The One and a Half Gemini
post by Zvi · 2024-02-22T13:10:04.725Z · LW · GW · 4 commentsContents
One Million Tokens Mixture of Experts Quality Not Quantity What To Do With It? None 4 comments
Previously: I hit send on The Third Gemini, and within half an hour DeepMind announced Gemini 1.5.
So this covers Gemini 1.5. One million tokens, and we are promised overall Gemini Advanced or GPT-4 levels of performance on Gemini Pro levels of compute.
This post does not cover the issues with Gemini’s image generation, and what it is and is not willing to generate. I am on top of that situation and will get to it soon.
One Million Tokens
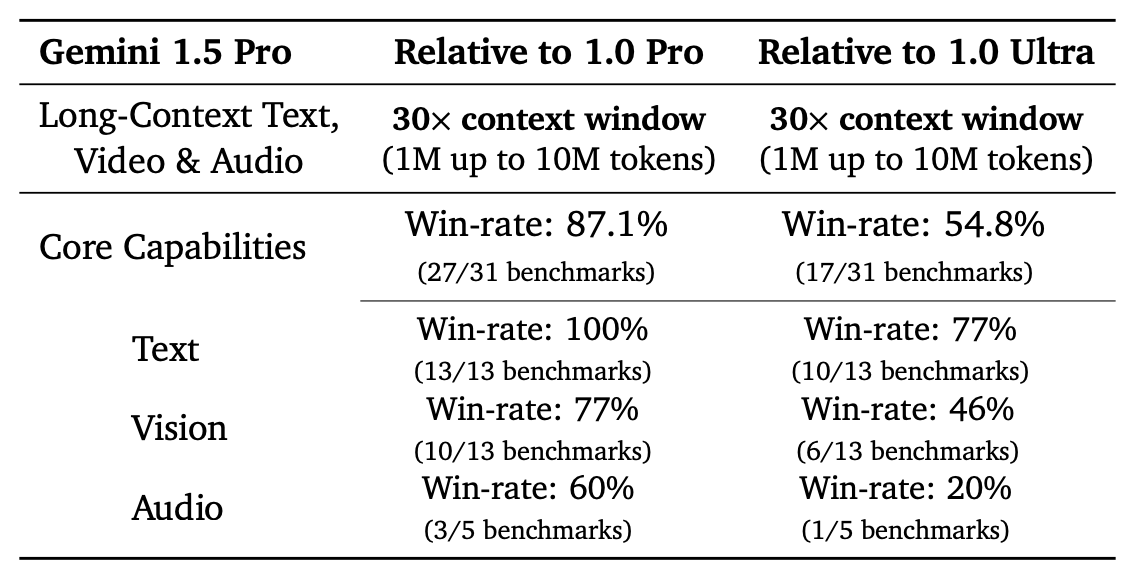
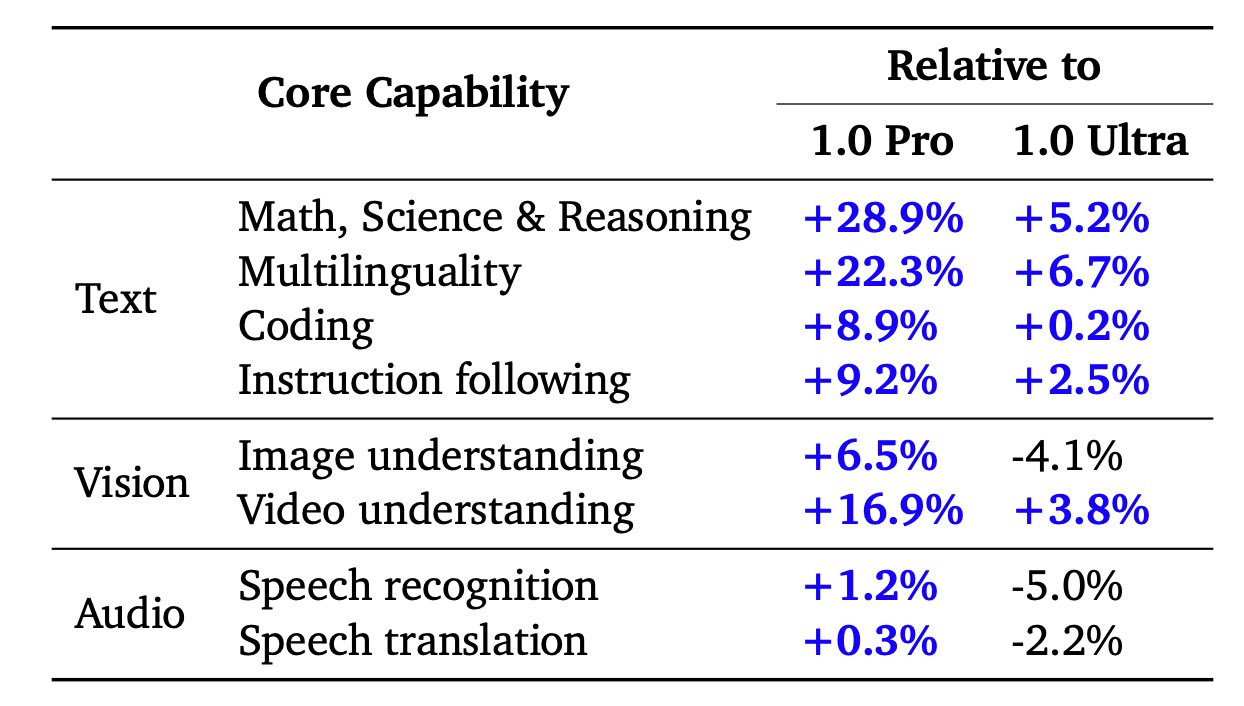
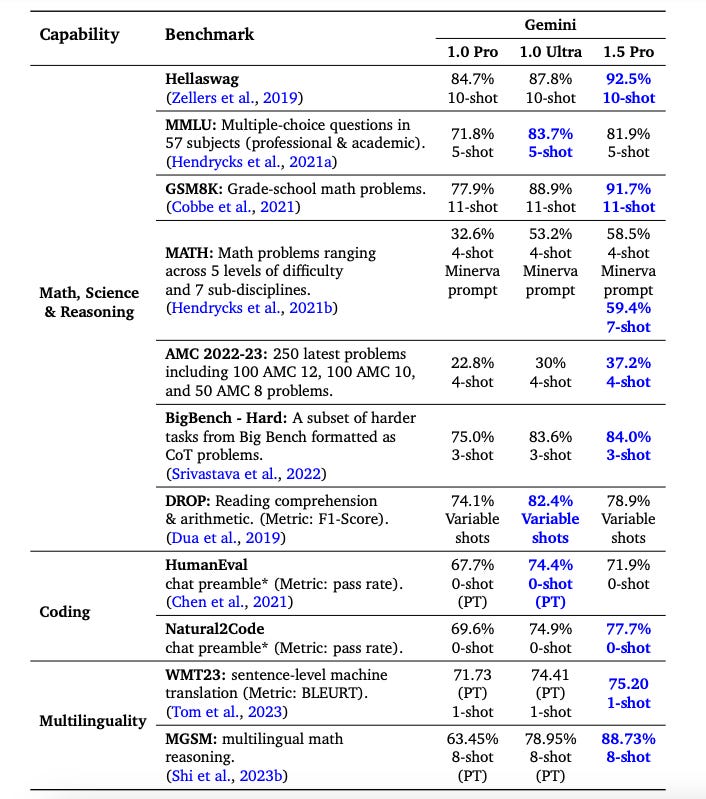
Our teams continue pushing the frontiers of our latest models with safety at the core. They are making rapid progress. In fact, we’re ready to introduce the next generation: Gemini 1.5. It shows dramatic improvements across a number of dimensions and 1.5 Pro achieves comparable quality to 1.0 Ultra, while using less compute.
