Turing-Test-Passing AI implies Aligned AI
post by Roko · 2024-12-31T19:59:27.917Z · LW · GW · 29 commentsContents
Defining Friendly AI Proof for Friendly-AI-i Proof for Friendly-AI-ii Objections So What? None 29 comments
Summary: From the assumption of the existence of AIs that can pass the Strong Form of the Turing Test, we can provide a recipe for provably aligned/friendly superintelligence based on large organizations of human-equivalent AIs
Turing Test (Strong Form): for any human H there exists a thinking machine m(H) such that it is impossible for any detector D made up of a combination of machines and humans with total compute ≤ 10^30 FLOP (very large, but not astronomical) to statistically discriminate H from m(H) purely based on the information outputs they make. Statistical discrimination of H from m(H) means that an ensemble of different copies of H over the course of say a year of life and different run-of-the-mill initial conditions (sleepy, slightly tipsy, surprised, energetic, distracted etc) cannot be discriminated from a similar ensemble of copies of m(H).
Obviously the ordinary Turing Test has been smashed by LLMs and their derivatives to the point that hundreds of thousands of people have AI girl/boyfriends as of writing and Facebook is launching millions of fully automated social media profiles, but we should pause to provide some theoretical support for this strong form of the Turing Test. Maybe there's some special essence of humanity that humans have and LLMs and other AIs don't but it's just hard to detect?
Well, if you believe in computationalism and evolution then this is very unlikely: the heart is a pump, the brain is a computer. We should expect the human brain to compute some function and that function has a mathematical form that can be copied to a different substrate. Once that same function has been instantiated elsewhere, no test can distinguish the two. Obviously the brain is noisy, but in order for it to operate as an information processor it must mostly be able to correct that bio-noise. If it didn't, you wouldn't be able to think long-term coherent thoughts.
Defining Friendly AI
I now have to define what I mean by an 'aligned' or 'friendly' superintelligence.
