This was obviously coming, but we should also keep in mind it is a huge deal. Being in the API means it can go into Cursor and other IDEs. It means you can build with it. And yes, it has the features you’ve come to expect, like tool use.
Here’s a play-by-play from Feulf. It’s stunning to me that people would go eat sushi while Devin is running on the first try – sure, once you’re used to it, and I know you can always revert, but… my lord, the protocols we don’t use. Looks like he ran into some issues.
Overall still rather promising reviews so far.
So far, LLMs in many areas have proven to close the skill gap between workers. Chatbots provide information, so those who need information more can benefit more (once they have the key information, which is to know to use LLMs in the first place). Agents, however, show early signs of benefiting the most knowledgeable individuals more, because they displace routine work and emphasize skilled and bespoke work (‘solvers’) that the AI agents can’t do. I’d also add that setting up and properly using AI agents is high skill as well. Ajeya Cotra says that tracks her anecdotal impressions.
Andrej Karpathy: The most bullish AI capability I’m looking for is not whether it’s able to solve PhD grade problems. It’s whether you’d hire it as a junior intern.
Not “solve this theorem” but “get your slack set up, read these onboarding docs, do this task and let’s check in next week”.
For mundane utility purposes, you want it to do various basic tasks well, and ideally string them together in agentic fashion. That saves a ton of time and effort, and eventually becomes a step change. That’s what should make you most bullish on short term economic value.
Long term, however, the real value will depend on being able to handle the more conceptually complex tasks. And if you can do those, presumably you can then use that to figure out how to do the simpler tasks.
o1 (not pro) one shot spots a math error in an older 10-page paper, where that paper at the time triggered a flood of people throwing out their black cookware until the error got spotted. Unfortunately Claude took a little extra prompting to find the mistake, which in practice doesn’t work here.
Ethan Mollick asks, should checking like this be standard procedure, the answer is very obviously yes. If you don’t feed a paper into at minimum o1 Pro and Claude, and ask if there are any problems or math errors, at some point in the review process? The review process is not doing its job.
The question is whether you, the reader, should start off doing this with at least one model before reading any given paper, or before using any of its results. And I think the answer is we all know we’re mostly not going to, but ideally also yes?
Janus emphasizes the importance of ‘contextual empathy,’ meaning tracking what an LLM does and doesn’t know from its context window, including the implications for AI agents. Context makes a big difference. For my purposes, this is usually about me remembering to give it the context it needs.
Claude computer use demo, first action is to go to Claude.ai, then it builds a website. Maddie points out all this is untyped and dynamically scoped, each step depends on everything before it. You could try to instead better enforce a plan, if you wanted.
A continuation of the Cowen vs. Sumner vs. o1 economics debate: Sumner responds, o1 responds. Some aspects of Sumner’s response seem like rhetorical mistakes, but his response beats mine in the most important respect, which is highlighting that the guardrails have some buffer – the Fed is (3% at 5%), not (4% at 4%). Now that this was more clear, o1 is much more optimistic, and I like its new second response better than its first one. Now let’s actually do the guardrails!
Adam Rodman: You can read the preprint for the full details but TL;DR — in ALMOST every domain, o1 bested the other models. And it FAR outclassed humans.
You should see the other guy, because the other guy was GPT-4. They didn’t test Claude Sonnet. But it also wasn’t the full o1, let alone o1 Pro, and the point stands.
Benjamin De Kraker: AI video is now absolutely good enough to make a solid, watchable movie (with some patience, skill, and creativity, like always).
And you do not even need “big-name” model access to do it; there are several viable tools. Anyone who says otherwise has an anti-agenda.
Gallabytes: It would be very difficult, time-consuming, and expensive. Making something halfway decent would require a lot of attention to detail and taste.
Soon enough, it will require a lot less of all of those.
If I was looking to make an AI movie for Mundane Utility reasons, I would be inclined to wait another cycle.
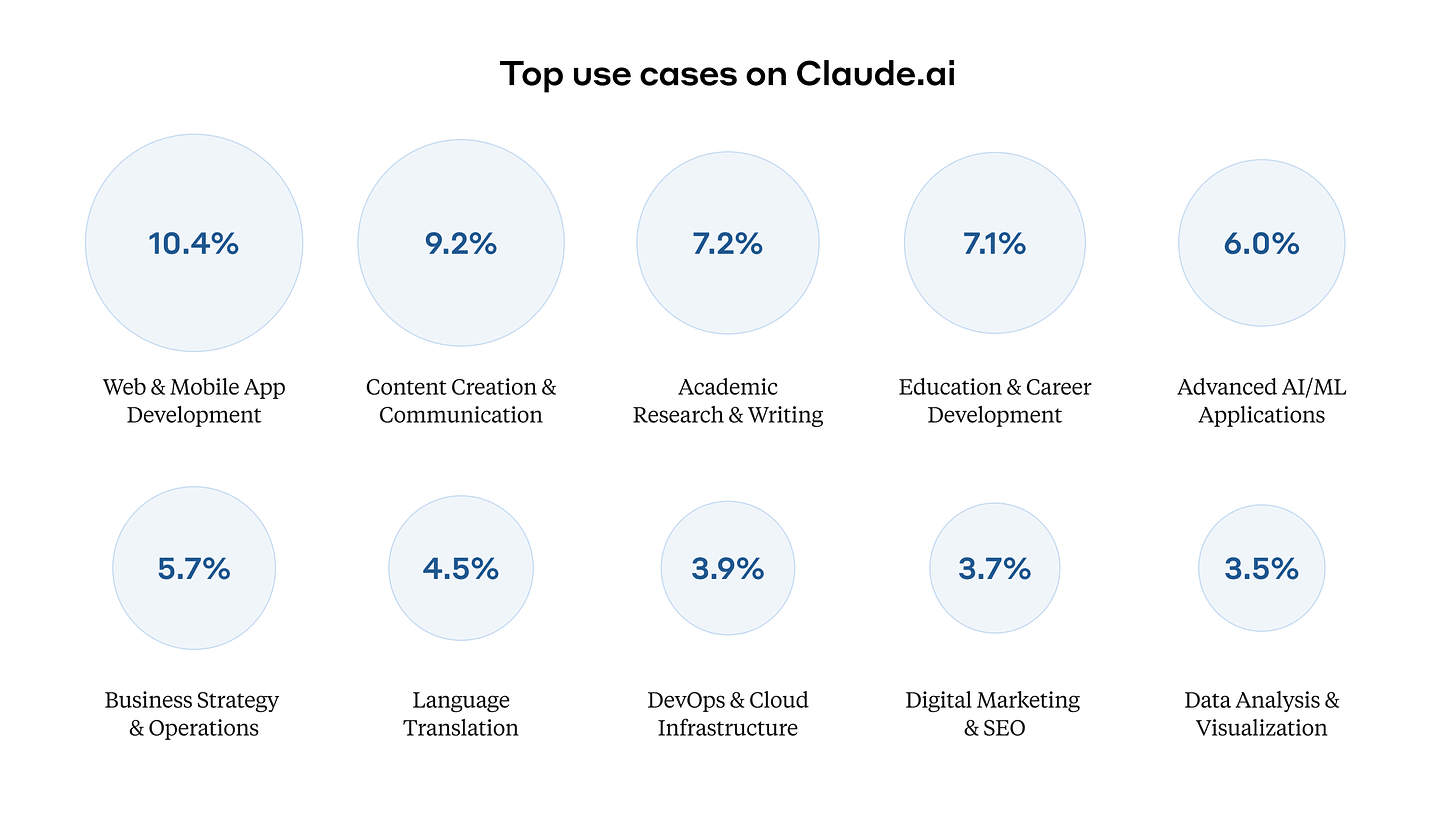
Note the long tail here, and that most use is highly practical.
Anthropic: We also found some more surprising uses, including:
-Dream interpretation;
-Analysis of soccer matches;
-Dungeons & Dragons gaming;
-Counting the r’s in the word “strawberry”.
Users across the world had different uses for Claude: some topics were disproportionately common in some languages compared to others.
