Forecasting Newsletter: May 2020.
post by NunoSempere (Radamantis) · 2020-05-31T12:35:58.063Z · LW · GW · 1 commentsContents
Index Prediction Markets & Forecasting platforms. Augur: augur.net Coronavirus Information Markets: coronainformationmarkets.com CSET: Foretell Epidemic Forecasting: epidemicforecasting.org (c.o.i) Foretold: foretold.io (c.o.i) /(Good Judgement?[^]*)|(Superforecast(ing|er))/gi Metaculus: metaculus.com Predict It & Election Betting Odds: predictIt.org & electionBettingOdds.com Replication Markets: replicationmarkets.com In The News. Grab Bag Negative examples. Long content None 1 comment
A forecasting digest with a focus on experimental forecasting. The newsletter itself is experimental, but there will be at least four more iterations. Feel free to use this post as a forecasting open thread; feedback is welcome.
- You can sign up here.
- You can also see this post on the EA Forum here [EA · GW]
- And the post is archived here
Index
- Prediction Markets & Forecasting platforms.
- Augur.
- Coronavirus Information Markets.
- CSET: Foretell.
- Epidemic forecasting (c.o.i).
- Foretold. (c.o.i).
- /(Good Judgement?[^]*)|(Superforecast(ing|er))/gi
- Metaculus.
- PredictIt & Election Betting Odds.
- Replication Markets.
- In the News.
- Grab bag.
- Negative examples.
- Long Content.
Prediction Markets & Forecasting platforms.
Augur: augur.net
Augur is a decentralized prediction market. Here is a fine piece of reporting outlining how it operates and the road ahead.
Coronavirus Information Markets: coronainformationmarkets.com
For those who want to put their money where their mouth is, this is a prediction market for coronavirus related information.
Making forecasts is tricky, so would-be-bettors might be better off pooling their forecasts together with a technical friend. As of the end of this month, the total trading volume of active markets sits at $26k+ (upwards from $8k last month), and some questions have been resolved already.
Further, according to their FAQ, participation from the US is illegal: "Due to the US position on information markets, US citizens and residents, wherever located, and anyone physically present in the USA may not participate in accordance with our Terms." Nonetheless, one might take the position that the US legal framework on information markets is so dumb as to be illegitimate.
CSET: Foretell
The Center for Security and Emerging Technology is looking for (unpaid, volunteer) forecasters to predict the future to better inform policy decisions. The idea would be that as emerging technologies pose diverse challenges, forecasters and forecasting methodologies with a good track record might be a valuable source of insight and advice to policymakers.
One can sign-up on their webpage. CSET was previously funded by the Open Philanthropy Project; the grant writeup contains some more information.
Epidemic Forecasting: epidemicforecasting.org (c.o.i)
As part of their efforts, the Epidemic Forecasting group had a judgemental forecasting team that worked on a variety of projects; it was made up of forecasters who have done well on various platforms, including a few who were official Superforecasters.
They provided analysis and forecasts to countries and regions that needed it, and advised a vaccine company on where to locate trials with as many as 100,000 participants. I worked a fair bit on this; hopefully more will be written publicly later on about these processes.
They've also been working on a mitigation calculator, and on a dataset of COVID-19 containment and mitigation measures.
Now they’re looking for a project manager to take over: see here [LW · GW] for the pitch and for some more information.
Foretold: foretold.io (c.o.i)
I personally added a distribution drawer to the Highly Speculative Estimates utility, for use within the Epidemic Forecasting forecasting efforts; the tool can be used to draw distributions and send them off to be used in Foretold. Much of the code for this was taken from Evan Ward’s open-sourced probability.dev tool.
/(Good Judgement?[^]*)|(Superforecast(ing|er))/gi
(The title of this section is a regular expression, so as to accept only one meaning, be maximally unambiguous, yet deal with the complicated corporate structure of Good Judgement.)
Good Judgement Inc. is the organization which grew out of Tetlock's research on forecasting, and out of the Good Judgement Project, which won the IARPA ACE forecasting competition, and resulted in the research covered in the Superforecasting book.
