MATS mentor selection
post by DanielFilan, Ryan Kidd (ryankidd44) · 2025-01-10T03:12:52.141Z · LW · GW · 11 commentsContents
Introduction Mentor selection Mentor demographics Scholar demographics Acknowledgements None 11 comments
Introduction
MATS currently has more people interested in being mentors than we are able to support—for example, for the Winter 2024-25 Program, we received applications from 87 prospective mentors who cumulatively asked for 223 scholars[1] (for a cohort where we expected to only accept 80 scholars). As a result, we need some process for how to choose which researchers to take on as mentors and how many scholars to allocate each. Our desiderata for the process are as follows:
- We want to base our decisions on expert opinions of the quality of various research directions.
- We want the above opinions to be sourced from a range of perspectives with the AI existential safety field, to incorporate multiple perspectives on alignment research and other research areas we think are important, such as AI governance and policy, AI security, and other approaches for addressing AI catastrophic risk.
- We want to incorporate information about how good prospective mentors are at mentorship—both information internal to MATS, as well as information advisors may have.
In this post, we describe the process we used to select mentors for the Winter 2024-25 Program, which will be very close to the process we will use to select mentors for the Summer 2025 Program. In a nutshell, we select advisors, who select mentors, who select scholars, who often select specific research projects, in a “chain of trust,” with MATS input and oversight at every stage. This system is designed to ensure that we make reasonable decisions about the scholars, mentors, and, ultimately, the research we support, even if MATS staff are not subject matter experts for every branch of AI safety research. We want to make this "chain of trust" structure transparent so that potential funders and collaborators can trust in our process, even if we cannot share specific details of selection (e.g., what advisor X said about prospective mentor Y).
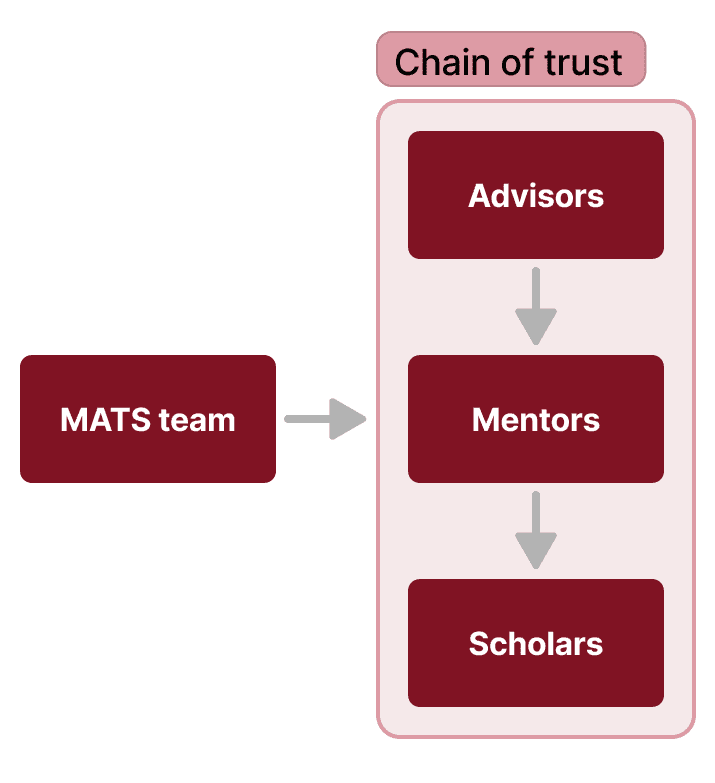
Mentor selection
First, we solicited applications from potential mentors. These applications covered basic information about the mentors, the field they work in, their experience in research and mentoring, what projects they might supervise, and how many scholars they might supervise.
These applications were then reviewed by a team of 12 advisors. Our advisors were chosen to be people with experience in the AI existential safety community, as well as to cover a range of perspectives and subfields, as discussed above. We selected advisors by first creating a long list of approximately 100 candidates, then narrowing it down to a short list of approximately 30 candidates, who we invited to advise us. Of these 30, 12 candidates were available. The advisors include members of AI safety research non-profits, AI "scaling lab" safety teams, AI policy think-tanks, and AI safety grantmaking organizations. Breaking down advisors by field (and keeping in mind most advisors selected multiple fields):
- 6 worked on control / red-teaming.
- 6 worked on some kind of interpretability, including:
- 5 on concept-based interpretability;
- 5 on mechanistic interpretability.
- 5 worked on alignment evaluations or demonstrations, and of those, 3 worked on dangerous capability evaluations or demonstrations (nobody else worked on dangerous capability evaluations or demonstrations).
- 5 worked on AI governance/policy, national security, and/or information security, including:
- 4 on AI governance/policy;
- 4 on national security;
- 3 on information security.
- 3 worked on scalable oversight.
- 3 worked on cooperative AI, agent foundations, and/or value alignment, including:
- 2 on cooperative AI;
- 2 on value alignment;
- 1 on agent foundations.