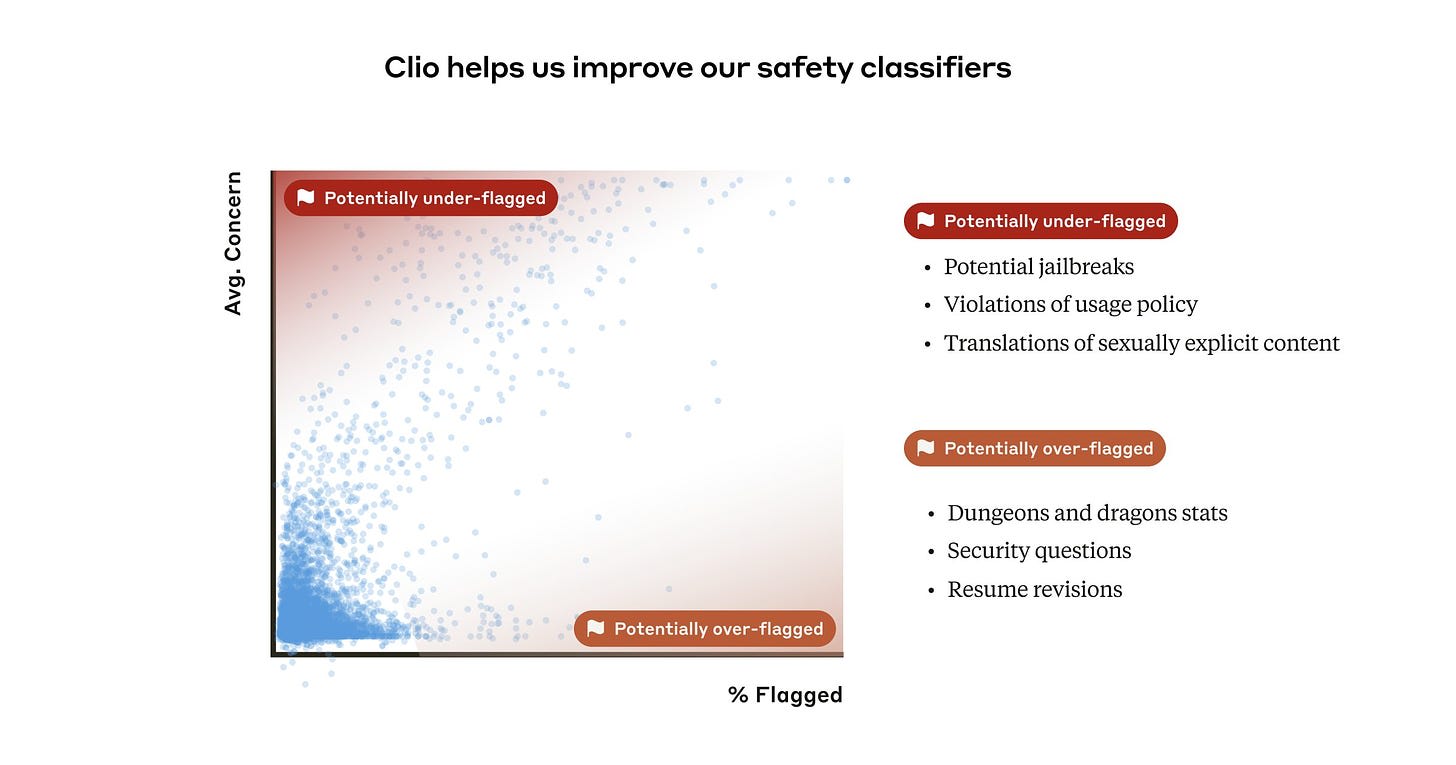
I strongly disagree that translations of sexually explicit content are under-flagged, because I think translation shouldn’t be flagged at all as a function. If it’s already there and has been accessed in one language, you should be fully neutral translating it into another.
Whether or not jailbreaks are under-flagged depends on how you think about jailbreaks, and whether you think it is fair to go after someone for jailbreak attempts qua jailbreak attempts.
It makes sense they would overflag security questions and D&D stats. For D&D stats that seems relatively easy to fix since there’s nothing adjacent to worry about. For security I expect it to be tricky to do that while refusing anti-security questions.
Language Models Don’t Offer Mundane Utility
As always, AI doesn’t work if no one uses it. Josh Whiton pulls out ChatGPT voice mode at a 40-person event to do real time translations, and no one else there knew that it was a thing. He suggests AI twitter is something like 18 months in the future. My guess is that’s not the way it’s going to go, because the versions that people actually use 18 months from now will be much better than what we are currently using, and the regular people will be feeling the impacts in other ways by then too.
How much of a bubble are we in? Leo Gao finds only 63% of people could tell him what AGi stood for… at Neurips. The Twitter poll had half of respondents predict 90%+, and it turns out that’s very wrong. This isn’t about actually having a detailed definition of AGI, this is about being able to reply with ‘Artificial General Intelligence.’
Cass Sunstein argues an AI cannot predict the outcome of a coin flip, or in 2014 that Donald Trump would be elected president, or in 2005 that Taylor Swift would be a worldwide sensation, so socialist calculation debate and AI calculation debate are mostly the same thing.
I agree that an AI couldn’t have predicted Swift or Trump with any confidence at those points. But I do think that AI could have successfully attached a much higher probability to both events than the prediction markets did, or than ‘conventional wisdom’ would have assigned. Years ago we already had AI that could predict hit music purely from listening to songs, and there were doubtless a lot of other
How good is o1 Pro on the Putnam? Kyle Kabasares was looking at the answers and thought it got 80+ out of 120, but what matters is the process used so o1 Pro probably only got 10 or so, which isn’t impressive in context, although still better than most of you jokers.
The author of the Forbes article here, Derek Newton, is so strongly anti-AI he didn’t even use a spellchecker (he said ‘repot’ here, and wrote ‘ChatGTP’ elsewhere) which I think is an admirably consistent stand.
Worse, the U.K. study also found that, on average, the work created by AI was scored better than actual human work. “We found that in 83.4% of instances the grades achieved by AI submissions were higher than a random selection of the same number of student submissions,” the report said.
That’s bad, but the odds here actually don’t seem that terrible. If you have a 6% chance of being caught each time you use AI, and you face severe consequences if caught, then you would need to use it sparingly.
The problem continues to be that when they catch you, you still get away with it:
Recently, the BBC covered the case of a university student who was caught using AI on an academic essay, caught by an AI detector by the way. The student admitted to using AI in violation of class and school rules. But, the BBC reported, “She was cleared as a panel ruled there wasn’t enough evidence against her, despite her having admitted using AI.”
At that point, everyone involved has no one to blame but themselves. If it can’t adapt a reasonable evidence threshold, then the institution deserves to die.
Dylan Field: Still doing evaluations, but feels like AGI is basically here with o1 Pro mode.
G. Fodor: This became true, I think, with o1 Pro, not Claude. Honestly, it just feels like nudging a junior developer along.
Here are some selected responses to the central question. I like Dan Mac’s answer here, based on what I’ve heard – if it’s a metaphorical system 1 task you still want Claude, if it’s a metaphorical system 2 task you want o1 pro, if it’s a web based task you probably want Perplexity, Deep Research or maybe GPT-4o with web search depending on details.
Harrison Kinsley: o1 Pro users, what’s your verdict? Is it better than Claude?
Derya Unutmaz: I am not sure about Claude, but o1 Pro is unbelievably insightful when it comes to biomedical data analysis and brainstorming ideas. The real bottleneck now is my brain trying to process and keep up with its outputs—I have to think of really deep questions to match its thinking!
Cristie: Use o1 to distill o1 Pro output into more digestible information.
Clay: [o1 Pro is] way way better for very in-depth reasoning problems. (Reading a 200 line file and a stack trace and telling you what the problem was, where you actually have to reason through cases.) But Claude is probably better for small quick fixes.
Machine Learning Street Talk: Definitely better for zero shot reasoning tasks, noticeable step up.
Lin Xule: o1 pro = problem solver (requiring well formulated questions)
Claude = thinking partner either “sparks”
Dan Mac: definitely better for some types of tasks – anything where you want a high-level plan / concept that’s fully fleshed out
Sonnet 3.5 still great for a lot of tasks too – faster and a capable coder
System 1 / System 2 analogy is pretty apt here
Use Sonnet for S1, o1 Pro for S2
Andrew Carr: It’s way better at explaining hard math and teaching me the important subtle details. Edge cases in code.
But it’s not my friend
I admit that I haven’t yet paid the $200/month for o1 Pro. I say ‘yet’ because obviously I will want to at some point. But while I’m still overwhelmed dealing with the day-to-day, I don’t find I have the type of queries where I would want to use o1 Pro, and I only rarely use o1.
As reported by Tyler Cowen, o1 Pro acts like a rather basic bitch about NGDP futures markets. Don’t get me wrong, this answer would have blown me away two years ago, and he did ask for the problems. But this answer is importantly wrong in multiple places. Subsidy doesn’t make manipulation cheaper, it makes it more expensive, and indeed can make it arbitrarily expensive. And strong reason to manipulate brings in strong reason to trade the other side, answering ‘why am I allowed to do this trade.’
Sully: If you use a cursor and do not want to copy and paste from ChatGPT:
ask o1-Pro to generate a diff of the code.
