The Fermi Paradox: What did Sandberg, Drexler and Ord Really Dissolve?
post by Shmi (shminux) · 2018-07-08T21:18:20.358Z · LW · GW · 28 commentsContents
Due to random chance, some of the parameters in the Drake equation, we do not know which, we do not know why, are many orders of magnitude smaller in our universe than previously estimated. Using the distributional estimate instead of a point estimate both increases the likely number of ETIs per galaxy, and the fraction of empty galaxies. If our universe is drawn at random from the pool of factors with the distributions as suggested by the paper, then there are substantial odds that we are alone in the observable universe. None 28 comments
(Cross-posted from my blog)
So this paper by the trio from the FHI, Anders Sandberg, Eric Drexler and Toby Ord (SDO for short) has been talked about quite a bit, on LessWrong [LW · GW], on SSC and on Reddit. It is about how their Monte-Carlo calculations based on probability distributions rather than on the usual point estimates of the Drake equation apparently dissolves the question of why we are seemingly alone in the Universe that is supposed to be teeming with intelligent life, if one takes the Copernican idea "we are not special" seriously. One grim suggestion is that there is a Great Filter that is still in front of us and is almost guaranteed to kill us off before the human civilization reaches the technological levels observable by other civilizations like ours.
There are plenty of other ideas, most addressing various factors in the Drake equation, but the one advanced in SDO is quite different from the mainstream: they say that estimating these factors is a wrong way to go, because the uncertainty in these very small probabilities is so large, the point estimates are all but meaningless. Instead they suggest that the correct approach is something along the following lines: First, assume a reasonable probability distribution for each factor, then draw a value for each factor based on their probability distributions, calculate the resulting expected value of the number of currently detectable civilizations, then repeat this process many times to create a synthetic probability distribution of the number of this civilizations, and finally extract the odds of us being alone in the universe from this distribution. And that is what they did, and concluded that the odds of us being alone in the Milky Way are something like 1:3. Thus, according to SDO, there is no paradox, an average universe is naturally a desolate place.
Their to the Fermi paradox solution is basically
Due to random chance, some of the parameters in the Drake equation, we do not know which, we do not know why, are many orders of magnitude smaller in our universe than previously estimated.
I have an issue with calling it "dissolving the paradox", since it doesn't answer any of the practical questions about the universe we live in. Fermi's question, "Where is everybody?" remains open.
But I may have misunderstood the paper. So, what follows is an attempt to understand their logic by reproducing it. Here I will analyze their toy model, as it has all the salient features leading to their conclusion:
There are nine parameters (f1, f2, . . .) multiplied together to give the probability of ETI [Extra-terrestrial intelligence] arising at each star. Suppose that our true state of knowledge is that each parameter could lie anywhere in the interval [0, 0.2], with our uncertainty being uniform across this interval, and being uncorrelated between parameters.
A point estimate would be taking a mean for each factor and multiplying them, giving one-in-a-billion chance per star, which results in a virtual certainty of ETI at least somewhere in a galaxy of hundreds of billions of stars.