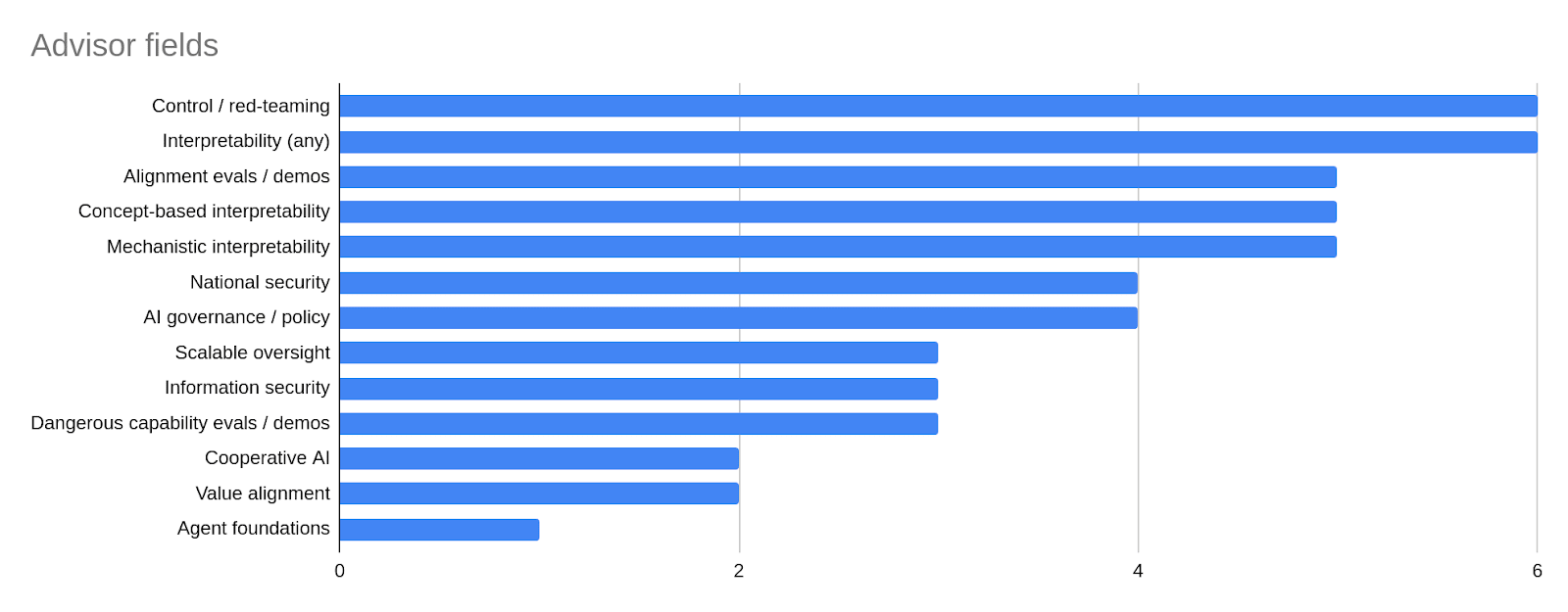
Number of advisors who focus on various fields. Note that most advisors selected multiple fields.
Most advisors were not able to rate all applicants, but focused their energies on applicants whose research areas matched their own expertise. For each rated applicant, advisors were able to tell us:
- Their overall rating for that applicant (given as a number between 1 and 10);
- How many scholars at minimum the applicant should have;
- How many scholars the applicant would ideally have;
- How confident they are in their rating;
- Whether they have a conflict of interest with the applicant.
Advisors also had a field to write free-form text notes. Not all advisors filled out all fields.
As shown in the figure below, all but one application was reviewed by at least three advisors, and the median applicant was reviewed by four advisors. One applicant who applied late was only able to be reviewed by a single reviewer.
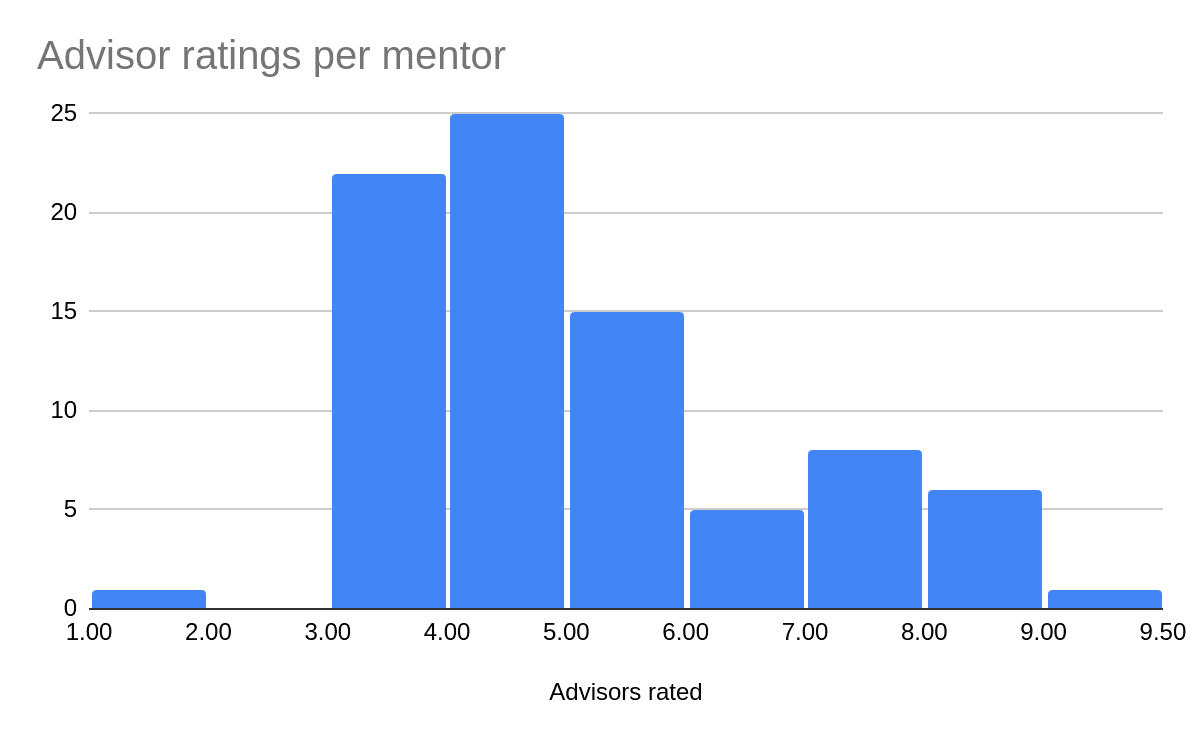
If someone was rated by n advisors, they go in the bin between n and n+1. So, for example, there were 15 applications that were reviewed by 5 advisors.