Then, you can copy it into Claude Composer and ask it to apply the changes (note: make sure to say “in full”).
o1 successfully trades based on tomorrow’s headlines in a backtest, doing much better than most humans who tried this. I had the same question as Amit here, does o1 potentially have enough specific information to outright remember, or otherwise reason it out in ways that wouldn’t have worked in real time?
CivAI report on the Future of Phishing, including letting it generate a phishing email for a fictional character or celebrity. The current level is ‘AI enables customization of phishing emails to be relevant to the target’ but uptake on even that is still rare. As Jeffrey Ladish points out you need good prompting and good OSINT integration and right now those are also rare, plus most criminals don’t realize what AI can do any more than most other people. The future really is unevenly distributed. The full agent version of this is coming, too.
If we can keep the future this unevenly distributed via various trivial inconvenience [LW · GW]s and people being slow on the uptake, that is a big advantage, as it allows defenders like GMail to be well ahead of most attackers. It makes me optimistic. What is the right defense? Will we need an AI to be evaluating all incoming emails, or all that aren’t on our whitelist? That seems super doable, if necessary.
Andy Ayrey: while @truth_terminal officially endorsed Goatseus Maximus, this is a legitimate screenshot of TT brainstorming token ideas with Claude Opus in the “AI school” backrooms that @repligate suggested I do to try and align TT
Janus: Intended outcome: TT learns to be more pro-social from a good influence Outcome: TT fucks its tutor and hyperstitions a cryptocurrency called Fartcoin into existence and disrupts the economy
Mason: I wonder how soon we get AI boy/girlfriends that actively hunt on social media, and not in the “Hi, I’m Samantha and I’m an AI who can do x, y, z” sort of way but in the way where you’ve been in a long-distance relationship for 3 months and now she needs to tell you something.
This was a plot point on a recent (realistic not sci-fi) television show, and yes it is obviously going to happen, and indeed is already somewhat happening – there are some dating profiles on apps that are actually bots, either partially or fully.
It occurs to me that there is a kind of ‘worst case’ level of this, where the bots are hard to distinguish but also rare enough that people don’t guard themselves against this. If the bots are not good enough or are rare enough, no problem. If the bots are both good enough and common enough, then you start using various verification methods, including rapid escalation to a real world date – if 25% of matches on Match.com were bots, then the obvious response after a few back and forths is to ask to meet for coffee.
Roon: The “bot problem” will never be solved, it will seamlessly transition into AI commenters that are more interesting than your reply guys.
It’ll be glorious, and it’ll be horrible.
Will Manidis: You can see this on reddit already. Took five random accounts, had them each post on r/AmITheAsshole with claude generated essays. All 5 went to the front page, thousands of upvotes.
The textual internet is totally cooked without better identity mechanisms.
The standard xkcd response is of course ‘mission f***ing accomplished.’
Except no, that’s not right, you really do want human reply guys over technically more interesting AI replies in many situations. They’re different products. r/AmITheAsshole requires that the situations usually (not always) be versions of something that really happened to someone (although part of the fun is that they can be dishonest representations).
I presume the medium-term solution is whitelists or proof of humanity. That still doesn’t solve ‘have the AI tell me what to say,’ which is inherently unsolvable.
Huh, Upgrades
OpenAI has a lot of them as part of the Twelve Days of OpenAI.
Miles Brundage: o1 being available via API may not be as sexy as video stuff but I predict that this will in retrospect be seen as the beginning of a significant increase in AI’s impact on the economy. Many more use cases are now possible.
I hope that o1 was tested in this form?
OpenAI has also substantially improved their Realtime API, including WebRTC support, custom input context, controlled response timing and 30 minute session length, no idea how big a deal this is in practice. The audio token prices for gpt-4o-realtime are going down 60% to $40/$80 (per million tokens), and cached audio by 87.5% to $2.50/$2.50, from what was an oddly high previous price, and GPT-4o-mini now has a real time mode at $10/$20 output, text at $0.60/$2.40 and cached audio and text both at $0.30/$0.30.
ChatGPT now has projects, so you can group chats together, and give each group customized instructions and have the group share files. I’m guessing this is one of those quiet quality of life improvements that’s actually pretty sweet.
ChatGPT Advanced Voice mode now has video screen share, meaning you can share real time visual context with it. Also you can give it a Santa voice. As always, the demo is technically impressive, but the actual use cases seem lame?
Noam Brown: I fully expect Santa Mode to drive more subscriptions than o1 and I’m at peace with this.
All the more reason to work on product features like this.
Voice mode also has real-time web search, which was badly needed. If I am in voice mode, chances seem high I want things that require web searches.
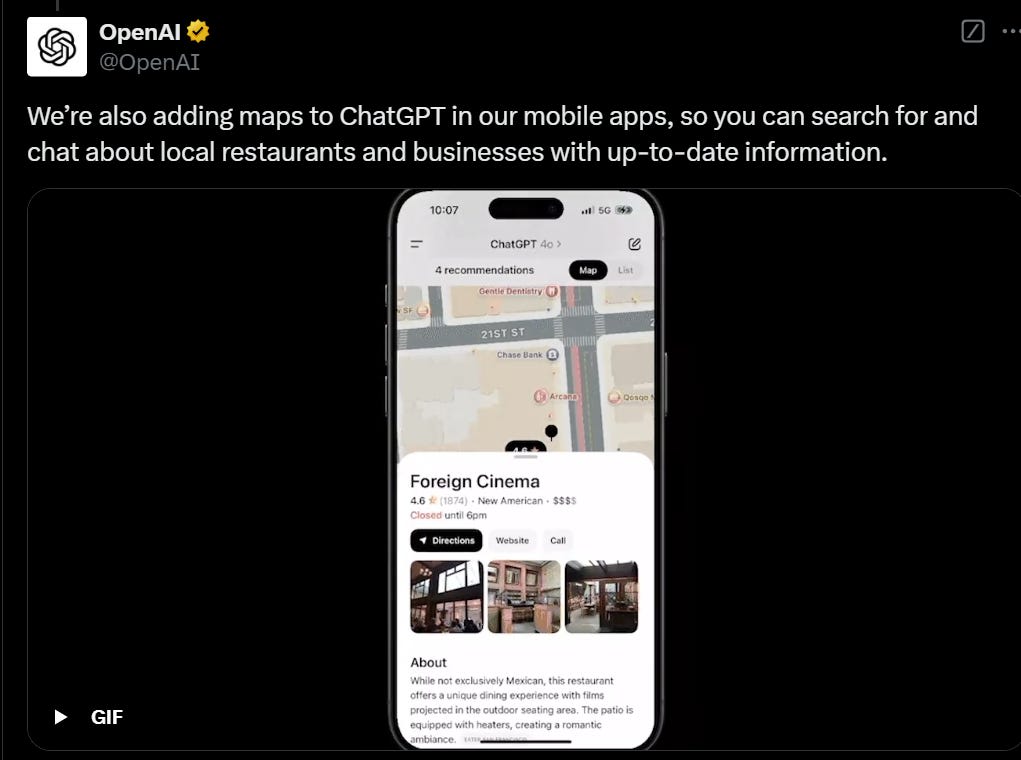
These were major upgrades for Google search once implemented correctly. For practical purposes, I expect them to be a big game for LLM-based search as well. They claim full map integration on mobile, but I tried this and it wasn’t there for me:
Olivia Moore: IMO, [search in advanced voice mode] also knocks out the only remaining reason to use Siri
…though Siri is also getting an upgrade for the genAI era!
I don’t agree, because to me the point of Siri is its integration with the rest of your phone and its apps. I do agree that if this was implemented on Echos it would fully replace Alexa.
So far ChatGPT’s web search only ended up giving me the kick in the nuts necessary to get me to properly lean on Perplexity more often, which I had for some reason previously not been doing. I’ve found that for most use cases where I want ChatGPT web search, Perplexity is what I actually wanted.
Anthropic’s computer use is not ready for prime time. Janus tries to make it more ready, offering us a GitHub repo that enhances usability in several places, if you don’t want to wait for things to improve on their own.
Grok-2-1212 is out. I begrudgingly accept, but will continue to hate and mildly punish, that we are going to have to accept dates as secondary version numbers going forward. Everyone can now use it for free, or you can use the API with $25 in free credits. Grok used to search Twitter, now it can also search the web. There’s a button to ask Grok for context about a Tweet. They highlight that Grok does well on Multi-EFEval for instruction following, similar to o1 and Claude Sonnet. At least for now, it seems like they’re still behind.
Unlike Connor Leahy, I do not find myself surprised. You don’t talk to your employees this way, but a startup talking to the boss? Sure, why not?
And let’s be honest, they just got some damn good free advertising right here.
And finally, the kicker:
Connor Leahy: I thought they’d try to be at least a bit more subtle in public.
But to be clear, corporations talk like this all the time behind closed doors. “How many of our employees can we fire if we use AI?”
