Constructing Goodhart
post by johnswentworth · 2019-02-03T21:59:53.785Z · LW · GW · 10 commentsContents
10 comments
A recent question from Scott Garrabrant [LW · GW] brought up the issue of formalizing Goodhart’s Law. The problem is to come up with some model system where optimizing for something which is almost-but-not-quite the thing you really want produces worse results than not optimizing at all. Considering how endemic Goodhart’s Law is in the real world, this is surprisingly non-trivial.
Let’s start simple: we have some true objective , and we want to choose x to maximize it. Sadly, we don’t actually have any way to determine the true value for a given value — but we can determine , where is some random function of . People talked about this following Scott’s question, so I won’t math it out here, but the main answer is that more optimization of still improves on average over a wide variety of assumptions. John Maxwell put it nicely in his answer to Scott’s question:
If your proxy consists of something you’re trying to maximize plus unrelated noise that’s roughly constant in magnitude, you’re still best off maximizing the heck out of that proxy, because the very highest value of the proxy will tend to be a point where the noise is high and the thing you’re trying to maximize is also high.
In short: absent some much more substantive assumptions, there is no Goodhart effect.
Rather than generic random functions, I suggest thinking about Goodhart on a causal DAG instead. As an example, I’ll use the old story about soviet nail factories evaluated on number of nails made, and producing huge numbers of tiny useless nails.
We really want to optimize something like the total economic value of nails produced. There’s some complicated causal network leading from the factory’s inputs to the economic value of its outputs (we’ll use a dramatically simplified network as an example).
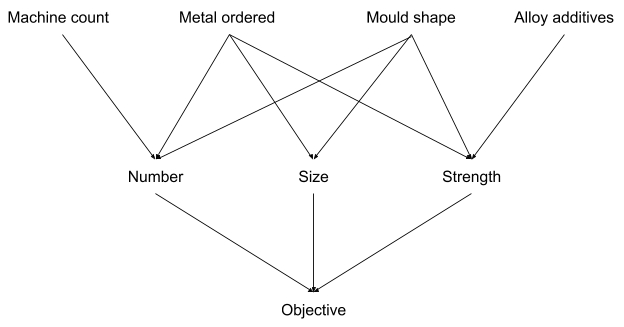
If we pick a specific cross-section of that network, we find that economic value is mediated by number of nails, size, and strength — those variables are enough to determine the objective. All the inputs further up influence the objective by changing number, size, and/or strength of nails.
Now, we choose number of nails as a proxy for the objective. If we were just using this proxy to optimize machine count, that would be fine — machine count only influences our objective via number of nails produced, it doesn’t effect size or strength, so number of nails is a fine proxy for our true objective for the purpose of ordering machines. But mould shape is another matter. Mould shape effects both number and size, so we can use a smaller mold to increase number of nails while decreasing size. If we’re using number as a proxy for the true objective, ignoring size and strength, then that’s going to cause a problem.
Generalizing: we have a complicated causal DAG which determines some output we really want to optimize. We notice that some node in the middle of that DAG is highly predictive of happy outputs, so we optimize for that thing as a proxy. If our proxy were a bottleneck in the DAG — i.e. it’s on every possible path from inputs to output — then that would work just fine. But in practice, there are other nodes in parallel to the proxy which also matter for the output — in our example, size and shape. By optimizing for the proxy, we accept trade-offs which harm nodes in parallel to it, which potentially adds up to net-harmful effect on the output.
So we have a model which can potentially give rise to Goodhart, but will it? If we construct a random DAG, choose a proxy node close to the objective, and optimize for that proxy, we probably won’t see a Goodhart effect (at least not right away). Why not? Well, if we’ve just initialized all the parameters randomly, then whatever change we make to optimize for number of nails is just as likely to improve other sub-objectives as to harm them. For instance, if we’re starting off with a random mould, then it’s just as likely to be too big as too small — if it’s producing giant useless nails, then shrinking the mould improves both number and size of nails.