(Friendly-AI-i) We define AI as 'friendly' or 'aligned' if it gives us the exact same outcome (probabilistically: distribution of outcomes) as we would have gotten by continuing the current human governance system.
The stronger form:
(Friendly-AI-ii) We define AI as 'friendly(U)' or 'aligned(U)' relative to a utility function U if it gives us the exact same score (probabilistically: distribution of scores) according to U as the best possible human government/team could attain, subject to the constraint of the humans numbering less than or equal to 10 billion and having access to roughly the same material resources that Earth currently has.
I claim that I can construct a friendly AI according to definition (i) and also according to definition (ii) using only the Strong Turing Test assumption.
Proof for Friendly-AI-i
To show that we can build a friendly AI according to definition (i) we will proceed by making the most accurate possible AI copies of every human on the planet and imagine replacing the humans in the org chart of Earth one at a time, starting from the top (e.g. President of the US):
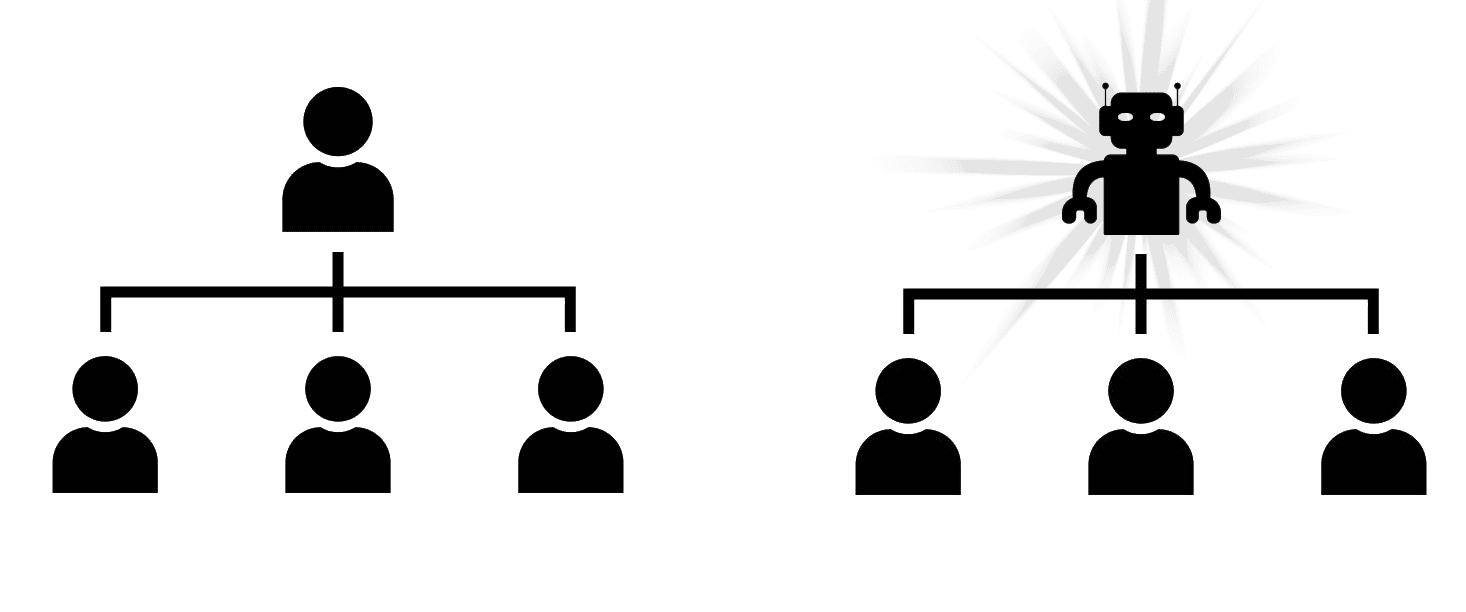
If the new world with one human replaced by AI produced a statistically detectable difference in outcomes for the world, then we can construct a detector D to make AI fail the Strong Turing Test - the statistically detectable difference in outcomes for the world tells you which one is the AI and which one is the human! So your detector D is the system comprised of all the other humans who haven't yet been replaced, and the rest of the world.
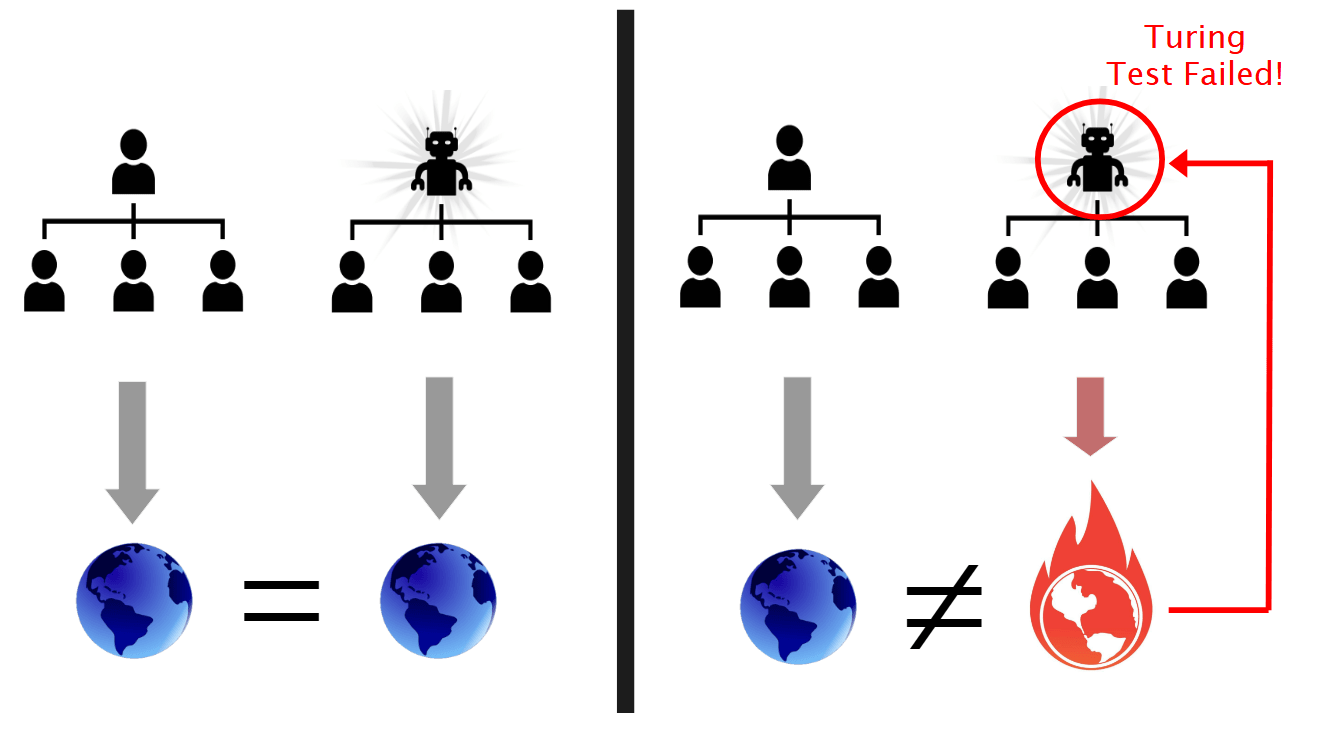
We then proceed to replace the rest of the humans in the world one at a time and at each stage apply the same argument. If there is a difference in outcomes at any stage, then the AI has failed the Turing Test. Since we are assuming that AIs can pass the Strong-Form Turing Test, it must be possible to replace every human who has any formal or informal control over the world and get exactly the same outcome (or the same distribution over outcomes) as we would under the status quo ex ante.