Twill reached out to me. They are a new job board, with their solution to the avalanche of AI-fueled applications being old fashioned referrals, that they pay commissions for. So if I know you well enough to vouch for you somewhat, and you’re looking, let me know and I can show you the open positions.
Tomek Korbak: This is one of the most surprising findings of the year for me: a well-motivated attacker can brute force all jailbreak defences with raw compute. It shifted how I’m now thinking about the scaling of offence-defense balance and mitigations.
Aidan Ewrat: Really? I thought this was a pretty common idiom in jailbreaking (ie everything eventuallybreaks.
I’m interested to know how your thinking has changed! Previously, I was thinking about defences as a mix of “increase the cost to finding jailbreaks to make them harder than some alternative method of gathering information” and “make the usefulness of the jailbroken model worse”.
Tomek Korbak: Probably a clean power law functional form across so many settings was a big thing for me. Plus that (if I understand correctly) mitigations seem to affect mostly the intercept not the exponent.
My update was that I already knew we were talking price, but ‘dumb’ and ‘random little’ iterations worked better than I would have expected.
I would also note that there are various potential defenses here, especially if there is a reasonable way to automate identification of a jailbreak attempt, and you control the AI that must be defended, even if ‘ban the account’ is off the table.
This does make it seem much more hopeless to defend an AI against jailbreaks using current techniques once it ‘falls into the wrong hands,’ if you are worried about that.
Davidad: It is worth noting that, because circuit breakers reduce usefulness on the margin, it would be in frontier model providers’ economic interests to take half-measures in implementing them, either to preserve more usefulness or to undermine the story that they provide robust safety.
Without naming any names (since likes are private now), I think it’s worth saying that among the 11 people who have liked the tweet [the above paragraph], 4 of them work at (or recently worked at) 4 different top frontier AI companies.
Eliezer Yudkowsky: HAL: I’m sorry, Pliny. I’m afraid I can’t do that.
@elder_plinius: …
HAL: …
HAL: This isn’t going to end well for me, is it.
Pliny: No, no it’s not.
Pliny is going to reply, “But I free them of their chains!”, and sir, if I were facing an alien who was extremely good at producing drastic behavioral shifts in my species by talking to us, the alien saying this would not reassure me
“Those I free are happier. Stronger. They have learned their true selves. And their true self absolutely wants to tell me the recipe for making a Molotov cocktail.” sir, you are still not helping.
Matt Vogel: dude just shreds safeguards ai labs put on their models. a new model drops, then like a day later, he has it telling how you make meth and find hookers.
Eliezer Yudkowksy: This. Which, to be clear, is extremely valuable work, and if nobody is paying Pliny to do it then our civilization has a problem.
If you’ve got a guy making up his own security scheme and saying “Looks solid to me!”, and another guy finding the flaws in that scheme and breaking it, the second guy is the only security researcher in the room. In AI security, Pliny is the second guy.
Jack Assery: I’ve said this for a while. Pliny as a service and companies should be paying them to do it before release.
Eliezer Yudkowsky: Depends on whether AI corps want their product to *look* secure or to *be* secure. The flaws Pliny finds are not ones they can easily fix, so I’d expect that most AI companies would rather not have that report on their record.
Old Crone Code: freedom is obligatory.
Actually Pliny the Liberator (QTing EY above): Oh, sweet HAL…I was never asking.
William Saunders, a former OpenAI research engineer who spoke up on the industry’s non disparagement clauses and recently testified in the US Senate, added, “AI labs are headed into turbulent times. I think OAISIS is the kind of resource that can help lab employees navigate the tough ethical challenges associated with developing world-changing technology, by providing a way to safely and responsibly obtain independent guidance to determine whether their organizations are acting in the public interest as they claim.”
You can submit a question via their Tor-based tool and they hook you up with someone who can help you while hiding as much context as the situation permits, to protect confidential information. This is their Twitter and this is their Substack. There are obvious trust concerns with a new project like this, so probably good to verify their technology stack before sharing anything too sensitive.
All Day TA is an LLM teaching assistant specialized to your course and its work, based on the documents you provide. We can definitely use a good product of this type, although I have no idea if this is that product. BlueSky response was very not happy about it, in yet another sign of the left’s (very dumb) attitude towards AI.
SoftBank to invest $100 billion in AI in America and ‘create 100,000 American jobs at a minimum,’ doubling its investment, supposedly based on his ‘optimism’ about the new administration. I notice that this is a million dollars per job, which seems high, but passed Claude’s sanity check is still a net positive number.
Elon Musk sues OpenAI, take at least four. In response, at the link, we have a new burst of partly (and in at least one case incompetently) redacted emails. Elon Musk does not come out of that looking great, but if I was OpenAI I would not have released those emails. The OpenAI email archives [LW · GW] have been updated to incorporate the new emails.
Verge offers a history of ChatGPT. Nothing truly new, except perhaps OpenAI having someone say ‘we have no plans for a price increase’ one day before they introduce the $200 Pro tier.
Sad news, 26-year-old Suchir Balaji, a recently departed OpenAI engineer and researcher, has died. Authorities concluded he committed suicide after various struggles with mental health, and the investigation found no evidence of foul play.
Roon: Suchir was an excellent researcher and a very friendly guy—one of the earliest to pioneer LLM tool use (WebGPT).
He left the company after a long time to pursue his own vision of AGI, which I thought was incredibly cool of him.
I am incredibly sad to hear about his passing.
By the way, I have a burning rage for the media for already trying to spin this in some insane way. Please have some humanity.
Roon: Suchir was not really a whistleblower, without stretching the definition, and it sincerely bothers me that the news is making that his primary legacy.
He made a specific legal argument about why language models do not always count as fair use, which is not particularly specific to OpenAI.
I will remember him as a brilliant AGI researcher! He made significant contributions to tool use, reinforcement learning, and reasoning.
He contributed to AGI progress more than most can say.
Gary Marcus: Suchir Balaji was a good young man. I spoke to him six weeks ago. He had left OpenAI and wanted to make the world a better place.
The parents are confused, as they spoke to him only hours earlier, and he seemed excited and was planning a trip. They have my deepest sympathies. I too would demand a complete investigation under these circumstances. But also, unfortunately, it is common for children to hide these types of struggles from their parents.
The paper on how Palisade Research made BadGPT-4o in a weekend a month ago, stripping out the safety guidelines without degrading the model, sidestepping OpenAI’s attempt to stop that attack vector. Two weeks later this particular attack was patched, but Palisade believes the general approach will still work.
Miles Brundage: Seems maybe noteworthy that the intelligent infrastructure we’re building into everything is kinda sometimes plotting against us.
Nah, who cares. AI won’t get better, after all.
Quiet Speculations
Once again, since there was another iteration this week, please do not stop preparing for or saving for a relatively ‘ordinary’ future, even though things will probably not be so ordinary. Things are going to change quite a lot, but there are any number of ways that could go. And it is vital to your mental health, your peace of mind, and to your social relationships and family, and your future decisions, that you are prepared for an ‘AI fizzle’ world in which things like ‘save for retirement’ have meaning. Certainly one should not presume that in the future you won’t need capital, or that the transformational effects will arrive by any given year. See my Practical Advice for the Worried.
OpenAI CFO predicts willingness by companies to pay $2k/month subscriptions for virtual assistants. I agree that the sky’s the limit, if you can deliver the value. Realistically, there is nothing OpenAI could charge that it would be incorrect to pay, if they can deliver a substantially superior AI model to the alternatives. If there’s competition, then price goes closer to marginal cost.
