Interviews on Improving the AI Safety Pipeline
post by Chris_Leong · 2021-12-07T12:03:04.420Z · LW · GW · 15 commentsContents
Evan Hubringer (MIRI): Buck Shlegeris (Redwood Research): Someone involved in the Cambridge AGI Safety Fundamentals Course: AI Safety Support - JJ Hepburn: Adam Shimi (Mentor coordinator for AI Safety Camp): Janus (Eleuther): Richard (previously a funded AI Safety researcher): Founder of an Anonymous EA Org: Remmelt (AI Safety Camp): Logan (Funded to research Vanessa's work): Toon (RAISE, now defunct): John Maxwell: Anonymous: Anonymous: Anonymous: Anonymous: None 15 comments
I conducted the following interviews to better understand how we might aim to improve the AI safety pipeline. It is very hard to summarise these interviews as everyone has different ideas of what needs to be done. However, I suppose there is some value in knowing this in and of itself.
A lot of people think that we ought to grow the field more, but this is exactly the kind of proposal that we should definitely not judge based on popularity. Given the number of people trying to break into the field, such a proposal was almost automatically going to be popular. I suppose a more useful takeaway is that a lot of people are currently seriously pursuing proposals to run projects in this space.
I guess another comment I can make is that the people who are most involved in the field seemed quite enthusiastic about the Cambridge AI Safety Fundamentals course as a way of growing the field.
If you think you’d have interesting thoughts to share, please feel free to PM me and we can set up a meeting.
Disclaimers: These interviews definitely aren’t a random sample. Some of the people were just people I wanted to talk to anyway. I was also reluctant to contact really senior people as I didn’t want to waste their time.
I tended towards being inclusive, so the mere fact that I talked to someone or included some of what they shared shouldn’t be taken as an endorsement of their views or of them being any kind of authority.
Evan Hubringer (MIRI):
- Evan is now running a mentorship program with the assistance of SERI to mentor more people that he would be able to mentor himself:
- Participants (14 people) were recruited from the AI Safety Fundamentals Course
- This involves going through a set of shared readings for a few months, summarising and expanding upon a research artifact, then attempting an open research problem
- SERI handled interviews + logistics
- Evan had a 1/2 hour 1-on-1 weekly chat with each participant in the 1st stage & 1 hour weekly chat in the second stage where he cut the number of participants in half
- Evan would like to see other researchers could copy this model to maximise their ability to mentor people:
- Chris’ Note:
- Perhaps Non-Linear could organise something similar under multipliers for existing talent - although I think Evan might try expanding this to other researchers himself
- Suggested that there needs to be a new organisation to house people:
- Why?:
- None of the current places can scale rapidly
- Research focus of MIRI is narrow
- Structure:
- Suggested a mix of remote and in-person
- A comprehensive research agenda limits ability to scale
- Challenges:
- Hardest part is training. People need a model of AI safety and AI:
- Easiest way to get it is to copy it from someone else
- Can’t just read things as you need to be able to poke the model
- Hardest part is training. People need a model of AI safety and AI:
- Why?:
- Suggested that the EA movement has been the most successful way of getting people interested in AI Safety
Buck Shlegeris (Redwood Research):
- Suggested that there need to be more problem sets:
- These can be integrated into the middle of articles
- Greatly impressed by the AGI Safety Fundamentals course - he liked the content and who it attracted
- Running a machine learning bootcamp (details here [LW · GW]):
- Aim is to turn strong python programmers into ML engineers (handling the engineering parts of their research)
- Surprisingly, full-stack web experience can be useful here such as if you’ve learned to handle large volumes of data
- Expects to hire people in the following ratio: 1 researcher, 2 research engineers, 1 infrastructure
Someone involved in the Cambridge AGI Safety Fundamentals Course:
- Fundamentals Course
- Content covers:
- Why AI risk might be particularly concerning. Introducing various research agendas.
