How to evaluate (50%) predictions
post by Rafael Harth (sil-ver) · 2020-04-10T17:12:02.867Z · LW · GW · 50 commentsContents
What are predictions? What's special about 50%? What's the proper way to phrase predictions? Summary/Musings None 50 comments
I commonly hear (sometimes from very smart people) that 50% predictions are meaningless. I think that this is wrong, and also that saying it hints at the lack of a coherent principle by which to evaluate whether or not a set of predictions is meaningful or impressive. Here is my attempt at describing such a principle.
What are predictions?
Consider the space of all possible futures:

If you make a prediction, you do this:

You carve out a region of the future space and declare that it occurs with some given percentage. When it comes to evaluating the prediction, the future has arrived at a particular point within the space, and it should be possible to assess whether that point lies inside or outside of the region. If it lies inside, the prediction came true; if it lies outside, the prediction came false. If it's difficult to see whether it's inside or outside, the prediction was ambiguous.
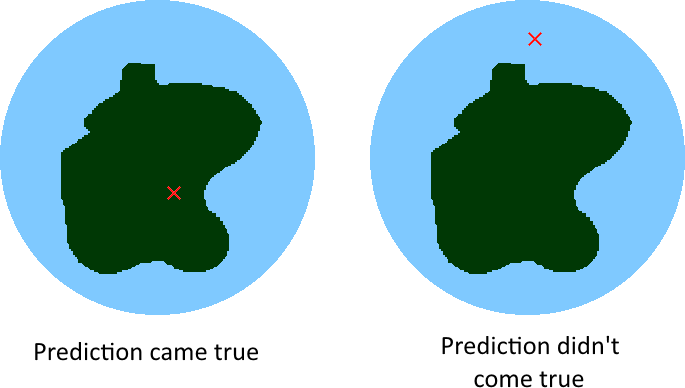
Now consider the following two predictions:
- A coin I flip comes up heads (50%)
- Tesla's stock price at the end of the year 2020 is between 512$ and 514$ (50%)
Both predictions have 50% confidence, and both divide the future space into two parts (as all predictions do). Suppose both predictions come true. No sane person would look at them and be equally impressed. This demonstrates that confidence and truth value are not sufficient to evaluate how impressive a prediction is. Instead, we need a different property that somehow measures 'impressiveness'. Suppose for simplicity that there is some kind of baseline probability that reflects the common knowledge about the problem. If we represent this baseline probability by the size of the areas, then the coin flip prediction can be visualized like so:
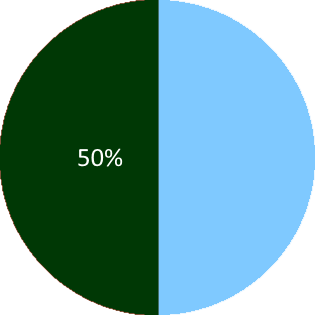
And the Tesla prediction like so:
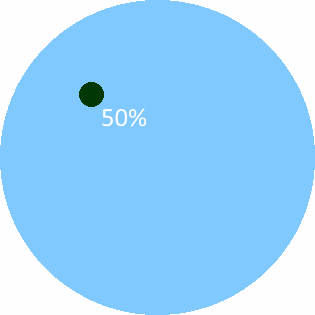
The coin flip prediction is unimpressive because it assigns 50% to a subset of feature space whose baseline probability is also 50%. Conversely, the Tesla prediction is impressive because it assigns 50% to a subset of future space with a tiny baseline probability. Thus, the missing property is the "boldness" of the prediction, i.e., the (relative) difference between the stated confidence and the baseline probability.
Importantly, note that we can play the same game at every percentage point, e.g.:
- A number I randomize on random.org falls between 15 and 94 – 80%
Even though this is an 80% prediction, it is still unimpressive because there is no difference between the stated confidence and the baseline probability.

What's special about 50%?
In January, Kelsey Piper predicted that Joe Biden would be the Democratic Nominee with 60% confidence. If this prediction seems impressive now, we can probably agree that this is not so because it's 60% rather than 50%. Instead, it's because most of us would have put it much lower than even 50%. For example, BetFair gave him only ~15% back in March.
So we have one example where a 50% prediction would have been impressive and another (the random.org one) where an 80% prediction is thoroughly unimpressive. This shows that the percentage being 50% is neither necessary nor sufficient for a prediction being unimpressive. Why, then, do people say stuff like "50% predictions aren't meaningful?"
Well, another thing they say is, "you could have phrased the predictions the other way." But there are reasons to object to that. Consider the Tesla prediction:
- Tesla's stock price at the end of the year 2020 is between 512$ and 514$ (50%)
As-is, this is very impressive (if it comes true). But now suppose that, instead of phrasing it in this way, we first flip a coin. If the coin comes up heads, we flip the prediction, i.e.:
- Tesla's stock price at the end of the year 2020 is below 512$ or above 514$ (50%)
Whereas, if it comes up tails, we leave the prediction unchanged.
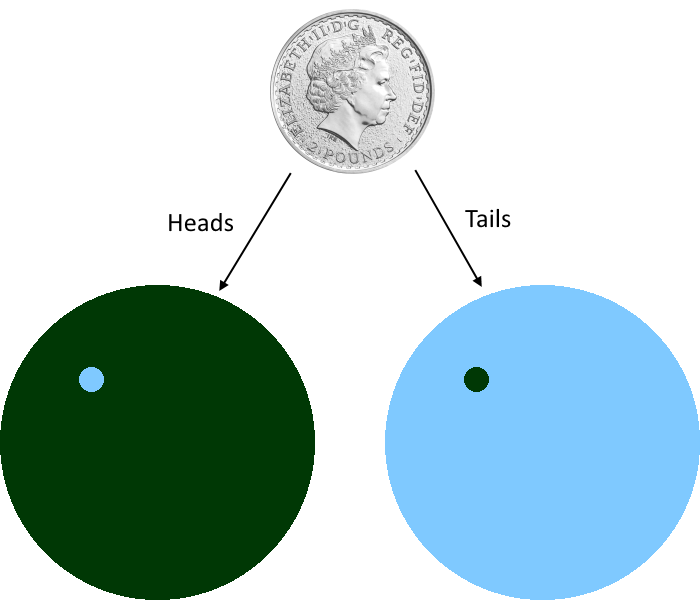
What is the probability that we are correct from the point of view we have before the flip? Well, at some point it will be possible to evaluate the prediction, and then we will either at a point outside of the small blob or at a point inside of the small blob. In the first case, we are correct if we flipped the prediction (left picture). In the latter case, we are correct if we didn't flip the prediction (right picture). In other words, in the first case, we have a 50% chance of being correct, and in the latter case, we also have a 50% chance of being correct. Formally, for any probability that the future lands in the small blob, the chance for our prediction to be correct is exactly
Importantly, notice that this remains true regardless of how the original prediction divides the future space. The division just changes , but the above yields for every value of .
