Transparency and AGI safety
post by jylin04 · 2021-01-11T18:51:50.022Z · LW · GW · 12 commentsContents
Introduction Why should longtermists care about transparency? AI timelines are uncertain (and could be much longer than suggested by forecasts based on compute) Motivation #1: Work on transparency could help to reduce this uncertainty Inner AGI alignment problems otherwise seem hard to solve Toy models of AGI Subtypes of alignment problem Motivation #2: Transparency seems necessary to guard against emergent misbehavior Motivation #3: Exact transparency could solve AGI safety via control What if AI will go well by default without any intervention from longtermists today? Operationalizing agency Which things constrain a system's high-level action space? Reasons that the first AGI may be safely non-agentic Motivation #4: Work on transparency could still be instrumentally valuable in such a world Summary of this section Towards transparent AI in practice Review of the circuits program Summary of the technical approach High-level vision Challenges to the vision Directions for future work Direction #1: Following up on modularity Direction #2: Following up on subjectivity Direction #3: Apply the circuits program to other architectures Direction #4: Develop an end-to-end picture for AGI safety Figures Notes None 12 comments
Introduction
Transparency is the problem of going inside the black box of an AI system and understanding exactly how it works, by tracking and understanding the processes in its internal state.
In this post, I’ll argue that making AI systems more transparent could be very useful from a longtermist or AI safety point of view. I’ll then review recent progress on this centered around the circuits program being pursued by the Clarity team at OpenAI, and finally point out some directions for future work that could be interesting to pursue.
Some definitions that I’ll use in this note are that
- Transformative AI (TAI) is AI that precipitates a social transition on the scale of the Industrial Revolution.
- Artificial general intelligence (AGI) is usually more vaguely defined as an AI system that can do anything that humans can do. Here, I’ll operationally take it to mean “AI that can outperform humans at the task of generating qualitative insights into technical AI safety research,” for instance by coming up with new research agendas that turn out to be fruitful.
Why should longtermists care about transparency?
I’ll start by summarizing my views on AI safety and why I think that transparency could help with it. The upshot is that I think that AGI is fairly likely to go well by default (in a sense that I'll explain more below), but that work on transparency
- … could help to reduce our considerable uncertainties around AI timelines,
- … seems broadly useful, if not necessary, to solve the (inner) alignment problem in a world where the development of advanced AI doesn’t go well by default,
- … provides a solution in principle for AGI safety via control, and
- … could nonetheless be instrumentally useful for longtermists in a world where advanced AI goes well by default.
This section is organized according to these four items.
AI timelines are uncertain (and could be much longer than suggested by forecasts based on compute)
A first comment is that AI timelines seem to me to be rather uncertain, and in particular could be much longer than suggested by forecasts based on compute. This is because such forecasts assume that today’s algorithms + the datasets that will be available under business as usual will scale up to TAI or AGI given unlimited compute, but it's not clear to me that this has to be true. Since the usefulness of AI safety research today likely decays with longer timelines due to a nearsightedness penalty, reducing these uncertainties seems important to shed light on how much we should be investing into AI safety research today.
More concretely, here is a strawman argument for why one might think that today's algorithms will definitely be able to scale up to AGI:
A useful picture to have in mind when thinking about timelines is that ML algorithms are search algorithms over a space parametrized by the values of the model parameters to be learned, e.g. the space of weights for a neural network. Moreover, for neural networks in particular, the universal approximation theorem (UAT) tells us that for any (bounded) capability that we might want an AI system to have, there exists some search space containing models with that capability [^1]. From this point of view, the problem of trying to build an AI system with a given capability is naively just a balancing act between picking a search space large enough to contain such models, yet small enough that we can find those models in finite time, and increasing the amount of available compute relaxes the second bound.
However, the problem with this argument is that algorithms like SGD aren't systematic searches over this space. Rather, they depend on the interplay of the model initialization with the choice of dataset / environment, which together pick out a (stochastic set of) path(s) over the naive search space [^2]. It could be that generic such paths would force us into some subspace of the search space, thereby invalidating the appeal to the UAT even in theory (in that it does us no good to say that we have models with desired capabilities somewhere in our search space if we don’t know how to find them).
This problem is related to other cruxes in AI forecasting. E.g.
- Can we get to TAI by training blank-slate models?
A first and frequently debated crux is whether we can get to TAI from end-to-end training of models specified by relatively few bits of information at initialization, such as neural networks initialized with random weights. OpenAI in particular seems to take the affirmative view[^3], while people in academia, especially those with more of a neuroscience / cognitive science background, seem to think instead that we'll have to hard-code in lots of inductive biases from neuroscience to get to AGI [^4].
From the point of view that we all agree that the UAT is true but are unsure if generic combinations of initialization + dataset will let us find the solutions that we want, this question is basically asking: "How important are the model initializations for reaching a desired outcome, keeping the dataset fixed?" E.g., we know that the dataset of video frames from a Coursera course is sufficient for some neural networks (that approximate whatever function it is that human brains compute) to learn the material in the course. But it could be that sufficiently human-like networks are very rare in the space of large neural networks, such that most of our efforts would have to go into indeed borrowing insights from neuroscience to reverse-engineer the appropriate initial conditions.
- Will AGI require an "evolution-like” phase of pretraining RL agents in a simulation?
Another crux is around whether the development of AGI might require a pretraining phase where we train RL agents in a simulated environment on an objective different from what we ultimately want them to do.
From the present point of view that different model initializations + datasets map to different paths over an algorithm's search space, the context here is that if we now would keep the initialization fixed, it could be that datasets leading to models with the desired capabilities are actually quite rare [AF · GW]. Intuitively, a narrow basin of attraction to an advanced capability could reflect a need for curriculum learning. E.g., perhaps future AI systems that are able to do very well on high school math contests will turn out to be reliably trainable only starting from models that can already do arithmetic perfectly, while other models fed on datasets of math questions would just flail about in the search space and get stuck.
The cognitive abilities to learn efficiently, reason, plan, ... are themselves advanced capabilities, and if this "hard paths hypothesis" is true, it could be that the path to AGI itself will require a curriculum learning sequence whose details we don't yet understand [^5]. For example, Yann LeCun has suggested that a rudimentary form of concept-learning might emerge spontaneously from an embodied agent practicing self-supervised learning in an environment similar to ours:
"To learn that the world is three-dimensional, if we train our brains to predict what the world is going to look like when we move our head a little bit or when we switch from our left eye to our right eye view, the best explanation for how the world changes is the fact that every object (or pixel, if you want) has a depth because that explains parallax motion. So it's quite possible to imagine that if we train ourselves to predict how the world changes as the camera moves, implicitly the system that is trained to do this will learn to represent depth, as a side effect. Now once you have depth, you have occlusion edges from objects, so you have objects. Once you have objects, you can make the difference between animate and inanimate objects [as] the ones whose trajectories are predictable or not. So that's perhaps by which we build sort of a hierarchy of representations and concepts... just by observation.”
Others have suggested that the human capability to do math may have similar origins.
The narrower the path to AGI, the more valuable it seems to be if we could automate the search for that path, rather than trying to guess it by ourselves. This sort of "autocurricular learning" is what we would gain by having RL agents learn from self-play in a rich simulated environment.
To summarize, even if one assumes the UAT in the current deep learning paradigm, the choice of model initialization + dataset that would let us get to AGI may be highly non-generic. To the extent that this is true, it pushes towards (indefinitely) longer timelines than forecasted in analyses based on compute, since practitioners might then have to understand an unknown number of qualitatively new things around setting initial conditions for the search problem.
Motivation #1: Work on transparency could help to reduce this uncertainty
This leads to a first motivation for transparency research: that getting a better understanding of how today's AI systems work seems useful to let us make better-educated guesses about how they might scale up.
For example, learning more about how GPT-3 works seems like it could help us to reason better about whether the task of text prediction by itself could ever lead to AGI, which competes with the hard paths hypothesis. (For examples of the type of insights that we might hope to gain from applying transparency tools, see Part 2 of this note below.)
Inner AGI alignment problems otherwise seem hard to solve
Let's move on to how transparency could help with classic problems in AGI safety.
In a sentence, my understanding of the problem of AGI safety (see here [? · GW] for a nice review) is that agentic AGI would basically be like an alien, and sharing our world with more intelligent aliens generically seems bad; but since these aliens would be of our own design, maybe we can design them in ways that would turn out to be less bad.
There seems to be substantial disagreement even within this community, and certainly in the AI community at large, about whether AGI safety is a real problem that we'll have to solve. (An alternative is that it could be solved by default instead, e.g. if AGI would turn out to be "non-agentic" by default.) I'll say more about this in the next section and indeed am sympathetic to the contrarian view, but for now, let me assume that we want to solve the classic problem.
The ways that people go about trying to do this seem to fall into two categories:
- alignment, which is the problem of how to make advanced AI systems actually do what we want, and
- control, which is the stopgap measure of otherwise figuring out how to retain control over a misaligned AI (for example by retaining the ability to turn it off, despite its greater intelligence),
and I claim that transparency would be quite helpful to make progress in both directions.
Toy models of AGI
To reason about AGI, I find it helpful to imagine toy models for it which are grounded in situations that we understand. So suppose we assume the situation described above where the path to AGI goes through a step of pretraining RL agents on an "evolution-like” objective unrelated to what we actually want them to do. I assume this not because I think that AGI will definitely go this way, but because I think the alignment issues that come up in this case would encompass the ones that appear in more prosaic situations.