Good Judgement Inc. also organizes the Good Judgement Open gjopen.com, a forecasting platform open to all, with a focus on serious geopolitical questions. They structure their questions in challenges. Of the currently active questions, here is a selection of those I found interesting (probabilities below):
- Before 1 January 2021, will the People's Liberation Army (PLA) and/or People’s Armed Police (PAP) be mobilized in Hong Kong?
- Will the winner of the popular vote in the 2020 United States presidential election also win the electoral college?- This one is interesting, because it has infrequently gone the other way historically, but 2/5 of the last USA elections were split.
- Will Benjamin Netanyahu cease to be the prime minister of Israel before 1 January 2021?. Just when I thought he was out, he pulls himself back in.
- Before 28 July 2020, will Saudi Arabia announce the cancellation or suspension of the Hajj pilgrimage, scheduled for 28 July 2020 to 2 August 2020?
- Will formal negotiations between Russia and the United States on an extension, modification, or replacement for the New START treaty begin before 1 October 2020?s
Probabilities: 25%, 75%, 40%, 62%, 20%
On the Good Judgement Inc. side, here is a dashboard presenting forecasts related to covid. The ones I found most worthy are:
- When will the FDA approve a drug or biological product for the treatment of COVID-19?
- Will the US economy bounce back by Q2 2021?
- What will be the U.S. civilian unemployment rate (U3) for June 2021?
- When will enough doses of FDA-approved COVID-19 vaccine(s) to inoculate 25 million people be distributed in the United States?
Otherwise, for a recent interview with Tetlock, see this podcast, by Tyler Cowen.
Metaculus: metaculus.com
Metaculus is a forecasting platform with an active community and lots of interesting questions. In their May pandemic newsletter, they emphasized having "all the benefits of a betting market but without the actual betting", which I found pretty funny.
This month they've organized a flurry of activities, most notably:
- The Salk Tournament on vaccine development
- The El Paso Series on collaboratively predicting peaks.
- The Lightning Round Tournament, in which metaculus forecasters go head to head against expert epidemiologists.
- They also present a Covid dashboard.
Predict It & Election Betting Odds: predictIt.org & electionBettingOdds.com
PredictIt is a prediction platform restricted to US citizens, but also accessible with a VPN. This month, they present a map about the electoral college result in the USA. States are colored according to the market prices:
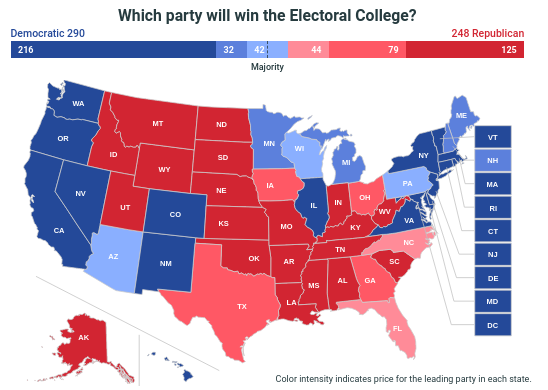
Some of the predictions I found most interesting follow. The market probabilities can be found below; the engaged reader might want to write down their own probabilities and then compare.
- Will Benjamin Netanyahu be prime minister of Israel on Dec. 31, 2020?
- Will Trump meet with Kim Jong-Un in 2020?
- Will Nicolás Maduro be president of Venezuela on Dec. 31, 2020?
- Will Kim Jong-Un be Supreme Leader of North Korea on Dec. 31?
- Will a federal charge against Barack Obama be confirmed before November 3?
Some of the most questionable markets are:
- Will Trump switch parties by Election Day 2020?
- Will Michelle Obama run for president in 2020?
- Will Hillary Clinton run for president in 2020?
Market probabilities are: 76%, 9%, 75%, 82%, 8%, 2%, 6%, 11%.
Election Betting Odds aggregates PredictIt with other such services for the US presidential elections, and also shows an election map. The creators of the webpage used its visibility to promote ftx.com, another platform in the area, whose webpage links to effective altruism and mentions:
FTX was founded with the goal of donating to the world’s most effective charities. FTX, its affiliates, and its employees have donated over $10m to help save lives, prevent suffering, and ensure a brighter future.