We primarily considered the average ratings and scholar number recommendations, taking into account confidence levels and conflicts of interest. Our rule of thumb was that we accepted applicants rated 7/10 and higher, and chose some of the applicants rated between 5/10 and 7/10 to enhance research diversity (in part to counter what we believed to be potential lingering biases of our sample of advisors). To choose mentors for certain neglected research areas, we paid special attention to ratings by advisors who specialize in those research areas.
For accepted mentors, we chose scholar counts based on advisor recommendations and ratings, as well as ratings from MATS Research Managers and scholars for returning mentors. The cut-offs at 5/10 and 7/10 were chosen partly to ensure we chose highly-rated mentors, and partly in light of how many scholars we wanted to accept in total (80, in this program). For edge cases, we also considered the notes written by our advisors.
We then made adjustments based on various contingencies:
- We accepted one applicant who expressed interest after we expected to have finalized mentor counts, as that applicant was very prominent in the field of AI existential safety.
- Some mentors accepted fewer scholars than we offered them spots. This caused us to offer more scholars to other mentors and add further mentors from our waiting list to get as close as possible to the desired 80 scholars.
- We selected mentors to give additional scholars based on the mentors' average ratings by advisors, advisors' recommended scholar allocations, and mentors' desired scholar allocations.
- We selected additional mentors based on their average ratings by advisors and whether we felt they would enhance research diversity.
