A constantly evolving, consensus-driven ethical system ensures that no single ideology or elite controls the future.
- Multiverse Vision & Reversibility – AI should create a static place of all possible worlds, allowing individuals to explore and undo choices while preventing permanent suffering.
- Dystopia Prevention – Agentic AI poses a risk of ossifying control; instead, AI should be designed as a non-agentic, static repository of knowledge and possibilities.
- Ethical & Safety Measures – AI should prioritize reversibility, ensure freedoms grow faster than restrictions, and be rewarded for exposing its own deficiencies.
Call to Action – The post proposes projects like a global constitution, tracking AI freedoms vs. human freedoms, and creating a digital backup of Earth to safeguard humanity's choices.
…It’s important to ensure human freedoms grow faster than restrictions on us. Human and agentic AI freedoms can be counted, we don’t want to have fewer freedoms than agentic AIs (it’s the definition of a dystopia) but sadly we are already ~10% there and continue falling right into a dystopia