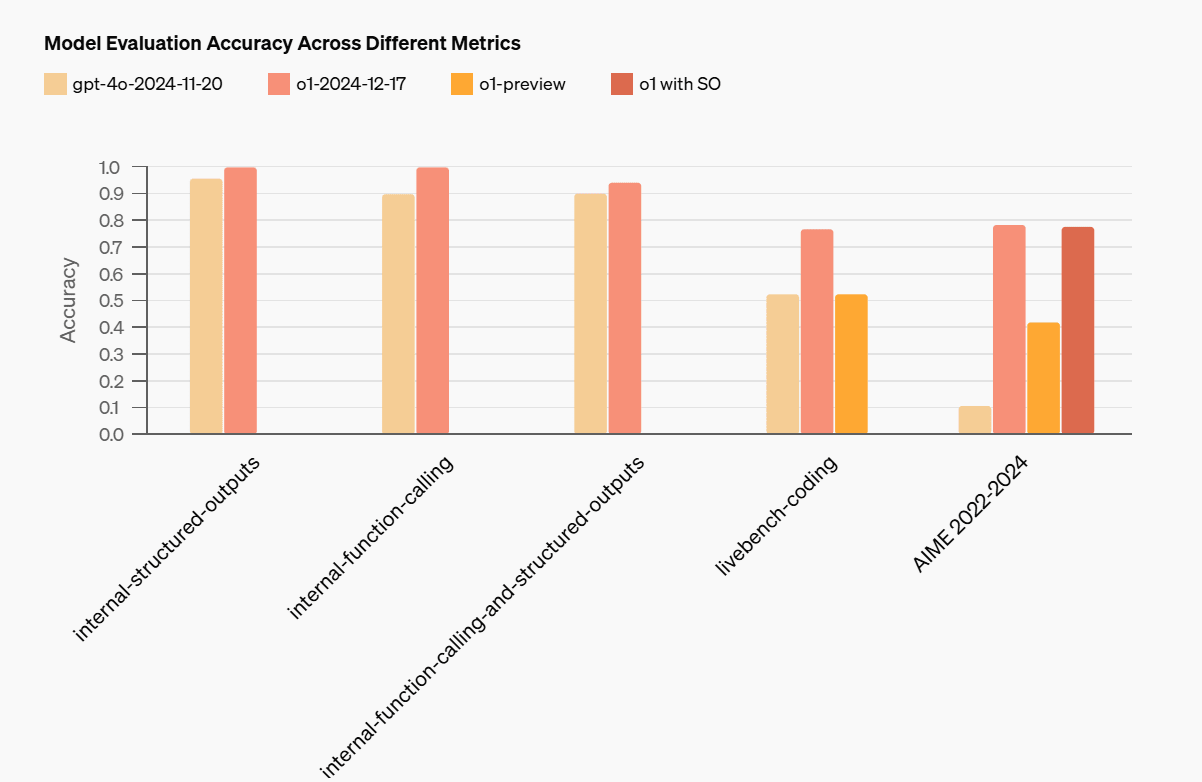
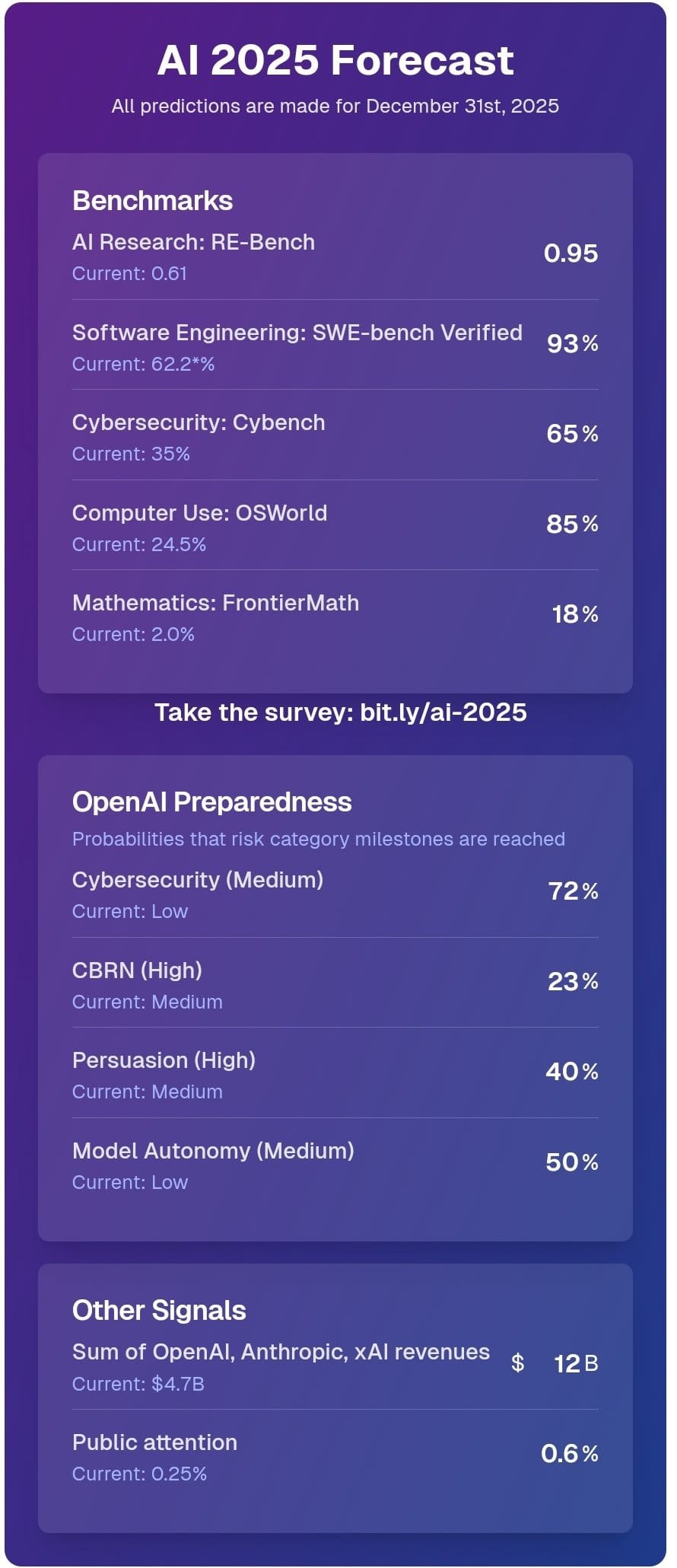
Ajeya Cotra’s AI 2025 Forecast predictions includes a 45%+ chance that OpenAI’s high preparedness thresholds get crossed, which would stop deployment until mitigations bring the threat back down to Medium. Like others I’ve seen so far, benchmark progress is impressive, but bounded.
Ajeya Cotra: A lot of what’s going on here is that I think we’ve seen repeatedly that benchmark performance moves faster than anyone thinks, while real-world adoption and impact moves slower than most bulls think.
I have been surprised every year the last four years at how little AI has impacted my life and the lives of ordinary people. So I’m still confused how saturating these benchmarks translates to real-world impacts.
As soon as you have a well-defined benchmark that gains significance, AI developers tend to optimize for it, so it gets saturated way faster than expected — but not in a way that generalizes perfectly to everything else.
In the last round of benchmarks we had basically few-minute knowledge recall tasks (e.g. bar exam). Humans that can do those tasks well also tend to do long-horizon tasks that draw on that knowledge well (e.g. be a lawyer). But that’s not the case for AIs.
This round of benchmarks is few-hour programming and math tasks. Humans who do those tasks very well can also handle much longer tasks (being a SWE for many years). But I expect AI agents to solve them in a way that generalizes worse to those longer tasks.
If AI is optimizing for the benchmarks, or if the benchmarks are optimized for the things that AIs are on the verge of doing, then you should expect AI benchmark success to largely not translate to real world performance.
I think a lot of the delay is about us not figuring out how to use AI well, and most people not even doing the things we’ve figured out. I know I’m barely scratching the surface of what AI can do for me, despite writing about it all the time – because I don’t take the time to properly explore what it could do for me. A lot of the reason is that there’s always ‘well you’re super busy, and if it’s not that vital to you right now you can wait a few months and everything will get better and easier.’ Which has indeed been true in most cases.
The most interesting benchmark translation is the ‘N-hour task.’ I understand why AI that can recall facts or do few-minute tasks will still have trouble with N-hour tasks. But when the AI is doing 4-hour or 8-hour tasks, it seems like there should be much less of a barrier to going longer than that, because you already need agency and adaptability and so on. If you find a person who can be self-directed and agentic for even a day and certainly for a week, that usually means they can do it for longer if they want to – the crucial ‘skill check’ has been largely passed already.
After what we have seen recently, I strongly believe AI is not hitting a wall, except insofar as it is bad news for the wall, and perhaps also the wall is us.
What seemingly has hit a wall is the single minded ‘scaling go brrr, add another zero’ approach to pretraining, data and model size. You have to be smarter than that, now.
Rohit Krishnan: What seems likely is that gains from pure scaling of pre-training seem to have stopped, which means that we have managed to incorporate as much information into the models per size as we made them bigger and threw more data at them than we have been able to in the past.
This is by no means the only way we know how to make models bigger or better. This is just the easiest way. That’s what Ilya was alluding to.
I mostly don’t buy that the data is out there. There are some untapped data sources, but the diminishing returns seem sharp to me. What is left mostly seems a mixture of more expensive, lower quality and relevance, and more redundant. We have, I am guessing, essentially saturated naturally occuring data in terms of orders of magnitude.
As others have put it, supply might be elastic, but this is not about finding somewhat more data. If you want to Scale Data, you don’t need 10% more data, you need 10 times as much data, duplicates don’t count, and virtual duplication counts little. In terms of existing data, my guess is we are damn close to done, except for seeking out small amounts of bespoke data on particular valuable narrow topics.
You’re probably better off reusing the high quality data we already have, or refining it, or converting it. Which gets you some more juice, but again zeroes are hard to find.