Thus, given an arbitrary prediction, if we flip a coin, flip the prediction iff the coin came up heads and leave it otherwise, we have successfully constructed a perfect 50% prediction.
Note: if the coin flip thing seems fishy (you might object that, in the Tesla example, we either end up with an overconfident prediction or an underconfident prediction, and they can't somehow add up to a 50% prediction), you can alternatively think of a set of predictions where we randomly flip half of them. In this case, there's no coin involved, and the effect is the same: half of all predictions will come true (in expectation) regardless of their original probabilities. Feel free to re-frame every future mention of coin flips in this way.
This trick is not restricted to 50% predictions, though. To illustrate how it works for other percentage points, suppose we are given a prediction which we know has an 80% probability of coming true. First off, there are three simple things we can do, namely
- leave it unchanged for a perfect 80% prediction
- flip it for a perfect 20% prediction
- do the coin flip thing from above to turn it into a perfect 50% prediction. Importantly, note that we would only flip the prediction statement, not the stated confidence.
(Again, if you object to the coin flip thing, think of two 80% predictions where we randomly choose one and flip it.)
In the third case, the formula
from above becomes
This is possible no matter what the original probability is; it doesn't have to be 80%.
Getting slightly more mathy now, we can also throw a biased coin that comes up heads with probability and, again, flip the prediction iff that biased coin came up heads. (You can still replace the coin flip; if , think of flipping every third prediction in a set.) In that case, the probability of our prediction coming true is
This term takes values in the interval . Here's the graph:
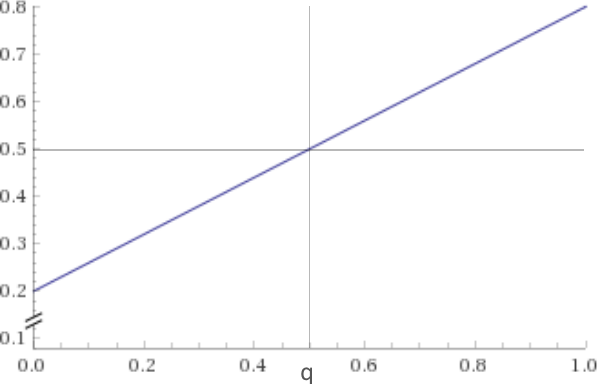
Thus, by flipping our prediction with some probability other than , we can obtain every probability within . In particular, we can transform an 80% probability into a 20% probability, a 30% probability, a 60% probability, a 78.3% probability, but we cannot make it an 83% or a 13% probability.
Finally, the formula with a variable prior probability and a variable flip chance is , and its graph looks like this:
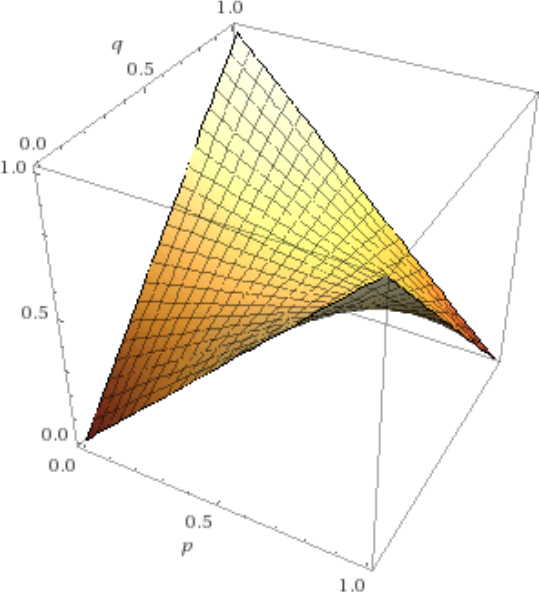
If you fix , you'll notice that, by changing , you get the -value fluctuating between and . For , the -value is a constant at . (When I say -value, I mean the result of the formula which corresponds to the height in the above picture.)
So it is always possible to invert a given probability or to push it toward 50% by arbitrarily introducing uncertainty (this is sort of like throwing information away). On the other hand, it is never possible to pull it further away from 50% (you cannot create new information). If the current probability is known, we can obtain any probability we want (within ); if not, we don't know how the graph looks/where we are on the 3d graph. In that case, the only probability we can safely target is 50% because flipping with probability (aka flipping every other prediction in a set) turns every prior probability into 50%.
And this, I would argue, is the only thing that is special about 50%. And it doesn't mean 50% predictions are inherently meaningless; it just means that cheating is easier – or, to be more precise, cheating is possible without knowing the prior probability. (Another thing that makes 50% seem special is that it's sometimes considered a universal baseline, but this is misguided.)
As an example, suppose we are given 120 predictions, each one with a correct probability of 80%. If we choose 20 of them at random and flip those, 70% of all predictions will come true in expectation. This number is obtained by solving for ; this yields , so we need to flip one out of every six predictions.
What's the proper way to phrase predictions?
Here is a simple rule that shuts the door to this kind of "cheating":
Always phrase predictions such that the confidence is above the baseline probability.