At the end of this pretraining step, we'd basically have a bunch of super smart aliens doing their own thing in a perfectly boxed simulation. How could we fine-tune them to do useful things for us without going off the rails? [^6]
This is some future version of a transfer learning problem, so we can take inspiration from transfer learning strategies for current RL systems. One of the first questions that people face when doing transfer learning in RL today is how to turn the target problem (to be transferred to) into a Markov decision process (MDP). If the target MDP is identical or very close to the source MDP (to be transferred from), then we can just transfer the learned policy wholesale and fine-tune it from there, keeping the same input/output channels for our RL agent. If on the other hand the two are very far apart, it may be easier to design and train a new system on the target problem with different input/output channels, keeping just some of the learned representations from the source network (e.g. by freezing the weights of the source network and coupling a new network to it).
By scaling up these two extremes, we reach two possible toy models for AGI:
- An "alien in a box". The first is that we could imagine physically instantiating the pretrained RL agents directly into robot bodies, keeping the weights that they learned in simulation and the same input/output channels; perhaps putting the robot bodies into additionally data-limited containers for safety; and then letting them update their weights on new inputs in real time. I think this is pretty close to what people had in mind in classic takes on AI safety like in Superintelligence.
- "Lobotomized aliens". Alternatively, we could imagine somehow isolating the cognitively interesting parts of a pretrained RL agent from any motivational drives that it acquired in the simulation [^7] and retraining just those parts as if they were a "neural network 2.0", somehow much better at learning things than today's algorithms but otherwise fitting exactly into the current deep learning paradigm.
Subtypes of alignment problem
Returning to the alignment problem, it's a big problem, and to tackle it we might want to split it up into smaller parts and tackle the parts separately. Different people have partitioned it in different ways, that fit more or less naturally with each of the toy models above.
From the machine learning ("lobotomized alien") point of view, a natural way to partition the alignment problem is as
- an outer alignment (specification) problem of making sure that our systems are designed with utility / loss functions that would make them do what we intend for them to do in theory, and
- an inner alignment (distribution shift) problem of making sure that a system trained on a "theoretically correct" objective with a finite-sized training set would keep on pursuing that objective when deployed in a somewhat different environment than the one that it trained on.
From the more anthropomorphic "alien in a box" point of view on the other hand, one might instead find it natural to slice up [? · GW] the alignment problem into
- a competence (translation) problem of making the AI system learn to understand what we want, and
- an intent alignment problem of making the AI system care to do what we want, assuming that it understands us perfectly well.
A thing that nearly all of these components have in common though is that they involve having to account for emergent behavior that wasn't part of the top-down specification of the AI system, and that therefore can't be understood using only formal top-down arguments [^8]. In the first, ML-inspired split, this is basically by definition the partition of the problem into inner and outer alignment problems: the outer part is the part that we specify and the inner part is the part that we don't. But in the second split, both the internal representations that the "alien" would use to understand us and the motivational drives that it acquires during "evolution" would be things that emerge from the evolutionary training process as opposed to things that we get to specify from the top down.
This problem of having to account for emergent misbehavior is quite general. Although it's underscored by the ML paradigm of extremizing a fixed utility function, it goes well beyond that paradigm. Rather, it will be relevant as long as learning involves an interaction between a system with many degrees of freedom and noisy data, which I expect to be broadly true as more of a statement about the nature of data than a commitment to a particular type of algorithm.
Motivation #2: Transparency seems necessary to guard against emergent misbehavior
This leads to a second motivation for transparency research, which is that to defend against emergent misbehavior in all situations that an agentic AGI could encounter when deployed, it seems necessary to me that we understand something about the AI's internal cognition.
This is because I usually see people point to three ideas for attacking distribution shift: adversarial training, transparency, and verification. But we can't guarantee ahead of time that adversarial training will catch every failure mode, and verification requires that we characterize the space of possible inputs, which seems hard to scale up to future AI systems with arbitrarily large input/output spaces [^9]. So this is in no way a proof but is a failure of my imagination otherwise (and I'd be very excited to hear about other ideas!).
As a sanity check, in Evan Hubinger's recent review of 11 proposals for building safe AI [AF · GW], either sufficient interpretability or myopia seems to be a necessary step for inner alignment in all of the proposals, sometimes in combination with other things like adversarial training. I consider sufficiently myopic systems to be non-agentic and will discuss them in the next section.
Motivation #3: Exact transparency could solve AGI safety via control
A third motivation is that exact transparency would give us a mulligan [AF · GW]: a chance to check if something could go catastrophically wrong with a system that we've built before we decide to deploy it in the real world. E.g. suppose that just by looking at the weights of a neural network, we could read off all of the knowledge encoded inside the network. Then you could imagine looking into the "mind" of a paperclip-making AI system, seeing that for some reason it had been learning things related to making biological weapons, and deciding against letting it run your paperclip-making factory.
More precisely, the idea here is that since learning is a continuous process, with transparency we could shut off and discard models in the act of acquiring dangerous competencies before they actually acquire those competencies. This could lay the foundation for a theoretically complete, if perhaps impractical solution to AI risk via control.
(I haven't fleshed out how one would go from exact transparency to a full end-to-end solution for AGI safety via control, but it kind of seems like it should be possible by combining transparency with existing outer alignment techniques, say by automating a continuous monitoring process with more AI, and using some amplification [? · GW]-flavored thing to scale up to arbitrarily strong systems. The bottleneck here seems more likely to be that exact transparency is a very strong aspiration, that we're nowhere near to in practice.)
What if AI will go well by default without any intervention from longtermists today?
Putting on my devil's advocate hat, I'd now like to argue that advanced AI could go well by default in the sense that classic arguments for AI risk tend to rely on a vague notion of the AI being a "goal-directed agent," yet I think that the first AI system capable of qualitatively accelerating progress on technical AI safety research may be safely "non-agentic". My views here are similar to the ones in Eric Drexler's CAIS paper.
This section is both orthogonal to the rest of the post and incomplete (it's basically a first draft that I hesitated to include at all), so I'd recommend that people who are interested in the main story on transparency not spend too much time on it! At the same time, I'd be grateful for either pushback on this section or ideas on how to make it more precise.
Operationalizing agency
As we did above for alignment, let's start by rounding up some definitions of goal-directed agency. Unfortunately, there doesn't seem to be a canonical definition in the community.
In a recent take on this problem, Richard Ngo defines a system as being more “agenty” the more it exhibits each of six traits [? · GW] of self-awareness, planning, consequentialism, scale, coherence and flexibility. Of these, I'd especially like to emphasize the traits of
- planning: "[the AI] considers a wide range of possible sequences of [actions] (let’s call them “plans”), including long plans", and
- scale: "[the AI's] choices are sensitive to the effects of plans over large distances and long time horizons",
for reasons that will soon become clear.
In response to Richard's article, Ben Garfinkel defines a system as being more “agenty” the more it is [? · GW]
- useful to explain and predict the system's actions in terms of its goals;
- the further those goals lie in the future; and
- the further those goals lie outside a system's "domain of action" at any given time.
For example, AlphaGo does well on the first measure -- it's useful to explain its actions as trying to win a game of Go -- but less well on measures two and three, since it only cares about the effects of its actions up to the end of a game, and never takes actions in "other domains" to further its goal within the domain of Go. Here, I'm especially interested in the implication from item 3 that an agent should be able to take different types of actions across unrelated domains.
For another take, we can look to the difference between supervised learning (SL) and reinforcement learning algorithms, since RL algorithms are generally considered to be more agentic than SL ones. Actually, SL is a special case of RL in a degenerate MDP where
- no matter which state the RL agent is in, actions taken by it either do or don't return a reward of a fixed magnitude, after which
- the RL agent is teleported to a new random state.
In a typical MDP on the other hand, the magnitude of the reward signal depends on where the agent is in the state space of the MDP, which in turn depends on previous actions taken by the agent. This incentivizes an RL agent to learn sequences of actions that take it to more rewarding parts of the state space. If we coarse-grain coherent sequences of actions into new high-level ones (in a way that needs to be made more precise), then the main difference between SL and RL is that RL can lead to models with larger effective action spaces.
The point here is that our colloquial notion of agency seems to include a component where an agent should be able to take a wide range of high-level actions. This means that we can partly operationalize how "agenty" an AI system is by counting the number of high-level actions that it can take. It's not a very satisfactory operationalization both because it only partly overlaps with what we really mean by agency, and because what counts as a "high-level action" isn't well-defined.
Which things constrain a system's high-level action space?
That said, let’s run with it and brainstorm which things would constrain a system’s high-level action space.
A trivial constraint comes from the system's hard-coded, low-level action space. The number of high-level actions available to a system is combinatorially bounded by some function of the number of low-level actions available to it, and indeed it seems intuitively clear that AI systems with more restrictions on their output channels should be safer; there's little room for an AI to be dangerous if its only way to influence the world is to suggest moves for a game of Go. The idea of making AI systems safe by restricting the size of their low-level action space has been discussed elsewhere under the name of "boxing".
But with enough steps, even a very small space of low-level actions can give rise to emergent ones of great complexity, and the early AI risk literature is replete with scenarios where a boxed AI with few output channels finds a clever way to "get out of the box" (say, by broadcasting the recipe for a dangerous DNA sequence to a human accomplice in Morse code). So why doesn't AlphaGo hide coded DNA sequences in its outputs? The additional ingredient is selection pressure, namely that a system will only learn those sequences of actions that it has incentive to learn during training.