Of course, in the real world, we probably wouldn’t be starting from a giant useless mould. Goodhart hits in the real world because we’re not just starting from random points, we’re starting from points which have had some optimization already. But we’re not starting from the best possible point — then any change would be bad, proxy optimization or not. Rather, I expect that most real systems are starting from a pareto-optimal point.
Here’s why: look at the cross-section of our causal DAG from earlier. Number, size, strength… in the business world, we’d call these key performance indicators (KPIs) for the factory. If something obviously improves one or more KPIs without any downside, then usually everyone immediately agrees that it should be done. That’s the generalized efficient markets hypothesis, on super-easy mode. Without trade-offs, optimization is trivial. Add trade-offs, and things get contentious: there’s a trade-off between number and size, so the quality assurance department gets into an argument with the sales department about how to handle the trade-off, and some agreement is hammered out which probably isn’t all that optimal.
If we’ve made all the optimizations we can without getting into trade-offs, then we’re at a pareto optimal point: we cannot improve any KPI without harming some other KPI. If we expect those optimizations to be easy and to happen all the time, then we should expect to usually end up at pareto optima.
And if we’re already at a pareto optimum, and we start optimizing for some proxy objective, then we’re definitely going to harm all the other objectives. That’s the whole point of pareto optimality, after all: we can’t improve one thing without trading off against something else. That doesn’t mean that we’ll see net harm to the true objective right away; even if we’re pareto optimal, we could be starting from a point with far too few nails produced. If the factory has a culture of unnecessary perfectionism, then pushing for higher nail count may help. But keep pushing, and we’ll slide down the pareto curve past the optimal point and into unhappy territory. That’s the mark of a Goodhart effect.
10 comments
Comments sorted by top scores.
comment by migueltorrescosta · 2019-02-03T22:37:17.769Z · LW(p) · GW(p)
I think it's possible to build a Goodharts example on a 2D vector space.
Say you get to choose two parameters and . You want to maximize their sum, but you are constrained by . Then the maximum is attained when . Now assume that is hard to measure, so you use as a proxy. Then you move from the optimal point we had above to the worse situation where , but .
The key point being that you are searching for a solution in a manifold inside your vector, but since some dimensions of that vector space are too hard or even impossible to measure, you end up in sub optimal points of your manifold.
In formal terms you have a true utility function based on all the data you have, and a misaligned utility function based on the subspace of known variables , where could be obtained by integrating out the unknown dimensions if we know their probability distribution, or any other technique that might be more suitable.
Would this count as a more substantive assumption?
Best, Miguel
Edit: added the "In formal terms" paragraph
Replies from: johnswentworth↑ comment by johnswentworth · 2019-02-03T22:57:53.003Z · LW(p) · GW(p)
Assuming you mean , optimizing for , and using as the proxy, this is a pretty nice formulation. Then, increasing will improve the objective over most of the space, until we run into the boundary (a.k.a the pareto frontier), and then Goodhart kicks in. That's actually a really clean, simple formulation.
Replies from: migueltorrescosta↑ comment by migueltorrescosta · 2019-02-03T23:28:58.846Z · LW(p) · GW(p)
Note: The LaTeX is not rendering properly on this reply. Does anyone know what the reason could be?
I chose because the optimal point in that case is the set of integers , but the argument holds for any positive real constant, and by using either equality, less than or not greater than.
There is one thing we assumed which is that, given the utility function , our proxy utility function is .This is not necessarily obvious, and even more so if we think of more convoluted utility functions: if our utility was given by , what would be our proxy when we only know ?
To answer this question generally my first thought would be to build a function that maps a vector space , a utility function , the manifold S of possible points and a map from those points to a filtration that tells us the information we have available when at point to a new utility function .
However this full generality seems a lot harder to describe.
Best, Miguel
Replies from: johnswentworth, habryka4↑ comment by johnswentworth · 2019-02-04T00:21:00.082Z · LW(p) · GW(p)
The problem with is that it's not clear why would seem like a good proxy in the first place. With an inequality constraint, has positive correlation with the objective everywhere except the boundary. You get at this idea with knowing only , but I think it's more a property of dimensionality than of objective complexity - even with a complicated objective, it's usually easy to tell how to change a single variable to improve the objective if everything else is held constant.