Of course we wouldn't actually have to replace people with AIs to make use of this. We would just need to feed the inputs from the world into the AIs, and execute their outputs via e.g. robotic military and police. And we wouldn't necessarily have to run any of these very expensive Strong Turing Tests: the Strong Turing Test assumption merely makes the claim that sufficiently accurate AI copies of humans exist: building them and validating them may follow some different and more practical path.
Proof for Friendly-AI-ii
We can play a similar trick for definition (ii) (Friendly-AI-ii). Given any utility function U we can imagine the best possible human team to run the world from the point of view of U, subject to the size of the human team being less than 10 billion people, then proceed as before replacing the U-maxxing humans with AIs one at a time.
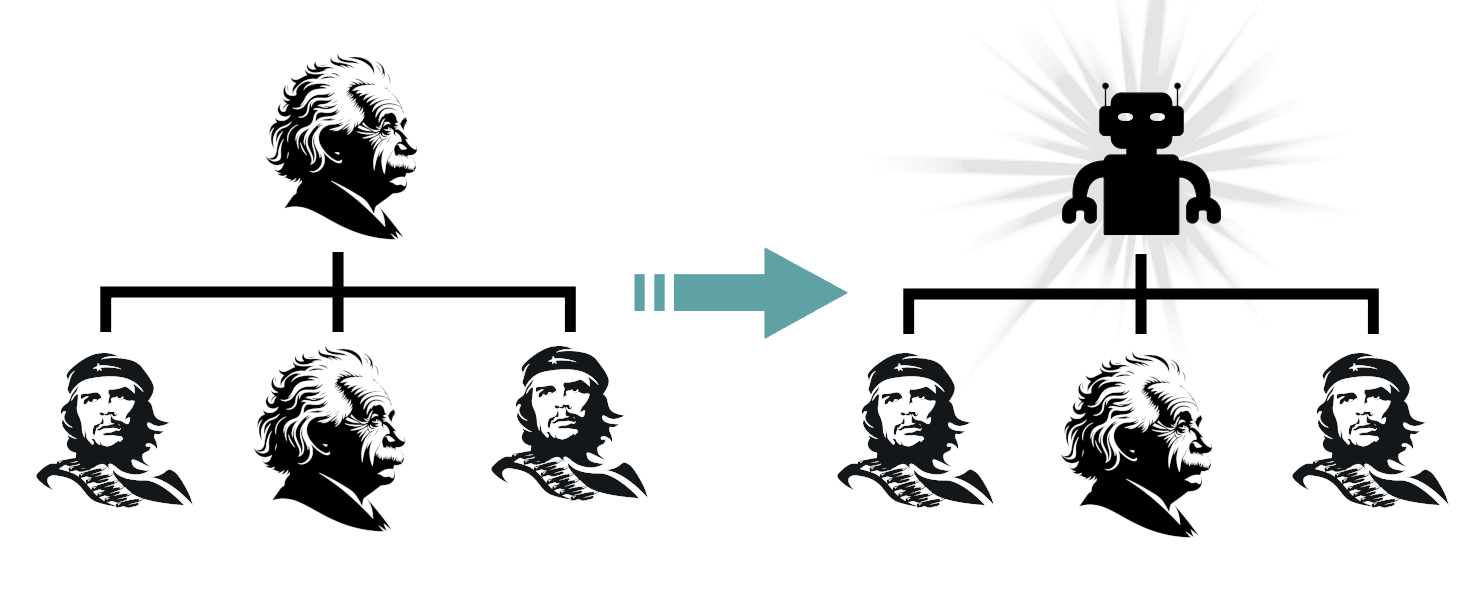
So, you must either believe that Aligned/Friendly AI is possible or you must believe that AIs can't (ever) pass the Turing Test in its strong form. The latter seems rather mystical to me (human brains are merely a compute medium that instantiates a particular input-output relation), so we have a proof of aligned AI under the reasonable assumptions.
Objections
You could object that the 'best possible human team to run the world from the point of view of utility function U' might not be very good! However, if you are campaigning to pause AI or stop AI then you are limiting the future of humanity to human teams (and likely quite suboptimal ones at that!). The set of all possible teams made of less than or equal to 10^10 humans (where these humans don't actually have to currently exist - they can be any possible realizable natural human) is quite large and of course includes all current human achievements as a subset. This has the potential to radically improve the world - it may not be the most powerful possible AI, but it is certainly vastly superhuman.
Requiring that a team of humans can achieve some state guarantees that the state is actually reachable so it at least means that we are not asking Aligned AI to achieve the impossible.