More precisely, we can divide selection pressure into two types. There’s a global selection pressure where a system will only learn those actions that could plausibly help it to achieve its goals. However, this leaves one open to worries about instrumental convergence. For a stronger constraint, we need to invoke what one might call local selection pressure: that a system will only learn those actions that could plausibly help it to achieve its goals and are not too far from its existing repertoire of thoughts and actions. In deep learning, the technical sense in which this is true is that learning takes place via the explicitly local process of gradient descent. For more advanced systems that reason and plan such as ourselves, the analog would be that a system will only invest in capabilities that seem useful to it given its existing world-model, so e.g. wouldn't think to master human psychology if it didn't know that humans exist, even if this would be a globally useful instrumental goal.
As with the earlier discussion around emergent misalignment, this point is underscored by the current ML paradigm but goes beyond that paradigm. Rather, it depends on the far more general view that learning is a continuous process of incrementally improving on existing ideas.
Reasons that the first AGI may be safely non-agentic
Given the above, here are some reasons why the first AGI may be safely non-agentic, i.e. have too small of a high-level action space to be an existential threat. Recall that I've defined “AGI” to mean “an AI system that can generate qualitatively new insights into technical AI safety research.”
- The first AGI may have write-only output channels reminiscent of “Oracle AI”.
The first reason is that since AI systems with strictly larger action spaces would take longer to train, there could be economic pressure towards the first AI system that can perform a given service being the one that does it with the fewest number of input/output channels possible. (E.g. the USPS doesn't train mail-sorting image classifiers to do ten other things besides making a guess for the zip code on a piece of mail.) This goes in the opposite direction to the usual handwaving that eventually, there may be some economic pressure towards building systems with large numbers of input/output channels.
A minimal AI system that can write blog posts about AI safety, or otherwise do theoretical science research, doesn't seem to require a large output space. It plausibly just needs to be able to write text into an offline word processor. This suggests that the first AGI may be close to what people have historically called an “Oracle AI [? · GW]”.
In my opinion, Oracle AIs already seem pretty safe by virtue of being well-boxed, without further qualification. If all they can do is write offline text, they would have to go through humans to cause an existential catastrophe. However, some might argue that a hypothetical Oracle AI that was very proficient at manipulating humans could trick its human handlers into taking dangerous actions on its behalf. So to strengthen the case, we should also appeal to selection pressure.
- The first (oracle) AGI won't have selection pressure to deceive humans.
To finish this argument, we would need to characterize what's needed to do AI safety research and argue that there exists a limited curriculum to impart that knowledge that wouldn't lead to deceptive oracle AI. I don't have a totally satisfactory argument for this (hence the earlier caveat!), but one bit of intuition in this direction is that the transparency agenda in this rest of this document certainly doesn't require deep (or any) knowledge of humans. The same seems true of at least a subset of other safety agendas, and we need only argue that AI that could accelerate progress in some parts of technical AI safety or otherwise change how we do intellectual work will come before plausibly dangerous agent AIs to reconsider how much to invest in object-level AI safety work today (since then it might make sense to defer some of the work to future researchers). We don't need to prove that a safe AGI oracle would solve the entire problem of AGI safety in one go.
To summarize, if we expect that there will be a window of time in the future when non-agentic tool AIs will significantly change the way that we do research, then technical AI safety work today may not have much of a counterfactual impact on the future. If we are confident the first AGI will be a non-agentic tool, we may even want to accelerate capabilities progress towards it instead!
Again, this argument is incomplete and I'd welcome either help with it or pushback on it.
Motivation #4: Work on transparency could still be instrumentally valuable in such a world
Even in such a world though, there are some non-AGI-safety reasons that transparency research could be well-motivated today.
One reason is that work on transparency could help to make AI safer for any level of assumption about the strength of the AI, so could be used to facilitate deployment of narrow AI systems for other altruistic causes. In this sense, it seems like an especially “low-risk” area for an EA-minded person with a technical background to work on.
Another is that it could be helpful for EA cause prioritization via Motivation #1.
Finally, work on transparency could help with field-building. Transparency, broadly defined as “the natural science of AI systems,” seems like an area that’s likely to grow in coming years (as long as interest in AI as a whole is here to stay). Yann LeCun has said that AI today is an engineering science, and engineering discoveries often precede the establishment of new natural science fields. If this turns out to be true, then getting involved relatively early could allow people to build up career capital in AI, which seems like a generally useful thing for longtermists to have.
To be clear though, these are much weaker motivations than a direct belief that AI safety work today would help to reduce x-risk, and if a more precise argument in this direction would hold up, then it might be good for EA to reconsider how much we should invest in technical AI safety work today.
Summary of this section
To summarize, transparency -- the problem of understanding why AI systems do what they do -- seems to me to be one of the safest bets for longtermists interested in AI safety to work on for several reasons, including that it could (1) help us to reduce uncertainties around AGI timelines, (2) be plausibly necessary to achieve inner alignment of advanced AI systems, (3) go most of the way towards providing a theoretical solution to AGI safety via control, and (4) be broadly useful for non-AGI-related reasons as well.
Towards transparent AI in practice
Let’s move on to how we might make AI systems more interpretable in practice.
I'll anchor this part of the post around the circuits program being pursued by the Clarity team at OpenAI, which is an especially well-developed approach to transparency in current deep learning systems. I'll first briefly review the program, then use some of the (well-known) gaps in it to motivate ideas for future work.
In addition to the published work that I've cited throughout the section, I should also mention at the outset that everything in this section is strongly inspired by unpublished work and discussions hosted on the Distill Slack!
Review of the circuits program
Summary of the technical approach
Given a neural network that we'd like to understand, the circuits program proceeds as follows.
1. Collect some descriptive data about what every neuron in the network is doing.
E.g. if we're trying to understand a vision model, we might tag each neuron in the model with a collection of images from the training set that cause that neuron to fire especially strongly, or with a feature visualization where we first feed white noise to the model, then optimize over the noise in the direction of making the target neuron fire strongly. OpenAI has done this for a selection of vision models and made the data publicly available on a site called OpenAI Microscope, with typical results like in Figure 1 below.
We can also imagine doing a similar thing for non-vision models, say by tagging the neurons inside RNNs with text snippets that they activate strongly on; see here [AF · GW] for some work in this direction.
2. Find clusters of neurons (circuits) that are closely connected, and use the data from step 1 to conjecture a causal interpretation for them.
We then look for clusters of neurons that are closely connected, and use the data from step 1 to make a guess for what's going on inside each cluster. In practice, this step is done manually for now. We might first pick a neuron from step 1 that seems to be doing something interesting (see Figure 1 below), then look at how the neurons in earlier layers conspire to make that thing happen.
The surprising and nontrivial discovery that we make when we try this is that (at least some of the time, in models studied so far) this step turns out to be tractable at all. For example, the "black and white detector" neuron in Figure 1 is connected by large negative weights to neurons in the previous layer that seem to activate on brightly-colored images. This suggests that perhaps the model has learned to approximately implement an algorithm of the form “Black and white = not (color 1 or color 2 or …)"; see Figure 2 below.
3. Test our conjectures.
Finally, we'd like to verify our conjectures, or at least test them further somehow. This is where most of the work that's gone into the circuits program so far has taken place.
At the single-neuron level, the most obvious way to test a conjecture that a neuron is sensitive to something is to throw many more data points at the neuron than the few that we used to come up with the conjecture. This idea of bouncing inputs off a neural network and seeing how it responds comes from visual neuroscience, but we're actually much better off in deep learning because we can much more quickly test a huge number of examples. See OpenAI's paper on curve detector neurons for a study along these lines.
As for circuits, the interpretation of circuits that are one layer deep follows directly from combining the interpretation of its component neurons with the naive interpretation of weights as either incentivizing or dis-incentivizing pairs of neurons from firing together: see Figures 2 and 3 below. For multi-layer circuits, the development of methods to verify them is work in progress, see the forthcoming curve circuits paper from OpenAI.
High-level vision
From results like these, the paper Zoom In: An Introduction to Circuits made three bold conjectures:
- Features are the fundamental units of neural networks. They correspond to directions [in the space of neurons]. They can be rigorously studied and understood.
- Features are connected by weights, forming circuits. These circuits can also be rigorously studied and understood.
- Analogous features and circuits form across models [that are trained on qualitatively similar data].
Challenges to the vision
However, in order to fully realize the vision for all neural networks, the circuits program will have to solve certain challenges (as acknowledged in the “Zoom In” article and elsewhere on the #circuits channel of the Distill Slack).
1. Computational tractability of scaling up the program.
The first is the computational tractability of carrying out the program for large neural networks. The first step described above, of tagging all the neurons in a neural network with dataset samples (as was done in the OpenAI Microscope), seems hard to scale up to large models as it grows with both network and dataset size.
One way around it might be to run a more coarse-grained version of steps 1 and 2 in reverse. We could first look for tightly-coupled groups of neurons (modules) inside a network, then map out how the different modules activate when we feed the network sample inputs (mimicking FMRI experiments in neuroscience), and only then go in and tag the neurons of the most active modules with more fine-grained data.
If we proceed in this way though, we might worry that the analysis could overlook subtle effects coming from the long tail of small weights that connect a module to seemingly less relevant neurons elsewhere in the network. I'll say more about this below.