Thus, you should predict
- Joe Biden will be the Democratic nominee (60%)
rather than
- Joe Biden will not be the Democratic nominee (40%)
because 60% is surprisingly high for this prediction, and similarly
- The price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02 (20%)
rather than
- The price of a barrel of oil at the end of 2020 will not be between $50.95 and $51.02 (80%)
because 20% is surprisingly high for this prediction. The 50% mark isn't important; what matters is the confidence of the prediction relative to the baseline/common wisdom.
This rule prevents you from cheating because it doesn't allow flipping predictions. In reality, there is no universally accessible baseline, so there is no formal way to detect this. But that doesn't mean you won't notice. The list:
- The price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02 (50%)
- Tesla's stock price at the end of the year 2020 is between 512$ and 514$ (50%)
- (more extremely narrow 50% predictions)
which follows the rule looks very different from this list (where half of all predictions are flipped):
- The price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02 (50%)
- Tesla's stock price at the end of the year 2020 is below 512$ or above 514$ (50%)
- (more extremely narrow 50% predictions where every other one is flipped)
and I would be much more impressed if the first list has about half of its predictions come true than if the second list manages the same.
Other than preventing cheating, there is also a more fundamental reason to follow this rule. Consider what happens when you make and evaluate a swath of predictions. The common way to do this is to group them into a couple of specific percentage points (such as 50%, 60%, 70%, 80%, 95%, 99%) and then evaluate each group separately. To do this, we would look at all predictions in the 70% group, count how many have come true, and compare that number to the optimum, which is .
Now think of such a prediction like this:

Namely, there is a baseline probability (blue pie, ~60%) and a stated confidence (green pie, 70%). When we add such a prediction to our 70% group, we can think of that like so:
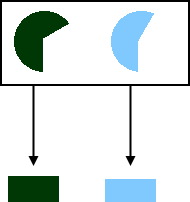
We accumulate a confidence pile (green) that measures how many predictions we claim will come true, and a common wisdom pile (blue) that measures how many predictions ought to come true according to common wisdom. After the first prediction, the confidence pile says, "0.7 predictions will come true," whereas the common wisdom pile says, "0.6 predictions will come true."
Now we add the second (70% confidence, ~45% common wisdom):
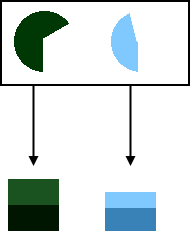
At this point, the confidence pile says, "1.4 predictions will come true," whereas the common wisdom pile says, "1.05 predictions will come true."
If we keep doing this for all 70% predictions, we eventually end up with two large piles:

The confidence pile may say, "70 predictions will come true," whereas the common wisdom pile may say, "48.7 predictions will come true."
Then (once predictions can be evaluated) comes a third pile, the reality pile:
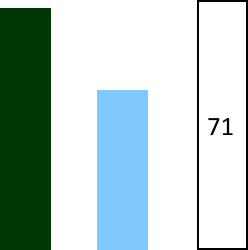
The reality pile counts how many predictions did, in fact, come true. Now consider what this result means. We've made lots of predictions at 70% confidence for which common wisdom consistently assigns lower probabilities. In the end, (slightly more than) 70% of them came true. This means we have systematically beaten common wisdom. This ought to be impressive.
One way to think about this is that the difference between the confidence and common wisdom piles is a measure for the boldness of the entire set of predictions. Then, the rule that [each prediction be phrased in such a way that the confidence is above the baseline probability] is equivalent to choosing one of two ways that maximize this boldness. (The other way would be to invert the rule.)
If the rule is violated, the group of 70% predictions might yield a confidence pile of a height similar to that of the common wisdom pile. Then, seeing that the reality pile matches them is much less impressive. To illustrate this, let's return to the example from above. In both cases, assume exactly one of the two predictions comes true.
Following the rule:
- The price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02 (50%)
- Tesla's stock price at the end of the year 2020 will be between 512$ and 514$ (50%)
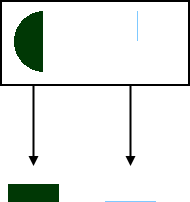

Bold, therefore impressive.
Violating the rule:
- The price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02 (50%)
- Tesla's stock price at the end of the year 2020 will be below 512$ or above 514$ (50%)
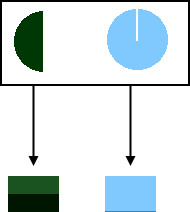
Not bold at all, therefore unimpressive. And that would be the reason to object to the claim that you could just phrase 50% predictions in the opposite way.
Note that the 50% group is special insofar as predictions don't change groups when you rephrase them, but the principle nonetheless applies to other percentage points.
Summary/Musings
According to this model, when you make predictions, you should follow the confidence baseline rule; and when you evaluate predictions, you should
- estimate their boldness (separately for each group at a particular percentage point)
- be impressed according to the product of calibration boldness (where calibration is how closely the reality pile matches the confidence pile, which is what people commonly focus on)
Boldness is not formal because we don't have universally accessible baseline probabilities for all statements lying around (50% is a non-starter), and I think that's the primary reason why this topic is confusing. However, baselines are essential for evaluation, so it's much better to make up your own baselines and use those than to use a model that ignores baselines (that can give absurd results). It does mean that the impressiveness of predictions has an inherent subjective component, but this strikes me as a fairly intuitive conclusion.
In practice, I think people naturally follow the rule to some extent – they tend to predict things they're interested in and then overestimate their probability – but certainly not perfectly. The rule also implies that one should have separate groups for 70% and 30% predictions, which is currently not common practice.
50 comments
Comments sorted by top scores.
comment by SarahNibs (GuySrinivasan) · 2020-04-10T21:34:20.412Z · LW(p) · GW(p)
I think you're conflating impressiveness of predictions with calibration of predictions. It's possible to be perfectly calibrated and unimpressive (for every statement, guess 50% and then randomly choose whether to use the statement or its negation). It's also possible to be uncalibrated and very impressive (be really good at finding all the evidence swaying things from baseline, but count all evidence 4x, for instance).