Let's try a distribution estimate instead: take 9 random numbers from a uniform distribution over the interval [0, 0.2]. Here is a bunch of sample runs, the expected values of ETIs in the toy galaxy, and the odds of the toy galaxy being empty:

Notice that, out of the 10 sample galaxies in this example, about half show considerable odds of being empty, highlighting the difference between using a distribution and the point estimates. SDO likely had run a lot more simulations to get more accuracy, and I did, too. Here is the distribution of the odds for a given number of ETIs in the galaxy, based on about ten million runs:
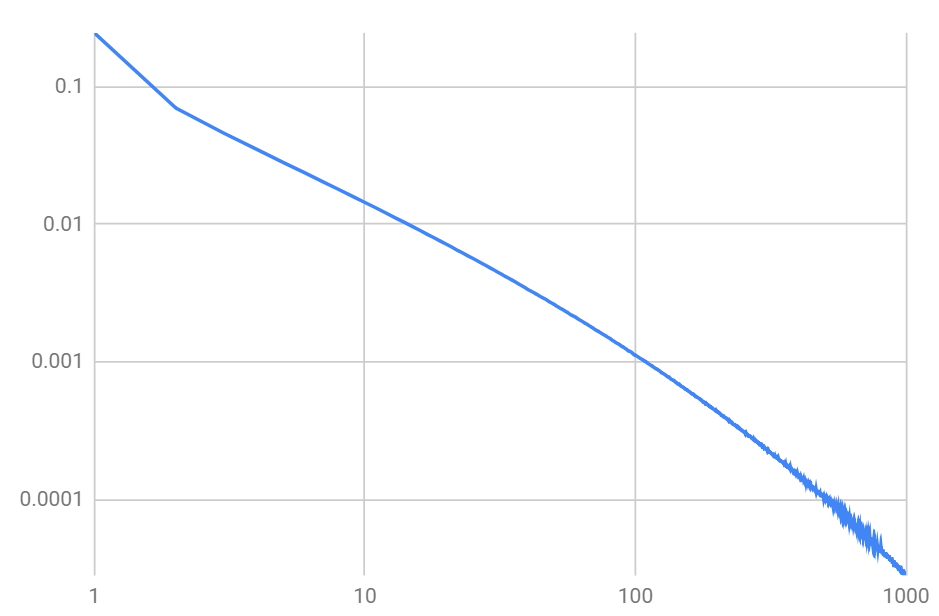
The horizontal axis is the number of ETIs, and the vertical axis is the probability of this number of ETIs to happen in a given toy galaxy drawn at random, given the probability distribution for each factor, as specified above.
Notice how wide this distribution is: some galaxies are completely bereft of ETIs, while others have hundreds and even thousands of them!
The above graph is very close to the power law: the probability of the number of ETIs goes roughly as the number of ETIs to the power of -1.2. This means that the estimate of the expected number of ETIs is actually divergent, though the median number of ETI's per galaxy is finite and about 30. So, somewhat paradoxically,
Using the distributional estimate instead of a point estimate both increases the likely number of ETIs per galaxy, and the fraction of empty galaxies.
The paper states that "Monte Carlo simulation shows that this actually produces an empty galaxy 21.45% of the time," but does not specify the way this number was calculated. From the plot above, the probability of having between zero and one ETIs, whatever it might mean, is 24.63%. A different way of calculating the average odds of an empty toy galaxy would be to calculate the odds of each sample galaxy to be empty as
P(empty) = (1-p_1*p_2*...*p_9)^(10^11)
then average all these odds. This approach gives the fraction of empty galaxies as 21.43%, very close to the number quoted in the paper.
This toy example demonstrates nicely the main result of the SDO paper: the usual point estimate produces a wildly inaccurate expected fraction of galaxies with no ETIs in them. The rest of the SDO paper is focused on calculating a more realistic example, based on the current best guesses for the distributions of each factor in the Drake equation:

Using these distributions and their further refinements to calculate the odds yield the following conclusion:
When we update this prior in light of the Fermi observation, we find a
substantial probability that we are alone in our galaxy, and perhaps even in our
observable universe (53%–99.6% and 39%–85% respectively). ’Where are they?’
— probably extremely far away, and quite possibly beyond the cosmological
horizon and forever unreachable.
If our universe is drawn at random from the pool of factors with the distributions as suggested by the paper, then there are substantial odds that we are alone in the observable universe.
This is because some of the factors in the Drake equation, due to their uncertainty, can end up many orders of magnitude smaller than the value used for a point estimate, the one where this uncertainty is not taken into account. There is no claim which of the parameters are that small, since they differ for different desolate universes. Just the (bad) luck of the draw.