Replication Markets: replicationmarkets.com
On Replication Markets, volunteer forecasters try to predict whether a given study's results will be replicated with high power. Rewards are monetary, but only given out to the top few forecasters, and markets suffer from sometimes being dull.
The first week of each round is a survey round, which has some aspects of a Keynesian beauty contest, because it's the results of the second round, not the ground truth, what is being forecasted. This second round then tries to predict what would happen if the studies were in fact subject to a replication, which a select number of studies then undergo.
There is a part of me which dislikes this setup: here was I, during the first round, forecasting to the best of my ability, when I realize that in some cases, I'm going to improve the aggregate and be punished for this, particularly when I have information which I expect other market participants to not have.
At first I thought that, cunningly, the results of the first round would be used as priors for the second round, but a programming mistake by the organizers revealed that they use a simple algorithm: claims with p < .001 start with a prior of 80%, p < .01 starts at 40%, and p < .05 starts at 30%.
In The News.
Articles and announcements in more or less traditional news media.
- Locust-tracking application for the UN (see here for a take by the Washington Post), using software originally intended to track the movements of air pollution. NOAA also sounds like a valuable organization: "NOAA Research enables better forecasts, earlier warnings for natural disasters, and a greater understanding of the Earth. Our role is to provide unbiased science to better manage the environment, nationally, and globally."
- United Nations: World Economic Situation and Prospects as of mid-2020. A recent report is out, which predicts a 3.2% contraction of the global economy. Between 34 and 160 million people are expected to fall below the extreme poverty line this year. Compare with Fitch ratings, which foresee a 4.6% decline in global GDP.
- Fox News and Business Insider report about the CDC forecasting 100k deaths by June the 1st, differently.
- Some transient content on 538 about Biden vs past democratic nominees, about Trump vs Biden polls and about the USA vicepresidential draft, and an old review of the impact of VP candidates in USA elections which seems to have aged well. 538 also brings us this overview of models with unrealistic-yet-clearly-stated assumptions
- Why Economic Forecasting Is So Difficult in the Pandemic. Harvard Review Economists share their difficulties. Problems include "not knowing for sure what is going to happen", the government passing legislation uncharacteristically fast, sampling errors and reduced response rates from surveys, and lack of knowledge about epidemiology.
- IBM releases new AI forecasting tool: "IBM Planning Analytics is an AI-infused integrated planning solution that automates planning, forecasting and budgeting." See here or here for a news take.
- Yahoo has automated finance forecast reporting. It took me a while (two months) to notice that the low-quality finance articles that were popping up in my google alerts were machine-generated. See Synovus Financial Corp. Earnings Missed Analyst Estimates: Here's What Analysts Are Forecasting Now, Wienerberger AG Earnings Missed Analyst Estimates: Here's What Analysts Are Forecasting Now, Park Lawn Corporation Earnings Missed Analyst Estimates: Here's What Analysts Are Forecasting Now; they have a similar structure, paragraph per paragraph, and seem to have been generated from a template which changes a little bit depending on the data (they seem to have different templates for very positive, positive, neutral and negative change). To be clear, I could program something like this given a good finance api and a spare week/month, and in fact did so a couple of years ago for an automatic poetry generator, but I didn't notice because I wasn't paying attention.
- Wimbledon organisers set to net £100 million insurance payout after taking out infectious diseases cover following 2003 SARS outbreak, with tournament now cancelled because of coronavirus. Cheers to Wimbledon.
- The Post ranks the top 10 faces in New York sports today, accompanied by Pitfall to forecasting top 10 faces of New York sports right now. Comparison with the historical situation: Check. Considering alternative hypothesis: Check. Communicating uncertainty to the reader in an effective manner: Check. Putting your predictions out to be judged: Check.