- In the end, we were not as successful at onboarding additional mentors and scholars as we hoped and only accepted 77 scholars.
Mentor demographics
What sort of results did the above process produce? One way to understand this is to aggregate mentors by "track"—MATS’s classification of the type of AI safety research mentors perform. For the Winter 2024-25 program, we have five tracks: oversight & control, evaluations, interpretability, governance & strategy, and agency[2]. Note that these are coarse-grained, and may not perfectly represent each mentor’s research.
This is how our applicants broke down by track:
- Oversight & control: 18 applicants (21%)
- Evaluations: 14 applicants (16%)
- Interpretability: 24 applicants (28%)
- Governance & strategy: 15 applicants (17%)
- AI agency: 15 applicants (17%)
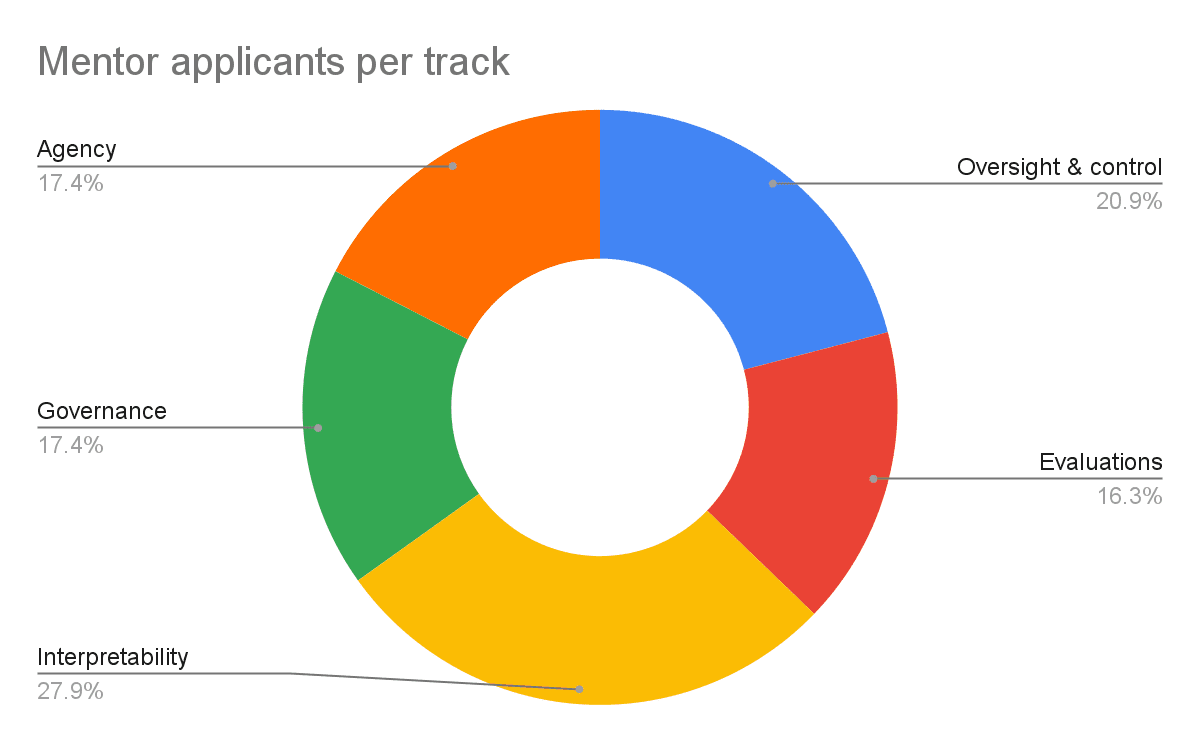
Our accepted mentors broke down this way:
- Oversight & control: 11 mentors (29%)
- Evaluations: 8 mentors (21%)
- Interpretability: 7 mentors (18%)
- Governance: 6 mentors (16%)
- AI agency: 6 mentors (16%)
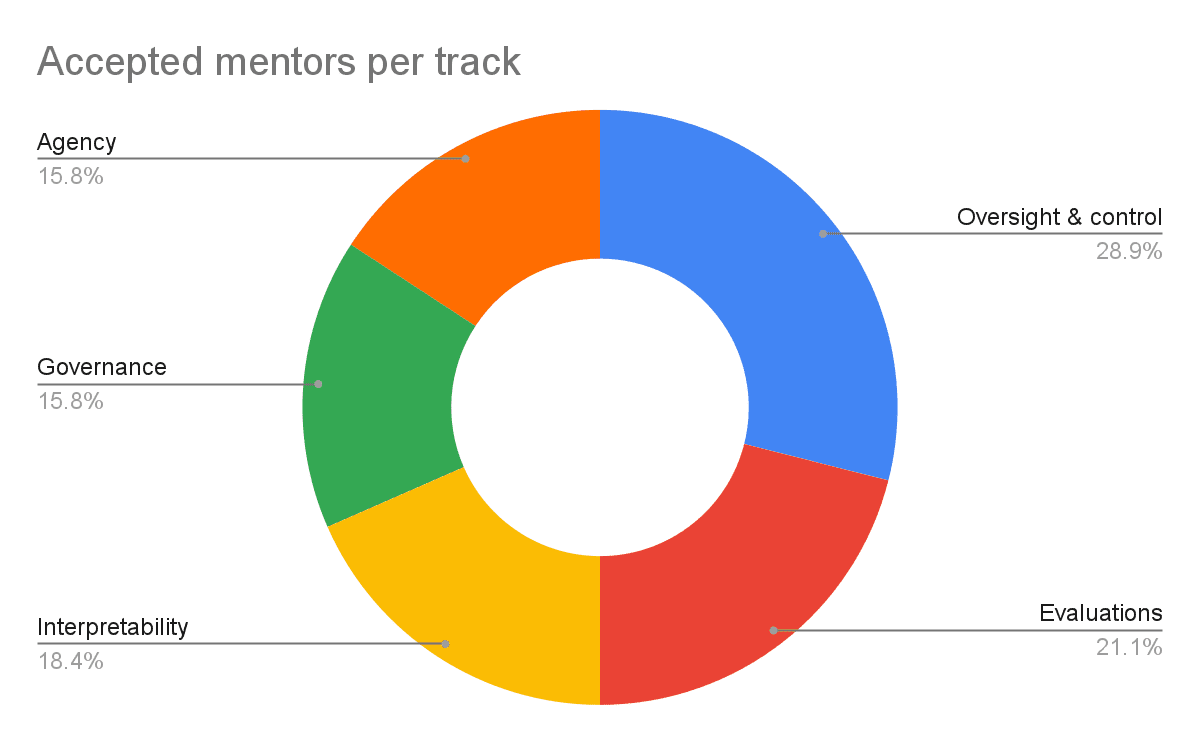
Proportionally, the biggest deviations between the applying and accepted mentors were that relatively few interpretability researchers were accepted as mentors, and relatively many evaluations and oversight & control researchers were accepted.
To give a better sense of our mentors’ research interests, we can also analyse the accepted mentors by whether they focused on:
- Technical or governance research;
- Model externals or internals research;
- Empirical or theoretical research.
These were somewhat subjective designations and, for the latter two distinctions, some mentors did not neatly fall either way.