50% predictions don't really tell us about calibration due to the "swap statement with negation at random" strategy, but they can tell us plenty about impressiveness.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-04-11T09:07:54.033Z · LW(p) · GW(p)
I might have been unclear, but I didn't mean to conflate them. The post is meant to be just about impressiveness. I've stated in the end that impressiveness is boldness accuracy (which I probably should have called calibration). It's possible to have perfect accuracy and zero boldness by making predictions about random number generators.
I disagree that 50% predictions can't tell you anything about calibration. Suppose I give you 200 statements with baseline probabilities, and you have to turn them into predictions by assigning them your own probabilities while following the rule. Once everything can be evaluated, the results on your 50% group will tell me something about how well calibrated you are.
(Edit: I've changed the post to say impressiveness = calibration boldness)
Replies from: Douglas_Knight↑ comment by Douglas_Knight · 2020-04-11T16:57:04.815Z · LW(p) · GW(p)
The title and first sentence are about calibration. You never hear very smart people saying that 50% predictions are meaningless in the context of accuracy.
There's nothing magical about 50%. The closer the predictions are to 50%, the harder it is to judge calibration.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2020-05-03T15:40:13.118Z · LW(p) · GW(p)
You never hear very smart people saying that 50% predictions are meaningless in the context of accuracy.
I have heard this from very smart people.
Replies from: Douglas_Knight↑ comment by Douglas_Knight · 2020-05-03T17:46:53.657Z · LW(p) · GW(p)
Could you give an example?
Could you give an example where the claim is that 50% predictions are less meaningful than 10% predictions?
How do you know that it is about accuracy?
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2020-05-04T01:20:06.773Z · LW(p) · GW(p)
I don't really want to point to specific people. I can think of a couple of conversations with smart EAs or Rationalists where this claim was made.
Replies from: Douglas_Knight↑ comment by Douglas_Knight · 2020-05-04T02:17:12.837Z · LW(p) · GW(p)
So you probably won't convince me that these people know what the claim is, but you haven't even attempted to convince me that you know what the claim is. Do you see that I asked multiple questions?
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2020-05-04T02:23:41.361Z · LW(p) · GW(p)
Do you see how giving very specific answers to this question would be the same as stating people's names?
Suffice it to say that I understand the difference between impressiveness and calibration, and it didn't seem like they did before our conversation, even though they are smart.
Replies from: Douglas_Knight↑ comment by Douglas_Knight · 2020-05-04T02:43:47.741Z · LW(p) · GW(p)
Well, that's something, but I don't see how it's relevant to this thread.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2020-05-04T02:50:42.731Z · LW(p) · GW(p)
I think you're conflating impressiveness of predictions with calibration of predictions.
Could you give an example where the claim is that 50% predictions are less meaningful than 10% predictions?
I mean, these things? A very similar claim to "10% are less meaningful than 50%" which was due to conflating impressiveness and calibration.
It may be that we're just talking past each other?
Replies from: Douglas_Knight↑ comment by Douglas_Knight · 2020-05-04T18:54:54.994Z · LW(p) · GW(p)
Yes, exactly: this post conflates accuracy and calibration. Thus it is a poor antidote to people who make that mistake.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2020-05-04T19:01:13.230Z · LW(p) · GW(p)
I do think we're talking past each other now as I don't know how this relates to our previous discussion.
At any rate I don't think the discussion is that high value to the rest of the post so I think I'll just leave it here.
comment by Scott Alexander (Yvain) · 2020-04-10T22:31:38.823Z · LW(p) · GW(p)
Correction: Kelsey gave Biden 60% probability in January 2020. I gave him 20% probability in January 2019 (before he had officially entered the race). I don't think these contradict each other.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-04-11T08:44:08.428Z · LW(p) · GW(p)
Oh, sorry! I've taken the reference to your prediction out and referred only to BetFair as the baseline.
comment by habryka (habryka4) · 2020-04-30T20:33:58.951Z · LW(p) · GW(p)
Promoted to curated. My engagement with this post was interesting, I went from "this post makes a trivial point" to "this post is obviously wrong" to "I am really confused by this post" to "this post is obviously right and makes some counterintuitive claims". I am not really sure what I initially thought this post was saying, so maybe I just confused myself, but I do think this journey of mine is pretty significant evidence that the post said something interesting.
I also really like having a reference that covers how to deal with 50% predictions pretty comprehensively, which this post does.
Replies from: strangepoop↑ comment by a gently pricked vein (strangepoop) · 2020-05-13T01:30:15.680Z · LW(p) · GW(p)
Thank you for this comment. I went through almost exactly the same thing, and might have possibly tabled it at the "I am really confused by this post" stage had I not seen someone well-known in the community struggle with and get through it.
My brain especially refused to read past the line that said "pushing it to 50% is like throwing away information": Why would throwing away information correspond to the magic number 50%?! Throwing away information brings you closer to maxent, so if true, what is it about the setup that makes 50% the unique solution, independent of the baseline and your estimate? That is, what is the question?
I think it's this: in a world where people can report the probability for a claim or the negation of it, what is the distribution of probability-reports you'd see?
By banning one side of it as Rafael does, you get it to tend informative. Anyway, this kind of thinking makes it seem like it's a fact about this flipping trick and not fundamental to probability theory. I wonder if there are more such tricks/actual psychology to adjust for to get a different answer.
comment by Dagon · 2020-04-10T18:01:15.138Z · LW(p) · GW(p)
I think your "boldness" is a subset of the actual value of low-confidence predictions. In the cases where a prediction is DIFFERENT between two agents, it's pretty clear how one could structure a bet that rewards accuracy of such. Where it's different from most, there are lots of bets available.