- In Forecasting Hurricane Dorian, Models Fell Short (and see here for the National Hurricane Center report). "Hurricane forecasters and the models they depend on failed to anticipate the strength and impact of last year's deadliest storm." On the topic of weather, see also Nowcasting the weather in Africa to reduce fatalities, and Misunderstanding Of Coronavirus Predictions Is Eerily Similar To Weather Forecasting, Forbes speculates.
- Pan-African Heatwave Health Hazard Forecasting. "The main aim, is to raise the profile of heatwaves as a hazard on a global scale. Hopefully, the project will add evidence to this sparse research area. It could also provide the basis for a heat early warning system." The project looks to be in its early stages, yet nonetheless interesting.
- Nounós Creamery uses demand-forecasting platform to improve production process. The piece is shameless advertising, but it's still an example of predictive models used out in the wild in industry.
Grab Bag
Podcasts, blogposts, papers, tweets and other recent nontraditional media.
-
Some interesting discussion about forecasting over at Twitter, in David Manheim's and Philip Tetlock's accounts, some of which have been incorporated into this newsletter. This twitter thread contains some discussion about how Good Judgement Open, Metaculus and expert forecasters fare against each other, but note the caveats by @LinchZhang: "For Survey 10, Metaculus said that question resolution was on 4pm ET Sunday, a lot of predictors (correctly) gauged that the data update on Sunday will be delayed and answered the letter rather than the spirit of the question (Metaculus ended up resolving it ambiguous)." This thread by Marc Lipsitch has become popular, and I personally also enjoyed these two twitter threads by Linchuan Zhang, on forecasting mistakes.
-
SlateStarCodex brings us a hundred more predictions for 2020. Some analysis by Zvi Mowshowitz here [LW · GW] and by user Bucky [LW · GW].
-
FLI Podcast: On Superforecasting with Robert de Neufville. I would have liked to see a more intense drilling on some of the points. It references The NonProphets Podcast, which looks like it has some more in-depth stuff. Some quotes:
So it’s not clear to me that our forecasts are necessarily affecting policy. Although it’s the kind of thing that gets written up in the news and who knows how much that affects people’s opinions, or they talk about it at Davos and maybe those people go back and they change what they’re doing.
I wish it were used better. If I were the advisor to a president, I would say you should create a predictive intelligence unit using superforecasters. Maybe give them access to some classified information, but even using open source information, have them predict probabilities of certain kinds of things and then develop a system for using that in your decision making. But I think we’re a fair ways away from that. I don’t know any interest in that in the current administration.
Now one thing I think is interesting is that often people, they’re not interested in my saying, “There’s a 78% chance of something happening.” What they want to know is, how did I get there? What is my arguments? That’s not unreasonable. I really like thinking in terms of probabilities, but I think it often helps people understand what the mechanism is because it tells them something about the world that might help them make a decision. So I think one thing that maybe can be done is not to treat it as a black box probability, but to have some kind of algorithmic transparency about our thinking because that actually helps people, might be more useful in terms of making decisions than just a number.
-
Space Weather Challenge and Forecasting Implications of Rossby Waves. Recent advances may help predict solar flares better. I don't know how bad the worst solar flare could be, and how much a two year warning could buy us, but I tend to view developments like this very positively.
-
An analogy-based method for strong convection forecasts in China using GFS forecast data. "Times in the past when the forecast parameters are most similar to those forecast at the current time are identified by searching a large historical numerical dataset", and this is used to better predict one particular class of meteorological phenomena. See here for a press release.
-
The Cato Institute releases 12 New Immigration Ideas for the 21st Century, including two from Robin Hanson: Choosing Immigrants through Prediction Markets & Transferable Citizenship. The first idea is to have prediction markets forecast the monetary value of taking in immigrants, and decide accordingly, then rewarding forecasters according to their accuracy in predicting e.g. how much said immigrants pay in taxes.
-
A General Approach for Predicting the Behavior of the Supreme Court of the United States. What seems to be a pretty simple algorithm (a random forest!) seems to do pretty well (70% accuracy). Their feature set is rich but doesn't seem to include ideology. It was written in 2017; today, I'd expect that a random bright highschooler might be able to do much beter.