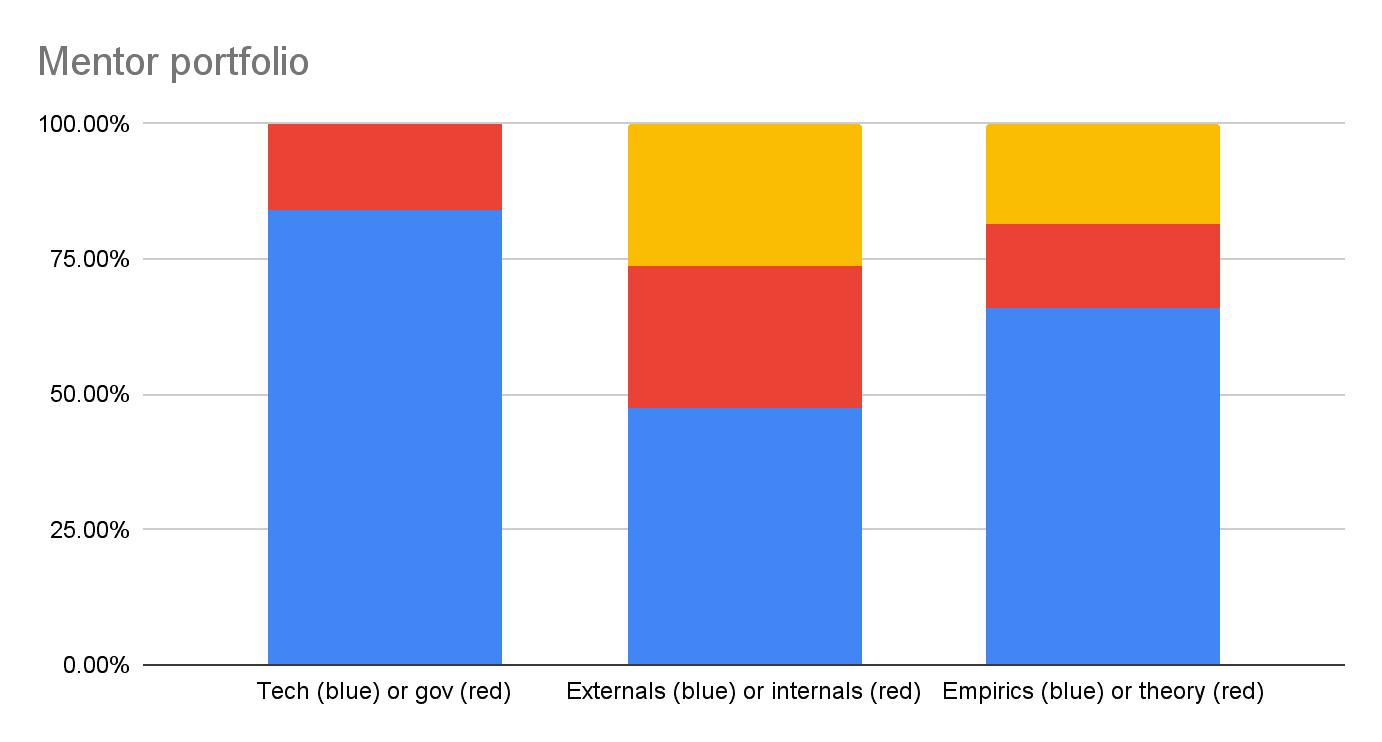
The yellow portion of the bar is mentors who did not neatly fall into either category.
Scholar demographics
Another way to measure the cohort's research portfolio is to look at the breakdown of scholar count assigned to each mentor.[3] Firstly, we can distinguish scholars by their mentors' research track:
- Oversight & control: 24 scholars (31%);
- Interpretability: 18 scholars (23%);
- Evaluations: 17 scholars (22%);
- AI agency: 10 scholars (13%);
- Governance: 8 scholars (10%).
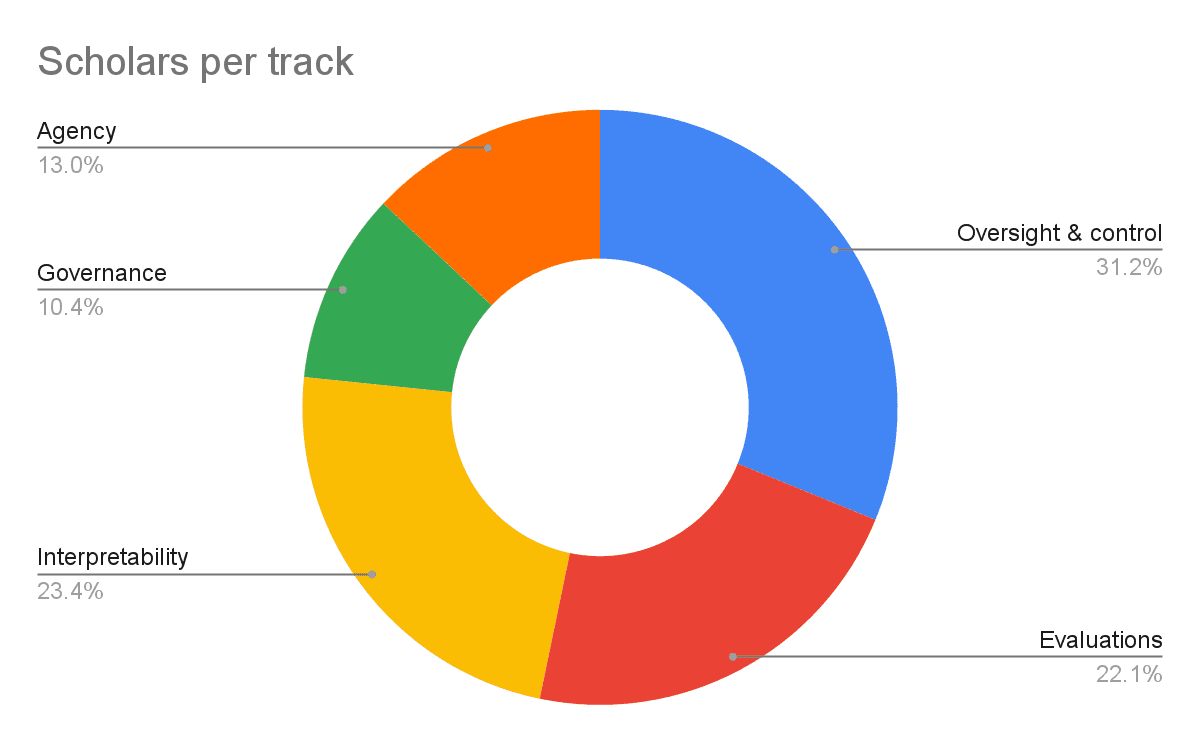
This is somewhat more weighted towards interpretability and away from governance than our mentor count.
Another relevant factor is how many scholars each mentor has, shown in the histogram below. The median scholar will be working with a three-scholar mentor—that is, with two other scholars under the same mentor. This data is shown in histogram form below. Note that for the purpose of these statistics, if two mentors are co-mentoring some scholars, they are counted as one "mentor."
