Parameter count of ML systems through time?
post by Jsevillamol · 2021-04-19T12:54:26.504Z · LW · GW · 3 commentsThis is a question post.
Contents
Answers 6 philip_b None 3 comments
Pablo Villalobos [LW · GW] and I have been working to compile a rough dataset of parameter counts for some notable ML systems through history.
This is hardly the most important metric about the systems (other interesting metrics we would like to understand better are training and inference compute , and dataset size), but it is nonetheless an important one and particularly easy to estimate.
So far we have compiled what it is (to our knowledge) the biggest dataset so far of parameter counts, with over a 100 entries.
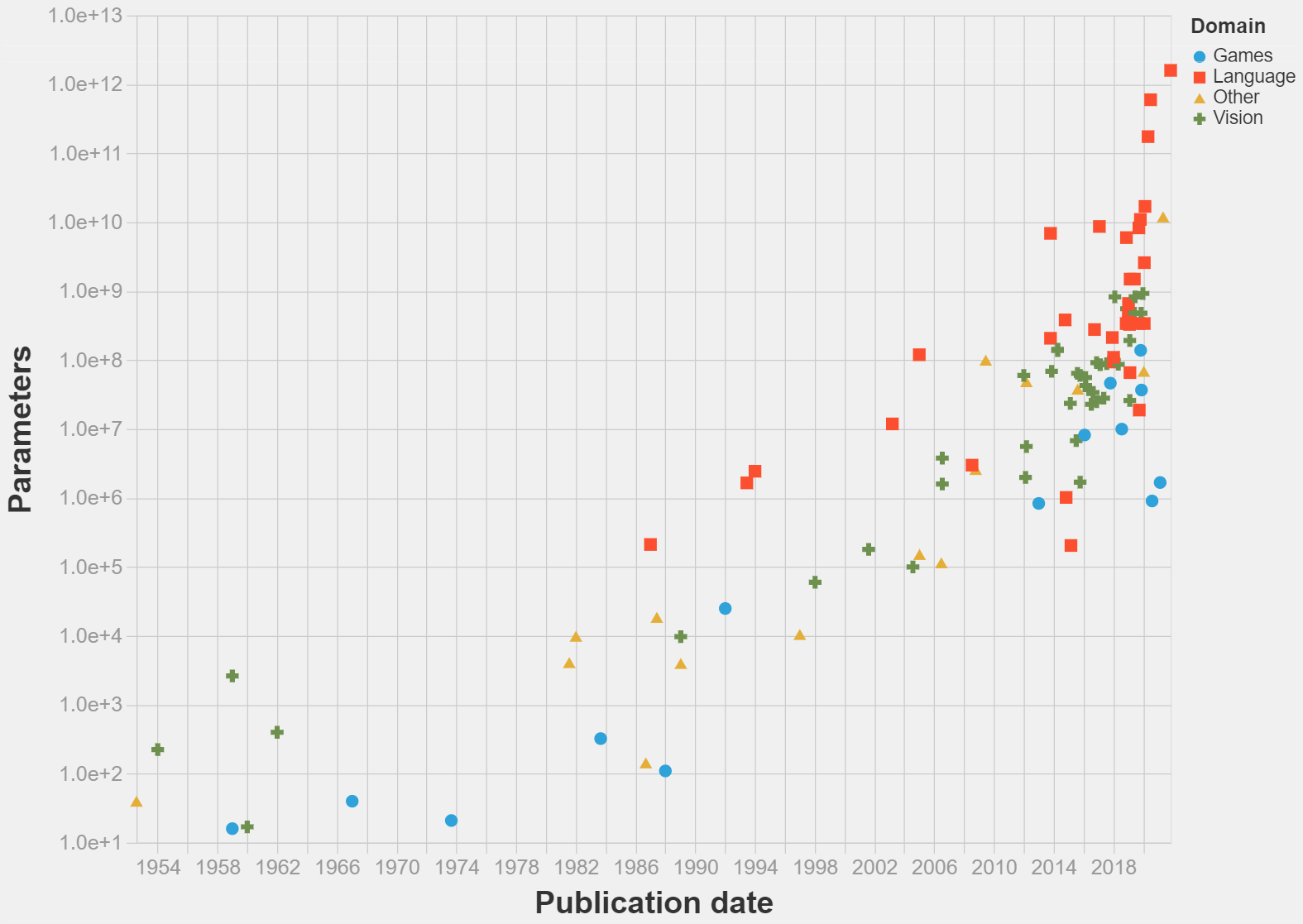
But we could use some help to advance the project:
- Is there any previous relevant work? We are aware of the AI and compute post by OpenAI, and there are some papers with some small tables of parameter counts.
