A Simple Introduction to Neural Networks
post by Rafael Harth (sil-ver) · 2020-02-09T22:02:38.940Z · LW · GW · 13 commentsContents
I II II.I II.II II.III III III.I III.II III.III None 13 comments
This post will discuss what neural networks are (chapter I), why they work (chapter II), and how they are trained (chapter III). It serves as the tenth entry in a sequence on Machine Learning, but it's written to be accessible without having read any previous part. Most of chapters I and II also doesn't require any advanced math.
Note that bold and italics means "I am introducing a new Machine Learning term."
I
Meet the neural network:

The term "neural network" describes a class of Machine Learning predictors which is inspired by the architecture of the human brain. It is an extremely important class: AlphaGo, AlphaGo Zero, AlphaStar, and GPT-2 are all based on neural networks.
The network above will be our running example throughout this post. Let's begin by defining its components. The blobs are called neurons. The arrows are called edges. Together, they define the graph underlying the neural network. (This usage of the term "graph" has nothing to do with a function graph – instead, a graph is simply a bunch of nodes with arrows between them.) If this graph has no cycles (= edges going around in a circle), the neural network is also called feed-forward. For this post, you can assume networks are always feed-forward. The green neurons are called input neurons, the red neurons are called output neurons, and the blue neurons are called bias neurons.

If it is possible to divide the entire set of neurons into an ordered list of subsets, such that each neuron only points towards neuron in the subset next in line, the network is called layered. For this post, you can assume networks are always layered. However, note that non-layered networks do exist: a network with edges and and cannot be divided into layers.

As you can see, each neuron only points towards neurons in the next higher layer. Note that the first blue neuron, despite being in the input layer, isn't an input neuron.
So far, our view has been simplified. In reality, there's more going on:

The written on the edges are numbers called weights. They will determine how important the value of the incoming edge is. The written inside of the neurons are functions (in the classical sense: they take a value as input and output something else). From here on, if I talk about "the fifth neuron," I mean the neuron with written in it.
This picture is a good guide to explain how a neural network works.
First, an input value (think of a number) is fed into the input neuron, which forwards it to neurons three and four. At the same time, neuron two (the bias neuron) sends the value to neurons three and four (sending the number 1 is all that bias neurons ever do). At this point, the third neuron has received two values – it now multiplies them with the weights on the respective edges, so it multiplies the value coming from the first neuron with and the number 1 coming from the bias neuron with . Then it adds both values together and applies the function to them. The result of this process is . The fourth neuron has also received two values, and it does the same thing (using the weights and ), leading to the term . With that done, the third neuron sends its value (the one we just computed) to the sixth neuron, the fourth sends its value to both the sixth and the seventh, and the fifth neuron (the bias neuron) sends the number to both the sixth and the seventh neuron. Now they apply their weights, then their functions, and so on. Eventually, the ninth neuron receives a value, applies to it, and outputs the result, which is the output of the network.
Recall that the blue neurons are called bias neurons – that is because they have no incoming edges. Instead of computing something, they always output 1 and thus "bias" the weighted sum, which arrives at the neurons in the next layer, by a constant factor. Each hidden layer has exactly one bias neuron, and the input layer also has one. That way, each neuron except the input neurons has an incoming edge from a bias neuron. Also, note that the input neuron doesn't apply any function to the input it receives (but all other neurons do).
To describe this process more formally, we need some additional notation for the value that goes into a neuron (the weighted sum of the values on its incoming edges) and the value which comes out (after the function is applied to it). Let's zoom into the sixth neuron:

When the input values arrive, first the weighted sum is computed, then is applied to it, and that will be the output value . Thus,
.
The new thing here is that we express the output of any neuron in terms of the outputs of neurons in the previous layer; thus, the equation can describe the output of any neuron in the network. Notice that the value is missing – that's because the fifth neuron is a bias neuron, which means it puts out the value 1, which means that is the same as . Also, note that the image shows the weights of the incoming edges, but not the weight of the outgoing edge: the weights of an edge should always be thought of as belonging to the neuron the edge is heading into.
Recall that our neural network can be divided into layers:
This is useful for evaluating the network – it allows us to do so layer-by-layer. In the beginning, we just know the input value(s) . We set
for each neuron in layer 1 (the input layer). This is just a relabeling – nothing has happened yet. But now, assuming we have all the output values for some layer , we compute the output values for each neuron in layer by setting
where is the set of indices of neurons that have an edge pointing towards neuron . Since this equation applies for any layer, it allows us to evaluate the entire network, one layer at a time. The output values of the final layers will be the output values of the network. If you're unfamiliar with the notation, then never mind this – the equation merely states what we have already discussed, namely that the output of each neuron is computed in terms of the outputs of neurons in the previous layer. The purpose of writing it down as a single equation is to make it less ambiguous and more compact.
II
Now you know what a neural network is and how it is computed. But what are they good for, and why do they work so well?
Let's start with the first question. If you already know what they're good for, you can skip forward to section II.II for the second one. Otherwise, here's a quick overview.
II.I
If all values (input values, output values, and values sent between neurons) are regular numbers, then the entire network implements a function , where is the number of neurons in the input layer and the number of neurons in the output layer. In our case, . The notation means that always takes an element in , which is a vector of numbers (all numbers fed to input neurons), and returns an element in , which is a vector of numbers (all numbers returned by output neurons). And it does this for any possible input – so for any input numbers, it returns output numbers. To say that the network "implements a function" means that we can abstract away from how exactly it works: in the end, its behavior is fully described by such a function . This is nice because functions are more well-understood objects than neural networks.
So the utility of a neural network is that it lets us evaluate this function . This can be valuable if does useful things. As an example, we can suppose that takes the source code of an image as input and outputs a single bit indicating whether or not the image contains a cat. In that case, if we suppose the image is gray-scale with 1 byte per pixel and 200 by 200 pixels, the function is of the form . This notation means that it takes a vector of bits as input (which determines an image), and outputs a single bit, where 1 means "cat" and 0 means "no cat". And again, it does this for every possible vector of bits. Having access to this function would be useful, and thus, having a neural network that implements this function – or more realistically, which implements a similar function (with some flaws) – would also be useful.
Another example could be the function . This function takes a vector of bits as input which encodes a tweet (280 character limit, each character is encoded by 1 byte, weird symbols are ignored), and outputs a number between 0 and 10 that rates how likely this tweet is to violate twitter's terms of service. This function would be very useful to learn – and, in fact, Jack Dorsey mentioned that they are using Machine Learning for stuff like this (whether they use neural networks, I don't know, but they probably do).
How to train a neural network is something we discuss in detail in chapter III. For now, I'll only mention that it works based on training data. That is, we have some sequence of examples where the are inputs to the neural network (in the twitter example, tweets), and the are outputs (in the twitter example, scores from 0 to 10 that have been assigned by a human). We then train the network to do well on the training data, and hope that this will lead it to also do well in the real world (in the twitter example, we hope that it also labels new tweets accurately). However, this description is not specific to neural networks – it applies to all instances of supervised learning, which is a big part of Machine Learning – and there are many different machine learning techniques out there. So what is it about neutral networks in particular that make them so powerful? We know that they are inspired by the human brain, but that is hardly an answer.
II.II
This feels like an apt time to add the disclaimer that I am very much not an expert. The following is a result of my searching the existing literature for the best answers, but it is an incomplete search evaluated with limited knowledge.
That said, one possible answer is to point towards the expressibility theorems we have on neural networks. Most notably, there is the universal approximation theorem – it states that a feed-forward neural network with only a single hidden layer (recall that, in our example, we had two hidden layers) can approximate any continuous & bounded function under some reasonably mild conditions. Sounds pretty good – until you realize that the proof basically consists of brute-forcing the approximation. This makes it kind of like pointing out that the class of all hypotheses such that there is a C program of size at most 1 GB implementing them can also solve a wide variety of practically relevant problems. A fairly damning fact is that the neural networks constructed in the proof have exponentially many neurons in the hidden layer – just like there are exponentially many C programs of with at most bits. ("Exponential" means that the number is an exponential function of , in this case, .) Results stating that something can be done with exponential resources are generally unimpressive.
A much simpler result that can be rigorously proved in just a few lines states that a neural network (with only one hidden layer) can implement any function of the kind . This sort of function is called a boolean function, and it can be thought of as taking in input bits and outputting a binary yes/no. More precisely, the theorem states that there is an architecture for a neural network (i.e., a graph) such that, for each possible function , there is a set of weights such that the neural network defined by that architecture & that set of weights implements that function. Moreover, every neuron in this network applies the same, very simple function . But once again, the number of neurons in the hidden layer of that architecture is exponential in . And there is also a second theorem which shows that this is a lower bound – an (architecture for a) neural network implementing this kind of function has to have an exponential number of neurons in , no matter how smartly it is designed.
Verdict: unsatisfying.
II.III
If the universal approximation theorem cannot answer the question, what then? The best explanation I've found is from a paper co-authored by Max Tegmark – the guy who wrote Our Mathematical Universe and is the president of the Future of Life Institute. It's titled "Why does deep and cheap learning work so well?" and it begins with the observation that even simple tasks such as image-classification are, in some sense, impossible to solve by a neural network. As mentioned, a 200-by-200 bit gray-scale image with just a single byte for each pixel defines the input space . That space has size (i.e., it consists of encodings for images), which is roughly . (Note that the dot is not a decimal point.) But there's no reason to be so modest; neural networks are, in fact, used to classify much larger images. Let's say our images are 1000-by-1000 pixels with 4 bytes per pixel. In that case, the space has elements, which is about . On the other hand, a neural network with, say, 1000 neurons only has possible combinations, where is the number of different values each weight can take. Even if we're overly generous and assume that each weight can lead to a 100 meaningfully different configurations, that would only provide us with the ability to differentiate between at most different cases – barely enough for tiny gray-scale images, but nowhere near enough for decently sized images. This follows because a neural network cannot possibly differentiate more images than it has different configurations. And we didn't even talk about the amounts of training data that are available in practice, which are nowhere near as large.
This suggests that the situation in practice looks something like this:

And one is left to wonder how this could ever work out.
The solution the paper suggests is to replace the above image with this one:

That is, the problem state space has actually been generated by a physical process that is far simpler to specify than the state space itself and usually even simpler than the neural network. For example, cats (or even pictures of cats) are pretty complicated mathematical objects, but the process which has generated cats (namely evolution) is relatively simple. Similarly, the phrase "draw cat pictures," which one can give to a bunch of artists, is far simpler than the images they will produce. Thus, while it is true that a neural network with ~1000 neurons can only give reasonable answers to a tiny subset of images in image-space, this is acceptable: most of the images we care about are contained in that subset. Perhaps most strikingly, the standard model of physics only has 32 parameters, according to the paper.
Now, you might recall that the title of the paper mentioned "deep learning." This term refers to a neural network with a lot of hidden layers, as supposed to just one or two. The fact that deep learning has had massive success in practice stands in contrast to the universal approximation theorem, which argues using a network of only a single hidden layer. It is probably fair to say that "shallow" networks are more similar to other kinds of predictors and less analogous to what the human brain does.
So why neural nets – and more specifically, deep learning – rather than any other technique? On this point, Lin et al. (Tegmark is part of the "et al.") argue that that nature is fundamentally hierarchical:
One of the most striking features of the physical world is its hierarchical structure. Spatially, it is an object hierarchy: elementary particles form atoms which in turn form molecules, cells, organisms, planets, solar systems, galaxies, etc. Causally, complex structures are frequently created through a distinct sequence of simpler steps.
So we can rethink the picture yet again to arrive at something like this:

So the idea is not just that the small complexity of the generation process makes it feasible for neural networks to accomplish tasks such as recognizing faces, but also that it may learn by reversing this generative process. Furthermore, since this process naturally takes place in multiple steps, the most effective neural networks will themselves be performing their computations in multiple steps. The paper also proves something to the effect that generative hierarchies can be "optimally reversed one step at a time," but I can't tell you what exactly that means since the statement is formalized in information theory.
Now, do "multiple steps" translate into "multiple layers"? The answer to that is a pretty clear yes (here is where we need to introduce a bit of math). Notice that, even if a neural network has many input notes, it can be considered to modify just a single object – namely a vector , where is the number of input neurons. Now the entire function which the neural network computes can be written down like so:
where is the number of layers, the are linear functions ( matrices), and the are the functions that the neurons implement, applied coordinate-wise. The symbol means that we first apply the right function, then the left one. If the input vector is fed into the neural network, it first passes unchanged to the input neurons (recall that, unlike all other neurons, they don't compute a function). Then they are scaled according to the weight values between layers 1 and 2, which corresponds to the linear transformation , our first transformation. (It's indexed with 2 because it leads into layer 2.) Now the input neurons in the second layer (the first hidden layer) apply their functions, which corresponds to the component-wise application of (provided all neurons on the layer implement the same function, which is an assumption we make here). Then the outputs are scaled according to the weight values between layers 2 and 3, which corresponds to the linear transformation , and so on. In the end, the output neurons apply their function component-wise.
Hence the neural network does indeed apply one (pair of) transformations per layer. However, no-one knows what neural networks are actually doing most of the time, so all of this is still largely speculative.
Nonetheless, here is an interesting observation that backs up Lin et al.'s claims. (Skip this part if you have never taken a course in Linear Algebra.) Suppose we declare that the neurons aren't allowed to do anything (i.e., they just implement the identity function). In that case, the neural network decomposes into the transformations
Concatenating many linear functions yields itself a linear function, so this neural network does nothing except apply a single matrix to the input vector, namely the matrix .
Let's suppose the input elements form a matrix , and the goal of the network is to multiply that matrix with another matrix . Then, this can be trivially realized with just an input and an output layer (no hidden layers), by setting . This corresponds to the standard way of doing matrix multiplication, which requires operations. But there are also (much more sophisticated) algorithms with funny time complexities such as – point being, they're faster for very large matrices. Thus, since neural networks are universal approximators, there exists a neural network that implements matrix multiplication with similar time complexity. This is impossible to replicate on a shallow network. (Related: proofs in linear algebra often argue by decomposing a matrix into smaller ones.)
The paper calls these results "no-flattening theorems" and goes on to reference a bunch of other examples. So it is possible to rigorously prove that at least some specific neural networks cannot be flattened without losing efficiency. And it's also worth noting that there exists a version of the universal approximation theorem which manages to restrict a network's width in favor of more hidden layers.
That's all I have on the why question. Has it been a satisfying answer? I would vote a firm no – it seems a rather long way from being satisfactory. Nonetheless, I at least feel like I now have some nonzero insight into why neural networks are powerful, which is more than I had before reading the paper.
III
This final chapter is where we look at how to train a neural network. From this point onward, the post will get a lot more mathy – in particular, it assumes you know derivatives and the chain rule. If you don't, feel free to skip right to the end.
First, we need to discuss which part of the network we wish to learn. In principle, there are many possible approaches, but in practice, one usually fixes everything except the weights. That is, one fixes
- the underlying graph (i.e., all neurons and edges)
- the functions (which aren't very complicated, they might even all be the same)
and then looks for the set of weights with which the network performs best. The above is also called the architecture of the network. Any given architecture can implement a wide variety of different functions (by giving it different weights).
As mentioned, we assume that we're in the setting of supervised learning, where we have access to a sequence of training examples. Each is an input to the network for which is the corresponding correct output.
The idea is now to train the neural network to do well on the training data and hope that this will cause it to do well in the real world.
How do we do that? Given infinite computing power, there is a simple algorithm: we choose some finite encoding for real numbers, say 64-bit encoding, and perform an exhaustive search over all possible combinations of weight values; then we test the network with each one and stick with the combination that works best. Unfortunately, there are many combinations of weight values, so this approach would require rounds, where each round consists of testing the neural network with those weights on all of . This is infeasible even for our small network, therefore we need a more efficient approach. The algorithm we will study is called backpropagation, and it relies on something called Stochastic Gradient Descent.
III.I
Here is how it works. Suppose we give the network some preliminary weights so that it is fully defined, and we focus on one particular training point, .