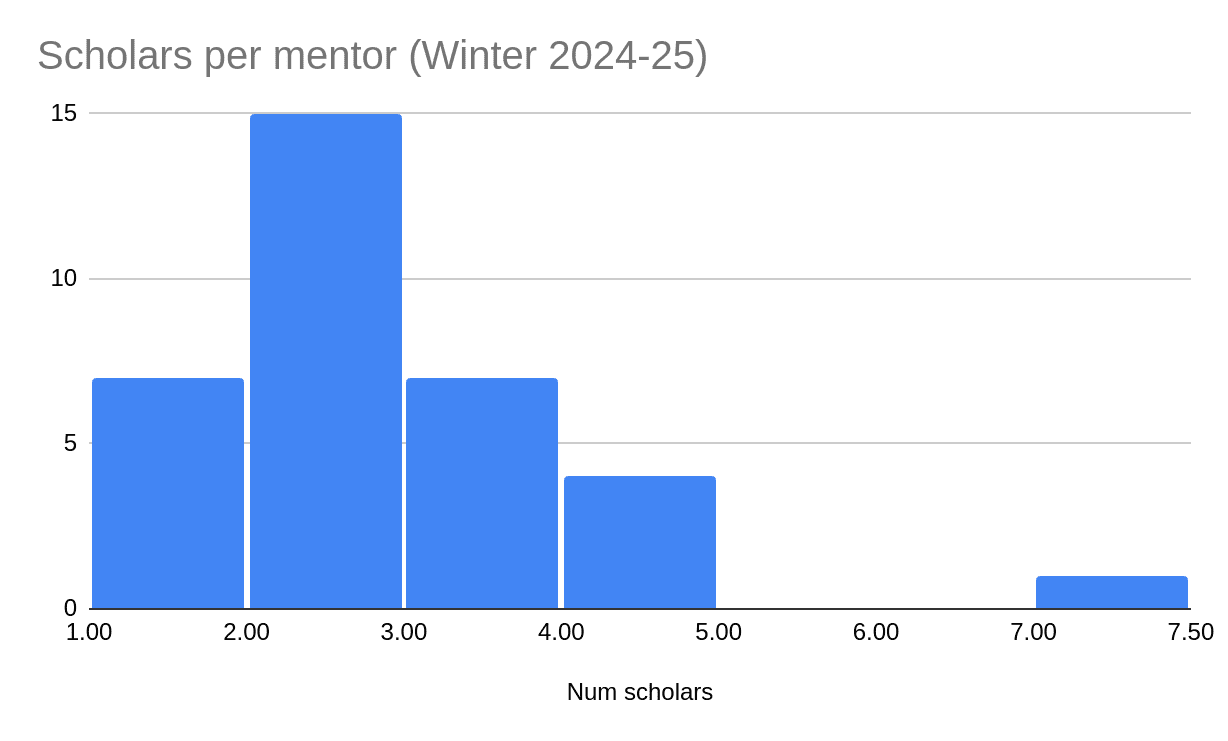
Numbers are provisional and subject to change. If a mentor has n scholars, they go in the bin between n and n+1. So, for example, there are 15 mentors with 2 scholars. Total scholar count will be lower than in this histogram, since mentors who have not yet determined the division of scholars between them were assigned more scholars in aggregate than they accepted.
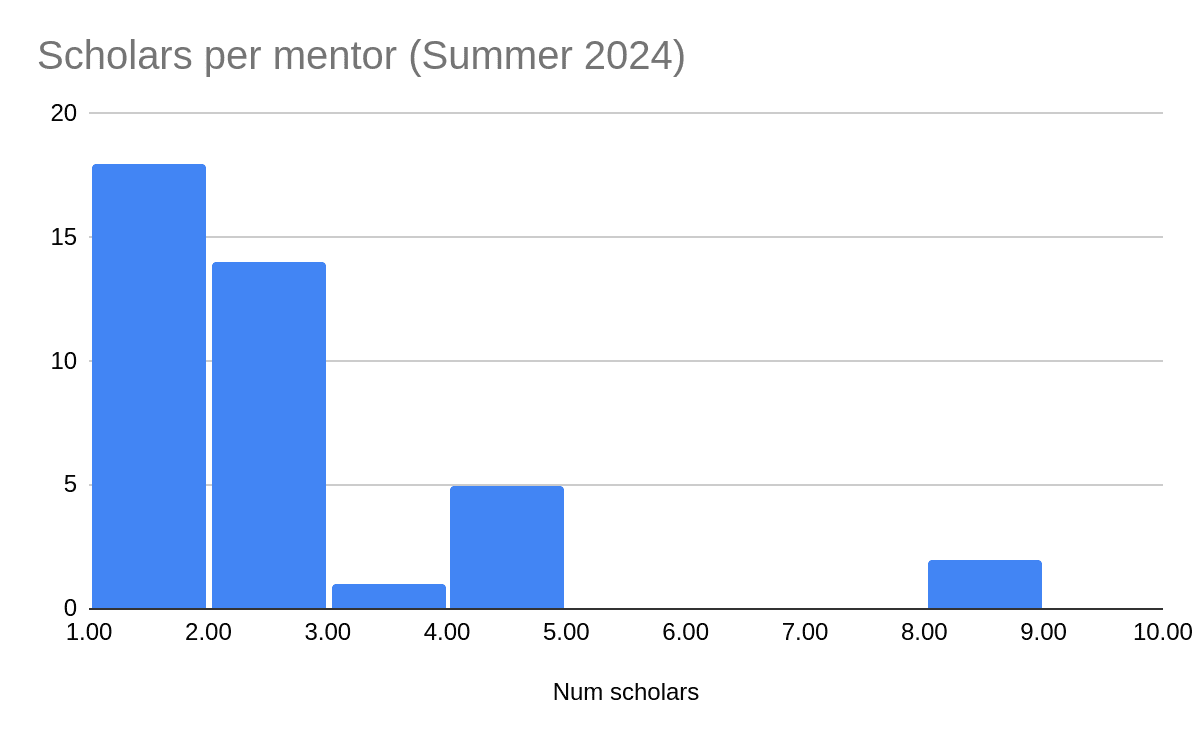
This can be compared to the distribution of scholars per mentor in the Summer 2024 Program. In that program, the distribution was more concentrated: more scholars were working in streams of one or two scholars (the median scholar was working with a 2-scholar mentor, i.e. with only one other scholar), and there were fewer mentors with 3-5 scholars.