- Further course details here [EA · GW]
- Not optimised for getting people a job/internship or for teaching ML
- There is a four week period for projects - but it isn’t optimised for projects
- Content covers:
- Favorable on:
- AI safety camp - valuable to encourage people to pursue their own projects
- Encouraging more professors to become AI safety researchers:
- High value, but extremely difficult
- Not sure whether we can actually achieve this
AI Safety Support - JJ Hepburn:
- Suggests talking to the major orgs - Why aren't they twice as big? Keep following this question:
- Is it structural? FHI being at Oxford
- Suspects that money isn’t the limiting factor
- Keep following the question why they aren't twice as big
- Reviewers have more of a bias towards avoiding false positives than false negatives. At the very least need to be able to justify their decisions to hire people
- Perhaps the problem is assessing good researchers?:
- Many people won’t/can’t even apply in the first place such as if the application might say must have PhD
- Chris’ note:
- Would be worthwhile for someone to talk to these organisations and find out the answer. Even if we can probably guess without talking to them, it would be useful to make this common knowledge
- Assessing potential researchers:
- Assessing people is expensive and time-intensive
- People are occasionally only given one chance to succeed - suggests this is a common issue
- Feedback matters for applicants:
- Long-term future fund - JJ knows applicants who didn't receive feedback and won't apply again
- JJ spoke to a bunch of applicants for a role he advertised - even those who they rejected:
- What changed rankings?
- Things missing or not as obvious on their application
- ie. Might say part of group X - found out that they actually founded group X
- One person assumed JJ would Google them
- Things missing or not as obvious on their application
- What changed rankings?
- Some people are capable, but unassessably so.:
- You can't write "I read Less Wrong a lot" on your AI safety application
- Typically they have to do an undergraduate degree, then ML masters, then phD. That’s a long process.
- Further distorted by tournament effects:
- If you aren't assessably good, then it becomes harder at each level because you might not have made it into something sufficiently prestigious at the previous level
- Can be an issue for people who are just below a standard (ie. 53rd when there's 50 spots)
- Lowering the bar on researchers who are funded:
- Need to somehow isolate them so that they don't pull the community down:
- Perhaps work from home or a separate office
- Analogy: some universities have a level of a library only for graduate students, as the undergraduates are messing around
- AI safety camp is good:
- Fairly isolated - though they interact with mentors
- We need to be careful about not over-updating on people’s performance in this program:
- People often join projects that weren't really their idea or where their project was doomed. They might be the only good person in their group.
- Need to somehow isolate them so that they don't pull the community down:
- Role of AI Safety Support:
- JJ tries to figure out who should talk to who and makes it easy to connect to colleagues and potential mentors:
- He lowers the activation energy
- People are reluctant to do this themselves as rejection sucks
- JJ used to suggest people to apply to the LTFF, but people always procrastinate. He now suggests people draft an application as this encourages people to actually read the application
- He chats to people, then follows up, keeping them accountable
- Meets on average two new people within the community per week - mostly early career researchers
- He offers thinner and broader help:
- Often he’s able to provide advice just when it is needed
- JJ tries to figure out who should talk to who and makes it easy to connect to colleagues and potential mentors:
Adam Shimi (Mentor coordinator for AI Safety Camp):
- Adam has a proposal to establish an Alignment Center in the EU:
- Hard to gain funding without personal recommendations. This could help evaluate people who aren't in the US/UK social group.
- Need a Visa to stay in the hubs like the Bay/UK
- Chris’ note:
- Comment on LW [LW(p) · GW(p)]:
- There’s incentives against field-building - only research helps you get funded
- Suggests it’s easy to get initial funding for AI research, but there isn’t a plan for long-term funding outside of labs
- Difficult to stop what you're doing for a year then go back if it doesn’t work out as it can interfere in your previous career
- AI Safety Camp:
- In the next camp, mentors will propose projects instead of teams:
- Mentors have a better idea of which projects are useful
- Mentors are more likely to be involved in multiple camps if the projects interest them
- Future camps will have more about surviving in the ecosystem - ie. seeking funding
- In the next camp, mentors will propose projects instead of teams:
- Chicken and egg problem:
- There’s lots of money available for AI Safety Research, but not enough stops
- You could create an new organisation, but that requires people and without experienced people, hard to set up an org
- Difficult working convincing people to work in alignment:
- Some of his friends say that it seems really hard and complicated to work in this field
- Difficult to receive money b/c of the complexity of handling taxes
- France - harder to lose a job than the US - so people have lower risk tolerance
- Can be difficult renting places without a contract
- Have to freeze your own money for unemployment insurance
- Enthusiastic about producing an alignment textbook:
- Start with an argument for AI being aligned by default. Then lists counterarguments, then proposed solutions
- Should assist people in building a map of the field, so that when they read research they can recognise what they are doing
- Adam runs AI Safety Coffee Time:
- He considers it both a success and failure
- People turn up every week, but he had hoped it’d be more
- Has some interesting work considering the epistemic strategies employed by various researchers
Janus (Eleuther):
- Ideas:
- It could be worth doing intentional outreach to convince more traditional AI researchers to care about alignment:
- Counterpoint: “Raising awareness will also inevitably increase excitement about the possibility of AGI and cause more people to start pushing towards it. For each new alignment researcher we onboard, we will attract the attention of many more capabilities researchers. It's worth noting that so many people are already working on AGI capabilities that the effect of adding additional researchers may be marginal. However, my biggest concern would be causing a giant tech company (or government) to "wake up" and devote significantly more resources towards developing AGI. This could significantly accelerate the race to AGI and make coordination even more unlikely.”