-
From Self-Prediction to Self-Defeat: Behavioral Forecasting, Self-Fulfilling Prophecies, and the Effect of Competitive Expectations. Abstract: Four studies explored behavioral forecasting and the effect of competitive expectations in the context of negotiations. Study 1 examined negotiators' forecasts of how they would behave when faced with a very competitive versus a less competitive opponent and found that negotiators believed they would become more competitive. Studies 2 and 3 examined actual behaviors during negotiation and found that negotiators who expected a very competitive opponent actually became less competitive, as evidenced by setting lower, less aggressive reservation prices, making less demanding counteroffers, and ultimately agreeing to lower negotiated outcomes. Finally, Study 4 provided a direct test of the disconnection between negotiators' forecasts for their behavior and their actual behaviors within the same sample and found systematic errors in behavioral forecasting as well as evidence for the self-fulfilling effects of possessing a competitive expectation.
-
Neuroimaging results altered by varying analysis pipelines. Relevant paragraph: "the authors ran separate ‘prediction markets’, one for the analysis teams and one for researchers who did not participate in the analysis. In them, researchers attempted to predict the outcomes of the scientific analyses and received monetary payouts on the basis of how well they predicted performance. Participants — even researchers who had direct knowledge of the data set — consistently overestimated the likelihood of significant findings". Those who had more knowledge did slightly better, however.
-
Forecasting s-curves is hard: Some clear visualizations of what it says on the title.
-
Forecasting state expenses for budget is always a best guess; exactly what it says on the tin. Problem could be solved with a prediction market or forecasting tournament.
-
Fashion Trend Forecasting using Instagram and baking preexisting knowledge into NNs.
-
The advantages and limitations of forecasting. A short and sweet blog post, with a couple of forecasting anecdotes and zingers.
Negative examples.
I have found negative examples to be useful as a mirror with which to reflect on my own mistakes; highlighting them may also be useful for shaping social norms. Andrew Gelman continues to fast-pacedly produce blogposts on this topic. Meanwhile, amongst mortals:
- Kelsey Piper of Vox harshly criticizes the IHME model. "Some of the factors that make the IHME model unreliable at predicting the virus may have gotten people to pay attention to it;" or "Other researchers found the true deaths were outside of the 95 percent confidence interval given by the model 70 percent of the time."
- The Washington post offers a highly partisan view of Trump's chances of winning the election. The author, having already made a past prediction, and seeing as how other media outlets offer a conflicting perspective, rejects the information he's learnt, and instead can only come up with more reasons which confirm his initial position. Problem could be solved with a prediction market or forecasting tournament.
- California politics pretends to be about recession forecasts. See also: Simulacra levels [LW(p) · GW(p)]; the article is at least three levels removed from consideration about bare reality. Key quote, about a given forecasting model: "It’s just preposterously negative... How can you say that out loud without giggling?" See also some more prediction ping-pong, this time in New Jersey, here. Problem could be solved with a prediction market or forecasting tournament.
- What Is the Stock Market Even for Anymore?. A New York Times claims to have predicted that the market was going to fall (but can't prove it with, for example, a tweet, or a hash of a tweet), and nonetheless lost significant amounts of his own funds. ("The market dropped another 1,338 points the next day, and though my funds were tanking along with almost everyone else’s, I found some empty satisfaction, at least, in my prognosticating.") The rest of the article is about said reported being personally affronted with the market not falling further ("the stock market’s shocking resilience (at least so far) has looked an awful lot like indifference to the Covid-19 crisis and the economic calamity it has brought about. The optics, as they say, are terrible.")
- Forecasting drug utilization and expenditure: ten years of experience in Stockholm. A normally pretty good forecasting model had the bad luck of not foreseeing a Black Swan, and sending a study to a journal just before a pandemic, so that it's being published now. They write: "According to the forecasts, the total pharmaceutical expenditure was estimated to increase between 2 and 8% annually. Our analyses showed that the accuracy of these forecasts varied over the years with a mean absolute error of 1.9 percentage points." They further conclude: "Based on the analyses of all forecasting reports produced since the model was established in Stockholm in the late 2000s, we demonstrated that it is feasible to forecast pharmaceutical expenditure with a reasonable accuracy." Presumably, this has increased further because of covid, sending the mean absolute error through the roof. If the author of this paper bites you, you become a Nassim Taleb.