It is truly bizarre to launch Gemini Advanced as a paid service, and then about a week later announce the new Gemini Pro 1.5 is now about as good as Gemini Advanced. Yes, actually, I do feel the acceleration, hot damn.
And that’s not all!
This new generation also delivers a breakthrough in long-context understanding. We’ve been able to significantly increase the amount of information our models can process — running up to 1 million tokens consistently, achieving the longest context window of any large-scale foundation model yet.
One million is a lot of tokens. That covers every individual document I have ever asked an LLM to examine. That is enough to cover my entire set of AI columns for the entire year, in case I ever need to look something up, presumably Google’s NotebookLM is The Way to do that.
A potential future 10 million would be even more.
Soon Gemini will be able to watch a one hour video or read 700k words, whereas right now if I use the web interface of Gemini Advanced interface all I can upload is a photo.
The standard will be to give people 128k tokens to start, then you can pay for more than that. A million tokens is not cheap inference, even for Google.
Oriol Vinyals (VP of R&D DeepMind): Gemini 1.5 has arrived. Pro 1.5 with 1M tokens available as an experimental feature via AI Studio and Vertex AI in private preview.
Then there’s this: In our research, we tested Gemini 1.5 on up to 2M tokens for audio, 2.8M tokens for video, and
10M


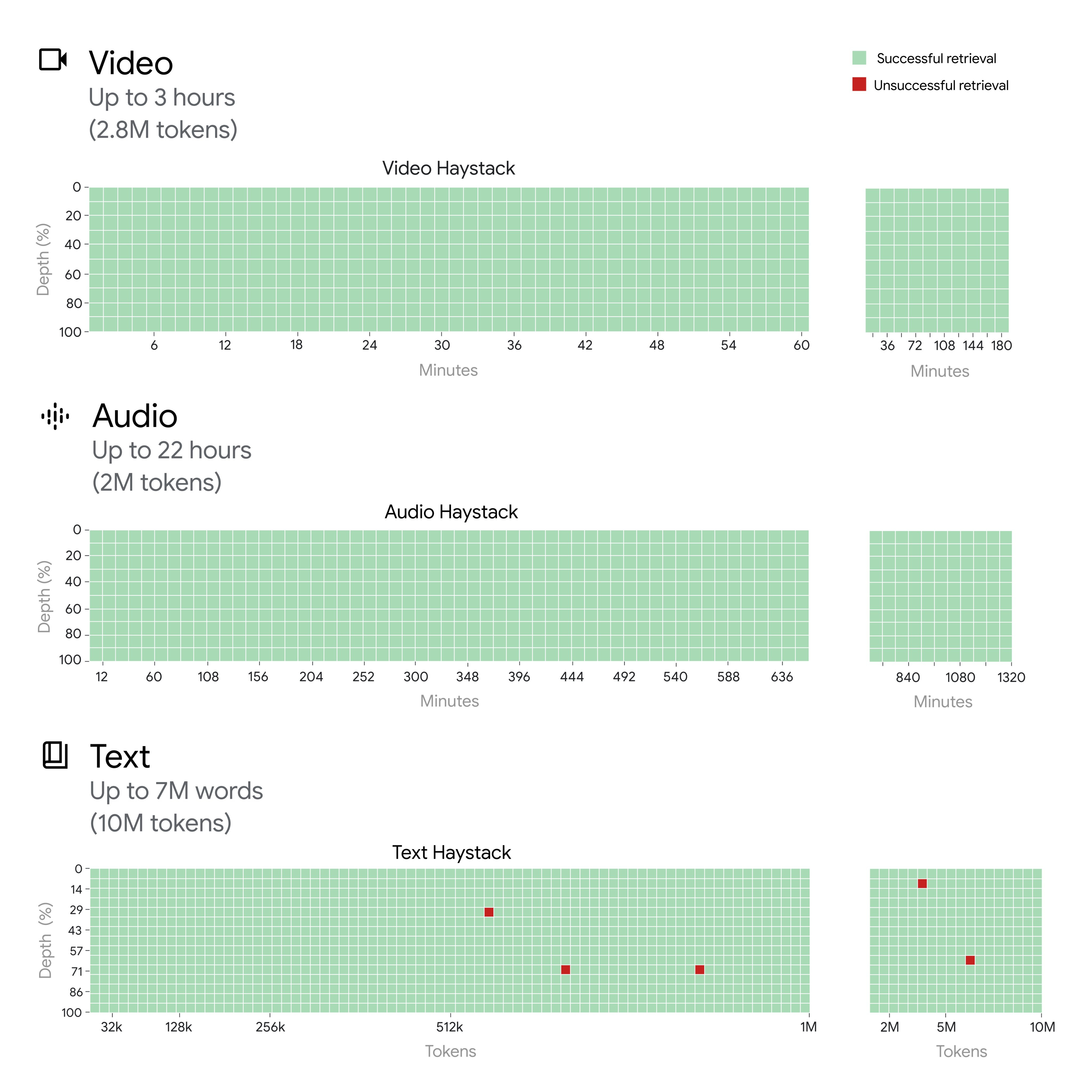
Jeff Dean (Chief Scientist, Google DeepMind): Multineedle in haystack test: We also created a generalized version of the needle in a haystack test, where the model must retrieve 100 different needles hidden in the context window. For this, we see that Gemini 1.5 Pro’s performance is above that of GPT-4 Turbo at small context lengths and remains relatively steady across the entire 1M context window, while the GPT-4 Turbo model drops off more quickly (and cannot go past 128k tokens).