- In longer timelines, might we worth creating alignment conferences and endowing more PhD programs
- Maybe alignment textbooks?
- Suggests AI Safety research is currently in a phase of supralinear growth with each additional person adding more than the previous because there are so many potential directions to explore and each person's research can inspire others
- Thinks that there should be more experiments - particularly those involving large language models
- It could be worth doing intentional outreach to convince more traditional AI researchers to care about alignment:
- Thinking of joining an existing organisation or starting a new one:
- ML experiments like Redwood
- Worried about the rift between engineers and alignment researchers:
- The alignment forum looks super abstract and disconnected to engineers and can easily turn them off
- “Because many alignment researchers are disconnected from the ML research community, they may lack important intuitions about how neural networks act in practice. This might not be a problem when modern ML is far from AGI, but as we get closer those intuitions could become relevant”
- Suggested that he’s seen many misunderstandings about GPT-3 on the alignment forum
- “I am concerned that this problem will become much worse as companies become increasingly private about progress towards AGI. For example. if alignment researchers do not have access to (or knowledge of) GPT-5, they may be totally unable to come up with a relevant alignment strategy or even realize that that is the problem they should be working on.”
- They have a lot of ideas for experiments they don't talk about or do as they may increase capabilities
- Suggested running Kaggle competitions:
- Ie. How can we train GPT3 to give honest medical advice?
- I asked what would be useful if there was to be a light touch research organisation. :
- Physical colocation
- Temporary events: ie. 2 weeks coworking together
- Active mentorship and collaboration
- Writing support:
- Suggests that everyone has things that they’d write up if they had time
- Notes that it would be difficult to do this over video
- Chris’ note:
- Perhaps something for the multiplier fund?
Richard (previously a funded AI Safety researcher):
- Richard wrote a post about why he left AI Alignment here [LW · GW]. I was following up to see if he had anything else to add.
- Writing group:
- Richard organized a writing group, but was unsure of how helpful it was. He left AI safety before it had the chance to become useful:
- While in Richard’s group everyone was working on their own research, Logan gets together with people to work on something concrete (he’s completed two such projects)
- What would have helped? (“…me avoid the mistakes I made”)
- Biggest barrier is money
- Better system for connecting people online
- A matching program to find someone who would like to work on the same project
- Mentorship:
- As a beginner, it is hard to know what to study and how to study
- Going through a maths textbook may not be the best way to learn what you need to learn
- Guides on studying like the MIRI study guide could help
- Might need to backtrack if something is too high-level. Would be better if there were guides for different levels.
- No one has reached out in terms of keeping the AI safety calendar up-to-date (Not a complaint. Just a statement of fact)
- One thought on funding applications:
- These tend to ask what you’d do if you weren’t funded.
- This is a double-edged sword. While this improves marginal impact, the most resourceful (and therefore high expected impact) people will always have good B, C plans.
Founder of an Anonymous EA Org:
- I’ve included this because it is relevant to the light-touch research organisation idea
- How do they handle downside risks?:
- “So far we haven't had any cases where people were proposing to do anything that seemed likely to lead down an obviously dangerous path with AI. Mostly people are learning about it rather than pushing the envelope of cutting-edge research. And no one is running large ML models or anything like that.”
- On maintaining productivity:
- “For checking on project's progress, it is often a bit of a battle to get people to fill out progress updates and outputs, but we are working on it. We've now got weekly meetings where people fill out a spreadsheet with what they are working on. But ask people to keep the Progress Updates and Outputs GDocs shown on the people page updated (quarterly or at least monthly - as per Terms & Conditions. Going to make this more explicit by having a dedicated tick box to it on the application form). I've also been thinking that a Discord bot linked to the GDocs could help (e.g. have it set up to automatically nudge people if the GDocs aren't updated at certain dates)”
Remmelt (AI Safety Camp):
- AI Safety Camp:
- Main benefits:
- This brings in people from the sidelines. It makes people think it is actually possible to do something about this.
