A New Way to Visualize Biases
post by dtm · 2020-07-22T17:57:48.245Z · LW · GW · 16 commentsContents
16 comments
I have started using a visual metaphor to diagram biases in my attempts to remove and mitigate them in myself. I have found this to be incredibly useful, particularly when dealing with multiple compounding biases.
I view an inference as an interaction between external inputs/premises and the resulting cognitions/conclusions. It can be read either as "if x then y," or "x therefore y." A basic inference looks like this:

A biased inference looks like this:
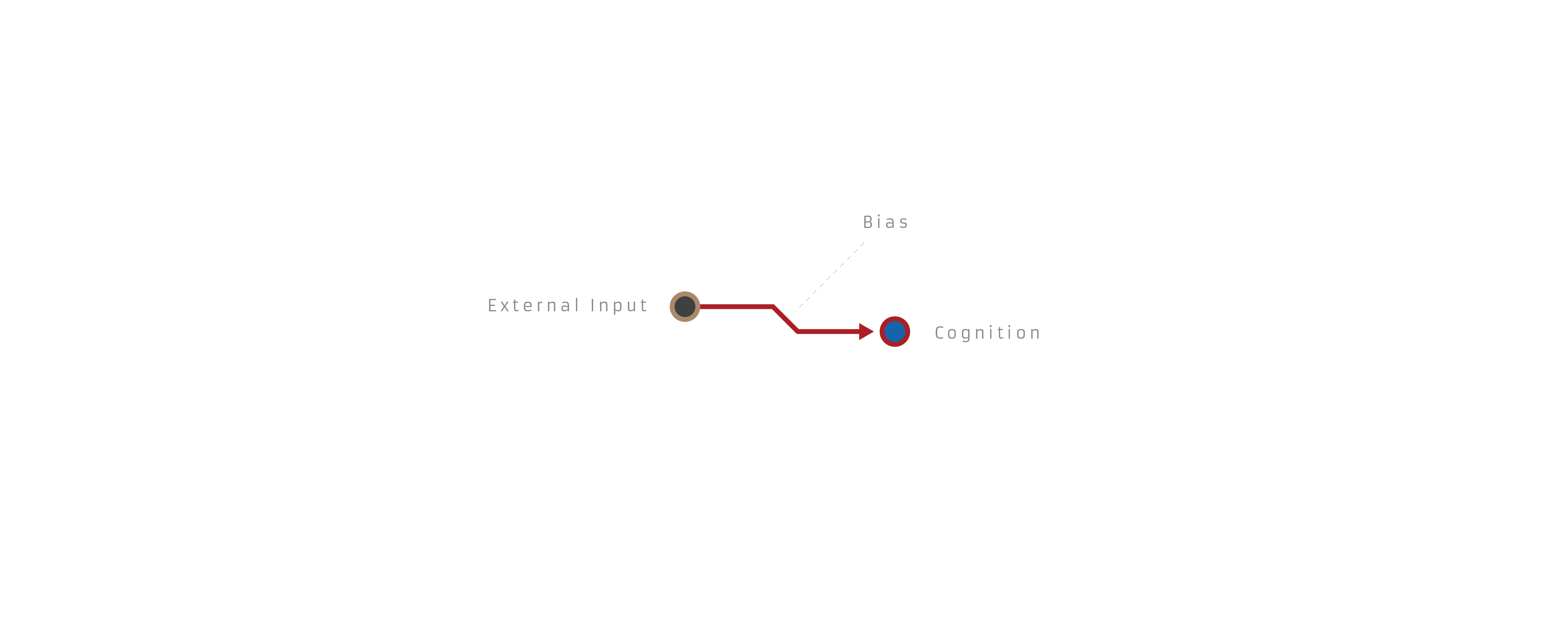
This is obviously a simplification of complex cognitive shit, but it's meant to be more of a functional interface than any kind of theory.
So to run through a few example biases, the fallacy of the undistributed middle:

The planning fallacy:

Planning fallacy corrected:

A little awkward, but it can capture basic failures in Bayesian reasoning as well:

Bayesian reasoning corrected:

And an example of compounding biases resulting in a distorted worldview:

I'm curious if anyone sees downsides to this framework, has other ideas to improve it, or thinks I'm hopelessly naive for even trying to capture human reasoning in a tidy diagram.
16 comments
Comments sorted by top scores.
comment by Free6000 · 2020-07-22T18:29:44.994Z · LW(p) · GW(p)
I’m not sure that you’re using these variables consistently. In some cases, the external input node is a fact or basic premise, in others (like the planning fallacy example) it represents an intuition. Same goes for the cognition/conclusion node which is also a bit confusing. I can see the value in this type of diagram, but I think it could use some refinement.
Replies from: dtm↑ comment by dtm · 2020-07-22T22:06:21.072Z · LW(p) · GW(p)
That makes sense; they are intentionally somewhat fluid so they can adapt to capture a wider variety of biases/phenomena. I'm trying to use the same framework to visualize emotional reactions and behavioral habits.
Replies from: JacobKopczynski↑ comment by Czynski (JacobKopczynski) · 2020-07-23T19:44:45.228Z · LW(p) · GW(p)
Capturing a wide variety of phenomena is a bug, not a feature.
Replies from: dtm↑ comment by dtm · 2020-07-23T22:29:09.468Z · LW(p) · GW(p)
It's a feature if the benefits of a more comprehensive model outweigh the costs. Whether that's true in this case is another question.
Replies from: JacobKopczynski↑ comment by Czynski (JacobKopczynski) · 2020-07-23T23:56:50.239Z · LW(p) · GW(p)
No, it is a bug in virtually all cases. A model which depicts a broad class of phenomena in a single way is a bad model unless the class of phenomena are actually very similar along the axis the model is trying to capture. These phenomena are not similar along any useful axis. In fact, there is no observable criterion you could choose to distinguish the examples depicted as biased from the examples depicted as correct. A biased inference, a correct inference where no bias you know of played a substantial role, an instance where multiple biases canceled out, an instance where you overcompensated for bias (e.g. "the world isn't actually dangerous, so that guy at the bus top with a drawn knife probably doesn't actually mean me harm"), and a Gettier case are all structurally identical.
This diagram format is a pure placebo and any value you perceive it to have given you is incorrectly attributed.
comment by Czynski (JacobKopczynski) · 2020-07-23T19:44:01.064Z · LW(p) · GW(p)
I don't see how this adds any value. For it to add value, you would have to have a coherent meaning for what a jog in the line represents, including notation that made it clear what an overcompensation for bias looks like and how that is distinguished from the unbiased picture, which must work even when you do not know, a priori, what the unbiased conclusion is.
Replies from: dtm↑ comment by dtm · 2020-07-23T22:25:56.931Z · LW(p) · GW(p)
I think I see what you're saying, but let me know if I've misinterpreted it.
Let's look at the planning fallacy example. First, I would argue it is entirely possible to be aware of the existence of the planning fallacy and be aware that you are personally subject to it while not knowing exactly how to eliminate it. So you might draw up a diagram showing the bias visually before searching or brainstorming a debiasing method for it.
According to Daniel Kahneman, “Using… distributional information from other ventures similar to that being forecasted is called taking an ‘outside view’ and is the cure to the planning fallacy.”
So removing the planning fallacy is not a matter of simply compensating for the bias, but adopting a new pathway to that type of conclusion. I don't think overcompensating for a bias can be said to remove it on a systemic level, and I don't think it necessarily needs to be shown differently in the diagram. If you are able to habitualize taking the outside view to determine deadlines by default, you still may not perfectly predict how long things will take, but this will no longer be due to the planning fallacy.
Replies from: abramdemski, JacobKopczynski↑ comment by abramdemski · 2020-07-24T14:44:55.548Z · LW(p) · GW(p)
If you are able to habitualize taking the outside view to determine deadlines by default, you still may not perfectly predict how long things will take, but this will no longer be due to the planning fallacy.
The point Czynski is making is that the diagram does not help us do that. Using the diagram, we mark an inference with a crooked line if we recognize that it is biased, and a straight line if we think it's unbiased. So if we forget a given bias, the diagram does not help us remember to e.g. take the outside view.
Let's say the diagram had three spots: evidence, prior, conclusion. And let's say the diagram is a visual representation of Bayes' Law. (I don't know how to draw a diagram like that, but for the sake of argument, let's pretend.) Then you would be forced to take the outside view in order to come up with a prior. So that kind of diagram would actually help you do the right thing instead of the wrong thing (at least for some biases).
↑ comment by Czynski (JacobKopczynski) · 2020-07-23T23:46:04.726Z · LW(p) · GW(p)
You have not so much misinterpreted it as failed to understand it at all. Drawing the diagram visually does literally nothing to make the situation in any way clearer. It adds no information which you did not have beforehand. There does not appear to be anything about this diagram format that could be used to add new information even in principle. You have replaced "I think this will take X hours; however, planning fallacy." with a drawing that depicts "I think this will take X hours; however, planning fallacy." This is not helpful. It is almost a type error to think that this could be helpful.
A disciple of another sect once came to Drescher as he was eating his morning meal.
“I would like to give you this personality test”, said the outsider, “because I want you to be happy.”