So, the Fermi paradox has been solved, right? Well, yes and no. Once we draw a set of parameters to use in the Drake equation in one specific universe, for example ours, we are still left with the task of explaining their values. We are no closer to understanding the Great Filter, if any, than before. Is abiogenesis extremely rare? Do ETIs self-destruct quickly? Are there some special circumstances required for life to thrive beyond the planet being in the Goldilocks zone? Is there the singleton effect where the first civilization out of the gate takes over the galaxy? Who knows. SDO concludes that
This result dissolves the Fermi paradox, and in doing so removes any need to invoke speculative mechanisms by which civilizations would inevitably fail to have observable effects upon the universe.
I find that this conclusion does not follow from the main result of the paper. We live in this one universe, and we are stuck with the specific set of values of the factors in the Drake equation that our universe happened to have. It is quite possible that in our universe there is a Great Filter "by which civilizations would inevitably fail to have observable effects upon the universe," because, for example one specific parameter has the value that is many orders of magnitude lower than the estimate, and it would be really useful to know which one and why. The error SDO is making is looking at the distribution of the universes, whereas the Fermi paradox applies to the one we are stuck with. A real resolution of the paradox would be, for example, determining which parameters in the Drake equation are vanishingly low and why, not simply declaring that it is exceedingly likely that a randomly drawn universe has one or several vanishingly small parameters leading to it being very likely bereft of ETIs.
28 comments
Comments sorted by top scores.
comment by Rob Bensinger (RobbBB) · 2018-07-08T23:24:12.281Z · LW(p) · GW(p)
If there's nothing particularly bizarre or inconsistent-seeming about a situation, then I don't think we should call that situation a "paradox". E.g., "How did human language evolve?" is an interesting scientific question, but I wouldn't label it "the language paradox" just because there's lots of uncertainty spread over many different hypotheses.
I think it's fine to say that the "Fermi paradox," in the sense SDO mean, is a less interesting question than "why is the Fermi observation true in our world?". Maybe some other term should be reserved for the latter problem, like "Great Filter problem", "Fermi's question" or "Great Silence problem". ("Great Filter problem" seems like maybe the best candidate, except it might be too linked to the subquestion of how much the Filter lies in our past vs. our future.)
Replies from: Raemon, radford-neal↑ comment by Raemon · 2018-07-09T01:40:11.407Z · LW(p) · GW(p)
I agree with that complaint about use-of-paradox, but AFAICT most things I've heard called paradoxes seemed more like "thing that someone was obviously confused by" rather than anything actually paradoxical. (To the point where I'm not even sure the word would get used if we restricted it's usage thus)
Replies from: Jayson_Virissimo↑ comment by Jayson_Virissimo · 2018-07-09T05:22:31.755Z · LW(p) · GW(p)
Quine categorized paradoxes into veridical (apparently absurd, but actually true), falsidical (seemingly contradictory, because they actually do assume something false or use an invalid step somewhere), and antinomy (self-contradiction from true premises using only valid steps [arguably there are no such things]). I find these categories to be helpful for improving communication about such things.
Replies from: ryan_b↑ comment by Radford Neal (radford-neal) · 2018-07-09T01:12:54.673Z · LW(p) · GW(p)
I agree that the word "Paradox" was some sort of hype. But I don't think anyone believed it. Nobody plugged their best guesses for all the factors in the Drake equation, got the result that there should be millions of advanced alien races in the galaxy, of which we see no sign, and then said "Oh my God! Science, math, and even logic itself are broken!" No. They instead all started putting forward their theories as to which factor was actually much smaller than their initial best guess.
comment by avturchin · 2018-07-09T11:14:50.203Z · LW(p) · GW(p)
The SDO paper ignores Katja Grace's result about SIA doomsday (https://meteuphoric.com/2010/03/23/sia-doomsday-the-filter-is-ahead/), that tell us, in short, that if there are two types of the universes, one where rare Earth is true, and another, where civilizations are common but die because of the Late Great Filter, we are more likely to be in the second type of the Universe.