- People get to work on concrete research, which is what makes them see where it’s possible for them to make progress themselves (rather than pondering in abstract about whether they’d make a good fit)
- Ways it hasn't been so useful:
- People often don’t pick good projects
- Hard to find repeat mentors:
- In previous editions, mentors received requests for projects thought up by participants and they often weren’t very interested in them. In the next edition, people are applying to work on a problem proposed by the mentors themselves.
- Main benefits:
- More difficult for people without a STEM background to contribute - ie. doesn’t really support people interested in policy or operations
Logan (Funded to research Vanessa's work):
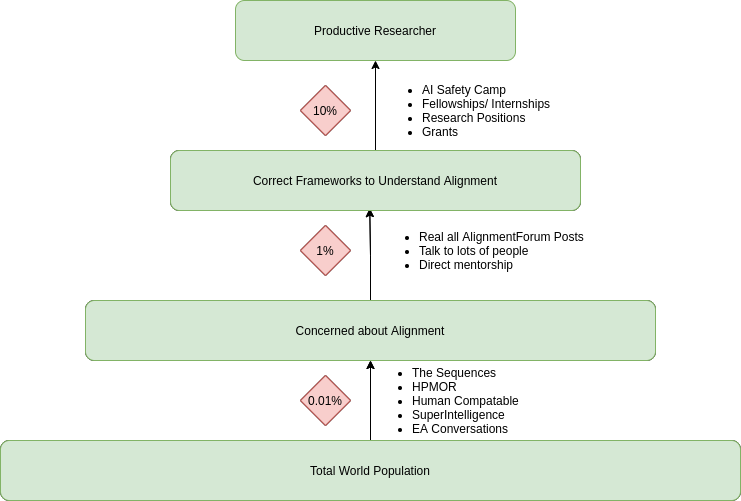
- Image is from this document
- Lots of people want to do something, but have no idea what to do:
- Main bottleneck is moving from concerned about alignment to having correct frameworks to understand alignment:
- Runs into the exploding link problem when trying to read alignment forum
- It’s hard to evaluate quality of posts to decide what to read
- Main bottleneck is moving from concerned about alignment to having correct frameworks to understand alignment:
- What would be helpful:
- Social proof is important. Meeting someone who took AI safety seriously was a large part of getting him involved.
- One-on-one mentoring calls to instil tacit knowledge:
- Possibly recorded for the benefit of others
- Further thoughts:
- People who are actually in the alignment field should be writing research proposals for junior researchers instead of these junior researchers writing their own.
- Logan’s note: this idea was from talking with Adam Shimi.
- People who are actually in the alignment field should be writing research proposals for junior researchers instead of these junior researchers writing their own.
Toon (RAISE, now defunct):
- “You know, it might not even be that hard to get started for an average rationalist. This myth that you need to be super smart is at least off-putting. I’m personally in a perfect position to give it a shot, but still not willing to try it because I don’t want to waste 6 months on getting nowhere. So you need to somehow reduce the risk for people. Dunning-kruger etc. To reduce their risk of trying, people need 1) direction/mentoring/hero licensing/encouragement and 2) a way to pay the bills in the meantime”:
- Writes: “I would set up regular video calls with people and tell them what to do, put their learning progress in context, give them feedback, etc. You can do this in a group setting and you probably don’t need more than an hour or two per week per person.
- Allowing people to cover their bills is harder. Suggests that we might have enough money to fund people trying to skill up, but people “seem to think you need to be the next Einstein”
- “I might be wrong though. Because I have some credence that I could do it and I wouldn’t call myself smarter than others, but either of these could easily be wrong”
- Further suggests more experiments
John Maxwell:
- Proposes an AI Safety tournament [LW(p) · GW(p)] where the blue team makes a proposal and the red team tries to break it. Strongest players on each team advance:
- Suggests this could be useful for identifying talent
- Chris:
- Not a bad idea, but judges might need to be pretty senior in order to evaluate this and the time of senior people is valuable
- John: Perhaps a tournament for judges as well
- Chris: Debating does this
- Thinking of creating a new forum for discussing AI safety:
- John has lots of bookmarked posts. Sometimes he leaves a comment on an older post and this normally gets ignored
- Older forums have an intellectual culture where threads can become live again when they are bumped
- Other ways to differentiate from the alignment forum:
- More informal, no downvotes as these reduce contrarian comments, perhaps this would create an area for people who are a little more junior?