Replies from: dtmDrescher took the paper that was offered him and put it into the toaster, saying: “I wish the toaster to be happy, too.”
↑ comment by dtm · 2020-07-24T01:16:45.906Z · LW(p) · GW(p)
You are overestimating the ambition of the diagram. I know it does not add any new information. I am (working on) presenting the information in a visual form. That’s why I called it a new way of visualizing biases, not a new way to get rid of them with this one simple trick. You can convey all the information shown in a Venn diagram without a diagram, but that doesn’t mean the diagram has no possible value. And if there were a community dedicated to understanding logical relations between finite collections of sets back in 1880, I’m sure they would have shot down John’s big idea at first too.
Replies from: abramdemski↑ comment by abramdemski · 2020-07-24T15:03:55.300Z · LW(p) · GW(p)
Venn diagrams allow one to visually see and check the logical relations between finite collections of sets. For example, it makes it easy to see that A-(U-A) = A (where U is the universe); or to give a more complicated example, .
Argument maps allow one to visually see the structure of an argument laid out, which:
- helps avoid circular arguments;
- ensures that we can see what's supposed to be an unsupported assumption, which has to be agreed to for the argument to go through;
- allows us to check whether any assumptions require further justification (ie cannot be justified by broad agreement or obviousness);
- allows us to go through and check each inference step, in a way which is more difficult in an argument that's written out in text, and very difficult if we're just talking to someone and trying to get their argument -- or, thinking to ourselves about our own arguments.
In other words, both of these techniques help stop you when you try to do something wrong, because the structure of the visuals help you see mistakes.
Your proposed diagrams don't have this feature, because you have to stop yourself, IE you have to make a line crooked to indicate that the inference was biased.
Replies from: lambdaloop↑ comment by lambdaloop · 2020-07-25T21:15:21.814Z · LW(p) · GW(p)
It seems that people are focused a lot on the visualization as a tool for removing biases, rather than as a tool for mapping biases. Indeed, visualizations can have value as a summary tool rather than as a way to logically constrain thinking.
Some examples of such visualizations:
- scatter plots to summarize a pattern
- visualizations that use dots to convey the scale of a number intuitively (e.g. 1 person = 1 square, etc)
In these kinds of visualizations, you get a different way to look at the problem which may appeal to a different sense. I can already see value in this as a way to summarize biased thought.
That said, I do agree with the comments about perhaps tuning the diagram to provide a bit more constraints. Going off of abramdemski's comment above, I think perhaps coloring or changing the lines by the type of reasoning that is happening would be useful. For instance, in your examples, you could have the attributes of "future prediction" for the planning fallacy example or something like "attribute inference" for the Bayesian inference example and maybe undistributed example. By disambiguating between these types in your diagram, you can add rules about the necessary input to correct a biased inference. A "future prediction" line without the "outside view" box would be highly suspect.
Replies from: dtm↑ comment by dtm · 2020-07-27T16:32:32.300Z · LW(p) · GW(p)
I think my comments about it being helpful in working through biases led people to think I intended these primarily as active problem-solving devices. Of course you can't just draw a diagram with a jog in it and then say "Aha! That was a bias!" If anything, I think (particularly in more complex cases) the visuals could help make biases more tangible, almost as a kind of mnemonic device to internalize in the same way that you might create a diagram to help you study for a test. I would like to make the diagrams more robust to serve as a visual vocabulary for the types of ideas discussed on this site, and your comments on distinguishing types of biases visually are helpful and much appreciated. Would love to hear your thoughts on my latest post [LW · GW] in response to this.
comment by ChristianKl · 2020-07-25T20:07:47.854Z · LW(p) · GW(p)
Having good notation is generally good. Whether or not a notation is good depends on how you want to use it. It seems to be a CBT exercise to write out thoughts and identify cognitive distortions.
It seems to me like it would be valuable to be able to write out the thought before being able to decide whether or not a bias is involved. It might make sense to have a notation in which you can more easily add the information about whether or not a cognitive distortion is involved later then stating the thought by adding a graphical feature.
If you do it a lot I could also imagine that you might want to have symbols for the commons biases instead of writing them out.
More practically I'm not sure that it's good to focus on biases. When writing down belief networks it feels like belief reporting and asking a lot of "why X" seems like it goes deeper for me.
Replies from: dtm↑ comment by dtm · 2020-07-27T16:37:16.002Z · LW(p) · GW(p)
You are a step ahead of my latest post [LW · GW] with the CBT comment. Good points on being able to write out thought chains and add distortion notation later and symbols for common biases. Have you seen examples of belief network diagrams used in this way?
Replies from: ChristianKl↑ comment by ChristianKl · 2020-07-27T18:51:20.001Z · LW(p) · GW(p)
I have read about CBT but haven't done the exercise about spotting cognitive distortions.
I have created larger diagrams in the belief reporting context. My knowledge about the technique comes from a single two hour workshop at the LessWrong community weekend and not directly from Leverage. I'm not sure what kind of notation the Leverage folks use to layout belief networks.