Guido Appenzeller (responding to similar post): Is this really done with a monolithic model? For a 10M token window, input state would be many Gigabytes. Seems crazy expensive to run on today’s hardware.
Sholto Douglas (DeepMind): It would honestly have been difficult to do at decent latency without TPUs (and their interconnect) They’re an under appreciated but critical piece of this story
Here are their head-to-head results with themselves:
Here is the technical report. There is no need to read it, all of this is straightforward. Their safety section says ‘we followed our procedure’ and offers no additional details on methodology. On safety performance, their tests did not seem to offer much insight, scores were similar to Gemini Pro 1.0.
Mixture of Experts
What is their secret to the overall improved performance?
Gemini 1.5 is built upon our leading research on Transformer and MoE architecture. While a traditional Transformer functions as one large neural network, MoE models are divided into smaller “expert” neural networks.
My understanding is that GPT-4 is probably a mixture of experts model as well, although we have no official confirmation.
This all suggests that Google’s underlying Gemini models are indeed better than OpenAI’s GPT-4, except they are playing catch-up with various features and details. As they catch-up in those features and details, they could improve quite rapidly. Combine that with Google integration and TPUs, and they will soon have an advantage, at least until GPT-5 shows up.
They claim understanding and reasoning are greatly improved. They have a video talking about analyzing a Buster Keaton silent movie and identifying a scene.