This generalizes - the value of a prediction is in it's effect on a decision. If knowing something is 50% likely makes you do something different than if you thought it were 30% or 70% likely, then the prediction has improved your (expected average across worlds) outcome.
comment by Yandong Zhang (yandong-zhang) · 2020-04-14T00:37:00.645Z · LW(p) · GW(p)
For training new graduates from computer science major, I often asked them to develop a simple website to predict the UP/DOWN probability of tomorrow’s SP index (close price), by using any machine learning model. Then, if the website reported a number that was very close 50%, I would say: the website worked well since the SP index was very close to random walk. “What is the meaning of the work!” Most of them would ask angrily. “50% visitors will be impressed by your website. “
I apologize if you feel the story is irrelevant. In my opinion, 50% prediction definitely is meaningful in many cases. It depends on the audience’s background. For example, if your model tell people, the probability of the disappearing of COVID-19 in tomorrow is 50%, we will be more than happy.
comment by Chris_Leong · 2020-04-10T20:44:20.115Z · LW(p) · GW(p)
"Always phrase predictions such that the confidence is above the baseline probability" - This really seems like it should not matter. I don't have a cohesive argument against it at this stage, but reversing should fundamentally be the same prediction.
(Plu in any case it's not clear that we can always agree on a baseline probability)
Replies from: Chris_Leong, sil-ver, rosiecam↑ comment by Chris_Leong · 2020-04-10T21:23:36.239Z · LW(p) · GW(p)
So I've thought about this a bit more. It doesn't matter how someone states their probabilities. However, in order to use your evaluation technique we just need to transform the probabilities so that all of them are above the baseline.
In any case, it's good to see this post. I've always worried for a long time that being calibrated on 50% estimates mightn't be very meaningful as you might be massively overconfident on some guesses and massively underconfident on others.
↑ comment by Rafael Harth (sil-ver) · 2020-04-11T08:57:15.716Z · LW(p) · GW(p)
"Always phrase predictions such that the confidence is above the baseline probability" - This really seems like it should not matter. I don't have a cohesive argument against it at this stage, but reversing should fundamentally be the same prediction.
So I've thought about this a bit more. It doesn't matter how someone states their probabilities. However, in order to use your evaluation technique we just need to transform the probabilities so that all of them are above the baseline.
Yes, I think that's exactly right. Statements are symmetric: 50% that happens 50% that happens. But evaluation is not symmetric. So you can consider each prediction as making two logically equivalent claims ( happens with probability and happens with probability) plus stating on which one of the two you want to be evaluated on. But this is important because the two claims will miss the "correct" probability in different directions. If 50% confidence is too high for (Tesla stock price is in narrow range) then 50% is too low for (Tesla stock price outside narrow range).
(Plu in any case it's not clear that we can always agree on a baseline probability)
I think that's the reason why calibration is inherently impressive to some extent. If it was actually boldness multiplied by calibration, then you should not be impressed at all whenever the boldness pile and confidence pile have identical height. And I think that's correct in theory; if I just make predictions about dice all day, you shouldn't be impressed at all regardless of the outcome. But since it takes some skill to estimate the baseline for all practical purposes, boldness doesn't go to zero.
comment by rosiecam · 2020-04-25T05:56:16.461Z · LW(p) · GW(p)
As has been noted, the impressiveness of the predictions has nothing to do with which way round they are stated; predicting P at 50% is exactly as impressive as predicting ¬P at 50% because they are literally the same. I think one only sounds more impressive when compared to the 'baseline' because our brains seem to be more attuned to predictions that sound surprisingly high, and we don't seem to notice ones that seem surprisingly low. I.e., we hear: 'there is a 40% chance that Joe Biden will be the democratic nominee' and somehow translate that to 'at least 40%', and fail to consider what it implies for the other 60%.
Consider the examples given of unimpressive-sounding predictions:
- There is a 50% chance that the price of a barrel of oil at the end of 2020 will not be between $50.95 and $51.02
- There is a 50% chance that Tesla's stock price at the end of the year 2020 is below $512 or above $514
You can immediately make these sound impressive without flipping them by inserting the word 'only' or 'just':
- There is only a 50% chance that the price of a barrel of oil at the end of 2020 will not be between $50.95 and $51.02
- There is just a 50% chance that Tesla's stock price at the end of the year 2020 will be below $512 or above $514
Suddenly, we are forced to confront how surprisingly low this percentage is, given what you might expect from common wisdom, and it goes back to seeming impressive.
I also think it's a mistake to confuse 'common wisdom' and 'baseline' with 'all possible futures' when thinking about impressiveness. If I say that there's a 50% that the price of a barrel of oil at the end of 2020 will be between -$1 million and $1 million, this sounds unimpressive because I've chosen a very wide interval relative to common sense. But there are a lot more numbers below -$1 million and above $1 million than there are within it, so arguably this is actually quite a precise prediction in the space of all possible futures, but that's not important - what matters is the common sense range / baseline.
(Of course, "there's a 50% that the price of a barrel of oil at the end of 2020 will be between -$1 million and $1 million" is actually a very bold prediction, because it's saying that there is a 50% chance that the price of oil will be either less than -$1 million or above $1 million which is surprisingly high... but we only notice it when phrased to seem surprisingly high rather than surprisingly low!)
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-04-25T07:55:40.990Z · LW(p) · GW(p)
As has been noted, the impressiveness of the predictions has nothing to do with which way round they are stated; predicting P at 50% is exactly as impressive as predicting ¬P at 50% because they are literally the same.
If that were true, then the list
- The price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02 (50%)
- Tesla's stock price at the end of the year 2020 is between 512$ and 514$ (50%)
- ⋯ (more extremely narrow 50% predictions)
and the list
- The price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02 (50%)
- Tesla's stock price at the end of the year 2020 is below 512$ or above 514$ (50%)
- ⋯ (more extremely narrow 50% predictions where every other one is flipped)
would be equally impressive if half of them came true. Unless you think that's the case, it immediately follows that the way predictions are stated matters for impressiveness.
It doesn't matter in case of a single 50% prediction, because in that case, one of the phrasings follows the rule I propose, and the other follows the inverse of the rule, which is the other way to maximize boldness. As soon as you have two 50% predictions, there are four possible phrasings and only two of them maximize boldness. (And with predictions, possible phrasings and only 2 of them maximize boldness.)