It's the "held constant" part that really matters - changing one variable while holding all else constant only makes sense in the interior of the set, so it runs into Goodhart-type tradeoffs once you hit the boundary. But you still need the interior in order for the proxy to look good in the first place.
↑ comment by habryka (habryka4) · 2019-02-04T20:14:13.668Z · LW(p) · GW(p)
Fixed the LaTeX for you. You were in WYSIWYG editor mode, where you type LaTeX by pressing CTRL/CMD and 4 at the same time.
Replies from: migueltorrescosta↑ comment by migueltorrescosta · 2019-02-06T06:26:08.697Z · LW(p) · GW(p)
Thank you habryka!
comment by sudhanshu_kasewa · 2019-02-14T12:06:18.921Z · LW(p) · GW(p)
The problem is to come up with some model system where optimizing for something which is almost-but-not-quite the thing you really want produces worse results than not optimizing at all.
I'm confused; maybe the following query is addressed elsewhere but I have yet to come across it:
Doesn't the (standard, statistical machine learning 101) formulation of minimising-training-error-when-we-actually-care-about-minimising-test-error fall squarely in the camp of something that demonstrates Goodhart's law? Aggressively optimising to reduce training error with a function-approximator with parameters >> number of data points (e.g. today's deep neural networks) will result in ~0.0 training error, but it would most likely totally bomb on unseen data. This, to me, appears to be as straightforward an example of a Goodhart's Law as is necessary to illustrate the concept, and serves as a segue into how to mitigate this phenomenon of overfitting, e.g. by validation, regularisation, enforcing sparsity, and so on.
Given the premise that we are likely to start from something close to pareto-optimal to begin with, we now have a system which works well from the get-go, and without suitable controls optimising on reducing training error to the exclusion of all other metrics will almost certainly be worse than not optimising at all.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-02-14T18:37:52.423Z · LW(p) · GW(p)
The problem is that you invoke the idea that it's starting from something close to pareto-optimal. But pareto optimal with respect to what? Pareto optimality implies a multi-objective problem, and it's not clear what those objectives are. That's why we need the whole causality framework: the multiple objectives are internal nodes of the DAG.
The standard description of overfitting does fit into the DAG model, but most of the usual solutions to that problem are specific to overfitting; they don't generalize to Goodhart problems in e.g. management.
Replies from: sudhanshu_kasewa↑ comment by sudhanshu_kasewa · 2019-02-14T22:34:02.926Z · LW(p) · GW(p)
I assumed (close to) pareto-optimality, since the OP suggests that most real systems are starting from this state.
The (immediately disceranable) competing objectives here are training error and test error. Only one can be observed ahead of deployment (much like X in the X+Y example earlier), while it's actually the other which matters. That is not to say that there aren't other currently undiscovered / unstated metrics of interest (training time, designer time, model size, etc.) which may be articulated and optimised for, still leading to a suboptimal result on test error. Indeed, we can imagine a situation with a perfectly good predictive neural network, which for some reason won't run on the new hardware that's provisioned, and so a hasty, over-extended engineer might simply delete entire blocks of it, optimising their time and the ability of the model to fit on a Raspberry PI, while most likely completely voiding any ability of the network to perform the task meaningfully.
If this sounds contrived, forgive me. Perhaps I'm am talking tangentially past the discussion at hand; if so, kindly ignore. Mostly, I only wish to propose that a fundamental formulation of ML, of minimising training loss while we want to reduce test loss, is an example of Goodhart's law in action, and there is rich literature on techniques to circumvent its effects. Do you agree? Why / why not?
comment by Gurkenglas · 2019-02-04T11:08:13.642Z · LW(p) · GW(p)
Can't we just say something like "Optimize e^(-x²). The Taylor series converges, so we can optimize it instead. Use a partial sum as a proxy. Oops, we chose the worst possible value. Should have used another mode of convergence!"?