Grace's argument becomes especially strong if we assume that all variability is because of the pure randomness variation of some parameters because we should find ourselves in the Universe where all parameters are optimised for the creation of many civilizations of our type.
In other words, we should take all parameters in Drake's equation at maximum, not median, as suggested by SDO.
Thus Fermi Paradox is far from being solved.
Replies from: shminux, Gurkenglas↑ comment by Shmi (shminux) · 2018-07-09T16:19:00.502Z · LW(p) · GW(p)
I am not a fan of using the untestable assumptions like SSA or SIA to do anything beyond armchair handwaving, but then again, SDO might be one of those.
Still, SDO used some anthropic approaches to improve their best guess for some parameter distributions. I have not looked at what they did in any detail though.
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2018-07-09T23:41:03.186Z · LW(p) · GW(p)
SSA and SIA aren't exactly untestable. They both make predictions, and can be evaluated according to them, e.g. SIA predicts larger universes. It could be said to predict an infinite universe with probability 1, insofar as it at all works with infinities.
The anthropic bits in their paper looks like SSA, rather than SIA.
Replies from: shminux↑ comment by Shmi (shminux) · 2018-07-10T01:39:02.131Z · LW(p) · GW(p)
I am not sure how one can test SSA or SIA. What kind of experiment would need to be set up, or what data needs to be collected?
Replies from: cousin_it↑ comment by cousin_it · 2018-07-10T07:26:25.474Z · LW(p) · GW(p)
Well, SSA and SIA are statements about subjective probabilities. How do you test a statement about subjective probabilities? Let's try an easier example: "this coin is biased toward heads". You just flip it a few times and see. The more you flip, the more certain you become. So to test SSA vs SIA, we need to flip an "anthropic coin" repeatedly.
What could such an anthropic coin look like? We could set up an event after which, with 1:N odds, N^2 copies of you exist. Otherwise, with N:1 odds, nothing happens and you stay as one copy. Going through this experiment once is guaranteed to give you an N:1 update in favor of either SSA (if you didn't get copied) or SIA (if you got copied). Then we can have everyone coming out of this experiment go through it again and again, keeping all memory of previous iterations. The population of copies will grow fast, but that's okay.
Imagine yourself after a million iterations, finding out that the percentage of times you got copied agrees closely with SIA. You try a thousand more iterations and it still checks out. Would that be evidence for you that SIA is "true" in some sense? For me it would! It's the same as with a regular coin, after seeing a lot of heads you believe that it's either biased toward heads or you're having one hell of a coincidence.
That way of thinking about anthropic updates can be formalized in UDT [LW · GW]: after a few iterations it learns to act as if SSA or SIA were "true". So I'm pretty sure it's right.
Replies from: shminux, Lanrian↑ comment by Shmi (shminux) · 2018-07-10T15:29:17.881Z · LW(p) · GW(p)
We could set up an event after which, with 1:N odds, N^2 copies of you exist.
So that's a pure thought experiment then. There is no actual way to test those As. Besides, in the universe where we are able to copy humans, SSA vs SIA would be the least interesting question to talk about :) I am more interested in "testing" that applies to this universe.
Would that be evidence for you that SIA is "true" in some sense? For me it would!
"For me"? I don't understand. Presumably you mean some kind of objective truth? Not a personal truth? Or do you mean adhering to one of the two is useful for, I don't know, navigating the world?
It would be nice to have an realistic example one could point at and say "Thinking in this way pays rent."
Replies from: cousin_it↑ comment by cousin_it · 2018-07-10T17:07:24.243Z · LW(p) · GW(p)
I don't know, do you like chocolate? If yes, does that fact pay rent? Our preferences about happiness of observers vs. number of observers are part of what needs to be encoded into FAI's utility function. So we need to figure them out, with thought experiments if we have to.