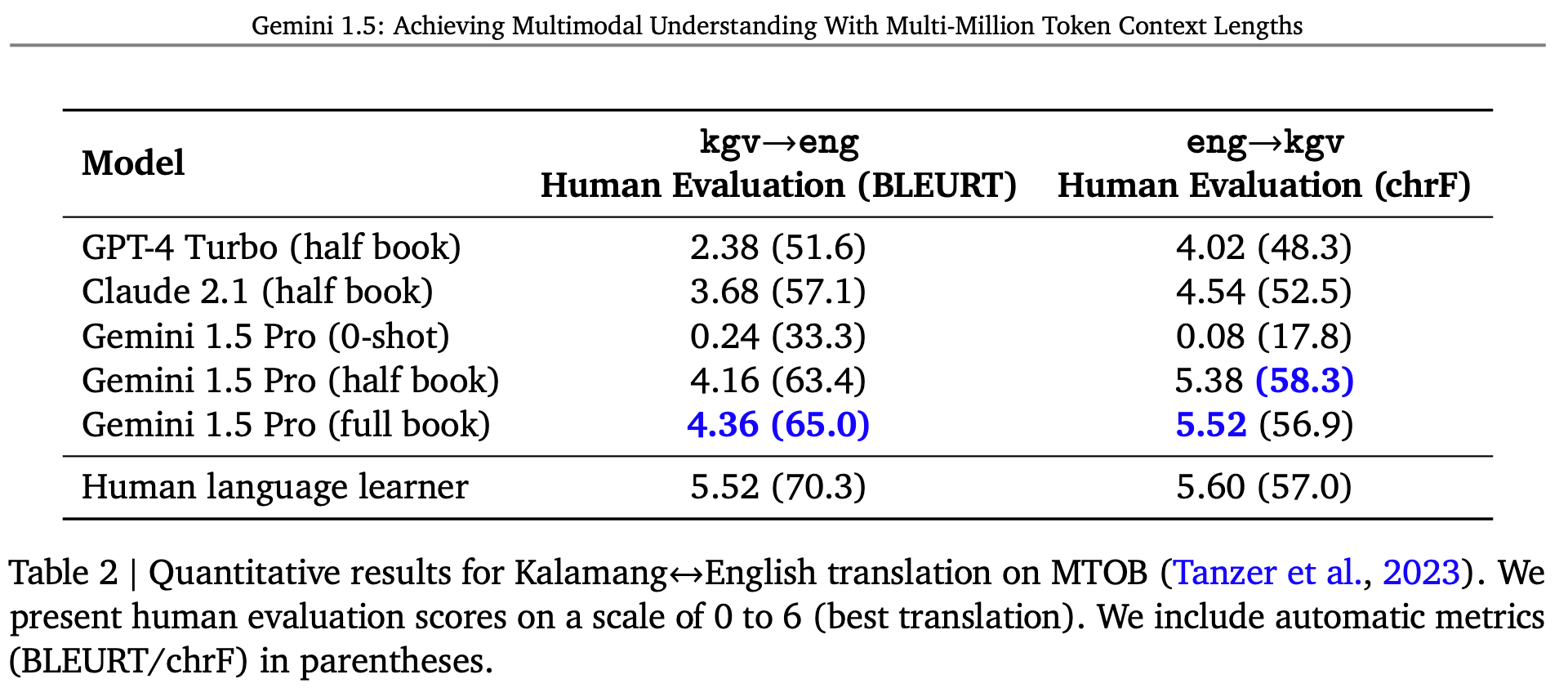
Another thing they are proud of is Kalamang Translation.
Jeff Dean (Chief Scientist, DeepMind): One of the most exciting examples in the report involves translation of Kalamang. Kalamang is a language spoken by fewer than 200 speakers in western New Guinea in the east of Indonesian Papua. Kalamang has almost no online presence. Machine Translation from One Book is a recently introduced benchmark evaluating the ability of a learning system to learn to translate Kalamang from just a single book.
Eline Visser wrote a 573 page book “A Grammar of Kalamang.”
Thank you, Eline! The text of this book is used in the MTOB benchmark. With this book and a simple bilingual wordlist (dictionary) provided in context, Gemini 1.5 Pro can learn to translate from English to/from Kalamang. Without the Kalamang materials in context, the 1.5 Pro model produces almost random translations. However, with the materials in the context window, Gemini Pro 1.5 is able to use in-context learning about Kalamang, and we find that the quality of its translations is comparable to that of a person who has learned from the same materials. With a ChrF of 58.3 for English->Kalamang translation, Gemini Pro 1.5 improves substantially over the best model score of 45.8 ChrF and also slightly exceeds the human baseline of 57.0 ChrF reported in the MTOB paper.
The possibilities for significantly improving translation for very low resource languages are quite exciting!