The person you're referring to left an addendum in a second comment (as a reply to the first) acknowledging that phrasing matters for evaluation.
Replies from: rosiecam↑ comment by rosiecam · 2020-04-25T14:52:11.360Z · LW(p) · GW(p)
Thanks for the response!
I don't think there is any difference in those lists! Here's why:
The impressiveness of 50% predictions can only be evaluated with respect to common wisdom. If everyone thinks P is only 10% likely, and you give it 50%, and P turns out to be true, this is impressive because you gave it a surprisingly high percentage! But also if everyone says P is 90% likely, and P turns out to be false, this is also impressive because you gave it a surprisingly low percentage!
I think what you're suggesting is that people should always phrase their prediction in a way that, if P comes true, makes their prediction impressive because the percentage was surprisingly high, i.e.:
Most people think there is only a 20% chance that the price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02. I think it's 50% (surprisingly high), so you should be impressed if it turns out to be true.
But you could also say:
Most people think there is an 80% chance that the price of a barrel of oil at the end of 2020 will not be between $50.95 and $51.02. I think it's only 50% (surprisingly low), so you should be impressed if it turns out to be false.
These are equally impressive (though I admit the second is phrased in a less intuitive way) - when it comes to 50% predictions, it doesn't matter whether you evaluate it with respect to 'it turned out to be true' vs 'it turned out to be false'; you're trying to correctly represent both the percentages in both cases (i.e. the correct ratio), and the impressiveness comes from the extent to which your percentages on both sides differ from the baseline.
I think what I'm saying is that it doesn't matter how the author phases it, when evaluating 50% predictions we should notice both when it seems surprisingly high and turns out to be true, and when it's surprisingly low and turns out to be false, as they are both impressive.
When it comes to a list of 50% predictions, it's impossible to evaluate the impressiveness only by looking at how many came true, since it's arbitrary which way they are phrased, and you could equally evaluate the impressiveness by how many turned out to be false. So you have to compare each one to the baseline ratio.
Probability is weird and unintuitive and I'm not sure if I've explained myself very well...
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-04-25T16:23:26.927Z · LW(p) · GW(p)
(Edit: deleted a line based on tone. Apologies.)
Everything except your last two paragraphs argues that a single 50% prediction can be flipped, which I agree with. (Again: for every predictions, there are ways to phrase them and precisely 2 of them are maximally bold. If you have a single prediction, then . There are only two ways, both are maximally bold and thus equally bold.)
When it comes to a list of 50% predictions, it's impossible to evaluate the impressiveness only by looking at how many came true, since it's arbitrary which way they are phrased
I have proposed a rule that dictates how they are phrased. If this rule is followed, it is not arbitrary how they are phrased. That's the point.
Again, please consider the following list:
- The price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02 (50%)
- Tesla's stock price at the end of the year 2020 is between 512$ and 514$ (50%)
- ...
You have said that there is no difference between both lists. But this is obviously untrue. I hereby offer you 2000$ if you provide me with a list of this kind and you manage to have, say, at least 10 predictions where between 40% and 60% come true. Would you offer me 2000$ if I presented you with a list of this kind:
- The price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02 (50%)
- Tesla's stock price at the end of the year 2020 is below 512$ or above 514$ (50%)
- ⋯
and between 40% and 60% come true? If so, I will PM you one immediately.
I think you're stuck at the fact that a 50% prediction also predicts the negated statement with 50%, therefore you assume that the entire post must be false, and therefore you're not trying to understand the point the post is making. Right now, you're arguing for something that is obviously untrue. Everyone can make a list of the second kind, no-one can make a list of the first kind. Again, I'm so certain about this that I promise you 2000$ if you prove me wrong.
Replies from: rosiecam, Pongo↑ comment by rosiecam · 2020-04-25T17:53:47.868Z · LW(p) · GW(p)
I agree there is a difference between those lists if you are evaluating everything with respect to each prediction being 'true'. My point is that sometimes a 50% prediction is impressive when it turns out to be false, because everyone else would have put a higher percentage than 50% on it being true. The first list contains only statements that are impressive if evaluated as true, the second mixes ones that would be impressive if evaluated as true with those that are impressive if evaluated as false. If Tesla's stock ends up at $513, it feels weird to say 'well done' to someone who predicts "Tesla's stock price at the end of the year 2020 is below 512$ or above 514$ (50%)", but that's what I'm suggesting we should do, if everyone else would have only put say a 10% chance on that outcome. If you're saying that we should always phrase 50% predictions such that they would be impressive if evaluated as true because it's more intuitive for our brains to interpret, I don't disagree.
I read the post in good faith and I appreciate that it made me think about predictions and probabilities more deeply. I'm not sure how else to explain my position so will leave it here.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-04-25T18:26:51.420Z · LW(p) · GW(p)
Well, now you've changed what you're arguing for. You initially said that it doesn't matter which way predictions are stated, and then you said that both lists are the same.
Replies from: rosiecam↑ comment by rosiecam · 2020-04-26T13:03:03.523Z · LW(p) · GW(p)
I hereby offer you 2000$ if you provide me with a list of this kind
Can you specify what you mean by 'of this kind', i.e. what are the criteria for predictions included on the list? Do you mean a series of predictions which give a narrow range?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-04-26T15:32:12.593Z · LW(p) · GW(p)
A list of predictions that all seem extremely unlikely to come true according to common wisdom.
Replies from: rosiecam↑ comment by rosiecam · 2020-04-26T15:46:37.483Z · LW(p) · GW(p)
Ok this confirms you haven't understood what I'm claiming. If I gave a list of predictions that were my true 50% confidence interval, they would look very similar to common wisdom because I'm not a superforecaster (unless I had private information about a topic, e.g. a prediction on my net worth at the end of the year or something). If I gave my true 50% confidence interval, I would be indifferent to which way I phrased it (in the same way that if I was to predict 10 coin tosses it doesn't matter whether I predict ten heads, ten tails, or some mix of the two).