- Some films are so bad it's funny. This article fills the same niche for forecasting. It has it all: Pythagorean laws of vibration, epicycles, an old and legendary master with mystical abilities, 90 year predictions which come true. Further, from the Wikipedia entry: "He told me that his famous father could not support his family by trading but earned his living by writing and selling instructional courses."
- Austin Health Official Recommends Cancelling All 2020 Large Events, Despite Unclear Forecasting. Texan article does not consider the perspective that one might want to cancel large events precisely because of the forecasting uncertainty.
- Auditor urges more oversight, better forecasting at the United State's Department of Transport: "Instead of basing its spending plan on project-specific cost estimates, Wood said, the agency uses prior-year spending. That forecasting method doesn't account for cost increases or for years when there are more projects in the works." The budget of the organization is $5.9 billion. Problem could be solved with a prediction market or forecasting tournament.
Long content
This section contains items which have recently come to my attention, but which I think might still be relevant not just this month, but throughout the years. Content in this section may not have been published in the last month.
-
How to evaluate 50% predictions [LW · GW]. "I commonly hear (sometimes from very smart people) that 50% predictions are meaningless. I think that this is wrong."
-
Named Distributions as Artifacts. On how the named distributions we use (the normal distribution, etc.), were selected for being easy to use in pre-computer eras, rather than on being a good ur-prior on distributions for phenomena in this universe.
-
The fallacy of placing confidence in confidence intervals. On how the folk interpretation of confidence intervals can be misguided, as it conflates: a. the long-run probability, before seeing some data, that a procedure will produce an interval which contains the true value, and b. and the probability that a particular interval contains the true value, after seeing the data. This is in contrast to Bayesian theory, which can use the information in the data to determine what is reasonable to believe, in light of the model assumptions and prior information. I found their example where different confidence procedures produce 50% confidence intervals which are nested inside each other particularly funny. Some quotes:
Using the theory of confidence intervals and the support of two examples, we have shown that CIs do not have the properties that are often claimed on their behalf. Confidence interval theory was developed to solve a very constrained problem: how can one construct a procedure that produces intervals containing the true parameter a fixed proportion of the time? Claims that confidence intervals yield an index of precision, that the values within them are plausible, and that the confidence coefficient can be read as a measure of certainty that the interval contains the true value, are all fallacies and unjustified by confidence interval theory.
“I am not at all sure that the ‘confidence’ is not a ‘confidence trick.’ Does it really lead us towards what we need – the chance that in the universe which we are sampling the parameter is within these certain limits? I think it does not. I think we are in the position of knowing that either an improbable event has occurred or the parameter in the population is within the limits. To balance these things we must make an estimate and form a judgment as to the likelihood of the parameter in the universe that is, a prior probability – the very thing that is supposed to be eliminated.”
The existence of multiple, contradictory long-run probabilities brings back into focus the confusion between what we know before the experiment with what we know after the experiment. For any of these confidence procedures, we know before the experiment that 50 % of future CIs will contain the true value. After observing the results, conditioning on a known property of the data — such as, in this case, the variance of the bubbles — can radically alter our assessment of the probability.
“You keep using that word. I do not think it means what you think it means.” Íñigo Montoya, The Princess Bride (1987)
-
Psychology of Intelligence Analysis, courtesy of the American Central Intelligence Agency, seemed interesting, and I read chapters 4, 5 and 14. Sometimes forecasting looks like reinventing intelligence analysis; from that perspective, I've found this reference work useful. Thanks to EA Discord user @Willow for bringing this work to my attention.
-
Chapter 4: Strategies for Analytical Judgement. Discusses and compares the strengths and weaknesses of four tactics: situational analysis (inside view), applying theory, comparison with historical situations, and immersing oneself on the data. It then brings up several suboptimal tactics for choosing among hypotheses.