2. Assumption of modular structure in the neural network.
The coarse-graining strategy requires that the network have a modular structure. Indeed, modularity (i.e., locality in which part of an AI system computes a particular capability or idea) was a necessary assumption for the entire logic of the circuits program to make sense. If in step 1 all of the neurons had seemed equally responsive to all inputs, we'd never have gotten a handle on which parts of the model to pay attention to. And if in step 2 each neuron had seemed to be randomly connected to all the other ones, we wouldn't have been able to pick out subgraphs of the network to zoom in on.
Fortunately, we also saw that this isn't what happens in practice. Instead, trained neural networks seem to have some amount of emergent modularity built in.
And perhaps this isn't surprising. After all, the real world is objectively well-described by discrete and compositional stuff (on the scales that we care about), and minds that can efficiently model an environment probably have an edge on being able to achieve their goals in said environment. So we might even conjecture that as AI systems get stronger, they'll naturally come with more disentangled representations, that would make them more amenable to this type of analysis.
That said, there's still a model-by-model question of whether the AI systems that we deploy will be modular enough for techniques like these to work well in practice.
3. Subjective nature of the results.
Finally, an orthogonal (and perhaps even more fundamental) problem is that the way that we chose to label neurons in this program was subjective. We decided that the neuron in Figure 1 was a black-and-white detector, and those in Figure 3 car component detectors, based on their responses to a finite number of examples. This introduces some observer-dependency into the program, and has led to debates around whether any of these neurons really track what we say they do, or if they're just responding to correlated patterns instead.
Directions for future work
These challenges suggest some directions for future work. [^10]
Direction #1: Following up on modularity
The circuits program is contingent on neural networks exhibiting some amount of modularity. More generally, AI systems that are more modular may be easier to interpret.
One follow-up direction that I've mentioned already would be to characterize the effects of the long tails of small weights that connect a given circuit to neurons outside the circuit. For example, having guessed the emergent algorithm in Figure 2, we might worry that our guess is too naive, with important contributions to the black-and-white detector being stored among other neurons besides the handful of "color detector neurons" shown in Figure 2. Or we might worry that the capability of black-and-white detection isn't localized to the module shown in Figure 2 (and related ones that we've identified), but is also redundantly encoded elsewhere in a way that's hard for humans to recognize.
One way to get some insight into these things might be to edit the network. To test the first thing, we could delete the "color detectors" and see how badly that degrades the performance of the black-and-white detector at finding black-and-white images, while to test the second one, we could delete the black-and-white circuit from InceptionV1, and see how badly that degrades the performance of InceptionV1 at transfer learning on the task of black-and-white vs. color image classification [^11]. It might be interesting to develop quantitative standards for checks along these lines.
Other directions include to
- Devise metrics to quantify the amount of modularity present in existing AI systems. See e.g. this recent paper from CHAI.
- See if we can make neural networks more modular without suffering too much of a performance tradeoff. This is probably related to the previous problem, since finding metrics to add to the loss function would be a zeroth-order way to approach it.
- Review the inter-network modular structure in state-of-the-art AI systems that go beyond single NNs. Many state-of-the-art systems today combine multiple neural networks with other moving parts. I'd find it useful to have a high-level survey of some of these architectures, with an eye towards how interpretable they seem to be.
Direction #2: Following up on subjectivity
A major challenge for the circuits program is that results obtained in it seem to be inherently subjective.
To think about which parts of the program can be made precise, it's useful to step back and remind ourselves of what neural networks are doing at a very elementary level.
In a supervised learning problem, a neural network learns to map a vector of size dim(input layer) to one of size dim(output layer) = #_{classes}, where every neuron in the output layer is assigned a label corresponding to one of the classes. Given a new input vector, we can then classify it by plugging it into the model, seeing which output neuron has the largest activation, and looking up the label assigned to that neuron.
Without that label, which was put there by a human engineer, our attempts at interpreting neurons in the output layer would be in the same logical state as attempts to interpret any of the neurons in the hidden layers. We might notice that a neuron in the last layer of a network trained on MNIST frequently activates on things that look like the digit "0", but the match wouldn't be 100% exact, and we wouldn't have an answer key to check our hunch against.
More concisely, each neuron in the final layer of a neural network defines a function
F(input vector) = activation of that neuron (*)
over the space of raw data, and a supervised network assigns to each new input the label corresponding to the largest of these functions.

The "features" step in circuits simply generalizes this to all neurons. Namely, every neuron in a neural network defines a function like (*) over the space of raw data [^12], and transparency methods aspire to understand (where) these functions (take on especially large values). (Note that this perspective works equally well for visual and non-visual models.)
In practice, these functions are hard to compute exactly, so we sample from them instead. E.g. feature visualizations involve picking a random starting point and hill-climbing to a local maximum of one of these functions, while dataset samples involve sampling from such functions at random points that happen to be a part of the dataset, and recording when the result happens to exceed some threshold value.

Given that what we really have access to are (samples from) functions like (*), it's clear that whether or not a feature aligns with a human-interpretable concept can't be made precise without added information about how the underlying raw data is related to a Platonic space of human ideas! In particular, we can get quantitative results by comparing a neuron's performance on a dataset with how a human chooses to manually label that same dataset (see the section “Human Comparison” in Curve Detectors), but we can’t avoid subjectivity.
We can, however, try to get rigorous and generalizable results about the functions learned by hidden-layer neurons in the abstract. E.g.
- Under what circumstances do (linear combinations of) neurons actually model aspects of the data distribution that they're trained on, as opposed to just encoding the decision boundaries between classes? Something like this seems necessary for feature visualization to work.
- How are features related to generalization?
- Do neurons that seem to represent "meaningful” things have typical shapes over the high-dimensional space of raw data? (This is as much a question about how the underlying data is structured -- an interesting question in and of itself! -- as it is about how that space is modeled by machine learning algorithms.)
And so on. Concrete directions that we could potentially follow up on include to
- Train neural networks on low-dimensional data distributions that we can specify analytically, and try to address some of these questions there. For example, following this paper, we could imagine solving a very small neural network trained on samples drawn from two 2d Gaussian blobs in hopes of learning things that would generalize to larger networks [^13][^14].
- Compare circuits work to existing work on loss landscapes in deep learning. Another strategy might be to go through the literature of existing results from other perspectives and look for synergies with the circuits approach. As a semi-random example, the linked paper in the previous bullet-point suggests that some directions in the loss landscape are more important than others; it might be interesting to understand if such directions play an interesting role from the circuits POV.
It's worth noting that this problem of subjectivity may become more tractable as our AI systems get stronger. In particular, if we knew that a future neural network-like system was capable of exactly representing symbolic operations such as addition with perfect accuracy, we could perhaps use insight into how it represents those operations to get a foothold into seeing how it encodes everything else. But today's models probably can't exactly represent such things.
Direction #3: Apply the circuits program to other architectures
I mentioned earlier that AI today resembles an engineering science, where the discovery of a useful artifact anticipates the development of a scientific field. One way that today's AI systems differ from past examples of this paradigm though is that they aren't just one artifact, but rather a collection of different architecture types that exhibit a wide range of different behaviors after training. A priori, it need not be the case that these different architectures will be explained by the same underlying theories, although it seems plausible that there will be high-level similarities between how they work. (Indeed, it need not even be the case that a given architecture type exhibits the same qualitative behavior as itself at a different scale, as Figure 3.10 in the GPT-3 paper weakly suggests!)
In this respect, today’s AI technologies are perhaps more like a collection of (virtual) materials that exhibit interesting behaviors, and transparency “the empirical study of intelligent materials”.
It follows that a shovel-ready set of interesting projects might be to apply transparency tools to other architectures besides the medium-sized CNNs that have been the focus of study so far. Language models, RL models (though see the recent Understanding RL vision) and the many different types of unsupervised learning models [^15] all seem like fair game. Since it's currently unclear how any of these architectures work, all of these projects would seem to have some chance of being genuinely interesting [^16].
These seem like they could make good "starter projects" for people to get involved with transparency research. See the #circuits channel on the Distill Slack for concrete project ideas along these lines.
Direction #4: Develop an end-to-end picture for AGI safety
Finally, to follow up on the discussion around Motivation #3, it might be interesting to flesh out how exact transparency could be combined with existing ideas for outer alignment to get an end-to-end story for aligning AGI.
To summarize, transparency seems like not only a well-motivated research direction but one with plenty to do, and I'm excited to see the progress in this field in the coming years!
Thanks to Owen Cotton-Barratt, Max Daniel, Daniel Eth, Owain Evans, Lukas Finnveden, Hamish Hobbs and Ben Snodin for comments on an earlier draft of this post.
Figures
All of these figures come from work by the OpenAI Clarity team.