From what I can tell from your examples, the list of predictions you proposed sending to me would not have represented your true 50% confidence intervals each time - you could have sent me 5 things you are very confident will come true and 5 things you are very confident won't come true. It's possible to fake any given level of calibration in this way.
Replies from: sil-ver, sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-04-26T17:16:12.087Z · LW(p) · GW(p)
Also, I apologize for the statement that I "understand you perfectly" a few posts back. It was stupid and I've edited it out.
Replies from: rosiecam↑ comment by rosiecam · 2020-04-26T17:24:52.476Z · LW(p) · GW(p)
Thanks I appreciate that :) And I apologize if my comment about probability being weird came across as patronizing, it was meant to be a reflection on the difficulty I was having putting my model into words, not a comment on your understanding
↑ comment by Rafael Harth (sil-ver) · 2020-04-26T16:14:40.487Z · LW(p) · GW(p)
Ok this confirms you haven't understood what I'm claiming.
I'm arguing against this claim:
I don't think there is any difference in those lists!
I'm saying that it is harder to make a list where all predictions seem obviously false and have half of them come true than it is to make a list where half of all predictions seem obviously false and half seem obviously true and have half of them come true. That's the only thing I'm claiming is true. I know you've said other things and I haven't addressed them; that's because I wanted to get consensus on this thing before talking about anything else.
↑ comment by Pongo · 2020-04-27T06:16:17.273Z · LW(p) · GW(p)
Reading this, I was confused: it seemed to me that I should be equally willing to offer $2000 for each list. I realised I was likely enough mistaken that I shouldn't actually make such an offer!
At first I guessed that the problem in lists like the second was cheating via correlations. That is, a more subtle version of:
- The price of a barrel of oil at the end of 2020 will be between $50.95 and $51.02 (50%)
- The price of a barrel of oil at the end of 2020 will be below $50.95 or above $51.02 (50%)
Then I went and actually finished reading the post (! oops). I see that you were thinking about cheating, but not quite of this kind. The slogan I would give is something like "cheating by trading accuracy for calibration". That is, the rule is just supposed to remove the extra phrasing choice from a list to prevent shenanigans from patterned exploitation of this choice.
I now think a challenge to your post would complain that this doesn't really eliminate the choice -- that common wisdom is contradictory enough that I can tweak my phrasing to satisfy your rule and still appear calibrated at 50%-wards probabilities. To be clear, I'm not saying that's true; the foregoing is just supposed to be a checksum on my understanding.
comment by romeostevensit · 2020-04-10T23:16:04.330Z · LW(p) · GW(p)
Thanks for taking the trouble to write this. Having something to link to is valuable vs having the same conversation over and over.
comment by lsusr · 2020-04-10T18:21:31.969Z · LW(p) · GW(p)
Was this inspired by Scott Alexander's 2019 Predictions: Calibration Results?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-04-10T18:32:13.269Z · LW(p) · GW(p)
Yes, and in particular, by Scott saying that 50% predictions are "technically meaningless."
Replies from: Vaniver↑ comment by Vaniver · 2020-04-10T20:33:55.828Z · LW(p) · GW(p)
I believe what "technically meaningless" means in that sentence is something like "the simple rule doesn't distinguish between predictions." The "Biden 60%" prediction has one canonical form, but a "Biden 50%" prediction is as canonical as a "not Biden 50%" prediction. So you have to use some other rule to distinguish them, and that means the 50% column is meaningfully different from the other columns on the graph.
For example, Scott ending up ~60% right on the things that he thinks are 50% likely suggests that he's throwing away some of his signal, in that his 'arbitrary' rule for deciding whether to write "Ginsberg still alive" instead of "Ginsberg not still alive" (and similar calls) is in fact weakly favoring the one that ends up happening. (This looks like a weak effect in previous years as well, tho it sometimes reverses.)
Replies from: Bucky↑ comment by Bucky · 2020-04-10T21:57:17.153Z · LW(p) · GW(p)
For example, Scott ending up ~60% right on the things that he thinks are 50% likely suggests that he's throwing away some of his signal
If we compare two hypotheses:
Perfect calibration at 50%
vs
Unknown actual calibration (uniform prior across [0,1])
Then the Bayes factor is 2:1 in favour of the former hypothesis (for 7/11 correct) so it seems that Scott isn't throwing away information. Looking across other years supports this - his total of 30 out of 65 is 5:1 evidence in favour of the former hypothesis.
Replies from: Vaniver↑ comment by Vaniver · 2020-04-11T00:39:26.587Z · LW(p) · GW(p)
So I was mostly averaging percentages across the years instead of counting, which isn't great; knowing that it's 30/65 makes me much more on board with "oh yeah there's no signal there."
But I think your comparison between hypotheses seems wrong; like, presumably it should be closer to a BIC-style test, where you decide if it's worth storing the extra parameter p?
Replies from: Bucky↑ comment by Bucky · 2020-04-11T06:46:01.949Z · LW(p) · GW(p)
The Bayes factor calculation which I did is the analytical result for which BIC is an approximation (see this sequence [? · GW]). Generally BIC is a large N approximation but in this case they actually do end up being fairly similar even with low N.
comment by Pattern · 2020-04-11T19:00:40.334Z · LW(p) · GW(p)
Styling:
In reality, there is [not] a universally accessible baseline, so there is no formal way to detect this.
Commentary:
Great post. The visualizations of tiny space, high probability are really good.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-04-11T19:56:57.115Z · LW(p) · GW(p)
Fixed. And thanks!
comment by streawkceur · 2020-04-11T09:53:25.039Z · LW(p) · GW(p)
1. I think the "calibration curves" one sees e.g. in https://slatestarcodex.com/2020/04/08/2019-predictions-calibration-results/ are helpful/designed to evaluate/improve a strict subset of prediction errors: Systematic over- oder underconfidence. Clearly, there is more to being an impressive predictor than just being well-calibrated, but becoming better-calibrated is a relatively easy thing to do with those curves. One can also imagine someone who naturally generates 50 % predictions that are over-/underconfident.