If we feed into the network, we will get some number as the result. Let's call it .

This prediction will be good if is close to and bad otherwise, since is the correct output for . Thus, the difference between them is a measure for the quality of the prediction. For unimportant reasons, we square the difference, so we take as our measure for how our network did (on this one point). If is small, it did well; if it's large, it did poorly.

This difference depends on all of the weight values , because all of them were used to compute . Suppose we arbitrarily pick out one such weight , and pretend that all other weights are fixed. Then we can consider the difference as a function of that weight. We call that function the loss function. To reiterate: the loss function takes a value for the weight , and outputs the value of given that we apply the network with value for weight . (Remember that all other weights are fixed.) And if we can somehow compute this function, we can also take the derivative. For the weight , this will be the number .

If is positive, we know that will increase if we increase the value for (and conversely, it will decrease if we decrease the value for ). If it is negative, we know that will decrease if we increase the value for . In both cases, we know how to change so that the term will decrease – which is what we want. Now we do this for each weight separately, i.e., we change each weight such that decreases. The result of this step is a neural network in which all weights are a little bit better than before.
And now – starting with our new weights – we do all of this again with for the next training point. That will again update our weights, and we can repeat the process for a third point, and so on. After updating on all the training points we have, the final weights are the algorithm's output. How much we change each weight is determined by a parameter of the algorithm called the step size. It usually decreases over the course of the algorithm, i.e., we move the weights more in the beginning when we know they aren't yet any good.
III.II
The remaining question is how to compute the derivative of the loss function with regard to each weight. (From here on, "derivative" will always mean "derivative of the loss function.")
Remember how the network was evaluated layer by layer? Evaluating the derivative with regard to each weight will also be done layer by layer, but this time in reverse. That's why it's called backpropagation. Let's begin by computing the weight of an edge leading into the final layer – let's take .
At some point in chapter 1, we've zoomed into the sixth neuron to see that there are actually three distinct elements we need to differentiate: the input to the neuron, i.e., the sum of the weighted values from the incoming edges (), the function of the neuron () and the output after applying the function . Now we need to do the same with the ninth neuron.

Note that is the same as . We're interested in the term . Using the chain rule, we can write
The first term is . (This notation is compact but somewhat sloppy – in truth, is a function which needs to be applied to a parameter.) The second term is the output of the ninth neuron with regard to its input; it depends on the function . And the third term is easy; we have
Note that these are all known parameters – we have obtained the by evaluating the neural network on the input .
At this point, we perform a non-obvious change of course. Even though the value is what we really care about, to process the entire network, it will be more useful to focus on the term . That is, we will focus on the derivative with regard to the input value of the neuron of the final layer, rather than with regard to the weights of the incoming edges. This is easily done – we just drop the third term in the chain rule above, i.e., . Once we have those derivatives for the entire network (i.e., the derivatives with regard to the input values of every neuron), it will be easy to reconstruct the derivatives with regard to the weights – we just multiply with the third term again.
Thus, the way we will process the entire network is via the following three steps
- compute the derivative with regard to the input neurons of the final layer
- for each layer (starting from the second last), compute the derivative with regard to the inputs of the neurons of layer in terms of the derivatives with regard to the inputs of the neurons of layer
- for each weight , compute
We've already dealt with step #1, and step #3 is fully described by the equation above. All that's left is to demonstrate how we can do step #2. So suppose we have already processed layers three and four, and now we wish to process layer two. Then we already know the derivatives and and (check with the network above). We now demonstrate how, using this, we can compute the derivative with regard to an input neuron of the second layer. Let's choose an example; they all work the same way. Once again, we zoom into the relevant part of the network:

Now we have
The second term depends on . What about the first? Here is where the last complication comes in. The way influences the error cannot be reduced to any single derivative in the third layer, because the fourth neuron feeds into both the sixth and the seventh neurons. Thus, we have the apply the advanced chain rule to write
Now and are terms we have computed in previous rounds, and the other two terms are easy – we have and .
III.III
If you have read the previous posts in this sequence, or just know about gradient descent, you might object that the learning process will get stuck in a local minimum because the loss-function is non-convex. In less jargony language: suppose we have gone through a few rounds of the training process with backpropagation. It could be that now our weights are locally optimal – any small change will make the network perform worse – but if we changed them far enough, we could still improve its performance. We don't want the step size to be too large; otherwise, we would keep jumping over the target. Thus, if the network is large, the algorithm will inevitably get stuck in a local minimum.
The practical solution is simply to run the entire backpropagation algorithm a bunch of times, say 1000 times, starting from different initial weights. The hope is that, if each run of the algorithm finds some local optimum, and then we take the best of those, the result could still be pretty good. While repeating the entire algorithm 1000 times may seem inefficient, recall that the brute force approach would require upwards of steps, where is the number of neurons. For large networks, even running backpropagation a million times would be vastly more efficient than using a brute-force search.
It's worth noting that neural networks are popular because they perform well in practice, not because of theoretical results. Given how important they are, the existing theory is rather underwhelming.
Finally, I've skipped over the functions inside of the neurons all post long. That's because I think they're quite nonessential, and introducing them would complicate the key ideas. But for the sake of completeness: a choice still found in textbooks is the logistic function , given by the equation
Its graph looks like this (picture from Wikipedia):
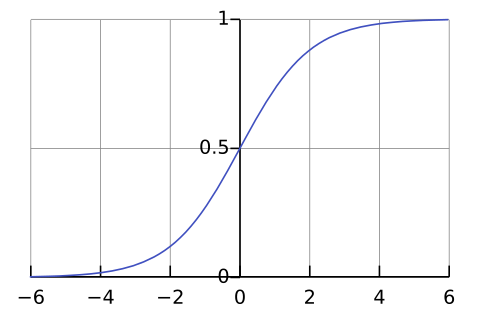
So it simply ranges between 0 and 1; it gets close to 0 for very small (negative) inputs, and close to 1 for very large inputs. This particular function has the lovely property that , i.e., its derivative is very easy to compute. However, I've been told that this function is not commonly used in practice anymore, and instead, a popular choice is something called the rectifier function defined by
Its graph looks like this,