-
Chapter 5: When does one need more information, and in what shapes does new information come from?
Once an experienced analyst has the minimum information necessary to make an informed judgment, obtaining additional information generally does not improve the accuracy of his or her estimates. Additional information does, however, lead the analyst to become more confident in the judgment, to the point of overconfidence.
Experienced analysts have an imperfect understanding of what information they actually use in making judgments. They are unaware of the extent to which their judgments are determined by a few dominant factors, rather than by the systematic integration of all available information. Analysts actually use much less of the available information than they think they do.
There is strong experimental evidence, however, that such self-insight is usually faulty. The expert perceives his or her own judgmental process, including the number of different kinds of information taken into account, as being considerably more complex than is in fact the case. Experts overestimate the importance of factors that have only a minor impact on their judgment and underestimate the extent to which their decisions are based on a few major variables. In short, people's mental models are simpler than they think, and the analyst is typically unaware not only of which variables should have the greatest influence, but also which variables actually are having the greatest influence.
-
Chapter 14: A Checklist for Analysts. "Traditionally, analysts at all levels devote little attention to improving how they think. To penetrate the heart and soul of the problem of improving analysis, it is necessary to better understand, influence, and guide the mental processes of analysts themselves." The Chapter also contains an Intelligence Analysis reading list.
-
-
The Limits of Prediction: An Analyst’s Reflections on Forecasting, also courtesy of the American Central Intelligence Agency. On how intelligence analysts should inform their users of what they are and aren't capable of. It has some interesting tidbits and references on predicting discontinuities. It also suggests some guiding questions that the analyst may try to answer for the policymaker.
- What is the context and reality of the problem I am facing?
- How does including information on new developments affect my problem/issue?
- What are the ways this situation could play out?
- How do we get from here to there? and/or What should I be looking out for?
"We do not claim our assessments are infallible. Instead, we assert that we offer our most deeply and objectively based and carefully considered estimates."
-
How to Measure Anything [LW · GW], a review. "Anything can be measured. If a thing can be observed in any way at all, it lends itself to some type of measurement method. No matter how “fuzzy” the measurement is, it’s still a measurement if it tells you more than you knew before. And those very things most likely to be seen as immeasurable are, virtually always, solved by relatively simple measurement methods."
-
The World Meteorological organization, on their mandate to guarantee that no one is surprised by a flood. Browsing the webpage it seems that the organization is either a Key Organization Safeguarding the Vital Interests of the World or Just Another of the Many Bureaucracies Already in Existence, but it's unclear to me how to differentiate between the two. One clue may be their recent Caribbean workshop on impact-based forecasting and risk scenario planning, with the narratively unexpected and therefore salient presence of Gender Bureaus.
-
95%-ile isn't that good: "Reaching 95%-ile isn't very impressive because it's not that hard to do."
-
The Backwards Arrow of Time of the Coherently Bayesian Statistical Mechanic: Identifying thermodynamic entropy with the Bayesian uncertainty of an ideal observer leads to problems, because as the observer observes more about the system, they update on this information, which in expectation reduces uncertainty, and thus entropy. But entropy increases with time.
- This might be interesting to students in the tradition of E.T. Jaynes: for example, the paper directly conflicts with this LessWrong post: The Second Law of Thermodynamics, and Engines of Cognition [LW · GW], part of Rationality, From AI to Zombies. The way out might be to postulate that actually, the Bayesian updating process itself would increase entropy, in the form of e.g., the work needed to update bits on a computer. Any applications to Christian lore are left as an exercise for the reader. Otherwise, seeing two bright people being cogently convinced of different perspectives does something funny to my probabilities: it pushes them towards 50%, but also increases the expected time I'd have to spend on the topic to move them away from 50%.
-
Behavioral Problems of Adhering to a Decision Policy
Our judges in this study were eight individuals, carefully selected for their expertise as handicappers. Each judge was presented with a list of 88 variables culled from the past performance charts. He was asked to indicate which five variables out of the 88 he would wish to use when handicapping a race, if all he could have was five variables. He was then asked to indicate which 10, which 20, and which 40 he would use if 10, 20, or 40 were available to him.