Anonymous:
- Ways of Scaling up is very sensitive to timelines and what you want to scale up:
- Personally, he has very aggressive timelines
- Doesn’t know if there is a good way of speeding up agent foundations
- One way is to throw money at things: Constructing better environments and test cases:
- Just need good software engineers + one guy with vision
- As an example of how these are limited: Basalt is still very gym-like. It lacks real time interaction and still only has a single AI.
- Many people have projects they want to conduct:
- Just need ML engineers to do this
- Reaching massive scale:
- There aren’t many alignment-researchers/manager hybrids (ie. equivalent to principal investigators). It takes time to develop these skills.
- Over scales 15-20 years:
- Worthwhile engaging in movement building and accelerate people to becoming dedicated alignment researchers
- Suggests that there is a vetting bottleneck
- Money:
- John Wentworth worked in finance so he doesn't need to justify his projects to other people:
- Note: I’ve seen him apply for grants though
- Similarly, they are trying to acquire money, so that he can do independent work:
- John Wentworth worked in finance so he doesn't need to justify his projects to other people:
- Grants are risky
- He doesn’t feel he has a lot of clout
- Grants aren't large compared to the money you make in Silicon valley
Anonymous:
- Found attempting to make it into AI safety demoralising:
- Didn't really receive feedback - what if organisations had an operations person to provide rejection feedback?:
- Chris’ note: When I worked as an interviewer for Triplebyte we had a team of writers to write up some feedback from our notes and how we responded to some tick-boxes.
- Didn't really receive feedback - what if organisations had an operations person to provide rejection feedback?:
- They are worried about credentialism, although they argue it is most useful on a medium timeframe:
- If AGI will be invented in the next five years, then credibility has limited importance
- For a longer timeline, we should be investing a lot more in junior people
- In so far as AI Safety is pre-paradigmatic, senior people may not have more insight"pre-paradigmatic", senior people might not actually have more insight"
Anonymous:
- Talked about the difficulty of trying to transition from pure maths to AI safety alignment. A pure maths post-doc is very demanding and an 80,000 advisor didn’t quite understand this difficulty, suggesting that maybe he didn’t want to transition.
- Advised people trying to transition not to try to juggle too many things
- Suggested that a mental health referral system for people trying to break into the field could be useful
Anonymous:
- In response to “not everyone should be funded”:
- There’s a sense in which that is trivially true, but it may also be obscuring the key point. If we removed the bottom 5% of alignment researchers, then that would only remove around 10 people. We really don’t have problem where a lot of poor alignment researchers are being funded; the problem we have is that there simply aren’t enough people working on alignment. If someone has the aptitude to understand the concepts and is willing to really try, they should be funded. If we had 10,000 people working on alignment, then we would have to raise the bar, but right now that isn’t the case. If $10Bn went to researchers, that would pay for a 60k salary for 166,666 people years! We are currently getting 200 people years per year? and we have 5-25 years until the singularity. To clarify: $10Bn seems like a reason spend on alignment researchers and you can spread that over the entire timeline to the singularity.
15 comments
Comments sorted by top scores.
comment by TekhneMakre · 2021-12-09T03:36:30.486Z · LW(p) · GW(p)
I think there's an issue where Alice wants to be told what to do to help with AI safety. So then Bob tells Alice to do X, and then Alice does X, and since X came from Bob, the possibility of Alice helping manifest the nascent future paradigms of alignment is lost. Or Carol tells Alice that AI alignment is a pre-paradigmatic field and she should think for herself. So then Alice thinks outside the box [LW · GW], in the way she already knows how to think outside the box; empirically, most of most people's idea generation is surprisingly unsurprising. Again, this loses the potential for Alice to actually deal with what matters.
Not sure what could be done about this. One thing is critique. E.g., instead of asking "what are some ways this proposed FAI design could go wrong", asking "what is the deepest, most general way this must go wrong?", so that you can update away from that entire class of doomed ideas, and potentially have more interesting babble.
comment by plex (ete) · 2021-12-08T20:04:34.695Z · LW(p) · GW(p)
I'm interested in talking with anyone who is looking at the EU EA Hotel idea mentioned in the post. Also I'm working with Rob Miles's community on a project to improve the pipeline, an interactive FAQ system called Stampy.
The goals of the project are to:
- Offer a one-stop-shop for high-quality answers to common questions about AI alignment.
- Let people answer questions in a way which scales, freeing up researcher time while allowing more people to learn from a reliable source.
- Make external resources more easy to find by having links to them connected to a search engine which gets smarter the more it's used.
- Provide a form of legitimate peripheral participation for the AI Safety community, as an on-boarding path with a flexible level of commitment.