2.0. Having access to "baseline probabilities/common-wisdom estimates" is mathematically equivalent to having a "baseline predictor/woman-on-the-street" whose probability estimates match those baseline probabilities. I think your discussion can be clarified and extended by not framing it as "judging the impressiveness of one person by comparing their estimates against a baseline", but as "given track records of two or more persons/algorithms, compare their predictions' accuracy and impressiveness, where one person might be the 'baseline predictor'".
2.1. If you do want to measure to compare two persons' track record/generalized impressiveness on the same set of predictions (e.g. to decide whom to trust more), the natural choice is log loss as used to optimize ML algorithms. This means that one sums -ln(p) for all probability estimates p of true judgments; lower sums are better. 50 % predictions are of course a valid data point for the log loss if both persons made a prediction. In contrast, if reference predictions aren't available, it doesn't seem feasible to me to judge predictions of 50 % or any other probability estimate.
2.2. One can prove: For events with a truly random component, the expectation value of the log loss is minimized by giving the correct probability estimates. If there is a very competent predictor who is nevertheless systematically overconfident as in 1., on can strictly improve upon their log loss by appropriately rescaling their probability estimates.
comment by benjamincosman · 2022-03-27T21:28:07.062Z · LW(p) · GW(p)
I think the core idea of this post is valid and useful, but that the specific recommendation that predictors phrase their predictions using the "confidence > baseline" rule is a misguided implementation detail. To see why, first consider this variant recommendation we could make:
Variant A: There are no restrictions on the wordings of predictions, but along with their numeric prediction, a predictor should in some manner provide the direction by which the prediction differs from baseline.
Notice that any computation that can be performed in your system can also be performed using Variant A, since I could always at scoring time convert all "I predict [claim] with confidence p; baseline is higher" predictions into "I predict [negation of claim] with confidence 1-p; baseline is lower" to conform to your rule. Now even Variant A is I believe a minor improvement on the "confidence > baseline" rule, because it gives predictors more freedom to word things in human-convenient ways (e.g. "The stock price will be between 512 and 514" is far nicer to read than either "...not be between 512 and 514", or the very clunky "...less than 512 or more than 514"). But more importantly, Variant A is a useful stepping stone towards two much more significant improvements:
Variant B: ...a predictor should in some manner provide the direction by which the prediction differs from baseline, or better yet, an actual numeric value for the baseline.
First, notice as before that any computation that can be performed in Variant A can also be performed using Variant B, since we can easily derive the direction from the value. Now of course I recognize that providing a value may be harder or much harder than reporting direction alone, so I am certainly not suggesting we mandate that the baseline's value always be reported. But it's clearly useful to have, even for your original scheme: though you don't say so explicitly, it seems to be the key component in your "estimate their boldness" step at the end, since boldness is precisely the magnitude of the difference between the prediction and the baseline. So it's definitely worth at least a little extra effort to get this value, and occasionally the amount of effort required will actually be very small or none anyway: one of the easiest ways to satisfy your original mandate of providing the direction will sometimes be to go find the numeric value (e.g. in a prediction market).
Variant C: ...a predictor should in some manner provide the direction by which the prediction differs from baseline, or better yet, some third party should provide this direction.
Now again I recognize that I can't make anybody, including unspecified "third parties", do more work than they were going to. But to whatever extent we have the option of someone else (such as whoever is doing the scoring?) providing the baseline estimations, it definitely seems preferable: in the same way that in the classical calibration setting, a predictor has an incentive to accidentally (or "accidentally") phrase predictions a certain way to guarantee perfect calibration at the 50% level, here they have an incentive to mis-estimate the baselines for the same reason. There might also be other advantages to outsourcing the baseline estimations, including
- this scheme would become capable of scoring predictors who do not provide baselines themselves (e.g. because they simply don't know they're supposed to, or because they don't want to put in that effort)
- we might get scale and specialization advantages from baseline-provision being a separate service (e.g. a prediction market could offer this as an API, since that's kind of exactly what they do anyway)
So overall, I'd advocate using the tweaks introduced in all the variants above: A) we should not prefer that predictors speak using extra negations when there are equally good ways of expressing the same information, B) we should prefer that baseline values are recorded rather than just their directions, and C) we should prefer that third parties decide on the baselines.
Replies from: benjamincosman↑ comment by benjamincosman · 2022-03-27T21:46:05.370Z · LW(p) · GW(p)
I think a lot of the pushback against the post that I'm seeing in the older comments is generated by the fact that this "confidence > baseline" rule is presented in its final form without first passing through a stage where it looks more symmetrical. By analogy, imagine that in the normal calibration setting, someone just told you that you are required to phrase all your predictions such that the probabilities are >= 50%. "But why," you'd think; "doesn't the symmetry of the situation almost guarantee that this has to be wrong - in what sane world can we predict 80% but we can't predict 20%?" So instead, the way to present the classical version is that you can predict any value between 0 and 100, and then precisely because of the symmetry noticed above, for the purpose of scoring we lump together the 20s and 80s. And that one possible implementation of this is to do the lumping at prediction-time instead of scoring-time by only letting you specify probabilities >= 50%. Similarly in the system from this post, the fundamental thing is that you have to provide your probability and also a direction that it differs from baseline. And then come scoring time, we will lump together "80%, baseline is higher" with "20%, baseline is lower". Which means one possible implementation is to do the lumping at prediction-time by only allowing you to make "baseline is lower" predictions. (And another implementation, for anyone who finds this lens useful since it's closer to the classical setting, would be to only allow you to make >=50% predictions but you also freely specify the direction of the baseline.)
comment by leggi · 2020-04-11T07:26:42.034Z · LW(p) · GW(p)
(veterinary) medically/surgically speaking:
Animal owner: ""What are its chances?"
Me: "50-50".
What I mean: Treatment's worth a try but be prepared for failure. The magical middle figures that say ' I don't know, can't guess, don't have an intuition either way, and we'll have to see what happens'.