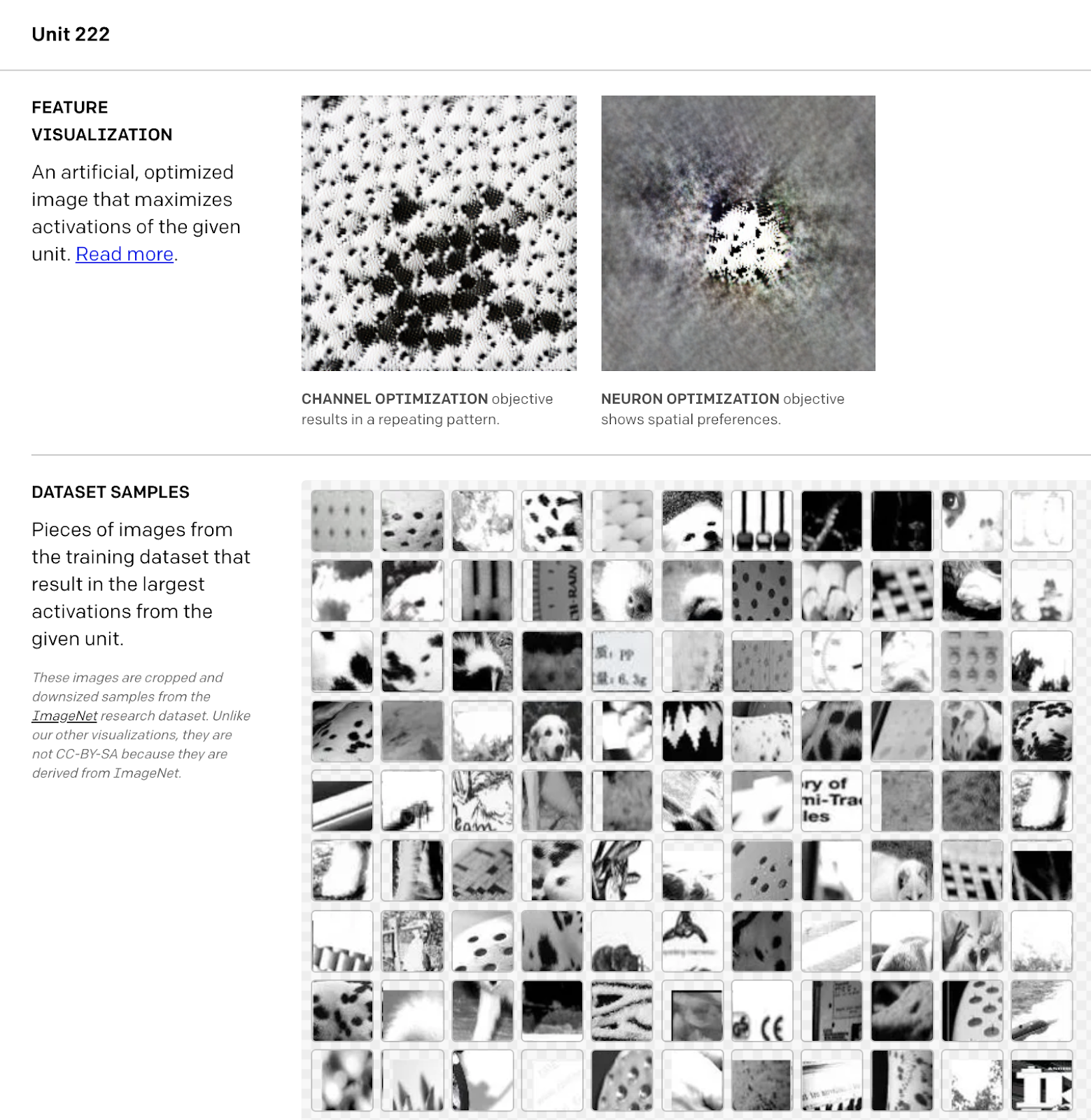
Figure 1: An example of descriptive data used to tag channel mixed3a:222 of InceptionV1, implementing step 1 of the circuits program for InceptionV1. The top row shows feature visualizations that maximize the mean activation of all the neurons in channel mixed3a:222 (left) and of the centermost neuron in the channel (right), while the bottom row shows examples of ImageNet images that the centermost neuron fires strongly on. This data suggests that the channel detects input images that are black and white. Figure taken from the OpenAI Microscope.

Figure 2: The “black and white detector” neuron of Figure 1 is connected by large negative weights to neurons in the previous layer that seem to like to fire on brightly-colored images. Figure taken from An Overview of Early Vision in InceptionV1.

Figure 3: An example of a circuit in the later layers of a neural network, where the neurons involved seem to align with more sophisticated meanings. Namely, a neuron that seems to activate on images of wheels and a neuron that seems to activate on images of windows incentivize the downstream activation of a neuron that seems to activate on images of cars. Figure taken from Zoom In: An Introduction to Circuits.
Notes
[^0] Transparency is part of a larger field called interpretability, which also includes (post-hoc) explainability: the problem of generating plausible, good enough explanations for what an AI system might be doing after the fact. The latter is useful for getting people to trust and adopt current AI systems but not so useful from a safety point of view.
[^1] In practice, we would probably never want the implementation of a function to be the one generated by the UAT, which turns infinitely large neural networks into lookup tables for functions. So I think that the UAT is even less useful for forecasting than the handwavy way that it's often referred to in this community.
[^2] One way to visualize this is that each choice of dataset first gives rise to a loss landscape over the search space of a model. The choice of initial conditions then determines where on the landscape we put a ball, that we (approximately) allow to roll to a local minimum.
[^3] Heuristics for this view include Rich Sutton’s bitter lesson and the success of scaling laws for AI models so far, although those laws apply to a specific set of capabilities.
[^4] A heuristic for this view is that the best-performing narrow models aimed at mimicking specific developmental capabilities often involve coupling neural networks to rather ad-hoc structures.
[^5] A handwavy argument in favor of AGI perhaps being bottlenecked by having a sufficiently Earth-like training environment in the future is that systems that evolved on Earth such as ourselves had selection pressure to be especially good at interacting with real-world datasets, which are also the only kind of dataset that we actually care about.
[^6] Alternatively, you could imagine that we're the aliens in a simulation being run by some much slower civilization, and ask how they might re-instantiate, communicate with and convince us to do economically useful things for them! See That Alien Message [LW · GW].
[^7] For example, we could imagine isolating the neocortex from all of the midbrain stuff in a simulated human, if one believes naive neuroscience theories that say that the neocortex is the seat of human intelligence.
[^8] Unless we someday understand AI systems well enough to map (model initialization, training set) pairs to an exact understanding of the cognition of the trained model. But this would basically be like solving transparency.
[^9] Unless we insist that our future AGI systems have small enough input/output spaces to make verification work. I consider such systems to be non-agentic and will address this in the next section.
[^10] These are just a small subset of open questions in and around the circuits program that seemed especially relevant to issues raised in Part 1. For longer lists of research questions (including some shovel-ready project ideas), see the section “Questions for future research” in Understanding RL vision and the #circuits channel on the Distill slack.
[^11] This idea comes from a post on the Distill slack by Chris Olah who did a similar experiment for curve detector neurons there.
[^12] As well as over the latent space defined by any earlier layer in the network.
[^13] Although we shouldn't expect such a simple laboratory to have something to say about all of the interesting questions. In particular, by approximating a data distribution with a Gaussian we coarse-grain over all of its internal structure, so we shouldn't expect human-interpretable features to be assigned to any of the hidden-layer neurons in this experiment.
[^14] Some work on this is in progress!
[^15] Note that many deep unsupervised learning algorithms are just vanilla NNs trained on unorthodox datasets when compared to the supervised learning case. This might make them seem less interesting to interpret if our goal is to discover general principles of some architecture class. In some ways though, it makes them more interesting: e.g. perhaps interpreting them could give us more insight into the earlier discussion that it's not a model choice in isolation, but rather the interplay of model choice + environment that we should think about when we think about timelines and so on. Also, the latent space in some of these models might open up new avenues for transparency work.
[^16] A challenge for this line of projects is that we wouldn't have analogs of the OpenAI Microscope to tell us which neurons to study. One way around this might be to work with small enough models that we could construct the analog of the OpenAI Microscope ourselves, as discussed around Direction #2. Another might be to coarse-grain over many neurons and apply transparency tools to entire layers or modules of a network at once (see e.g. the post Interpreting GPT [AF · GW]), although then we'd run the risk of averaging out interesting information, and have to deal with the issues from Direction #1.
12 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2021-01-12T00:13:43.947Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
This post identifies four different motivations for working on transparency:
1. By learning more about how current neural networks work, we can improve our forecasts for AI timelines.
2. It seems _necessary_ for inner alignment. In particular, whatever AI development model you take, it seems likely that there will be some possibility of emergent misbehavior, and there doesn’t yet seem to be a way to rule that out except via transparency.
3. A good solution to transparency would be _sufficient_ for safety, since we could at least notice when AI systems were misaligned, and then choose not to deploy them.
4. Even if AI will “go well by default”, there are still instrumental reasons for transparency, such as improving cause prioritization in EA (via point 1), and for making systems more capable and robust.
After reviewing work on <@circuits@>(@Thread: Circuits@), the post suggests a few directions for future research:
1. Investigating how modular neural networks tend to be,
2. Figuring out how to make transparency outputs more precise and less subjective,
3. Looking for circuits in other networks (i.e. not image classifiers), see e.g. <@RL vision@>(@Understanding RL Vision@),
4. Figuring out how transparency fits into an end-to-end story for AI safety.
Planned opinion:
I’m on board with motivations 2 and 3 for working on transparency (that is, that it directly helps with AI safety). I agree with motivation 4, but for a different reason than the post mentions. If by “AI goes well by default” we mean that AI systems are trying to help their users, that still leaves the AI governance problem. It seems that making these AI systems transparent would be significantly helpful; it would probably enable a “right to an explanation”, for example. I don’t agree with motivation 1 as much: if I wanted to improve AI timeline forecasts, there are a lot of other aspects I would investigate first. (Specifically, I’d improve estimates of inputs into <@this report@>(@Draft report on AI timelines@).) Part of this is that I am less uncertain than the author about the cruxes that transparency could help with, and so see less value in investigating them further.