We see that accuracy was as good with five variables as it was with 10, 20, or 40. The flat curve is an average over eight subjects and is somewhat misleading. Three of the eight actually showed a decrease in accuracy with more information, two improved, and three stayed about the same. All of the handicappers became more confident in their judgments as information increased.
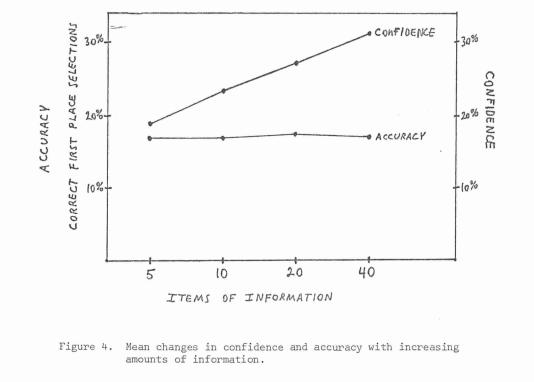
- The study contains other nuggets, such as:
- An experiment on trying to predict the outcome of a given equation. When the feedback has a margin of error, this confuses respondents.
- "However, the results indicated that subjects often chose one gamble, yet stated a higher selling price for the other gamble"
- "We figured that a comparison between two students along the same dimension should be easier, cognitively, than a 13 comparison between different dimensions, and this ease of use should lead to greater reliance on the common dimension. The data strongly confirmed this hypothesis. Dimensions were weighted more heavily when common than when they were unique attributes. Interrogation of the subjects after the experiment indicated that most did not wish to change their policies by giving more weight to common dimensions and they were unaware that they had done so."
- "The message in these experiments is that the amalgamation of different types of information and different types of values into an overall judgment is a difficult cognitive process. In our attempts to ease the strain of processing information, we often resort to judgmental strategies that do an injustice to the underlying values and policies that we’re trying to implement."
- "A major problem that a decision maker faces in his attempt to be faithful to his policy is the fact that his insight into his own behavior may be inaccurate. He may not be aware of the fact that he is employing a different policy than he thinks he’s using. This problem is illustrated by a study that Dan Fleissner, Scott Bauman, and I did, in which 13 stockbrokers and five graduate students served as subjects. Each subject evaluated the potential capital appreciation of 64 securities. [...] A mathematical model was then constructed to predict each subject's judgments. One output from the model was an index of the relative importance of each of the eight information items in determining each subject’s judgments [...] Examination of Table 4 shows that the broker’s perceived weights did not relate closely to the weights derived from their actual judgments.
- I informally replicated this.
- As remedies they suggest to create a model by eliciting the expert, either by having the expert make a large number of judgments and distilling a model, or by asking the expert what they think the most important factors are. A third alternative suggested is computer assistance, so that the experiment participants become aware of which factors influence their judgment.
Vale.
Conflicts of interest: Marked as (c.o.i) throughout the text.
Note to the future: All links are automatically added to the Internet Archive. In case of link rot, go there.
1 comments
Comments sorted by top scores.
comment by Charles R. Twardy (charles-r-twardy) · 2020-07-31T21:51:57.189Z · LW(p) · GW(p)
Thank you for including Replication Markets! A couple of notes:
- Yes, the survey round is potentially a Keynesian beauty contest, though it takes some doing. You're not forecasting the market round. You're forecasting the best estimate we can make using peer prediction on the independent surveys. Harvard's peer prediction algorithm has done well in previous tests, and in theory takes a lot of coordination to defeat.* The truth is probably a good bet. We'll know more in December.
- We had originally planned to use the output of surveys to set the market starting prices - but it made for a very messy experimental design. So we used a 70% accurate decision tree. It wasn't intended to be secret - I thought we had stated it fully but searching the site I find only oblique references.
*We got to test that a bit in Round 8 when we discovered a coordinated "attack" that accounted for ~1/3 of our surveys. Some forecasts would have changed, prizes would have been won, but neither so much as we feared.