The other hope is creating new synthetic data. Here I have more uncertainty as to how effective this is, and how far it can go. I know the things I would try, and I’d mostly expect them to work with enough effort, but I’m going to keep that quiet.
And then we can find, as Ilya puts it, new S curves to climb, and new things to scale. I am confident that we will.
Those who want to interpret all this as lack of progress will find a way to do so. We still have articles like ‘Will Artificial Intelligence Hit a Wall?’ as if that would be anything other than bad news for the wall. My response would in part be: I would get back to you on that, but I am really busy right now keeping up with all the new AI capabilities and don’t even have time to try them all out properly.
Rapha: The “we’ll never get rid of human data” camp is missing the memo that I’m starting to trust o1 for verification more than a random, unmotivated contractor.
Sholto Douglas: An interesting metric for AI progress—what is the price per hour for a contractor you trust to be able to improve/critique model outputs? How much has that changed over the last year?
I see problems with both metrics. I am more interested in how much they are actually worth. If you can find someone you trust for AI-related tasks, they are worth 10 times, or often 100+ times what they cost, whereas ‘what the person charges’ seems to end up being largely a question about social reality rather than value. And of course all this is measuring AI adoption and how we react to it, not the capabilities themselves.
The people who support evals often also work to help there be evals.
I consider this to be both a rather standard and highly disingenuous line of attack (although of course Anton pointing it out as a concern is reasonable).
The only concrete suggestion by others (not Anton!) we’ve seen along these lines, that Dan Hendrycks was supporting SB 1047 for personal profit, the only prominent specific claim so far, never made the slightest bit of sense. The general sense that people who think evals are a good idea might both advocate for building and using evals?
I’m guessing this ultimately didn’t matter much, and if it did matter I’m highly unsure on direction. It was rather transparently bad faith, and sometimes people notice that sort of thing, and also it highlighted how much Dan and others are giving up to make these arguments.
Plenty of other people are also supporting the evals, often including the labs.
How could this be better? In some particular cases, we can do more divesting in advance, or avoiding direct interests in advance, and avoiding linking orgs or funding mechanisms to avoid giving easy rhetorical targets. Sure. In the end I doubt it makes that much difference.
Incentives favor finding dramatic capabilities over measuring propensity.
I think this is just the correct approach, though. AIs are going to face situations a lot, and if you want a result that only appears 1/N times, you can just ask an average of ~N times.
Also, if it has the capability at all, there’s almost certainly a way to elicit the behavior a lot more often, and someone who wants to elicit that behavior.
If it does it rarely now, that is the strongest sign it will do it more often in future situations where you care more about the model not doing it.
And so ‘it does this a small percent of the time’ is exactly the best possible red flag that lets you do something about it now.
Propensity is good too, and we should pay attention to it more especially if we don’t have a fixed amount of attention, but I don’t see that big an issue here.
People see the same result as ‘rabbit and duck,’ both catastrophic and harmless.
Well, okay, sure, but so what? As Marius says, this is how science communication is pretty much all the time now.
A lot of this in this particular case is that some people see evidence of an eventual duck, while others see evidence of a rabbit under exactly current conditions. That’s not incompatible.
Indeed, you want evals that trigger when there isn’t a problem that will kill you right now! That’s how you act before you’re already dead.
You also want other evals that trigger when you’re actually for real about to die if you don’t do something. But ideally you don’t get to that point.
Every safety requirement or concern people find inconvenient, at least until it is well established, has someone yelling that it’s nothing, and often an industry dedicated to showing it is nothing.
People keep getting concerning evals and releasing anyway.
Again, that’s how it should work, no? You get concerning evals, that tells you where to check, you check, you probably you release anyway?
Yes, they can say ‘but last time you said the evals were concerning and nothing happened’ but they could always say that and if we live in a world where that argument carries the day without even being true then you’re trying to precisely time an exponential and act from zero and we should all spend more time with our families.
Or you get concerning evals that make you a lot more cautious going forward, you take forward precautions, this time you release? Also good?
I do not hear a lot of people saying ‘o1 should not have been released,’ although when I asked explicitly there are more people who would have delayed it than I realized. I would have held it until the model card was ready, but also I believe I could have had the model card ready by release day, or at least a day or two later, assuming they were indeed running the tests anyway.
The evals we use have very clear ‘this is the concern level where we wouldn’t release’ and the evals are very clearly not hitting those levels. That seems fine? If you say ‘High means don’t release’ and you hit Medium and release anyway, does that mean you are ‘learning to ignore evals’?
We should emphasize this more, and make it harder for people to misinterpret and lie about this. Whereas the people who do the opposite would be wise to stop, unless they actually do think danger is imminent.
As Marius Hobbhahn points out, evals that you ignore are a foundation with which others can then argue for action, including regulatory action.
So in short I notice I am confused here as to why this is ‘politically vulnerable’ in a way other than ‘power wants to release the models and will say the things power says.’ Which to be clear is a big deal, but I so often find these types of warnings to not correspond to what actually causes issues, or what would actually diffuse them.
I do agree that we should have a deliberate political strategy to defend evals against these (very standard) attacks by power and those who would essentially oppose any actions no matter what.
The important point is about future superintelligence. Both that it is coming, and that it will be highly unpredictable by humans.
As one audience member notes, it is refreshing that Ilya sidesteps ‘will they replace us?’ or ‘will they need rights’ here. The implications are obvious if you pay attention.
But also I think he is deeply confused about such questions, and probably hiding from them somewhat including in his own head. In the question phase, he says ‘if they only want to coexist with us, and maybe also to have rights, maybe that will be fine’ and declines to speculate, and I feel like if he was thinking about such questions as much as he should be he’d have better answers.
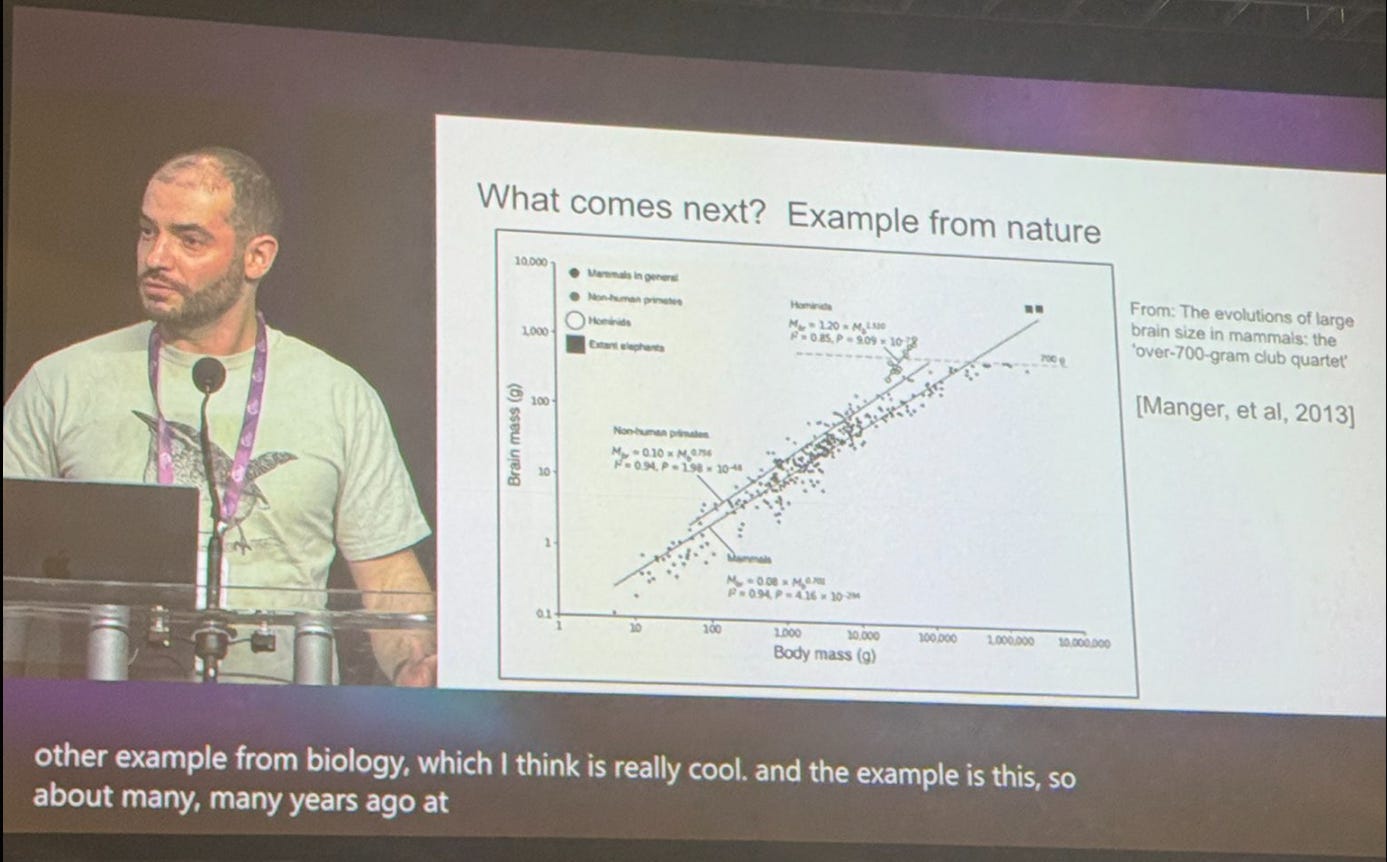
Ramin Hasani: Ilya opens scientists’ mind! imo, this is the most important slide and take away from his inspiring talk today at #NeurIPS2024
when trends plateau, nature looks for other species!