- Encourage people to think, read, and talk about AI alignment while answering questions, creating a community of co-learners who can give each other feedback and social reinforcement.
- Provide a way for budding researchers to prove their understanding of the topic and ability to produce good work.
- Collect data about the kinds of questions people actually ask and how they respond, so we can better focus resources on answering them.
- Track reactions on messages so we can learn which answers need work.
- Identify missing external content to create.
We're still working on it, but would welcome feedback on how the site is to use and early adopters who want to help write and answer questions. You can join the public Discord or message me for an invite to the semi-private patron one.
comment by TekhneMakre · 2021-12-09T03:10:32.613Z · LW(p) · GW(p)
Typically they have to do an undergraduate degree, then ML masters, then phD. That’s a long process.
Do you know what this was referring to? Is it referring specifically to orgs that focus on ML-based AI alignment work, or more generally grant-makers who are trying to steer towards good AGI outcomes, etc.? This seems like a fine thing if you're looking for people to work under lead researchers on ML stuff, but seems totally insane if it's supposed to be a filter on people who should be fed and housed while they're trying to solve very difficult pre-paradigmatic problems.
Replies from: jj-hepburn, Chris_Leong↑ comment by JJ Hepburn (jj-hepburn) · 2021-12-09T04:46:43.704Z · LW(p) · GW(p)
Not exactly sure what I was trying to say here. Probably using the PhD as an example of a path to credentials.
Here are some related things I believe:
- I don't think a PhD is necessary or the only way
- University credentials are not now and should not be the filter for people working on these problems
- There is often a gap between peoples competencies and their ability to signal them
- Credentials are the default signal for competence
- Universities are incredibly inefficient ways to gain competence or signal
- Assessing people is expensive and so reviewers are incentivised to find cheaper to assess signals
- Credentials are used as signals not because they are good but because they are cheap to assess and universally understood
- Credentials are often necessary but rarely sufficient
↑ comment by TekhneMakre · 2021-12-09T06:15:26.288Z · LW(p) · GW(p)
Cool. I appreciate you making these things explicit.
If the bottleneck is young people believing that if they work on the really hard problems, then there will be funding for them somehow, then, it seems pretty important for funders to somehow signal that they would fund such people. By default, even using credentials as a signal at all, signals to such young people that this funder is not able/willing to do something weird with their money. I think funders should probably be much more willing to say to someone with (a) a PhD and (b) boring ideas, "No, sorry, we're looking for people working on the hard parts of the problem".
↑ comment by Chris_Leong · 2021-12-09T03:26:14.905Z · LW(p) · GW(p)
I don't know exactly, if you're interested might be best to message JJ directly.
comment by Linda Linsefors · 2022-02-05T14:11:59.040Z · LW(p) · GW(p)
What is "AI Safety Coffee Time"?
Link?
↑ comment by Chris_Leong · 2022-02-06T01:24:01.286Z · LW(p) · GW(p)
https://www.alignmentforum.org/posts/cysgh8zpmvt56f6Qw/event-weekly-alignment-research-coffee-time-01-31
comment by TekhneMakre · 2021-12-09T03:25:32.240Z · LW(p) · GW(p)
AI safety is obviously super important and super interesting. So if high-potential young people aren't working on it, it's because they're being diverted from obviously super important and super interesting things. Why is that happening?
Replies from: Chris_Leong↑ comment by Chris_Leong · 2022-02-16T05:10:22.498Z · LW(p) · GW(p)
A lot of the AI old guard are still extremely skeptical about it which discourages people who trust their views.
Replies from: TekhneMakre↑ comment by TekhneMakre · 2022-02-17T01:16:29.378Z · LW(p) · GW(p)
Are high-potential young people discouraged by this?
Replies from: Chris_Leong↑ comment by Chris_Leong · 2022-02-17T11:16:50.520Z · LW(p) · GW(p)
Some definitely are; some aren't.
Replies from: TekhneMakre↑ comment by TekhneMakre · 2022-02-19T04:18:18.490Z · LW(p) · GW(p)
What fraction, would you guess?
comment by Lone Pine (conor-sullivan) · 2021-12-08T07:17:25.753Z · LW(p) · GW(p)
Where did the $10B number come from? Is that how much money the AI safety orgs have on hand?
Replies from: Chris_Leong↑ comment by Chris_Leong · 2021-12-08T08:23:47.642Z · LW(p) · GW(p)
It was based on an estimate of how much money EA might have access to in total. AI safety orgs have nothing like that on hand - they were arguing that EA should increase its AI safety spend.