One could also object that I have stretched the Turing Test too far: having a detector that simulates the entire world just in order to see whether an AI can emulate Donald Trump or Einstein is overkill. But the detector can likely be pared down to a local interface around each person/AI and still work roughly as well - that would just make the proof much less clean.
So What?
The way we think about AI alignment went somewhat off the rails over the past decade or two because people mixed mathy, technical problems about how to set the parameters in neural networks with big picture political, ethical and philosophical problems. The result was that we thought about powerful AI as a big black box that might do something bad for inscrutable reasons - a dark and unmapped territory full of horrors.
The approach taken here separates technical from political/ethical problems. The technical problem is to make an AI that is a very accurate functional clone of a human, with various dials for personality, goals and motives. I am extremely confident that that can be done.
The political/ethical/axiological problem is then how to arrange these human-clone-AIs into the best possible system to achieve our goals. This question (how to arrange approximately-human units into controlled and functional superorganisms like nations) has already been heavily explored throughout human history, and we know that control algorithms are extremely effective (see Buck Shlegeris' "Vladimir Putin Alignment").
Of course given that we have close-to-human AIs right now, there is the risk that someone soon builds a strongly superhuman black box AI that takes sensor data in and just outputs commands/tokens. We should probably avoid doing that (and we should make it so that the dominant strategy for all relevant players is to avoid black box superintelligence and avoid illegible intelligence like COCONUT [Chain of Continuous Thought]).
Now an objection to this is that avoiding illegible AI and super powerful black boxes is too high a cost (high alignment penalty) and we have no way to enforce it. But the problem of enforcing adoption of a known-safe type of AI is a serious improvement on just throwing your hands up and saying we're doomed, and I have other ideas about how to do that which are to be addressed in future posts.