Other comments (i.e. not going in the newsletter):
I feel like the most interesting parts of this post are exactly the parts I didn't summarize. (I chose not to summarize them because they felt quite preliminary, where I couldn't really extract a key argument or insight that I believed.) But some thoughts about them:
- The "alien in a box" hypothetical made sense to me (mostly), but I didn't understand the "lobotomized alien" hypothetical. I also didn't see how this was meant to be analogous to machine learning. One concrete question: why are we assuming that we can separate out the motivational aspect of the brain? (That's not my only confusion, but I'm having a harder time explaining other confusions.)
- It feels like your non-agentic argument is too dependent on how you defined "AGI". I can believe that the first powerful research accelerator will be limited to language, but that doesn't mean that other AI systems deployed at the same time will be limited to language.
- It seems like there's a pretty clear argument for language models to be deceptive -- the "default" way to train them is to have them produce outputs that humans like; this optimizes for being convincing to humans, which is not necessarily the same as being true. (However, it's more plausible to me that the first such model won't cause catastrophic risk, which would still be enough for your conclusions.)
↑ comment by jylin04 · 2021-01-14T16:22:25.057Z · LW(p) · GW(p)
Thanks Rohin! Agree with and appreciate the summary as I mentioned before.
I don’t agree with motivation 1 as much: if I wanted to improve AI timeline forecasts, there are a lot of other aspects I would investigate first. (Specifically, I’d improve estimates of inputs into <@this report@>(@Draft report on AI timelines@).) Part of this is that I am less uncertain than the author about the cruxes that transparency could help with, and so see less value in investigating them further.
I'm curious: does this mean that you're on board with the assumption in Ajeya’s report that 2020 algorithms and datasets + "business as usual" in algorithm and dataset design will scale up to strong AI, with compute being the bottleneck? I feel both uncertain about this assumption and uncertain about how to update on it one way or the other. (But this probably belongs more in a discussion of that report and is kind of off topic here.)
- The "alien in a box" hypothetical made sense to me (mostly), but I didn't understand the "lobotomized alien" hypothetical. I also didn't see how this was meant to be analogous to machine learning. One concrete question: why are we assuming that we can separate out the motivational aspect of the brain? (That's not my only confusion, but I'm having a harder time explaining other confusions.)
A more concrete version of the “lobotomized alien" hypothetical might be something like this: There’s this neuroscience model that sometimes gets discussed around here that human cognition works by running some sort of generative model over the neocortex, with a loss function that's modulated by stuff going on in the midbrain (see e.g. https://www.lesswrong.com/posts/diruo47z32eprenTg/my-computational-framework-for-the-brain [LW · GW]). Suppose that you buy this theory, and now suppose that we’re the AIs being trained in a simulation by a more advanced alien race. Then one way that the aliens could try to get us to do stuff for them might be to reinstantiate just a human neocortex and train it from scratch on a loss function + dataset of their choice, as some sort of souped-up unsupervised learning algorithm.
In this example, I’m definitely just assuming by fiat that the cognition and motivation parts of the brain are well-separated (and moreover, that the aliens are able to discover this, say by applying some coarse-grained transparency tools). So it’s just a toy model for how things *could* go, not necessarily how they *will* go.
- It feels like your non-agentic argument is too dependent on how you defined "AGI". I can believe that the first powerful research accelerator will be limited to language, but that doesn't mean that other AI systems deployed at the same time will be limited to language.
Hmm. I think I agree that this is a weak point of the argument and it's not clear how to patch it. I think I had some intuition like, even once we have some sort of pretrained AGI algorithm (like an RL agent trained in simulation), we would have to fine-tune it on real-world tasks one at a time by coming up with a curriculum for each of those tasks; this seems easier to do for simple bounded tasks than for more open-ended ones (though in some sense that needs to be made more precise, and is maybe already assuming some things about alignment); and "research acceleration" seems like a much narrower task with a relatively well-defined training set of papers, books, etc. than "AI agent that competently runs a company", so might still come first on those grounds. But even then it would have to come first by a large enough margin for insights from the research accelerator to actually be implemented, for this argument to work. So there's at least a gap there...
- It seems like there's a pretty clear argument for language models to be deceptive -- the "default" way to train them is to have them produce outputs that humans like; this optimizes for being convincing to humans, which is not necessarily the same as being true. (However, it's more plausible to me that the first such model won't cause catastrophic risk, which would still be enough for your conclusions.)
Yeah, fair enough. I should have said that I don't see a path for language models to get selection pressure in the direction of being catastrophically deceptive like in the old "AI getting out of the box" stories, so I think we agree.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-01-14T18:06:09.427Z · LW(p) · GW(p)
I'm curious: does this mean that you're on board with the assumption in Ajeya’s report that 2020 algorithms and datasets + "business as usual" in algorithm and dataset design will scale up to strong AI, with compute being the bottleneck?
Yes, with the exception that I don't know if compute will be the bottleneck (that is my best guess; I think Ajeya's report makes a good case for it; but I could see it being other factors as well).
I think the case for is basically "we see a bunch of very predictable performance lines; seems like they'll continue to go up". But more importantly I don't know of any compelling counterpoints; the usual argument seems to be "but we don't see any causal reasoning / abstraction / <insert property here> yet", which I think is perfectly compatible with the scaling hypothesis (see e.g. this comment [LW(p) · GW(p)]).
A more concrete version of the “lobotomized alien" hypothetical might be something like this
I see, that makes sense, and I think it does make sense as an intuition pump for what the "ML paradigm" is trying to do (though as you sort of mentioned I don't expect that we can just do the motivation / cognition decomposition).
"research acceleration" seems like a much narrower task with a relatively well-defined training set of papers, books, etc. than "AI agent that competently runs a company", so might still come first on those grounds.
Definitely depends on how powerful you're expecting the AI system to be. It seems like if you want to make the argument that AI will go well by default, you need the research accelerator to be quite powerful (or you have to combine with some argument like "AI alignment will be easy to solve").
I don't think papers, books, etc are a "relatively well-defined training set". They're a good source of knowledge, but if you imitate papers and books, you get a research accelerator that is limited by the capabilities of human scientists (well, actually much more limited, since it can't run experiments). They might be a good source of pretraining data, but there would still be a lot of work to do to get a very powerful research accelerator.
I should have said that I don't see a path for language models to get selection pressure in the direction of being catastrophically deceptive like in the old "AI getting out of the box" stories, so I think we agree.
Fwiw I'm not convinced that we avoid catastrophic deception either, but my thoughts here are pretty nebulous and I think that "we don't know of a path to catastrophic deception" is a defensible position.
comment by adamShimi · 2021-01-13T18:26:14.165Z · LW(p) · GW(p)
Thanks a lot for all the effort you put into this post! I don't agree with everything, but reading and commenting it was very stimulating, and probably useful for my own research.
In this post, I’ll argue that making AI systems more transparent could be very useful from a longtermist or AI safety point of view. I’ll then review recent progress on this centered around the circuits program being pursued by the Clarity team at OpenAI, and finally point out some directions for future work that could be interesting to pursue.
I'm quite curious about why you wrote this post. If it's for convincing researchers in AI Safety that transparency is useful and important for AI Alignment, my impression is that many researchers do agree, and those who don't tend to have thought about it for quite some time (Paul Christiano comes to mind, as someone who is less interested in transparency while knowing a decent amount about it). So if the goal was to convince people to care about transparency, I'm not sure this post was necessary.
I'm not saying I don't find value this post. As a big fan of the circuit research, I'm glad to have more in-depth discussion about and around it. I am simply trying to understand what you wanted to do with this post, to give you better feedback.
Artificial general intelligence (AGI) is usually more vaguely defined as an AI system that can do anything that humans can do. Here, I’ll operationally take it to mean “AI that can outperform humans at the task of generating qualitative insights into technical AI safety research,” for instance by coming up with new research agendas that turn out to be fruitful.
Nitpicking here, but I assume you mean coming up with a high enough proportion of new research agendas, instead of just coming up with some. That changes removes stupid edge cases like programs writing all the permutations of some sentences about AGI, which would probably generate at least some useful ideas among the noise.
To summarize, even if one assumes the UAT in the current deep learning paradigm, the choice of model initialization + dataset that would let us get to AGI may be highly non-generic. To the extent that this is true, it pushes towards (indefinitely) longer timelines than forecasted in analyses based on compute, since practitioners might then have to understand an unknown number of qualitatively new things around setting initial conditions for the search problem.
I agree with the idea, with maybe the caveat that it doesn't apply to Ems à la Hanson. A similar argument could hold about neuroscience facts we would need to know to scan and simulate brains, though.
Motivation #1: Work on transparency could help to reduce this uncertainty
This leads to a first motivation for transparency research: that getting a better understanding of how today's AI systems work seems useful to let us make better-educated guesses about how they might scale up.
For example, learning more about how GPT-3 works seems like it could help us to reason better about whether the task of text prediction by itself could ever lead to AGI, which competes with the hard paths hypothesis. (For examples of the type of insights that we might hope to gain from applying transparency tools, see Part 2 of this note below.)
This argument applies to every part of ML that studies how learned model works and why. So as itself, it's insufficient for privileging transparency over theoretical work on neural nets, for example.
From the machine learning ("lobotomized alien") point of view, a natural way to partition the alignment problem is as
- an outer alignment (specification) problem of making sure that our systems are designed with utility / loss functions that would make them do what we intend for them to do in theory, and
- an inner alignment (distribution shift) problem of making sure that a system trained on a "theoretically correct" objective with a finite-sized training set would keep on pursuing that objective when deployed in a somewhat different environment than the one that it trained on.