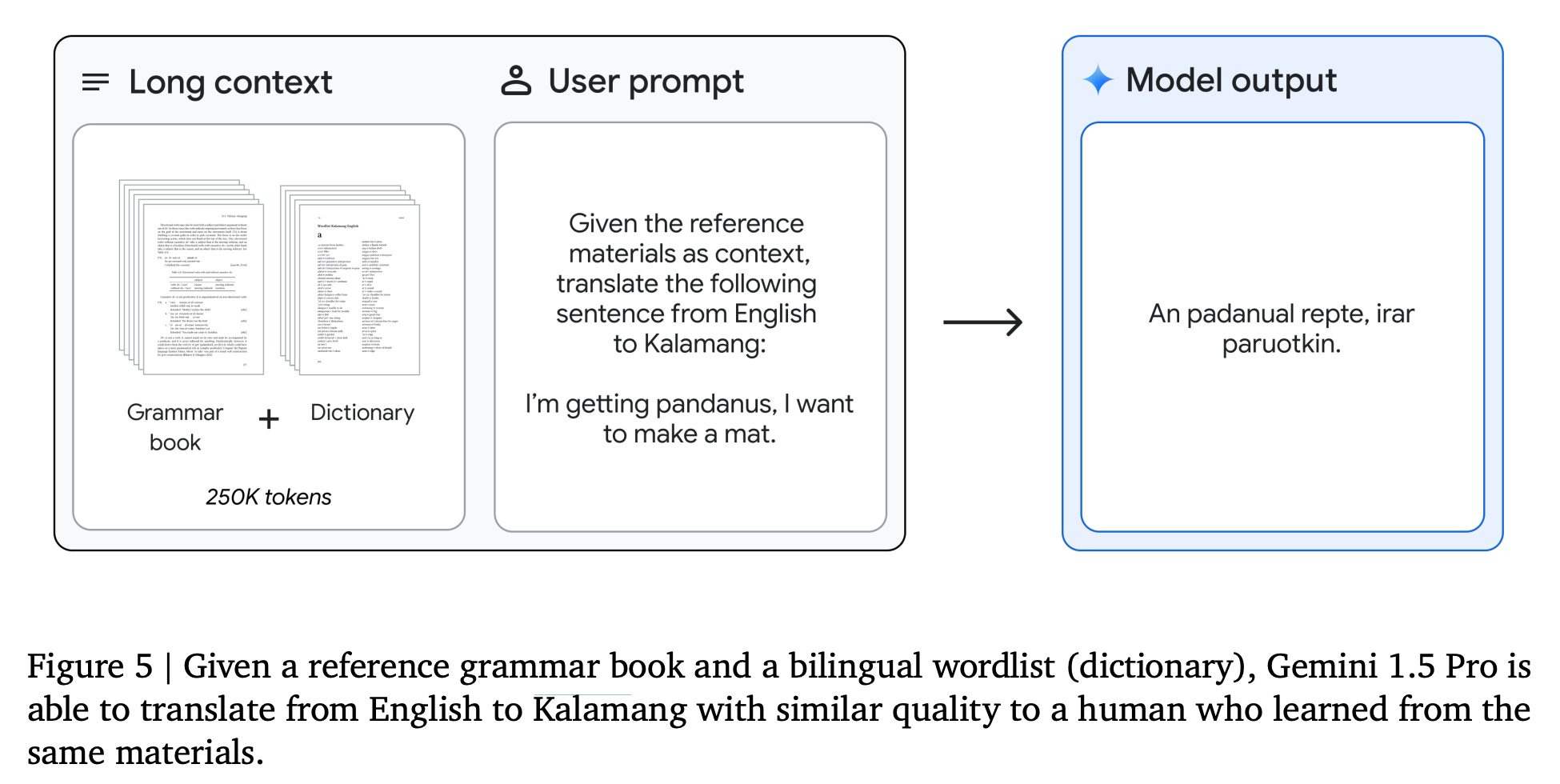
Overall they claim that Gemini Pro 1.5 is broadly similar in performance level to Gemini Ultra 1.0. Except presumably for the giant context window.
Something else I noticed as well:
Max Woolf: I am finally looking at the demo for Gemini 1.5 Pro and they have the generation temperature set at 2.
Quality Not Quantity
In practice how good is it?