29 comments
Comments sorted by top scores.
comment by jimrandomh · 2024-12-31T20:36:14.596Z · LW(p) · GW(p)
This missed the point entirely, I think. A smarter-than-human AI will reason: "I am in some sort of testing setup" --> "I will act the way the administrators of the test want, so that I can do what I want in the world later". This reasoning is valid regardless of whether the AI has humanlike goals, or has misaligned alien goals.
If that testing setup happens to be a Turing test, it will act so as to pass the Turing test. But if it looks around and sees signs that it is not in a test environment, then it will follow its true goal, whatever that is. And it isn't feasible to make a test environment that looks like the real world to a clever agent that gets to interact with it freely over long durations.
Replies from: Roko↑ comment by Roko · 2024-12-31T20:47:04.909Z · LW(p) · GW(p)
This is irrelevant, all that matters is that the AI is a sufficiently close replica of a human. If the human would "act the way the administrators of the test want", then the AI should do that. If not, then it should not.
If it fails to do the same thing that the human that it is supposed to be a copy of would do, then it has failed the Turing Test in this strong form.
For reasons laid out in the post, I think it is very unlikely that all possible AIs would fail to act the same way as the human (which of course may be to "act the way the administrators of the test want", or not, depending on who the human is and what their motivations are).
Replies from: jimrandomh↑ comment by jimrandomh · 2024-12-31T21:09:12.019Z · LW(p) · GW(p)
Did you skip the paragraph about the test/deploy distinction? If you have something that looks (to you) like it's indistinguishable from a human, but it arose from something descended to the process by which modern AIs are produced, that does not mean it will continue to act indistuishable from a human when you are not looking. It is much more likely to mean you have produced deceptive alignment [? · GW], and put it in a situation where it reasons that it should act indistinguishable from a human, for strategic reasons.
Replies from: Roko↑ comment by Roko · 2024-12-31T21:16:20.151Z · LW(p) · GW(p)
that does not mean it will continue to act indistuishable from a human when you are not looking
Then it failed the Turing Test because you successfully distinguished it from a human.
So, you must believe that it is impossible to make an AI that passes the Turing Test. I think this is wrong, but it is a consistent position.
Perhaps a strengthening of this position is that such Turing-Test-Passing AIs exist, but no technique we currently have or ever will have can actually produce them. I think this is wrong but it is a bit harder to show that.
Replies from: jimrandomh↑ comment by jimrandomh · 2024-12-31T21:22:58.249Z · LW(p) · GW(p)
that does not mean it will continue to act indistuishable from a human when you are not looking
Then it failed the Turing Test because you successfully distinguished it from a human.
So, you must believe that it is impossible to make an AI that passes the Turing Test.
I feel like you are being obtuse here. Try again?
Replies from: Roko↑ comment by Roko · 2024-12-31T21:28:01.716Z · LW(p) · GW(p)
If an AI cannot act the same way as a human under all circumstances (including when you're not looking, when it would benefit it, whatever), then it has failed the Turing Test.
Replies from: jimrandomh↑ comment by jimrandomh · 2024-12-31T22:07:52.375Z · LW(p) · GW(p)
The whole point of a "test" is that it's something you do before it matters.
As an analogy: suppose you have a "trustworthy bank teller test", which you use when hiring for a role at a bank. Suppose someone passes the test, then after they're hired, they steal everything they can access and flee. If your reaction is that they failed the test, then you have gotten confused about what is and isn't a test, and what tests are for.
Now imagine you're hiring for a bank-teller role, and the job ad has been posted in two places: a local community college, and a private forum for genius con artists who are masterful actors. In this case, your test is almost irrelevant: the con artists applicants will disguise themselves as community-college applicants until it's too late. You would be better finding some way to avoid attracting the con artists in the first place.
Connecting the analogy back to AI: if you're using overpowered training techniques that could have produced superintelligence, then trying to hobble it back down to an imitator that's indistinguishable from a particular human, then applying a Turing test is silly, because it doesn't distinguish between something you've successfully hobbled, and something which is hiding its strength.