- If you want to contribute with an entry, please do! The key information for an entry is a reference (citation and link), domain (language, vision, games, etc), main task the system was designed to solve, parameter count (explained with references so its easy to double check), and date of publication. The criteria for inclusion is not very well defined at this stage in the process; we have been focusing on notable papers (>1000 citations), significant SOTA improvements (>10% improvement on a metric over previous system) and historical relevance (subjective). We mostly have ML/DL/RL papers, and some statistical learning papers. To submit an entry either leave an answer here, send me a PM, email
jaimesevillamolina at gmail dot comor leave a comment in the spreadsheet. - If you'd be interested in joining the project, shoot me an email. The main commitment is to spend 1h per week curating dataset entries. Our current goal is compiling parameter counts of one system per year between 2000 and 2020 and per main domain. If you can compute the number of parameters of a CNN from its architecture you are qualified. I expect participating will be most useful to people who would enjoy having an excuse to skim through old AI papers.
Thank you to Girish Sastry and Max Daniel for help and discussion so far!
Answers
Since you wrote about OpenAI's "AI and compute", you should take a look at https://www.lesswrong.com/posts/wfpdejMWog4vEDLDg/ai-and-compute-trend-isn-t-predictive-of-what-is-happeningfor [LW · GW].
3 comments
Comments sorted by top scores.
comment by gwern · 2021-04-19T14:07:07.574Z · LW(p) · GW(p)
You should probably also be tracking kind of parameter. I see you have Switch and Gshard in there, but, as you can see in how they are visibly outliers, MoEs (and embeddings) use much weaker 'parameters', as it were, than dense models like GPT-3 or Turing-NLG. Plotting by FLOPS would help correct for this - perhaps we need graphs like training-FLOPS per parameter? That would also help correct for comparisons across methods, like to older architectures such as SVMs. (Unfortunately, this still obscures that the key thing about Transformers is better scaling laws than RNNs or n-grams etc, where the high FLOPS-per-parameter translates into better curves...)
Replies from: Jsevillamol↑ comment by Jsevillamol · 2021-04-19T15:22:29.883Z · LW(p) · GW(p)
Thank you for the feedback, I think what you say makes sense.
I'd be interested in seeing whether we can pin down exactly in what sense are Switch parameters "weaker". Is it because of the lower precision? Model sparsity (is Switch sparse on parameters or just sparsely activated?)?
What do you think, what typology of parameters would make sense / be useful to include?
Replies from: gwern↑ comment by gwern · 2021-04-19T16:36:53.384Z · LW(p) · GW(p)
It's not the numerical precision but the model architecture being sparse such that you only active a few experts at runtime, and only a small fraction of the model runs for each input. It may be 1.3t parameters or whatever, but then at runtime, only, I dunno, 20b parameters actually compute anything. This cheapness of forward passes/inferencing is the big selling point of MoE for training and deployment: that you don't actually ever run 1.3t parameters. But it's hard for parameters which don't run to contribute anything to the final result, whereas in GPT-3, pretty much all of those 175b parameters can participate in each input. It's much clearer if you think about comparing them in terms of FLOPS at runtime, rather than static parameter counts. GShard/Switch is just doing a lot less.
(I also think that the scaling curves and comparisons hint at Switch learning qualitatively worse things, and the modularity encouraging more redundancy and memorization-heavy approaches, which impedes any deeper abstractions or meta-learning-like capabilities that a deep dense model might learn. But this point is much more speculative, and not necessarily something that, say, translation researchers would care too much about.)
This point about runtime also holds for those chonky embeddings people sometimes bring up as examples of 'models with billions of parameters': sure, you may have a text or category embedding which has billions of 'parameters', but for any specific input, only a handful of those parameters actually do anything.