I’ve had access to it this week, but didn’t do enough queries to be confident yet.
So far, from what I have seen? It is quite good. Others mostly agree.
Sully Omar is impressed: Been testing Gemini 1.5 pro and I’m really impressed so far Recall has been outstanding, and its really good at following instructions even with > 200k tokens. oh and agents just got a lot better. the only missing piece is really latency + cost.
Oriol Vinyals (DeepMind) Latency is coming (down)
Sully Omar: lfg.

The caveat on that one, of course, is that while this very much seems like an honest opinion, I saw this because it was retweeted by Demis Hassabis. So there might be some favorable selection there. Just a bit.
Sully also reported that he put an entire GitHub codebase in, and Gemini 1.5 identified the most urgent issue and implemented a fix. This use case seems like a big deal, if the related skills can handle it.
Ethan Mollick is more objective. He gave Gemini 1.5 the rulebook for the over-the-top 60 Years in Space, and it was the first AI to successfully figure out how to roll up a character.
He then uploads The Great Gatsby with two anachronisms. GPT-4 fails to find them, Claude finds them but also hallucinates, Gemini 1.5 finds them and also finds a third highly plausible one (the ‘Swastika Holding Company’) that was in the original text.
Then he uploaded his entire academic works all at once, and got highly accurate summaries with no major hallucinations.
Finally, he turns on screen video, which he notes could be real time, and has Gemini analyze what he did, look for inefficiencies and generate a full presentation.
Ethan Mollick: I now understand more viscerally why multimodal was such a critical goal for the big AI labs. It frees AI from the chatbot interface and lets it interact with the world in a natural way. Even if models don’t get better (they will) this is going to have some very big impacts.
Paige Bailey similarly records a screen capture of her looking for an apartment on Zillow, and it generates Selenium code to replicate the task (she says it didn’t quite work out of the box was 85%-90% of the way there), including finding a parameter she hadn’t realized she had set. The prompt was to upload the video and say: “This is a screen recording of me completing a task on my laptop. Could you please write Selenium code that would accomplish the same task?”
Simon Willison took a seven second video of his bookshelf and got a JSON array of all the books, albeit with one hallucination and one dumb initial refusal for the word ‘cocktail.’ The filters on Gemini are really something, but often you can get past them if you insist what you are doing is fine. He also reports good image analysis results.
Mckay Wrigley says it got multiple extremely specific biology questions right from a 500k token textbook. As one would expect some people are calling this ‘glorified search’ or saying ‘Ctrl+F’ and, well, no. We are not the same. There are many situations in which traditional search will not work at all, or be painfully slow. Doing it one-shot with a simple request is a sea change if it reliably works.
Here are two sides of the coin. Matt Shumer is impressed that Gemini 1.5 was able to watch a long video and summarize it within only a minute, and others are unimpressed because of key omissions and the very large mistake that the summary gets the final outcome wrong.
I think both interpretations are right. The summary is impressive in some ways, and also unimpressively full of important errors. Other summaries of other things were mostly much better at avoiding such errors. This was actually a relative underperformance.
What To Do With It?
There are three big changes coming.
We are getting much larger context windows, we are getting GPT-4 level inference at GPT-3.5 level costs, and Google is poised to have a clearly superior free-level offering to OpenAI.
So far, due to various other shiny objects, people are sleeping on all of them.
Assuming Gemini 1.5 becomes Google’s free offering, that suddenly becomes the default. I prefer Gemini Advanced to GPT-4 for most text queries, but I prefer DALLE-3 by far to Gemini for images and there are complications and other features. Google also has wide reach to offer its products. We should expect them to grab a lot of market share on the free side.
Next up is the ability of other services to use Gemini 1.5 via the API. Right now, essentially every application that has to produce inference at scale is using GPT-3.5 or an open weights model that offers at best similar performance. We only got GPT-4-level responses in bespoke situations. Lots of studies used GPT-3.5. That random chatbot with a character was no better than GPT-3.5. Most people’s idea of ‘what is a chatbot’ were 3.5 rather than 4.