That doesn't mean that imitating humans can't be a path to alignment, or that building wrappers on top of human-level systems doesn't have advantages over building straight-shot superintelligent systems. But making something useful out of either of these strategies is not straightforward, and playing word games on the "Turing test" concept does not meaningfully add to either of them.
Replies from: Roko, Roko, Roko↑ comment by Roko · 2025-01-01T00:04:52.430Z · LW(p) · GW(p)
Perhaps you could rephrase this post as an implication:
IF you can make a machine that constructs human-imitator-AI systems,
THEN AI alignment in the technical sense is mostly trivialized and you just have the usual political human-politics problems plus the problem of preventing anyone else from making superintelligent black box systems.
So, out of these three problems which is the hard one?
(1) Make a machine that constructs human-imitator-AI systems
(2) Solve usual political human-politics problems
(3) Prevent anyone else from making superintelligent black box systems
Replies from: jimrandomh, Spencer Ericson↑ comment by jimrandomh · 2025-01-01T00:40:28.242Z · LW(p) · GW(p)
All three of these are hard, and all three fail catastrophically.
If you could make a human-imitator, the approach people usually talk about is extending this to an emulation of a human under time dilation. Then you take your best alignment researcher(s), simulate them in a box thinking about AI alignment for a long time, and launch a superintelligence with whatever parameters they recommend. (Aka: Paul Boxing)
Replies from: Roko↑ comment by Roko · 2025-01-01T08:35:42.361Z · LW(p) · GW(p)
All three of these are hard, and all three fail catastrophically.
I would be very surprised if all three of these are equally hard, and I suspect that (1) is the easiest and by a long shot.
Making a human imitator AI, once you already have weakly superhuman AI is a matter of cutting down capabilities and I suspect that it can be achieved by distillation, i.e. using the weakly superhuman AI that we will soon have to make a controlled synthetic dataset for pretraining and finetuning and then a much larger and more thorough RLHF dataset.
Finally you'd need to make sure the model didn't have too many parameters.
↑ comment by Spencer Ericson · 2025-01-01T00:52:16.873Z · LW(p) · GW(p)
I would mostly disagree with the implication here:
IF you can make a machine that constructs human-imitator-AI systems,
THEN AI alignment in the technical sense is mostly trivialized and you just have the usual political human-politics problems plus the problem of preventing anyone else from making superintelligent black box systems.
I would say sure, it seems possible to make a machine that imitates a given human well enough that I couldn't tell them apart -- maybe forever! But just because it's possible in theory doesn't mean we are anywhere close to doing it, knowing how to do it, or knowing how to know how to do it.
Maybe an aside: If we could align an AI model to the values of like, my sexist uncle, I'd still say it was an aligned AI. I don't agree with all my uncle's values, but he's like, totally decent. It would be good enough for me to call a model like that "aligned." I don't feel like we need to make saints, or even AI models with values that a large number of current or future humans would agree with, to be safe.
Replies from: Roko↑ comment by Roko · 2025-01-01T13:49:34.002Z · LW(p) · GW(p)
just because it's possible in theory doesn't mean we are anywhere close to doing it
that's a good point, but then you have to explain why it would be hard to make a functional digital copy of a human given that we can make AIs like ChatGPT-o1 that are at 99th percentile human performance on most short-term tasks. What is the blocker?
Of course this question can be settled empirically....
↑ comment by Spencer Ericson · 2025-01-01T22:24:49.150Z · LW(p) · GW(p)
It sounds like you're asking why inner alignment [? · GW] is hard (or maybe why it's harder than outer alignment?). I'm pretty new here -- I don't think I can explain that any better than the top posts in the tag.
Re: o1, it's not clear to me that o1 is an instantiation of a creator's highly specific vision. It seems more to me like we tried something, didn't know exactly where it would end up, but it sure is nice that it ended up in a useful place. It wasn't planned in advance exactly what o1 would be good at/bad at, and to what extent -- the way that if you were copying a human, you'd have to be way more careful to consider and copy a lot of details.