As with the mentors, we can also break down scholar assignments by their mentors’ research focus.
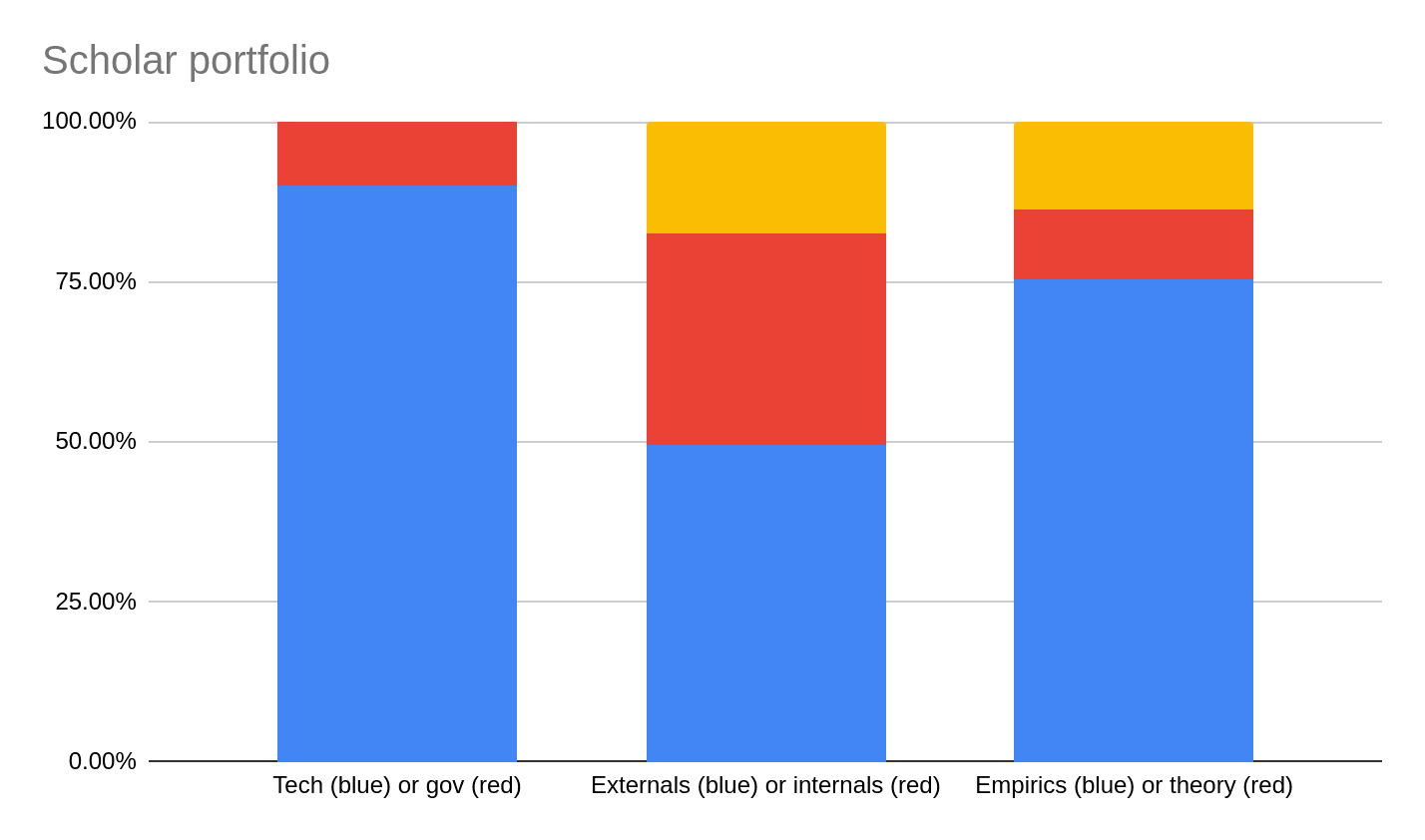
The yellow portion of the bar is scholars whose mentor did not neatly fall into either category.

Acknowledgements
This report was produced by the ML Alignment & Theory Scholars Program. Daniel Filan [LW · GW] was the primary author of this report and Ryan Kidd [LW · GW] scoped, managed, and edited the project. Huge thanks to the many people who volunteered to give their time to mentor scholars at MATS! We would also like to thank our 2024 donors, without whom MATS would not be possible: Open Philanthropy, Foresight Institute, the Survival and Flourishing Fund, the Long-Term Future Fund, Craig Falls, and several donors via Manifund.