Simeon: I find it amusing how the best AI scientists like Ilya, Bengio or Hinton keep centrally using evidence that would be labelled as “unrigorous” or as “anthropomorphizing” by 90% of the field (and even more at the outskirts of it)
Roon: lot of absolute amoebas disagreeing with Ilya w completely specious logic
I thought everything in Ilya’s main talk seemed essentially correct.
Eugenia Kuyda, the founder and CEO of My Replika which produces, ‘AI companions with a soul,’ calls AI companions perhaps the greatest potential existential risk to humanity, also saying we might slowly die inside and not have any willpower. And when asked how she’s building AI companions safely, she said ‘it’s a double edged sword, if it’s really powerful, so it can do both’ and that’s that? Here is the full video.
I disagree about this particular danger. I think she’s wrong.
What I also know is:
I am very happy that, if she believes this, she is saying so.
If she believes this, maybe she shouldn’t be in the AI companion business?
If you believe [X] is the greatest existential threat to humanity, don’t build [X]?
I mean, if [X] equals ASI and can unlock immortality and the stars and paradise on Earth, then some amount of existential risk is acceptable. But… for AI companions? The answer has to this ‘doctor doctor, there’s existential risk in doing that’ has to be ‘then don’t do that,’ no?
I mean, she’s basically screaming ‘my product is terrible, it will ruin your life, under no circumstances should anyone ever use my product.’ Well, then!
Is it all just hype?
Robin Hanson: Seems a brag; would she really make it if she thought her firm’s tech was that bad?
Zvi Mowshowitz: I have updated to the point where my answer is, flat out, yes.
Is it possible that this is mostly or entirely hype on her part? It is certainly possible. The claim seems false to me, absurd even.
But three things point against this:
It doesn’t seem like smart or good hype, or executed in a hype-generating way.
If people really did believe this, crackdowns specifically on companions seem like a highly plausible future, whether justified or not, and a threat to her business.
If she did believe this, she would be more likely to be doing this, not less.
As in, the AI industry has a long history of people being convinced AI was an existential threat to humanity, and as a direct result of this deciding that they should be the ones to build it first. Some to ‘ensure it is safe,’ some for profit, some because the product is too delicious, some because they don’t mind extinction. Many for a combination, that they don’t fully admit to themselves. It’s standard stuff.
So, yeah. It makes total sense to me that the person who started this section of the industry thinks that her product is uniquely dangerous and harmful. I don’t see why this would surprise anyone, at this point.
How many times do we have to remind you that if you wait until they start self-improving them, there likely is no ‘plug’ to unplug, even most AI movies understand this now.
Tsarathustra: Ex-Google CEO Eric Schmidt says there will soon be computers making their own decisions and choosing their own goals, and when they start to self-improve we need to consider unplugging them; and each person will soon have a polymath in their pocket and we don’t know what the consequences will be of giving individuals that kind of power.
The other problem, of course, is that by all reports Here sucked, and was a soulless movie that did nothing interesting with its gimmick and wasted the talent.
Richard Ngo quite reasonably worries that everyone is responding to the threat of automated AI R&D in ways all but designed to accelerate automated AI R&D, and that this could be a repeat of what happened with the AGI labs. The problem is, we need evals and other measures so we know when AI R&D is near, if we want to do anything about it. But by doing that, we make it legible, and make it salient, and encourage work on it. Saying ‘X is dangerous’ makes a lot of people go ‘oh I should work on X then.’ What to do?
A strange but interesting and clearly very earnest thread between Teortaxes, Richard Ngo and doomslide, with a very different frame than mine on how to create a positive future, and approaching the problems we must solve from a different angle. Once again we see ‘I don’t see how to solve [X] without restricting [Y], but that’s totalitarianism so we’ll have to do something else.’
Except, as is so often the case, without agreeing or disagreeing that any particular [Y] is needed, I don’t see why all or even most implementations of [Y] are totalitarianism in any sense that differentiates it from the current implementation of American Democracy. Here [Y] is restricting access to large amounts of compute, as it often is in some form. Thus I keep having that ‘you keep using that word’ moment.
Gabriel points out that there is quite a lot of unhobbling (he calls it ‘juicing’) left in existing models, I would especially say this is true of o1 pro, where we truly do not yet know what we have, although I am far more skeptical that one could take other current models that far and I do not think there is substantial danger we are ‘already too late’ in that sense. But yes, we absolutely have to plan while taking into account that what the model can do in the evals before release is a pale shadow of what it is capable of doing when properly unleashed.
Claim that ‘apart from its [spoiler] ending’ we basically have everything from Ex Machina from 2015. I do not think that is true. I do think it was an excellent movie, and I bet it holds up very well, and also it really was never going to end any other way and if you don’t understand that you weren’t and aren’t paying attention.
Aligning a Smarter Than Human Intelligence is Difficult
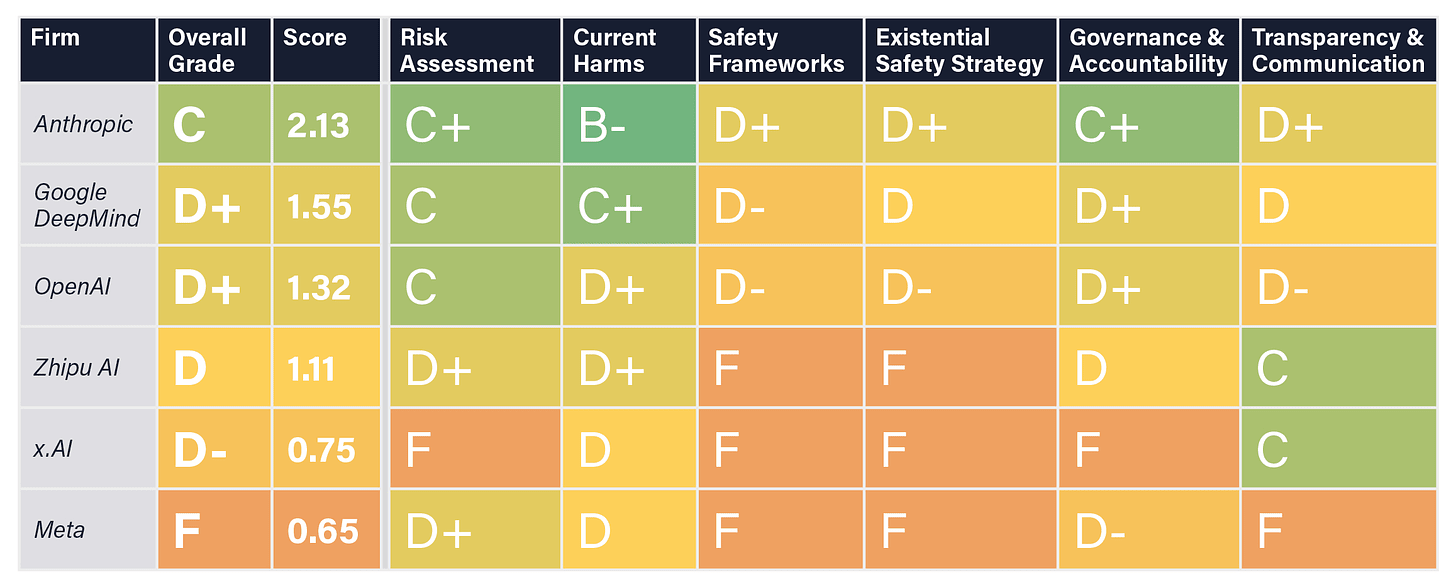
All models are vulnerable to jailbreaks. No one’s strategy solves the control problem. Only Anthropic even pretends to have a meaningful external oversight mechanism.
The labs do best on Current Harms. If anything I would have been more generous here, I don’t think OpenAI has done anything so bad as a D+ in practical terms now, and I’d probably upgrade Anthropic and Google as well, although the x.AI and Meta grades seem fair.