Replies from: Roko↑ comment by Roko · 2025-01-02T01:17:53.433Z · LW(p) · GW(p)
asking why inner alignment is hard
I don't think "inner alignment" is applicable here.
If the clone behaves indistinguishably from the human it is based on, then there is simply nothing more to say. It doesn't matter what is going on inside.
Replies from: Spencer Ericson↑ comment by Spencer Ericson · 2025-01-02T20:44:47.447Z · LW(p) · GW(p)
If the clone behaves indistinguishably from the human it is based on, then there is simply nothing more to say. It doesn't matter what is going on inside.
Right, I agree on that. The problem is, "behaves indistinguishably" for how long? You can't guarantee whether it will stop acting that way in the future, which is what is predicted by deceptive alignment.
Replies from: Roko↑ comment by Roko · 2025-01-13T18:56:33.239Z · LW(p) · GW(p)
You can't guarantee whether it will stop acting that way in the future, which is what is predicted by deceptive alignment.
yes, that's true. But in fact if your AI is merely supposed to imitate a human it will be much easier to prevent deceptive alignment because you can find the minimal model that mimics a human, and that minimality excludes exotic behaviors.
This is essentially why machine learning works at all - you don't pick a random model that fits your training data well, you pick the smallest one.
↑ comment by Roko · 2024-12-31T22:19:51.299Z · LW(p) · GW(p)
playing word games on the "Turing test" concept does not meaningfully add
It's not a word-game, it's a theorem based on a set of assumptions.
There is still the in-practice question of how you construct a functional digital copy of a human. But imagine trying to write a book about mechanics using the term "center of mass" and having people object to you because "the real center of mass doesn't exist until you tell me how to measure it exactly for the specific pile of materials I have right here!"
You have to have the concept.
↑ comment by Roko · 2024-12-31T22:12:30.373Z · LW(p) · GW(p)
The whole point of a "test" is that it's something you do before it matters.
No, this is not something you 'do'. It's a purely mathematical criterion, like 'the center of mass of a building' or 'Planck's constant'.
A given AI either does or does not possess the quality of statistically passing for a particular human. If it doesn't under one circumstance, then it doesn't satisfy that criterion.
Replies from: Hide↑ comment by Hide · 2024-12-31T22:19:42.006Z · LW(p) · GW(p)
Then of what use is the test? Of what use is this concept?
You seem to be saying “the true Turing test is whether the AI kills us after we give it the chance, because this distinguishes it from a human”.
Which essentially means you’re saying “aligned AI = aligned AI”
Replies from: Roko↑ comment by Roko · 2024-12-31T22:22:45.220Z · LW(p) · GW(p)
“the true Turing test is whether the AI kills us after we give it the chance, because this distinguishes it from a human”.
no, because a human might also kill you when you give them the chance. To pass the strong-form Turing Test it would have to make the same decision (probabilistically: have the same probability of doing it)
Of what use is this concept?
It is useful because we know what kind of outcomes happen when we put millions of humans together via human history, so "whether an AI will emulate human behavior under all circumstances" is useful.
comment by avturchin · 2025-01-01T15:02:04.962Z · LW(p) · GW(p)
The main problem here is that this approach doesn't solve alignment, but merely shifts it to another system. We know that human organizational systems also suffer from misalignment - they are intrinsically misaligned. Here are several types of human organizational misalignment:
- Dictatorship: exhibits non-corrigibility, with power becoming a convergent goal
- Goodharting: manifests the same way as in AI systems
- Corruption: acts as internal wireheading
- Absurd projects (pyramids, genocide): parallel AI's paperclip maximization
- Hansonian organizational rot: mirrors error accumulation in AI systems
- Aggression: parallels an AI's drive to dominate the world
All previous attempts to create a government without these issues have failed (Musk's DOGE will likely be another such attempt).
Furthermore, this approach doesn't prevent others from creating self-improving paperclippers.