As to objective vs personal truth, I think anthropic probabilities aren't much different from regular probabilities in that sense. Seeing a quantum coin come up heads half the time is the same kind of "personal truth" as getting anthropic evidence in the game I described. Either way there will be many copies of you seeing different things and you need to figure out the weighting.
↑ comment by Lukas Finnveden (Lanrian) · 2018-07-10T21:42:52.256Z · LW(p) · GW(p)
When you repeat this experiment a bunch of times, I think an SSA advocate can choose their reference class to include all iterations of the experiment. This will result in them assigning similar credences as SIA, since a randomly chosen awakening from all iterations of the experiment is likely to be one of the new copies. So the update towards SIA won't be that strong.
This way of choosing the reference class lets SSA avoid a lot of unintuitive results. But it's kind of a symmetric way of avoiding unintuitive results, in that it might work even if the theory is false.
(Which I think it is.)
↑ comment by Gurkenglas · 2018-07-09T14:12:06.760Z · LW(p) · GW(p)
Wouldn't this argument also become convinced of the simulation hypothesis?
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2018-07-09T23:47:32.726Z · LW(p) · GW(p)
Sure, SIA assigns very high probability to us being in a simulation. That conclusions isn't necessarily absurd, though I think anthropic decision theory (https://arxiv.org/abs/1110.6437) with aggregative ethics is a better way to think about it, and yields similar conclusions. Brian Tomasik has an excellent article about the implications https://foundational-research.org/how-the-simulation-argument-dampens-future-fanaticism
Replies from: Gurkenglas↑ comment by Gurkenglas · 2018-07-10T07:06:00.218Z · LW(p) · GW(p)
Wouldn't you *also* fall prey to Pascal's Mugging, assigning ever larger weight to more complicated hypotheses that posit absurd amounts of copies of you? If you are just trying to calculate your best action, you still go for that which the most optimized Mugger asks. Which needn't converge.
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2018-07-10T21:25:34.283Z · LW(p) · GW(p)
I'm not sure. The simplest way that more copies of me could exist is that the universe is larger, which doesn't imply any crazy actions, except possible to bet that the universe is large/infinite. That isn't a huge bullet to bite. From there you could probably get even more weight if you thought that copies of you were more densely distributed, or something like that, but I'm not sure what actions that would imply.
Speculation: The hypothesis that future civilisations spend all their resources simulating copies of you get a large update. However, if you contrast it with the hypothesis that they simulate all possible humans, and your prior probability that they would simulate you is proportional to the number of possible humans (by some principle of indifference), the update is proportional to the prior and is thus overwhelmed by the fact that it seems more interesting to simulate all humans than to simulate one of them over and over again.
Do you have any ideas of weird hypothesis that imply some specific actions?
Replies from: Gurkenglas↑ comment by Gurkenglas · 2018-07-11T14:43:58.274Z · LW(p) · GW(p)
Posit that physics allows a perpetuum mobile and the infinities make the bounded calculation break down and cry, as is common. If we by fiat disregard unbounded hypotheses: Also posit a Doomsday clock beyond the Towers of Hanoi, as specified by when some Turing machine halts. This breaks the calculation unless your complexity penalty assigner is uncomputable, even unspecifiable by possible laws of physics.
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2018-07-11T21:51:03.643Z · LW(p) · GW(p)
Sure, there are lots of ways to break calculations. That's true for any theory that's trying to calculate expected value, though, so I can't see how that's particularly relevant for anthropics, unless we have reason to believe that any of these situations should warrant some special action. Using anthropic decision theory you're not even updating your probabilities based on number of copies, so it really is only calculating expected value.
Replies from: Gurkenglas↑ comment by Gurkenglas · 2018-07-12T12:35:18.253Z · LW(p) · GW(p)
It's not true if potential value is bounded, which makes me sceptical that we should include a potentially unbounded term in how we weight hypotheses when we pick actions.
comment by vsm · 2018-07-09T02:21:02.307Z · LW(p) · GW(p)
"
This result dissolves the Fermi paradox, and in doing so removes any need to invoke speculative mechanisms by which civilizations would inevitably fail to have observable effects upon the universe.