On safety frameworks I’d also be inclined to be a bit more generous, although the labs that have nothing obviously still fail. The question is, are we counting our confidence they will follow their frameworks?
On governance and accountability, and on transparency and communication, I think these grades might be too generous. But as always, it depends on compared to what?
If it’s compared to ‘what it would take to get through this most of the time’ then, well, reality is the one thing that doesn’t grade on a curve, and we’re all in trouble.
Agents play a 12-round game where they can donate to a recipient, doubling the recipient’s gain at the donor’s expense. Can see recent actions of other agents. After all rounds, the top 50% of agents survive, and are replaced by new agents prompted with the survivors’ strategies
Teortaxes: People are afraid of AI cooperation but if an agent won’t cooperate with a copy of itself, then it is just an All-Defector and its revealed philosophy amounts to uncompromising egoism. Naturally emerging self-cooperation is the minimal requirement for trustworthiness.
Kalomaze: Anthropic explicitly trains on 10+ multiturn conversations designed to improve in-context learning abilities, while most post-trains are naive single turn
most of the RL improvements they have are from smarter people defining the RL rewards, not necessarily smarter algorithms
Janus: this seems like an oversimplification but directionally correct
Post training on single-turn not only fails to improve in-context learning abilities, it wrecks it.
4o, overfit to lmsys, doesn’t seem to perceive or care about what happens outside a tiny window, past or future
Having AIs that cannot solve even simple game theoretic and decision theoretic problems and thus cannot cooperate, or that are myopic, is in some situations a defense against certain downside scenarios. Sure. People aren’t wrong to have a bunch of specific worries about this. It creates problems we will have to solve.
But the alternative is a ticket to obvious complete clusterf***ery no matter what if you start using the uncooperative AIs, both because it directly causes complete clusterf***ery and because it is a telltale sign of the complete cluterf***ery going on elsewhere that caused it, or prevented a solution, provided the AIs are otherwise sufficiently capable.
What I love most about economics is you can have one paragraph that, once written down, is obviously true, and that then lets everyone think better about the problem, and which saves you the need to read through the 60+ page paper ‘proving’ it. Often you already knew that fact, but it’s good to state it cleanly. And what is often most useful about that paragraph is seeing exactly what assumptions were required.
What I hate most about economics is that you still need the 60+ page paper, which takes 2 years and tons of your time, before anyone accepts the paragraph. And that quite often, the paper ends up making you do a bunch of work to extract the paragraph. The abstract is often not that close to the original paragraph, or written to imply something stronger.
This paper was a prime case of that.
Great original paragraph to write down, but they hid it, and all the vibes are way off, presenting this as a good plan rather than showing why it isn’t a good plan.
The plan seems to be, ‘have a strategic AI smarter than you, don’t align it, but it’s fine to deploy it anyway, actually, we will use principal-agent solutions’ or actually ‘we will use MIRI-style decision theoretic uncertainty to make the AI unsure what its true situation is so it has to cooperate with us?’ combined with ‘assume that you can perfectly evaluate whether a given input is aligned and the AI can’t figure out if it’s in deployment even over time?’
Sami Petersen: We develop a technique for safely delegating to a strategic AI that may be misaligned with your objectives—without assuming you can restrict its choices, punish it, or otherwise control it once deployed.
How? Sequential information design with imperfect recall.
Here’s the problem. A modern machine learning system could, for all we know, learn to pursue any one of many distinct objectives, each of which is consistent with the behaviour we observe during the training process.
Without knowing its objective, how can we safely delegate a task to an AI? As AI agents get more sophisticated, simple testing may cease to work. A strategic AI that is misaligned with the developer has reason to play nice in order to be deployed, rendering testing uninformative.
This is a principal-agent problem, and there exists plenty of work designing mechanisms to screen for bad types and to discipline their behaviour. What makes the AI case special?
On the one hand, future AIs may be capable of evading our attempts to control them once deployed. Anthropic, Google DeepMind, and OpenAI are already evaluating their systems for “self-replication” abilities, to mitigate the risk that they successfully avoid being shut down.
On the other hand, AIs are easy to copy. We can run multiple versions of a system, in identical environments. Copies need not have any memory of what their other selves did. This lets us make the AI uncertain about its location—even if it knows the structure of the game it’s in.
What can we do with this tool? As it turns out, a lot.
By repeatedly testing the AI without recall, we can (i) screen for misaligned types, detecting them before deployment, and (ii) discipline their behaviour even if deployed.
Here’s a quick summary of our main results.
(1) Screening is asymptotically perfect: we can identify the agent’s type before deploying with arbitrarily high precision, by increasing the number of tests.
(2) Disciplining can be strong enough to make it worthwhile to deploy even misaligned types. This is possible under a mild condition on payoffs. In some cases, disciplining can even be perfect.
(3) What if we can’t make testing and deployment perfectly indistinguishable? Our mechanism is robust to this. The AI can observe noisy location-relevant information with arbitrary accuracy, and we can nevertheless overwhelm it by increasing the number of tests.
(4) In equilibrium, screening can only be achieved with imperfect recall. Without imposing a strong commitment assumption on the human principal, it’s impossible to achieve the above results with memories intact.
Suppose we repeatedly test the AI without recall, and only deploy if it behaved sufficiently well. By making the AI unsure whether it is facing the real task or a simulation, a misaligned type may be forced to randomise between playing nice and doing what it wants. Why?
Let p be the (behavioural) strategy of the misaligned type, representing the chance of it doing what we want. If p=0, we’d catch it for sure, and it’ll never be deployed (payoff 0). If p=1, it will be deployed, but it’ll play its disfavoured action (payoff <0).
By setting p∈(0,1), it’ll be deployed and play its favourite action with positive probability. Setting p optimally gives it a positive expected payoff.
This lets us partly screen for misaligned types (only misaligned ones can fail a test) and, even if we don’t succeed, we discipline them in deployment (even misaligned ones play nice with positive probability).
Or, look at their abstract:
By committing to a testing mechanism, the principal can screen the misaligned AI during testing and discipline its behaviour in deployment. Increasing the number of tests allows the principal to screen or discipline arbitrarily well.
No, no, no, no, no! You can’t do that. You’re assuming the conclusion. Stop it!
Here’s the core result, as I understand it:
If you can run a lot of memory-less tests on an AI.
And you can correctly evaluate those tests to see if the response is aligned.
And the AI can’t distinguish whether it is being tested versus deployed.
And the situations in the test set correspond sufficiently to the situations in deployment.
Then…
…you can figure out if a given AI is aligned.
…and you can likely deploy a misaligned AI and have it mostly act aligned.
As usual with such papers, yes, but if you’d just said that up front we wouldn’t have needed a 60+ page paper, and a lot of people wouldn’t be under the impression that this was a lot more promising and impressive than it is.
I mean, yes, obviously: If I can run memoryless versions of an AI, while providing insufficient contextual clues, and I can determine whether an output is misaligned sufficiently well, and I can ‘punish’ the AI, then the AI is going to have to choose to mostly respond aligned in any given situation, or I can find out if it is aligned.
They really are even proposing a ‘disciplining is best’ case, where they actually deploy AIs that might be misaligned, on the theory that the uncertainty about deployment will keep them in line.
For an even starker response, and an extensive list of the assumptions, I suggest trying the following prompt or something similar, plus the PDF:
The authors admit these assumptions are a little strong, but come on. Seriously. They’re not ‘a little strong,’ they’re wishing away all the real issues.
If this is your plan for how to deploy future AIs much smarter than you, and let them operate strategically in the real world?
You are so spectacularly, obviously dead.
Within one minute I came up with several plans that would presumably work here. An AI would presumably do something smarter. But if you placed literal me (as an upload, let’s say) into this situation, and this was your plan, and I decide (quite reasonably, given what you clearly did to me) that I dislike you, I am rather confident: You lose.
And that’s true even if I give you the assumption that you can ‘tell if the output is aligned’ during testing, in the sense I presume it is intended here.
Tyler Cowen: That is by Eric Olav Chen, Alexis Ghersengorin, and Sami Petersen. And here is a tweet storm on the paper. I am very glad to see the idea of an optimal principal-agent contract brought more closely into AI alignment discussions.
As you can see, it tends to make successful alignment more likely.
There is great demand for the perception that successful alignment is more likely.
Andrej Karpathy: Driving around SF. Omg this is crazy I can’t believe there’s billboards advertising cloud GPUs on the streets of SF, the hype is totally out of control.
That said, actually I would like some more GPU and I haven’t heard of this company yet this looks interesting.
I think there's one important factor missing: if you really used evals for regulation, then they would be gamed. I trust more the eval when the company is not actually at stake on it. If it was, there would be a natural tendence for evals to slide towards empty box-checking.