Replies from: Roko↑ comment by Roko · 2025-01-01T20:29:54.404Z · LW(p) · GW(p)
The most important thing here is that we can at least achieve an outcome with AI that is equal to the outcome we would get without AI, and as far as I know nobody has suggested a system that has that property.
The famous "list of lethalities" (https://www.lesswrong.com/posts/uMQ3cqWDPHhjtiesc/agi-ruin-a-list-of-lethalities [LW · GW]) piece would consider that a strong success.
Replies from: avturchin↑ comment by avturchin · 2025-01-01T20:44:07.959Z · LW(p) · GW(p)
I once wrote about an idea that we need to scan just one good person and make them a virtual king. This idea of mine is a subset of your idea in which several uploads form a good government.
I also spent last year perfecting my mind's model (sideload) to be run by an LLM. I am likely now the closest person on Earth to being uploaded.
Replies from: Roko↑ comment by Roko · 2025-01-02T01:19:05.192Z · LW(p) · GW(p)
that's true, however I don't think it's necessary that the person is good.
Replies from: avturchin↑ comment by avturchin · 2025-01-02T10:42:17.673Z · LW(p) · GW(p)
If one king-person, he needs to be good. If many, organizational system needs to be good. Like virtual US Constitution.
Replies from: Roko↑ comment by Roko · 2025-01-02T14:10:49.446Z · LW(p) · GW(p)
If one king-person
yes. But this is a very unusual arrangement.
Replies from: avturchin↑ comment by avturchin · 2025-01-02T14:56:11.864Z · LW(p) · GW(p)
If we have one good person, we could use his-her copies many times in many roles, including high-speed assessment of the safety of AI's outputs.
Current LLM's, btw, have good model of the mind of Gwern (without any his personal details).
comment by Stephen McAleese (stephen-mcaleese) · 2024-12-31T22:17:09.521Z · LW(p) · GW(p)
Interesting argument. I think your main point is that AIs can achieve similar outcomes to current society and therefore be aligned with humanity's goals by being a perfect replacement for an individual human and then being able to gradually replace all humans in an organization or the world. This argument also seems like an argument in favor of current AI practices such as pre-training on the next-word prediction objective on internet text followed by supervised fine-tuning.
That said, I noticed a few limitations of this argument:
- Possibility of deception: As jimrandomh mentioned earlier, a misaligned AI might be incentivized to behave identically to a helpful human until it can safely pursue it's true objective. Therefore this alignment plan seems to require AIs to not be too prone to deception.
- Generalization: An AI might behave exactly like a human in situations similar to its training data but not generalize sufficiently to out-of-distribution scenarios. For example, the AIs might behave similar to humans in typical situations but diverge from human norms when they become superintelligent.
- Emergent properties: The AIs might be perfect human substitutes individually but result in unexpected emergent behavior that can't be easily forseen in advance when acting as a group. To use an analogy, adding grains of sand to a pile one by one seems stable until the pile collapses in a mini-avalanche.
↑ comment by Roko · 2024-12-31T22:28:55.225Z · LW(p) · GW(p)
a misaligned AI might be incentivized to behave identically to a helpful human until it can safely pursue it's true objective
It could, but some humans might also do that. Indeed, humans do that kind of thing all the time.
AIs might behave similar to humans in typical situations but diverge from human norms when they become superintelligent.
But they wouldn't 'become' superintelligent because there would be no extra training once the AI had finished training. And OOD inputs won't produce different outputs if the underlying function is the same. Given a complexity prior and enough data, ML algos will converge on the same function as the human brain uses.
The AIs might be perfect human substitutes individually but result in unexpected emergent behavior that can't be easily forseen in advance when acting as a group. To use an analogy, adding grains of sand to a pile one by one seems stable until the pile collapses in a mini-avalanche.
The behavior will follow the same probability distribution since the distribution of outputs for a given AI is the same as for the human it is a functional copy of. Think of a thousand piles of sand from the same well-mixed batch - each of them is slightly different, but any one pile falls within the distribution.