From the more anthropomorphic "alien in a box" point of view on the other hand, one might instead find it natural to slice up [? · GW] the alignment problem into
- a competence (translation) problem of making the AI system learn to understand what we want, and
- an intent alignment problem of making the AI system care to do what we want, assuming that it understands us perfectly well.
I really like the way you present the two point of view and how they partition the alignment problem. It's going to be quite useful for me. Notably, I almost always take the "lobotomized alien" perspective, but now I can remind myself to make that a choice and see if the "alien in a box" perspective is more appropriate. Thanks!
Motivation #2: Transparency seems necessary to guard against emergent misbehavior
This leads to a second motivation for transparency research, which is that to defend against emergent misbehavior in all situations that an agentic AGI could encounter when deployed, it seems necessary to me that we understand something about the AI's internal cognition.
I completely agree with this motivation, and it is really well presented.
But we can't guarantee ahead of time that adversarial training will catch every failure mode, and verification requires that we characterize the space of possible inputs, which seems hard to scale up to future AI systems with arbitrarily large input/output spaces [^9]. So this is in no way a proof but is a failure of my imagination otherwise (and I'd be very excited to hear about other ideas!).
My take on why verification might scale is that we will move towards specification of properties of the program instead of it's input/output relation. So verifying whether the code satisfy some formal property that indicates myopia or low goal-directedness. Note that transparency is still really important here, because even with completely formal definitions of things like myopia and goal-directedness, I think transparency will be necessary to translate them into properties of the specific class of models studied (neural networks for example).
A third motivation is that exact transparency would give us a mulligan [AF · GW]: a chance to check if something could go catastrophically wrong with a system that we've built before we decide to deploy it in the real world. E.g. suppose that just by looking at the weights of a neural network, we could read off all of the knowledge encoded inside the network. Then you could imagine looking into the "mind" of a paperclip-making AI system, seeing that for some reason it had been learning things related to making biological weapons, and deciding against letting it run your paperclip-making factory.
I think this misses a very big part of what makes a paperclip-maximizer dangerous -- the fact that it can come up with catastrophic plans after it's been deployed. So it doesn't have to be explicitly deceptive and bidding it's time; it might just be really competent and focused on maximizing paperclips, which requires more than exact transparency to catch. It requires being able to check properties that ensures the catastrophic outcomes won't happen.
But I still think your motivation makes sense for a part of deceptive alignment. My more general caveat is that I don't believe in exact transparency, so I am more for a mixed transparency and verification approach (as mentioned above).
A minimal AI system that can write blog posts about AI safety, or otherwise do theoretical science research, doesn't seem to require a large output space. It plausibly just needs to be able to write text into an offline word processor. This suggests that the first AGI may be close to what people have historically called an “Oracle AI [? · GW]”.
In my opinion, Oracle AIs already seem pretty safe by virtue of being well-boxed, without further qualification. If all they can do is write offline text, they would have to go through humans to cause an existential catastrophe. However, some might argue that a hypothetical Oracle AI that was very proficient at manipulating humans could trick its human handlers into taking dangerous actions on its behalf. So to strengthen the case, we should also appeal to selection pressure.
An AI who does AI Safety research is properly terrifying. I'm really stunned by this choice, as I think this is probably one of the most dangerous case of oracle AI (and oracle AI is a pretty dangerous class by itself) that I can think of. I see two big problems with it:
- It looks like exactly the kind of tasks where, if we haven't solve AI alignment in advance, Goodhart is upon us. What's the measure? What's the proxy? Best scenario: the AI is clearly optimizing something stupid, and nobody cares. Worst case scenario, more probably because the AI is actually supposed to outperform humans: it pushes for something that looks like it makes sense but doesn't actually work, and we might use these insight to build more advanced AGIs and be fucked.
- It's quite simple to imagine a Predict-o-matic [AF · GW] type scenario: pushing simpler and easier models that appear to work but don't, so that its task becomes easier.
To finish this argument, we would need to characterize what's needed to do AI safety research and argue that there exists a limited curriculum to impart that knowledge that wouldn't lead to deceptive oracle AI. I don't have a totally satisfactory argument for this (hence the earlier caveat!), but one bit of intuition in this direction is that the transparency agenda in this rest of this document certainly doesn't require deep (or any) knowledge of humans. The same seems true of at least a subset of other safety agendas, and we need only argue that AI that could accelerate progress in some parts of technical AI safety or otherwise change how we do intellectual work will come before plausibly dangerous agent AIs to reconsider how much to invest in object-level AI safety work today (since then it might make sense to defer some of the work to future researchers). We don't need to prove that a safe AGI oracle would solve the entire problem of AGI safety in one go.
I don't think any of the intuitions given work, for a simple reason: even if the research agenda doesn't require in itself any real knowledge of humans, the outputs still have to be humanly understandable. I want the AI to write blog posts that I can understand. So it will have to master clear writing, which seems from experience to require a lot of modeling of the other (and as a human, I get a bunch of things for free unconsciously, that an AI wouldn't have, like a model of emotions).
Another issue with this proposal is that you're saying on one side that the AI is superhuman at technical AI safety, and on the other hand that it can only do these specific proposals that don't use anything about humans. That's like saying that you have an AI that wins at any game, but in fact it only works for chess. Either the AI can do research on everything in AI Safety, and it will probably have to understand humans; or it is specifically for one research proposal, but then I don't see why not create other AIs for other research proposals. The technology is available, and the incentives would be here (if only to be as productive as the other researchers who have an AI to help them).
Motivation #4: Work on transparency could still be instrumentally valuable in such a world
Even in such a world though, there are some non-AGI-safety reasons that transparency research could be well-motivated today.
I disagree with the previous argument, yet I find this motivation really useful, because if it's also useful when things go correctly, that's a good way to have people unconvinced by risks work on it.
Notably, I believe in pushing new entrants who want do to AI (and are not interested or ready to switch to AI Alignment) towards transparency, as this is a really useful subfield for alignment and it's one of the parts of AI that push capabilities the less.
Summary of the technical approach
Even for someone who read most of the circuits paper, I found this summary really clear and insightful. You might actually be where I redirect people for getting an idea of circuits!
One way to get some insight into these things might be to edit the network. To test the first thing, we could delete the "color detectors" and see how badly that degrades the performance of the black-and-white detector at finding black-and-white images, while to test the second one, we could delete the black-and-white circuit from InceptionV1, and see how badly that degrades the performance of InceptionV1 at transfer learning on the task of black-and-white vs. color image classification [^11]. It might be interesting to develop quantitative standards for checks along these lines.
These looks great! I hadn't thought about the issue you mention according to modularity, but it seems really important to settle, and your proposals are ingenious ways to study the question.
Compare circuits work to existing work on loss landscapes in deep learning. Another strategy might be to go through the literature of existing results from other perspectives and look for synergies with the circuits approach. As a semi-random example, the linked paper in the previous bullet-point suggests that some directions in the loss landscape are more important than others; it might be interesting to understand if such directions play an interesting role from the circuits POV.
I'm especially interested in this direction, as it seems highly relevant to my own research on gradient hacking [AF · GW].
Replies from: jylin04↑ comment by jylin04 · 2021-01-14T14:42:46.614Z · LW(p) · GW(p)
Thanks a lot for all the effort you put into this post! I don't agree with anything, but reading and commenting it was very stimulating, and probably useful for my own research.
Likewise, thanks for taking the time to write such a long comment! And hoping that's a typo in the second sentence :)
I'm quite curious about why you wrote this post. If it's for convincing researchers in AI Safety that transparency is useful and important for AI Alignment, my impression is that many researchers do agree, and those who don't tend to have thought about it for quite some time (Paul Christiano comes to mind, as someone who is less interested in transparency while knowing a decent amount about it). So if the goal was to convince people to care about transparency, I'm not sure this post was necessary.
Fair enough! Since I'm pretty new to thinking about this stuff, my main goal was to convince myself and organize my own thoughts around this topic. I find that writing a review is often a good way to get up to speed on something. Then once I’d written it, it seemed like I might as well post it somewhere.
Wrt the community though, I’d be especially curious to get more feedback on Motivation #2. Do people not agree that transparency is *necessary* for AI Safety? And if they do agree, then why aren’t more people working on it?
I agree with the idea, with maybe the caveat that it doesn't apply to Ems à la Hanson. A similar argument could hold about neuroscience facts we would need to know to scan and simulate brains, though.
Yeah, I'd add that if even we had a similar hardware-based forecast for mapping the human connectome, there would still be a lot that we don't know about dynamics there too. I have the impression that basically all ways to forecast things in this space have to make some non-obvious (to me) assumption that business as usual will scale up to strong AI without a need for qualitative breakthroughs.
My take on why verification might scale is that we will move towards specification of properties of the program instead of it's input/output relation. So verifying whether the code satisfy some formal property that indicates myopia or low goal-directedness. Note that transparency is still really important here, because even with completely formal definitions of things like myopia and goal-directedness, I think transparency will be necessary to translate them into properties of the specific class of models studied (neural networks for example).
I agree, but think that transparency is doing most of the work there (i.e. what you say sounds more to me like an application of transparency than scaling up the way that verification is used in current models.) But this is just semantics.