and its derivative is no harder to compute, as it's either 1 or 0.
13 comments
Comments sorted by top scores.
comment by [deleted] · 2020-02-10T21:56:42.074Z · LW(p) · GW(p)
Slight ntipick: Simply because logistic isn't actually used in practice anymore, it might be better to start people new to the sequence with a better activation function like reLU or tanh?
When I was first learning this material, due to people mentioning sigmoid a lot, I thought it would be a good default, and then I learned later on that it's actually not the activation function of choice anymore, and hasn't been for a while. (See, for example, Yann LeCun here in 1998 on why normal sigmoid has drawbacks.)
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-02-10T22:55:17.146Z · LW(p) · GW(p)
Okay – since I don't actually know what is used in practice, I just added a bit paraphrasing your correction (which is consistent with a quick google search), but not selling it as my own idea. Stuff like this is the downside of someone who is just learning the material writing about it.
comment by Pattern · 2020-02-10T02:10:04.055Z · LW(p) · GW(p)
General:
This was a very clear explanation. Simplifications were used, then discarded, at good points. Everything built up very well, and I feel I have a much clearer understanding - and more specific questions. (Like how is the number of nodes/layers chosen?)
Specifics:
f=Aℓ∘⋯∘A2
What's the "ℓ"? (I'm unclear on how one iterates from L to 2.)
Nonetheless, I at least feel like I now have some nonzero insight into why neural networks are powerful, which is more than I had before reading the paper.
And you've explained the 'ML is just matrix multiplication no one understands' joke, which I appreciate.
As mentioned, we assume that we're in the setting of supervised learning, where we have access to a sequence S=((x1,y1),...,(xm,ym)) of training examples. Each xi is an input to the network for which yi is the corresponding correct output.
This topic deserves its own comment. (And me figuring out the formatting.)
For unimportant reasons, we square the difference
Absolute value, because bigger errors are quadratically worse, it was tried and it worked better, or tradition?
This makes it convenient to use in the backpropagation algorithm.
Almost as convenient as the identity function.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-02-10T08:31:28.940Z · LW(p) · GW(p)
What's the "ℓ"? (I'm unclear on how one iterates from L to 2.)
is the number of layers. So if it's 5 layers, then . It's one fewer transformation than the number of layers because there is only one between each pair of layers.
Absolute value, because bigger errors are quadratically worse, it was tried and it worked better, or tradition?
I genuinely don't know. I've wondered forever why squaring is so popular. It's not just in ML, but everywhere.
My best guess is that it's in some fundamental sense more natural. Suppose you want to guess a location on a map. In that case, the obvious error would be the straight-line distance between you and the target. If your guess is and the correct location is , then the distance is – that's just how distances are computed in 2-dimensional space. (Draw a triangle between both points and use the Pythagorean theorem.) Now there's a square root, but actually the square root doesn't matter for the purposes of minimization – the square root is minimal if and only if the thing under the root is minimal, so you might as well minimize . The same is true in 3-dimensional space or -dimensional space. So if general distance in abstract vector spaces works like the straight-line distance does in geometric space, then squared error is the way to go.
Also, thanks :)
Replies from: Richard_Kennaway, ZankerH, None↑ comment by Richard_Kennaway · 2020-02-11T17:05:23.359Z · LW(p) · GW(p)
One reason for using squared errors, which may be good or bad depending on the context, is that it's usually easier to Do Mathematics on it.
↑ comment by ZankerH · 2020-02-11T13:22:13.174Z · LW(p) · GW(p)
Square error has been used instead of absolute error in many diverse optimization problems in part because its derivative is proportional to the magnitude of the error, whereas the derivative of the absolute error is constant. When you're trying to solve a smooth optimization problem with gradient methods, you generally benefit from loss functions with a smooth gradient than tends towards zero along with the error.
↑ comment by [deleted] · 2020-02-11T17:50:13.960Z · LW(p) · GW(p)
Another possible reason for using squared error is that from a stats perspective, the Bayes (optimal) estimator of the squared error, will be the mean of the distribution, whereas the optimal estimator of the MAE will be the median. It's not clear to me that the mean's what you want but maybe?
comment by tfluids (j-a-collins) · 2022-09-17T13:39:35.833Z · LW(p) · GW(p)
Just wondering, you refer to the derivative here but the notation is for the partial derivative, which one is correct?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2022-09-17T13:52:05.284Z · LW(p) · GW(p)
Partial, I think. I mean, it's all with respect to one variable.
(Looking at this post now, it really should have included concrete numbers in addition to the symbols, which would also have answered the question. Idk if I'll get around to fixing it...)
Replies from: j-a-collins, j-a-collins↑ comment by tfluids (j-a-collins) · 2022-09-17T13:56:12.581Z · LW(p) · GW(p)
Cool, thanks a lot. I assumed the notation was right.
Thanks for the post, by the way, really great work.
↑ comment by tfluids (j-a-collins) · 2022-09-29T13:02:28.316Z · LW(p) · GW(p)
Just another quick question about this part: The first term is .
Shouldn't this be: ?
You mentioned just after something about notation, but I wanted to understand a bit better in case I'm missing something
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2022-09-29T13:57:33.445Z · LW(p) · GW(p)
I believe you're correct. (I haven't thought through the full context, but that shouldn't be necessary for that equation... I hope.) I've edited it. Thanks!
comment by George3d6 · 2020-02-11T04:41:18.930Z · LW(p) · GW(p)
I always thought there ought to be a good way to explain neural networks starting at backprop.
Since to some extent the criterion for architecture selection always seems to be whether or no gradients will explode very easy.
As in, I feel like the correct definition of neural networks in the current climate is closer to: "A computation graph structured in such a way that some optimize/loss function combination will make it adjust its equation towards a seemingly reasonable minima".
Because in practice that's what seems to define a good architecture design.