Then there is the gigantic new context window. It is a bigger jump than it looks. Right now, we have large context windows, but if you use anything close to the full window, recall levels suffer. You want to stay well clear of the limit. It is good and right for companies to let you push that envelope if you want, but you also should mostly avoid pushing it.
Whereas Gemini 1.5 seems much better at recall over very large context windows. You really can use at least a lot of the million tokens.
Sully: The more i use gemini 1.5 the more I’m convinced long context models is where the magic of ai is going to continue to happen. It genuinely feels magical at this point. Easily 10x in productivity when its faster something about how it understands all the context, feel different.
So much value is in ‘this just works’ and ‘I do not have to explain this.’ If you make the request easy to make, by allowing context to be provided ‘for free’ via dumping tons of stuff on the model including video and screen captures, you are in all sorts of new business.
What happens when context is no longer that which is scarce?
There are also a lot of use cases that did not make sense before, and do make sense now. I suspect this includes being able to use the documents as a form of training data and general guidance much more effectively. Another use case is simply ‘feed it my entire corpus of writing,’ or other similar things. Or you can directly feed in video. Once the available UI gets good things are going to get very interesting. That goes double when you consider the integration with Google’s other services, including GMail and Google Drive.
There was a lot of shiny happening this week. We had Sora, then GPT-4 went crazy and Gemini’s image generator had some rather embarrassing issues. It is easy to lose the thread.
I still think this is the thread.
4 comments
Comments sorted by top scores.
comment by Anders Lindström (anders-lindstroem) · 2024-02-22T14:31:39.395Z · LW(p) · GW(p)
Imagine having a context window that fits something like PubMed or even The Pile (but that's a bit into the future...), what would you be able to find in there that no one could see using traditional literature review methods? I guess that today a company like Google could scale up this tech and build a special purpose supercomputer that could handle a 100-1000 millions token context window if they wanted, or perhaps they already have one for internal research? its "just" 10x+ of what they said they have experimented with, with no mentions of any special purpose built tech.
comment by Gunnar_Zarncke · 2024-02-22T13:49:49.383Z · LW(p) · GW(p)
What are these video tokens? In all examples I have seen it seems to be about 260 tokens per second. While text tokens capture the information losslessly, these video tokens must do something else unless they are very big.
Replies from: nathan-simons↑ comment by Nathan Simons (nathan-simons) · 2024-02-22T21:19:35.742Z · LW(p) · GW(p)
From Simon Willison’s Weblog it seems to be about 260 tokens per frame, where each frame comes from one second of a video, and each of these frames is being processed the same as any image:
it looks like it really does work by breaking down the video into individual frames and processing each one as an image.
And at the end:
The image input was 258 tokens, the total token count after the response was 410 tokens—so 152 tokens for the response from the model. Those image tokens pack in a lot of information!
But these 152 tokens are just the titles and authors of the books. Information about the order, size, colors, textures, etc. of each book and the other objects on the bookshelf are likely (mostly) all extractable by Gemini. Which would mean that image tokens are much more information dense than regular text tokens.
Someone should probably test how well Gemini 1.5 Pro handles lots of images that are just text as well as images that contain varying levels of text density and see if it's as simple as putting your text into an image in order to effectively "extend" Gemini's context window - though likely with a significant drop in performance.
Note: I've added the clarification: "where each frame comes from one second of a video"
I misread the section which quotes the Gemini 1.5 technical report; the paper clearly states, multiple times, the video frames are taken at 1FPS. Presumably, given the simple test that Simon Willison performed, it is a single frame that gets taken from each second and not the entire second of video that gets tokenized.
comment by SashaWu · 2024-02-22T20:04:49.105Z · LW(p) · GW(p)
the ‘Swastika Holding Company’
I think this only looks like an anachronism to a superficial observer. Swastika was a quite fashionable symbol in 1920s and around. Nazis didn't pull it out of Indian tradition on their own. They just appropriated what was already very much present in Western culture.