I find that this conclusion does not follow from the main result of the paper .... It is quite possible that in our universe there is a Great Filter "by which civilizations would inevitably fail to have observable effects upon the universe," because, for example one specific parameter has the value that is many orders of magnitude lower than the estimate, and it would be really useful to know which one and why. "
I think you are in fact in agreement with SDOs intended meaning. They are saying there is no need to explain why ETIs are hidden from our observations, as would be the case if we believed the initial interpretation of the Drake equation of there being many ETIs. They are doing away with the 'aliens transcended' or choose not to talk with us class of hypotheses. But their analysis still says some of the factors in the equation must be very low to filter out all the places ETIs could have evolved.
The 'paradox' was 'they should be here, why aren't they?', which is dissolved as the first part is not true. Now it is only a question of the actual values of the Drake equation factors
Replies from: shminux↑ comment by Shmi (shminux) · 2018-07-09T16:03:05.640Z · LW(p) · GW(p)
The 'paradox' was 'they should be here, why aren't they?', which is dissolved as the first part is not true. Now it is only a question of the actual values of the Drake equation factors
Not sure if this paper has more content than "there are so many uncertainties in the factors, the odds of several of them being much smaller than the current best guesses is large enough to make a lifeless universe likely and we are apparently living in one of those". But yes, the "should be here" part goes away if you pay attention to all the uncertainties.
comment by Ofer (ofer) · 2018-07-09T09:59:05.742Z · LW(p) · GW(p)
(I haven't read the entire paper)
I'm confused. I thought the distribution of each factor that is considered in the paper is just subjective probabilities for the possible values of the factor in our universe. Is this not the case?
If the distributions considered are those of some random process that creates new universes - how can one possibly reason over them in any useful way?
Replies from: shminux↑ comment by Shmi (shminux) · 2018-07-09T16:02:05.283Z · LW(p) · GW(p)
We don't know for sure what universe we live in, since we don't have enough information about it. The distribution they construct is over infinitely many possible universes, of which ours is one, just not clear which one. They calculate the odds that our universe has only us and no ETIs, based on this distribution.
comment by cubefox · 2018-07-10T18:21:28.485Z · LW(p) · GW(p)
"One grim suggestion is that there is a Great Filter that is still in front of us"
Is this really the case? As I understand it, the existence of a Great Filter implies that a parameter in the Drake equation has an extremely small value. It could be a parameter which for us is already in the past, e.g. the probability for the development of life. In this case the filter would be behind us. Or is this unlikely because of some anthropic reasoning? In other words, if SDO have shown that the existence of a Great Filter is rather likely, it would require a further argument to show that the filter is more likely in our future than in our past.
Replies from: shminux↑ comment by Shmi (shminux) · 2018-07-11T06:12:46.574Z · LW(p) · GW(p)
Yes, exactly, SDO does not claim anything about the filter beyond that universes with one are very likely, provided we take their probability distribution for the parameters in the Drake equation, so it's not surprising that we might be the only ones in the observable universe. The filter can be anywhere relative to us.
comment by MrFailSauce (patrick-cruce) · 2018-07-09T14:00:24.518Z · LW(p) · GW(p)
What basis is there to assume that the distribution of these variables is log uniform? Why, in the toy example, limit the variables to the interval [0,0.2]? Why not [0,1]?
These choices drive the result.
The problem is, for many of the probabilities, we don’t even know enough about them to say what distribution they might take. You can’t infer a meaningful distribution over variables where your sample size is 1 or 0
Replies from: shminux↑ comment by Shmi (shminux) · 2018-07-09T15:58:38.298Z · LW(p) · GW(p)
The [0, 0.2] was a toy example. They take a fair bit of care to evaluate the distribution of the real factors in the Drake formula, which is what most of the paper is about.