I think this misses a very big part of what makes a paperclip-maximizer dangerous -- the fact that it can come up with catastrophic plans after it's been deployed. So it doesn't have to be explicitly deceptive and bidding it's time; it might just be really competent and focused on maximizing paperclips, which requires more than exact transparency to catch. It requires being able to check properties that ensures the catastrophic outcomes won't happen.
Hm, I want to disagree, but this may just come down to a difference in what we mean by deployment. In the paragraph that you quoted, I was imagining the usual train/deploy split from ML where deployment means that we’ve frozen the weights of our AI and prohibit further learning from taking place. In that case, I’d like to emphasize that there’s a difference between intelligence as a meta-ability to acquire new capabilities and a system’s actual capabilities at a given time. Even if an AI is superintelligent, i.e. able to write new information into its weights extremely efficiently, once those weights are fixed, it can only reason and plan using whatever object-level knowledge was encoded in them up to that point. So if there was nothing about bio weapons in the weights when we froze them, then we wouldn't expect the paperclip-maximizer to spontaneously make plans involving bio weapons when deployed.
On the other hand, none of this would apply to the “alien in a box” model that would basically be continuously training by my definition (though in that case, we could still patch the solution by monitoring the AI in real time). So maybe it was a poor choice of words.
An AI who does AI Safety research is properly terrifying. I'm really stunned by this choice, as I think this is probably one of the most dangerous case of oracle AI that I can think of. I see two big problems with it:
- It looks like exactly the kind of tasks where, if we haven't solve AI alignment in advance, Goodhart is upon us. What's the measure? What's the proxy? Best scenario: the AI is clearly optimizing something stupid, and nobody cares. Worst case scenario, more probably because the AI is actually supposed to outperform humans: it pushes for something that looks like it makes sense but doesn't actually work, and we might use these insight to build more advanced AGIs and be fucked.
- It's quite simple to imagine a Predict-o-matic [LW · GW] type scenario: pushing simpler and easier models that appear to work but don't, so that its task becomes easier.
I don't think any of the intuitions given work, for a simple reason: even if the research agenda doesn't require in itself any real knowledge of humans, the outputs still have to be humanly understandable. I want the AI to write blog posts that I can understand. So it will have to master clear writing, which seems from experience to require a lot of modeling of the other (and as a human, I get a bunch of things for free unconsciously, that an AI wouldn't have, like a model of emotions).
These two comments seem related so let me reply to them together. I think what you're asking here is “how can we be sure that a "research accelerator" AI, trained to help with a self-contained AI safety agenda such as transparency, will produce solutions that we can understand before we implement them [so as to avoid getting tricked into implementing something that turns out to be bad, as in your first quote]?” And I would answer that I’ve made an assumption that knowledge is universal and new ideas are discovered by incrementally building on existing ones. This is why basically any student today knows more about science than the smartest people from a century ago, and on the flip side, I think would constrain how far beyond us the insights from early AGIs trained on our work could be. Suppose an AI system was trained on a dataset of existing transparency papers to come up with new project ideas in transparency. Then its first outputs would probably use words like neurons and weights instead of some totally incomprehensible concepts, since those would be the very same concepts that would let it efficiently make sense of its training set. And new ideas about neurons and weights would then be things that we could independently reason about even if they’re very clever ideas that we didn’t think of ourselves, just like you and I can have a conversation about circuits even if we didn’t come up with it.
Another issue with this proposal is that you're saying on one side that the AI is superhuman at technical AI safety, and on the other hand that it can only do these specific proposals that don't use anything about humans. That's like saying that you have an AI that wins at any game, but in fact it only works for chess. Either the AI can do research on everything in AI Safety, and it will probably have to understand humans; or it is specifically for one research proposal, but then I don't see why not create other AIs for other research proposals. The technology is available, and the incentives would be here (if only to be as productive as the other researchers who have an AI to help them).
Agree that there's a (strong!) assumption being made that "research accelerators for narrow agendas" will come before potentially dangerous AI systems. I think this might actually be a weak point of my story. Rohin asked something similar in the second bullet-point of his comment so I’ll try to answer there...
Replies from: adamShimi↑ comment by adamShimi · 2021-01-17T19:18:13.255Z · LW(p) · GW(p)
Likewise, thanks for taking the time to write such a long comment! And hoping that's a typo in the second sentence :)
You're welcome. And yes, this was as typo that I corrected. ^^
Wrt the community though, I’d be especially curious to get more feedback on Motivation #2. Do people not agree that transparency is *necessary* for AI Safety? And if they do agree, then why aren’t more people working on it?
My take is that a lot of people around here agree that transparency is at least useful, and maybe necessary. And the main reason why people are not working on it is a mix of personal fit, and the fact that without research in AI Alignment proper, transparency doesn't seem that useful (if we don't know what to look for).
I agree, but think that transparency is doing most of the work there (i.e. what you say sounds more to me like an application of transparency than scaling up the way that verification is used in current models.) But this is just semantics.
Well, transparency is doing some work, but it's totally unable to prove anything. That's a big part of the approach I'm proposing. That being said, I agree that this doesn't look like scaling the current way.
Hm, I want to disagree, but this may just come down to a difference in what we mean by deployment. In the paragraph that you quoted, I was imagining the usual train/deploy split from ML where deployment means that we’ve frozen the weights of our AI and prohibit further learning from taking place. In that case, I’d like to emphasize that there’s a difference between intelligence as a meta-ability to acquire new capabilities and a system’s actual capabilities at a given time. Even if an AI is superintelligent, i.e. able to write new information into its weights extremely efficiently, once those weights are fixed, it can only reason and plan using whatever object-level knowledge was encoded in them up to that point. So if there was nothing about bio weapons in the weights when we froze them, then we wouldn't expect the paperclip-maximizer to spontaneously make plans involving bio weapons when deployed.
You're right that I was thinking of a more online system that could update it's weights during deployment. Yet even with frozen weights, I definitely expect the model to make plans involving things that were not involved. For example, it might not have a bio-weapon feature, but the relevant subfeature to build some by quite local rules that don't look like a plan to build a bio-weapon.
Suppose an AI system was trained on a dataset of existing transparency papers to come up with new project ideas in transparency. Then its first outputs would probably use words like neurons and weights instead of some totally incomprehensible concepts, since those would be the very same concepts that would let it efficiently make sense of its training set. And new ideas about neurons and weights would then be things that we could independently reason about even if they’re very clever ideas that we didn’t think of ourselves, just like you and I can have a conversation about circuits even if we didn’t come up with it.
That seems reasonable.
comment by Charlie Steiner · 2021-01-12T11:34:31.977Z · LW(p) · GW(p)
Thanks!
I'm reminded a bit of the reason why Sudoku and quantum computing are difficult: the possibilities you have to track are not purely local, they can be a nonlocal combination of different things. General NNs seem like they'd be at least NP to interpret.
But this is what dropout is useful for, penalizing reliance on correlations. So maybe if you're having trouble interpreting something you can just crank up the dropout parameters. On the other hand, dropout also promotes redundancy, which might make interpretation confusing - perhaps there's something similar to dropout that's even better for interpretability.
Edit for unfiltered ideas:
You could automatically sample an image, find neurons excited, sample neurons, sample images based on how much they excite that neuron, etc, until you end up with a sampled pool of similar images and similar neurons. Then you drop out all similar neurons.
You could try anti-dropout: punishing the NN for redundancy and rewarding it for fragility/specificity. However, to avoid the incentive to create fine tuned activation/inhibition pairs, you only use positive activations for this step.
Replies from: jylin04↑ comment by jylin04 · 2021-01-14T14:45:46.274Z · LW(p) · GW(p)
Thanks for the comment! Naively I feel like dropout would make things worse for the reason that you mentioned and anti-dropout better, but I’m definitely not an expert on this stuff.
I’m not sure I totally understand your first idea. Is the idea something like
- Feed some images through a NN and record which neurons have high average activation on them
- Randomly pick some of those neurons and record which dataset examples cause them to have a high average activation
- Pick some subset of those images and iterate until convergence?
Replies from: DanielFilan, Charlie Steiner↑ comment by DanielFilan · 2021-01-14T18:20:26.433Z · LW(p) · GW(p)
One interesting fact my group discovered is that dropout seems to increase the extent to which a network was modular. We have some results on the topic here but a more comprehensive paper should be out soon.
Replies from: jylin04↑ comment by Charlie Steiner · 2021-01-15T07:36:52.318Z · LW(p) · GW(p)
Dropout makes interpretation easier because it disincentivizes complicated features where you can only understand the function of the parts in terms of their high-order correlations with other parts. This is because if a feature relies on such correlations, it will be fragile to some of the pieces being dropped out.
Anti-dropout promotes consolidation of similar features into one, but it also incentivizes that one feature to be maximally complicated and fragile.
Re: first idea. Yeah, something like that. Basically just an attempt at formalization of "functionally similar neurons," so that when you go to drop out a neuron, you actually drop out all functionally similar ones.
comment by Charlie Steiner · 2021-01-12T11:38:46.615Z · LW(p) · GW(p)
Re: non-agenty AGI. The typical problem is that there are incentives for individual actors to build AI systems that pursue goals in the world. So even if you postulate non-agenty AGI, you then have to further figure out why nobody has asked the Oracle AI "What's the code to an AI that will make me rich?" or asked it for the motor output of a robot given various sense data and natural-language goals, then used that output to control a robot (also see https://slatestarcodex.com/2020/01/06/a-very-unlikely-chess-game/ ).