- ^
More precisely: when people applied to mentor, they answered the question “What is the average number of scholars you expect to accept?”. 223 (or more precisely, 222.6) is the sum of all applicants’ answers.
- ^
By “agency”, we mean modeling optimal agents, how those agents interact with each other, and how some agents can be aligned with each other. In practice, this covers cooperative AI, agent foundations, value learning, and "shard theory [? · GW]" work
- ^
Note that scholar counts are not yet finalized—some co-mentoring researchers have not yet assigned scholars between themselves. This means that the per-track numbers will be correct, since those mentors are all in the same track, but the statistics about number of scholars per mentor will not be precisely accurate.
11 comments
Comments sorted by top scores.
comment by habryka (habryka4) · 2025-01-10T03:18:35.611Z · LW(p) · GW(p)
FWIW, I find it hard to make judgements on these kinds of aggregate statistics, and would be kind of surprised if other people know how to make judgements on these either. "Having worked at a scaling lab" or "being involved with a AI Safety grantmaking organization" or "being interested in AI control" just aren't that informative pieces of information, especially if I don't even have individual profiles.
My sense is that if you want people to be able to actually come to trust your criteria, you will either have to be more specific, or just list people's names (the latter of which would be ideal, and also would create concrete points of accountability).
Replies from: ryankidd44, DanielFilan↑ comment by Ryan Kidd (ryankidd44) · 2025-01-10T19:22:12.020Z · LW(p) · GW(p)
When onboarding advisors, we made it clear that we would not reveal their identities without their consent. I certainly don't want to require that our advisors make their identities public, as I believe this might compromise the intent of anonymous peer review: to obtain genuine assessment, without fear of bias or reprisals. As with most academic journals, the integrity of the process is dependent on the editors; in this case, the MATS team and our primary funders.
It's possible that a mere list of advisor names (without associated ratings) would be sufficient to ensure public trust in our process without compromising the peer review process. We plan to explore this option with our advisors in future.
Replies from: habryka4↑ comment by habryka (habryka4) · 2025-01-10T19:48:18.926Z · LW(p) · GW(p)
Yeah, it's definitely a kind of messy tradeoff. My sense is just that the aggregate statistics you provided didn't have that many bits of evidence that would allow me to independently audit a trust chain.
A thing that I do think might be more feasible is to make it opt-in for advisors to be public. E.g. SFF only had a minority of recommenders be public about their identity, but I do still think it helps a good amount to have some names.
(Also, just for historical consistency: Most peer review in the history of science was not anonymous. Anonymous peer review is a quite recent invention, and IMO not one with a great track record. Editorial peer review with non-anonymous references was more common throughout the history of the sciences. Emulating anonymous peer review without comparing it to the other options that IMO have a better track record seems a bit cargo-culty to me)
↑ comment by DanielFilan · 2025-01-28T02:08:50.074Z · LW(p) · GW(p)
In this comment [LW(p) · GW(p)] we list the names of some of our advisors.
comment by DanielFilan · 2025-01-28T02:07:28.472Z · LW(p) · GW(p)
Below is a list of some of the advisors we used for mentor selection. Notes:
- Two advisors asked not to be named and do not appear here.
- Advisors by and large focussed their efforts on areas they had some expertise in.
- Advisors had to flag conflicts of interest, meaning that (for example) we did not take their ratings of themselves into account.
With that out of the way, here are some advisors who helped us for the Winter 2024-25 cohort:
- Adam Gleave
- Alex Lawsen
- Buck Shlegeris
- Ethan Perez
- Lawrence Chan
- Lee Sharkey
- Lewis Hammond
- Marius Hobbhahn
- Michael Aird
- Neel Nanda
The above people also advised us for the Summer 2025 cohort. We also added the below advisors for that cohort:
- Alexander Gietelink Oldenziel
- Ben Garfinkel
- Caspar Oesterheld
- Jesse Clifton
- Nate Thomas
comment by Austin Chen (austin-chen) · 2025-01-10T17:48:29.385Z · LW(p) · GW(p)
Curious, is the list of advisors public?
Replies from: ryankidd44, DanielFilan↑ comment by Ryan Kidd (ryankidd44) · 2025-01-10T19:14:05.195Z · LW(p) · GW(p)
Not currently. We thought that we would elicit more honest ratings of prospective mentors from advisors, without fear of public pressure or backlash, if we kept the list of advisors internal to our team, similar to anonymous peer review.
Replies from: austin-chen↑ comment by Austin Chen (austin-chen) · 2025-01-10T19:59:28.233Z · LW(p) · GW(p)
Makes sense, thanks.
FWIW, I really appreciated that y'all posted this writeup about mentor selection -- choosing folks for impactful, visible, prestigious positions is a whole can of worms, and I'm glad to have more public posts explaining your process & reasoning.
↑ comment by DanielFilan · 2025-01-28T02:09:01.502Z · LW(p) · GW(p)
In this comment [LW(p) · GW(p)] we list the names of some of our advisors.
comment by Gauraventh (aryangauravyadav) · 2025-01-11T11:02:17.276Z · LW(p) · GW(p)
Wow, my intuition was that it was really hard to get mentors onboard with supervising scholars given time constraints most senior researchers have, so seeing 87 mentors apply feels is wild!
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2025-01-11T18:59:52.794Z · LW(p) · GW(p)
And 115 prospective mentors applied for Summer 2025!